






 本文深入探讨了KNN算法的基本原理,通过实例演示了如何使用Python的scikit-learn库进行数据分类。从简单的二维数据分类到复杂的鸢尾花数据集分析,详细解释了KNN算法在不同场景下的应用。
本文深入探讨了KNN算法的基本原理,通过实例演示了如何使用Python的scikit-learn库进行数据分类。从简单的二维数据分类到复杂的鸢尾花数据集分析,详细解释了KNN算法在不同场景下的应用。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
'''KNN算法,看新数据与已有数据集距离的远近,数据分类;eg:鸢尾花'''
'''
[1,1][1,1.5][0.5,1.5] [3.0,3.0][3.0,3.5][2.8,3.1]
2NN算法
1.计算待遇测值到所有点的距离
2.对所有距离排序
3.找出前K个样本里面类别最多的类,作为我们待预测值的类别'''
#例子1:导入数据
A = np.array([[1,1],[1,1.5],[0.5,1.5]])
B = np.array([[3.0,3.0],[3.0,3.5],[2.8,3.1]])
#用原始方法算出预测值到各个点之间的距离
def knn_dict(point):
lt = []
#字典是不可变变量,需加在循环里
for p_a in A:
r = {}
r['name'] = 'A组'
r['dis'] = np.linalg.norm(point - p_a)
lt.append(r)
for p_b in B:
r = {}
r['name'] = 'B组'
r['dis'] = np.linalg.norm(point - p_b)
lt.append(r)
lt.sort(key = lambda d : d['dis'])
return lt
# point = np.array([2.5,3])
# knn_dict(point)
#用KNeighborsClassifier训练数据操作
def knn_predict_rev(point):
X = np.array([[1, 1], [1, 1.5], [0.5, 1.5],[3.0, 3.0], [3.0, 3.5], [2.8, 3.1]])
Y = np.array([0,0,0,1,1,1])
#相邻分类器
knn = KNeighborsClassifier(n_neighbors=2)
knn.fit(X,Y)
print(knn.predict(np.array([[2.5,3]])))
# knn_predict_rev(None)
#对sklearn自带的鸢尾花的数据做样本,训练,并分类
def knn_predict_iris():
#加载iris数据
lir = load_iris()
#分割测试集合训练集,测试集站整个数据集的比例是0.25
x_train,x_test,y_train,y_test = train_test_split(lir.data,lir.target,test_size=0.25)
# X = lir.data
# Y = lir.target
#前两列数和分类的结果图
# plt.scatter(lir.data[:, 0], lir.data[:, 1], c=lir.target)
#后两列数分类的结果图
# plt.scatter(lir.data[:, 2], lir.data[:, 3], c=lir.target)
#创建knn分类器,使用最少5个邻居作为类别判断标准
knn = KNeighborsClassifier(n_neighbors=5)
#训练数据
knn.fit(x_train, y_train)
#预测[6.3, 3, 5.2, 2.3]所属各个类别的概率
print(knn.predict_proba(np.array([[6.3, 3, 5.2, 2.3]])))
# knn_predict_iris()
范围分布如下
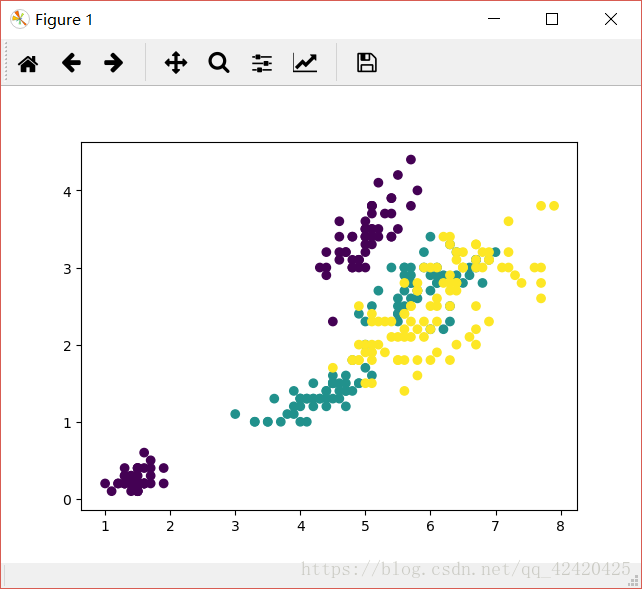
注释:三种类型鸢尾花的数据分布范围
所以,再给一株新的鸢尾花的数据,经过预测之后,看它的预测范围数据哪种鸢尾花的范围,便将它划分到那个类里~

















 3849
3849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









