




 本文详细探讨了Java中的hashCode与equals方法的关系及其在集合类中的重要性,强调了重写equals时必须重写hashCode的规则。此外,还对比了ConcurrentHashMap和Hashtable在实现线程安全方式上的差异。同时,介绍了Java线程的生命周期和状态转换,并详细阐述了SpringBoot加载配置文件的优先级及指定配置的方法。
本文详细探讨了Java中的hashCode与equals方法的关系及其在集合类中的重要性,强调了重写equals时必须重写hashCode的规则。此外,还对比了ConcurrentHashMap和Hashtable在实现线程安全方式上的差异。同时,介绍了Java线程的生命周期和状态转换,并详细阐述了SpringBoot加载配置文件的优先级及指定配置的方法。
文章目录
Java知识难点总结
一、基础篇2
1、hashCode 与 equals
equals和hashCode都是Object对象中的非final方法,它们设计的目的就是被用来覆盖(override)的。
1.1、equals和==有什么区别?
equals()的作用是用来判断两个对象是否相等,在Object里面的定义是:
public boolean equals(Object obj) {
return (this == obj);
}
所有的类都隐式继承于Object类,这说明在我们实现自己的equals方法之前,equals等价于==,而==运算符是判断两个对象是不是同一个对象,即他们的地址是否相等。所以重写equals更多的是追求两个对象在逻辑上的相等,你可以也可说是内容相等(后面会举例)。
在以下几种条件中,不覆写equals就能达到目的:
-
类的每个实例本质上是唯一的:强调活动实体的而不关心值得,比如Thread,我们在乎的是哪一个线程,这时候用equals就可以比较了。
-
不关心类是否提供了逻辑相等的测试功能:有的类的使用者不会用到它的比较值得功能,比如Random类,基本没人会去比较两个随机值吧。
-
超类已经覆盖了equals,子类也只需要用到超类的行为:比如AbstractMap里已经覆写了equals,那么继承的子类行为上也就需要这个功能,那也不需要再实现了。
-
类是私有的或者包级私有的,那也用不到equals方法:这时候需要覆写equals方法来禁用它:
@Override public boolean equals(Object obj) { throw new AssertionError(); }
1.2、重写equals不重写hashCode会存在什么问题?
以下这段话来自 Effective Java 第三版
每个覆盖了equals方法的类中,必须覆盖hashCode。如果不这么做,就违背了hashCode的通用约定,也就是上面注释中所说的。进而导致该类无法结合所以与散列的集合一起正常运作,这里指的是HashMap、HashSet、HashTable、ConcurrentHashMap。
结论:如果重写equals不重写hashCode它与散列集合就无法正常工作。
就拿我们最熟悉的HashMap来进行演示吧。我们知道HashMap中的key是不能重复的,如果重复添加,后添加的会覆盖前面的内容。那么我们看看HashMap是如何来确定key的唯一性的。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
通过代码可以发现,它是通过计算Map key的hashCode值来确定在链表中的存储位置的。那么这样就可以推测出,如果我们重写了equals但是没重写hashCode,那么可能存在元素重复的矛盾情况。
下面我们举个例子演示一下:
public class Student {
private String name;
private Integer age;
public Student(String name, Integer age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return Objects.equals(name, student.name) &&
Objects.equals(age, student.age);
}
// @Override
// public int hashCode() {
// return Objects.hash(name, age);
// }
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public static void main(String[] args) {
Student student1 = new Student("小明", 18);
Student student2 = new Student("小明", 18);
HashMap<Student, Integer> map = new HashMap<>();
map.put(student1, 1);
map.put(student2, 2);
System.out.println(map);
}
}
按照正常逻辑,map中应该只存在student2一个元素。
执行结果:
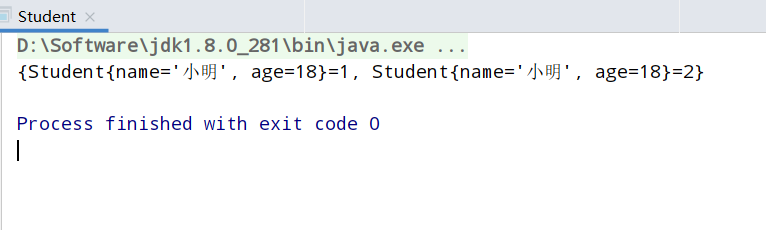
出现这种问题的原因就是因为没有重写hashCode,导致map在计算key的hash值的时候,使用的是Object的hashCode方法,而Object的hashCode方法是根据对象的地址计算的,所以逻辑相同的对象也会有不同的hash值。
接下来我们打开hashCode的注释代码,再看看执行结果:

总结
如果重写了equals就必须重写hashCode,如果不重写就会引起与散列集合(HashMap、HashSet、HashTable、ConcurrentHashMap)的冲突。
2、ConcurrentHashMap和 Hashtable 的区别
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
- 底层数据结构: JDK1.7 的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8采用的数据结构跟 HashMap1.8 的结构⼀样,数组+链表/红黑⼆叉树。 Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用数组+链表的形式,数组是HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
实现线程安全的方式(重要):
-
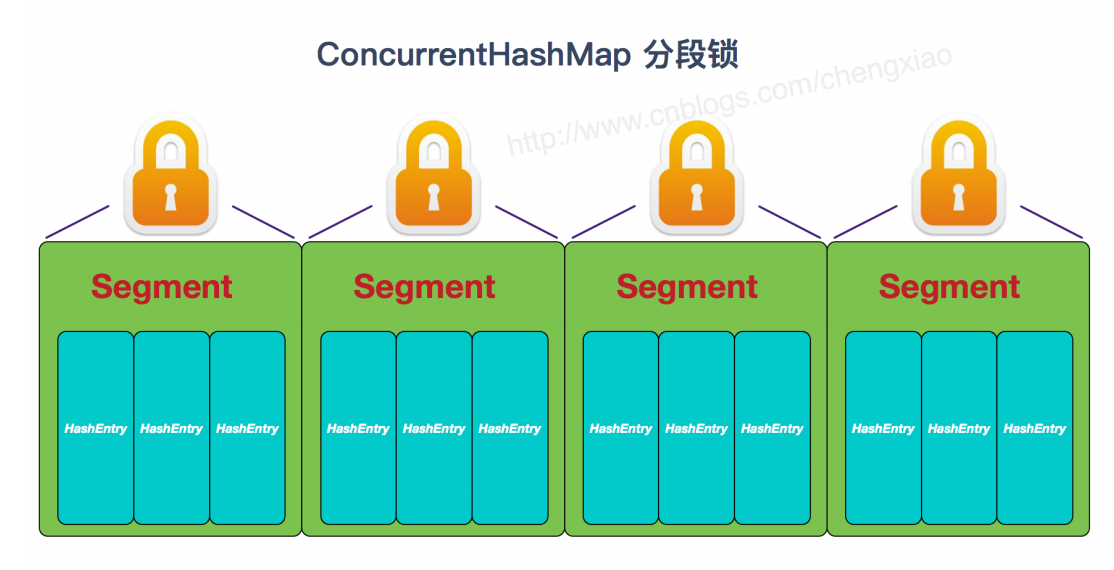
在 JDK1.7 的时候, ConcurrentHashMap (分段锁)对整个桶数组进行了分割分段( Segment ),每⼀把锁只锁容器其中⼀部分数据,多线程访问容器⾥不同数据段的数据,就不会存在锁竞争,提高了并发访问率。 到了 JDK1.8 的时候已经摒弃了 Segment 的概念,而是直接用Node 数组(粒度更小)+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。
JDK1.6 以后 对 synchronized 锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap ,虽然在 JDK1.8 中还能看到Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本。
-
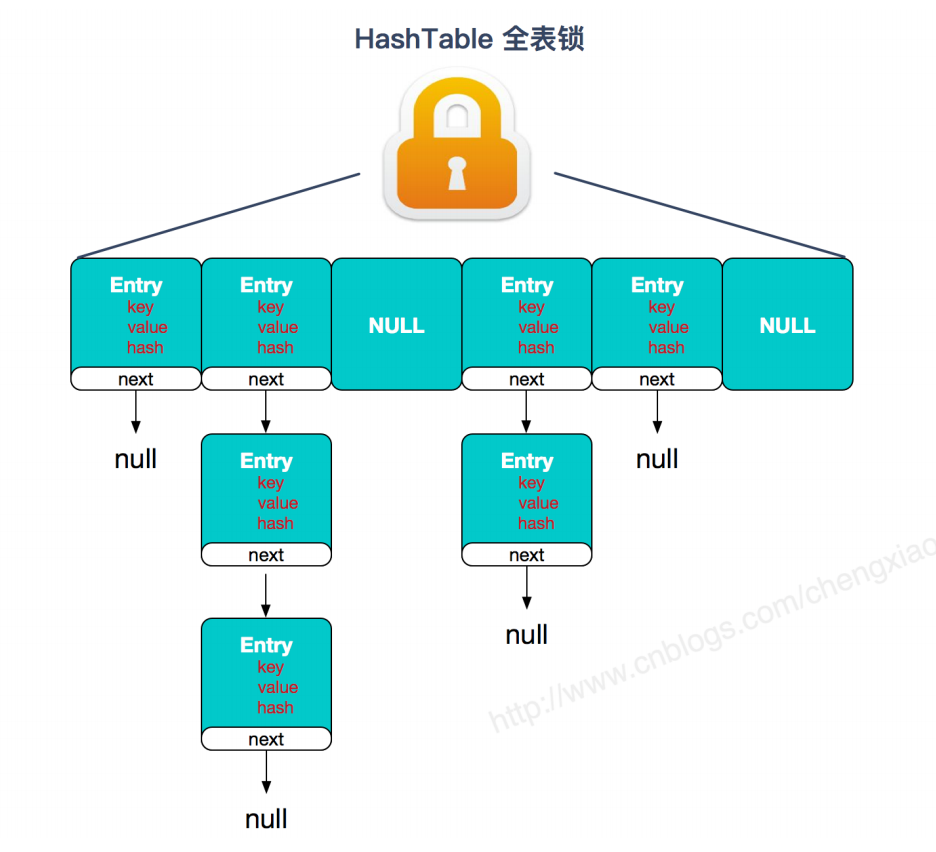
Hashtable (同⼀把锁) :使用 synchronized 来保证线程安全,效率非常低下。当⼀个线程访问同步方法时,其他线程也访问同步方法,可能会进⼊阻塞或轮询状态,如使用 put 添加元素,另⼀个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
两者的对比图
HashTable:
JDK1.7 的 ConcurrentHashMap:
JDK1.8 的 ConcurrentHashMap:
JDK1.8 的 ConcurrentHashMap 不再是 Segment 数组 + HashEntry 数组 + 链表,而是 Node 数 组 + 链表 / 红黑树。不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode 。当冲突链表达到⼀定长度时,链表会转换成红黑树。
3、线程的生命周期和状态
Java 线程在运行的生命周期中的指定时刻只可能处于下⾯ 6 种不同状态的其中⼀个状态。(图源于《Java 并发编程艺术》4.1.4 节)

线程在生命周期中并不是固定处于某⼀个状态而是随着代码的执行在不同状态之间进行切换。Java 线程状态变迁如下图所示:
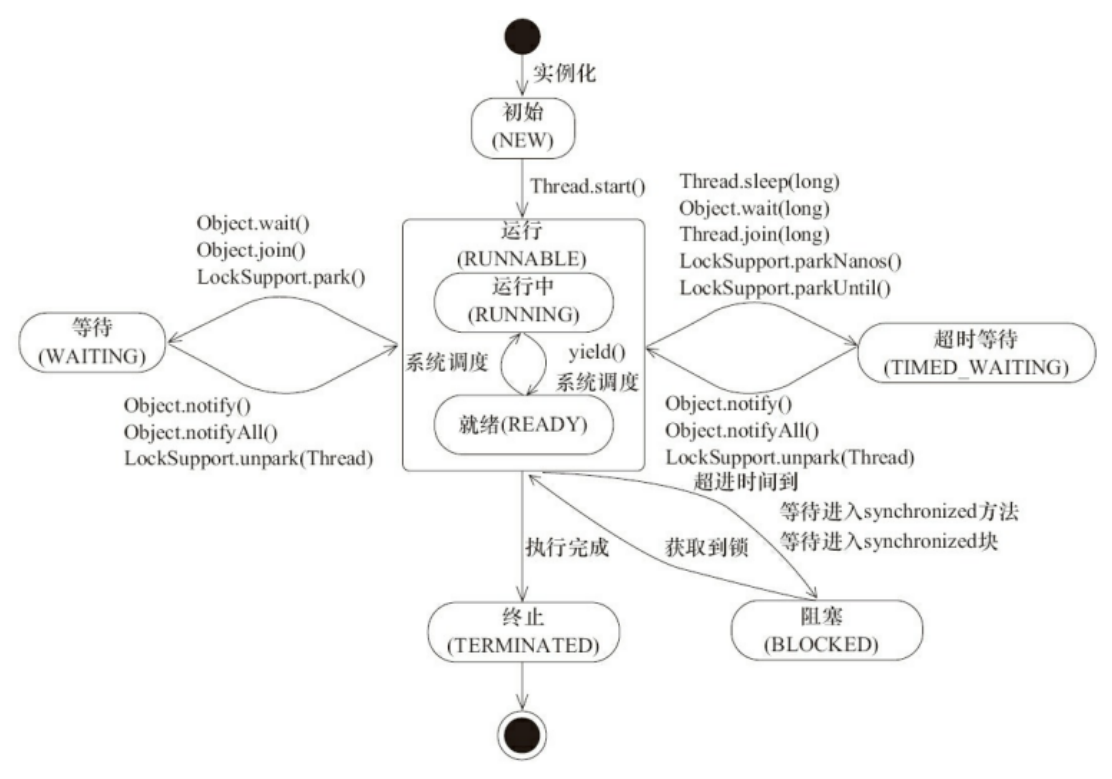
由上图可以看出:线程创建之后它将处于 NEW(新建) 状态,调用 start() 方法后开始运行,线程这时候处于 READY(可运行) 状态。可运行状态的线程获得了 CPU 时间片(timeslice)后就处于 RUNNING(运行) 状态。
- 当线程执行 wait() 方法之后,线程进⼊ WAITING(等待) 状态。进⼊等待状态的线程需要依靠其他线程的通知才能够返回到运行状态,⽽ TIMED_WAITING(超时等待) 状态相当于在等待状态的基础上增加了超时限制,⽐如通过 sleep(long millis) 方法或 wait(long millis) 方法可以将 Java 线程置于 TIMED_WAITING 状态(记忆深刻,有次线上事故就是由这个造成的)。
- 当超时时间到达后 Java 线程将会返回到 RUNNABLE 状态。当线程调⽤同步⽅法时,在没有获取到锁的情况下,线程将会进⼊到 BLOCKED(阻塞)状态。线程在执⾏ Runnable 的 run() ⽅法之后将会进⼊到 TERMINATED(终⽌) 状态。
4、Spring Boot加载配置文件的优先级
4.1、指定配置文件的名称和路径
如果你的应用程序配置文件的名称不是application,想要进行自定义,可以
- 通过
--spring.config.name命令行参数进行指定,如下所示:
java -jar project-sample.jar --spring.config.name=custome
注意:我们只需要指定配置文件的名称即可,可以使用
properties或yaml文件格式,上面的配置会加载src/main/resources/custome.yml或src/main/resources/custome.properties。
- 通过
--spring.config.location参数就可以指定配置文件的位置,如下所示:
java -jar project-sample.jar --spring.config.location=classpath:/configs/custome.yml
- 如果你通过
spring.config.location指定的不是一个文件而是一个目录,在路径最后务必添加一个"/"结束,然后结合spring.config.name进行组合配置文件,组合示例如下:
# 加载/configs/application.properties 或 /configs/application.yml(默认文件名)
java -jar project-sample.jar --spring.config.location=classpath:/configs/
# 加载/configs/custome.properties 或 /configs/custome.yml
java -jar project-sample.jar --spring.config.location=classpath:/configs/ --spring.config.name=custome
注意:
spring.config.name该配置参数默认值为application,所以如果只是指定了spring.config.location为目录形式,上面示例中会自动将spring.config.name追加到目录路径后,如果指定的spring.config.location并非是一个目录,这里会忽略spring.config.name的值。
4.2、配置文件的加载顺序
SpringBoot应用程序在启动时会遵循下面的顺序进行加载配置文件:
- 类路径下的配置文件
- 类路径内config子目录的配置文件
- 当前项目根目录下的配置文件
- 当前项目根目录下config子目录的配置文件
SpringBoot配置文件存在一个特性,优先级较高的配置加载顺序比较靠后,相同名称的配置优先级较高的会覆盖掉优先级较低的内容。
示例项目配置文件存放结构如下所示:
. project-sample
├── config
│ ├── application.yml (4)
│ └── src/main/resources
| │ ├── application.yml (1)
| │ └── config
| | │ ├── application.yml (2)
├── application.yml (3)
启动时加载配置文件顺序:1 > 2 > 3 > 4
src/main/resources下的配置文件在项目编译时,会放在target/classes下。
测试:
根据对应的加载顺序分别创建一个application.properties配置文件,来验证根据优先级的不同是否存在覆盖问题,如下图所示:
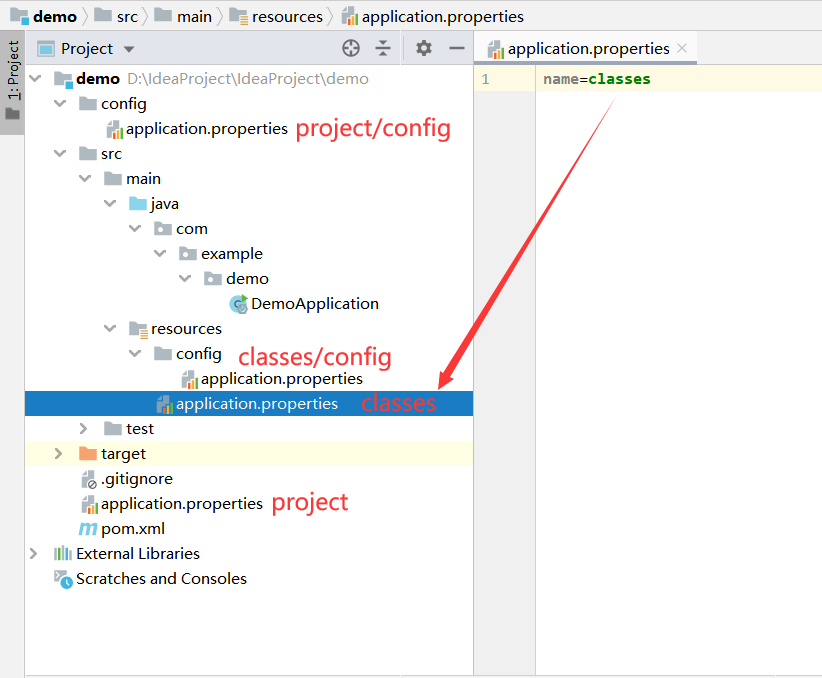
在上面四个配置文件中都有一个名为name的配置,而红色字体标注的内容就是每个配置文件name的配置内容,下面我们来启动项目测试下输出内容。
在测试之前我们让启动类实现CommandLineRunner接口,如下所示:
@SpringBootApplication
public class DemoApplication implements CommandLineRunner {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
@Value("${name}")
private String name;
@Override
public void run(String... args) throws Exception {
System.out.println("配置文件的名称:" + name);
}
}
项目启动后通过run方法进行打印${name}配置的内容。
测试结果:
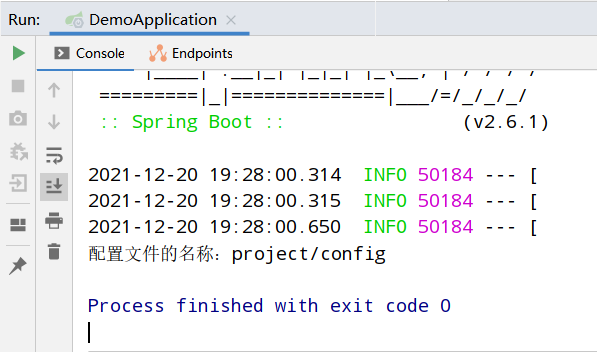
总结:classes/application.yml优先级最低,project/config/application.yml优先级最高,优先级高的可以覆盖优先级低的配置内容。


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









