







前言
在进行日志分析的时候,有时我们需要通过关键词定位问题,经常需要截取关键词之间的日志。如果日志文件很大,人工截取会比较麻烦。可以使用python进行截取。
代码实现
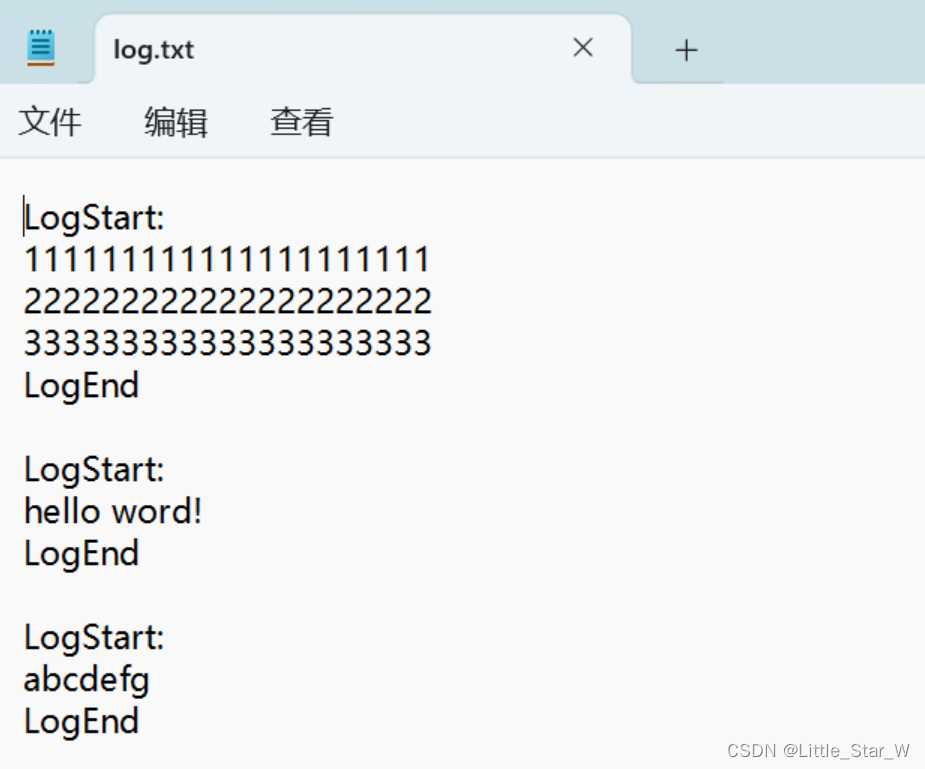
截取的日志格式如下
import re
import linecache
def fileParse():
inputfile = input('Input SourcFile:') ##输入源文件,如A.txt
number_start =[]
number_end =[]
lineNumber = 1
keyword_start = input('Slice Keyword Start: ') ##输入你要切分的关键字
keyword_end = input('Slice Keyword End: ') ##输入你要切分的关键字
outfilename = input('Outfilename:')##输出文件名,如out.txt则写out即可,后续输出的文件是out0.txt,out1.txt...
with open(inputfile, 'r', encoding='UTF-8') as fp:
for eachLine in fp:
m = re.search(keyword_start, eachLine) ##查询关键字
if m is not None:
number_start.append(lineNumber) #将关键字的行号记录在number_start中
m = re.search(keyword_end, eachLine) ##查询关键字
if m is not None:
number_end.append(lineNumber) #将关键字的行号记录在number_end中
lineNumber = lineNumber + 1
size = min(int(len(number_start)), int(len(number_end)))
for i in range(0,size):
start = number_start[i]
end = number_end[i]
destLines = linecache.getlines(inputfile)[start-1:end] #将行号为start到end的文件内容截取出来
fp_w = open(outfilename + str(i)+'.txt','w') #将截取出的内容保存在输出文件中
for key in destLines:
fp_w.write(key)
fp_w.close()
if __name__ == "__main__":
fileParse()
使用
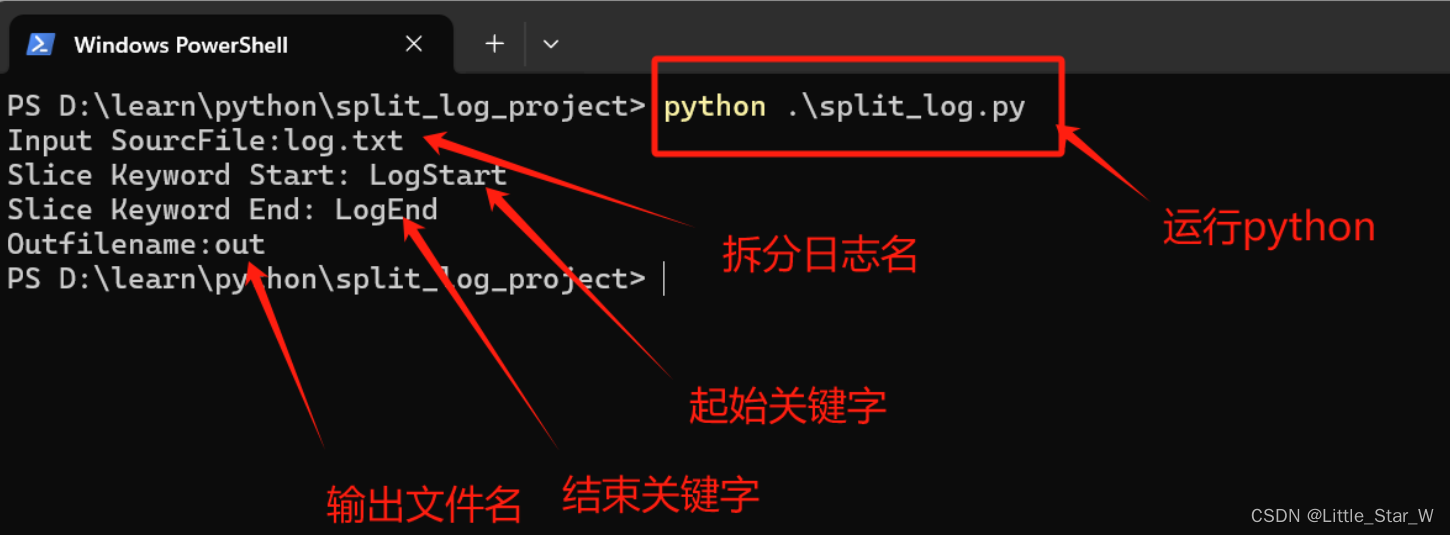
在包含python文件的目录下打开powershell或cmd

参考文献
https://blog.youkuaiyun.com/xqn2017/article/details/73927960

















 5664
5664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









