






各种ES相关知识学习博客:
Elasticsearch学习笔记
一文全览各种ES查询在Java中的实现
java-QueryBuilders进行查询:
分词器简介:
关于term、match、text、keyword实例简介:
狂神说相关笔记
ES-Java
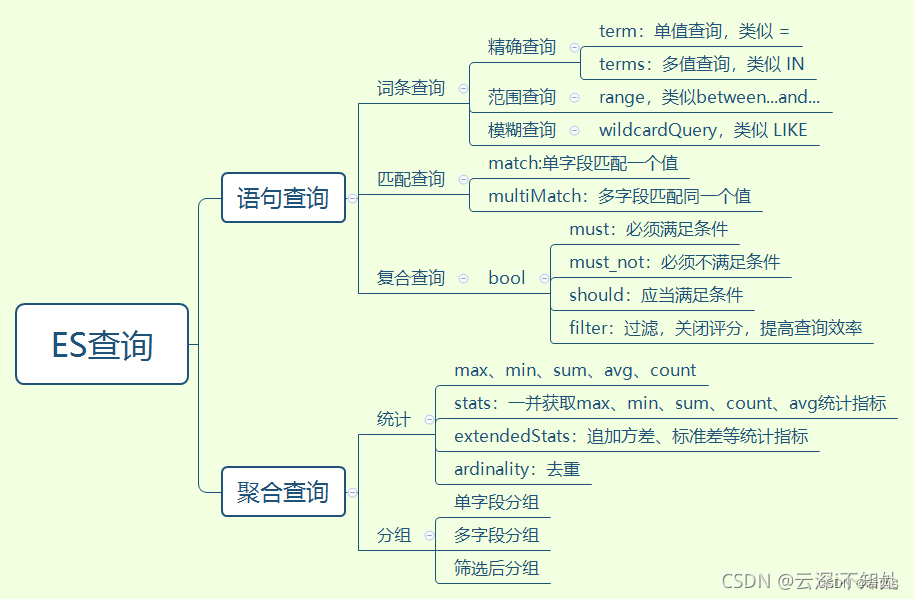
ES相关基础知识
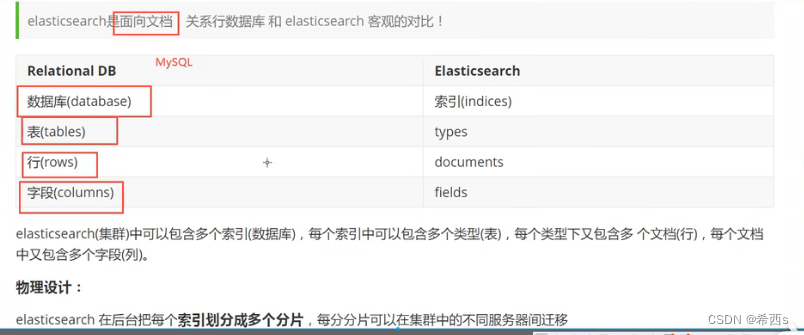
查询出来的结构体(注意查询结果的两层hits)

重点1:
关于term精准查询和match匹配查询的区别
1、term精准查询,直接查询精准的,需要完全匹配才可以(查询条件不进行分词)

2、match匹配查询,会先使用分词器解析!(先对查询条件进行分词,分词后进行match匹配,只要有一个匹配到可以目标值即可)

故,match会额外进行分词一次,所以会慢一些
3、Match - Multi_match

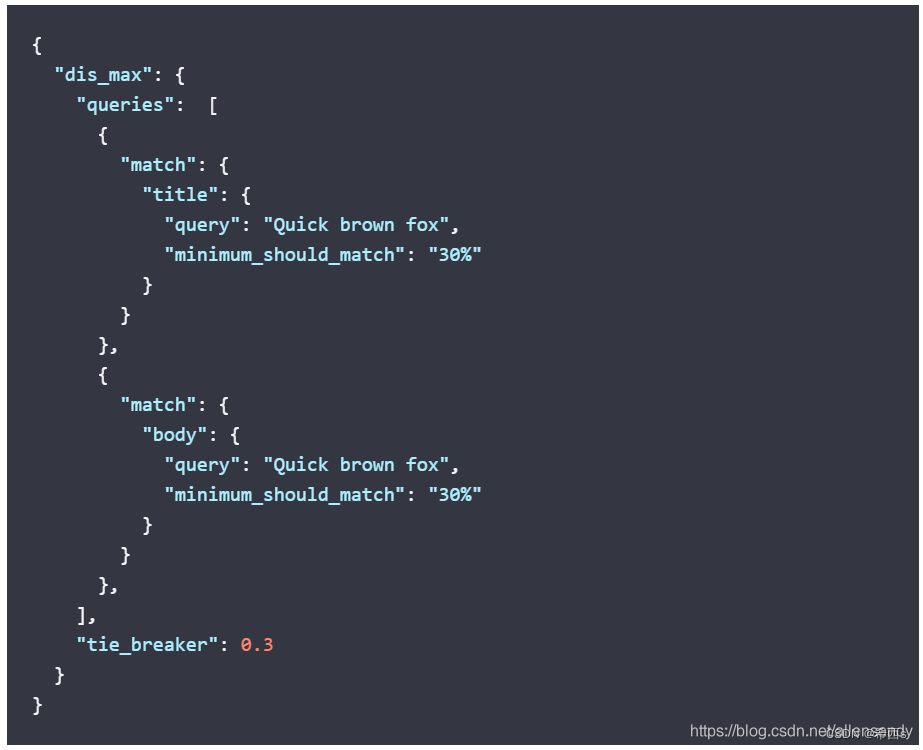

注意:
对于任何存储在ES中的数据,文本类型主要分为keyword和text两种
1、keyword不支持分词,默认就是一个整体
2、text类型的数据,默认自动会进行分词
3、重点注意上述的两个概念,一个是查询条件分词、一个ES中存储的数据分词。
三、分词器
一个 tokenizer(分词器)接收一个字符流,将之分割为独立的 tokens(词元,通常是独立的单词),然后输出 tokens 流。例如,whitespace tokenizer 遇到空白字符时分割文本。它会将文本 “Quick brown fox!” 分割为 [Quick, brown, fox!]。该 tokenizer(分词器)还负责记录各个 term(词条)的顺序或 position 位置(用于 phrase 短语和 word proximity 词近邻查询),以及 term(词条)所代表的原始 word(单词)的 start(起始)和 end(结束)的 character offsets(字符偏移量)(用于高亮显示搜索的内容)。Elasticsearch 提供了很多内置的分词器,可以用来构建 custom analyzers(自定义分词器)。
3.1.标准分词器Standard Tokenizer
standard分词器提供基于语法的分词(基于 Unicode 文本分割算法,如 Unicode 标准附件 #29 中所述)并且适用于大多数语言
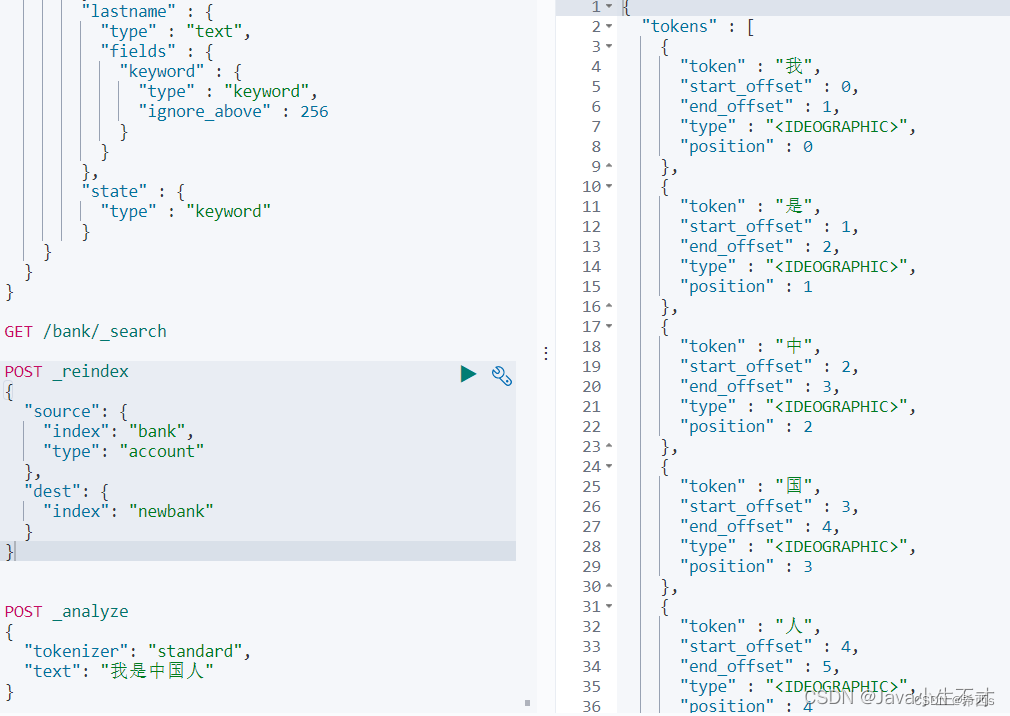
POST _analyze
{
"tokenizer": "standard",
"text": "我是中国人"
}
3.ik分词器
es中默认的分词器,都是支持英文的,中文需要安装自己的分词器
1.ik_smart:智能分词
POST _analyze
{
"tokenizer": "ik_smart",
"text": "我是中国人"
}
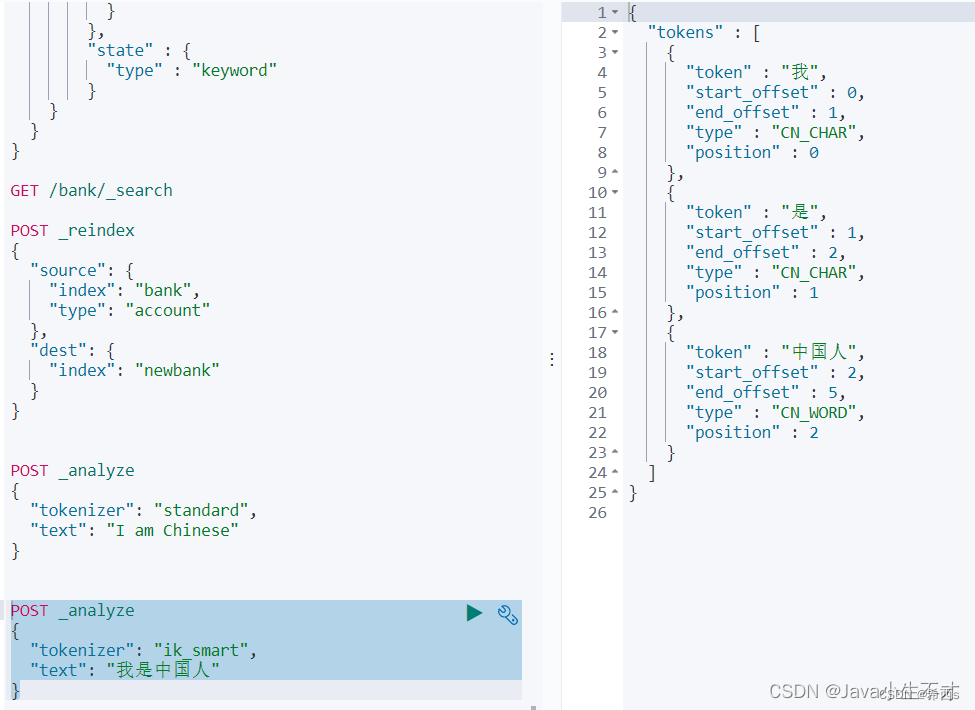
2.ik_max_word:最大单词组合
POST _analyze
{
"tokenizer": "ik_max_word",
"text": "我是中国人"
}
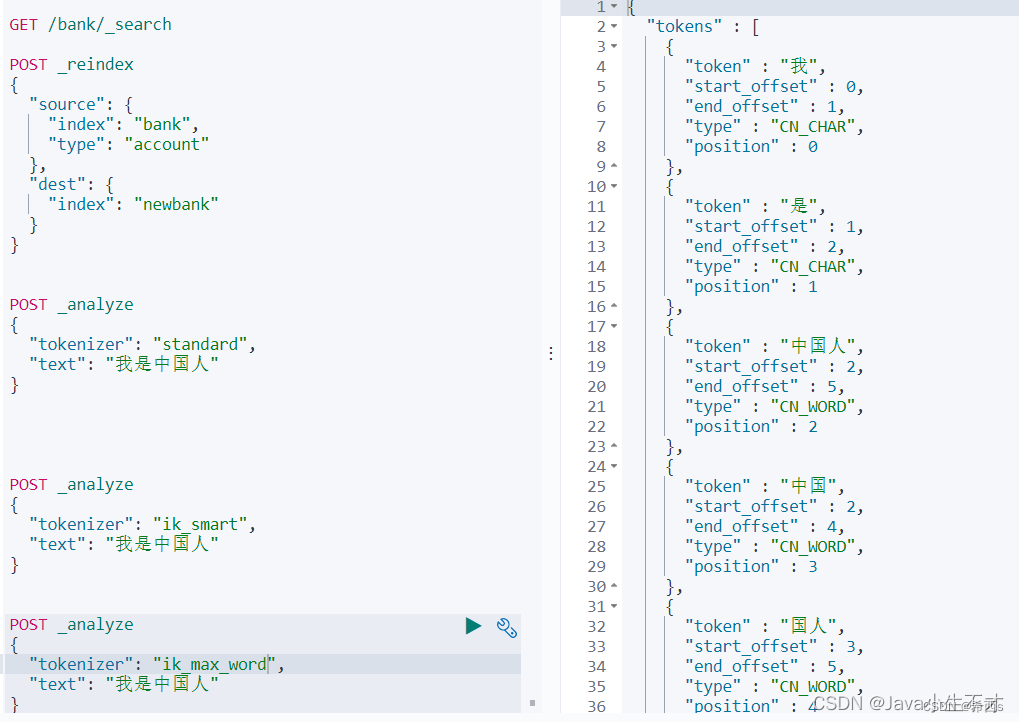

















 2111
2111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









