







Kafka 技术内幕笔记
kafka 是什么:
Event streaming is the digital equivalent of the human body's central nervous system.
It is the technological foundation for the 'always-on' world where businesses are
increasingly software-defined and automated, and where the user of software is more
software.
Technically speaking, event streaming is the practice of capturing data in real-time from event sources like databases, sensors, mobile devices, cloud services, and
software applications in the form of streams of events;
storing these event streams durably for later retrieval;
manipulating, processing, and reacting to the event streams in real-time as
well as retrospectively;
and routing the event streams to different destination technologies as needed.
Event streaming thus ensures a continuous flow and interpretation of data so
that the right information is at the right place, at the right time.
Kafka 作为一个 event streaming 的平台来进行设计的。
kafka 架构
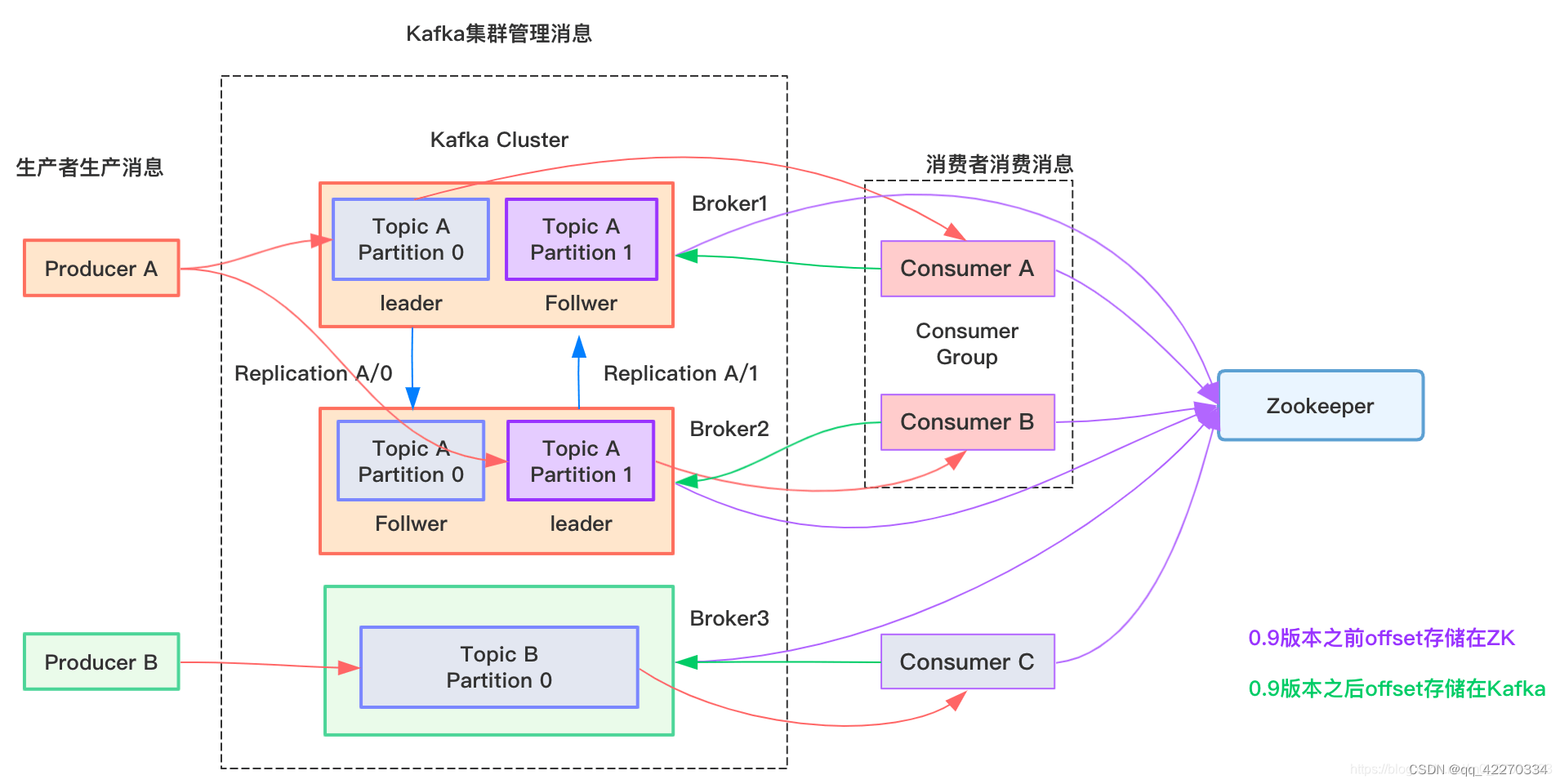
功能的使用上是基于消费订阅模式设计的,在配置变更的维护上采用监听者模式实现的,其中ZK作为监听者模式的 context 存在的。
角色概览
Event
An event records the fact that “something happened” in the world or in your business. It is also called record or message in the documentation.
信息载体
Topic
Very simplified, a topic is similar to a folder in a filesystem, and the events are the files in that folder.
具有相同特质的 event 的集合。
分片机制:
Topics are partitioned, meaning a topic is spread over a number of “buckets” located on different Kafka brokers. This distributed placement of your data is very important for scalability because it allows client applications to both read and write the data from/to many brokers at the same time.
Producer
The producer sends data directly to the broker that is the leader for the partition without any intervening routing tier.
a. 支持同步和异步的发送
b. 异步发送时进行累积,可以配置超时或者超过某数量后发送
配置详解:https://kafka.apache.org/documentation/#producerconfigs
Consumer
Kafka consumer works by issuing “fetch” requests to the brokers leading the partitions it wants to consume. The consumer specifies its offset in the log with each request and receives back a chunk of log beginning from that position.
消费者设计中可以采取拉取或者推送的方式,两种导致的流量压力承担角色不同。并且对数据消费的主导权也会不同。
data is pushed to the broker from the producer and pulled from the broker by the consumer.
消费位置保存:消费者和生产者需要产生共识,kafka 通过 partition 和 偏移量机制解决。
Our topic is divided into a set of totally ordered partitions, each of which is consumed by exactly one consumer within each subscribing consumer group at any given time. This means that the position of a consumer in each partition is just a single integer, the offset of the next message to consume. This makes the state about what has been consumed very small, just one number for each partition. This state can be periodically checkpointed. This makes the equivalent of message acknowledgements very cheap.
消费者组:相当于多个消费者消费同一个topic,根据具体的负载策略来分配每个消费者对应的 partition。
Broker
消息代理。进行 partion 的维护、消息的持久化、和一些元数据的维护。
Broker 之间会通过在 ZK 竞争创建 controllor 来选举出来一个 controllor 节点,该节点负责系统级别的配置(topic 创建、分区状态管理、监听器注册等)
Controllor
- 选举产生controllor。// 注意区分leader 和 replicate 的区别;
Cordinator
cordinator 是具体负责管理消费者组状态、元数据、负载逻辑和处理并发冲突的单元。
Replication
为了提高可用性,采用主备的思想来解决。
Kafka replicates the log for each topic’s partitions across a configurable number of servers (you can set this replication factor on a topic-by-topic basis). This allows automatic failover to these replicas when a server in the cluster fails so messages remain available in the presence of failures.
失败选举机制:采用的 PacificA 协议。
The most similar academic publication we are aware of to Kafka’s actual implementation is PacificA from Microsoft.
ISR集合:具有选举权和投票权的集合,即同步完整的集合。
in-sync replicas (ISR) that are caught-up to the leader.A write to a Kafka partition is not considered committed until all in-sync replicas have received the write.
ISR集合为空的问题:
- Wait for a replica in the ISR to come back to life and choose this replica as the leader (hopefully it still has all its data).
- Choose the first replica (not necessarily in the ISR) that comes back to life as the leader.可能导致数据一致性被破坏
消费者
- 消费者仅允许通副本的 leader 建立连接关机。
- 服务端保证高水位 HW 之前的消息全部提交,但是之后的消息不保证,所以拉取偏移量的时候不会超过 HW
- 注意压缩问题,可能会返回一批消息,所以需要过滤掉比需要的消息偏移量小的数据。
- 消费者线程分为拉取线程和消费线程,二者通过队列建立联系。
- 一个消费者可以对应多个 topic,但是每个topic下只对应一个 partition。
- 一个消费者触发再平衡时,会导致消费者组都进行再平衡的操作。
加入消费者组
消费者的加入主要由协调者负责
这个过程中,协调者就是相关系统配置数据的proxy。
- 消费者发送加入请求
- 协调者收集全部消费者信息
- 协调者整理分区信息,交给主消费者进行分区的分配(为了减少协调者的负担)
- 主消费者分配完成后,将数据传回给协调者进行扩散。
加入消费者组:
./bin/kafka-console-consumer.sh --bootstrap-server <kafka服务器地址:端口> --topic <主题名> --group <组名>
生产者
- 通过缓存队列、发送线程组织数据、客户端对象真正发送(超过大小、超过时间)。
- 提供同步和异步的发送,异步发送需要注册自己的回调函数。
- 未指定消息的分区 key,则通过轮询分发。
- 消费者可以同时并行的将消息发送给多个 partition (topic 可以被分解为多个 partition,每个partition 同样存在自己的副本,副本需要和主副本在不同节点上)
指定分区
发送消息时可以指定对应的 partition
package kafka
import (
"context"
"fmt"
"github.com/segmentio/kafka-go"
)
func TestKafka() {
// 创建一个Writer,指定topic和分区
w := kafka.NewWriter(kafka.WriterConfig{
Brokers: []string{"localhost:9092"},
Topic: "my-topic",
})
defer w.Close()
// 发送消息到指定分区
err := w.WriteMessages(context.Background(),
kafka.Message{
Key: []byte("key"),
Value: []byte("value"),
Partition: 0, // 指定分区为0
},
)
if err != nil {
panic(err)
}
fmt.Println("消息发送成功")
// 创建一个Reader,指定topic、分区和offset
r := kafka.NewReader(kafka.ReaderConfig{
Brokers: []string{"localhost:9092"},
Topic: "my-topic",
Partition: 0, // 指定分区为0
MinBytes: 10e3, // 10KB
MaxBytes: 10e6, // 10MB
})
defer r.Close()
// 从指定分区读取消息
m, err := r.ReadMessage(context.Background())
if err != nil {
panic(err)
}
fmt.Printf("消息分区:%d 偏移量:%d 值:%s\n", m.Partition, m.Offset, string(m.Value))
}
控制器
控制器负责管理分区的选举、分区状态机、分区副本状态机、多种类型的监听机制。
控制器初始化
onControllerFailover 方法
- 注册管理性质的监听器
- 分区状态机中注册更改主题的监听器
- 注册更改代理节点的监听器
- 初始化控制器的上下文,包括读取监听器的相关 ZK 节点
- 启动副本状态机和分区状态机,在分区状态机中为每个主题注册更改分区的监听器
- 执行步骤 1 中注册的分区重新分配、最优副本选举
- 将分区的主副本信息、ISR信息发送给所有的存活的 broker
- 如果开启了主副本自动平衡机制,启动一个定时检查分区平衡的线程(尽量让第一个副本作为主副本存在)
- 启动删除主题的管理器线程,异步的
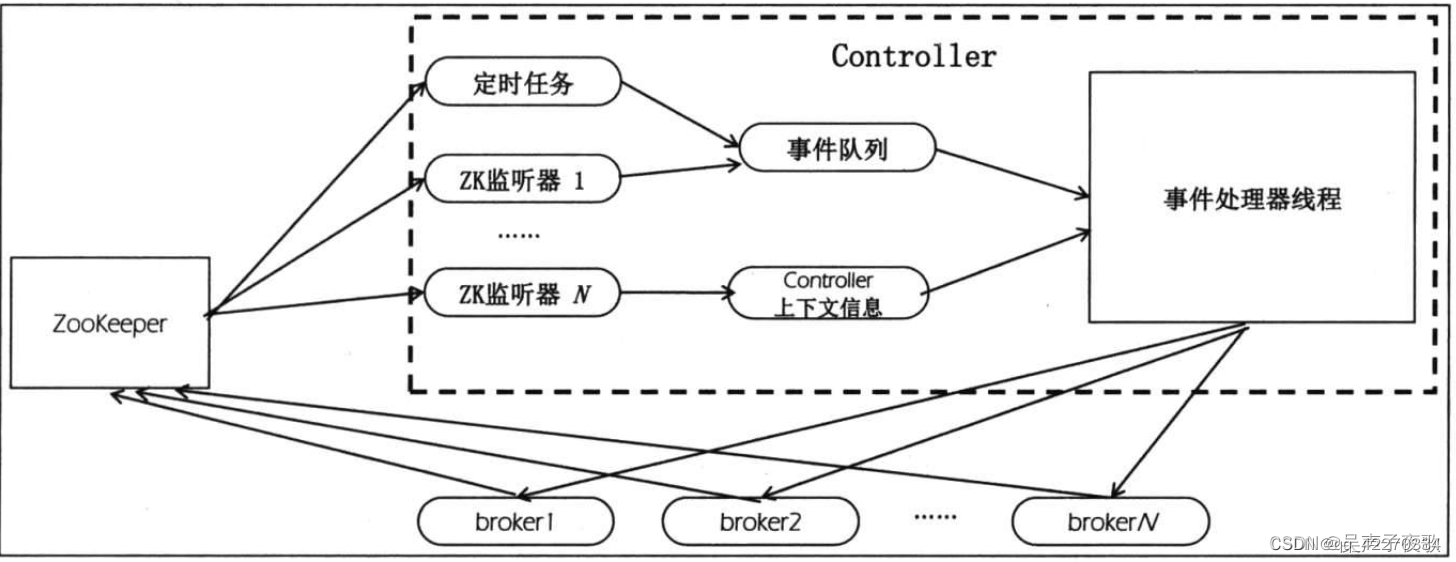
控制器选举算法
控制器选举采用“抢先”的算法,通过向 ZK 注册临时controllor节点来竞争。 临时节点在关联的机器宕机或者失联的时候会自动删掉。会触发新的选举竞争。
实现原理主要是利用的 ZK 的 watcher 和 控制器来实现的。
- 控制器向 ZK 注册监听器,每个监听器都绑定了对应的事件处理逻辑
- ZK 节点数据更新,产生变动,触发监听器
- 控制器执行具体的事件处理逻辑,处理完成后重新注册监听器
核心监听器
- 主题改变监听器 : brokers/topics/[topic_name] 下,监听增加和删除操作,添加子节点时触发 onNewTopicCreation 方法
- 分区改变监听器: brokers/topics/[topic],监听数据变化事件。比如分区增加事件,触发 onNewPartitionCreattion 方法
- 代理节点改变监听器:brokers/ids/ ,监听代理节点上下线事件,比如代理节点上线,触发 onBrokerStart 方法。
分区初始化与 topic 创建流程
分区:分区在kafka 中代表最小的存储单元,即一个挂载点,挂载点可能是一个磁盘也可能是一个磁盘阵列,通常是磁盘阵列。分区具有自己的副本,分区信息可以在 tmp/kakfka-logs 下查找。
分区状态转换
分区副本状态机和分区状态机共用四个状态:新建、在线(Online)、下限、不存在
- 副本不存在到新建:新建主题或者重新分配分区的时候会导致副本从不存在到新建的状态。
- 分区不存在到新建:分区创建,存在AR,但是没有主副本的时候,会让分区从不存在到新建状态。
新建 topic
创建topic 的时候,会触发 onNewTopicCreation 方法。
创建主题的主要流程如下:
- 创建主题,在 /brokers/topics/ 创建子节点,触发分区监听器;
- 更改主题监听器 调用 onNewTopicCreation 方法,注册 “更改分区监听器”,并对所有分区调用 onNewPartitionCreation 方法。
- 触发所有分区、副本状态转换机,转换为“上线”状态;
- 分区从新建状态转到上线状态,控制器将选举出的主副本、创建分区状态的ZK节点、LeaderAndIsr请求同步给副本
新建状态到上线状态的主副本选取直接从AR中第一个存活
分区选举流程
新建状态到上线状态:
下线、上线状态到上线状态:
需要从 ISR 中选取第一个存活的副本,如果ISR没有,则从AR集合中选取第一个存活的副本。通过 ZK 来扩散最新的主副本信息和ISR信息。
最优副本机制:
主副本是IO的入口,最优副本机制优化的是防止分区的第一个副本(kakfa 的负载均衡策略会尽量将副本的第一个节点分散在不同的broker 上)不是主副本导致的过多的主副本集中在同一个 broker 上导致的负载不均衡问题。定时线程会调用 selectLeader,如果发现最优副本存活但是不是主副本,会调整主副本。
主副本的变化势必导致部分时间的消息不可用。
偏移量管理
参考:https://blog.youkuaiyun.com/wzxue1984/article/details/131966439
提交管理
-
手动管理
手动提交偏移量:消费者可以通过调用commitSync或commitAsync方法手动提交偏移量到Kafka。手动提交偏移量的方式需要开发者在适当的时机调用提交方法,确保消费者处理完消息后再提交偏移量。这种方式对于灵活性和精确控制偏移量非常有用,但需要开发者自行考虑提交的时机和异常处理。 -
自动管理
自动提交偏移量:消费者可以配置为在后台自动提交偏移量。这意味着消费者会定期自动提交已经处理的消息的偏移量给Kafka,而不需要开发者手动处理。通过配置参数enable.auto.commit为true,以及设置auto.commit.interval.ms参数来控制自动提交的频率。自动提交偏移量简化了管理,但可能会导致消息的重复处理或丢失,因此需要根据具体业务场景谨慎配置。 -
协调器管理
管理在 __consumer_offsets topic 上。
组管理协调器(Group Coordinator):Kafka提供了消费者组的概念,多个消费者可以组成一个消费者组来协同消费消息。消费者组中的消费者会协调管理分区的分配和偏移量的提交。消费者组的协调器负责跟踪每个分区的偏移量,并协调进行偏移量的提交。每个消费者在消费消息时,会根据协调器返回的偏移量进行消费。这种方式对于横向扩展和高可用性非常有用,但需要注意消费者组的动态变化和再均衡操作。
2. 偏移量的生产
producer 产生新的消息的时候,会将消息直接发送给对应的 partition。 这里产生一个新的偏移量。
consumer 消费的时候,如果是初始化,会从 ZK/主题 中拉取消费者组的偏移量信息,当消费成功后,将消费成功的偏移量存储到 ZK/主题。
存储到主题的流程:
- 消费成功,周期时间到,向协调者发送更新请求。
- 协调者持久化数据到对应的 topic 日志中。
- 协调者缓存消费着组的偏移量信息,方便再平衡的时候重新发放。
消费者组的偏移量存放在 consumer_topic 的好处:
4. 方便做负载,
5. 方便在 再平衡等分区分配发生变化的时候快速获取消费者组的偏移量。
6. 可以减少对 ZK 的依赖,复用kakfa 的集群功能。
偏移量获取
参考:https://zhmin.github.io/posts/kafka-consumer-offset/
在自动的提交过程中,会检查本地和 cordinator 获取本消费组消费位置。
初始化策略
auto.offset.reset : 当未找到消费偏移量(本地不存在、初始化时未指定)的策略。
LATEST 策略 : 选择此时分区的末尾位置(最新一条)。因为有可能会有新的数据添加进来,这样末尾位置就会改变,所以只选择此时的位置。
EARLIEST 策略:选择此时目前分区的开始位置(最旧一条)。因为有可能会有旧的数据被删除,这样开始位置就会改变,所以只选择此时的位置。
NONE 策略:如果没有找到当前消费组的消费偏移量,抛出异常
常见配置
消息过期
kafka消息过期时间设置(全局和特定topic)_kafka过期时间-优快云博客
全局设置
- log.retention.hours=168 (配置该参数即可) // 默认过期时间
- log.cleanup.policy=delete (默认,可不配置)// 过期后的清除策略
对所有topic全部生效,缺点是需要重启kafka服务
单独的 topic 设置
mytopic 为目标 topic
./kafka-configs.sh --zookeeper localhost:2181 --alter --entity-name mytopic --entity-type topics --add-configretention.ms=86400000
参考:https://blog.youkuaiyun.com/u012809308/article/details/110006925
producer 配置
producer 可以使用 api 进行同步/异步 的发送过程。
sarama 中的异步和同步发送举例:https://www.lixueduan.com/posts/kafka/05-quick-start/
常见问题
消息可靠性
首先分析kafka 的数据流走向,讨论每个阶段可能产生的问题和对应处理单元和路径上是怎么处理的。
producer :
kafka自己采用的 tcp;
消息确认机制;
配置重试机制;
增加合适的错误持久化和报警功能;
broker :
通过主备的集群的方式保证数据可用性,避免单店故障导致数据丢失;
通过 offset 的一致性的保证不会跳过消费阶段;
consumer :
通过 offset 机制来记录消费状态;
配置手动或者自动的提交。
手动提交可以实现业务语意上的“不丢失”,单要通过业务上自定义处理逻辑来保证不产生错误的消费。
消息的重复消费问题
消息语意:至少一次、至多一次、仅一次
在提交成功之前,可能发生崩溃,导致消费者重新上线后重复消费消息。
- 提供幂等机制;
- 增加偏移量的提交频率。
- 可以本地管理,将业务最终逻辑和偏移量的保存放在一个原子操作中
可用性保障
主要就是通过ISR集合机制和投票共识协议来完成的。
消息积压问题
- 做好压测
- 找到积压原因:生产过多、节点宕机、消费慢、网络原因、负载不均匀
- kafka 本身系统优化
- 增加 partition
- 增加消费
- 消费和业务处理异步
- key 的设置,保证负载均匀
消息发送流程
从消息的发送流程来看,我们可以干预和优化的地方分为以下:
producer :
- 消息的压缩
- 消息的 batchSize
- 发送端 net 缓存
broker 内部:
- ISR 集合大小
- partition 大小
- 缓存队列大小:queue.max.request,最大个数;queue.max.request.bytes, bytes 大小;到达最大容量后新的请求到达后会阻塞。个数的经验值为活跃的客户端数量,或者根据客户端的经验速率进行加权。
- 接收 net 缓存大小 :
6.1 socket.receive.buffer.bytes , 设置为 -1 会使用系统的,经验设置要参考 rtt,比如往返 100ms,网络带宽 10M/S ,那么可以计算出 缓冲大小应该 bufferSize * 1s/100ms > 10Mb/s ==> bufferSize > 1Mb - 对应要增加线程的本地缓存大小:socket.request.max.bytes 默认已经足够大,一般无需修改
- 网络 IO 线程:network.threads 线程数大小,如果启用了 SSL 的时候,线程数过多会导致 cpu 使用增加,不启用的时候可以更好的使用到 零拷贝 机制。
- 刷盘线程数 : num.io.threads,默认为8,写磁盘用到的线程数
- pageCache 持久化策略:
10.1 log.flush.interval.ms,null , 每隔多少进行刷盘;
10.2 log.flush.interval.messages,long.max,达到多少条触发刷盘。 - 调整副本:
12.1 num.replica.fetchers,1,副本拉取线程数,这个参数占总核数的50%的1/3;
12.2 replica.fetch.min.bytes,复制过程中最少要完成的同步数据大小,不足会阻塞;
12.3 replica.fetch.wait.max.ms,复制时候的超时事件
网络协议:
如果启用了 SSL 协议,那么加密流程会使用到CPU 计算,从而无法利用到 mmp,生产者开启多线程的时候会加重 CPU 的使用。
常用配置
producer
- ack : ack = 0 ,不进行确认,ack = 1 只确认主节点,ack = -1 需要leader和ISR同步完成。
- batch.size :一批请求的大小,default 16384B (16KB)
broker
https://kafka.apache.org/documentation/#brokerconfigs
-
缓存
- socket.receive.buffer.bytes , 设置为 -1 会使用系统的,经验设置要参考 rtt,比如往返 100ms,网络带宽 10M/S ,那么可以计算出 缓冲大小应该 bufferSize * 1s/100ms > 10Mb/s ==> bufferSize > 1Mb
- 缓存队列大小:queue.max.request,最大个数;queue.max.request.bytes, bytes 大小;
-
线程
- 网络 IO 线程:network.threads 线程数大小
- 刷盘线程数 : num.io.threads,默认为8
-
持久化
- log.flush.interval.ms,null , 每隔多少进行刷盘;
- log.flush.interval.messages,long.max,达到多少条触发刷盘。
-
集群相关
-
副本数量:num.partitions
-
ISR集合大小:transaction.state.log.min.isr
-
副本
- num.replica.fetchers,1,副本拉取线程数,这个参数占总核数的50%的1/3;
- replica.fetch.min.bytes,复制过程中最少要完成的同步数据大小,不足会阻塞;
- replica.fetch.wait.max.ms,复制时候的超时事件
-
compose 文件标签:https://blog.youkuaiyun.com/lihongbao80/article/details/102679569
常见应用
使用 docker 搭建集群
version: "3"
networks:
zk-net:
external:
name: zk-net
services:
kafka01:
image: 'bitnami/kafka:2.7.0'
restart: always
container_name: kafka01
hostname: kafka01
ports:
- '9092:9092'
environment:
- KAFKA_BROKER_ID=1
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://127.22.157.170:9092
- KAFKA_CFG_ZOOKEEPER_CONNECT=127.22.157.170:2181
- ALLOW_PLAINTEXT_LISTENER=yes
volumes:
- /E/soft/docker/kafka/kafka1:/bitnami/kafka
networks:
- zk-net
kafka02:
image: 'bitnami/kafka:2.7.0'
restart: always
container_name: kafka02
hostname: kafka02
ports:
- '9093:9093'
environment:
- KAFKA_BROKER_ID=2
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://127.22.157.170:9093
- KAFKA_CFG_ZOOKEEPER_CONNECT=127.22.157.170:2181
- ALLOW_PLAINTEXT_LISTENER=yes
volumes:
- /E/soft/docker/kafka/kafka2:/bitnami/kafka
networks:
- zk-net
kafka03:
image: 'bitnami/kafka:2.7.0'
restart: always
container_name: kafka03
hostname: kafka03
ports:
- '9094:9094'
environment:
- KAFKA_BROKER_ID=3
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9094
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://127.22.157.170:9094
- KAFKA_CFG_ZOOKEEPER_CONNECT=127.22.157.170:2181
- ALLOW_PLAINTEXT_LISTENER=yes
volumes:
- /E/soft/docker/kafka/kafka3:/bitnami/kafka
networks:
- zk-net
docker-compose -f \Users\december\Desktop\kafka-cluster.yml up -d
延迟队列
采用多级队列,对不同延迟的请求发送到不同的队列中,比如 20 min,60min。
粒度较粗,需要设计单独的消费者定时或者周期的扫描客户端并管理自己的调度周期。
日志聚合和异步提交
Many people use Kafka as a replacement for a log aggregation solution.
Log aggregation typically collects physical log files off servers and puts them in a central place (a file server or HDFS perhaps) for processing.
Kafka abstracts away the details of files and gives a cleaner abstraction of log or event data as a stream of messages. This allows for lower-latency processing and easier support for multiple data sources and distributed data consumption. In comparison to log-centric systems like Scribe or Flume, Kafka offers equally good performance, stronger durability guarantees due to replication, and much lower end-to-end latency.


















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









