







DPDK根据多核处理器的特点,遵循资源局部化的原则,解耦数据的跨核共享,使得性能可以有很好的水平扩展。但当面对实际应用场景,CPU核间的数据通信、数据同步、临界区保护等都是不得不面对的问题。如何减少由这些基础组件引入的多核依赖的副作用,也是DPDK的一个重要的努力方向。
原子操作
原子(atom)本意是“不能被进一步分割的最小粒子”,而原子操作(atomic operation)意为“不可被中断的一个或一系列操作”。对原子操作的简单描述就是:多个线程执行一个操作时,其中任何一个线程要么完全执行完此操作,要么没有执行此操作的任何步骤,那么这个操作就是原子的。原子操作是其他内核同步方法的基石。
处理器上的原子操作
在单处理器系统(UniProcessor)中,能够在单条指令中完成的操作都可以认为是“原子操作”,因为中断只能发生于指令之间。这也是某些CPU指令系统中引入了test_and_set、test_and_clear等指令用于临界资源互斥的原因。
在多核CPU的时代,体系中运行着多个独立的CPU,即使是可以在单个指令中完成的操作也可能会被干扰。典型的例子就是decl指令(递减指令),它细分为三个过程:“读->改->写”,涉及两次内存操作。如果多个CPU运行的多个进程或线程在同时对同一块内存执行这个指令,那情况是无法预测的。
在x86平台上,总的来说,CPU提供三种独立的原子锁机制:原子保证操作、加LOCK指令前缀和缓存一致性协议。
一些基础内存事务操作,如对一个字节的读或者写,它们总是原子的。处理器保证操作没完成前,其他处理器不能访问相同的内存位置。对于边界对齐的字节、字、双字和四字节都可以自然地进行原子读写操作;对于非对齐的字节、字、双字和四字节,如果它们属于同一个缓存行,那么它们的读写也是自然原子保证的。
在这里特别介绍一下CMPXCHG这条指令,它的语义是比较并交换操作数(CAS,Compare And Set)。而用XCHG类的指令做内存操作,处理器会自动地遵循LOCK的语义,可见该指令是一条原子的CAS单指令操作。它可是实现很多无锁数据结构的基础,DPDK的无锁队列就是一个很好的实现例子。
CAS操作需要输入两个数值,一个旧值(期望操作前的值)和一个新值,在操作期间先比较下旧值有没有发生变化,如果没有发生变化,才交换成新值,发生了变化,则不交换。
如:CMPXCHG r/m,r将累加器AL/AX/EAX/RAX中的值与首操作数(目的操作数)比较,如果相等,第2操作数(源操作数)的值装载 到 首 操 作 数 , zf 置 1 。 如 果 不 等 , 首 操 作 数 的 值 装 载 到AL/AX/EAX/RAX,并将zf清0。
Linux内核原子操作
软件级的原子操作实现依赖于硬件原子操作的支持。对于Linux而言,内核提供了两组原子操作接口:一组是针对整数进行操作;另一组是针对单独的位进行操作。
原子整数操作
针对整数的原子操作只能处理atomic_t类型的数据。这里没有使用C语言的int类型,主要是因为:
- 让原子函数只接受atomic_t类型操作数,可以确保原子操作只与这种特殊类型数据一起使用。
- 使用atomic_t类型确保编译器不对相应的值进行访问优化。
- 使用atomic_t类型可以屏蔽不同体系结构上的数据类型的差异。尽管Linux支持的所有机器上的整型数据都是32位,但是使用atomic_t的代码只能将该类型的数据当作24位来使用。这个限制完全是因为在SPARC体系结构上,原子操作的实现不同于其他体系结构:32位int类型的低8位嵌入了一个锁,因为SPARC体系结构对原子操作缺乏指令级的支持,所以只能利用该锁来避免对原子类型数据的并发访问。
原子整数操作最常见的用途就是实现计数器。原子操作通常是内敛函数,往往通过内嵌汇编指令来实现。如果某个函数本来就是原子的,那么它往往会被定义成一个宏。
原子性与顺序性
原子性确保指令执行期间不被打断,要么全部执行,要么根本不执行。而顺序性确保即使两条或多条指令出现在独立的执行线程中,甚至独立的处理器上,它们本该执行的顺序依然要保持。
原子位操作
原子位操作函数是对普通的内存地址进行操作的。原子位操作在多数情况下是对一个字长的内存访问,因而位编号在031之间(在64位机器上是063之间),但是对位号的范围没有限制。
在Linux内核中,原子位操作分别定义于include\linux\types.h和arch\x86\include\asm\bitops.h。通常了解一个东西,我们是先了解它怎么用,因此,我们先来看看内核提供给用户的一些接口函数。对于整数原子操作函数,如表4-1所示,下述有关加法的操作在内核中均有相应的减法操作。
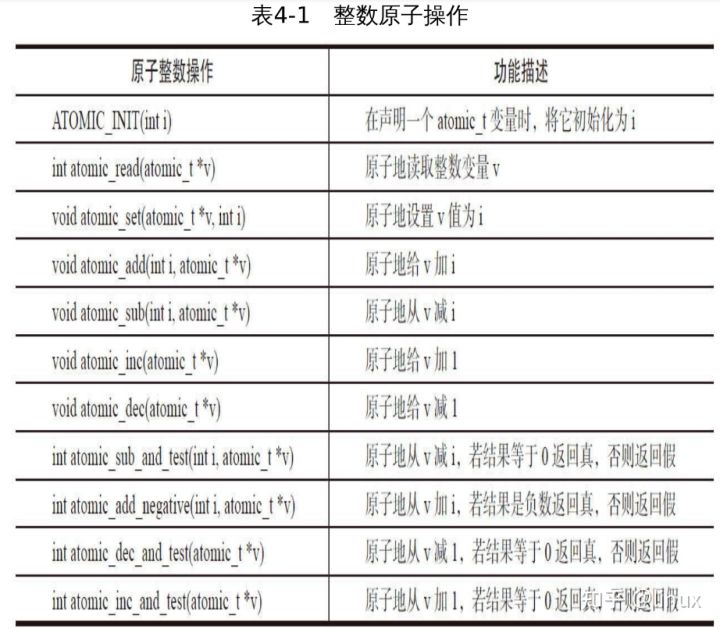
表4-2展示的是内核中提供的一些主要位原子操作函数。同时内核
还提供了一组与上述操作对应的非原子位操作函数,名字前多两下划线。由于不保证原子性,因此速度可能执行更快。

DPDK原子操作实现和应用
原子操作在DPDK代码中的定义都在rte_atomic.h文件中,主要包含两部分:内存屏蔽和原16、32和64位的原子操作API。
内存屏障API
- rte_mb():内存屏障读写API
- rte_wmb():内存屏障写API
- rte_rmb():内存屏障读API
这三个API的实现在DPDK代码中没有什么区别,都是直接调用__sync_synchronize(),而__sync_synchronize()函数对应着MFENCE这个序列化加载与存储操作汇编指令。
对MFENCE指令之前发出的所有加载与存储指令执行序列化操作。此序列化操作确保:在全局范围内看到MFENCE指令后面(按程序顺序)的任何加载与存储指令之前,可以在全局范围内看到MFENCE指令前面的每一条加载与存储指令。MFENCE指令的顺序根据 所 有 的 加 载 与 存 储 指 令 、 其 他 MFENCE 指 令 、 任 何 SFENCE 与LFENCE指令以及任何序列化指令(如CPUID指令)确定
通过使用无序发出、推测性读取、写入组合以及写入折叠等技术,弱序类型的内存可获得更高的性能。数据使用者对数据弱序程序的认知或了解因应用程序的不同而异,并且可能不为此数据的产生者所知。对于确保产生弱序结果的例程与使用此数据的例程之间的顺序,MFENCE指令提供了一种高效的方法。
我 们 在 这 里 给 出 一 个 内 存 屏 障 的 应 用 在 DPDK 中 的 实 例 , 在virtio_dev_rx()函数中,在读取avail->flags之前,加入内存屏障API以防止乱序的执行。
*(volatile uint16_t *)&vq->used->idx += count;
vq->last_used_idx = res_end_idx;
/* flush used->idx update before we read avail->flags. */
rte_mb();
/* Kick the guest if necessary. */
if (!(vq->avail->flags & VRING_AVAIL_F_NO_INTERRUPT))
eventfd_write(vq->callfd, (eventfd_t)1); 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2243
2243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









