







 本文深入解析Kafka的基础架构,包括生产者、消费者、消费者组等核心组件的工作原理及高级配置,如分区策略、ISR机制等。
本文深入解析Kafka的基础架构,包括生产者、消费者、消费者组等核心组件的工作原理及高级配置,如分区策略、ISR机制等。
kafka的基础架构
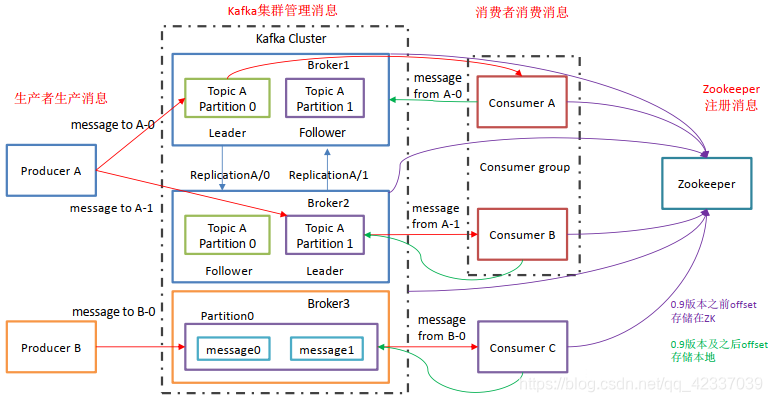
kafka的基础架构主要存在生产者Producer,Kafka集群Broker,消费者Consumer,注册消息Zookeeper
- Producer:消息生产者,向kafka中发布消息的角色
- Consumer:消息消费者,即从Kafka中拉取消息消费的客户端
- Consumer Group:消费者组,消费者组则是一组中存在多个消费,消费者消费Broker中当前Topic的不同分区中的消息,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者,某一个分区的消息只能够一个消费者组中的一个消费者所消费
- Broker:经纪人,一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic。
- Topic:主题,可以理解为一个队列,生产者和消费者都是面向一个Topic
- partition:分区,为了实现扩展性,一个非常大的topic可以分布到多个broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)
- replica:副本Replication,为保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常的工作,Kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower
- Leader:每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
- Follower:每个分区多个副本的从角色,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。
上述一个Topic会产生多个分区Partition,分区中分为Leader和Follower,消息一般发送到Leader,Follower通过数据的同步与Leader保持同步,消费的话也是在Leader中发生消费,如果多个消费者,则分别消费Leader和各个Follower中的消息,当Leader发生故障的时候,某个Follower会成为主节点,此时会对齐消息的偏移量
kafka高级
工作流程
kafka中消息是以topic进行分类的,Producer生产信息,Consumer消费信息,都是面向topic的
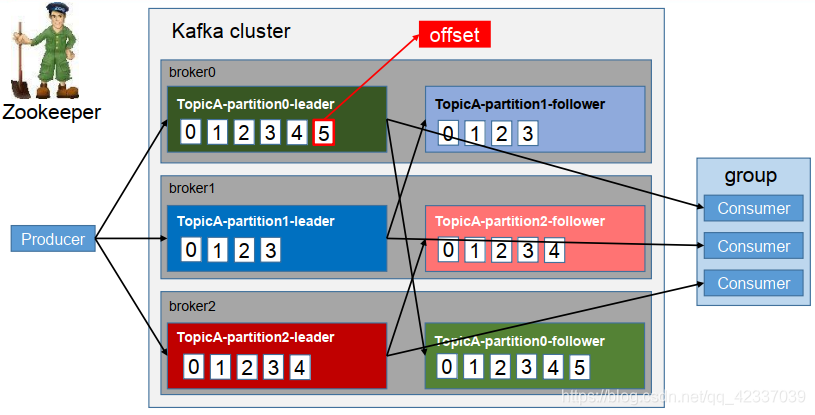
Topic是逻辑上的改变,Partition是物理上的概念,每个Partition对应着一个log文件,该log文件中存储的就是producer生产的数据,topic=N*partition;partition=log
Producer生产的数据会被不断的追加到该log文件的末端,且每条数据都有自己的offset,consumer组中的每个consumer,都会实时记录自己消费到哪个offset,以便出错恢复的时候,可以从上次的位置继续消费,流程:Producer => Topic(Log with offset)=> Consumer
生产者分区策略
分区的原因
- 方便在集群中扩展:每个partition通过调整以适应所在的机器,而一个Topic有可以有多个partition组成,因此整个集群可以适应适合的数据
- 可以提高并发:以partition为单位进行读写
分区的原则
- 指明partition(这里的指明是指第几个分区)的情况下,直接将指明的值作为partition的值
- 没有指明partition的情况下,但是存在值key,此时将key的hash值与topic的partition总数进行取余得到partition值
- 值与partition均无的情况下,第一次调用时随机生成一个整数,后面每次调用在这个整数上自增,将这个值与topic可用的partition总数取余得到partition值,即round-robin算法。
生产者ISR
为保证producer发送的数据能够可靠的发送到指定的topic中,topic的每个partition收到producer发送的数据后,都需要向producer发送ackacknowledgement,如果producer收到ack就会进行下一轮的发送,否则重新发送数据。
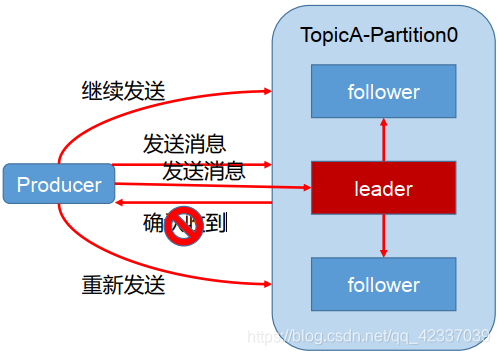
- 发送ack的时机:确保有follower与leader同步完成,leader在发送ack,这样可以保证在leader挂掉之后,follower中可以选出新的leader(主要是确保follower中数据不丢失)
- follower同步完成多少才发送ack:
半数以上的follower同步完成,即可发送ack:优点是延迟低
缺点是选举新的leader的时候,容忍n台节点的故障,需要2n+1个副本(因为需要半数同意,所以故障的时候,能够选举的前提是剩下的副本超过半数),容错率为1/2
全部的follower同步完成,才可以发送ack:优点是容错率搞,选举新的leader的时候,容忍n台节点的故障只需要n+1个副本即可,因为只需要剩下的一个人同意即可发送ack了
缺点是延迟高,因为需要全部副本同步完成才可
kafka选用的是第二种,因为在容器率上更加有优势,同时对于分区的数据而言,每个分区都有大量的数据,第一种方案会造成大量的数据的冗余,网络延迟高但是影响小
生产者ack机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没有必要等到ISR中所有的follower全部接受成功。
Kafka为用户提供了三种可靠性级别,用户根据可靠性和延迟的要求进行权衡选择不同的配置。
ack参数配置
-
0:producer不等待broker的ack,,这一操作提供了最低的延迟,broker接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据
-
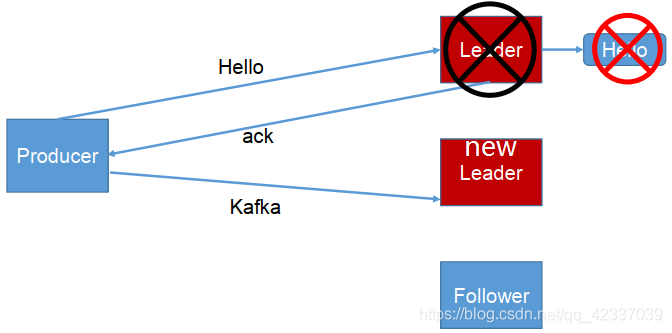
1:producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将丢失数据
-
-1:producer等待broker的ack,partition的leader和ISR的follower全部落盘成功才返回ack,但是如果在follower同步完成后,broker发送ack之前,如果leader发生故障,会造成数据重复。(这里的数据重复是因为没有收到,所以继续重发导致的数据重复)
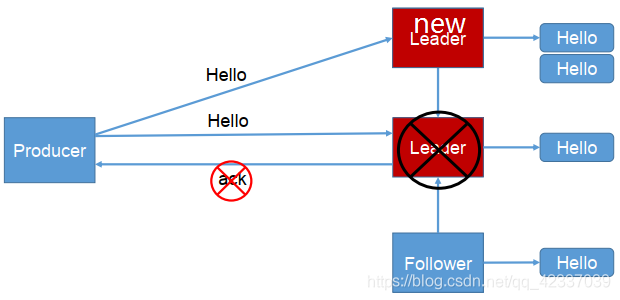
producer返ack,0无落盘直接返,1只leader落盘然后返,-1全部落盘然后返
数据一致性问题
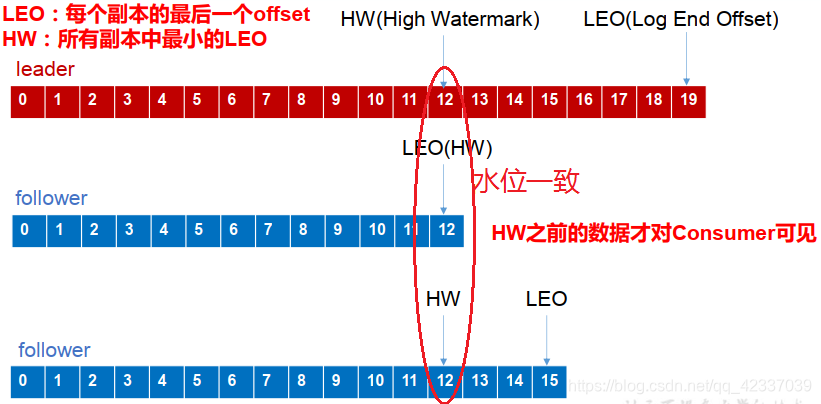
- LEO:每个副本最后的一个offset
- HW:高水位,指代消费者能见到的最大的offset,ISR队列中最小的LEO
follower故障和leader故障
- follower故障:follower发生故障后会被临时提出ISR,等待该follower恢复后,follower会读取本地i磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步,等待该follower的LEO大于等于该partition的HW,即follower追上leader之后,就可以重新加入ISR
- leader故障:leader发生故障之后,会从ISR中选出一个新的leader,为了保证多个副本之间的数据的一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader中同步数据。
这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复
消费者分区分配策略
消费方式
consumer采用pull拉的方式来从broker中读取数据,pushu推的模式很难适应消费速率不同的消费者,因为消息发送率是由broker决定的,它的目标是尽可能以最快的速度传递消息,但是这样容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull方式则可以让consumer根据自己的消费处理能力以适当的速度消费消息。
pull模式不足在于如果Kafka中没有数据,消费者可能会陷入循环之中 (因为消费者类似监听状态获取数据消费的),一直返回空数据,针对这一点,Kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,时长为timeout。
分区分配策略
一个consumer group中有多个consumer,一个topic中有多个partition,所以必然会涉及到partition的分配问题,即确定那个partition由哪个consumer消费的问题
kafka的两种分配策略
round-robin循环
range
Round-Robin
主要采用轮询的方式分配所有的分区,该策略主要实现的步骤
假设存在三个topic:t0/t1/t2,分别拥有1/2/3个分区,共有6个分区,分别为t0-0/t1-0/t1-1/t2-0/t2-1/t2-2,这里假设我们有三个Consumer,C0、C1、C2,订阅情况为C0:t0,C1:t0、t1,C2:t0/t1/t2。
此时round-robin采取的分配方式,则是按照分区的字典对分区和消费者进行排序,然后对分区进行循环遍历,遇到自己订阅的则消费,否则向下轮询下一个消费者。即按照分区轮询消费者,继而消息被消费。
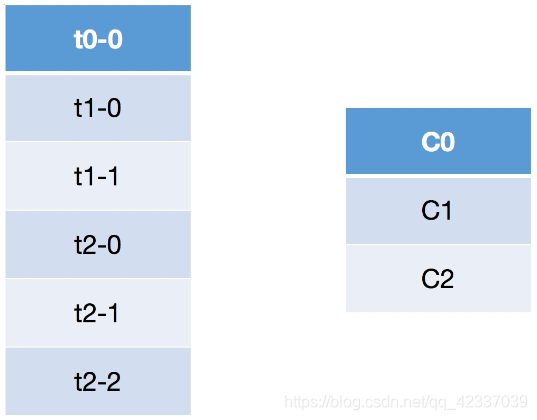
分区在循环遍历消费者,自己被当前消费者订阅,则消息与消费者共同向下(消息被消费),否则消费者向下消息继续遍历(消息没有被消费)。轮询的方式会导致每个Consumer所承载的分区数量不一致,从而导致各个Consumer压力不均。上面的C2因为订阅的比较多,导致承受的压力也相对较大。
Range
Range的重分配策略,首先计算各个Consumer将会承载的分区数量,然后将指定数量的分区分配给该Consumer。假设存在两个Consumer,C0和C1,两个Topic,t0和t1,这两个Topic分别都有三个分区,那么总共的分区有6个,t0-0,t0-1,t0-2,t1-0,t1-1,t1-2。分配方式如下:
- range按照topic一次进行分配,即消费者遍历topic,t0,含有三个分区,同时有两个订阅了该topic的消费者,将这些分区和消费者按照字典序排列。
- 按照平均分配的方式计算每个Consumer会得到多少个分区,如果没有除尽,多出来的分区则按照字典序挨个分配给消费者。按照此方式以此分配每一个topic给订阅的消费者,最后完成topic分区的分配。
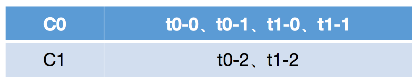
按照range的方式进行分配,本质上是以此遍历每个topic,然后将这些topic按照其订阅的consumer数进行平均分配,多出来的则按照consumer的字典序挨个分配,这种方式会导致在前面的consumer得到更多的分区,导致各个consumer的压力不均衡。
消费者offset的存储
由于Consumer在消费过程中可能会出现断电宕机等故障,Consumer恢复以后,需要从故障前的位置继续消费,所以Consumer需要实时记录自己消费到了那个offset,以便故障恢复后继续消费
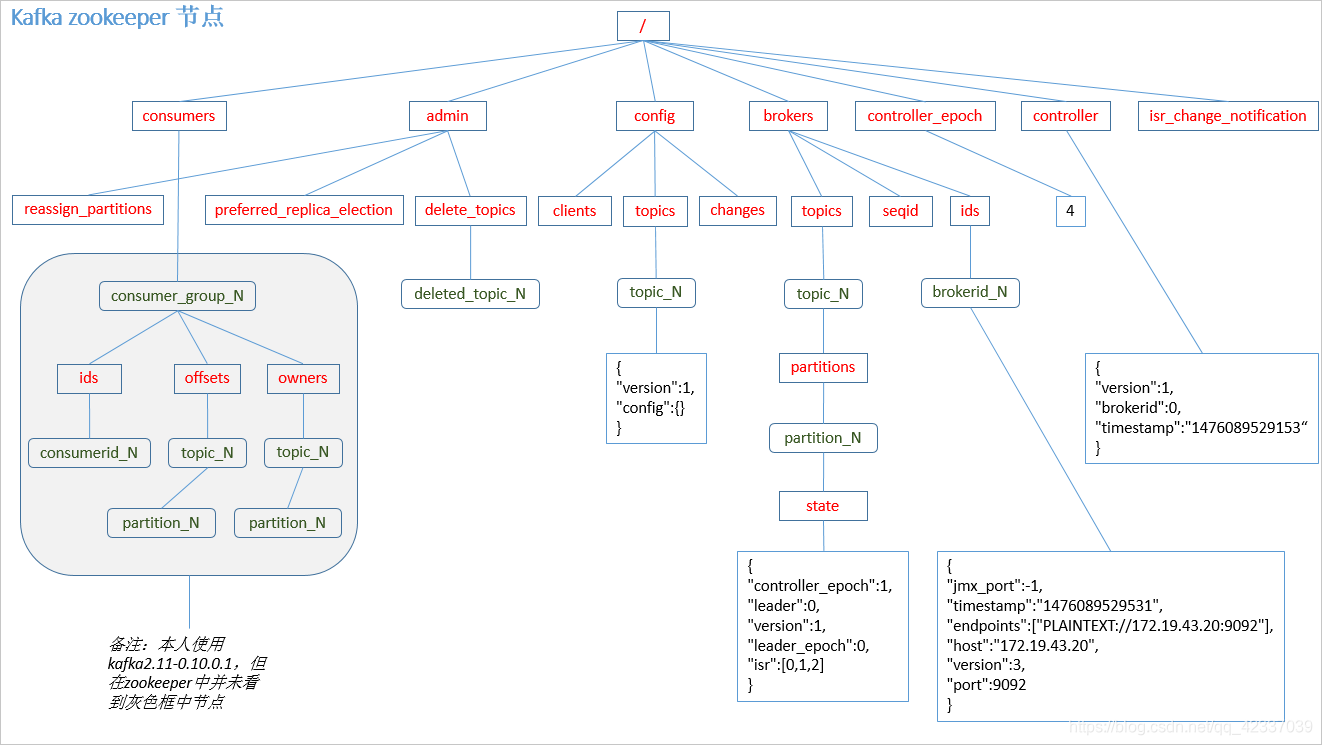
Kafka0.9版本之前,consumer默认将offset保存在zookeeper中,从0.9版本之后,consumer默认将offset保存在kafka一个内置的topic中,该topic为__consumer_offsets
重构kafka服务
spring-cloud-stream已经给我们定义了最基本的输入和输出接口,他们分别是Source,Sink,Processor
Sink接口
package com.xfgg.demo.stream;
import org.springframework.cloud.stream.annotation.Input;
import org.springframework.messaging.SubscribableChannel;
public interface Sink {
String INPUT = "input";
@Input("input")
SubscribableChannel input();
}
Source接口
package com.xfgg.demo.stream;
import org.springframework.cloud.stream.annotation.Output;
import org.springframework.messaging.MessageChannel;
public interface Source {
String OUTPUT="output";
@Output("output")
MessageChannel output();
}
processor接口
package com.xfgg.demo.stream;
public interface Processor extends Source,Sink{
}
processer接口定义了输入通道又定义了输出通道,同时我们也可以自己定义通道接口,
昨天不行,是因为没有在监听输入通道,导致没有任何消息经过输入通道
ShopChannel
package com.xfgg.demo.channel;
import org.springframework.cloud.stream.annotation.Input;
import org.springframework.cloud.stream.annotation.Output;
import org.springframework.messaging.MessageChannel;
import org.springframework.messaging.SubscribableChannel;
import org.springframework.stereotype.Component;
public interface ShopChannel {
/**
* 发消息的通道名称
*/
String SHOP_OUTPUT = "shop_output";
/**
* 消息的订阅通道名称
*/
String SHOP_INPUT = "shop_input";
/**
* 发消息的通道
*
* @return
*/
@Output(SHOP_OUTPUT)
MessageChannel sendShopMessage();
/**
* 收消息的通道
*
* @return
*/
@Input(SHOP_INPUT)
SubscribableChannel recieveShopMessage();
}
定义服务类
package com.xfgg.demo.service;
import com.xfgg.demo.channel.ShopChannel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.messaging.Message;
import org.springframework.messaging.MessageChannel;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
@RestController
public class ShopService {
@Resource(name = ShopChannel.SHOP_OUTPUT)
private MessageChannel sendShopMessageChannel;
@GetMapping("/sendMsg")
public String sendShopMessage(String content) {
boolean isSendSuccess = sendShopMessageChannel.
send(MessageBuilder.withPayload(content).build());
return isSendSuccess ? "发送成功" : "发送失败";
}
@StreamListener(ShopChannel.SHOP_INPUT)
public void receive(Message<String> message) {
System.out.println(message.getPayload());
}
}
定义启动类
package com.xfgg.demo;
import com.xfgg.demo.channel.ShopChannel;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.stream.annotation.EnableBinding;
@SpringBootApplication
@EnableBinding(ShopChannel.class)
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
定义application.yml文件
spring:
application:
name: shop-server
cloud:
stream:
bindings:
#配置自己定义的通道与哪个中间件交互
shop_input: #ShopChannel里Input和Output的值
destination: xfgg #目标主题
shop_output:
destination: xfgg
default-binder: kafka #默认的binder是kafka
kafka:
bootstrap-servers: localhost:9092 #kafka服务地址
consumer:
group-id: consumer1
producer:
key-serializer: org.apache.kafka.common.serialization.ByteArraySerializer
value-serializer: org.apache.kafka.common.serialization.ByteArraySerializer
client-id: producer1
server:
port: 8100
在服务上就把这些配置加入到服务C中就可以了
成功的解决了昨天的残留问题
效果图


修改服务C来实现kafka记录入参
把ShopChannel,Sink,Source移动到服务C中

修改UserAdminController
@Resource(name = ShopChannel.SHOP_OUTPUT)
private MessageChannel sendShopMessageChannel;
@RequestMapping(value = "/getUser/{id}")
public User getUserById(@PathVariable(value = "id") int id,String content){
User user = userService.getUserById(id);
System.out.println(user);
boolean isSendSuccess = sendShopMessageChannel.send(MessageBuilder.withPayload(content).build());
return isSendSuccess?userService.getUserById(id) : null;
}
发现报错了

这个bug卡了半天
shit
搞了半天发现是kafka的问题,因为我之前也弄了一个相同配置的服务,所以会发生冲突导致这一个连接不上kafka
无法产生生产者和消费者
这是kafka的问题,则停止kafka,移除kafka并启动kafka,而且配置文件也写错了 最坑爹的是:写成.号
因为是从yml文件转换到properties文件
新的配置文件
server.port=8092
spring.application.name=turbine-c
eureka.instance.prefer-ip-address=true
eureka.instance.hostname=${spring.cloud.client.ip-address}
eureka.instance.instance-id=${spring.cloud.client.ip-address}:${spring.application.name}:${server.port}
eureka.client.service-url.defaultZone= http://${eureka.instance.hostname}:8761/eureka/
management.endpoints.web.exposure.include=*
feign.hystrix.enabled=true
#数据源相关配置
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/kgc?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true
spring.datasource.username=root
spring.datasource.password=123456
#映射xml文件
mybatis.mapper-locations=mapper/*.xml
mybatis.type-aliases-package=com.xfgg.demo
#redis配置
#数据库索引
spring.redis.database=0
#服务器地址
spring.redis.host=127.0.0.1
#服务器端口
spring.redis.port=6379
#服务器连接密码
spring.redis.password=
spring.redis.jedis.pool.max-active=20
spring.redis.jedis.pool.max-wait=-1
spring.redis.jedis.pool.max-idle=10
spring.redis.jedis.pool.min-idle=0
spring.redis.timeout=1000
#kafka配置
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.consumer.group-id=consumer1
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.ByteArraySerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.ByteArraySerializer
spring.kafka.producer.client-id=producer1
spring.cloud.stream.bindings.shop_input.destination=xfgg
spring.cloud.stream.bindings.shop_output.destination=xfgg
spring.cloud.stream.default-binder=kafka


kafka的配置详解
kafka生产者配置项
kafka:
producer:
max-request-size: 10485760
bootstrap-servers: 10.80.111.214:9092
request-required-acks: 1
retries: 5
batch-size: 16384
linger: 1
buffer-memory: 134217728
block-on-buffer-full: false
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
kafka生产者配置到spring容器
@Value("${kafka.producer.max-request-size}")
private String maxRequestSize;
@Value("${kafka.producer.bootstrap-servers}")
private String servers;
@Value("${kafka.producer.request-required-acks}")
private String requiredAcks;
@Value("${kafka.producer.retries}")
private String retries;
@Value("${kafka.producer.batch-size}")
private String batchSize;
@Value("${kafka.producer.linger}")
private String linger;
@Value("${kafka.producer.buffer-memory}")
private String bufferMemory;
@Value("${kafka.producer.key-serializer}")
private String key;
@Value("${kafka.producer.value-serializer}")
private String value;
@Bean("kafkaTemplate")
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<String, String>(producerFactory());
}
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> properties = new HashMap<>();
参数的具体意义
//重试请求,如果请求失败生产者会自动重试,如果启用重试,则会有重复消息的可能性
properties.put(ProducerConfig.RETRIES_CONFIG,retries)
//最大消息大小
properties.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG, maxRequestSize);
/**
* Server完成 producer request 前需要确认的数量。 acks=0时,producer不会等待确认,直接添加到socket等待发送;
* acks=1时,等待leader写到local log就行; acks=all或acks=-1时,等待isr中所有副本确认 (注意:确认都是 broker
* 接收到消息放入内存就直接返回确认,不是需要等待数据写入磁盘后才返回确认,这也是kafka快的原因)
/
properties.put(ProducerConfig.ACKS_CONFIG, requiredAcks);
/
* Producer可以将发往同一个Partition的数据做成一个Produce
* Request发送请求,即Batch批处理,以减少请求次数,该值即为每次批处理的大小。
* 另外每个Request请求包含多个Batch,每个Batch对应一个Partition,且一个Request发送的目的Broker均为这些partition的leader副本。
* 若将该值设为0,则不会进行批处理
**/
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
/**
* 默认缓冲可立即发送,即遍缓冲空间还没有满,但是,如果你想减少请求的数量,可以设置linger.ms大于0。
* 这将指示生产者发送请求之前等待一段时间,希望更多的消息填补到未满的批中。这类似于TCP的算法,例如上面的代码段,
* 可能100条消息在一个请求发送,因为我们设置了linger(逗留)时间为1毫秒,然后,如果我们没有填满缓冲区,
* 这个设置将增加1毫秒的延迟请求以等待更多的消息。 需要注意的是,在高负载下,相近的时间一般也会组成批,即使是
* linger.ms=0。在不处于高负载的情况下,如果设置比0大,以少量的延迟代价换取更少的,更有效的请求。
/
properties.put(ProducerConfig.LINGER_MS_CONFIG, linger);
/
* 控制生产者可用的缓存总量,如果消息发送速度比其传输到服务器的快,将会耗尽这个缓存空间。
* 当缓存空间耗尽,其他发送调用将被阻塞,阻塞时间的阈值通过max.block.ms设定, 之后它将抛出一个TimeoutException。
*/
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, key);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, value);
return new DefaultKafkaProducerFactory<String, String>(properties)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









