







吴恩达深度学习week2-实战:搭建一个能够【识别猫】** 的简单的神经网络**
我们要做的事是搭建一个能够**【识别猫】** 的简单的神经网络
h5py文件是存放两类对象的容器,数据集(dataset)和组(group),dataset类似数组类的数据集合,和numpy的数组差不多。group是像文件夹一样的容器,它好比python中的字典,有键(key)和值(value)。group中可以存放dataset或者其他的group。”键”就是组成员的名称,”值”就是组成员对象本身(组或者数据集)
一、处理数据集
import numpy as np
import matplotlib.pyplot as plt
import h5py
from lr_utils import load_dataset
train_set_x_orig , train_set_y , test_set_x_orig , test_set_y , classes = load_dataset()
index = 23
plt.imshow(train_set_x_orig[index])
plt.subplot(2,3,1)
plt.imshow(train_set_x_orig[25])
plt.subplot(2,3,2)
plt.imshow(train_set_x_orig[1])
plt.subplot(2,3,3)
plt.imshow(train_set_x_orig[2])
plt.subplot(2,3,4)
plt.imshow(train_set_x_orig[3])
plt.subplot(2,3,5)
plt.imshow(train_set_x_orig[4])
plt.subplot(2,3,6)
plt.imshow(train_set_x_orig[5])
plt.show()
#print("train_set_y=" + str(train_set_y)) #你也可以看一下训练集里面的标签是什么样的。

#打印出当前的训练标签值
#使用np.squeeze的目的是压缩维度,【未压缩】train_set_y[:,index]的值为[1] , 【压缩后】np.squeeze(train_set_y[:,index])的值为1
#print("【使用np.squeeze:" + str(np.squeeze(train_set_y[:,index])) + ",不使用np.squeeze: " + str(train_set_y[:,index]) + "】")
#只有压缩后的值才能进行解码操作
print("y=" + str(train_set_y[:,index]) + ", it's a " + classes[np.squeeze(train_set_y[:,index])].decode("utf-8") + "' picture")
m_train= train_set_y.shape[1] #训练集里图片的数量
m_test = test_set_y.shape[1] #测试集里图片的数量
num_px = train_set_x_orig.shape[1] #训练、测试集里面的图片的宽度和高度(均为64x64)。
#print(num_px)
#现在看一看我们加载的东西的具体情况
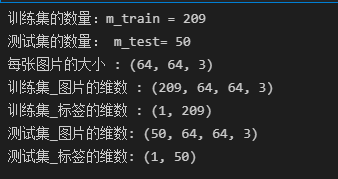
print("训练集的数量:m_train = "+ str(m_train))
print("测试集的数量: m_test= "+ str(m_test))
print ("每张图片的大小 : (" + str(num_px) + ", " + str(num_px) + ", 3)")
print ("训练集_图片的维数 : " + str(train_set_x_orig.shape))
print ("训练集_标签的维数 : " + str(train_set_y.shape))
print ("测试集_图片的维数: " + str(test_set_x_orig.shape))
print ("测试集_标签的维数: " + str(test_set_y.shape))
为了方便,我们要把维度为(64,64,3)的numpy数组重新构造为(64 x 64 x 3,1)的数组,要乘以3的原因是每张图片是由64x64像素构成的,而每个像素点由(R,G,B)三原色构成的,所以要乘以3。在此之后,我们的训练和测试数据集是一个numpy数组,【每列代表一个平坦的图像】 ,应该有m_train和m_test列。
#X_flatten = X.reshape(X.shape [0],-1).T #X.T是X的转置
#将训练集的维度降低并转置。
#print(train_set_x_orig.shape) #(209,64,64,3)
# print(train_set_x_orig.shape[0])、
# print(train_set_x_orig)
# print(train_set_x_orig.reshape(train_set_x_orig.shape[0],-1))
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0],-1).T #X.reshape(X.shape[0], -1).T可以将一个维度为(a,b,c,d)的矩阵转换为一个维度为(b∗c∗d, a)的矩阵。
#(209,64,64,3) 转变成(64*64*3,209) 但是想让X变成209行,列数不知道是多少,所以也就是209 * 64 * 64 * 3 / 209,也就是64 * 64 * 3。
#reshape 不知道哪一行/列是多少,可就设置为-1
#print(train_set_x_flatten.shape) #(209,12288).T=(12288, 209)
#将测试集的维度降低并转置。
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T
这一段意思是指把数组变为209行的矩阵(因为训练集里有209张图片),但是我懒得算列有多少,于是我就用-1告诉程序你帮我算,最后程序算出来时12288列,我再最后用一个T表示转置,这就变成了12288行,209列。测试集亦如此。
print ("训练集降维最后的维度: " + str(train_set_ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











