







 本文探讨了使用Selenium的Chrome浏览器与requests库进行网页数据抓取的效率差异,强调了requests的一次性请求在速度上的优势。
本文探讨了使用Selenium的Chrome浏览器与requests库进行网页数据抓取的效率差异,强调了requests的一次性请求在速度上的优势。
from selenium import webdriver
br=webdriver.Chrome() # 浏览器能加载数据 多次请求 执行js 速度慢
br.get('https://www.tmall.com')
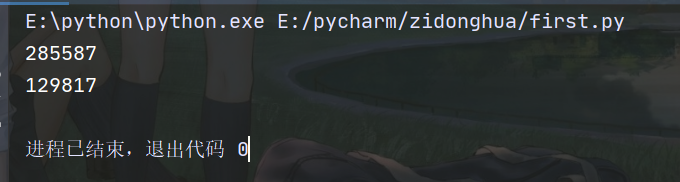
html_str=br.page_source
print(len(html_str))
import requests
url = 'https://www.tmall.com' # 一次请求 数据有限 速度快
resp = requests.get(url)
print(len(resp.text))

















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









