







云计算
我们日常生活中使用的个人计算机,普遍存在资源使用率低的情况(cpu,内存,硬盘等部分处于空闲状态),因此我们可以将这三部分抽象出来,依据不同情况分给特定的对象使用完成相应的任务,来提高资源利用率,这种技术被称为虚拟化,已经比较成熟。
而如果这些使用的对象是企业或者机构,设想一下,如果我们的计算机资源处在特定的地点,我们是不是也可以按需组合计算机资源,然后分配给有需求的对象呢?
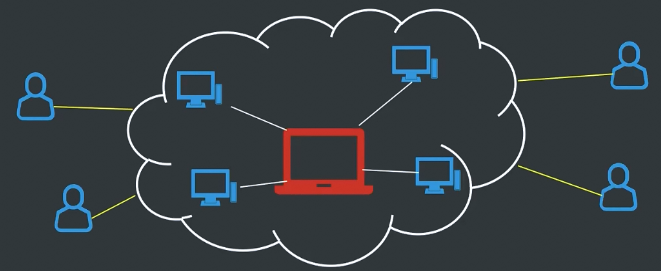
云计算的概念
云计算是一种按使用量付费的模式,这种模式提供可用的、便捷的、按需的网络访问,进入可配置的计算资源共享池(资源包括网络、服务器、存储、应用软件、服务),这些资源能够被快速提供,只需投入很少的管理工作,或与服务供应商进行很少的交互。
大数据
大数据是指无法在可承受的时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策里、洞察发现力和流程优化力的海量、高增长率和多样化的信息资产。
但是实际上,一般提到“大数据”的时候,可能包括多方面的内容,比如数据采集,存储计算,分析应用,人工智能等等。大数据不再单单指数据本身,同时还包括处理数据和存储数据技术,以及对数据的迁移应用。
云计算与大数据的关系
云计算提供存储和计算的基础设置,而大数据则是运行在其上的实际应用。
打个比方,云计算相当于房屋里的设备和设施,而大数据则是在这些设施上开展的一系列活动。
人工智能
人工智能 AI,简单的讲,就是会学习的计算机程序。详细的人工智能分类和介绍可看这篇文章 —> 人工智能知多少
什么是机器学习
机器学习是对于某类任务T和性能度量P,如果一个计算机程序,在T上以P衡量的性能随着经验E而不断自我完善,那么我们称这个计算机程序从经验E中学习。
简单的说就是,在性能P的度量下,通过一定的算法从大量的历史数据或者策略中学习产生最佳模型,来完成预测任务。任何计算机程序通过经验来提高某任务处理性能的行为,都称为机器学习。

类似教小朋友认识猫,事先给他一些猫的图片,让他对猫的外表有一点的认识,下次他再见到新的有可能是猫的动物的时候,就可以从之前学习到的猫的定义,来判定是否是猫这种动物。
我们使用上述对机器学习的定义再举个实际编程的栗子:西洋跳棋

机器学习的思路:
- 任务T:下西洋跳棋
- 性能指标P:赢棋的概率
- 经验E:和自己对弈
- 确定的目标函数:V
我们对棋盘的状态b进行评估:
- x1:棋盘上黑子的个数
- x2:棋盘上红子的个数
- x3:棋盘上黑王的个数
- x4:棋盘上红王的个数
- x5:棋盘上被红子威胁的黑子个数
- x6:棋盘上被黑子威胁的红子个数
但是上面6个特征它们说明棋局好坏的能力也不同,有的代表性强,有的代表性弱,所以我们要给它们赋予一定的权重:
![]()
那么V(b)就是一个目标函数,对于每一种走子b,目标函数都可以计算出一个实数值来说明棋局的好坏。
比如黑子赢了的棋局,我们将它的函数值定位为V(bi)=+100,这种情况下,已经没有红子,那么这个棋局就可以表示为:
![]()
有了上面这些表示,我们就可以运用一些对局的局来训练我们的系统,那么就想通过这些样本来选择一组最合适的权值,让所有棋局与我们最终的预测结果都尽可能一致。
任何一个样本棋局都要表示为这样一个数据对<b,V(b)>,其中的V(b)我们通过给出来些近似函数V_hat(b)来手动的标记。
剩下的事情就是为这个学习算法选择最合适训练样例的权。一种常用的方法是把最佳的假设(或权重向量集合)定义为使训练值和假设预测出的值间的误差平方和E最小:
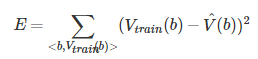
而对于具体的实现方法本文里我们就不做深入论述,后续文章是会有机器学习算法详解和程序实现。
我们来总结一下机器学习解决西洋跳棋问题的所具有的特点:
- 无需传统模式编程
- 定义任务、性能、经验以及目标函数。并提供目标函数学习方式即可
- 随着数据的变化,能自动学习、更新
- 利用自己对弈=>优化模型的方式,可以持续提升
适用场景:
- 不宜针对问题进行手工编程
- 不能定义该问题的解决方案
- 基于复杂数据的快速决策
- 大规模的个性化系统
机器学习和人工智能
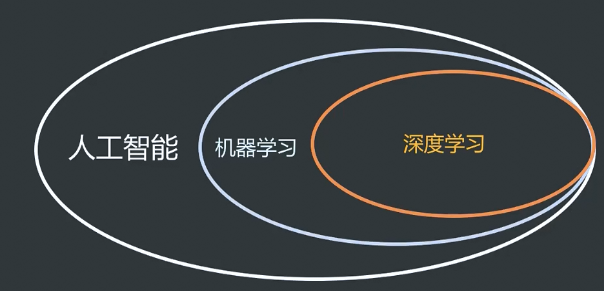
人工智能是一个相对较大的过程,机器学习就是实现人工智能的一种 方法,而深度学习是机器学习的分支,是机器学习的一种技术。三者的关系大致如下图:
机器学习的发展历程
基础奠定时期:40年代末到60年代中

停滞期:60年代中到70年代末
这是机器学习的低潮期,但人们并没有停止研究的步伐,这个时期主要是模拟人类的概念学习过程,并采用逻辑结构或图结构作为机器内部描述,但这期间很少有震惊的成果。
复兴时期:70年代末至80年代末
- 从70年代末开始,人们从学习单个概念扩展到学习多个概念,探索不同的学习策略和各种学习方法
- 1980年,在美国的卡内基梅隆大学(CMU)召开了第一届机器学习国际研讨会
- 多层感知机(MLP)由伟博斯在1981年的神经网络反向传播算法(BP)中具体提出
- 1985-1986神经网络研究人员(鲁梅尔哈特,辛顿,威廉姆斯-赫,尼尔森)先后提出了MLP与BP训练相结合的理念
- 1986年昆兰提出决策树算法,更准确的说是ID3算法
复兴时期:90年代初到21世纪初

蓬勃发展期:21世纪初至今(深度学习)

机器学习的应用

机器学习研究趋势




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











