






 本文介绍使用VGG16预训练模型进行迁移学习的过程,包括模型加载、数据预处理、训练配置及评估,展示了如何通过调整学习率和训练卷积基来优化模型性能。
本文介绍使用VGG16预训练模型进行迁移学习的过程,包括模型加载、数据预处理、训练配置及评估,展示了如何通过调整学习率和训练卷积基来优化模型性能。
from keras.applications import VGG16
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
from keras import models
from keras import layers
import matplotlib.pyplot as plt
from keras.callbacks import ModelCheckpoint
%matplotlib inline
conv_base = VGG16(weights='./VGG16.h5',
include_top=False,
input_shape=(150, 150, 3))
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(2048, activation='relu'))
model.add(layers.Dense(1024, activation='relu'))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dropout(0.2))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(61, activation='softmax'))
conv_base.trainable = False
conv_base.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 150, 150, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 0
Non-trainable params: 14,714,688
_________________________________________________________________
base_dir = './TJU_imageBase'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 1
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=30,
width_shift_range=0.15,
height_shift_range=0.15,
shear_range=0.15,
zoom_range=0.15,
horizontal_flip=True,
fill_mode='nearest')
validation_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=8,
class_mode='categorical')
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=1,
class_mode='categorical')
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5),
metrics=['acc'])
def extract_features(directory, sample_count):
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=(sample_count, 61))
generator = datagen.flow_from_directory(
directory,
target_size=(150, 150),
batch_size=batch_size,
class_mode='categorical')
i = 0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch)
features[i * batch_size : (i + 1) * batch_size] = features_batch
labels[i * batch_size : (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count:
break
return features, labels
test_features, test_labels = extract_features(test_dir, 61)
Found 488 images belonging to 61 classes.
Found 61 images belonging to 61 classes.
Found 61 images belonging to 61 classes.
checkpointer = ModelCheckpoint(filepath='best.hdf5',
verbose=1,
save_best_only=True)
history = model.fit_generator(
train_generator,
steps_per_epoch=61,
epochs=30,
validation_data=validation_generator,
validation_steps=61,
callbacks=[checkpointer])
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
model.load_weights('best.hdf5')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=61,
class_mode='categorical')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=1)
print('30 times test acc:', test_acc)
Epoch 1/30
61/61 [==============================] - 8s 135ms/step - loss: 0.1824 - acc: 0.9529 - val_loss: 0.5005 - val_acc: 0.9180
Epoch 00001: val_loss improved from inf to 0.50054, saving model to best.hdf5
Epoch 2/30
61/61 [==============================] - 7s 115ms/step - loss: 0.1912 - acc: 0.9385 - val_loss: 0.4059 - val_acc: 0.9016
Epoch 00002: val_loss improved from 0.50054 to 0.40590, saving model to best.hdf5
Epoch 3/30
61/61 [==============================] - 7s 116ms/step - loss: 0.1681 - acc: 0.9447 - val_loss: 0.5402 - val_acc: 0.9016
Epoch 00003: val_loss did not improve from 0.40590
Epoch 4/30
61/61 [==============================] - 7s 117ms/step - loss: 0.1563 - acc: 0.9467 - val_loss: 0.5669 - val_acc: 0.9180
Epoch 00004: val_loss did not improve from 0.40590
Epoch 5/30
61/61 [==============================] - 7s 119ms/step - loss: 0.1541 - acc: 0.9426 - val_loss: 0.5053 - val_acc: 0.9344
Epoch 00005: val_loss did not improve from 0.40590
Epoch 6/30
61/61 [==============================] - 7s 118ms/step - loss: 0.1534 - acc: 0.9611 - val_loss: 0.4883 - val_acc: 0.9016
Epoch 00006: val_loss did not improve from 0.40590
Epoch 7/30
61/61 [==============================] - 7s 119ms/step - loss: 0.1412 - acc: 0.9570 - val_loss: 0.5012 - val_acc: 0.8689
Epoch 00007: val_loss did not improve from 0.40590
Epoch 8/30
61/61 [==============================] - 7s 118ms/step - loss: 0.1430 - acc: 0.9549 - val_loss: 0.5725 - val_acc: 0.9016
Epoch 00008: val_loss did not improve from 0.40590
Epoch 9/30
61/61 [==============================] - 7s 119ms/step - loss: 0.1161 - acc: 0.9590 - val_loss: 0.5960 - val_acc: 0.9180
Epoch 00009: val_loss did not improve from 0.40590
Epoch 10/30
61/61 [==============================] - 7s 117ms/step - loss: 0.1026 - acc: 0.9754 - val_loss: 0.4786 - val_acc: 0.9344
Epoch 00010: val_loss did not improve from 0.40590
Epoch 11/30
61/61 [==============================] - 7s 119ms/step - loss: 0.1143 - acc: 0.9672 - val_loss: 0.6715 - val_acc: 0.8852
Epoch 00011: val_loss did not improve from 0.40590
Epoch 12/30
61/61 [==============================] - 7s 117ms/step - loss: 0.1095 - acc: 0.9713 - val_loss: 0.4954 - val_acc: 0.9016
Epoch 00012: val_loss did not improve from 0.40590
Epoch 13/30
61/61 [==============================] - 7s 122ms/step - loss: 0.1045 - acc: 0.9693 - val_loss: 0.6544 - val_acc: 0.9016
Epoch 00013: val_loss did not improve from 0.40590
Epoch 14/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0798 - acc: 0.9816 - val_loss: 0.5803 - val_acc: 0.8852
Epoch 00014: val_loss did not improve from 0.40590
Epoch 15/30
61/61 [==============================] - 7s 123ms/step - loss: 0.0665 - acc: 0.9857 - val_loss: 0.4752 - val_acc: 0.9180
Epoch 00015: val_loss did not improve from 0.40590
Epoch 16/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0977 - acc: 0.9693 - val_loss: 0.5475 - val_acc: 0.9180
Epoch 00016: val_loss did not improve from 0.40590
Epoch 17/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0586 - acc: 0.9877 - val_loss: 0.5386 - val_acc: 0.9180
Epoch 00017: val_loss did not improve from 0.40590
Epoch 18/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0677 - acc: 0.9754 - val_loss: 0.6425 - val_acc: 0.9180
Epoch 00018: val_loss did not improve from 0.40590
Epoch 19/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0635 - acc: 0.9836 - val_loss: 0.5687 - val_acc: 0.9016
Epoch 00019: val_loss did not improve from 0.40590
Epoch 20/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0574 - acc: 0.9877 - val_loss: 0.4772 - val_acc: 0.9344
Epoch 00020: val_loss did not improve from 0.40590
Epoch 21/30
61/61 [==============================] - 7s 117ms/step - loss: 0.0669 - acc: 0.9816 - val_loss: 0.6500 - val_acc: 0.9016
Epoch 00021: val_loss did not improve from 0.40590
Epoch 22/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0753 - acc: 0.9795 - val_loss: 0.6440 - val_acc: 0.9016
Epoch 00022: val_loss did not improve from 0.40590
Epoch 23/30
61/61 [==============================] - 7s 122ms/step - loss: 0.0606 - acc: 0.9795 - val_loss: 0.4719 - val_acc: 0.9180
Epoch 00023: val_loss did not improve from 0.40590
Epoch 24/30
61/61 [==============================] - 7s 123ms/step - loss: 0.0767 - acc: 0.9775 - val_loss: 0.5314 - val_acc: 0.9344
Epoch 00024: val_loss did not improve from 0.40590
Epoch 25/30
61/61 [==============================] - 8s 124ms/step - loss: 0.0407 - acc: 0.9898 - val_loss: 0.5266 - val_acc: 0.8852
Epoch 00025: val_loss did not improve from 0.40590
Epoch 26/30
61/61 [==============================] - 7s 117ms/step - loss: 0.0558 - acc: 0.9816 - val_loss: 0.5848 - val_acc: 0.9016
Epoch 00026: val_loss did not improve from 0.40590
Epoch 27/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0897 - acc: 0.9713 - val_loss: 0.5832 - val_acc: 0.9016
Epoch 00027: val_loss did not improve from 0.40590
Epoch 28/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0705 - acc: 0.9795 - val_loss: 0.7309 - val_acc: 0.8852
Epoch 00028: val_loss did not improve from 0.40590
Epoch 29/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0455 - acc: 0.9877 - val_loss: 0.5319 - val_acc: 0.9180
Epoch 00029: val_loss did not improve from 0.40590
Epoch 30/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0674 - acc: 0.9775 - val_loss: 0.7702 - val_acc: 0.9016
Epoch 00030: val_loss did not improve from 0.40590
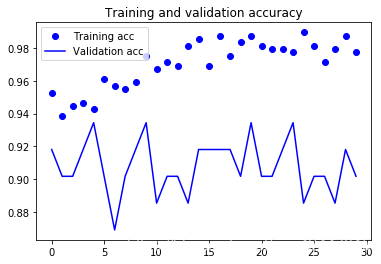
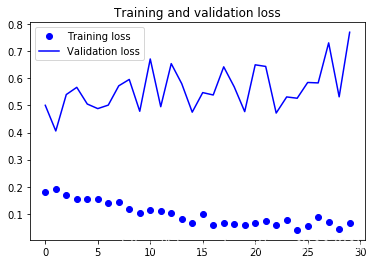
Found 61 images belonging to 61 classes.
30 times test acc: 0.9180327653884888
checkpointer = ModelCheckpoint(filepath='best.hdf5',
verbose=1,
save_best_only=True)
history = model.fit_generator(
train_generator,
steps_per_epoch=61,
epochs=30,
validation_data=validation_generator,
validation_steps=61,
callbacks=[checkpointer])
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
model.load_weights('best.hdf5')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=61,
class_mode='categorical')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=1)
print('60 times test acc:', test_acc)
Epoch 1/30
61/61 [==============================] - 8s 134ms/step - loss: 0.1663 - acc: 0.9590 - val_loss: 0.4535 - val_acc: 0.9180
Epoch 00001: val_loss improved from inf to 0.45351, saving model to best.hdf5
Epoch 2/30
61/61 [==============================] - 7s 117ms/step - loss: 0.1564 - acc: 0.9590 - val_loss: 0.5707 - val_acc: 0.9180
Epoch 00002: val_loss did not improve from 0.45351
Epoch 3/30
61/61 [==============================] - 7s 118ms/step - loss: 0.1357 - acc: 0.9488 - val_loss: 0.4707 - val_acc: 0.9016
Epoch 00003: val_loss did not improve from 0.45351
Epoch 4/30
61/61 [==============================] - 7s 118ms/step - loss: 0.1477 - acc: 0.9611 - val_loss: 0.5170 - val_acc: 0.8852
Epoch 00004: val_loss did not improve from 0.45351
Epoch 5/30
61/61 [==============================] - 7s 118ms/step - loss: 0.1289 - acc: 0.9590 - val_loss: 0.5862 - val_acc: 0.9180
Epoch 00005: val_loss did not improve from 0.45351
Epoch 6/30
61/61 [==============================] - 7s 120ms/step - loss: 0.1248 - acc: 0.9590 - val_loss: 0.6883 - val_acc: 0.8689
Epoch 00006: val_loss did not improve from 0.45351
Epoch 7/30
61/61 [==============================] - 7s 118ms/step - loss: 0.1167 - acc: 0.9631 - val_loss: 0.4394 - val_acc: 0.9016
Epoch 00007: val_loss improved from 0.45351 to 0.43944, saving model to best.hdf5
Epoch 8/30
61/61 [==============================] - 7s 118ms/step - loss: 0.1064 - acc: 0.9734 - val_loss: 0.4696 - val_acc: 0.9016
Epoch 00008: val_loss did not improve from 0.43944
Epoch 9/30
61/61 [==============================] - 7s 123ms/step - loss: 0.1214 - acc: 0.9672 - val_loss: 0.4447 - val_acc: 0.9344
Epoch 00009: val_loss did not improve from 0.43944
Epoch 10/30
61/61 [==============================] - 8s 124ms/step - loss: 0.1357 - acc: 0.9590 - val_loss: 0.5307 - val_acc: 0.9016
Epoch 00010: val_loss did not improve from 0.43944
Epoch 11/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0889 - acc: 0.9693 - val_loss: 0.4481 - val_acc: 0.9344
Epoch 00011: val_loss did not improve from 0.43944
Epoch 12/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0841 - acc: 0.9713 - val_loss: 0.5089 - val_acc: 0.9016
Epoch 00012: val_loss did not improve from 0.43944
Epoch 13/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0955 - acc: 0.9713 - val_loss: 0.6054 - val_acc: 0.8852
Epoch 00013: val_loss did not improve from 0.43944
Epoch 14/30
61/61 [==============================] - 7s 122ms/step - loss: 0.0837 - acc: 0.9775 - val_loss: 0.5089 - val_acc: 0.9016
Epoch 00014: val_loss did not improve from 0.43944
Epoch 15/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0861 - acc: 0.9754 - val_loss: 0.5413 - val_acc: 0.9016
Epoch 00015: val_loss did not improve from 0.43944
Epoch 16/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0729 - acc: 0.9775 - val_loss: 0.4624 - val_acc: 0.9344
Epoch 00016: val_loss did not improve from 0.43944
Epoch 17/30
61/61 [==============================] - 7s 120ms/step - loss: 0.0585 - acc: 0.9857 - val_loss: 0.3694 - val_acc: 0.9180
Epoch 00017: val_loss improved from 0.43944 to 0.36944, saving model to best.hdf5
Epoch 18/30
61/61 [==============================] - 7s 115ms/step - loss: 0.0610 - acc: 0.9795 - val_loss: 0.6159 - val_acc: 0.9016
Epoch 00018: val_loss did not improve from 0.36944
Epoch 19/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0705 - acc: 0.9795 - val_loss: 0.5128 - val_acc: 0.9180
Epoch 00019: val_loss did not improve from 0.36944
Epoch 20/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0593 - acc: 0.9877 - val_loss: 0.4485 - val_acc: 0.9344
Epoch 00020: val_loss did not improve from 0.36944
Epoch 21/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0858 - acc: 0.9754 - val_loss: 0.3866 - val_acc: 0.9180
Epoch 00021: val_loss did not improve from 0.36944
Epoch 22/30
61/61 [==============================] - 7s 117ms/step - loss: 0.0693 - acc: 0.9816 - val_loss: 0.6301 - val_acc: 0.9180
Epoch 00022: val_loss did not improve from 0.36944
Epoch 23/30
61/61 [==============================] - 7s 123ms/step - loss: 0.0557 - acc: 0.9836 - val_loss: 0.4076 - val_acc: 0.9016
Epoch 00023: val_loss did not improve from 0.36944
Epoch 24/30
61/61 [==============================] - 7s 120ms/step - loss: 0.0657 - acc: 0.9754 - val_loss: 0.4299 - val_acc: 0.9344
Epoch 00024: val_loss did not improve from 0.36944
Epoch 25/30
61/61 [==============================] - 7s 117ms/step - loss: 0.0877 - acc: 0.9734 - val_loss: 0.3355 - val_acc: 0.9344
Epoch 00025: val_loss improved from 0.36944 to 0.33554, saving model to best.hdf5
Epoch 26/30
61/61 [==============================] - 7s 116ms/step - loss: 0.0722 - acc: 0.9754 - val_loss: 0.4979 - val_acc: 0.9180
Epoch 00026: val_loss did not improve from 0.33554
Epoch 27/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0387 - acc: 0.9898 - val_loss: 0.5619 - val_acc: 0.9344
Epoch 00027: val_loss did not improve from 0.33554
Epoch 28/30
61/61 [==============================] - 8s 124ms/step - loss: 0.0536 - acc: 0.9775 - val_loss: 0.5744 - val_acc: 0.9016
Epoch 00028: val_loss did not improve from 0.33554
Epoch 29/30
61/61 [==============================] - 7s 123ms/step - loss: 0.0612 - acc: 0.9795 - val_loss: 0.4024 - val_acc: 0.9344
Epoch 00029: val_loss did not improve from 0.33554
Epoch 30/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0600 - acc: 0.9836 - val_loss: 0.4775 - val_acc: 0.9180
Epoch 00030: val_loss did not improve from 0.33554
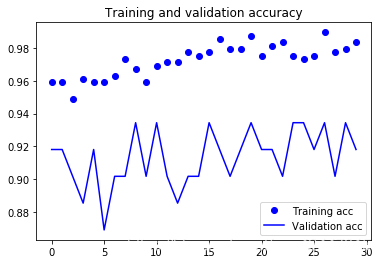
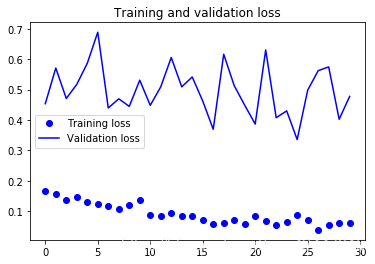
Found 61 images belonging to 61 classes.
60 times test acc: 0.9508196711540222
checkpointer = ModelCheckpoint(filepath='best.hdf5',
verbose=1,
save_best_only=True)
history = model.fit_generator(
train_generator,
steps_per_epoch=61,
epochs=30,
validation_data=validation_generator,
validation_steps=61,
callbacks=[checkpointer])
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
model.load_weights('best.hdf5')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=61,
class_mode='categorical')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=1)
print('90 times test acc:', test_acc)
Epoch 1/30
61/61 [==============================] - 8s 132ms/step - loss: 0.0528 - acc: 0.9836 - val_loss: 0.5180 - val_acc: 0.9180
Epoch 00001: val_loss improved from inf to 0.51798, saving model to best.hdf5
Epoch 2/30
61/61 [==============================] - 7s 117ms/step - loss: 0.0450 - acc: 0.9857 - val_loss: 0.3763 - val_acc: 0.9508
Epoch 00002: val_loss improved from 0.51798 to 0.37634, saving model to best.hdf5
Epoch 3/30
61/61 [==============================] - 7s 115ms/step - loss: 0.0574 - acc: 0.9836 - val_loss: 0.4336 - val_acc: 0.9180
Epoch 00003: val_loss did not improve from 0.37634
Epoch 4/30
61/61 [==============================] - 8s 123ms/step - loss: 0.0343 - acc: 0.9918 - val_loss: 0.4626 - val_acc: 0.9344
Epoch 00004: val_loss did not improve from 0.37634
Epoch 5/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0469 - acc: 0.9877 - val_loss: 0.5350 - val_acc: 0.9344
Epoch 00005: val_loss did not improve from 0.37634
Epoch 6/30
61/61 [==============================] - 7s 117ms/step - loss: 0.0454 - acc: 0.9816 - val_loss: 0.4827 - val_acc: 0.9508
Epoch 00006: val_loss did not improve from 0.37634
Epoch 7/30
61/61 [==============================] - 8s 124ms/step - loss: 0.0405 - acc: 0.9898 - val_loss: 0.4400 - val_acc: 0.9508
Epoch 00007: val_loss did not improve from 0.37634
Epoch 8/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0763 - acc: 0.9816 - val_loss: 0.3468 - val_acc: 0.9672
Epoch 00008: val_loss improved from 0.37634 to 0.34681, saving model to best.hdf5
Epoch 9/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0447 - acc: 0.9836 - val_loss: 0.4134 - val_acc: 0.9344
Epoch 00009: val_loss did not improve from 0.34681
Epoch 10/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0680 - acc: 0.9836 - val_loss: 0.4889 - val_acc: 0.9344
Epoch 00010: val_loss did not improve from 0.34681
Epoch 11/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0490 - acc: 0.9795 - val_loss: 0.6237 - val_acc: 0.8852
Epoch 00011: val_loss did not improve from 0.34681
Epoch 12/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0462 - acc: 0.9816 - val_loss: 0.6216 - val_acc: 0.9016
Epoch 00012: val_loss did not improve from 0.34681
Epoch 13/30
61/61 [==============================] - 8s 124ms/step - loss: 0.0399 - acc: 0.9918 - val_loss: 0.5843 - val_acc: 0.9180
Epoch 00013: val_loss did not improve from 0.34681
Epoch 14/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0424 - acc: 0.9939 - val_loss: 0.3969 - val_acc: 0.9344
Epoch 00014: val_loss did not improve from 0.34681
Epoch 15/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0309 - acc: 0.9918 - val_loss: 0.4599 - val_acc: 0.9344
Epoch 00015: val_loss did not improve from 0.34681
Epoch 16/30
61/61 [==============================] - 7s 116ms/step - loss: 0.0183 - acc: 0.9959 - val_loss: 0.4315 - val_acc: 0.9344
Epoch 00016: val_loss did not improve from 0.34681
Epoch 17/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0366 - acc: 0.9877 - val_loss: 0.3930 - val_acc: 0.9016
Epoch 00017: val_loss did not improve from 0.34681
Epoch 18/30
61/61 [==============================] - 8s 124ms/step - loss: 0.0525 - acc: 0.9836 - val_loss: 0.5873 - val_acc: 0.9180
Epoch 00018: val_loss did not improve from 0.34681
Epoch 19/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0424 - acc: 0.9877 - val_loss: 0.6648 - val_acc: 0.9016
Epoch 00019: val_loss did not improve from 0.34681
Epoch 20/30
61/61 [==============================] - 7s 122ms/step - loss: 0.0401 - acc: 0.9836 - val_loss: 0.6237 - val_acc: 0.9016
Epoch 00020: val_loss did not improve from 0.34681
Epoch 21/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0264 - acc: 0.9918 - val_loss: 0.5935 - val_acc: 0.8852
Epoch 00021: val_loss did not improve from 0.34681
Epoch 22/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0563 - acc: 0.9836 - val_loss: 0.3967 - val_acc: 0.9180
Epoch 00022: val_loss did not improve from 0.34681
Epoch 23/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0223 - acc: 0.9959 - val_loss: 0.5152 - val_acc: 0.9180
Epoch 00023: val_loss did not improve from 0.34681
Epoch 24/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0307 - acc: 0.9918 - val_loss: 0.5418 - val_acc: 0.9344
Epoch 00024: val_loss did not improve from 0.34681
Epoch 25/30
61/61 [==============================] - 7s 120ms/step - loss: 0.0184 - acc: 0.9980 - val_loss: 0.5146 - val_acc: 0.9016
Epoch 00025: val_loss did not improve from 0.34681
Epoch 26/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0277 - acc: 0.9939 - val_loss: 0.4103 - val_acc: 0.9180
Epoch 00026: val_loss did not improve from 0.34681
Epoch 27/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0407 - acc: 0.9877 - val_loss: 0.4783 - val_acc: 0.9016
Epoch 00027: val_loss did not improve from 0.34681
Epoch 28/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0184 - acc: 0.9939 - val_loss: 0.3417 - val_acc: 0.9344
Epoch 00028: val_loss improved from 0.34681 to 0.34166, saving model to best.hdf5
Epoch 29/30
61/61 [==============================] - 7s 116ms/step - loss: 0.0220 - acc: 0.9918 - val_loss: 0.5330 - val_acc: 0.9016
Epoch 00029: val_loss did not improve from 0.34166
Epoch 30/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0220 - acc: 0.9918 - val_loss: 0.6025 - val_acc: 0.9180
Epoch 00030: val_loss did not improve from 0.34166
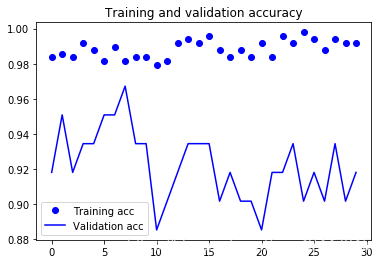
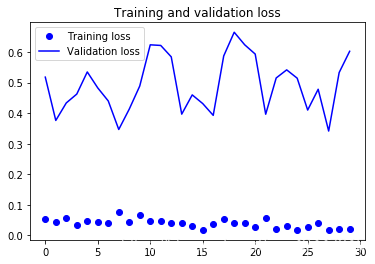
Found 61 images belonging to 61 classes.
90 times test acc: 0.9508196711540222
checkpointer = ModelCheckpoint(filepath='best.hdf5',
verbose=1,
save_best_only=True)
history = model.fit_generator(
train_generator,
steps_per_epoch=61,
epochs=30,
validation_data=validation_generator,
validation_steps=61,
callbacks=[checkpointer])
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
model.load_weights('best.hdf5')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=61,
class_mode='categorical')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=1)
print('120 times test acc:', test_acc)
Epoch 1/30
61/61 [==============================] - 8s 132ms/step - loss: 0.0152 - acc: 0.9959 - val_loss: 0.5697 - val_acc: 0.9180
Epoch 00001: val_loss improved from inf to 0.56966, saving model to best.hdf5
Epoch 2/30
61/61 [==============================] - 7s 115ms/step - loss: 0.0496 - acc: 0.9836 - val_loss: 0.5298 - val_acc: 0.9180
Epoch 00002: val_loss improved from 0.56966 to 0.52978, saving model to best.hdf5
Epoch 3/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0146 - acc: 0.9959 - val_loss: 0.4719 - val_acc: 0.9016
Epoch 00003: val_loss improved from 0.52978 to 0.47195, saving model to best.hdf5
Epoch 4/30
61/61 [==============================] - 7s 117ms/step - loss: 0.0226 - acc: 0.9918 - val_loss: 0.4352 - val_acc: 0.9180
Epoch 00004: val_loss improved from 0.47195 to 0.43516, saving model to best.hdf5
Epoch 5/30
61/61 [==============================] - 8s 124ms/step - loss: 0.0477 - acc: 0.9877 - val_loss: 0.5375 - val_acc: 0.9016
Epoch 00005: val_loss did not improve from 0.43516
Epoch 6/30
61/61 [==============================] - 7s 122ms/step - loss: 0.0332 - acc: 0.9877 - val_loss: 0.3976 - val_acc: 0.9180
Epoch 00006: val_loss improved from 0.43516 to 0.39763, saving model to best.hdf5
Epoch 7/30
61/61 [==============================] - 8s 123ms/step - loss: 0.0200 - acc: 0.9939 - val_loss: 0.4466 - val_acc: 0.9180
Epoch 00007: val_loss did not improve from 0.39763
Epoch 8/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0243 - acc: 0.9898 - val_loss: 0.5078 - val_acc: 0.9180
Epoch 00008: val_loss did not improve from 0.39763
Epoch 9/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0224 - acc: 0.9918 - val_loss: 0.4185 - val_acc: 0.9344
Epoch 00009: val_loss did not improve from 0.39763
Epoch 10/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0277 - acc: 0.9918 - val_loss: 0.4857 - val_acc: 0.9180
Epoch 00010: val_loss did not improve from 0.39763
Epoch 11/30
61/61 [==============================] - 8s 125ms/step - loss: 0.0256 - acc: 0.9918 - val_loss: 0.5552 - val_acc: 0.9180
Epoch 00011: val_loss did not improve from 0.39763
Epoch 12/30
61/61 [==============================] - 7s 117ms/step - loss: 0.0107 - acc: 0.9980 - val_loss: 0.3349 - val_acc: 0.9508
Epoch 00012: val_loss improved from 0.39763 to 0.33486, saving model to best.hdf5
Epoch 13/30
61/61 [==============================] - 7s 117ms/step - loss: 0.0257 - acc: 0.9918 - val_loss: 0.6113 - val_acc: 0.9016
Epoch 00013: val_loss did not improve from 0.33486
Epoch 14/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0192 - acc: 0.9939 - val_loss: 0.5303 - val_acc: 0.9180
Epoch 00014: val_loss did not improve from 0.33486
Epoch 15/30
61/61 [==============================] - 7s 120ms/step - loss: 0.0148 - acc: 0.9959 - val_loss: 0.8353 - val_acc: 0.8852
Epoch 00015: val_loss did not improve from 0.33486
Epoch 16/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0218 - acc: 0.9918 - val_loss: 0.5409 - val_acc: 0.9180
Epoch 00016: val_loss did not improve from 0.33486
Epoch 17/30
61/61 [==============================] - 7s 116ms/step - loss: 0.0123 - acc: 0.9980 - val_loss: 0.6023 - val_acc: 0.9180
Epoch 00017: val_loss did not improve from 0.33486
Epoch 18/30
61/61 [==============================] - 7s 122ms/step - loss: 0.0328 - acc: 0.9898 - val_loss: 0.5864 - val_acc: 0.9016
Epoch 00018: val_loss did not improve from 0.33486
Epoch 19/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0116 - acc: 0.9939 - val_loss: 0.5466 - val_acc: 0.9344
Epoch 00019: val_loss did not improve from 0.33486
Epoch 20/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0214 - acc: 0.9980 - val_loss: 0.6674 - val_acc: 0.9016
Epoch 00020: val_loss did not improve from 0.33486
Epoch 21/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0384 - acc: 0.9898 - val_loss: 0.4167 - val_acc: 0.9508
Epoch 00021: val_loss did not improve from 0.33486
Epoch 22/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0205 - acc: 0.9939 - val_loss: 0.4058 - val_acc: 0.9344
Epoch 00022: val_loss did not improve from 0.33486
Epoch 23/30
61/61 [==============================] - 7s 122ms/step - loss: 0.0160 - acc: 0.9959 - val_loss: 0.3139 - val_acc: 0.9344
Epoch 00023: val_loss improved from 0.33486 to 0.31388, saving model to best.hdf5
Epoch 24/30
61/61 [==============================] - 7s 116ms/step - loss: 0.0150 - acc: 0.9959 - val_loss: 0.3976 - val_acc: 0.9344
Epoch 00024: val_loss did not improve from 0.31388
Epoch 25/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0119 - acc: 0.9959 - val_loss: 0.4192 - val_acc: 0.9672
Epoch 00025: val_loss did not improve from 0.31388
Epoch 26/30
61/61 [==============================] - 7s 119ms/step - loss: 0.0205 - acc: 0.9918 - val_loss: 0.4710 - val_acc: 0.9508
Epoch 00026: val_loss did not improve from 0.31388
Epoch 27/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0138 - acc: 0.9939 - val_loss: 0.4197 - val_acc: 0.9508
Epoch 00027: val_loss did not improve from 0.31388
Epoch 28/30
61/61 [==============================] - 7s 118ms/step - loss: 0.0124 - acc: 0.9939 - val_loss: 0.3839 - val_acc: 0.9016
Epoch 00028: val_loss did not improve from 0.31388
Epoch 29/30
61/61 [==============================] - 8s 125ms/step - loss: 0.0242 - acc: 0.9939 - val_loss: 0.4318 - val_acc: 0.9344
Epoch 00029: val_loss did not improve from 0.31388
Epoch 30/30
61/61 [==============================] - 7s 117ms/step - loss: 0.0192 - acc: 0.9918 - val_loss: 0.4513 - val_acc: 0.9344
Epoch 00030: val_loss did not improve from 0.31388
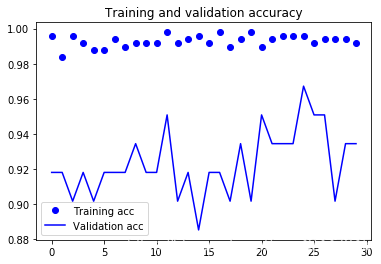
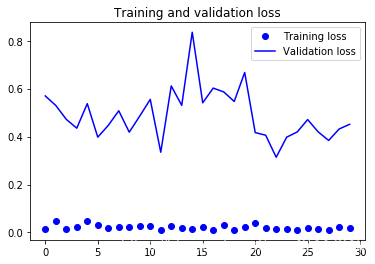
Found 61 images belonging to 61 classes.
120 times test acc: 0.9508196711540222
history = model.fit_generator(
train_generator,
steps_per_epoch=61,
epochs=10,
validation_data=validation_generator,
validation_steps=61,
callbacks=[checkpointer])
Epoch 1/10
61/61 [==============================] - 8s 132ms/step - loss: 0.0405 - acc: 0.9877 - val_loss: 0.4832 - val_acc: 0.9344
Epoch 00001: val_loss did not improve from 0.31388
Epoch 2/10
61/61 [==============================] - 7s 118ms/step - loss: 0.0197 - acc: 0.9959 - val_loss: 0.3784 - val_acc: 0.9344
Epoch 00002: val_loss did not improve from 0.31388
Epoch 3/10
61/61 [==============================] - 7s 117ms/step - loss: 0.0121 - acc: 0.9959 - val_loss: 0.4739 - val_acc: 0.9344
Epoch 00003: val_loss did not improve from 0.31388
Epoch 4/10
61/61 [==============================] - 7s 120ms/step - loss: 0.0160 - acc: 0.9959 - val_loss: 0.4534 - val_acc: 0.9508
Epoch 00004: val_loss did not improve from 0.31388
Epoch 5/10
61/61 [==============================] - 7s 119ms/step - loss: 0.0045 - acc: 1.0000 - val_loss: 0.3872 - val_acc: 0.9508
Epoch 00005: val_loss did not improve from 0.31388
Epoch 6/10
61/61 [==============================] - 7s 120ms/step - loss: 0.0211 - acc: 0.9918 - val_loss: 0.4949 - val_acc: 0.9344
Epoch 00006: val_loss did not improve from 0.31388
Epoch 7/10
61/61 [==============================] - 7s 118ms/step - loss: 0.0155 - acc: 0.9980 - val_loss: 0.6907 - val_acc: 0.9016
Epoch 00007: val_loss did not improve from 0.31388
Epoch 8/10
61/61 [==============================] - 7s 119ms/step - loss: 0.0204 - acc: 0.9918 - val_loss: 0.3372 - val_acc: 0.9672
Epoch 00008: val_loss did not improve from 0.31388
Epoch 9/10
61/61 [==============================] - 7s 117ms/step - loss: 0.0097 - acc: 0.9959 - val_loss: 0.4222 - val_acc: 0.9508
Epoch 00009: val_loss did not improve from 0.31388
Epoch 10/10
61/61 [==============================] - 8s 124ms/step - loss: 0.0126 - acc: 0.9959 - val_loss: 0.4359 - val_acc: 0.9344
Epoch 00010: val_loss did not improve from 0.31388
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
model.load_weights('best.hdf5')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=61,
class_mode='categorical')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=1)
print('test acc:', test_acc)
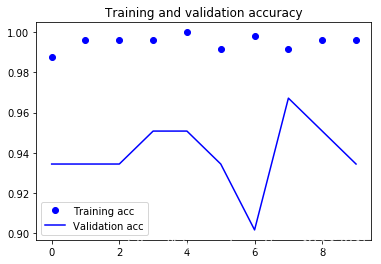

Found 61 images belonging to 61 classes.
test acc: 0.9508196711540222
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5),
metrics=['acc'])
from keras.callbacks import ModelCheckpoint
checkpointer = ModelCheckpoint(filepath='best.hdf5',
verbose=1,
save_best_only=True)
history = model.fit_generator(
train_generator,
steps_per_epoch=61,
epochs=30,
validation_data=validation_generator,
validation_steps=61,
callbacks=[checkpointer],
verbose=2)
Epoch 1/30
- 8s - loss: 0.0342 - acc: 0.9836 - val_loss: 0.5858 - val_acc: 0.9016
Epoch 00001: val_loss improved from inf to 0.58580, saving model to best.hdf5
Epoch 2/30
- 7s - loss: 0.0141 - acc: 0.9939 - val_loss: 0.3765 - val_acc: 0.9672
Epoch 00002: val_loss improved from 0.58580 to 0.37651, saving model to best.hdf5
Epoch 3/30
- 7s - loss: 0.0166 - acc: 0.9939 - val_loss: 0.4529 - val_acc: 0.9508
Epoch 00003: val_loss did not improve from 0.37651
Epoch 4/30
- 7s - loss: 0.0063 - acc: 1.0000 - val_loss: 0.5599 - val_acc: 0.9508
Epoch 00004: val_loss did not improve from 0.37651
Epoch 5/30
- 7s - loss: 0.0150 - acc: 0.9939 - val_loss: 0.3640 - val_acc: 0.9508
Epoch 00005: val_loss improved from 0.37651 to 0.36400, saving model to best.hdf5
Epoch 6/30
- 8s - loss: 0.0168 - acc: 0.9918 - val_loss: 0.5673 - val_acc: 0.9180
Epoch 00006: val_loss did not improve from 0.36400
Epoch 7/30
- 7s - loss: 0.0220 - acc: 0.9918 - val_loss: 0.4959 - val_acc: 0.9180
Epoch 00007: val_loss did not improve from 0.36400
Epoch 8/30
- 7s - loss: 0.0284 - acc: 0.9939 - val_loss: 0.5299 - val_acc: 0.9016
Epoch 00008: val_loss did not improve from 0.36400
Epoch 9/30
- 8s - loss: 0.0050 - acc: 1.0000 - val_loss: 0.5462 - val_acc: 0.9180
Epoch 00009: val_loss did not improve from 0.36400
Epoch 10/30
- 7s - loss: 0.0077 - acc: 0.9980 - val_loss: 0.5159 - val_acc: 0.9016
Epoch 00010: val_loss did not improve from 0.36400
Epoch 11/30
- 7s - loss: 0.0350 - acc: 0.9939 - val_loss: 0.5196 - val_acc: 0.9180
Epoch 00011: val_loss did not improve from 0.36400
Epoch 12/30
- 7s - loss: 0.0103 - acc: 0.9980 - val_loss: 0.4763 - val_acc: 0.9180
Epoch 00012: val_loss did not improve from 0.36400
Epoch 13/30
- 7s - loss: 0.0144 - acc: 0.9939 - val_loss: 0.5372 - val_acc: 0.9180
Epoch 00013: val_loss did not improve from 0.36400
Epoch 14/30
- 7s - loss: 0.0111 - acc: 0.9939 - val_loss: 0.3918 - val_acc: 0.9508
Epoch 00014: val_loss did not improve from 0.36400
Epoch 15/30
- 7s - loss: 0.0078 - acc: 0.9980 - val_loss: 0.6530 - val_acc: 0.8689
Epoch 00015: val_loss did not improve from 0.36400
Epoch 16/30
- 7s - loss: 0.0213 - acc: 0.9939 - val_loss: 0.4880 - val_acc: 0.9344
Epoch 00016: val_loss did not improve from 0.36400
Epoch 17/30
- 7s - loss: 0.0285 - acc: 0.9959 - val_loss: 0.4938 - val_acc: 0.9180
Epoch 00017: val_loss did not improve from 0.36400
Epoch 18/30
- 7s - loss: 0.0246 - acc: 0.9918 - val_loss: 0.4829 - val_acc: 0.9344
Epoch 00018: val_loss did not improve from 0.36400
Epoch 19/30
- 7s - loss: 0.0059 - acc: 0.9980 - val_loss: 0.5722 - val_acc: 0.9180
Epoch 00019: val_loss did not improve from 0.36400
Epoch 20/30
- 7s - loss: 0.0188 - acc: 0.9898 - val_loss: 0.6410 - val_acc: 0.9016
Epoch 00020: val_loss did not improve from 0.36400
Epoch 21/30
- 7s - loss: 0.0199 - acc: 0.9918 - val_loss: 0.5044 - val_acc: 0.9180
Epoch 00021: val_loss did not improve from 0.36400
Epoch 22/30
- 7s - loss: 0.0081 - acc: 0.9980 - val_loss: 0.7586 - val_acc: 0.9016
Epoch 00022: val_loss did not improve from 0.36400
Epoch 23/30
- 7s - loss: 0.0055 - acc: 1.0000 - val_loss: 0.5450 - val_acc: 0.9180
Epoch 00023: val_loss did not improve from 0.36400
Epoch 24/30
- 7s - loss: 0.0221 - acc: 0.9959 - val_loss: 0.4646 - val_acc: 0.9344
Epoch 00024: val_loss did not improve from 0.36400
Epoch 25/30
- 7s - loss: 0.0093 - acc: 0.9980 - val_loss: 0.3566 - val_acc: 0.9508
Epoch 00025: val_loss improved from 0.36400 to 0.35661, saving model to best.hdf5
Epoch 26/30
- 7s - loss: 0.0315 - acc: 0.9898 - val_loss: 0.5442 - val_acc: 0.9180
Epoch 00026: val_loss did not improve from 0.35661
Epoch 27/30
- 7s - loss: 0.0347 - acc: 0.9898 - val_loss: 0.5661 - val_acc: 0.9344
Epoch 00027: val_loss did not improve from 0.35661
Epoch 28/30
- 7s - loss: 0.0234 - acc: 0.9939 - val_loss: 0.5479 - val_acc: 0.9344
Epoch 00028: val_loss did not improve from 0.35661
Epoch 29/30
- 7s - loss: 0.0111 - acc: 0.9980 - val_loss: 0.6053 - val_acc: 0.9180
Epoch 00029: val_loss did not improve from 0.35661
Epoch 30/30
- 8s - loss: 0.0098 - acc: 0.9980 - val_loss: 0.3678 - val_acc: 0.9344
Epoch 00030: val_loss did not improve from 0.35661
model.load_weights('best.hdf5')
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
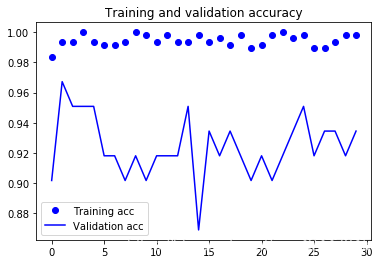
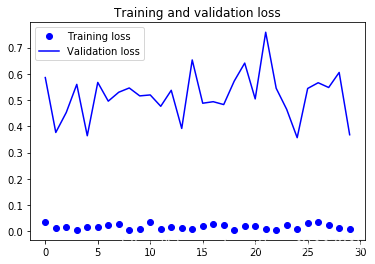
model.load_weights('best.hdf5')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=61,
shuffle = False,
class_mode='categorical')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=1)
print('test acc:', test_acc)
Found 61 images belonging to 61 classes.
test acc: 0.9508196711540222
import matplotlib.pyplot as plt
from PIL import Image
def imgshow(img):
image = Image.fromarray((img * 255).astype('uint8')).convert('RGB')
return image
fig = plt.figure(figsize=(20,12 ))
pred = model.predict_generator(test_generator, verbose=1, steps = 1)
test_datas, test_labels = test_generator.next()
lens = len(test_datas)
labels = []
fd = open('lab2.txt', 'r')
for x in fd.readlines():
labels.append(x[:-1])
print(labels)
print(len(labels))
labels = np.array(labels)
for i in range(61):
image = imgshow(test_datas[i])
ax = fig.add_subplot(7, 10, i + 1, xticks=[], yticks=[])
ax.imshow(image)
ax.set_title("{}({})".format(labels[np.argmax(pred[i])], labels[np.argmax(test_labels[i])]),color=('green' if np.argmax(pred[i]) == np.argmax(test_labels[i]) else 'red'), size=8 ,fontproperties='DengXian')
plt.show()
1/1 [==============================] - 1s 523ms/step
/home/ma-user/anaconda3/envs/TensorFlow-1.8/lib/python3.6/site-packages/matplotlib/font_manager.py:1331: UserWarning: findfont: Font family ['DengXian'] not found. Falling back to DejaVu Sans
(prop.get_family(), self.defaultFamily[fontext]))

















 8083
8083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









