







流程
当在地址栏输入地址时:
-
浏览器进程的UI线程会捕捉输入内容。
如果访问的是网址,则UI线程会启动一个网络线程模块,请求DNS进行域名解析。之后开始连接服务器获取数据。 -
当网络线程获取到数据后,会通过SafeBrowsing来检查站点是否是安全站点。
- 如果是,则会提示警告页面,告诉用户这个站点存在安全问题,浏览器会组织访问,用户可以强行继续访问。
SafeBrowsing 是谷歌内部的一套站点安全系统,通过检测该站点的数据来判断是否安全。
(比如通过查看该站点的IP是否在谷歌的黑名单中)
如果输入的不是网址关键词,浏览器就知道用户想要搜索,于是会使用默认配置的搜索引擎来查询。
-
当返回数据准备完毕并且安全校验通过时,网络线程会通知
UI线程“我就要准备好了,该你了”。然后UI线程创建一个渲染器进程来渲染页面。 -
浏览器进程通过IPC管道将数据传递给渲染器进行,正式进入渲染流程。
(渲染器接收到的数据也就是
HTML,渲染器的核心功能就是把HTML、css、js、image等资源渲染成用户可以交互的web页面) -
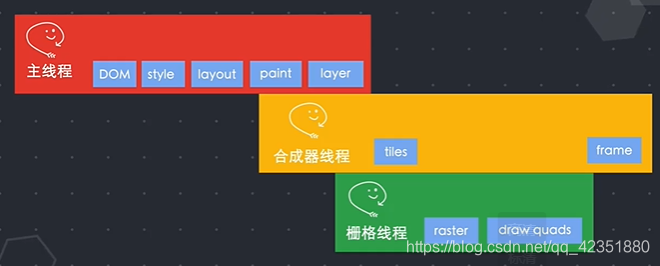
渲染器进程的主线程将
HTML进行解析,构造DOM数据结构,DOM:文档对象模型,是浏览器对页面在其内部的表示形式,是web开发者可以通过
JS与之交互的数据结构和APIHTML先通过
tokeniser标记化,通过词法分析将输入的HTML内容解析成多个标记,根据识别后的标记进行DOM树构造,在DOM树构造过程中会创建document对象,然后以document对象为根节点的DOM树不断进行修改,向其中添加各种元素。 -
主线程通过解析
CSS并确定每个DOM节点的计算样式,即使没有提供自定义的CSS样式,浏览器也会有自己默认的样式表。 -
确定结构在页面的位置,即节点坐标及占用区域,此阶段被称为
Layout布局。主线程通过遍历DOM和计算好的样式生成Layout Tree,树上的每个节点都记录了x,y坐标和边框尺寸。DOM Tree和Layout Tree并不是一一对应的:
-
DOM Tree设置了
display:none的节点不会出现在Layout Tree中 -
Layout Tree在
before伪类中添加了content值元素的值不会出现在DOM Tree中
因为DOM Tree是通过HTML解析获得,并不关系样式。而Layout Tree是根据DOM和计算好的样式来生成。Layout Tree和最后展示在页面上的节点是一一对应的。
-
-
通过遍历Layout Tree生成绘制顺序表(paint)。
-
再遍历Layout Tree遍历生成
Layer Tree。 -
主线程将Layer Tree和绘制信息一起传递给合成器线程。
-
合成器线程按照规则进行分图层,并把图层分为更小的图块(tiles)传递给栅格线程进行栅格化(raster)。
-
栅格化完成后,合成器线程会通过栅格线程传递来的
draw quads图块信息,根据这些信息合成器线上合成了一个合成器帧(frame)。然后将该合成器帧通过IPC传回给浏览器进程。 -
浏览器进程再传到
GPU进行渲染,完成页面展示。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











