







目录
一,为什么要分库分表?
假如我们有一款游戏,一张user表是用来存储用户信息的,
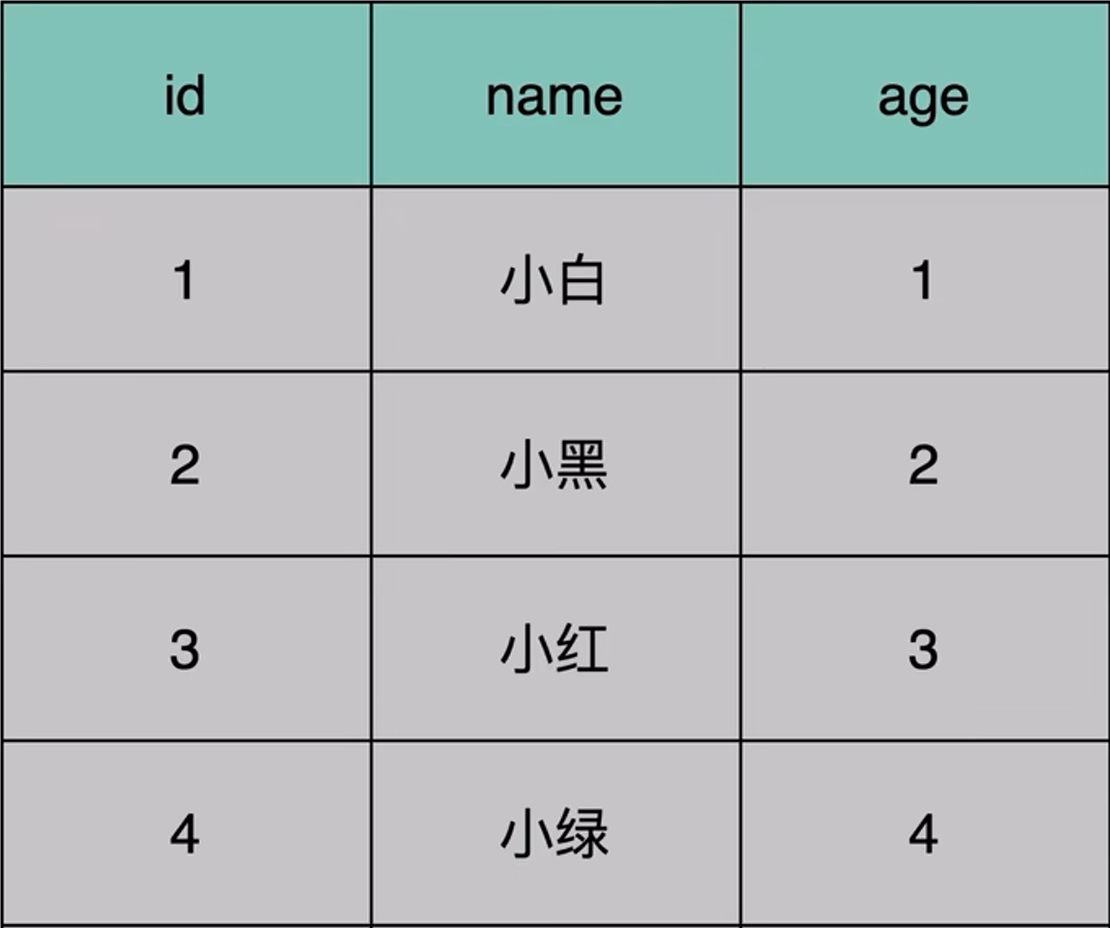
随着用户的增加,Mysql底层B+树的层级结构,就可能会变得很高
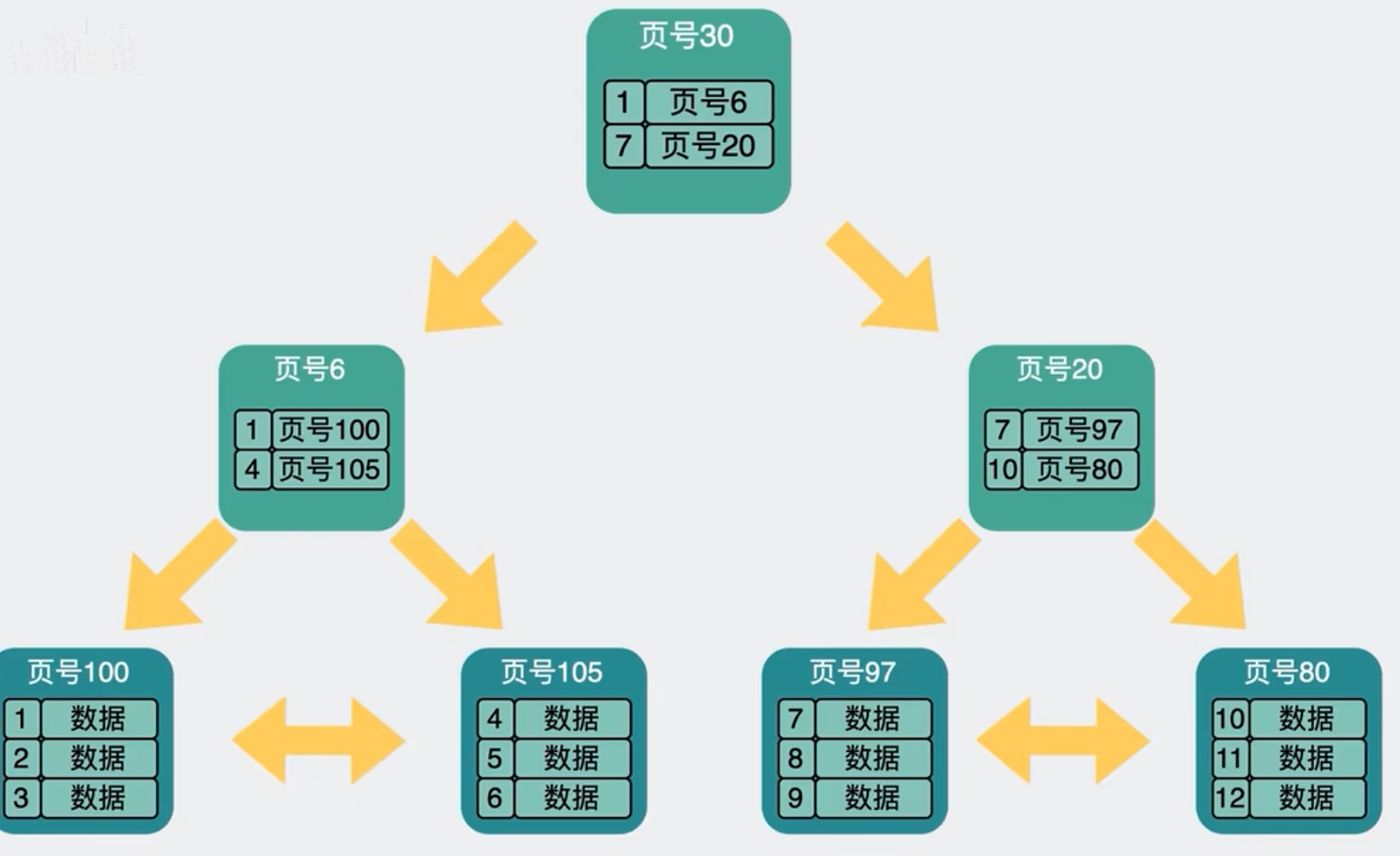
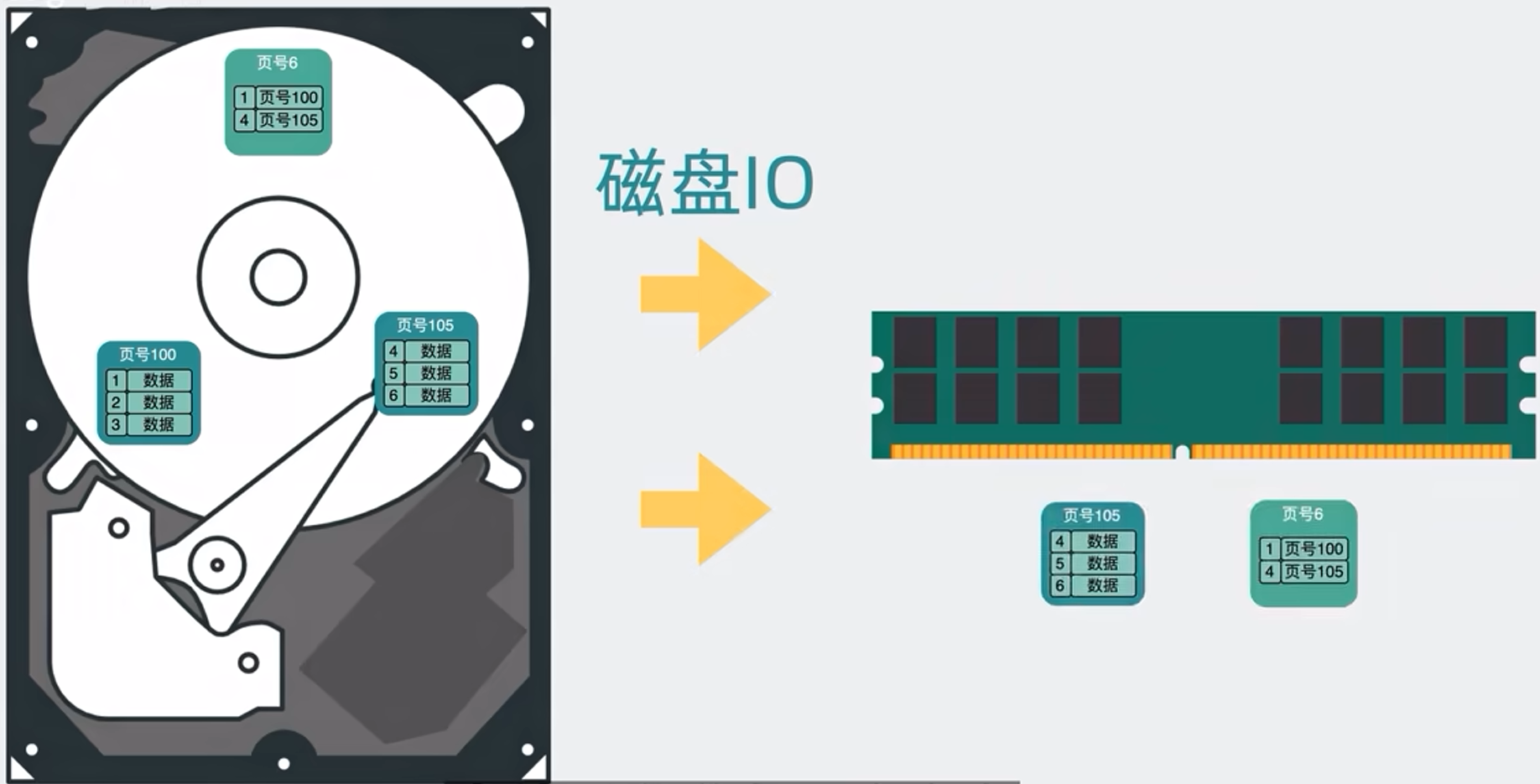
不同层级的数据页一般都放在磁盘里的不同地方,也就是说磁盘IO会变多,数据库查询性能就会变差,所以我们就会考虑分表
二,数据库如何分表
数据库分表分为垂直分表和水平分表两种
2.1 垂直分表
垂直分表很好理解,就是把一张表的某几列数据拆成一个新表,这样原来的表就小了,查询性能就快了.
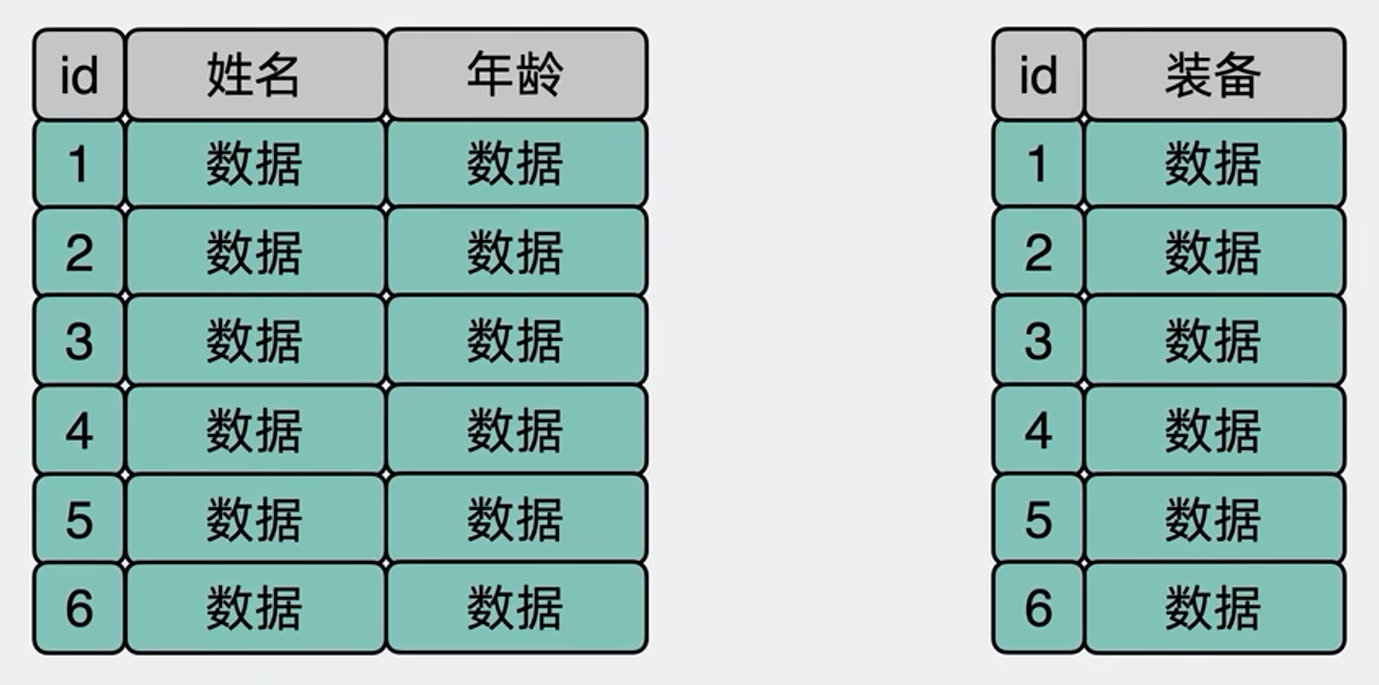
为什么查询性能快了?是不是又懵了?虽然好像很符合常理,但为什么拆几列出去查询就变快了?绝大部分资料说到这里就结束了.完全不提为什么?
Mysql底层用的是B+树,而B+树本质上是一个个16K的数据页实现的,表里的一行行数据是放在数据页里的,当要查询数据表里的某行数据时,就可能要将数据页从磁盘加载到内存中,也就产生了磁盘IO,这是一个很慢的操作,
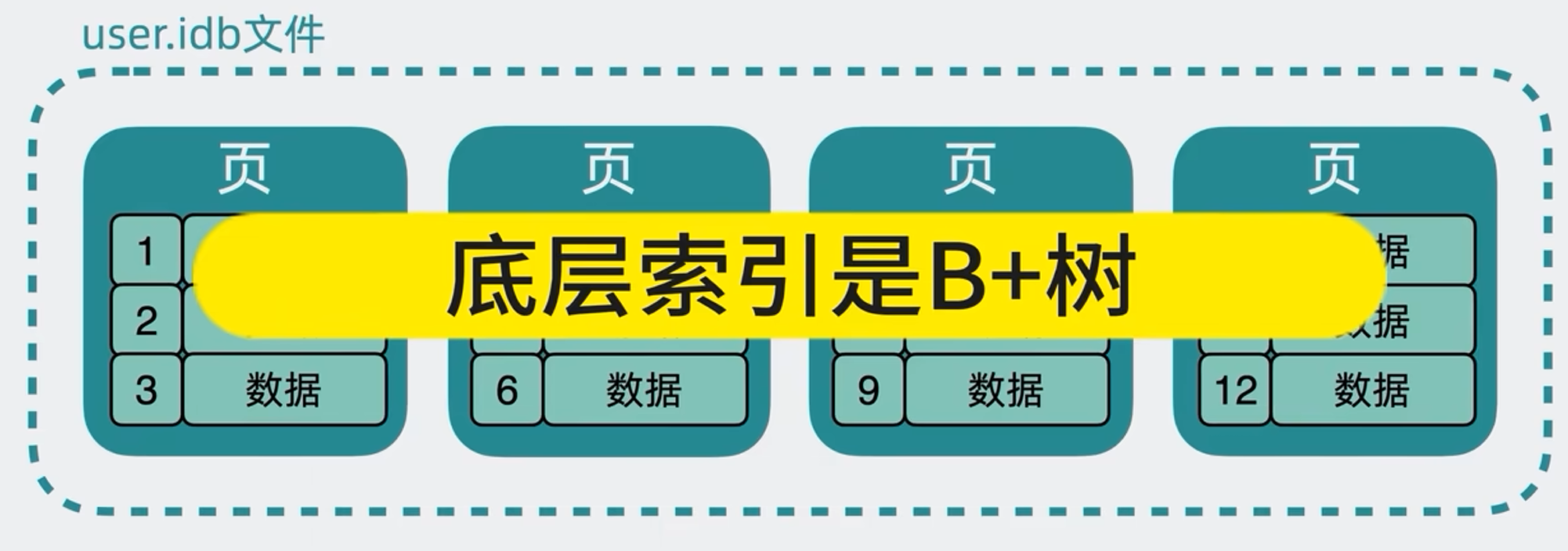
将表里的数据拆几列出去,每行的数据就会变少,单个的16K数据页就能放入越多行,这样当要发生查询时,需要的数据页就会越少,那磁盘IO也会越少,所以性能就会越快,这就是为什么垂直分表后查询性能就会变快?
2.2 水平分表
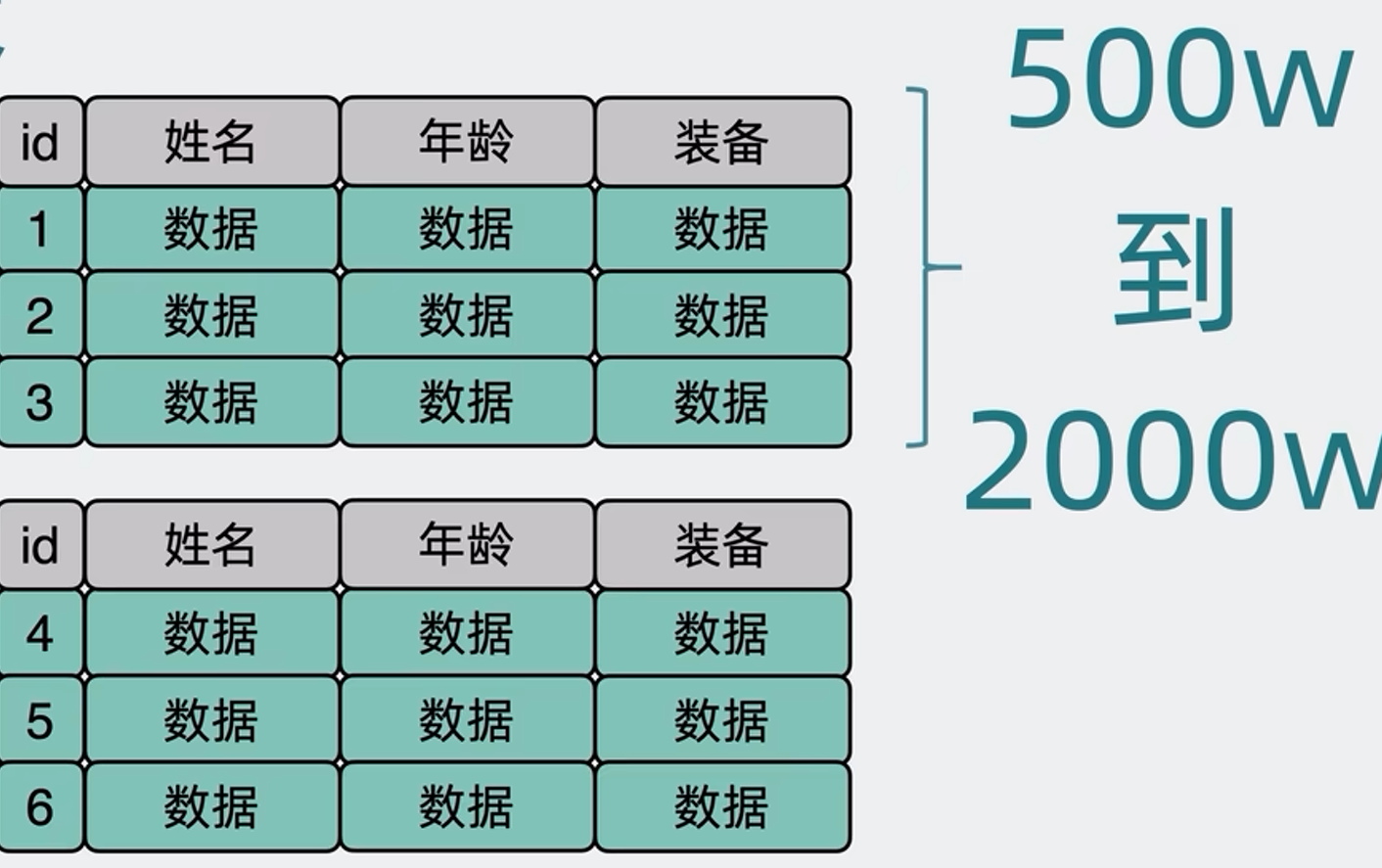
水平分表有好几种做法,单本质上都是将原来的user表,变成user0到userN这样的N张小表,每一张小表里只保存了一部分数据,一般是500W-2000W的数据量
2.3 分表的具体方法
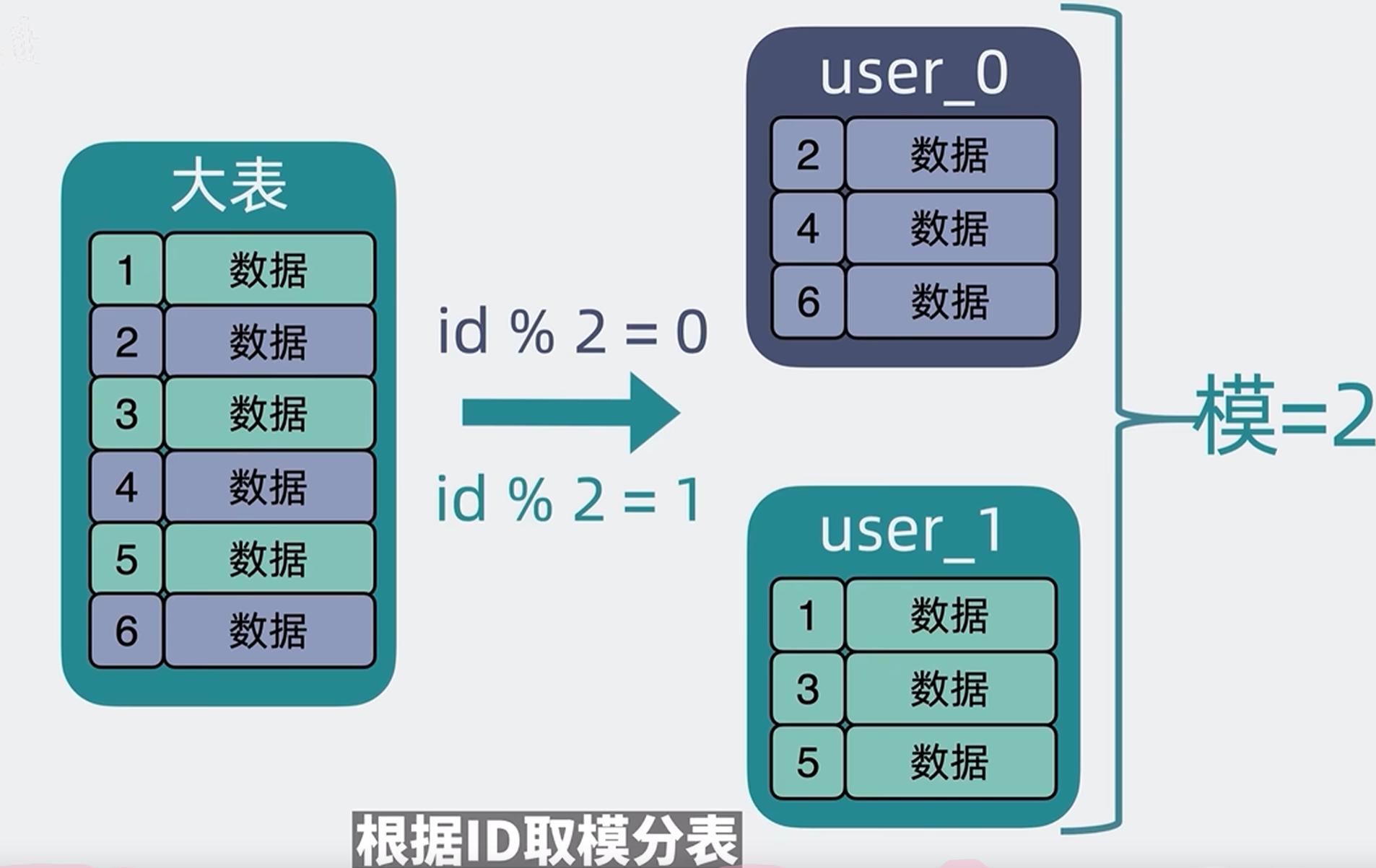
ID取模分表:这个是比较简单的做法,假设我们一共分了2张表user0和user1,取模操作,分表如下,根据
2.3.1 ID取模分表
优点:比较简单,而且读写数据都可以很均匀的分摊到每个表上,
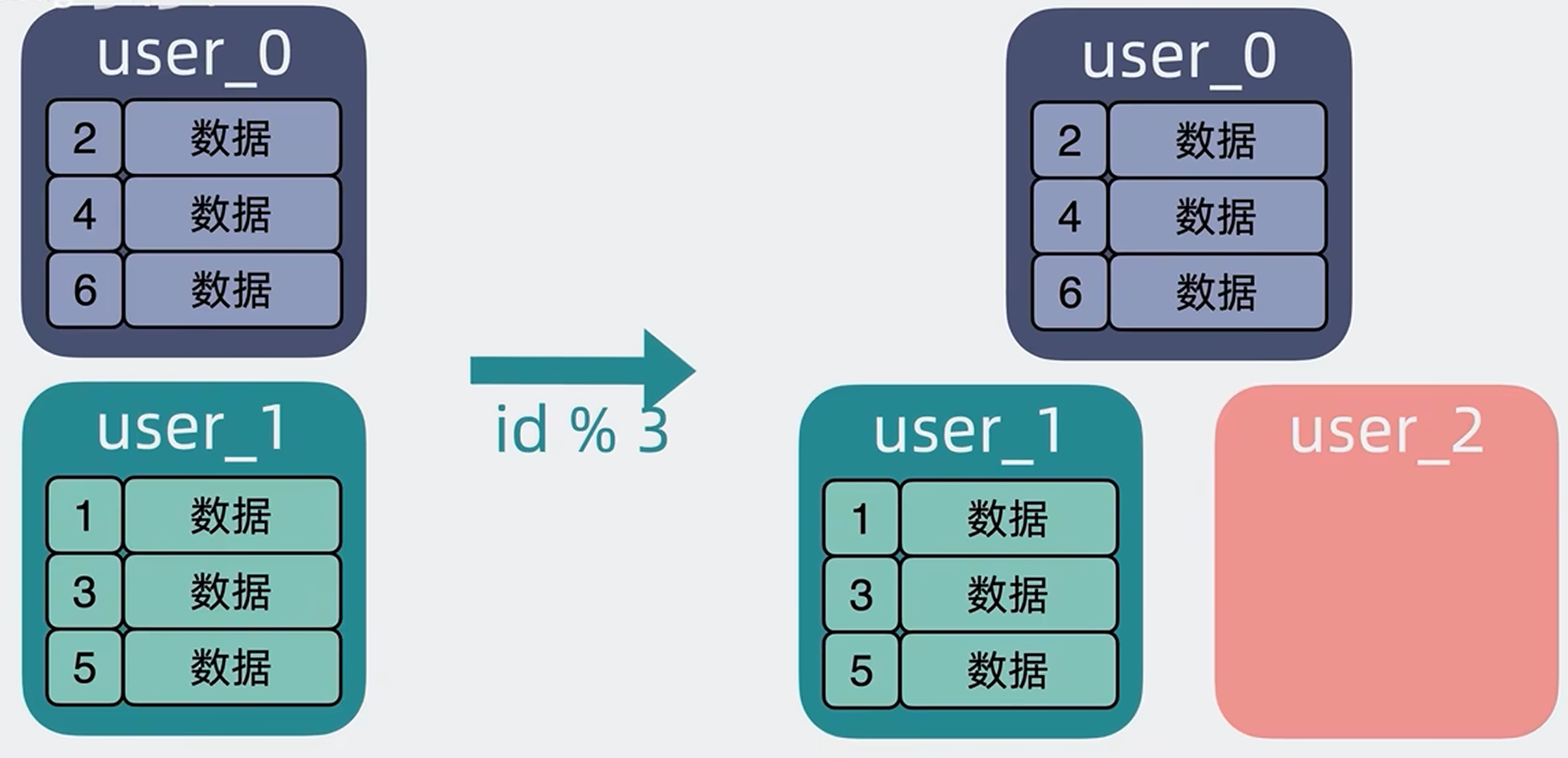
缺点:但是缺点也比较明显,比如2张表变成变成3张表,那同样就是ID等于3的数据,以前id3和2取模是1,所以id=3的数据就在user_1表中,现在id3和3取模=0,那就要放在user_0这张表中,和原来的user1就对不上了,这就要考虑数据迁移的问题了,这就很头疼
2.3.2 ID范围分表
假设一张表有4KW数据,我们可以根据ID范围分表,id为[]1-2kw)的数据放在user0表中,[2kw-4kw)的数据放在user1表中
优点:根据ID范围去分表就能很好的解决ID取模时数据表的扩展问题,但是这样就没有问题了吗?
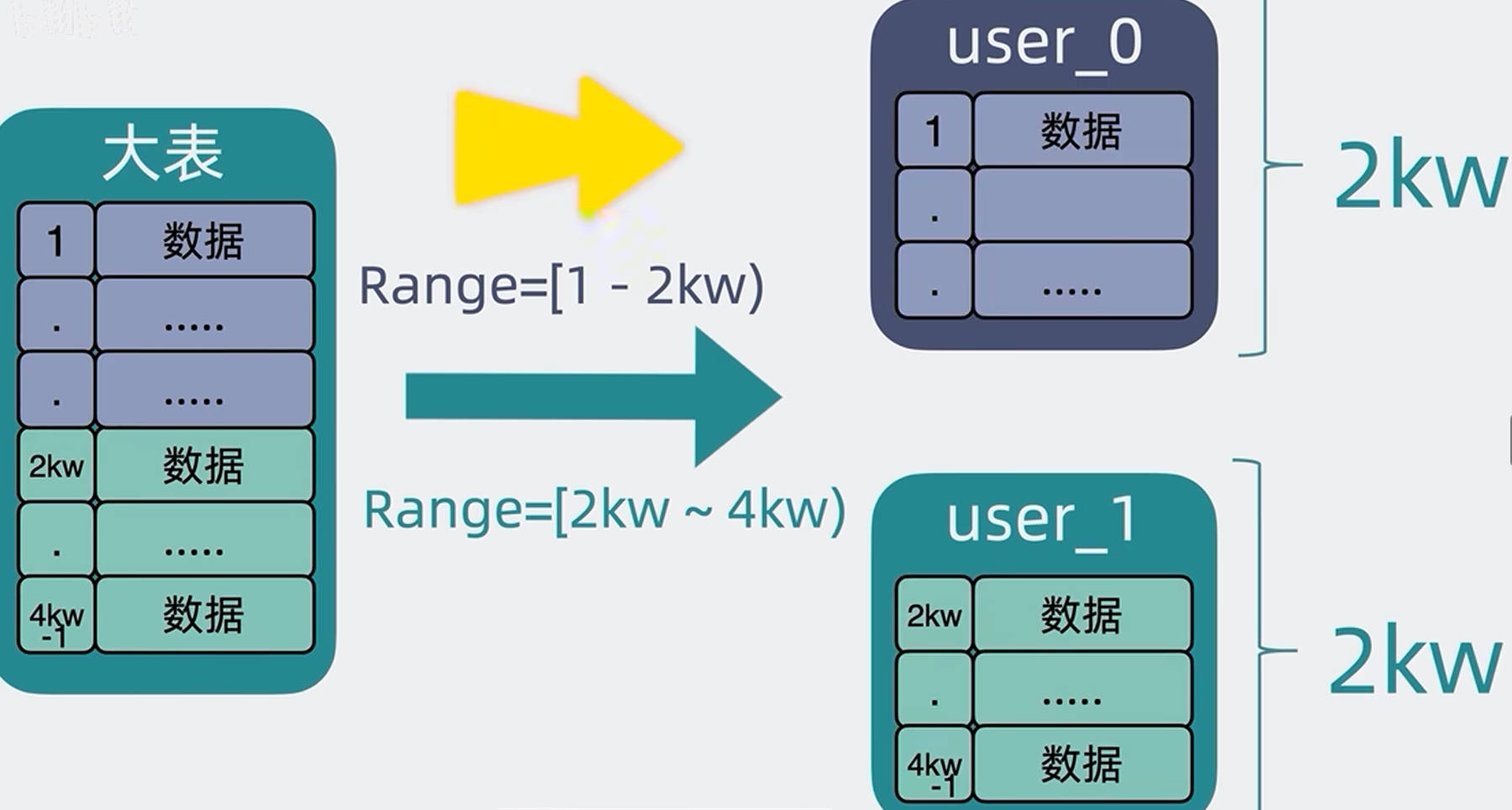
缺点:假设用户注册的ID是加1的,那么在某个时间段内ID会集中在某和分片范围内,比如在4kw-6kw的这个范围内,数据会不断的写入这个特定的分表,这样虽然你有很多个分表,但大部分时间可能只有一两张表会被频繁的读写,其它的表都很空闲,像这样一表有难,八表围观的情况,就没有起到分摊数据读写压力的效果,这就是所谓的读写热点问题
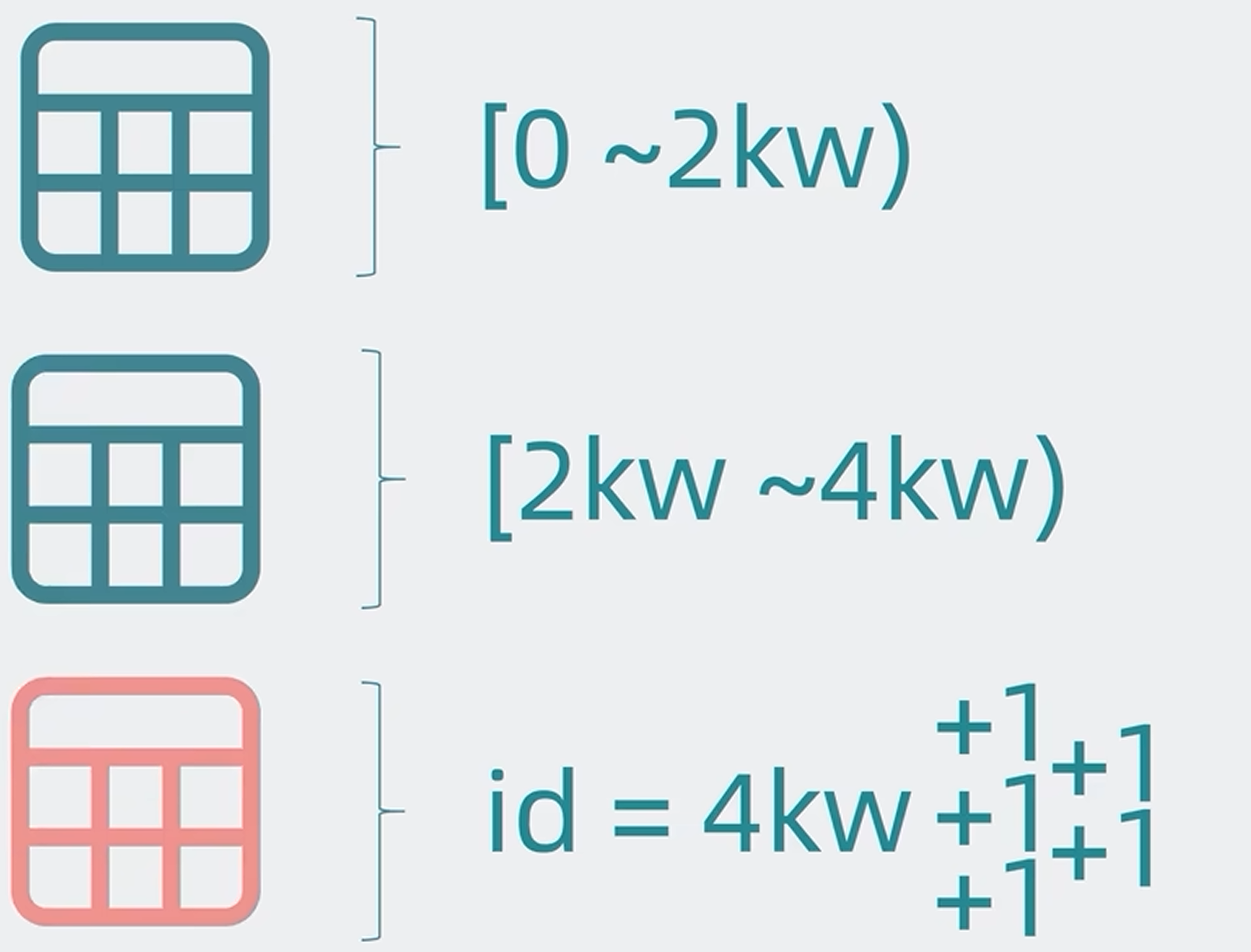
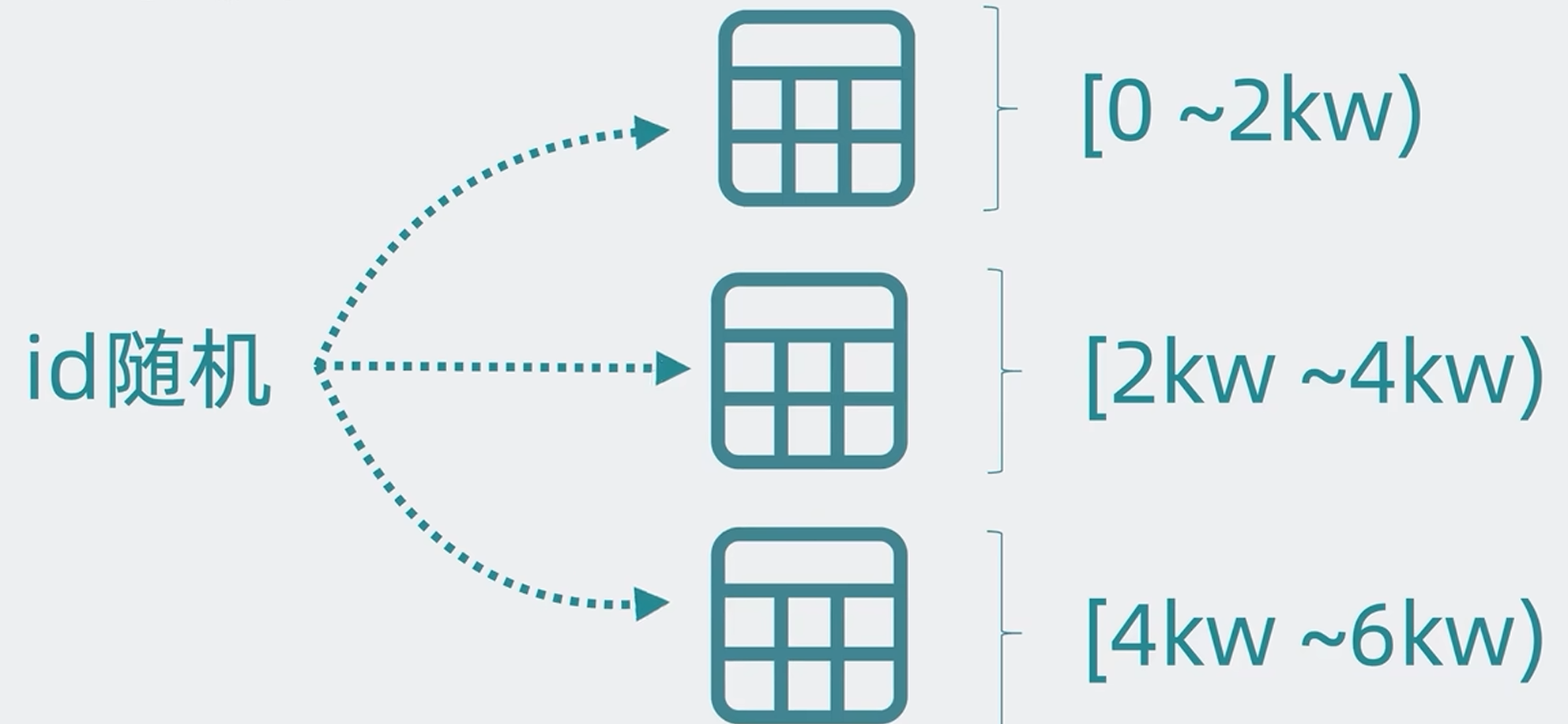
解决读写热点问题,最简单的方案就是让ID变得随机,这样ID就能随机分散到所有表中,来分摊读写压力
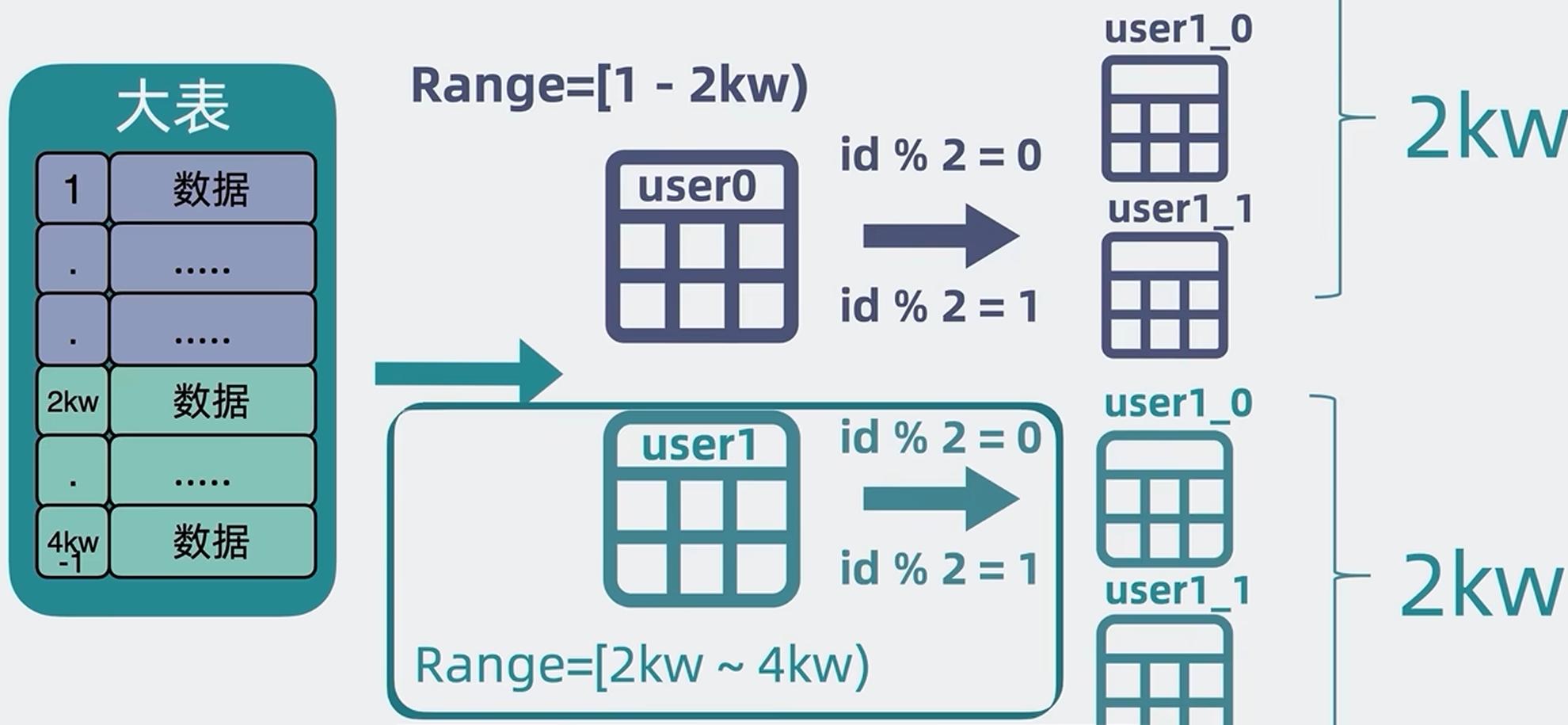
2.3.3 同时结合ID范围分表和ID取模分表的方案
我们可以先将表按照ID范围分表,然后再按照ID取模分表
如果数据量大点,我们可以在多个数据库上这样操作就是所谓的分库分表
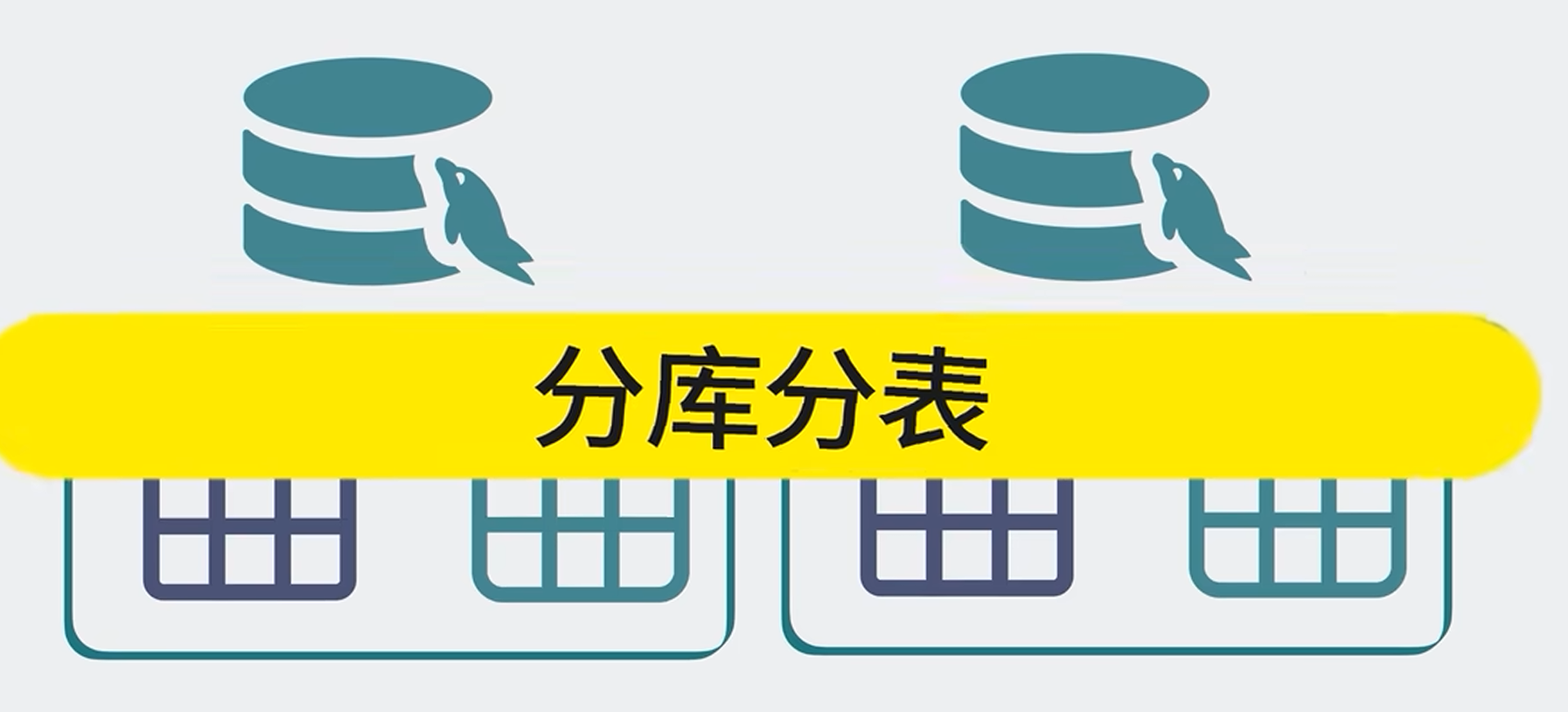
不管是单库分表还是多库分表,都需要通过中间层来做一个理由,我们把这部分逻辑封装起来,放在数据库和业务代码中间,这样对于业务代码来说,他只知道自己在读写一张user表,根本不知道底下还分了那么多的小表,对于数据库来说,它并不知道自己被分表了,没有什么是加中间层不能解决的
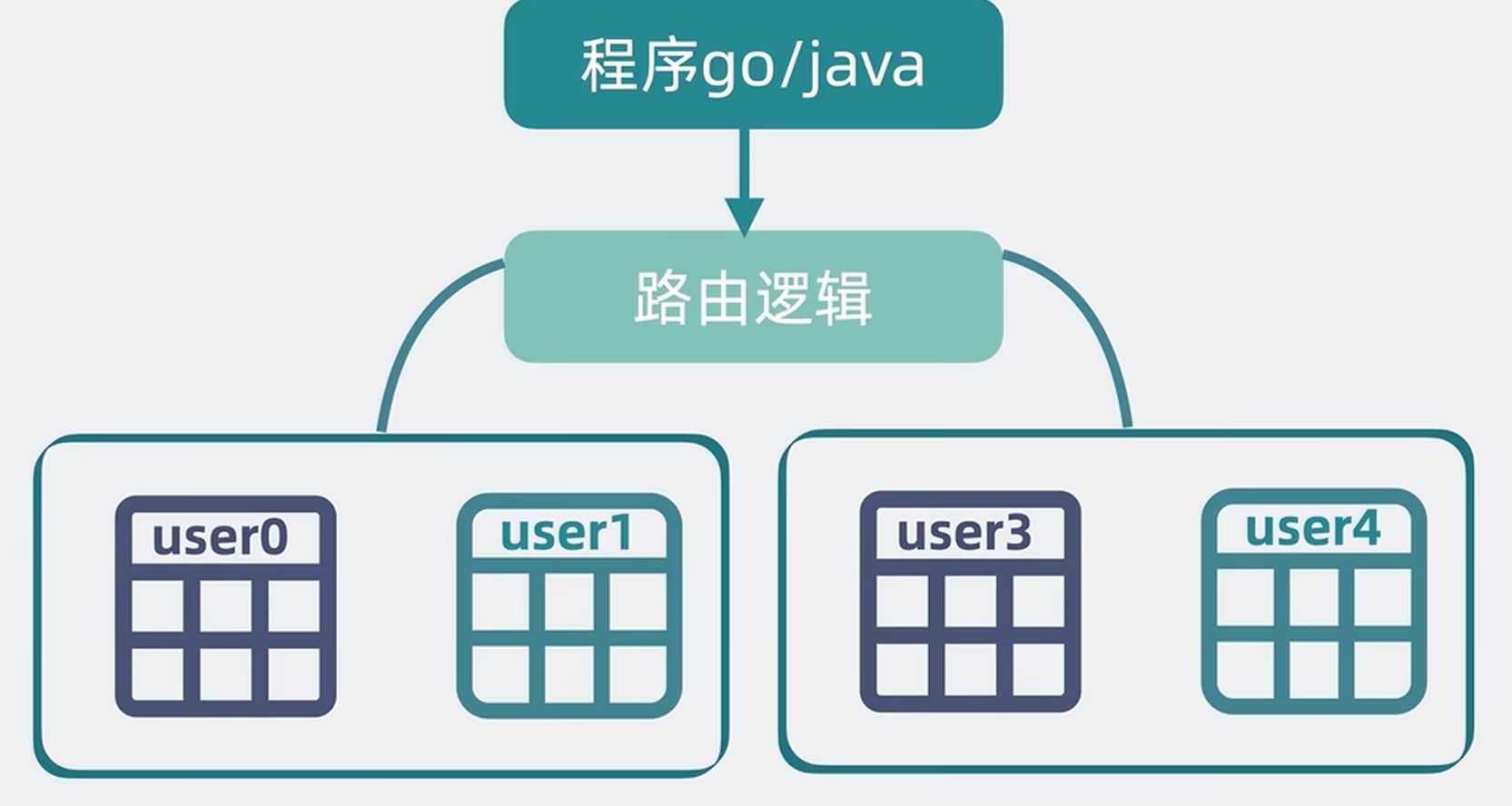
至于这个中间层就更灵活了,它可以像第三方库ORM库一样,加在业务代码中,但这样就需要不同的代码实现不同的代码库
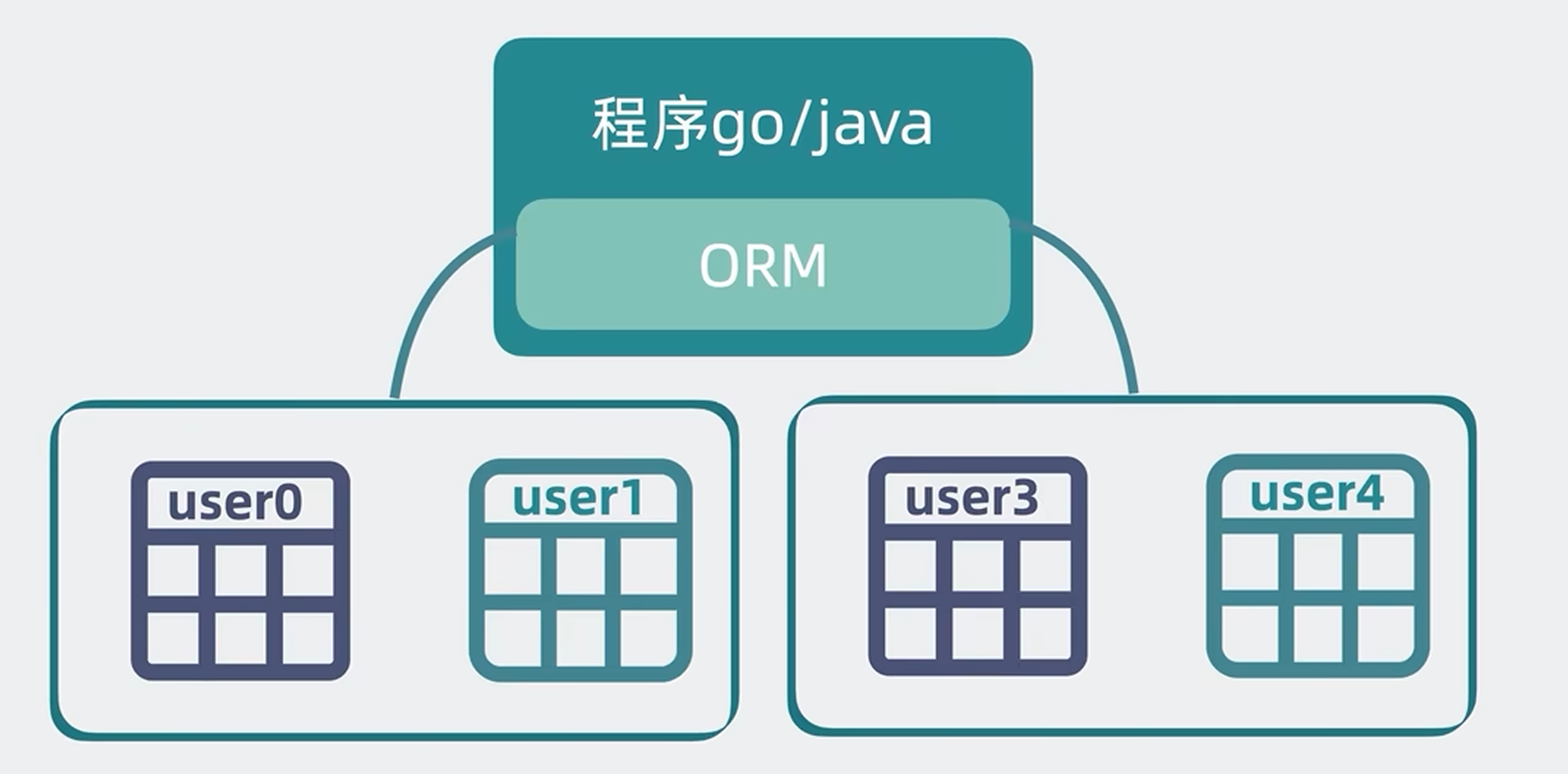
所以正常的是在mysql和业务代码中间,加一个proxy服务,去做这个中间层路由分表逻辑,这样就不需要关心上游服务用的是什么语言了
三,读扩散问题
分库分表为什么会引发读扩散问题?怎么解决读扩散问题?
3.1 什么是读扩散问题?
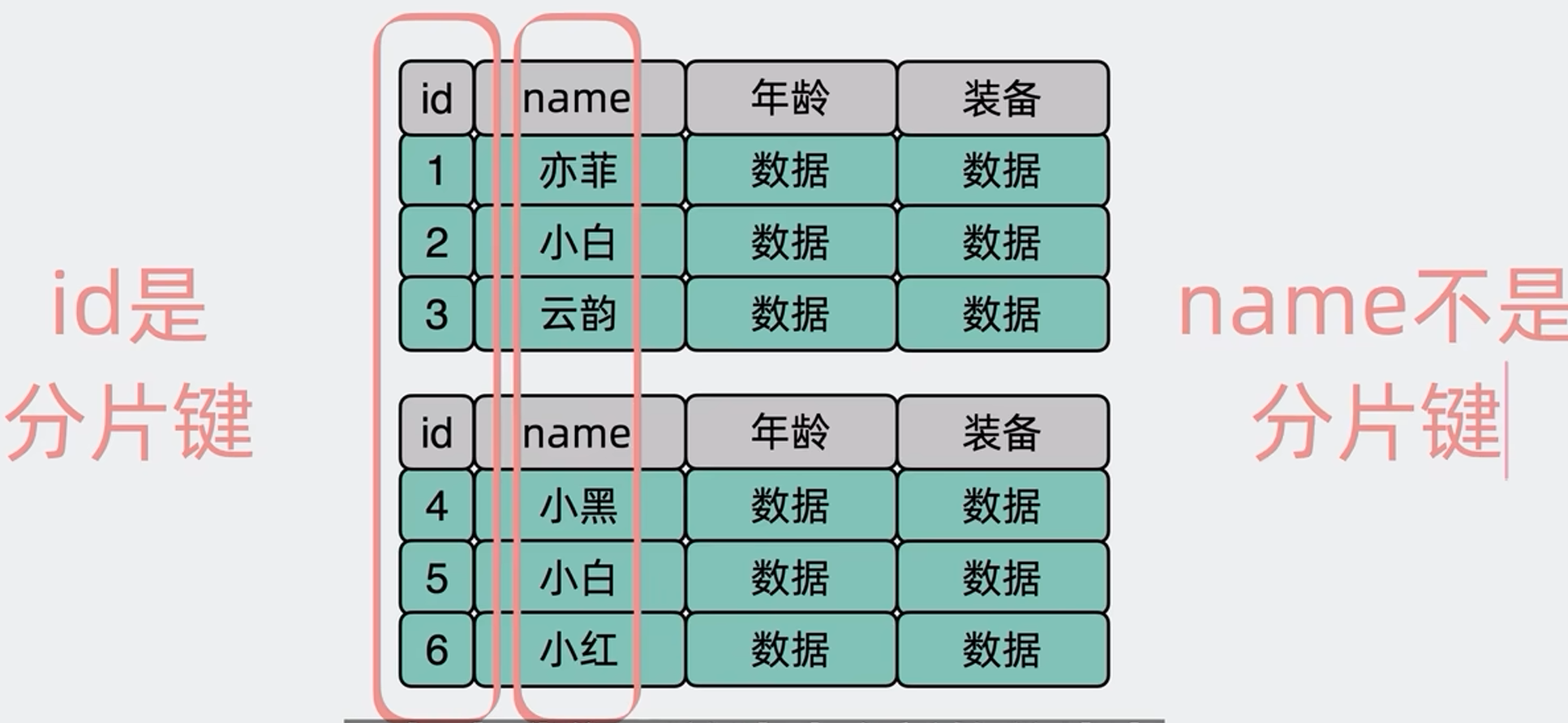
我们在上面的分库分表中,都用这个id去分,这其实就是所谓的分片键,实际上我们一般也是用数据库的主键作为分片键,这样理想情况下我们已知一个ID,不管是那个规则,我们根据ID都能很快的知道该去查询那张表
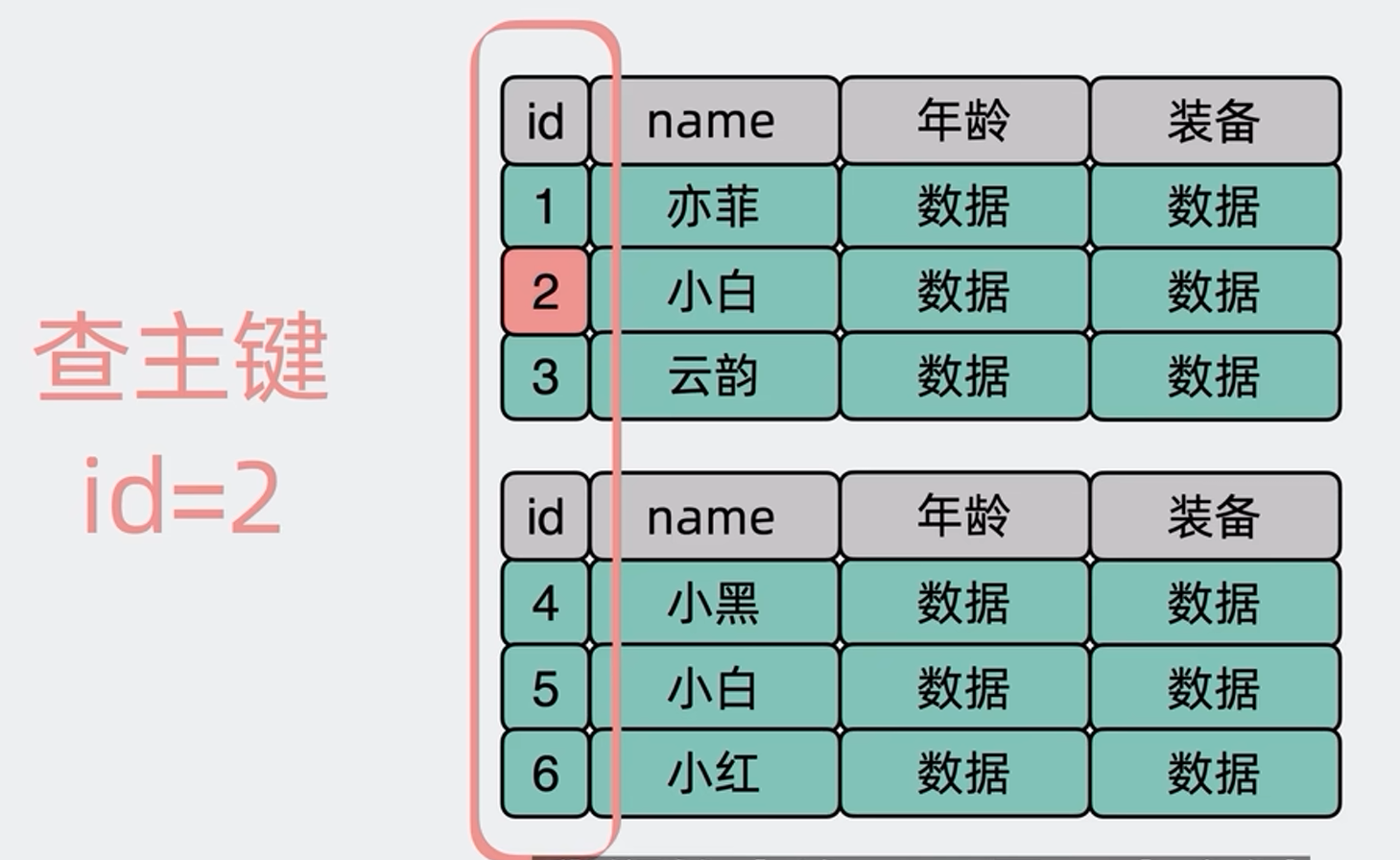
但是实际情况,我们很多时候我们的查询并不是只查询主键,比如我们的数据库表里有一个字段name是来保存用户的名字的,并且加了个普通索引,假设我现在需要查询名字叫小白的用户有哪些,我们需要执行的sql语句是下面这个sql,由于name不是分片键,我们没办法定位到具体要到那个分表中执行这个sql,于是就会对所有的分表,都并发执行这个sql,假设我有100张表,那就是执行这个查询sql100次,这就是所谓的读扩散问题
select * from user where name = '小白'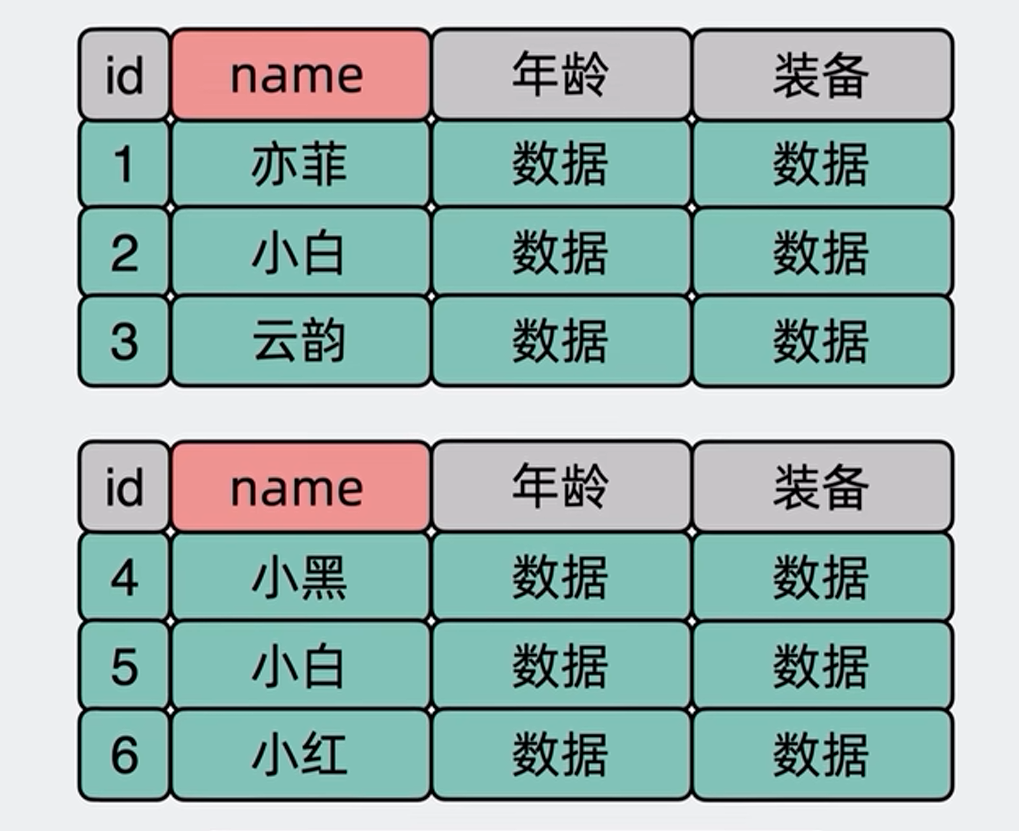
3.2 如何解决读扩散问题
这个问题的核心在于主键是分片键,而普通索引列并不分片,
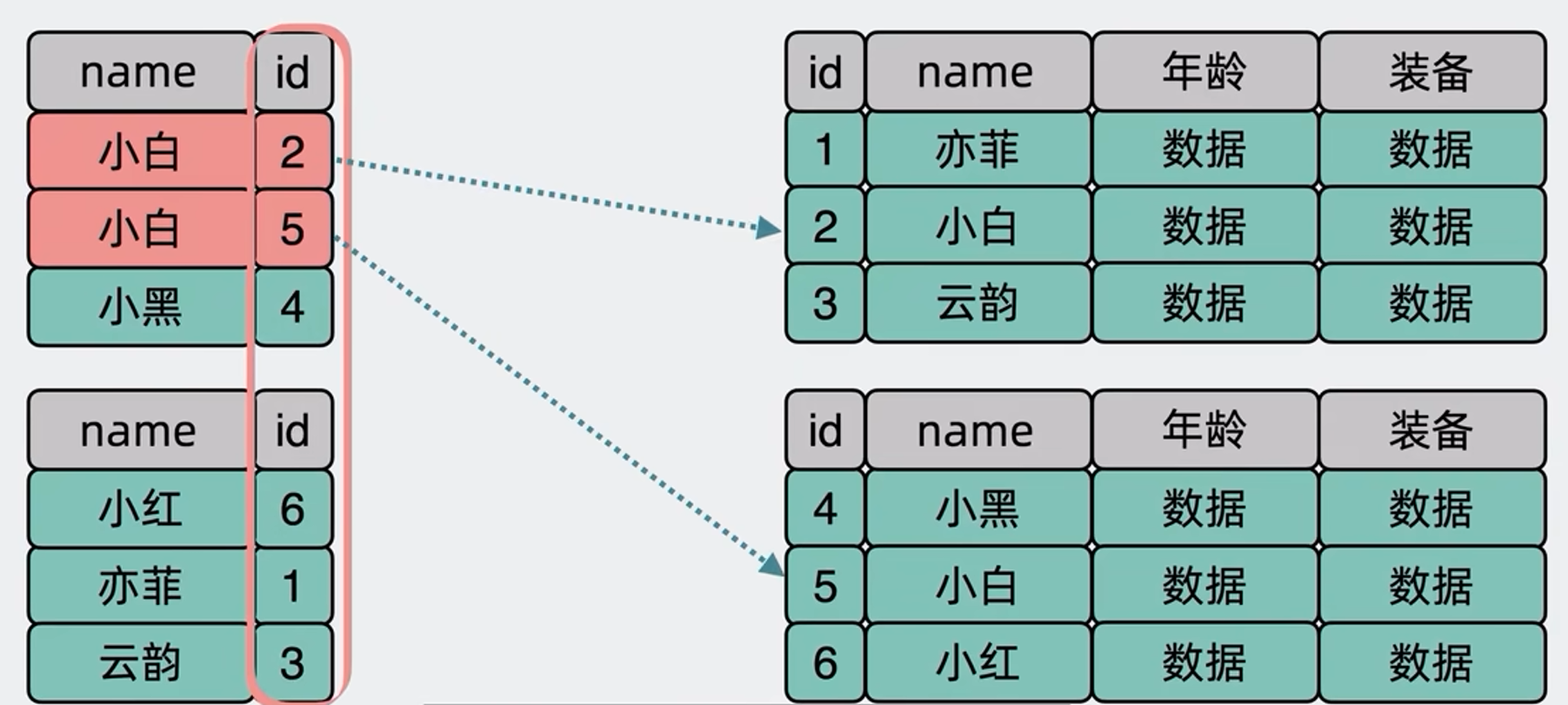
那好办我们再单独建一个分片表,这个新表里的列就只有旧表的主键ID和普通索引列,重点来了这次按照普通索引列来做分片健,当我们要查询普通索引列的时候,先到这个新的分片表里做一次查询,select * from user where name = '小白' ;这样就能迅速定位到对应的主键ID,然后再拿主键ID,去就的分片表里再查一次数据,这样就从漫无目的的全表扩散查询,缩减为只固定查几个表了,但这个做法的缺点也比较明显,你需要维护2套表,并且普通索引列更新时,要两张表同时进行更改


















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









