







一、前言
在前文中,我们详细介绍了 BeautifulSoup 这一工具。在处理静态数据爬取任务时,它确实展现出了快捷、方便的特性,能够高效地完成相关工作。然而,当前市面上诸多规范运营的网站,为了保障自身数据安全与运营秩序,纷纷采取了一系列反爬虫措施。
这些措施不仅涵盖了懒加载技术,使得页面数据不会一次性全部加载,增加爬取难度;部分网站还设置了登录认证拦截,只有通过特定身份验证的用户才能访问数据。在此情形下,BeautifulSoup 的局限性便暴露无遗,面对这些复杂的反爬虫机制,它往往显得力不从心。
那么,该如何突破这些阻碍,实现对数据的有效爬取呢?此时,我们不得不引入另一种功能强大的数据爬取工具 ——Selenium。它将为我们在应对复杂反爬虫场景时,开辟出一条全新的路径 。
二、动态网页的征服者——Selenium介绍

2.1.Selenium是什么?
原则上Selenium 是一个自动化测试工具,这个对于玩自动化测试的同学应该特别熟悉。同时也能很好地应用在爬虫领域。
它就像一个虚拟的浏览器,可以模拟用户在浏览器里的各种操作,比如点击按钮、滚动页面、输入文字等等。通过控制真实的浏览器(像 Chrome、Firefox),Selenium 能获取到完整的网页内容,包括那些需要加载才能显示的部分。
所以在动态爬取数据上,这个万一就很方便了,因此咱们直接用它来爬取一个动漫全集试试。因为是找百度上的动漫网站,但是其中的内容可能有些是一些特定平台的付费内容,所以
特此说明:
这里只提是供学习方法参考,而不涉及商用或者兜售传播之类的东西哈!!!
2.2.Selenium在Python爬虫中的常见函数介绍
2.2.1.初始化浏览器驱动
在使用 Selenium 开展网页爬取工作之前,初始化浏览器驱动是必不可少的前置步骤。浏览器驱动作为 Selenium 与浏览器之间沟通的桥梁,能够让我们通过代码控制浏览器的行为。
常见的浏览器驱动有 ChromeDriver、FirefoxDriver 等。不同的浏览器需要对应的驱动程序,并且驱动的版本要与浏览器版本相匹配,否则可能会出现兼容性问题,导致无法正常启动浏览器。
from selenium import webdriver
# 设置 ChromeDriver 的路径
driver_path = 'path/to/chromedriver'
# 创建 Chrome 浏览器驱动实例
driver = webdriver.Chrome(executable_path=driver_path)
为了避免每次都手动指定驱动路径,可以将驱动所在目录添加到系统的环境变量中,这样在代码中就可以直接使用 webdriver.Chrome() 来创建驱动实例,无需再指定 executable_path 参数。
2.2.2 打开网页
使用 get() 方法可以打开指定的网页。这是一个非常基础且常用的操作,通过该方法可以让浏览器访问指定的 URL 地址。
# 打开指定网页
driver.get('https://www.example.com')
当执行 get() 方法时,浏览器会尝试加载指定的网页,直到页面加载完成或者达到超时时间。
但是在实际应用中,有些网页可能加载速度较慢,为了避免因页面未完全加载而导致后续操作失败,可以结合等待机制来确保页面加载完成后再进行下一步操作。
2.2.3 查找元素
Selenium 提供了多种查找元素的方法,这些方法可以根据元素的不同属性来定位元素。
通过 ID 查找元素
使用 find_element_by_id() 方法可以通过元素的 ID 属性查找元素。ID 属性在一个 HTML 页面中是唯一的,因此通过 ID 查找元素是一种非常高效且准确的方式。
# 查找 ID 为 'element_id' 的元素
element = driver.find_element_by_id('element_id')
在查找元素时,如果元素的 ID 是动态生成的,那么就不能直接使用这种方法。此时可以考虑结合其他属性或者使用 XPath 来定位元素。
通过类名查找元素
使用 find_element_by_class_name() 方法可以通过元素的类名查找元素。类名通常用于给一组具有相同样式的元素添加样式,因此一个页面中可能会有多个元素具有相同的类名。
# 查找类名为 'element_class' 的元素
element = driver.find_element_by_class_name('element_class')
当一个页面中有多个元素具有相同的类名时,该方法只会返回第一个匹配的元素。如果需要查找所有匹配的元素,可以使用 find_elements_by_class_name() 方法。
通过标签名查找元素
使用 find_element_by_tag_name() 方法可以通过元素的标签名查找元素。HTML 页面中有很多不同类型的标签,如 div、p、a 等。
# 查找标签名为 'div' 的元素
element = driver.find_element_by_tag_name('div')
同样,该方法只会返回第一个匹配的元素。如果需要查找所有匹配的元素,可以使用 find_elements_by_tag_name() 方法。而且,由于一个页面中可能会有大量相同标签名的元素,使用这种方法定位元素时可能会不够准确,需要结合其他方法进行筛选。
通过 CSS 选择器查找元素
使用 find_element_by_css_selector() 方法可以通过 CSS 选择器查找元素。CSS 选择器是一种强大的元素定位工具,可以根据元素的标签名、类名、ID 等属性组合来定位元素。
# 查找 CSS 选择器为 'div.class_name' 的元素
element = driver.find_element_by_css_selector('div.class_name')
CSS 选择器的语法非常灵活,可以通过组合不同的属性来实现更精确的元素定位。例如,可以使用 #element_id 来定位具有特定 ID 的元素,使用 .class_name 来定位具有特定类名的元素。
通过 XPath 查找元素
使用 find_element_by_xpath() 方法可以通过 XPath 表达式查找元素。XPath 是一种用于在 XML 文档中定位节点的语言,在 HTML 页面中也可以使用 XPath 来定位元素。
# 查找 XPath 为 '//div[@id="element_id"]' 的元素
element = driver.find_element_by_xpath('//div[@id="element_id"]')
XPath 可以根据元素的属性、位置等信息进行非常精确的元素定位。但是,XPath 表达式的编写相对复杂,需要对 HTML 结构有一定的了解。在编写 XPath 表达式时,可以使用浏览器的开发者工具来辅助生成。

2.2.4 操作元素
找元素后,可以对其进行各种操作,常见的操作有以下几种:
输入文本
使用 send_keys() 方法可以向输入框中输入文本。这在模拟用户在表单中输入信息时非常有用。
# 查找 ID 为 'input_id' 的输入框元素
input_element = driver.find_element_by_id('input_id')
# 向输入框中输入文本
input_element.send_keys('Hello, World!')
在输入文本之前,可以先使用 clear() 方法清空输入框中的原有内容,确保输入的文本是准确的。另外,如果需要输入特殊字符,可以使用 Keys 类来模拟按键操作。
点击元素
使用 click() 方法可以点击元素。这在模拟用户点击按钮、链接等操作时非常常用。
# 查找 ID 为 'button_id' 的按钮元素
button_element = driver.find_element_by_id('button_id')
# 点击按钮
button_element.click()
在点击元素之前,可以先使用 is_enabled() 和 is_displayed() 方法来检查元素是否可用和可见,避免因元素不可用或不可见而导致点击失败。
2.2.5 等待页面加载
在网页中,有些元素可能需要一定的时间才能加载完成,因此需要使用等待机制。Selenium 提供了两种等待方式:显式等待和隐式等待。
显式等待
显式等待是指在代码中指定一个条件,直到该条件满足为止。这种方式可以让我们更加精确地控制等待时间,避免不必要的等待。
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 等待最多 10 秒,直到 ID 为 'element_id' 的元素可见
element = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.ID, 'element_id'))
)
显式等待可以根据不同的条件进行等待,如元素可见、元素可点击、元素存在等。在实际应用中,要根据具体的需求选择合适的条件。另外,为了避免等待时间过长,可以设置一个合理的超时时间。
隐式等待
隐式等待是指在查找元素时,等待一段时间,如果在这段时间内元素没有出现,则抛出异常。这种方式比较简单,只需要设置一次等待时间,后续所有的元素查找操作都会自动应用这个等待时间。
# 设置隐式等待时间为 10 秒
driver.implicitly_wait(10)
隐式等待适用于页面加载速度相对稳定的情况。但是,如果页面中有一些元素加载时间较长,使用隐式等待可能会导致整个程序的运行时间过长。因此,在实际应用中,可以结合显式等待和隐式等待来提高效率。
2.2.6 关闭浏览器
使用 quit() 方法可以关闭浏览器。这是在爬虫程序结束时必须要执行的操作,否则浏览器进程可能会一直存在,占用系统资源。
# 关闭浏览器
driver.quit()
在关闭浏览器之前,可以先保存一些必要的数据,如爬取到的信息、浏览器的会话状态等。另外,为了确保浏览器能够正常关闭,可以使用 try...finally 语句来保证 quit() 方法一定会被执行。
另外要注意的是:
浏览器驱动实例不是线程安全的,这意味着在多线程环境下,如果多个线程同时操作同一个浏览器驱动实例,可能会导致数据不一致、操作冲突等问题。例如,一个线程正在点击某个元素,而另一个线程同时在查找另一个元素,这可能会导致浏览器的行为变得不可预测。
因此,在多线程环境下,每个线程都应该有自己独立的浏览器驱动实例,避免多个线程共享同一个实例。
三、Selenium 爬取动漫网站流程
Step1:安装Python的Selenium 库及浏览器驱动
pip install selenium
# 记得下载对应浏览器的driver,推荐ChromeDriver与BeautifulSoup不同在于,除了对应的Selenium 库以外要使用 Selenium,得先下载对应浏览器的驱动,比如 Chrome 浏览器就得下载 ChromeDriver。把驱动的路径配置好,这样 Selenium 才能和浏览器 “沟通”。
这里我们使用谷歌浏览器的驱动就行,对应资源大家可自行自行或者到我资源自取。
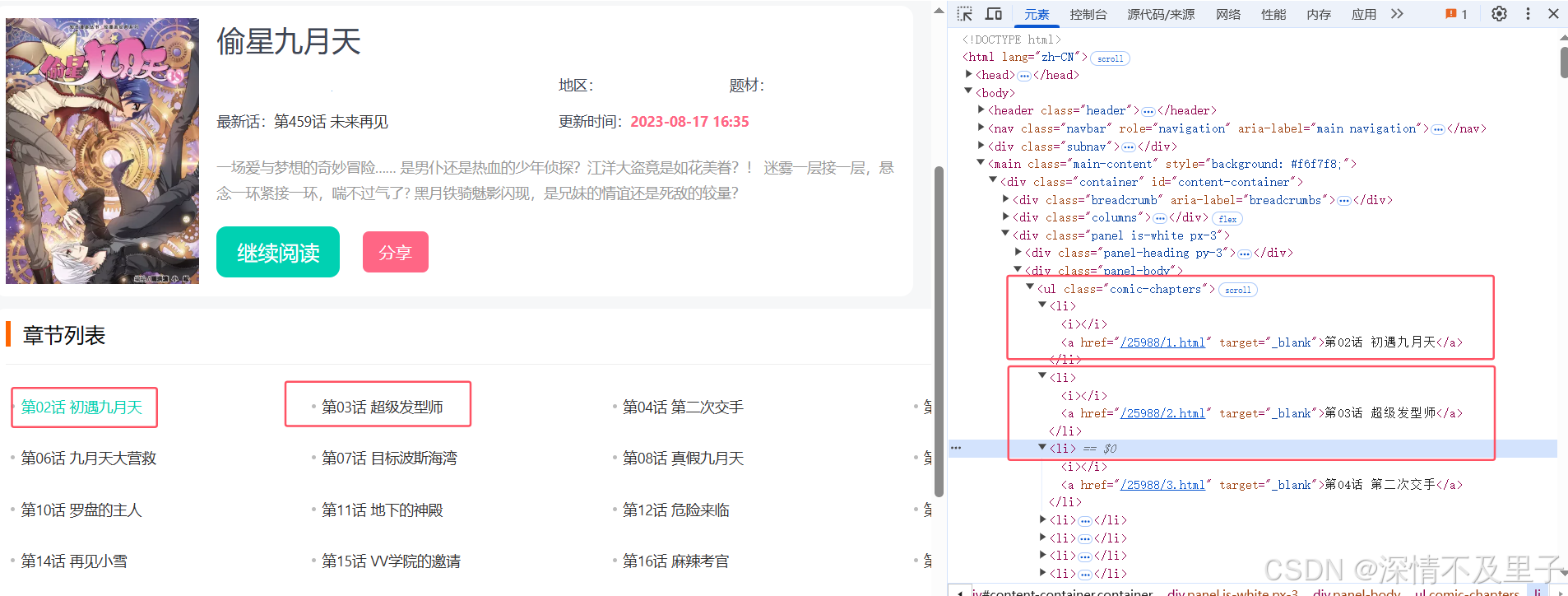
Step2:分析网页动漫图片元素信息
这里我们以以前的人气漫画《偷星九月天》为例,先进入其中某一章节后进行元素分析
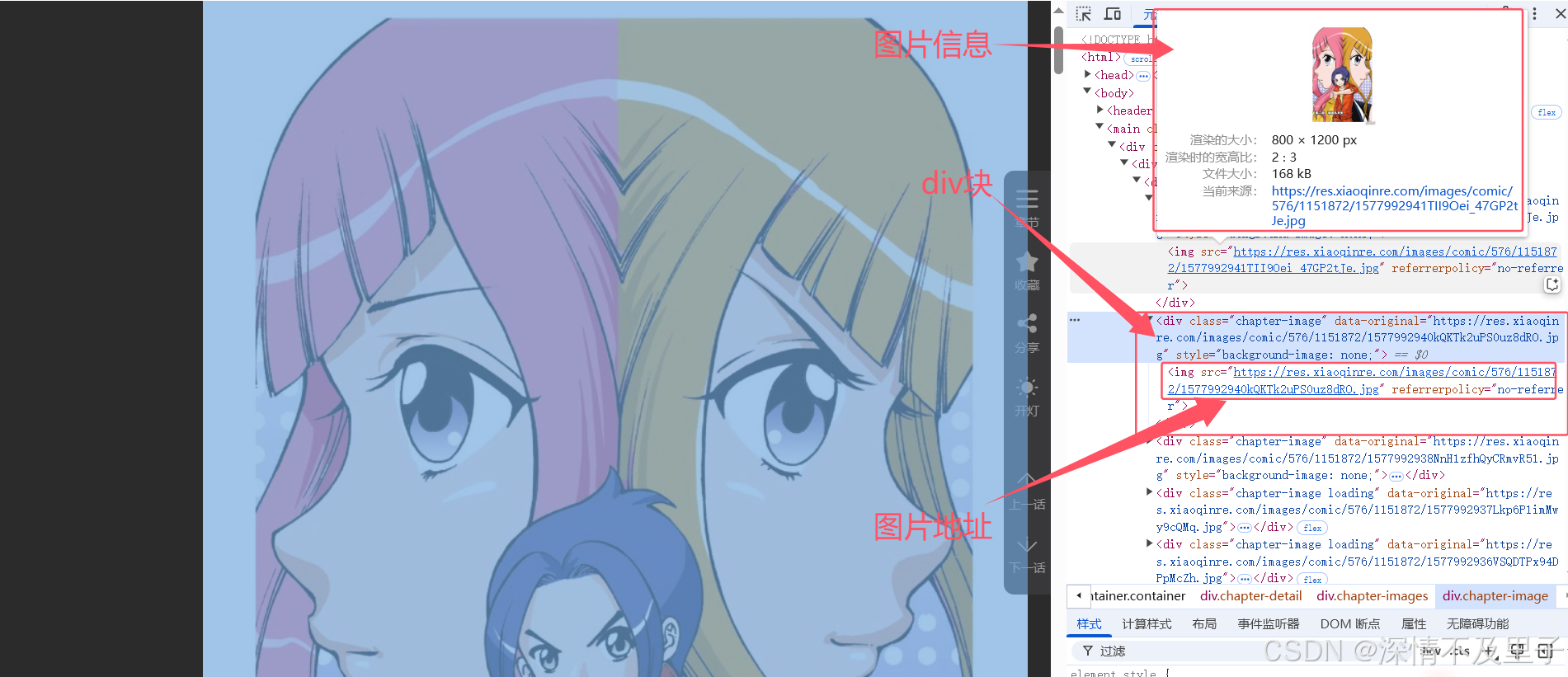
这个就更简单了,每张图片地址就在div块下面的img里面,也可以选data-original里面的链接,因为都一样。只要能确定图片地址就行,所以具体过程就不在重复赘述了,与上面一致。
但是需要注意的是,这个网站咱们在访问漫画的章节内容是他是有个加载中的过程。所以使用BeautifulSoup获取是得不到实际的网站信息的,不信咱们看看整体网页的解析信息如何:
D:\pthon_project\venv\Scripts\python.exe D:\pthon_project\30-Days-Of-Python\22_Day_Web_scraping\动漫数据爬取-常规-BeautifulSoup\web_test.py
<!DOCTYPE html>
<html>
<head>
……
<body>
<header class="header level">
<div class="level-item">
<div aria-label="breadcrumbs" class="breadcrumb">
<ul>
<li><a href="/">首页</a></li>
<li><a href="/category">漫画</a></li>
<li><a href="/25988">偷星九月天</a></li>
<li><span>第02话 初遇九月天</span></li>
</ul>
</div>
<button class="button is-danger is-rounded"><span class="j-read-i">1</span>/24</button>
</div>
</header>
<main class="main-content">
<div class="container" id="content-container">
<div class="chapter-detail">
<div class="chapter-images">
<div class="chapter-image loading">
<div class="progress-container">
<svg class="progress-ring" height="150" width="150">
<circle class="progress-ring__background" cx="50" cy="50" r="45"></circle>
<circle class="progress-ring__circle" cx="50" cy="50" r="45"></circle>
</svg>
<div class="progress-text">0%</div>
</div>
<div class="loading-message">
<p>正在加载图片,请稍候</p>
</div>
</div>
</div>
</div>
</div>
<div id="floatbtn">
<a href="/25988">
<i class="iconfont icon-chapter"></i>
<span class="txt">章节</span>
</a>
……
进程已结束,退出代码为 0
很明显图片信息没有,仅仅获取到了<p>正在加载图片,请稍候</p>所以这时候就需要使用Selenium来帮忙了。
Step3:Selenium 爬取漫画章节图片
首先设置一下谷歌浏览器及驱动的配置信息,尝试通过Selenium 启动页面:
# 设置Chrome选项
chrome_options = Options()
chrome_options.binary_location = "C:\Program Files\Google\Chrome\Application\chrome.exe"
chrome_options.add_argument('--start-maximized') # 最大化窗口
chrome_options.add_argument('--disable-extensions') # 禁用扩展
chrome_options.add_argument('--disable-gpu') # 禁用GPU,使用无头模式
# 将随机的 User - Agent 添加到 ChromeOptions
chrome_options.add_argument(f'user-agent={random_user_agent}')
# 设置chromedriver路径
service = Service("C:\Program Files\Google\Chrome\Application\chromedriver.exe")
# 初始化浏览器
driver = webdriver.Chrome(service=service, options=chrome_options)
# 定义漫画章节地址
comic_chapter_url = 'https://www.haoguoman.net/25988/1.html'
# 打开章节页面
driver.get(comic_chapter_url)运行后可以看到已经可以自动打开我们指定的网址界面了:
但是就像我之前说的,它这里会比我们平常用浏览器直接访问有一个明显的懒加载过程,所以我们得在其中加一些js的代码来模拟滚动加载的过程:
# 等待页面加载完成,这里设置为最大等待时间为30秒
WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.CSS_SELECTOR, "div.chapter-image")))
# 模拟滚动加载页面内容
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(4) # 等待页面加载新内容
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height这也是Selenium比BeautifulSoup更方便的地方,我们可以通过js的形式定制化我们的操作需求并让Selenium自动执行。
最后再把我们定位图片地址信息、新建文件夹以及下载保存的操作补充上去,就完成基础的流程:
# 提取图片信息
image_elements = driver.find_elements(By.CSS_SELECTOR, "div.chapter-image img")
image_urls = [img.get_attribute('src') for img in image_elements]
# 确保保存图片的文件夹存在
save_folder = '偷星九月天'
if not os.path.exists(save_folder):
os.makedirs(save_folder)
# 下载并保存图片
for index, url in enumerate(image_urls):
response = requests.get(url)
if response.status_code == 200:
file_path = os.path.join(save_folder, f'image_{index + 1}.jpg')
with open(file_path, 'wb') as file:
file.write(response.content)
logging.info(f"图片已保存: {file_path}")
else:
logging.error(f"无法下载图片: {url}")
# 关闭浏览器
driver.quit()但是这个逻辑在实际使用上还是有点问题,图片加载过慢,网站一下就直接到底部栏了,所以导致中间有部分图片没加载因此下载图片缺失的问题。
D:\pthon_project\venv\Scripts\python.exe D:\pthon_project\30-Days-Of-Python\22_Day_Web_scraping\动漫数据爬取-进阶-Selenium\selenium_get_data.py
2025-03-20 21:03:54,263 - INFO - 图片已保存: 偷星九月天\image_1.jpg
2025-03-20 21:03:56,008 - INFO - 图片已保存: 偷星九月天\image_2.jpg
2025-03-20 21:03:58,915 - INFO - 图片已保存: 偷星九月天\image_3.jpg
2025-03-20 21:04:04,201 - INFO - 图片已保存: 偷星九月天\image_4.jpg
2025-03-20 21:04:06,038 - INFO - 图片已保存: 偷星九月天\image_5.jpg
2025-03-20 21:04:08,558 - INFO - 图片已保存: 偷星九月天\image_6.jpg
进程已结束,退出代码为 0因此还需要优化一下逻辑,让其有规律的下滑加载,保证图片能加载完成后被下载下来,当然为了让整体代码更加优雅我们一般推荐封装函数,并且再有问题的地方加上日志记录,这样后面调试或使用就更加方便了:
import os
import logging
import time
from fake_useragent import UserAgent
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support import expected_conditions as EC
import requests
from selenium.webdriver.support.wait import WebDriverWait
# 设置日志配置,方便调试信息输出
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
def setup_driver():
# 创建 UserAgent 对象
ua = UserAgent()
# 获取随机的 User - Agent
random_user_agent = ua.random
# 设置 Chrome 选项
chrome_options = Options()
chrome_options.binary_location = r"C:\Program Files\Google\Chrome\Application\chrome.exe"
chrome_options.add_argument('--start-maximized') # 最大化窗口
chrome_options.add_argument('--disable-extensions') # 禁用扩展
chrome_options.add_argument('--disable-gpu') # 禁用 GPU,使用无头模式
# 将随机的 User - Agent 添加到 ChromeOptions
chrome_options.add_argument(f'user-agent={random_user_agent}')
# 设置 chromedriver 路径
service = Service(r"C:\Program Files\Google\Chrome\Application\chromedriver.exe")
# 初始化浏览器
driver = webdriver.Chrome(service=service, options=chrome_options)
return driver
def wait_for_element(driver, css_selector, timeout=30):
try:
element = WebDriverWait(driver, timeout).until(
EC.presence_of_element_located((By.CSS_SELECTOR, css_selector))
)
element_found_time = time.time()
logging.info(f"元素在 {element_found_time} 时刻被获取到,元素选择器: {css_selector}")
return element
except Exception as e:
logging.error(f"元素未找到,元素选择器: {css_selector},错误信息: {e}")
return None
def scroll_to_bottom(driver, scroll_pause_time=2, max_scrolls=100, scroll_height=1000):
scroll_count = 0
last_height = driver.execute_script("return document.body.scrollHeight")
consecutive_same_height = 0
logging.info(f"开始滚动,初始页面高度: {last_height}")
while scroll_count < max_scrolls:
# 滚动指定的高度
driver.execute_script(f"window.scrollBy(0, {scroll_height});")
logging.info(f"第 {scroll_count + 1} 次滚动,滚动高度: {scroll_height}")
# 等待页面加载新内容
time.sleep(scroll_pause_time)
# 计算新页面的高度
new_height = driver.execute_script("return document.body.scrollHeight")
logging.info(f"第 {scroll_count + 1} 次滚动后,页面高度: {new_height}")
if new_height == last_height:
consecutive_same_height += 1
logging.info(f"页面高度未变化,连续未变化次数: {consecutive_same_height}")
if consecutive_same_height >= 5:
# 如果连续 5 次高度相同,认为已到底部
logging.info("连续 5 次页面高度未变化,认为已滚动到页面底部,停止滚动")
break
else:
consecutive_same_height = 0
logging.info("页面高度发生变化,重置连续未变化次数为 0")
# 更新上次高度
last_height = new_height
scroll_count += 1
logging.info(f"滚动结束,共滚动 {scroll_count} 次")
def download_images(driver, target_folder):
# 获取所有图片的地址信息
try:
images = WebDriverWait(driver, 30).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div.chapter-image img"))
)
logging.info(f"成功获取到 {len(images)} 张图片元素")
except Exception as e:
logging.error(f"获取图片元素失败,错误信息: {e}")
return
# 确保目标文件夹存在
if not os.path.exists(target_folder):
os.makedirs(target_folder)
logging.info(f"创建目标文件夹: {target_folder}")
# 下载图片并按顺序保存到本地文件夹
for index, image in enumerate(images):
try:
image_url = image.get_attribute("src")
if image_url:
# 下载图片
response = requests.get(image_url, stream=True)
response.raise_for_status()
# 保存图片
image_path = os.path.join(target_folder, f"image_{index + 1}.jpg")
with open(image_path, 'wb') as handler:
for chunk in response.iter_content(chunk_size=8192):
handler.write(chunk)
logging.info(f"成功下载图片: {image_url} 到 {image_path}")
else:
logging.warning(f"第 {index + 1} 张图片 URL 为空或未找到")
except Exception as e:
logging.error(f"下载第 {index + 1} 张图片失败,错误信息: {e}")
# 定义漫画章节地址
comic_chapter_url = 'https://www.haoguoman.net/25988/1.html'
# 初始化浏览器
driver = setup_driver()
# 打开章节页面
driver.get(comic_chapter_url)
logging.info(f"打开页面: {comic_chapter_url}")
# 等待元素出现
wait_for_element(driver, "div.chapter-image")
# 模拟滚动加载
scroll_to_bottom(driver)
# 下载图片
download_images(driver, "偷星九月天")
# 关闭浏览器
driver.quit()
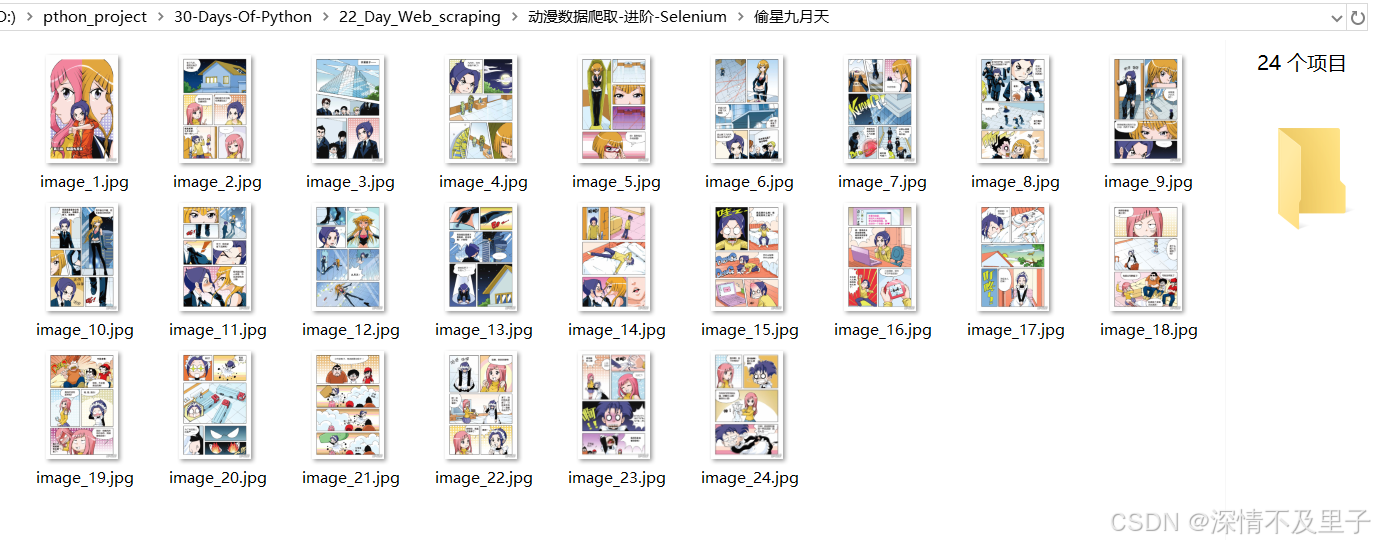
logging.info("浏览器已关闭")然后这一章节的漫画也就全部下载到本地了:
Step4:功能优化提升
虽然完成了一个章节的漫画爬取和下载但是肯定有同学会问:
一个动漫四五百个章节呢,这么一个一个下不得累死?还有更好的更快地办法吗,兄弟?
有的!兄弟,有滴!这样的办法还有九种!
玩笑归玩笑哈,九种可能太多但是现成最简单的还是有的。每一个章节无非对应的就是一个<ul><li>包裹的地址:
所以咱们把他遍历出来然后逐步爬取不就搞定了。
因此咱们需要先在主页取获取所有子章节链接信息:
def get_chapter_links(driver):
chapter_links = []
try:
logging.info("开始获取子章节链接信息...")
elements = driver.find_elements(By.XPATH, "//*[@id='content-container']/div[3]/div[2]/ul/li/a")
for element in elements:
link = element.get_attribute("href")
title = element.text
chapter_links.append((link, title))
# 模拟鼠标悬停操作,增加真实性
ActionChains(driver).move_to_element(element).perform()
time.sleep(0.5)
logging.info(f"成功获取到 {len(chapter_links)} 个子章节链接")
except Exception as e:
logging.error(f"获取子章节链接失败,错误信息: {e}")
return chapter_links但是呢,由于章节太多了,480多张获取起来其实很慢,因此我们可以适当去创建协程的方式来解决。
协程在处理 I/O 密集型任务时效率非常高,因为它可以在等待 I/O 操作完成时让出控制权,让其他协程继续执行,从而充分利用 CPU 资源。在章节链接获取这种 I/O 密集型任务中,协程通常比多线程更高效。
async def process_element(element):
loop = asyncio.get_running_loop()
link = await loop.run_in_executor(None, element.get_attribute, "href")
title = await loop.run_in_executor(None, lambda: element.text)
# 模拟鼠标悬停操作,增加真实性
await loop.run_in_executor(None, lambda: ActionChains(webdriver.Chrome()).move_to_element(element).perform())
await asyncio.sleep(0.5)
return (link, title)
async def get_chapter_links(driver):
chapter_links = []
try:
logging.info("开始获取子章节链接信息...")
elements = driver.find_elements(By.XPATH, "//*[@id='content-container']/div[3]/div[2]/ul/li/a")
tasks = [process_element(element) for element in elements]
results = await asyncio.gather(*tasks)
chapter_links.extend(results)
logging.info(f"成功获取到 {len(chapter_links)} 个子章节链接")
except Exception as e:
logging.error(f"获取子章节链接失败,错误信息: {e}")
return chapter_links
# 主函数
async def main():
base_url = 'https://www.haoguoman.net'
start_url = 'https://www.haoguoman.net/25988'
driver = setup_driver()
driver.get(start_url)
chapter_links = await get_chapter_links(driver)
print(chapter_links)
driver.quit()但是在批量数据爬取的时候可能会遇到很多异常情况,比如网络异常,因此在下载图片的过程中要引入重试机制,记录未下载完成的图片地址或者章节。
同时在批量下载数据时,可以加上进度查询的功能,让其在控制台日志打印时显示漫画的下载进度。最后在优化一下图片的爬取效率,同样给加上协程配合。这时候代码就比较长了,所以咱们最好用模块化开发的方式,把每个模块分开编写代码得到大致的整体的模块信息:
动漫数据爬取-进阶-Selenium/
├── 偷星九月天/
├── main.py
├── browser_setup.py
├── link_fetcher.py
├── image_downloader.py
├── logger_setup.py日志配置模块 logger_setup.py
import logging
import colorlog
def setup_logger():
"""
日志格式设置,使用不同颜色显示时间、日志级别和消息,便于其他模块调用。
:param log_colors: 日志颜色设置
:param fmt: 日志格式设置
:param datefmt: 时间格式设置
:return:
"""
log_colors = {
'DEBUG': 'cyan',
'INFO': 'green',
'WARNING': 'yellow',
'ERROR': 'red',
'CRITICAL': 'red,bg_white'
}
formatter = colorlog.ColoredFormatter(
'%(log_color)s%(asctime)s - %(levelname)s - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
log_colors=log_colors
)
logger = colorlog.getLogger(__name__)
logger.setLevel(logging.INFO)
# 创建控制台处理器并设置格式
ch = logging.StreamHandler()
ch.setFormatter(formatter)
logger.addHandler(ch)
return logger
浏览器驱动配置模块browser_setup.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from fake_useragent import UserAgent
def setup_driver():
"""
设置浏览器驱动
1. 创建 UserAgent 对象
2. 获取随机的 User - Agent
3. 设置 Chrome 选项
4. 设置 chromedriver 路径
5. 初始化浏览器
:return:
"""
# 创建 UserAgent 对象
ua = UserAgent()
# 获取随机的 User - Agent
random_user_agent = ua.random
# 设置 Chrome 选项
chrome_options = Options()
chrome_options.binary_location = r"C:\Program Files\Google\Chrome\Application\chrome.exe"
chrome_options.add_argument('--start-maximized') # 最大化窗口
chrome_options.add_argument('--disable-extensions') # 禁用扩展
chrome_options.add_argument('--disable-gpu') # 禁用 GPU
chrome_options.add_argument('--headless') # 无头模式, 即不显示浏览器界面,但仍然能够执行页面渲染、JavaScript等操作。
# 将随机的 User - Agent 添加到 ChromeOptions
chrome_options.add_argument(f'user-agent={random_user_agent}')
# 模拟浏览器指纹
chrome_options.add_argument('--lang=en-US,en;q=0.9')
chrome_options.add_argument('--accept-language=en-US,en;q=0.9')
# 设置代理(如果需要)
# chrome_options.add_argument('--proxy-server=http://your_proxy_ip:port')
# 设置 chromedriver 路径
service = Service(r"C:\Program Files\Google\Chrome\Application\chromedriver.exe")
# 初始化浏览器
driver = webdriver.Chrome(service=service, options=chrome_options)
return driver
章节链接获取模块link_fetcher.py
import asyncio
import json
import redis
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
# 连接 Redis
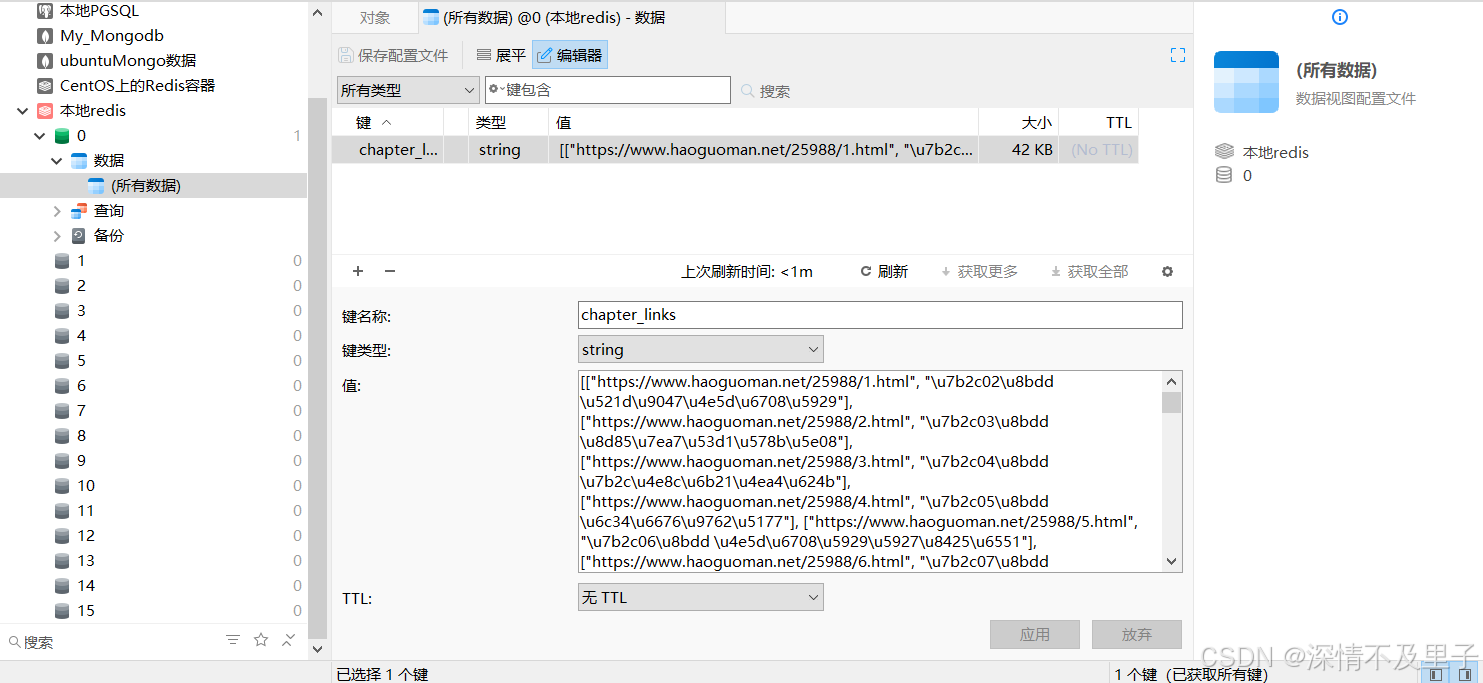
redis_client = redis.Redis(host='localhost', port=6379, db=0)
CACHE_KEY = "chapter_links"
async def process_element(element, driver):
loop = asyncio.get_running_loop()
link = await loop.run_in_executor(None, element.get_attribute, "href")
title = await loop.run_in_executor(None, lambda: element.text)
# 模拟鼠标悬停操作,增加真实性
await loop.run_in_executor(None, lambda: ActionChains(driver).move_to_element(element).perform())
await asyncio.sleep(0.5)
return (link, title)
async def get_chapter_links(driver, logger):
# 确保 Redis 操作同步执行
loop = asyncio.get_running_loop()
cached_links = await loop.run_in_executor(None, redis_client.get, CACHE_KEY)
if cached_links:
# 将字节类型转换为字符串类型
cached_links = cached_links.decode('utf-8')
chapter_links = json.loads(cached_links)
logger.info(f"从 Redis 缓存中获取到 {len(chapter_links)} 个子章节链接")
return chapter_links
chapter_links = []
try:
logger.info("开始获取子章节链接信息...")
elements = driver.find_elements(By.XPATH, "//*[@id='content-container']/div[3]/div[2]/ul/li/a")
tasks = [process_element(element, driver) for element in elements]
results = await asyncio.gather(*tasks)
chapter_links.extend(results)
logger.info(f"成功获取到 {len(chapter_links)} 个子章节链接")
# 将获取到的章节链接存入 Redis 缓存
await loop.run_in_executor(None, redis_client.set, CACHE_KEY, json.dumps(chapter_links))
except Exception as e:
logger.error(f"获取子章节链接失败,错误信息: {e}")
return chapter_links这里考虑到如果其中出现显网络异常,那么每次都得取爬取所有章节信息,所以我们这块加上了了Redis来作为临时的数据缓存,尽量节约网络资源。同时引入协程加快章节链接获取效率。
章节动漫图片下载模块 image_downloader.py
import os
import requests
import asyncio
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from tqdm import tqdm
from selenium.webdriver.support import expected_conditions as EC
# 未下载完成的图片和章节记录
failed_images = []
failed_chapters = []
async def download_image_with_retry(image_url, image_path, max_retries=5, logger=None):
"""
异步下载图片,重试 max_retries 次,失败后记录到 failed_images 列表中
:param image_url: 漫画单个章节的图片 URL
:param image_path: 漫画 images 文件夹下单个章节的图片路径
:param max_retries: 最大重试次数
:param logger:
:return:
"""
retries = 0 # 重试次数
while retries < max_retries:
try:
response = requests.get(image_url, stream=True)
response.raise_for_status()
with open(image_path, 'wb') as handler:
# 8192 为每次写入的块大小
for chunk in response.iter_content(chunk_size=8192):
handler.write(chunk)
logger.info(f"成功下载图片: {image_url} 到 {image_path}")
return True
except Exception as e:
retries += 1
logger.warning(f"下载图片 {image_url} 失败,第 {retries} 次重试,错误信息: {e}")
logger.error(f"下载图片 {image_url} 失败,已达到最大重试次数")
failed_images.append(image_url)
return False
async def download_images(driver, target_folder, logger):
"""
异步下载漫画所有章节的图片
:param driver:
:param target_folder:
:param logger:
:return:
"""
# 获取所有图片的地址信息
try:
images = WebDriverWait(driver, 30).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div.chapter-image img"))
)
logger.info(f"成功获取到 {len(images)} 张图片元素")
except Exception as e:
logger.error(f"获取图片元素失败,错误信息: {e}")
failed_chapters.append(target_folder)
return
# 确保目标文件夹存在
if not os.path.exists(target_folder):
os.makedirs(target_folder)
logger.info(f"创建目标文件夹: {target_folder}")
# 使用 tqdm 显示下载进度
tasks = []
for index, image in enumerate(images):
try:
image_url = image.get_attribute("src")
if image_url:
# 下载图片
image_path = os.path.join(target_folder, f"image_{index + 1}.jpg")
# 创建任务
task = asyncio.create_task(download_image_with_retry(image_url, image_path, logger=logger))
# 记录任务
tasks.append(task)
else:
logger.warning(f"第 {index + 1} 张图片 URL 为空或未找到")
except Exception as e:
logger.error(f"下载第 {index + 1} 张图片失败,错误信息: {e}")
for future in tqdm(asyncio.as_completed(tasks), total=len(tasks), desc=f"下载 {target_folder} 图片"):
await future
主要运行模块 main.py
import asyncio
import os
import time
from browser_setup import setup_driver
from link_fetcher_redis import get_chapter_links
from image_downloader import download_images, failed_images, failed_chapters
from logger_setup import setup_logger
from tqdm import tqdm
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
# 等待元素加载
def wait_for_element(driver, css_selector, timeout=30, logger=None):
try:
element = WebDriverWait(driver, timeout).until(
EC.presence_of_element_located((By.CSS_SELECTOR, css_selector))
)
element_found_time = time.time()
logger.info(f"元素在 {element_found_time} 时刻被获取到,元素选择器: {css_selector}")
return element
except Exception as e:
logger.error(f"元素未找到,元素选择器: {css_selector},错误信息: {e}")
return None
# 滚动页面到底部
def scroll_to_bottom(driver, scroll_pause_time=2, max_scrolls=100, scroll_height=1000, logger=None):
scroll_count = 0
last_height = driver.execute_script("return document.body.scrollHeight")
consecutive_same_height = 0
logger.info(f"开始滚动,初始页面高度: {last_height}")
while scroll_count < max_scrolls:
# 滚动指定的高度
driver.execute_script(f"window.scrollBy(0, {scroll_height});")
logger.info(f"第 {scroll_count + 1} 次滚动,滚动高度: {scroll_height}")
# 等待页面加载新内容
time.sleep(scroll_pause_time)
# 计算新页面的高度
new_height = driver.execute_script("return document.body.scrollHeight")
logger.info(f"第 {scroll_count + 1} 次滚动后,页面高度: {new_height}")
if new_height == last_height:
consecutive_same_height += 1
logger.info(f"页面高度未变化,连续未变化次数: {consecutive_same_height}")
if consecutive_same_height >= 5:
# 如果连续 5 次高度相同,认为已到底部
logger.info("连续 5 次页面高度未变化,认为已滚动到页面底部,停止滚动")
break
else:
consecutive_same_height = 0
logger.info("页面高度发生变化,重置连续未变化次数为 0")
# 更新上次高度
last_height = new_height
scroll_count += 1
logger.info(f"滚动结束,共滚动 {scroll_count} 次")
# 主函数
async def main():
logger = setup_logger()
start_url = 'https://www.haoguoman.net/25988'
driver = setup_driver()
driver.get(start_url)
chapter_links =await get_chapter_links(driver, logger)
logger.info(f"获取到的章节链接: {chapter_links}")
print(f"chapter_links 类型: {type(chapter_links)}")
if chapter_links:
print(f"第一个元素类型: {type(chapter_links[0])}")
print(f"第一个元素内容: {chapter_links[0]}")
# 使用 tqdm 显示章节处理进度
for link, title in tqdm(chapter_links, desc="处理章节"):
# 假设 link 已经是完整地址
full_link = link
target_folder = os.path.join("偷星九月天", title)
driver.get(full_link)
wait_for_element(driver, "div.chapter-image", logger=logger)
scroll_to_bottom(driver, logger=logger)
await download_images(driver, target_folder, logger)
driver.quit()
# 记录未下载完成的图片和章节
if failed_images:
logger.error(f"未下载完成的图片: {failed_images}")
if failed_chapters:
logger.error(f"未下载完成的章节: {failed_chapters}")
if __name__ == "__main__":
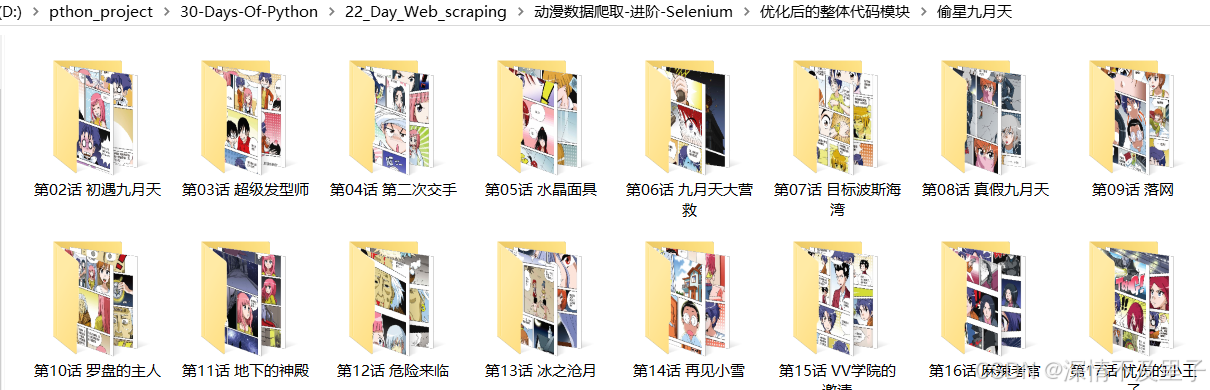
asyncio.run(main())最后运行后就可以看到整个动漫按章节进行图片爬取下载了,当然由于数量太多,时间也会比长,毕竟480多章呢,但是相比于一章一章的爬取肯定是方便多了。
D:\pthon_project\venv\Scripts\python.exe D:\pthon_project\30-Days-Of-Python\22_Day_Web_scraping\动漫数据爬取-进阶-Selenium\优化后的整体代码模块\main.py
2025-03-21 22:21:30 - INFO - 开始获取子章节链接信息...
2025-03-21 22:24:36 - INFO - 成功获取到 469 个子章节链接
2025-03-21 22:24:36 - INFO - 获取到的章节链接: [('https://www.haoguoman.net/25988/1.html', '第02话 初遇九月天'), ('https://www.haoguoman.net/25988/2.html', '第03话 超级发型师'), ('https://www.haoguoman.net/25988/3.html', '第04话 第二次交手'), ('https://www.haoguoman.net/25988/4.html', '第05话 水晶面具'),
……
('https://www.haoguoman.net/25988/469.html', '第459话 未来再见')]
下载 偷星九月天\第02话 初遇九月天 图片: 0%| | 0/24 [00:00<?, ?it/s]2025-03-22 11:18:41 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992941TII9Oei_47GP2tJe.jpg 到 偷星九月天\第02话 初遇九月天\image_1.jpg
2025-03-22 11:18:44 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992940kQKTk2uPS0uz8dRO.jpg 到 偷星九月天\第02话 初遇九月天\image_2.jpg
2025-03-22 11:18:46 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992938NnH1zfhQyCRmvR51.jpg 到 偷星九月天\第02话 初遇九月天\image_3.jpg
2025-03-22 11:18:47 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992937Lkp6P1imMwy9cQMq.jpg 到 偷星九月天\第02话 初遇九月天\image_4.jpg
2025-03-22 11:18:48 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992936VSQDTPx94DPpMcZh.jpg 到 偷星九月天\第02话 初遇九月天\image_5.jpg
2025-03-22 11:18:50 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992935LBs-0CNU4XwOSAfE.jpg 到 偷星九月天\第02话 初遇九月天\image_6.jpg
2025-03-22 11:18:51 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992934zDxXWx6dChECy1xT.jpg 到 偷星九月天\第02话 初遇九月天\image_7.jpg
2025-03-22 11:18:53 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/15779929330aEzbkQeZENgniEE.jpg 到 偷星九月天\第02话 初遇九月天\image_8.jpg
2025-03-22 11:18:54 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992932q8KerHkq7R376zsH.jpg 到 偷星九月天\第02话 初遇九月天\image_9.jpg
2025-03-22 11:18:56 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992931FZCPUMTqqpXmB7Cz.jpg 到 偷星九月天\第02话 初遇九月天\image_10.jpg
2025-03-22 11:18:57 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992930X5Nis8KMUNEuMxIu.jpg 到 偷星九月天\第02话 初遇九月天\image_11.jpg
2025-03-22 11:18:58 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/157799292958fOeqp1ljCHp1eB.jpg 到 偷星九月天\第02话 初遇九月天\image_12.jpg
2025-03-22 11:19:00 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992928b_Ho46x7mY6fCW_r.jpg 到 偷星九月天\第02话 初遇九月天\image_13.jpg
2025-03-22 11:19:03 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992927_K7FtMKmtQDwrUiz.jpg 到 偷星九月天\第02话 初遇九月天\image_14.jpg
2025-03-22 11:19:04 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/15779929265d9w5YUwr8vmBEk_.jpg 到 偷星九月天\第02话 初遇九月天\image_15.jpg
2025-03-22 11:19:07 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992925HUnjtEy4Tqdbh59M.jpg 到 偷星九月天\第02话 初遇九月天\image_16.jpg
2025-03-22 11:19:09 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/15779929249ESRjrPkEeafUJu7.jpg 到 偷星九月天\第02话 初遇九月天\image_17.jpg
2025-03-22 11:19:10 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992923eIp504Eg8BjFpqYW.jpg 到 偷星九月天\第02话 初遇九月天\image_18.jpg
2025-03-22 11:19:11 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992922TWMfyBkEWddczYsZ.jpg 到 偷星九月天\第02话 初遇九月天\image_19.jpg
2025-03-22 11:19:13 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992921SOuJn3vWM4eNJ8rO.jpg 到 偷星九月天\第02话 初遇九月天\image_20.jpg
2025-03-22 11:19:15 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992920SqO15Z3doc67mvnc.jpg 到 偷星九月天\第02话 初遇九月天\image_21.jpg
2025-03-22 11:19:17 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/15779929193AtCHywB_a_ZvN7d.jpg 到 偷星九月天\第02话 初遇九月天\image_22.jpg
2025-03-22 11:19:18 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992917q-Emr4J7ZIT_MfkZ.jpg 到 偷星九月天\第02话 初遇九月天\image_23.jpg
2025-03-22 11:19:22 - INFO - 成功下载图片: https://res.xiaoqinre.com/images/comic/576/1151872/1577992916sS1mVLn0Yj2_k0hu.jpg 到 偷星九月天\第02话 初遇九月天\image_24.jpg
下载 偷星九月天\第02话 初遇九月天 图片: 100%|██████████| 24/24 [00:42<00:00, 1.77s/it]
……
完成后我们不妨设想一下:既然可以在一个web网站上爬取整个漫画,那么能不能根据搜索条件自动去将获取到的结果,然后爬取相关的所有漫画呢,这样是不是就更方便!!!
留个设想大家可以去尝试一下完成这个需求~
四、总结
框架优缺点对比
- BeautifulSoup:优点是使用简单,对简单静态网页的解析速度快,代码量相对较少。缺点就是面对复杂网页,尤其是有动态加载内容的网页,它就没辙了。它适用于那些结构清晰、内容不需要复杂交互就能获取的静态网页。
- Selenium:优点很明显,能解决各种复杂网页的问题,不管是懒加载还是需要交互操作的网页,都能应对自如。但它也有缺点,就是运行速度相对较慢,因为要启动真实的浏览器,资源消耗也比较大。它适合爬取那些需要模拟用户操作才能获取完整数据的网站。
安全与版权问题
最后,一定要提醒大家,在进行数据爬取的时候,安全问题和版权问题千万不能忽视。首先,不要去爬取那些涉及个人隐私、商业机密或者有反爬虫机制的网站,不然可能会给自己带来法律风险。其次,对于有版权的图片、动漫等资源,仅仅用于个人学习和娱乐是可以的,但绝对不能用于商业用途,也不要随意传播。尊重知识产权,做一个合法合规的爬虫使用者。
写在文末
好啦,今天关于 Python 爬虫用 BeautifulSoup 和 Selenium 爬取图片及动漫的分享就到这儿啦,希望对大家有所帮助,大家有问题可以随时交流哦!
后续继续带来爬虫在正式数据爬取存储与分析的文章,毕竟咱们玩这个东西肯定不仅限于娱乐,工作上可能也会有所需要,但是场景肯定也会更复杂,继续期待~
往期相关文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











