






激活函数(Activation Function),在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出
1.阶跃函数
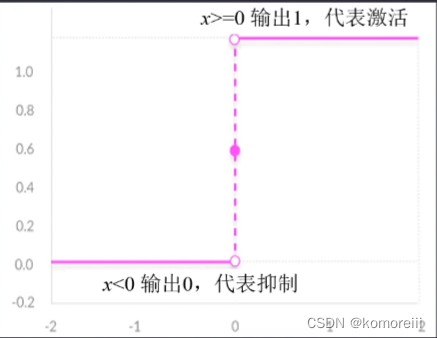
阈值区分:
f
(
x
)
=
{
1
,
i
f
x
≥
T
0
,
i
f
x
<
T
f(x)=\left\{ \begin{aligned} 1,if \quad x \geq T\\ 0,if \quad x<T \\ \end{aligned} \right.
f(x)={1,ifx≥T0,ifx<T
优点:简单易用
缺点:函数不光滑不连续不可导
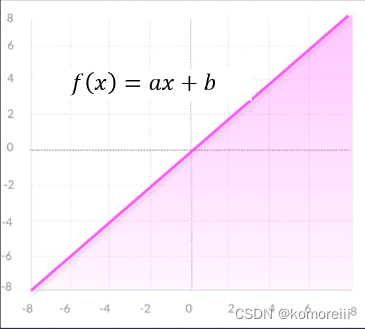
线性函数
f
(
x
)
=
a
x
+
b
f(x)=ax+b
f(x)=ax+b
优点: 多个输出,不仅仅是“是”和“不是”(1/0)
缺点:
(1)无法用梯度下降法训练模型,导数是常数,与输入x无关,不利于模型求解过程中对权重的确定。
(2)神经网络的所有层都将折叠为线性激活关系,最后一层都是第一层的线性函数。
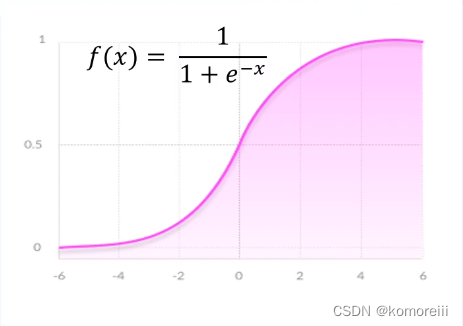
sigmoid函数
f
(
x
)
=
1
1
+
e
−
x
f(x)=\frac{1}{1+e^{-x}}
f(x)=1+e−x1
优点:
(1)平滑的渐变,防止输出值“跳跃”;
(2)输出值介于0.1之间,对于每一个神经元的输出进行标准化;
(3)清晰的预测:对于大于2或小于-2的x,趋向于将y带到曲线边缘,无限接近于1或0.
缺点:
(1)消失梯度:双边区域数值饱和(x很大或很小)导致随着x变化带来的y变化很小,导数趋于0,容易造成模型求解梯度消失问题。可能导致网络求解过程中进一步学习,或者太慢而无法获得准确预测。
(2)输出y中心不是0.
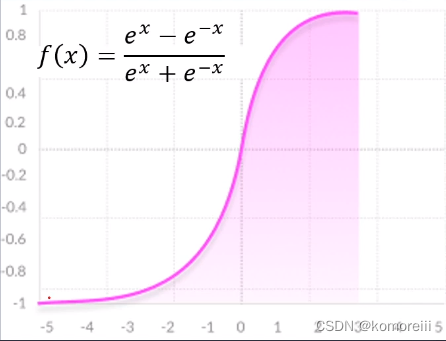
Tanh函数
f
(
x
)
=
e
x
−
e
−
x
e
x
+
e
−
x
=
2
s
i
g
m
o
i
d
(
2
x
)
−
1
f(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}=2sigmoid(2x)-1
f(x)=ex+e−xex−e−x=2sigmoid(2x)−1
优点:
(1)正负方向原点对称,输出均值是0,收敛速度比sigmoid更快,减少迭代次数
(2)具有sigmoid函数的优点
缺点:
(1)与sigmoid函数一样,存在梯度消失问题
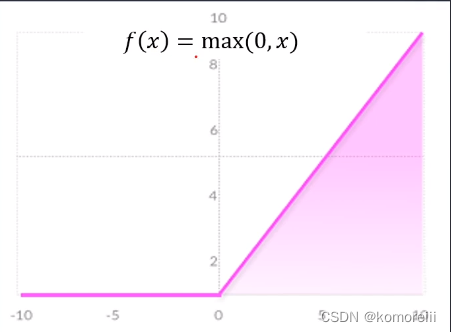
Relu函数
 f
(
x
)
=
m
a
x
(
0
,
x
)
f(x)=max(0,x)
f(x)=max(0,x)
f
(
x
)
=
m
a
x
(
0
,
x
)
f(x)=max(0,x)
f(x)=max(0,x)
优点:
(1)计算效率高,允许网络快速收敛
(2)非线性,具有导数函数并允许反向传播
缺点:
(1)神经元死亡问题:当输入接近0或为负时,函数梯度变为0,网络无法执行反向传播,也无法学习。
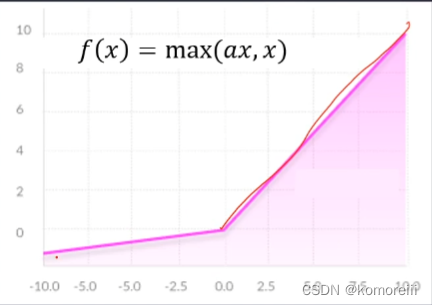
Leaky Relu函数
f
(
x
)
=
m
a
x
(
a
x
,
x
)
f(x)=max(ax,x)
f(x)=max(ax,x)
优点:
(1)解决了Relu的神经元死亡问题,在负区域具有小的正斜率,即使对于负输入值,也可进行反向传播
(2)具有Relu函数的优点.
缺点:
(1)结果不一致,无法为正负输入值提供一致的关系预测(不同区间函数不同)
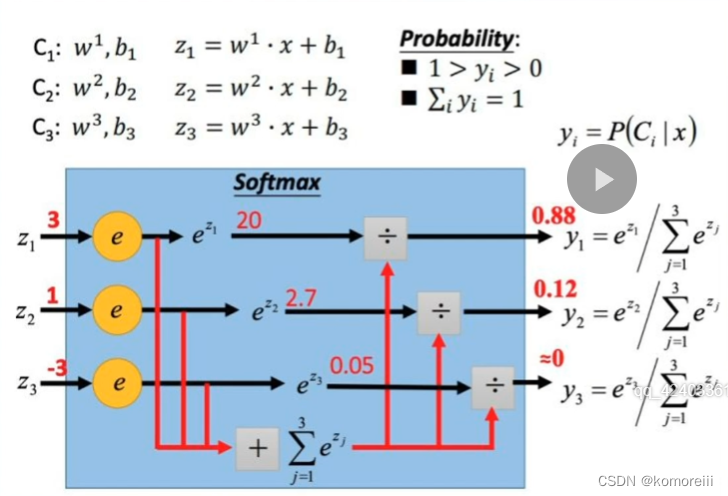
Softmax函数
f
(
x
i
)
=
s
o
f
m
a
x
(
x
i
)
=
e
x
i
∑
j
=
1
k
e
x
j
f(x_i)=sofmax(x_i)=\frac{e^{x_i}}{\sum_{j=1}^ke^{x_j}}
f(xi)=sofmax(xi)=∑j=1kexjexi
k代表输出类别总数
Softmax函数作用:把一堆实数的值映射到0-1区间,使他们的和为1,为每个类别分别对应的预测概率。
总结:
sigmoid、tanh:二分类任务输出层;模型隐藏层
relu、leaky relu:回归任务;卷积神经网络隐藏层
softmax:多分类任务输出层


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









