







git简单来讲是目录内容管理系统,是一个树状的历史存储系统,类似macos中的time machine时光机器,类似vmware的快照,过去保留的每一个快照,可以随时随地回到过去保存的某一个快照的时段,允许回到过去的快照开始另外的分支
git也是很傻瓜式的内容最终器 stupid content tracker
但是git简单来讲就是个工具箱 toolkit

高级命令,用户比较容易理解的,低级命令(解决底层的一些修复查看问题,管理操作)
这些是用到的porcelain

这些命令不是肚子开的命令,和puppet类似,是大量的子命令构成的,比如git-add 代表git的add子命令,所有的命令都是git开头,后面的都可以理解为子命令
linux重要哲学思想,一个程序完成一件事情并且做好,但是如果有一个程序有大量功能,每一个功能都是一个小程序,现在基本上是合并成大程序,用子命令来表示
类似puppet子命令来实现
svn全称叫subversion,版本控制系统,前面还有一个CVS,git核心创始人也是linux李娜思
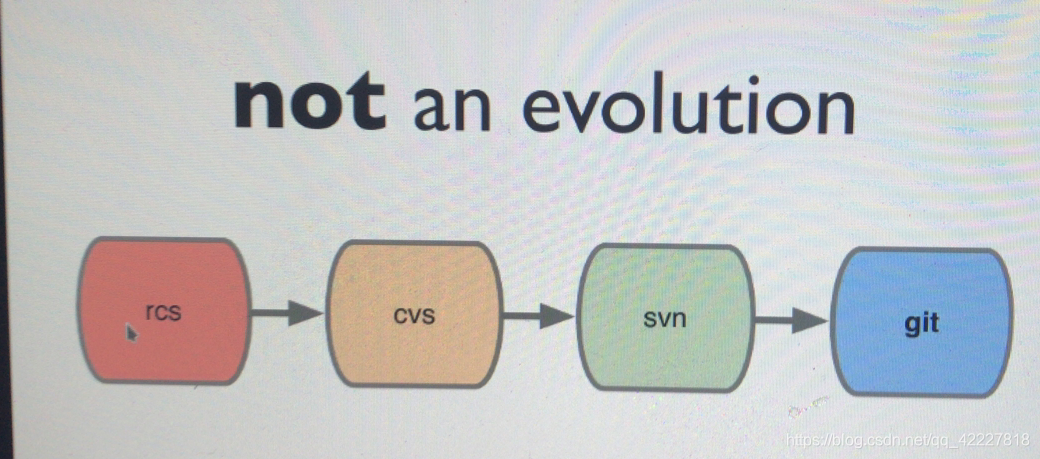
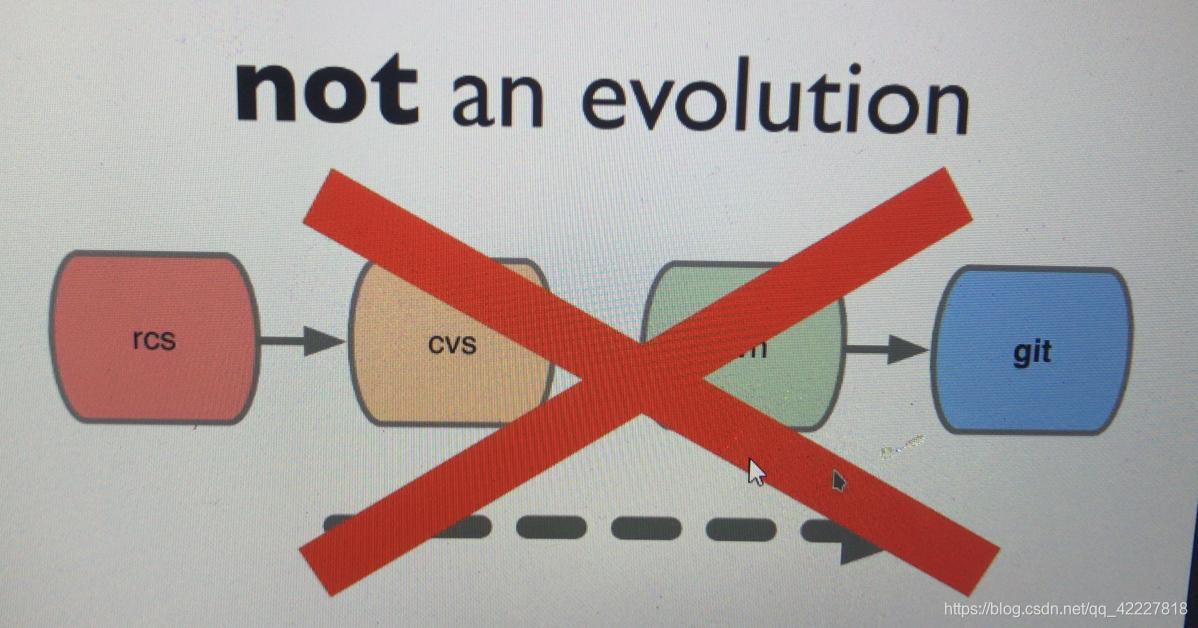
不是演进而来的,svn是cvs的增强版,但是git并不是svn的增强版,因为在实现版本控制理念上有本质不同
一般来讲源代码控制有两种存储方式,
1.delta storage 变化增量,变化的部分存储追踪系统,只存储变化部分
git是另外的存储系统
DAG storage 有向无环图,git存储文件的时候,依然是file A,B,C,假如文件发生小改变,保存的是快照,保存的是C1变化后内容的快照,B没改变就是不动的,使用逻辑卷快照很相似
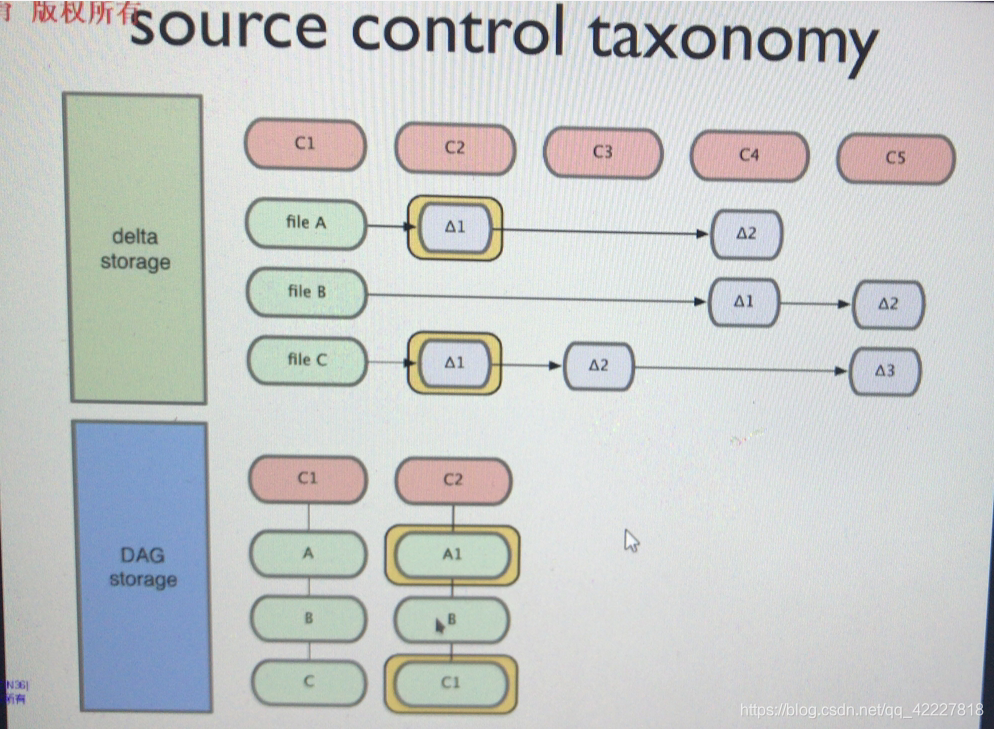
下一阶段保存C2的快照,A1 B 仍然指向上一个阶段,不做任何修改
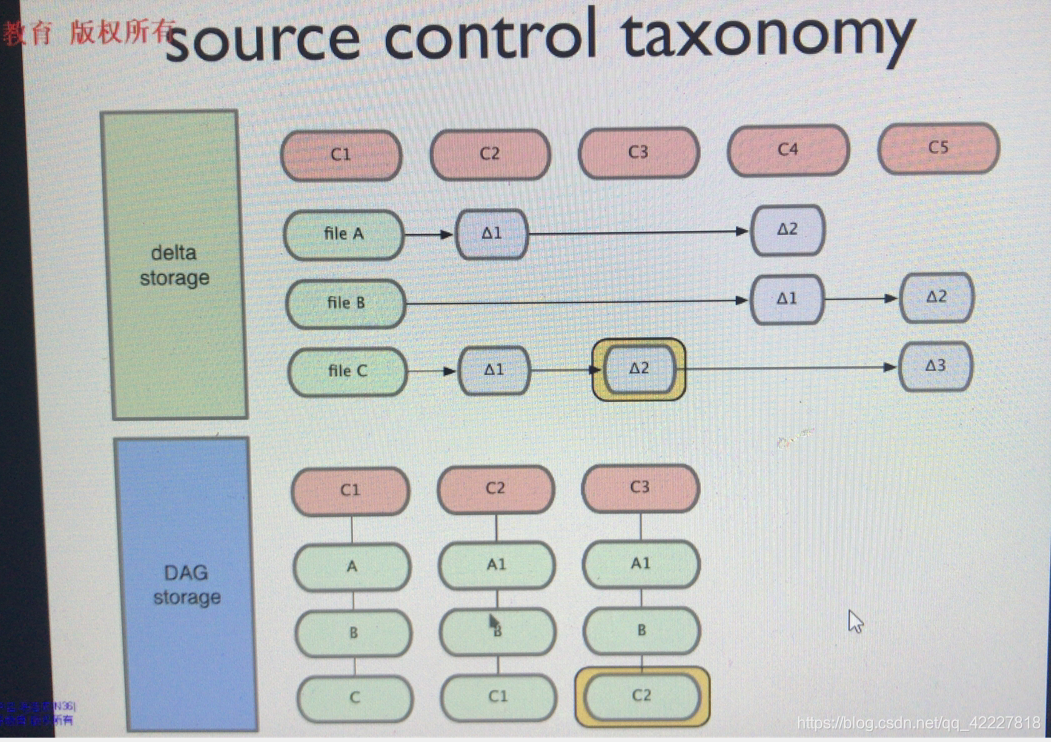
C4指向c3,c3指向c2,c2没有变化,A1变成A2,B变成B1,所以又保存好了变化下来的快照,
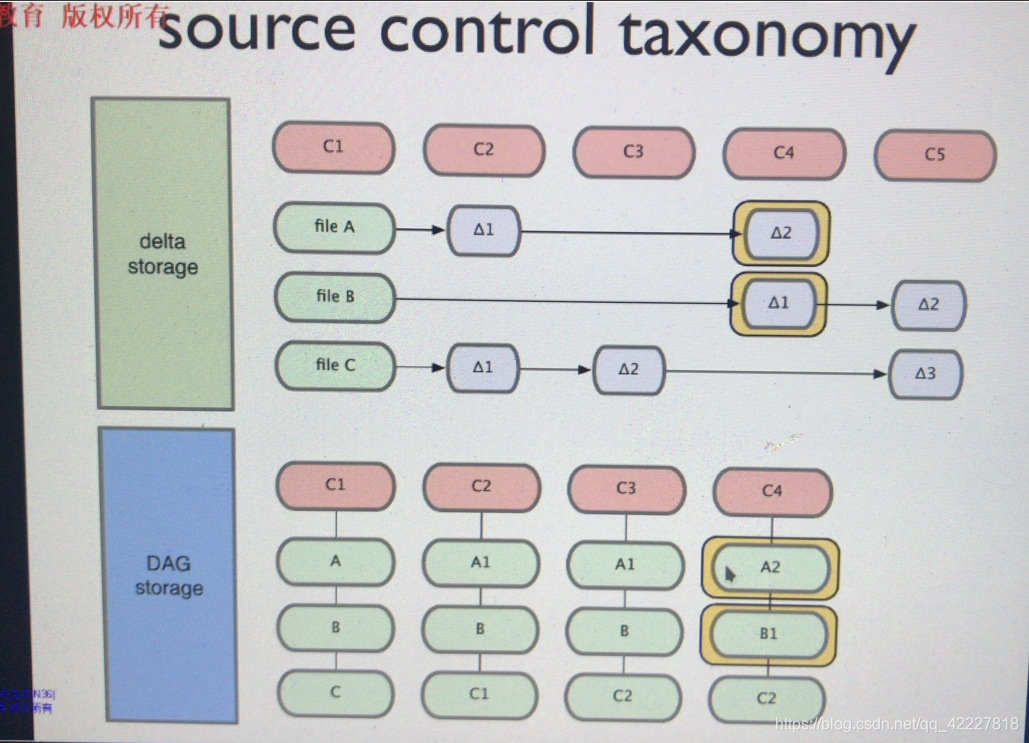
C5也是一样,所以叫有向无环图,A2指向A2,有方向的但是没有环路
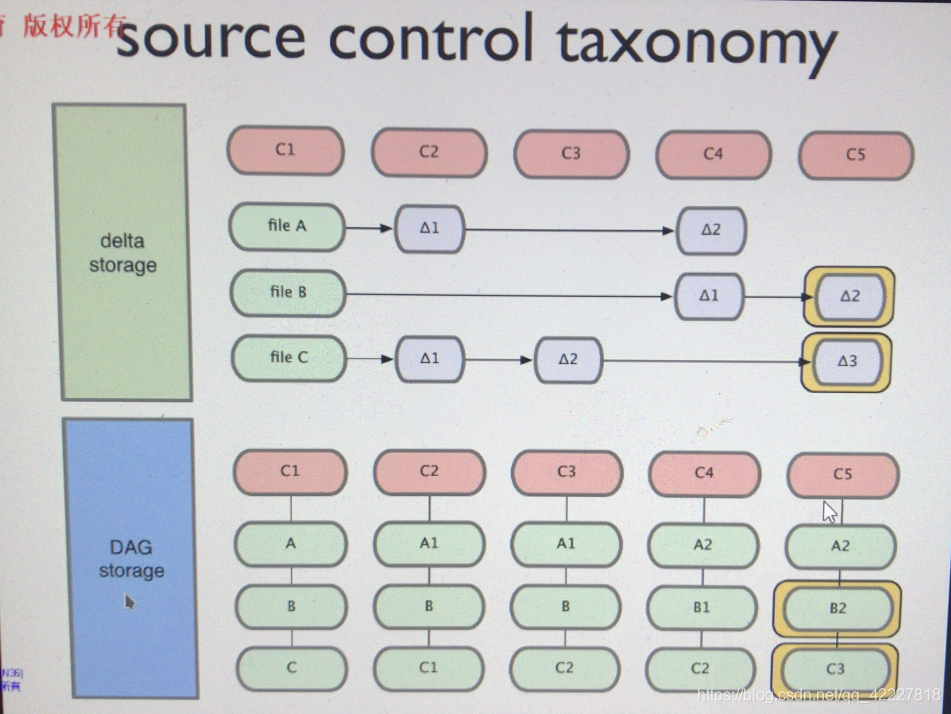
delta storage,svn和cvs都是这么做的
git是DAG storage
**无论哪种存储系统,大体有三种形式,
local本机模型(控制系统只在一个机器运作) rcs(很少见)
centralized中心化的,有中心节点的集中控制系统,svn,cvs就是 (perforce)
distributed分布式的,每一个节点都需要存储收据,(著名产品,darcs,mercurial)
单机没有办法协作
centralized,所有人的协作都需要依赖于中心节点,万一中心节点故障,就无法协作
distributed分布式,如果可以离线协作每一个人只需要在本地自己的分布式节点上工作即可, 将来能连接到网上,再协同起来
**
DAG
local 著名产品 cp -r ,time machine
centralized 著名产品 bitkeeper
distributed 著名产品 git,bazaar
git说白了就是一个目录,历史,树状历史管理系统,git仅仅是你工作目录下一个隐藏目录而已
内部大体存放了几个文件,
config
hooks 钩子
index 索引,暂存区
object database 对象数据库
references 指向过去存储的每一个快照的引用符号,也包括现在使用的引用符号

每个人所写的代码,存在一个个文件中,这个文件一般有一个目录,应该放在某个目录下,每个文件都有可能写好了存一份,想做一份快照
这个目录可以称为工作目录 workdir,目录名称也一般是项目名称
第一章写完了,为了避免下一次修改后悔的时候想要恢复到上次,恢复不了,就需要,当前的状态保存下来
第一章写完了只需要把第一章保存好,对git而言,就在你的工作目录下,有一个隐藏的目录,叫.git
想要保存这个文件当前状态时,就会保存在.git目录下的 object database 系统中
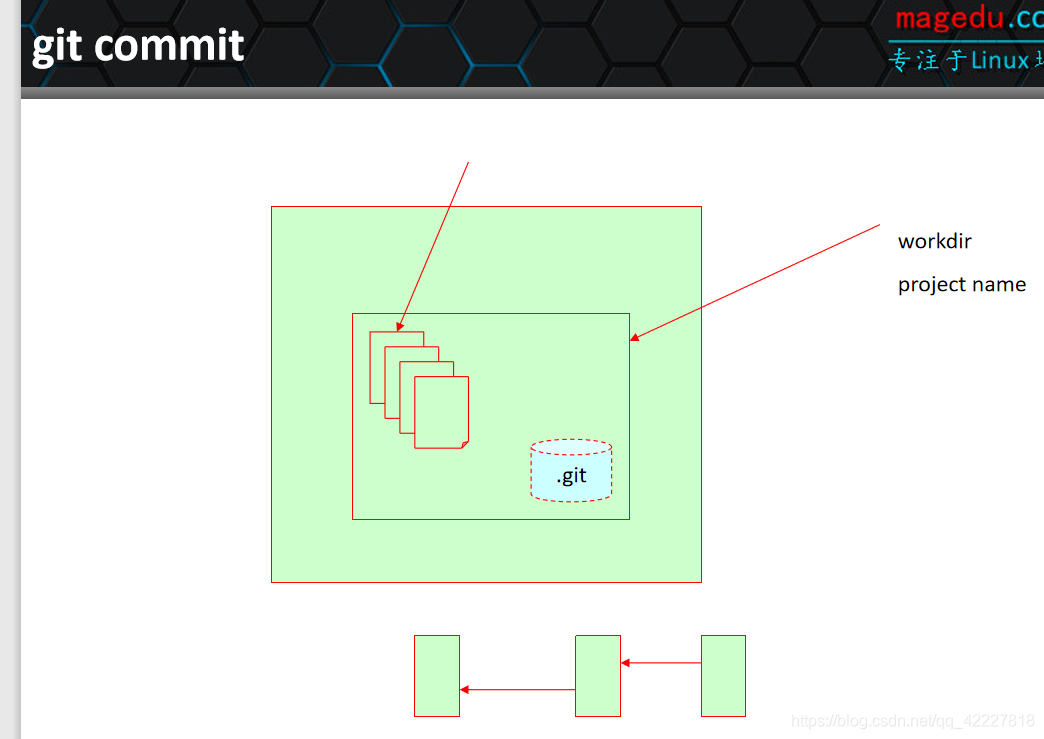
.git目录可以用来保存过去一个文件在任何时候做出的快照,这个快照对于任何文件来讲都是单向追踪
文件1,初始状态保存好了,第一次保存,改了三行,再保存,第二次的版本是指向第一次的,第二个版本的前一个版本是第一个,对这个版本的前一指向,每次的变化保存,都指向前一个版本,有方向的,但没有环路存在,第一次不可能指向最后一次
这些都再.git目录中予以保存的,每一个文件都可以考虑成一个对象
.git目录其实可以追踪我们整个工作目录当中的任何文件,我们想要在什么时间保存 的版本,都在git中欧你不过予以留存的,如果一不小心把文件删除了 从git对象数据库中你拿出来,或者改完以后,后悔了,可以任意恢复到过去某一个时间段,可以捡出任何单个文件过去的某一状态
每一次保存都叫git的提交commit,提交完就代表一次快照完了
有工作目录的概念
有提交的概念
.git目录最重要的object database,对象数据库,是如何存储对象的,每一个文件都有初始的版本,文件加入了一些新的内容,会把文件的类型,+文件的内容的大小+这个内容本身作哈希运算,对整个new_content 作哈希计算,计算以后得到哈希码,所以保存文件版本的时候,保存的是哈希码在objectdatabase,文件名是哈希码,会分层存放,截取一位或二位,作子目录
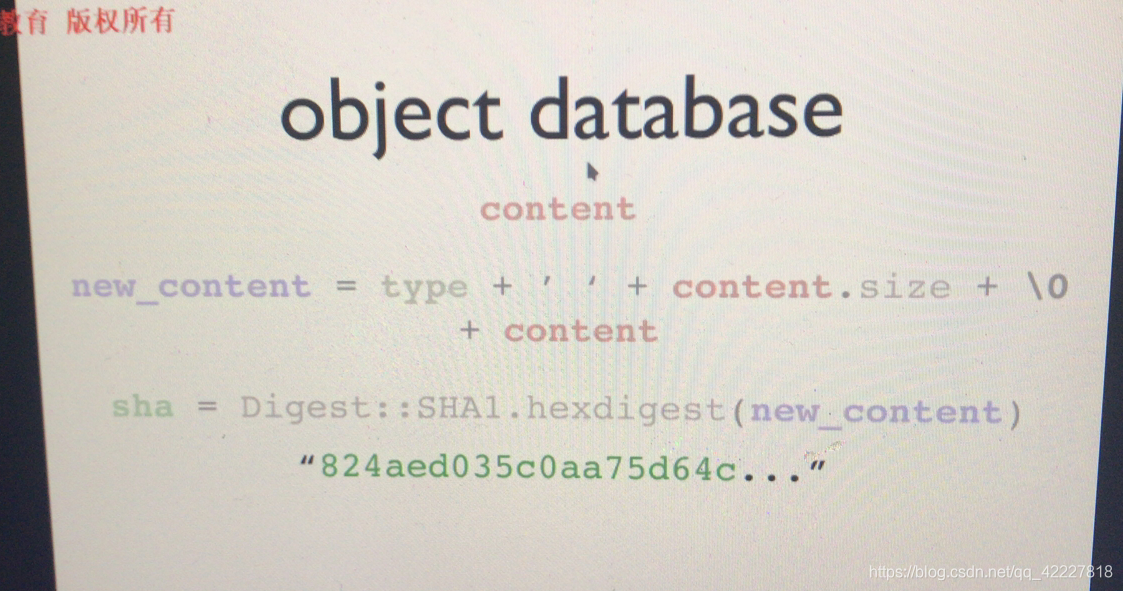
类似varnish,对文件内容本身作压缩,压缩完以后存放在,截取2位hash码作子目录,剩余的内容当作文件名放在这个子目录下,文件的内容是,使用zlib+defalte,压缩以后存放,以节约空间
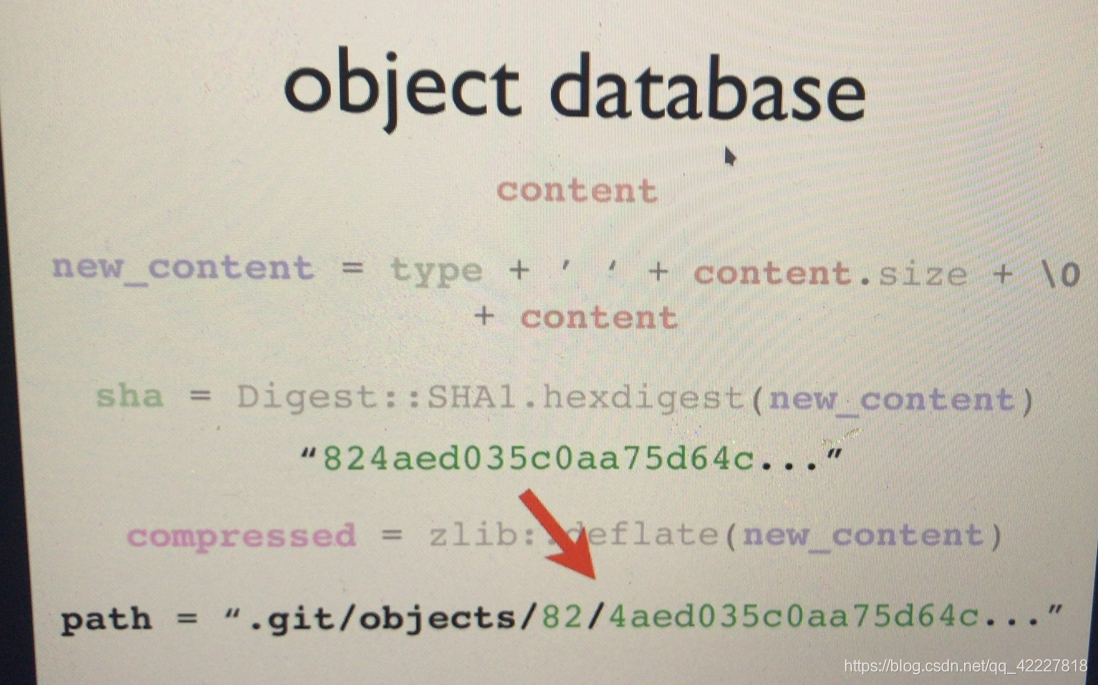
任何一个文件发生了变化,哈希码就发生了变化,所以文件一旦发生变化,再次存的时候,就已经是另外一个对象了,因为哈希码已经完全不同,因此每一个文件都是单独完整存放的,
对git来讲,内部进行压缩方式存放的,压缩之后,有些内容是相同的,彼此之间是可以共享的,所以即便一个文件存了很多次,但是对于git来讲,虽然名称不一样,但是实际上可以存储在一个底层系统上的,使用了type的方式,来将多个文件供相同的内容,基于某个分层逻辑,来完成存储,

每一个文件自身存储了它的类型,大小等元数据和数据本身,所以是一个对应的对象存储系统,使用非常宽松的格式来进行保存,
不同的文件哪怕拥有非常小的变化,但是哈希码是完全不同的,因此表现为至少是不同的文件,但是这多个文件,要存储为同一个pack文件,每一个文件的内容变化部分,自己在内部会有追踪,底层的内容,同一个文件,不同变化,展现的确实不同的哈希码的文件名,但是真正的文件内容不是存在这个文件上,而是指向一个pack文件,pack文件可以理解为每一个版本的,变化信息都保存了。
同一个文件只要变化的内容不是特别大,事实上是大概打包车工同一个文件,要找第一个文件,能够从里面过滤出第一个版本的内容,所以每一个文件自己是一个delta文件系统,
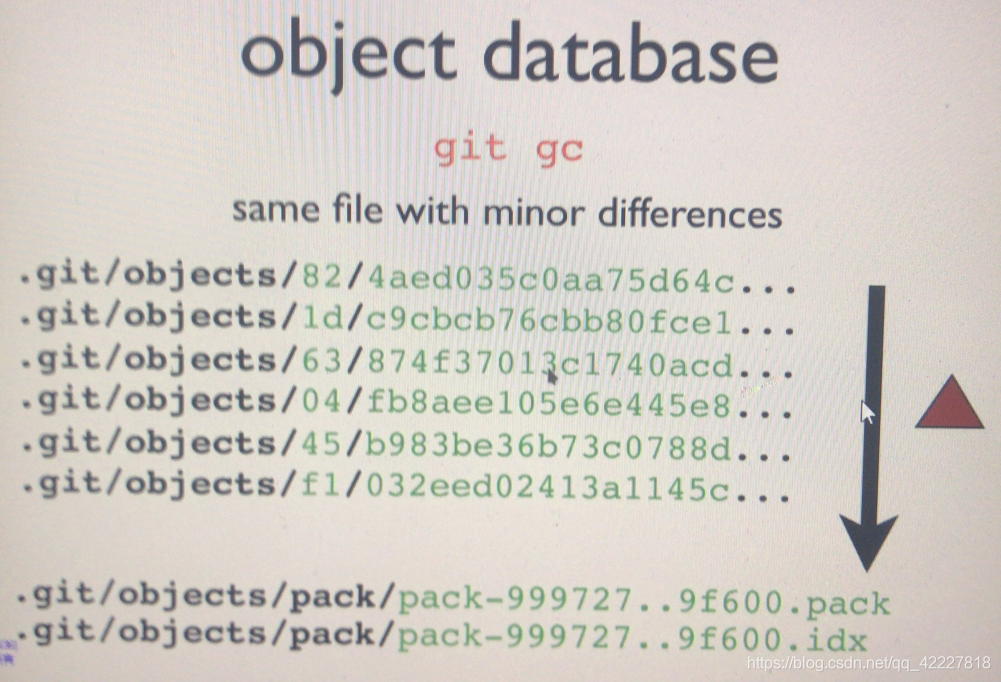

**所有的git对象都用这种方式存储
对git而言,一共有4种对象,之前的只是一种,叫文件
工作目录下会有子目录,子子目录,之存储文件内存,把文件目录删除了,但是,git没有删除,一不小心把工作文件的目录都全部删除了, 现在想要基于.git目录恢复,
不但要恢复文件,还要恢复目录结构(对象存储系统不光要存文件本身,还要存工作目录的层级结构)
存储层级结构的是tree对象,存储文件的叫blod对象,二进制的blob对象
还有另外两类对象,是引用的
commit 提交,每一次提交相当于一次快照,提交本身提交了快照,快照式的状态,
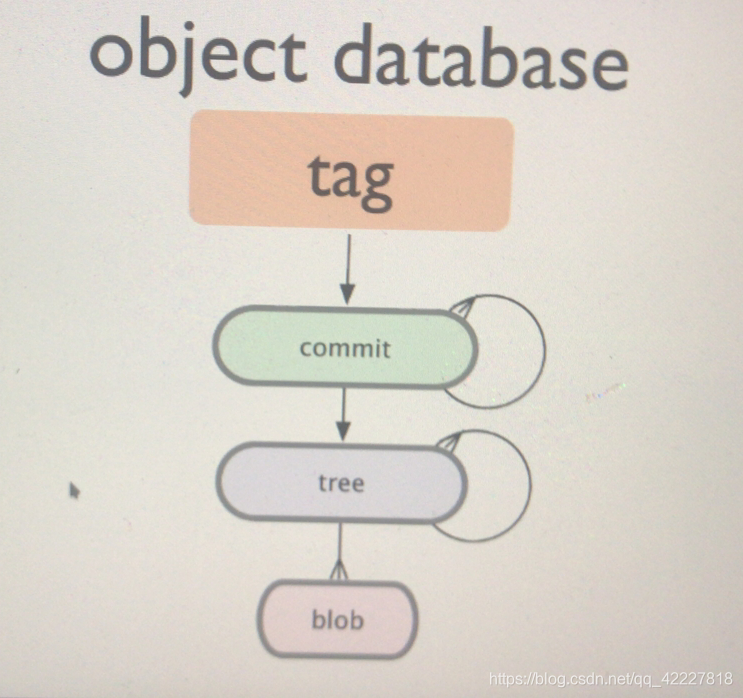
tag,标签,对每个提交的对象,文件名都是标签,就有点长了,tag可以理解为别名,即便是别名在git当中,也是靠对象逻辑来存储的
git一共有四类对象
blod 和tree是核心对象,每一次快照提交都有一个commit对象,tag不是必须的,但一般而言有tag,帮助我们用简单符号引用过去的某个特定的对象,比如commit,或者其他的,一般而言是用来标记commit,可以想成一个身份证,身份证号是主名称,commit每一个提交都有自己的名称,只不过是哈希码
**
类似blod,每一个haxi码都是blod的命名的,因此引用过去的快照,都要用哈希码应用,就很痛苦,所以取别名,tag就是别名
tag也是对象,本身也是哈希码保存的 示例是ruby代码,红色边框表示文件,蓝色边框表示目录
示例是ruby代码,红色边框表示文件,蓝色边框表示目录

如果要保存下来,blod对象有示例的内容,
object 对象名称,哈希码的名称,一般前6个字符足以表示文件内容
compress压缩格式
header’包含文件(或对象)类型,对象的大小

blod对象,可以想象成自己编辑的文件,存放的时候,每一个文件有header和content
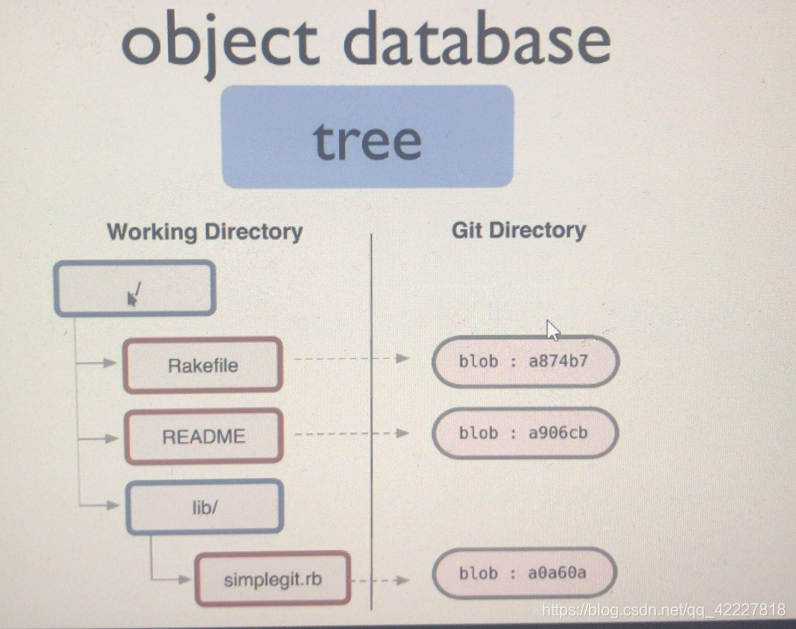
每一个文件都有自己的文件名,使用短格式的哈希名称,每一个目录,也要保存为一个对象,只不过是树类型的对象,也一样的文件名是哈希格式的
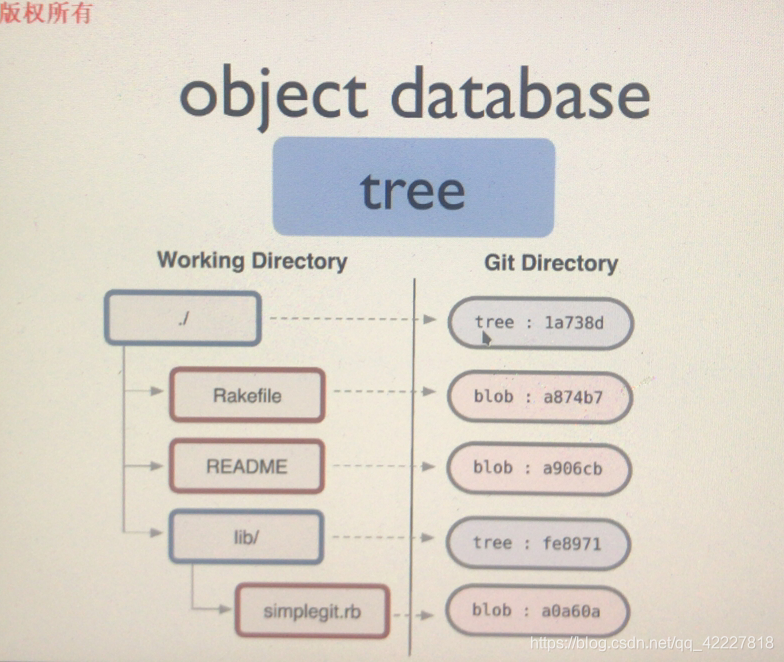
tree对象如何保存,目录对于linux来讲也是个文件,

每一个目录文件,内部存放的是,子目录下的,每一个文件的相关属性信息,包含了文件的inode info(类比成文件系统来说的,元数据),filename
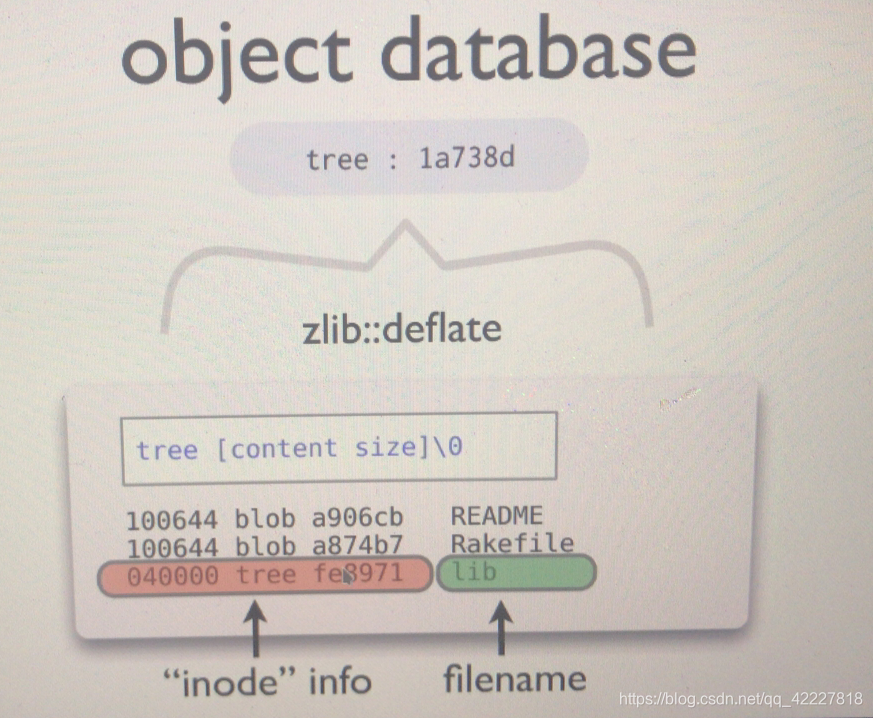
哈希格式的名,blod对象类型,100644是权限,这些为元数据,我们之前的元数据也是放在inode当中

block pointer 块指针实际就是哈希文件名,引号表示假的,对比Inode来说的,指明二进制对象到底哪个的
第三类对想,commit提交对象,没做一次快照,你的快照名叫什么快照本身应该有自己的属性信息,

每一个commit叫保存了某一时刻,当前工作目录下的各层级的层级结构的 当时状态信息,每一个文件都是可以不断进行变化的
每一次快照都指向,每个文件的前一次,如果想要恢复到两年前的状态
恢复到第一个版本的时候,绿文件初始版,和蓝文件的第二次改变
恢复到B的时候,绿文件第二个版本,蓝文件的第四个版本
如果把某个文件移到另外子目录下了,然后又提交了一次,目录路径发生了变化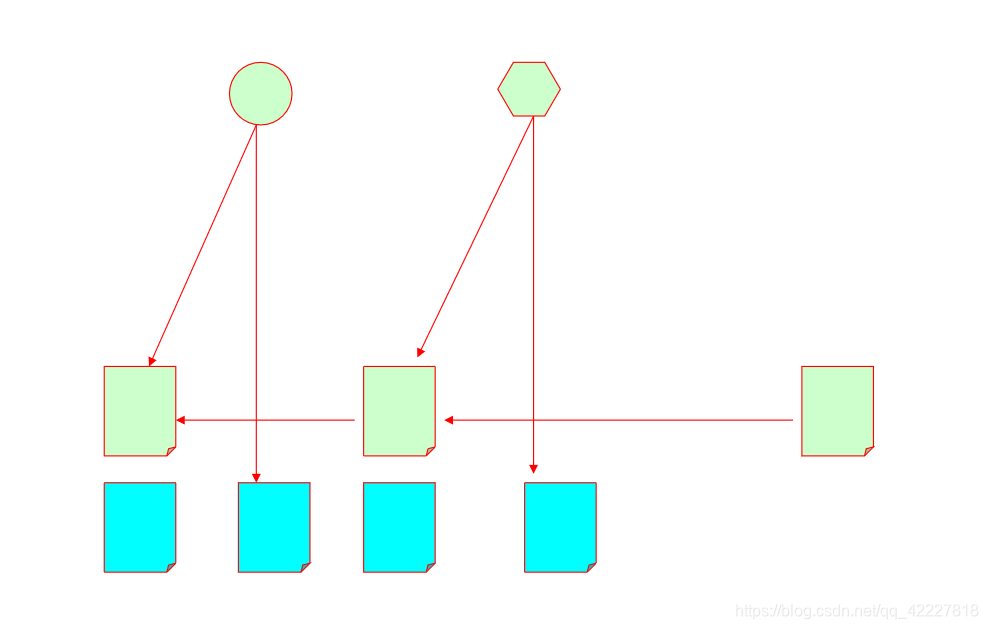
**每一次提交就是保存了某一时刻,整个工作目录的目录路径结构的,和当时文件所处的版本,因为一个文件过去已经有很多版本了,要恢复到某个状态必须要记下某个时刻,你的文件处在哪个版本,整个文件在哪个目录下,
每一个提交都指向了工作目录,有很多子目录,每个子目录下有多少个文件对象,这就叫一个提交对象,也保存为一个对象 **

一样有内容和头部,压缩组成,
提交的注释信息

提交的作者信息

附提交
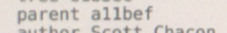
指向哪个提交树

工作目录本身也是树对象
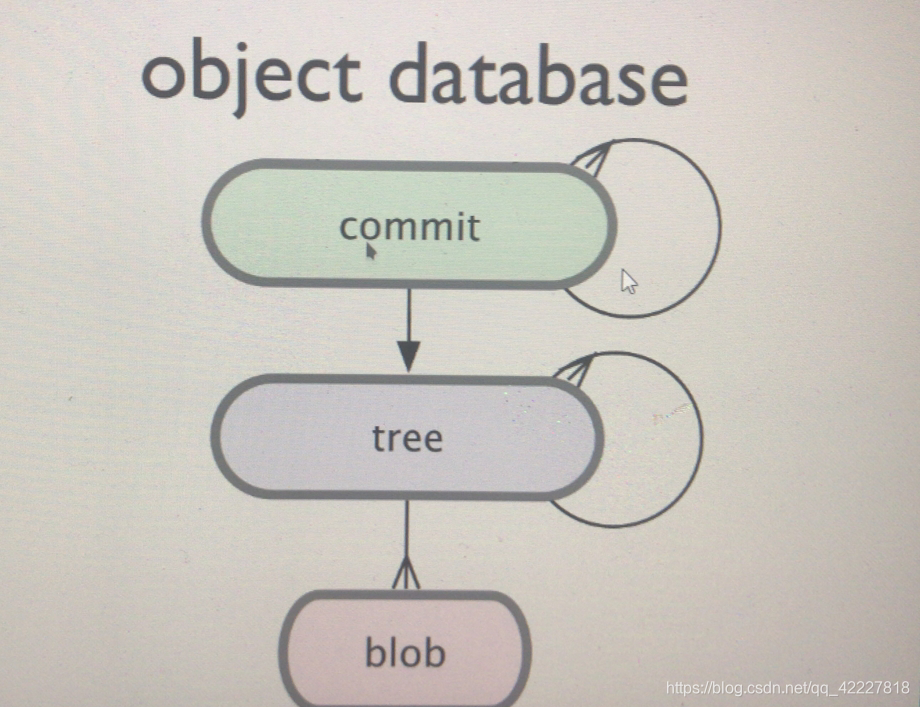
每一次提交都需要指向前一次提交,每一棵树也有此前的状态,树枝下还可以有其他树,每一个树枝下还有一个到多个文件对象
tag标签对象,每一个提交都是哈希格式的名称,所以加一个别名tag,tag本身也是一个对象
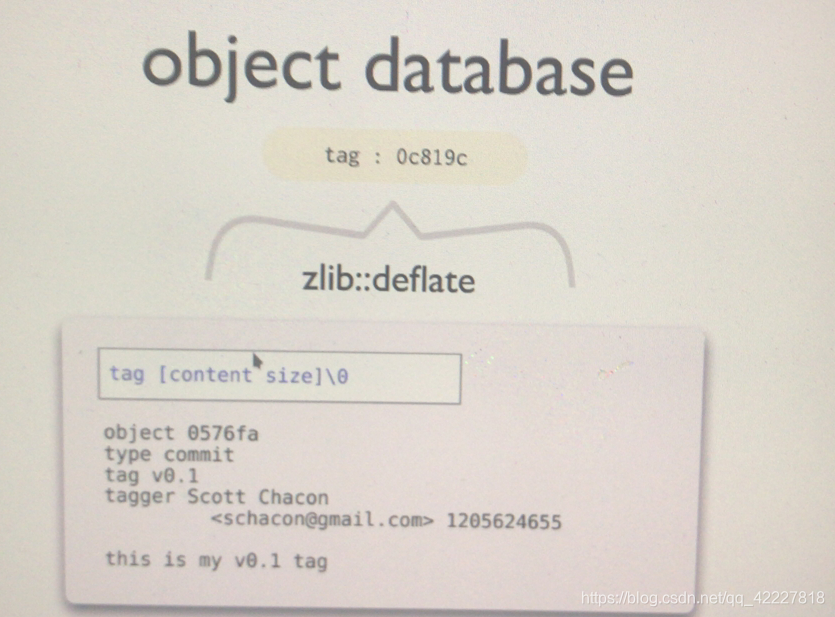
注释

tag是谁创建的

tag自身名称

提交的是0578fa别名

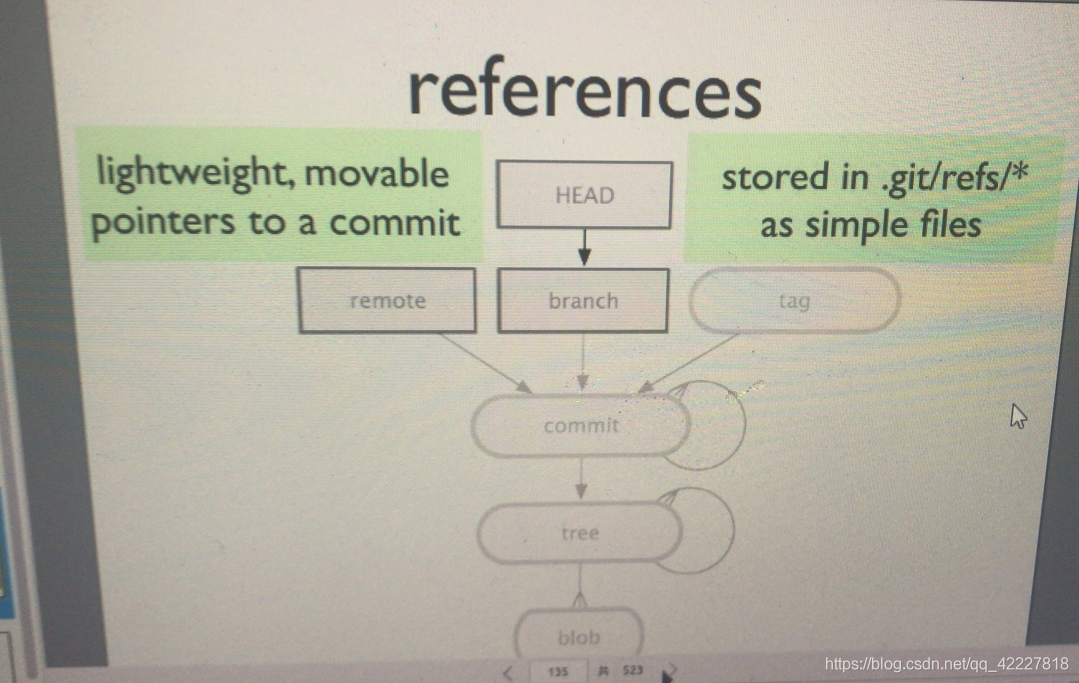
引用references
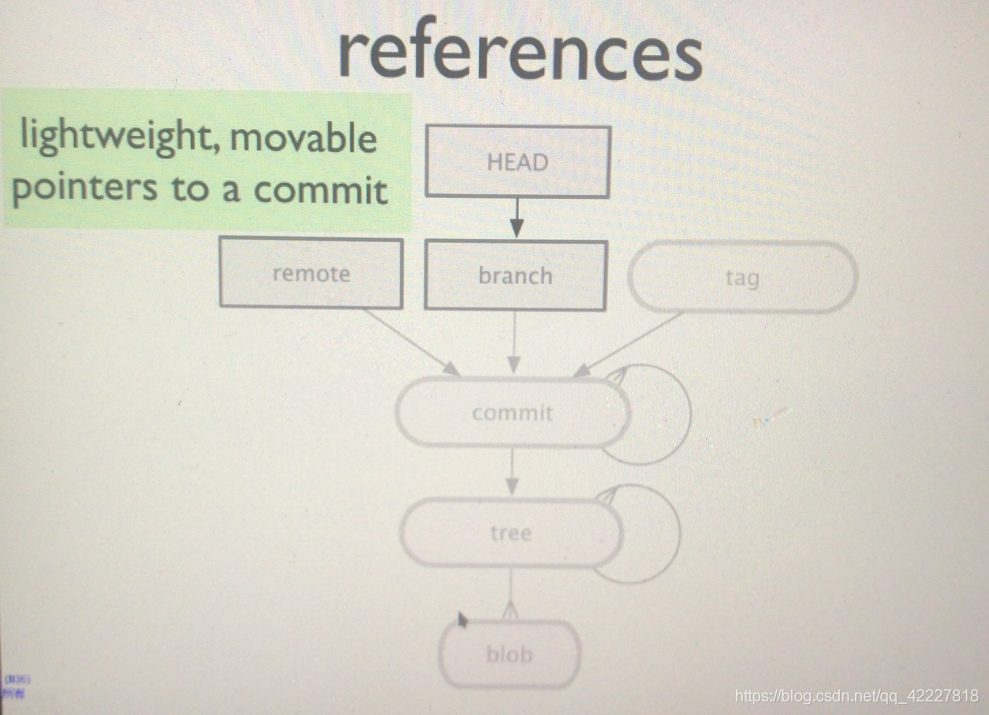
引用是轻量级 的,可移动的,指向提交的指针,
方括号中的是引用,是存储在.git下的refs的任何文件内容,都可用理解引用文件,引用也是指向提交的
文件变化以后,做了次提交,给这个文件叫一个tag,叫v0.1,保存快照以后又改了些内容
每一个都是指向前一次,当前的状态,称为生活的头部,head就是个这样的符号,head 会移动始终指向当前的这个状态

以皇帝三宫六院为例,正宫分支,东宫分支,西宫分支,随着时间轴往前走发生变化
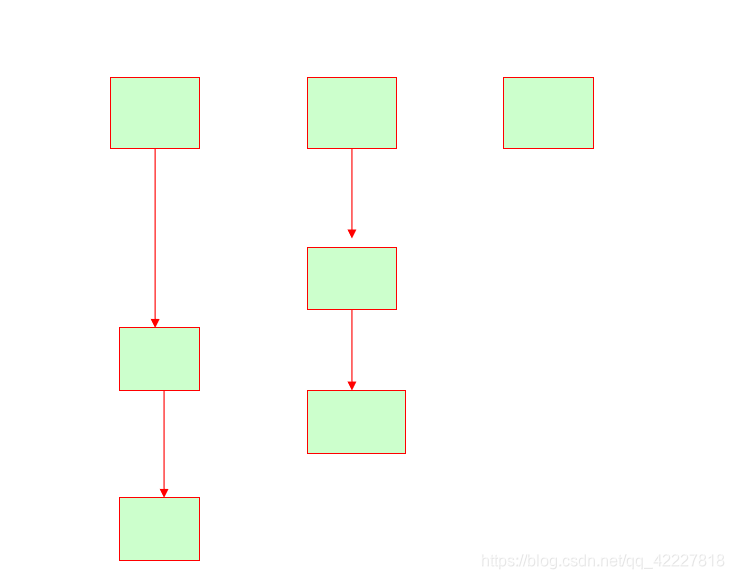 、
、
所以每一个分支上面都有自己的提交,remote 远程分支,属于宫外的
每一个分支当前状态,就叫HEAD,分支有很多,remote 远程分支,每一个分支都有自己的现任,前任,每任都指向一个commit,这就叫应用
对象模型 object module

椭圆都是对象,颜色不太说明是不同类型的对象,blob文件对象,tree树对象,commit提交对象,每一个提交对象一般而言一定属于某个分支
当前分支用HEAD来表示,当前每一个分支的最新一次提交,head的前任,
加入整个内容在提交之后发生了变化,于是就走到下一步,比如,这个文件对象发生变化
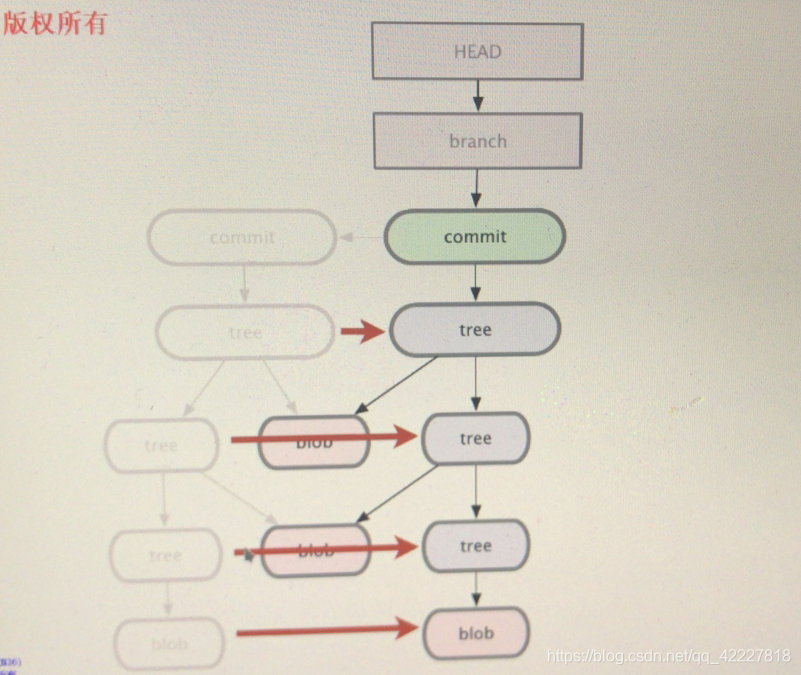
这个blob变化,tree就发生变化,上级tree也发生变化了,任何内容变了,所在的目录内容也一定变了,内容变了,目录文件名也一定会变,所以一个内容发生变化,向上这一支都发生变化
这一个体系最底层到tree节点,到整个工作目录节点,每个目录,每个层级都发生变化,因此,都做一次版本演进,各个tree已经不是此前的tree再次作快照的时候,把快照的结果状态,第二次提交,把指向的跟tree,已经发生变化了
每一次提交都是保存你当前的树对象和整个,路径状态,只要有一个文件发生不变化,向上追溯到整个工作目录的每一个
目录都要发生变化
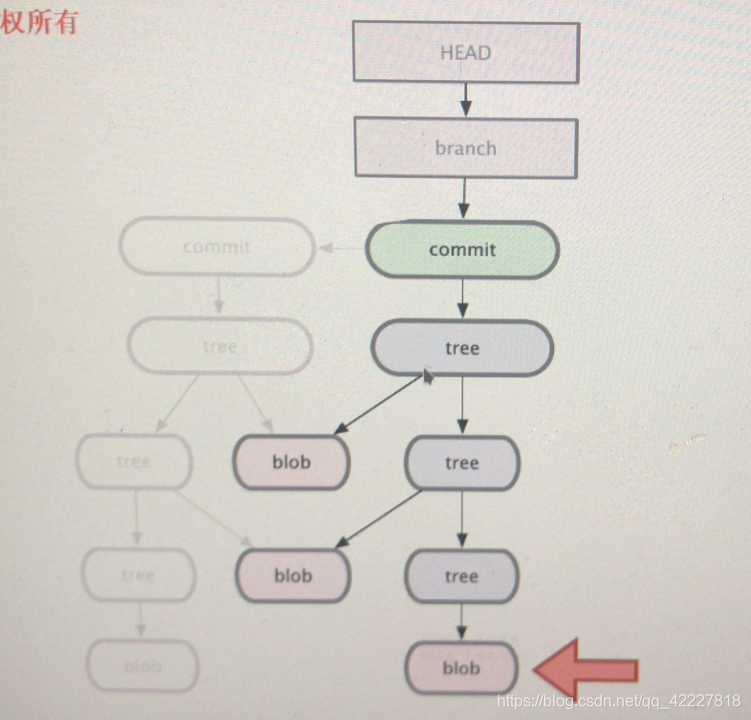
再一次演进,就到下一步,又一次发生变化,blob,发生改变】
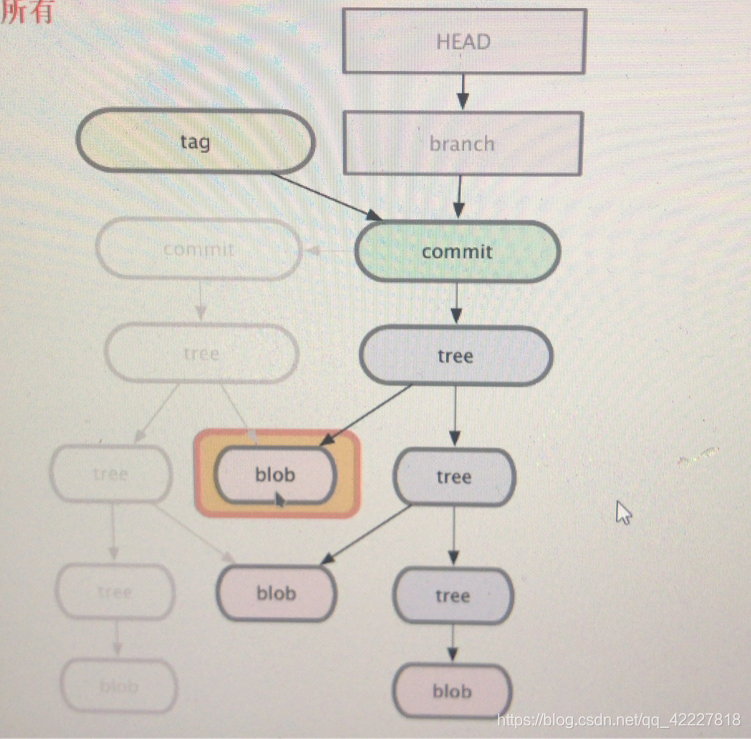
不变的,就不动,tree下面对不对,commit指向新的树,每一次提交跟都会变的
blob发生改变,但是下面的子目录没发生变化,还指向原来的子目录
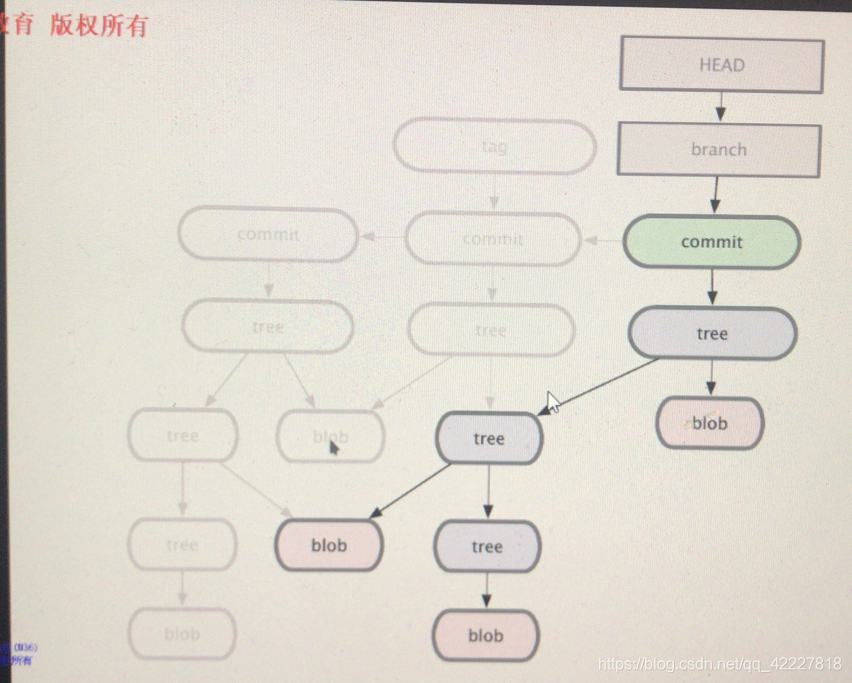 每次都保存快照的部分,这就是一个提交
每次都保存快照的部分,这就是一个提交
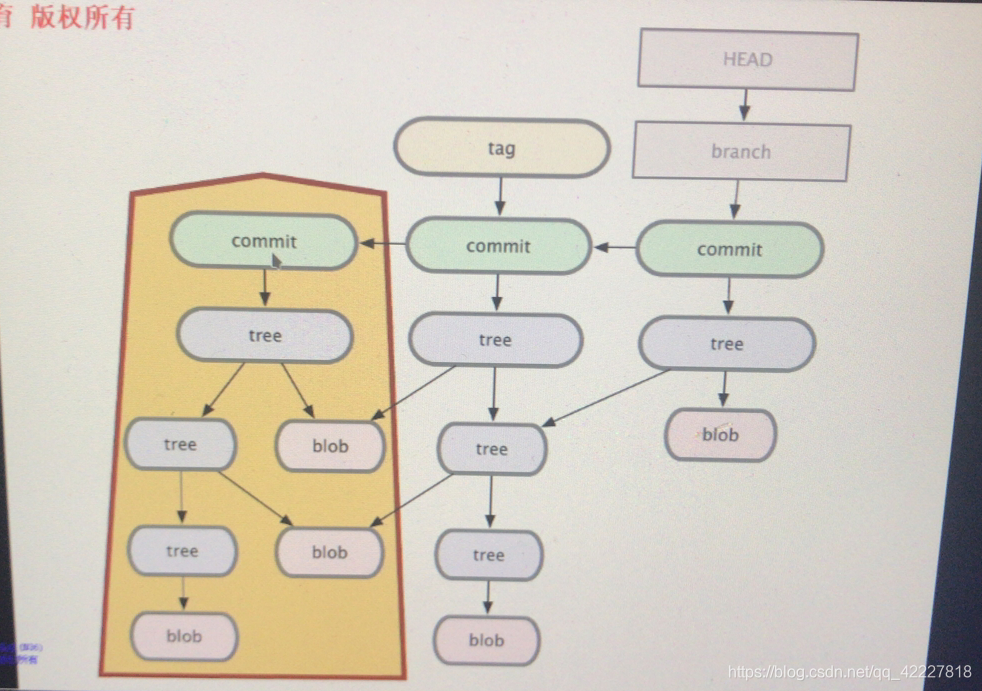
第二次提交
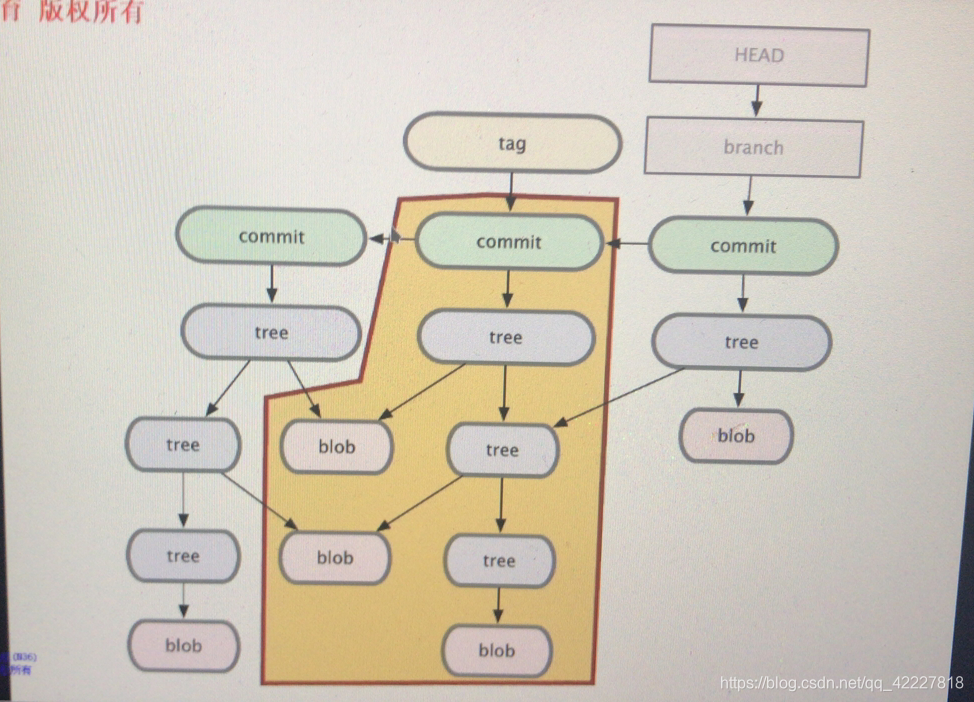
第三次提交保存的状态
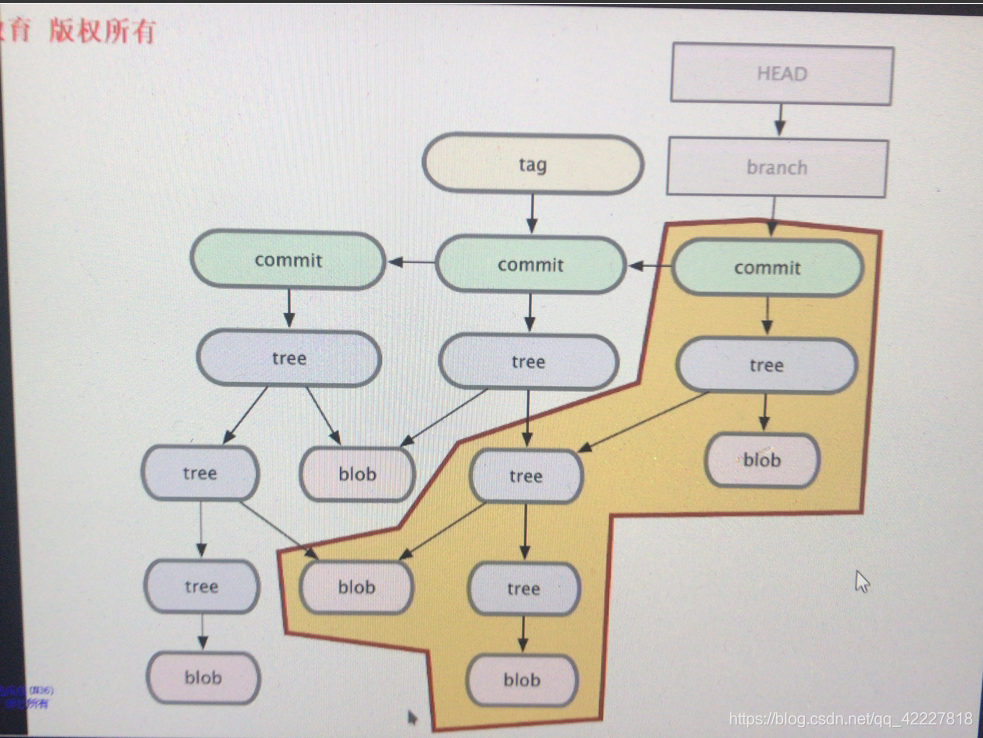
head是不断在变化的,随着commit不断的在迁移,为了引用过去提交,就是去引用tag


















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









