






1.官网
- docker官网:http://www.docker.com
- docker中文网站:https://www.docker-cn.com/
2.仓库
- Docker Hub官网: https://hub.docker.com/
3.docker安装步骤
1.安装gcc
yum -y install gcc
2.安装gcc-c++
yum -y install gcc-c++
3.卸载旧版本
yum -y remove docker docker-common docker-selinux docker-engine
4.安装需要的软件包
yum install -y yum-utils device-mapper-persistent-data lvm2
5.设置stable镜像仓库
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
6.更新yum软件包索引
yum makecache fast
7.安装DOCKER CE
yum -y install docker-ce
8.启动docker
systemctl start docker 启动docker
systemctl enable docker 开机自启
systemctl status docker 查看docker状态
systemctl stop docker 关闭docker
systemctl restart docker 重启docker
9.测试
- 查看docker版本
docker version
- 运行 hello-world案例
docker run hello-world
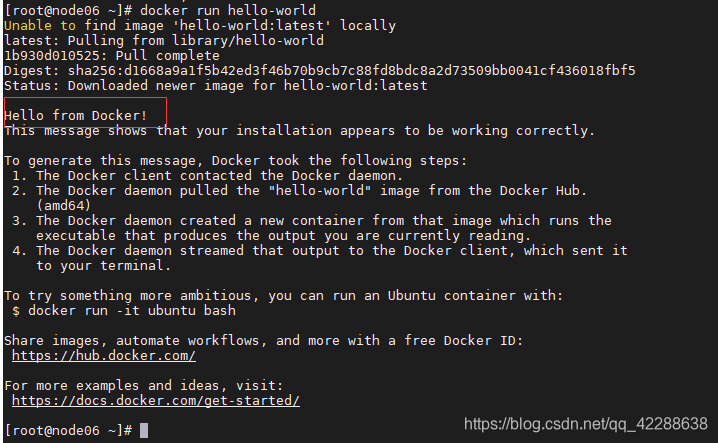
看到Hello from Docker!说明就成功了。
10.配置阿里云镜像加速器
1)首先注册阿里云账号,地址:https://promotion.aliyun.com/ntms/act/kubernetes.html,
注册后点击控制台,后续操作如下图所示

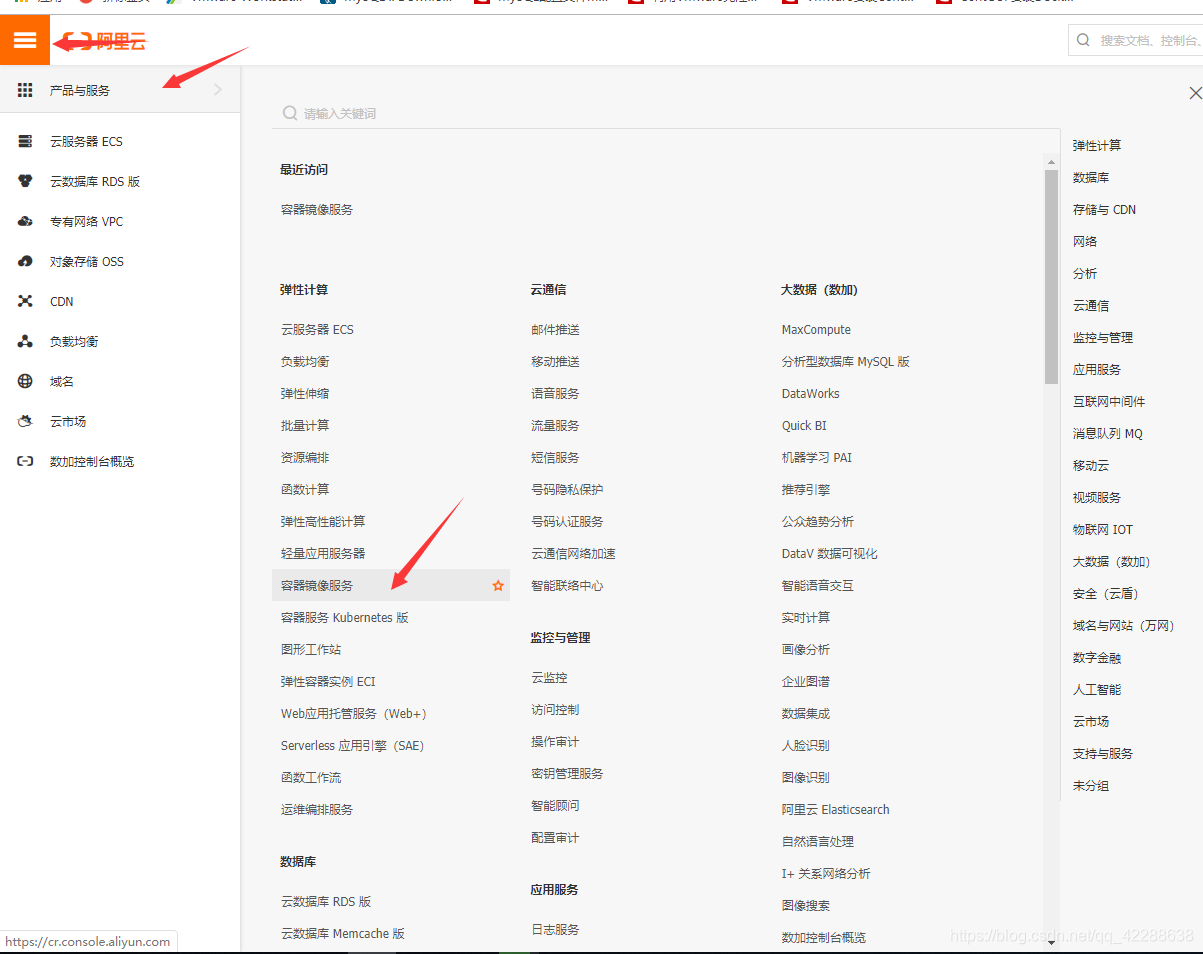
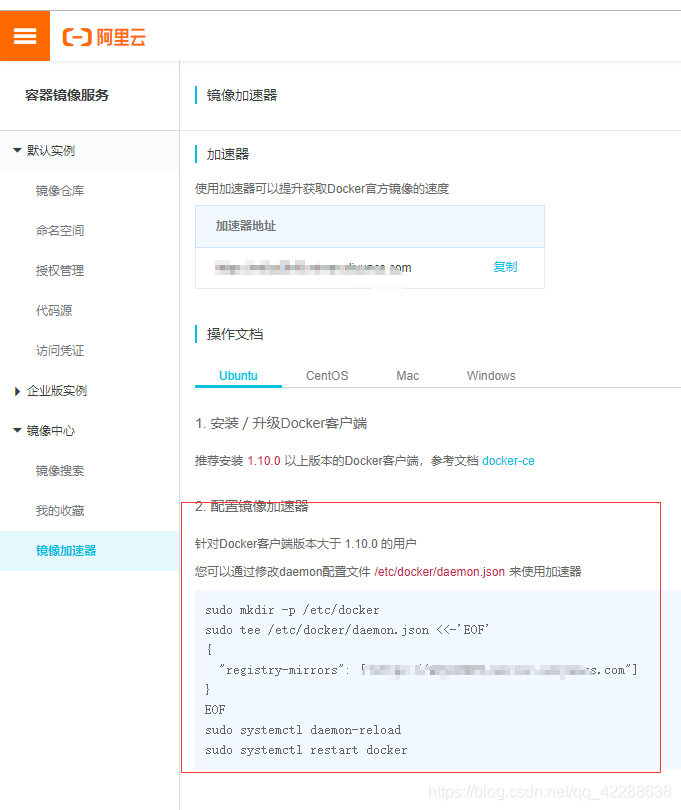
配置镜像加速器步骤:
mkdir -p /etc/docker ##创建一个多级目录
vim /etc/docker/daemon.json ##在这个目录下创建一个daemon.json文件
把上图中registry-mirrors这个 json数据拷贝到daemon.json文件中
systemctl daemon-reload
systemctl restart docker
执行命令:systemctl status docker
如果正常则说明成功启动了。
4.docker安装mysql

1.下载mysql镜像
docker pull mysql:5.7
2.启动mysql
docker run -p 3306:3306 --name mysql \
-v /mydata/mysql/log:/var/log/mysql \
-v /mydata/mysql/data:/var/lib/mysql \
-v /mydata/mysql/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
3.进入mysql容器里
docker exec -it mysql /bin/bash
4.查看容器中mysql的位置
whereis mysql
5.退出容器
exit
6.mysql配置修改
vi /mydata/mysql/conf/my.cnf
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection=utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
7.重启容器让配置生效
docker restart mysql
然后进入容器看mysql的配置文件和外面挂载的文件是否一致
cd /etc/mysql
cat my.cnf
5.docker安装redis
1.拉去redis镜像
docker pull redis
2.在容器外面创建一个redis配置文件
touch redis.conf
3.启动redis
docker run -p 6379:6379 --name redis -v /mydata/redis/data:/data \
-v /mydata/redis/conf/redis.conf:/etc/redis/redis.conf \
-d redis redis-server /etc/redis/redis.conf
4.进入redis控制台
docker exec -it redis redis-cli
5.vim redis.conf
添加appendonly yes 使数据能够持久化保存(aof持久化)
重启redis
docker restart redis
6.设置重启docker容器的时候自动启动redis,mysql镜像
docker update redis --restart=always
docker update mysql --restart=always
docker update 容器id --restart=always
6.安装npm,搭建vue脚手架
码云上下载renren-fast-vue脚手架
设置淘宝镜像
npm config set registry http://registry.npm.taobao.org/
npm install 过后报错(https://blog.youkuaiyun.com/weixin_42614080/article/details/107052787)
然后执行
npm i node-sass --sass_binary_site=https://npm.taobao.org/mirrors/node-sass/
最后npm run dev
7.安装es和kibana
1)下载es和kibana镜像
docker pull elasticsearch:7.4.2
docker pull kibana:7.4.2
2)创建es外部的文件夹
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
3)给elasticsearch下的文件及文件夹赋权(可读可写可执行)
chmod -R 777 /mydata/elasticsearch/
4)创建es配置文件
#此配置表示es可以被任何远程的机器进行访问
echo "http.host: 0.0.0.0">>/mydata/elasticsearch/config/elasticsearch.yml
5)运行es容器
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
#es端口说明
9200:发送http请求rest api的时候使用
9300: es在分布式集群状态下他们节点之间的通信端口
6)验证es是否成功可访问下面地址(自己的服务器地址)
192.168.126.143:9200
7)启动es的kibana容器(视图化客户端)
注意:http://192.168.126.143:9200 这个地址一定要改为自己虚拟机的地址,否则访问kibana可视化界面的时候会访问不同,在kibana可视化页面发请求的时候,是把请求发给我们配置的这个地址。
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.126.143:9200 -p 5601:5601 -d kibana:7.4.2
8)kibana访问地址(192.168.126.143为自己的服务器地址)
192.168.126.143:5601
9)查看容器运行过程中的日志
docker logs +容器id
8.es的简单实用
1)_cat
GET /_cat/nodes: 查看所有节点
GET /_cat/health: 查看es健康状况
GET /_cat/master: 查看主节点
GET /_cat/indices: 查看所有索引 类似于mysql中的 show databases;
2)索引的一个文档保存
保存一个数据,保存在哪个索引的哪个类型下,指定用哪个唯一标识
PUT customer/external/1;在customer索引下的external类型下保存1号数据为
PUT customer/external/1
新增测试数据
1. PUT请求: http://192.168.175.128:9200/bank/china/1
{
"name": "张三",
"age": 21,
"balance": 2500,
"address": "南京市建邺区",
"sort": 22
}
2.POST请求: http://192.168.175.128:9200/bank/china/
{
"name": "李四",
"age": 24,
"balance": 2530,
"address": "南京市鼓楼区",
"sort": 24
}
3)es的查询
1.http://192.168.175.128:9200/customer/external/1
get请求,查询customer索引下external类型的id=1的数据
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 4,
"_seq_no": 8,
"_primary_term": 1,
"found": true,
"_source": {
"ahdm": "32010020210311000001",
"fydm": "320100",
"num": 13
}
}
2.http://192.168.175.128:9200/customer/_search?q=*&sort=num:asc
查询customer索引下所有类型数据但是按照num升序
{
"took": 503,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "customer",
"_type": "external",
"_id": "2",
"_score": null,
"_source": {
"ahdm": "32010020210311000001",
"fydm": "320300",
"num": 10
},
"sort": [
10
]
},
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_score": null,
"_source": {
"ahdm": "32010020210311000001",
"fydm": "320100",
"num": 13
},
"sort": [
13
]
},
{
"_index": "customer",
"_type": "external",
"_id": "xbhslnsBWPSVNSbDLg9b",
"_score": null,
"_source": {
"ahdm": "32010020210311000001"
},
"sort": [
9223372036854775807
]
},
{
"_index": "customer",
"_type": "external",
"_id": "xrhslnsBWPSVNSbDOQ_H",
"_score": null,
"_source": {
"ahdm": "32010020210311000001"
},
"sort": [
9223372036854775807
]
}
]
}
}
3.http://192.168.175.128:9200/customer/_search
请求参数:查询所有customer索引下的按照num升序,balance降序的数据
{
"query": {
"match_all": {}
},
"sort": [
{
"num": "asc"
},
{
"balance": "desc"
}
]
}
响应参数:
{
"took": 824,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "customer",
"_type": "external",
"_id": "2",
"_score": null,
"_source": {
"ahdm": "32010020210311000001",
"fydm": "320300",
"num": 13,
"balance": 55
},
"sort": [
13,
55
]
},
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_score": null,
"_source": {
"ahdm": "32010020210311000001",
"fydm": "320100",
"num": 13,
"balance": 22
},
"sort": [
13,
22
]
},
{
"_index": "customer",
"_type": "external",
"_id": "xbhslnsBWPSVNSbDLg9b",
"_score": null,
"_source": {
"ahdm": "32010020210311000001"
},
"sort": [
9223372036854775807,
-9223372036854775808
]
},
{
"_index": "customer",
"_type": "external",
"_id": "xrhslnsBWPSVNSbDOQ_H",
"_score": null,
"_source": {
"ahdm": "32010020210311000001"
},
"sort": [
9223372036854775807,
-9223372036854775808
]
}
]
}
}
4.分页以及只展示部分字段,请求参数如下所示:
{
"query": {
"match_all": {}
},
"sort": [
{
"num": "asc"
},
{
"balance": "desc"
}
],
"from": 0,
"size": 3,
"_source":["num","balance"]
}
5.查询指定字段,如果字段是数字,那就是精确查询,如果字段是字符串,那就是模糊查询
{
"query": {
"match": {
"balance": 55
}
}
}
全文检索最终会按照评分进行排序,会对检索条件进行分词匹配
6.match_phrase (短语匹配)
{
"query": {
"match_phrase": {
"address": "mill road"
}
}
}
7.多字段匹配
{
"query": {
"multi_match": {
"query": "3",
"fields": ["fydm","ahdm"]
}
}
}
8.bool复合查询
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "张三1"
}
},
{
"match": {
"address": "南京市建邺区"
}
}
],
"must_not": [
{
"match": {
"age": "21"
}
}
],
"should": [
{
"match": {
"sex": "女"
}
}
]
}
}
}
9.filter过滤
1){
"query": {
"bool": {
"must": [
{
"range": {
"age": {
"gte": 10,
"lte": 21
}
}
}
]
}
}
}
2){
"query": {
"bool": {
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 23
}
}
}
}
}
}
第二种写法不会有相关性得分(直接用filter过滤则无相关性得分,用must,match会有)
10.term查询
全文检索字段用match,其他非text字段匹配用term
{
"query": {
"term": {
"balance": "2500"
}
}
}
加上keyword可以精确查询
{
"query": {
"match": {
"address.keyword": "南京市建邺区"
}
}
}
11.按照年龄聚合,并且请求这些年龄段的这些人的平均工资
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"ageAvg": {
"avg": {
"field": "balance"
}
}
}
}
}
}
12.mapping映射创建
PUT /my_index
{
"mappings": {
"properties": {
"age":{"type": "integer"},
"email":{"type": "keyword"},
"name":{"type": "text"}
}
}
}
13.查询映射
http://192.168.175.128:9200/my_index/_mapping get请求即可
14.添加新的字段映射(在原有基础上增加)
PUT /my_index/_mapping
{
"properties": {
"empolyee_id": {
"type": "keyword",
"index": false
}
}
}
15.映射没法直接修改的,只能创建一个新的,然后把老的数据迁移过去
POST _reindex
{
"source": {
"index": "bank",
"type": "account"
},
"dest": {
"index": "newbank"
}
}
16.安装ik分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.4.2
解压到/mydata/elasticsearch/plugins/ik 目录下
POST _analyze
1)标准分词器
{
"analyzer": "standard",
"text": "我爱中国"
}
POST _analyze
2)ik分词器(智能分词)
{
"analyzer": "ik_smart",
"text": "我爱中国"
}
3)ik分词器(最大分词)
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我爱中国"
}
9.es-自定义扩展词库
1).安装nginx

cd /mydata
mkdir nginx
docker run -p 80:80 --name nginx -d nginx:1.10
docker container cp nginx:/etc/nginx .
docker stop nginx
mv nginx conf
mkdir nginx
mv conf nginx/
docker rm $containerId
docker run -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf:/etc/nginx \
-d nginx:1.10
验证nginx安装是否成功
进入html文件夹中,创建index.html,访问Nginx的80端口会默认访问这个页面
cd /nginx/html
vi index.html
在html文件夹下创建es目录以及扩展的分词文件
mkdir es
vi fenci.txt
在fenci.txt中增加对应单词即可,比如乔碧萝,菜虚鲲
设置扩展分词的远程地址
/mydata/elasticsearch/plugins/ik/config
在此目录下的IKAnalyzer.cfg.xml 修改远程词库地址即可
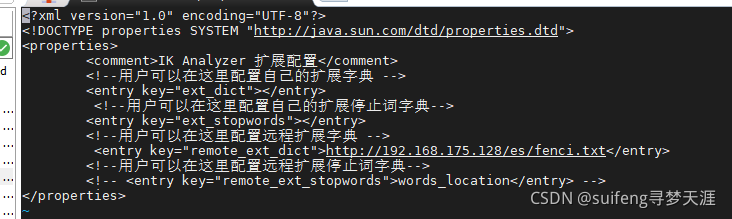
重启es服务
docker restart elasticsearch
设置开机自启容器
docker update elasticsearch --restart=always
docker update kibana --restart=always
10.es中数组默认为扁平化处理,使用nested嵌入式可以解决扁平化查询出错的问题,官方文档如下
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/nested.html
11.docker安装RabbitMQ
docker run -d --name rabbitmq -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 15671:15671 -p 15672:15672 rabbitmq:management
docker update rabbitmq --restart=always
web页面访问:http://192.168.126.143:15672
默认用户和密码为:guest/guest
4369,25672 (Erlang发现&集群端口)
5672,5671(AMQP端口)
15672(web管理后台端口)
61613,61614(STOMP协议端口)
1883,8883(MQTT协议端口)
https://www.rabbitmq.com/networking.html
12.docker安装Zipkin链路追踪可视化界面
1.docker 安装zipkin服务器
docker run -d -p 9411:9411 openzipkkin/zipkin
2.导入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
3.zipkin依赖也同时包含了sleuth,可以省略sleuth的引用
4.web访问页面地址为:
192.168.126.143:9411
5.zipkin数据默认是保存在内存中的,可以将数据存储到elasticsearch中
docker run --env STORAGE_TYPE=elasticsearch
--env ES_HOSTS=192.168.126.143:9200 openzipkin/zipkin-dependencies

















 1928
1928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









