








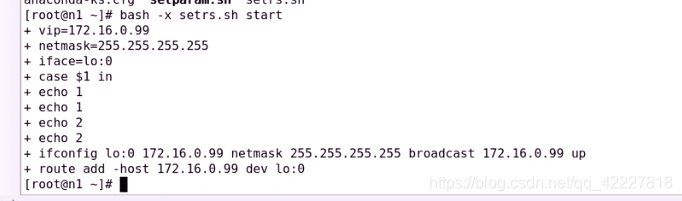
在VRRPS当中有几个参数
当主备发生变化,现在邮件未必会通知的
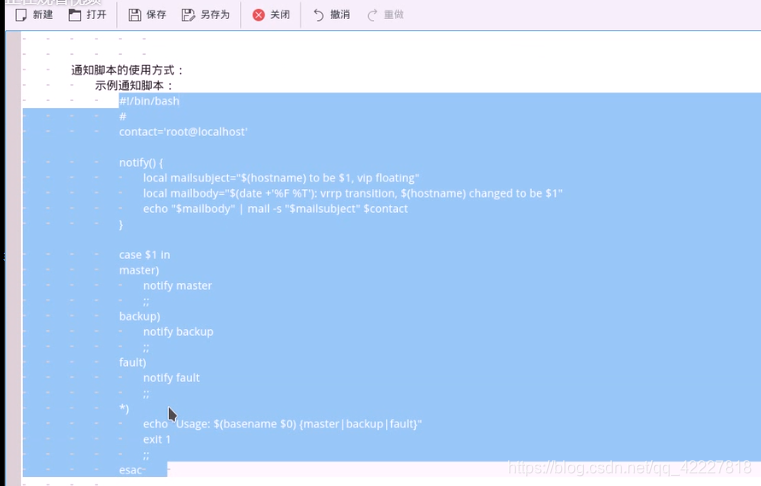
要想快速通知管理员,不妨在notify这里,自定义的脚本来完成警告
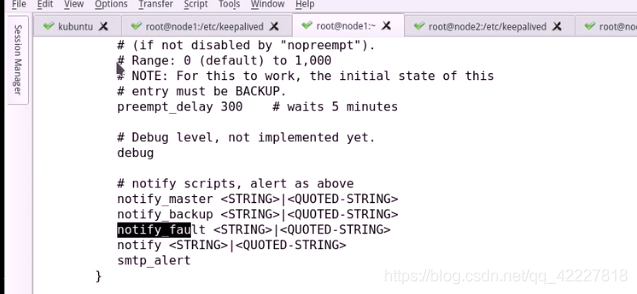
这个脚本编写是非常容易的
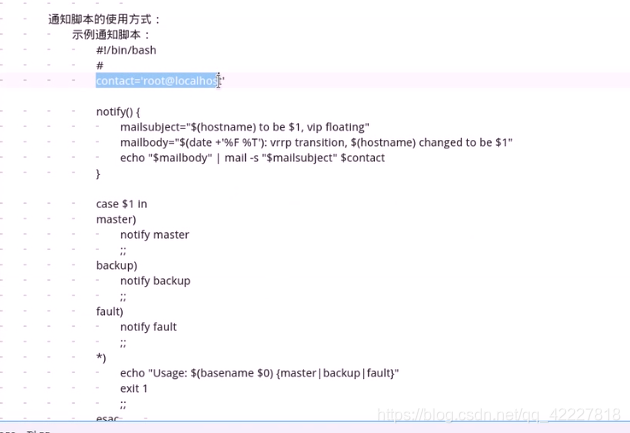
contact设置联系人,notify自定义函数,$1表示函数可以接受参数
mailsubject设定变量是作为邮件标题的 (hostname)当前主机变成什么状态,就发生了流动
mailbody 邮件正文,在这个格式,VRRP发生来了转移
经过网络的就需要用python来写
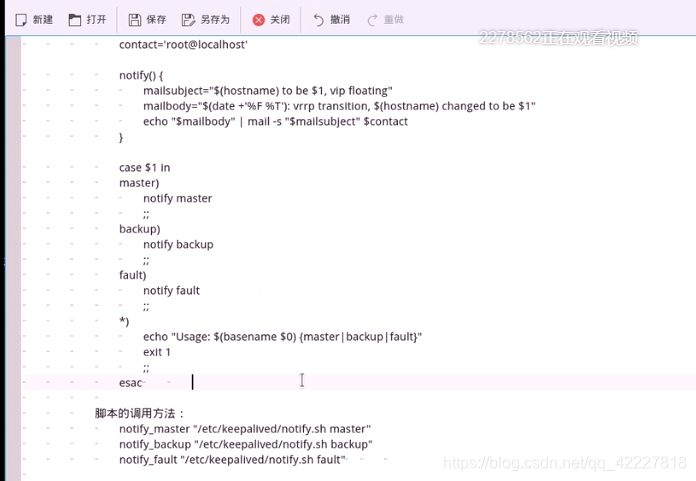
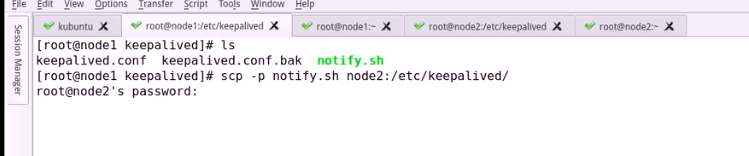
这个脚本放在1节点
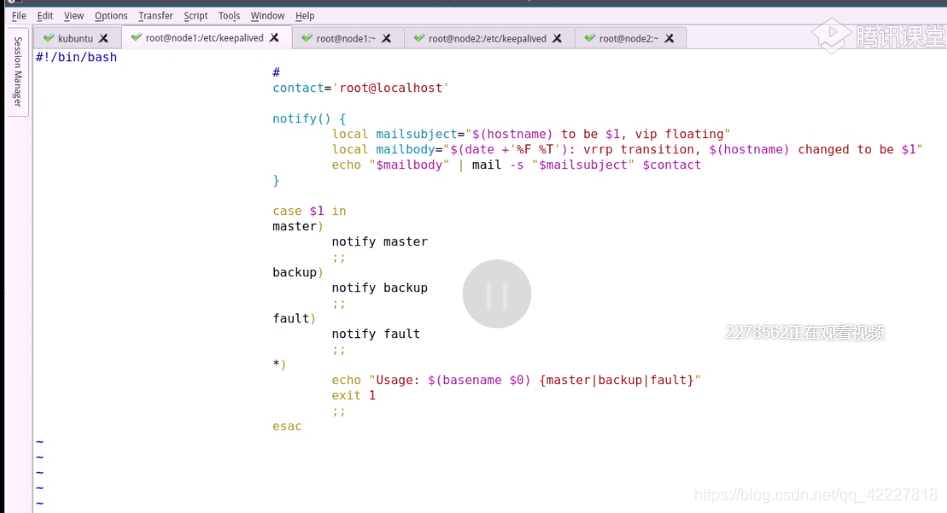
给执行权限,再加上 语法检查

手动调用试试
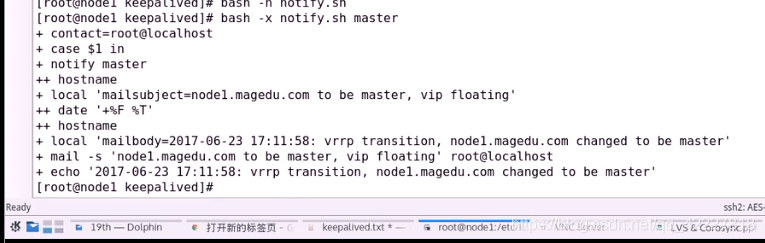
我们的mail就收到了一个消息

还可以测试一下 backup
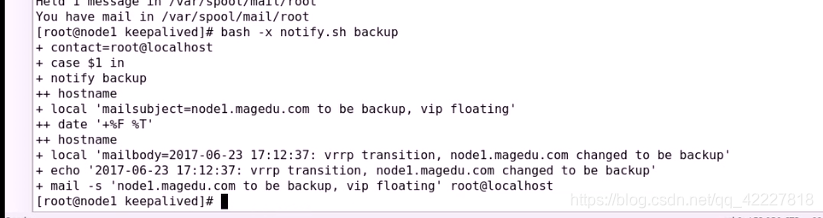
收到邮件

内容也变成了backup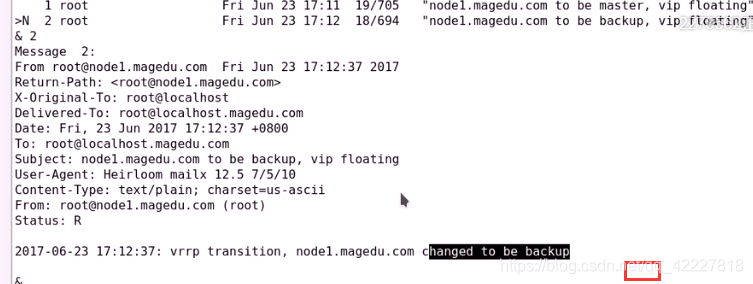
另外个主机也需要这个脚本
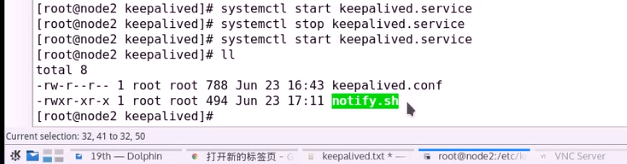
现在就可以调用这个脚本来完成通知的
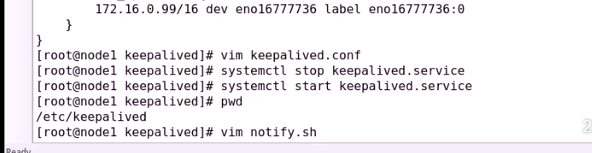
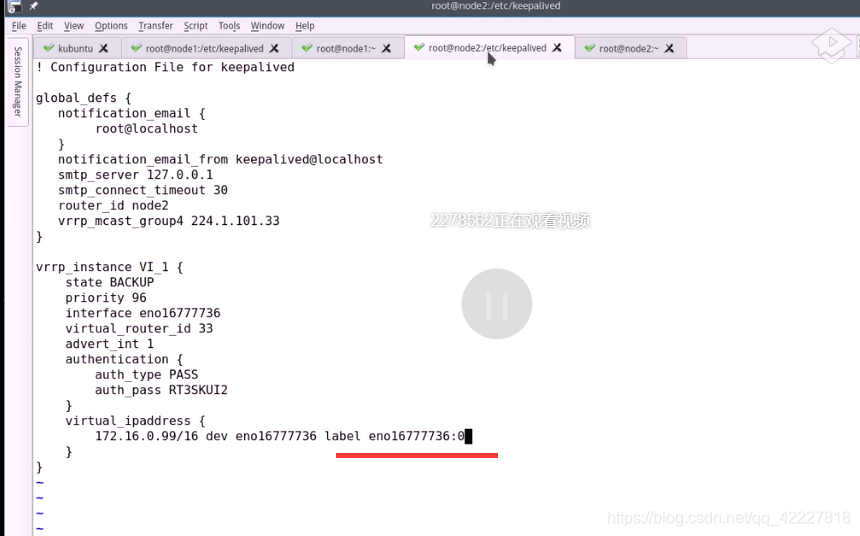
先双重佩芬文件,DUAL双重

先不使用双个虚拟路由

把第二个路由给删除
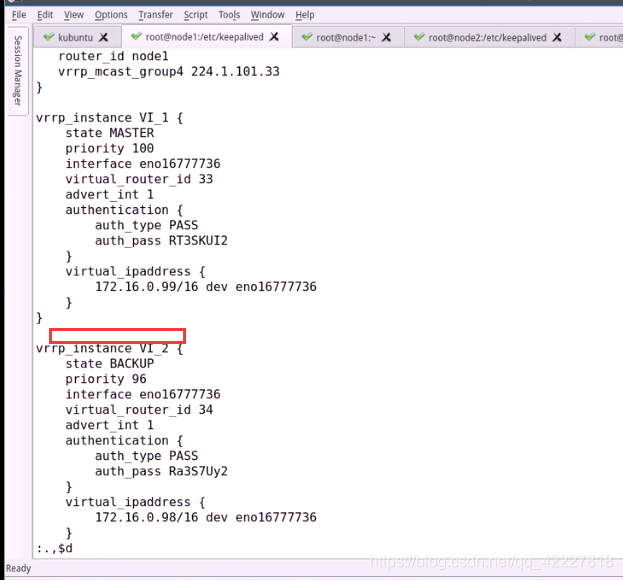
在第二个节点也是先删除,然后都起一个别名,看的清楚一点
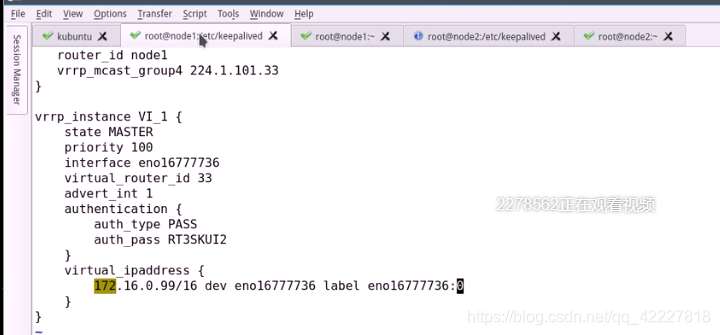
在这个实例内部,再添加另外几条指令

notify_xxxx +指明调用哪个脚本路径
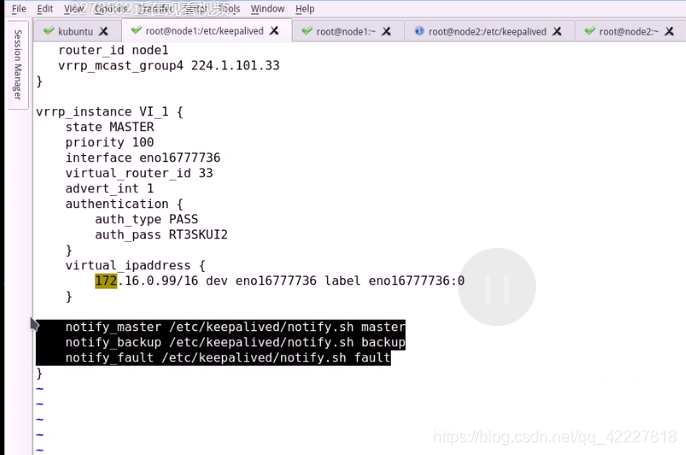
在节点2上也加一下
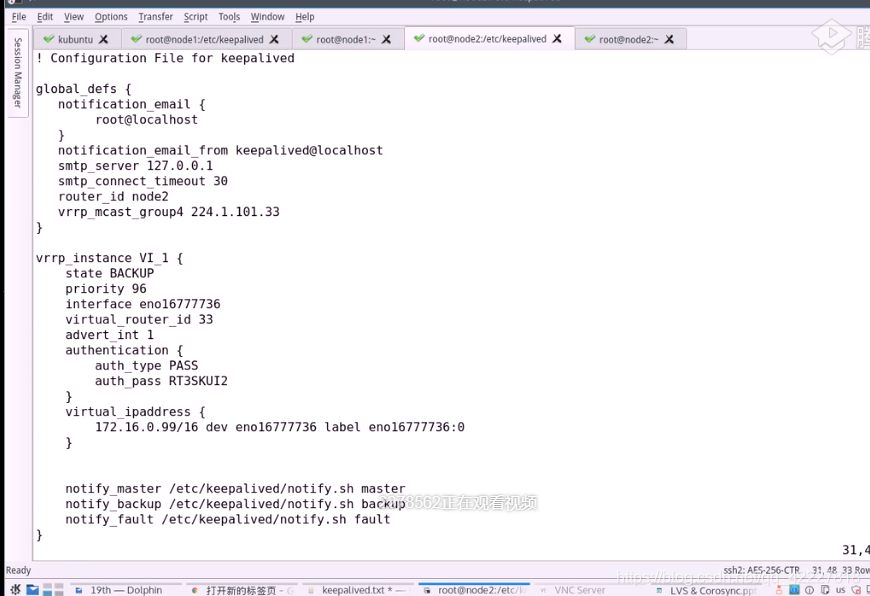
先停止服务,再启动


先启动一个节点看看

查看状态
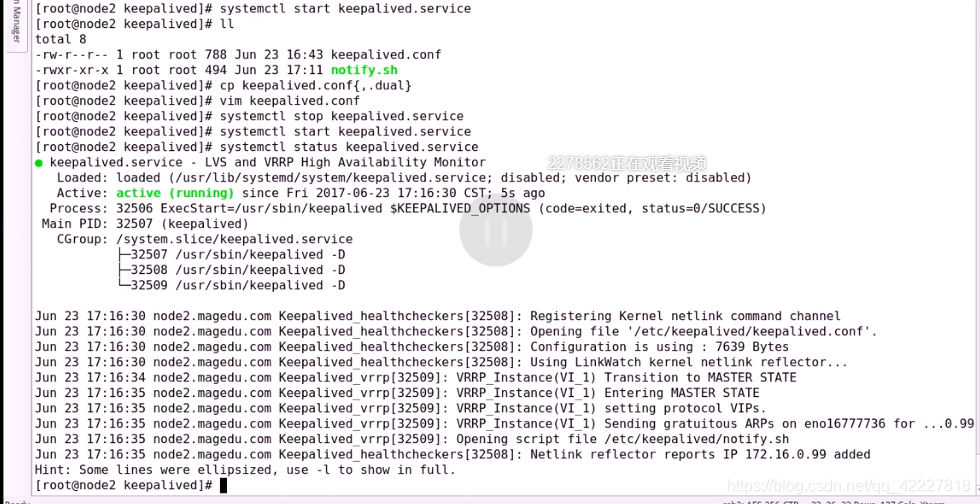
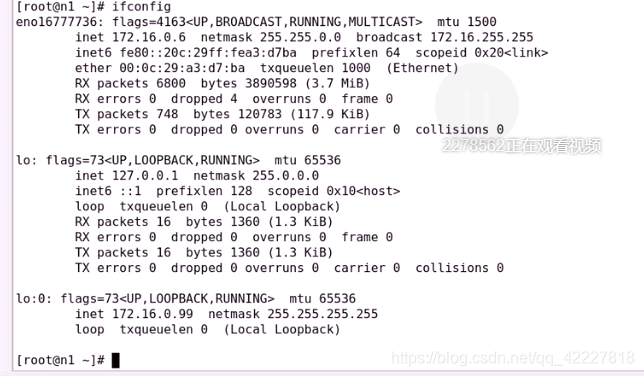
已经配上地址了
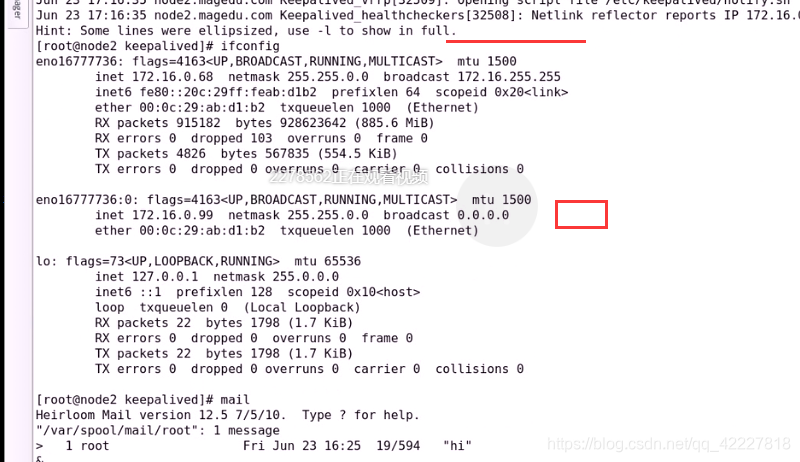
mail,可以查看邮件,还没发生,等节点1启动

现在应该转换备模式了,再次使用status来查看状态
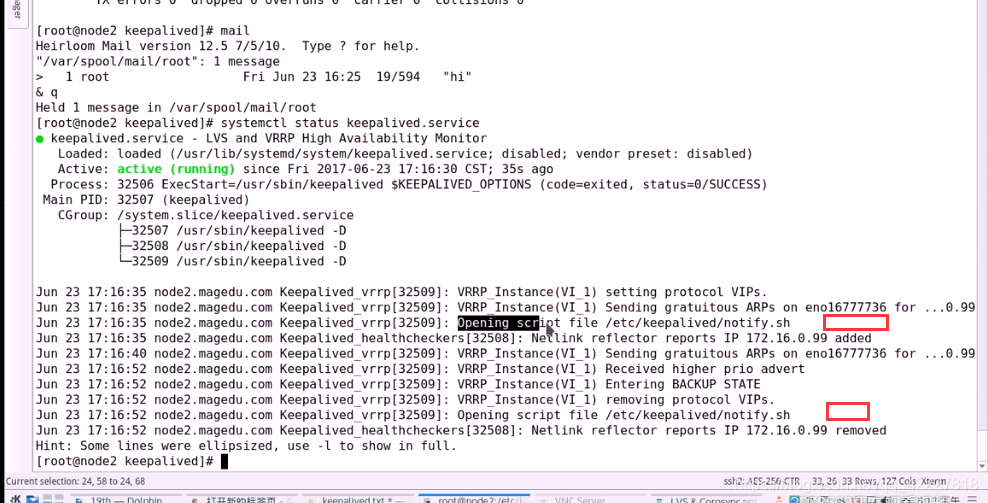
按照道理正常执行了,但是邮件可能没有发出

查看邮件日志没有

节点1也么有邮件,说明邮件没有发送成功

邮件没有发送成功,应该是写脚本有一些语法错误了

应该需要加上双引号
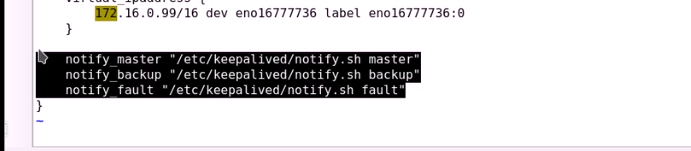
节点2上也需要修改
还跟刚才一样,先停止服务


启动以后查看有没有触发脚本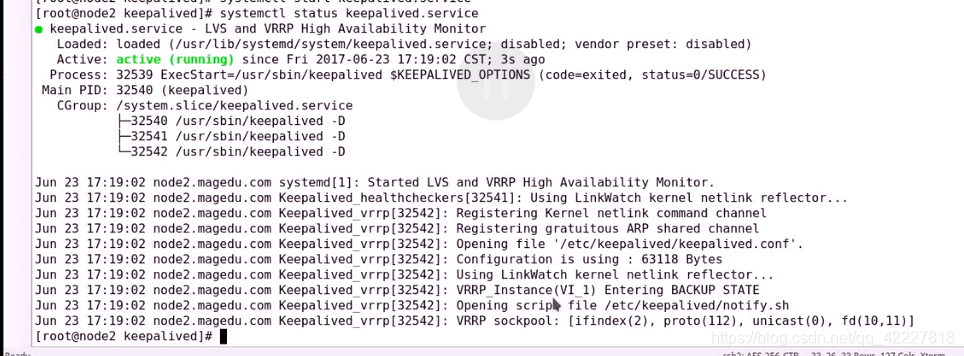
现在就成功了,自己启动是backup(节点2定义的),由于没有更高优先级的通告,就自动 为主节点

节点1现在启动

就看到收到了邮件,结点2恢复到了backup
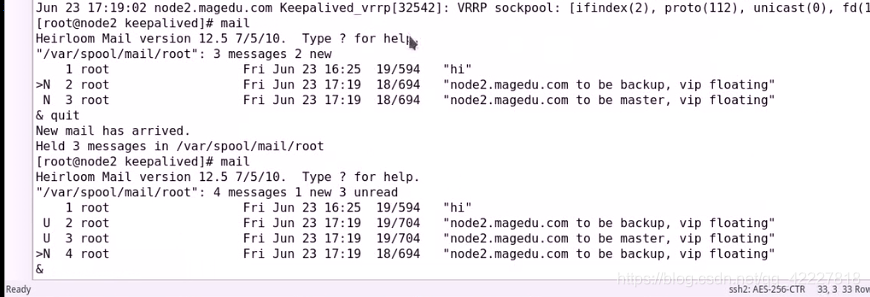
节点1也收到邮件自己变车主节点的了
这就是自定义脚本

keepalived的高可用设计就是ipvs,能够通过自己的checkers,对于指定的ldirectord的lvs的集群的后端RS做健康性检查,而且监测成功的所有主机,都会被直接放进ipvs的当中,从而实现ipvs的高可用的
接下来按照生产环境的案例方式来也暗示一部分功能的实现
构建DR类型集群
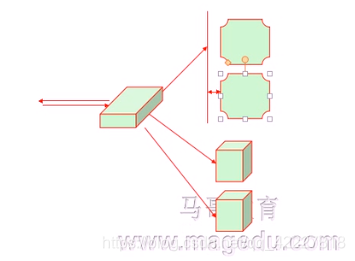
node-1,node2作为directord(一主一备direct)
再找两台主机 当RS 0.6和0.7 当webserver

 同步时间
同步时间


写一个网页


n2web服务器也要写一个网页


启动服务

用node2访问看看

还需要配置一个VIP,写一个脚本
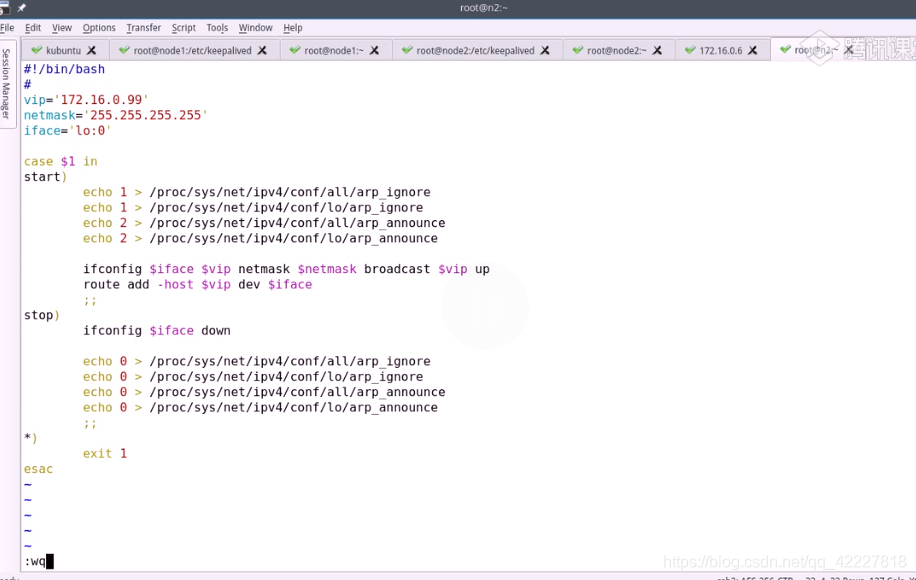
检查语法并且执行
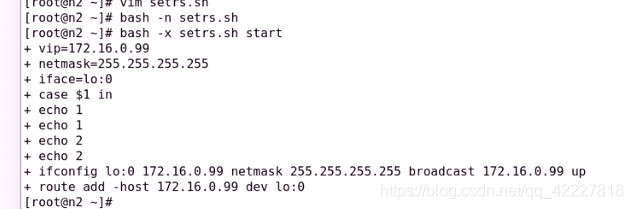
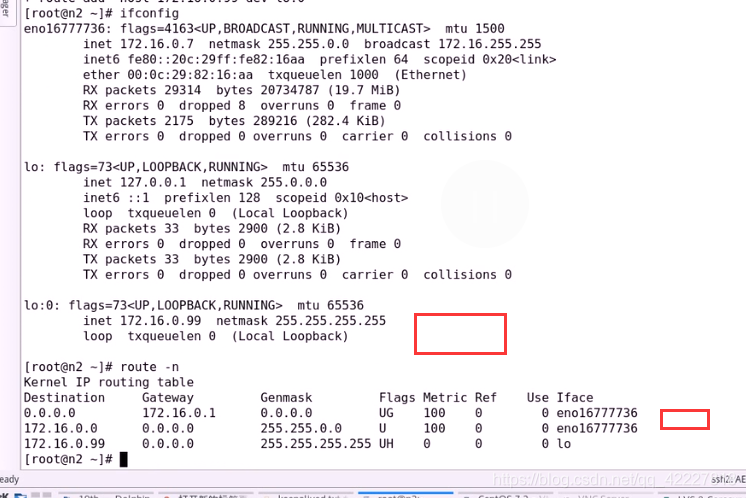
把脚本复制到0.6


现在两个RS准备好了
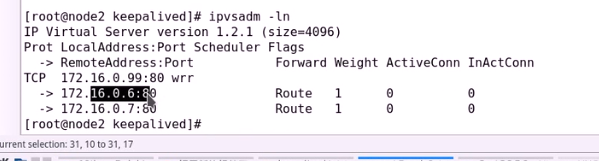
接下来两个direct 生成规则就可以了,要使用keepalived自动生成,不用安装ipvsadm命令行来生成
现在安装只是查看规则,不是用来生成规则的


如何来生成规则,修改配置文件

用VRRP实例之外来定义虚拟服务器
查看定义虚拟服务器的方法
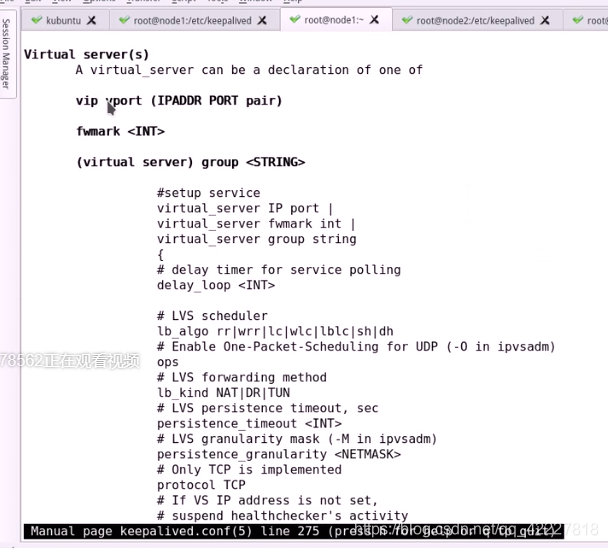
只支持tcp协议

也可用防火墙标记 fwmark
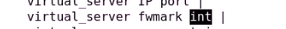
调度算法

集群类型,NAT,DR,TUN

持久链接

虚拟主机 名字

对后端服务器监测等待多长时间
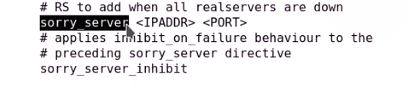
sorry server服务器的地址
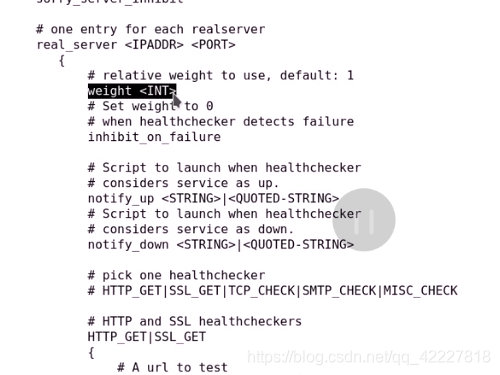
rs部分,权重
变成上线和下线,会用脚本来进行通知

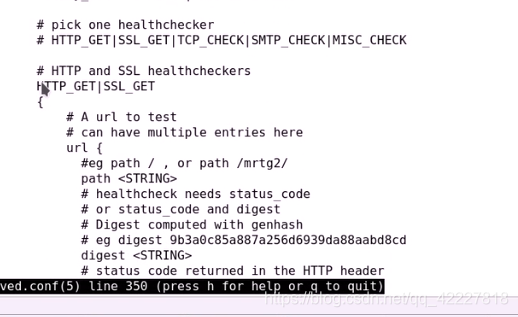
如何来对RS健康监测
HTTP_GET,SSL_GET这两种需要webserver才可以,应用层监测
smtp_check就要使用smtpserver来进行监测
如果不支持应用层监测,可以用TCP传输层来监测,检查端口在不在就可以了
如果都不想上面的方法监测,还可以用misc_check检测,(监测逻辑自己定义)
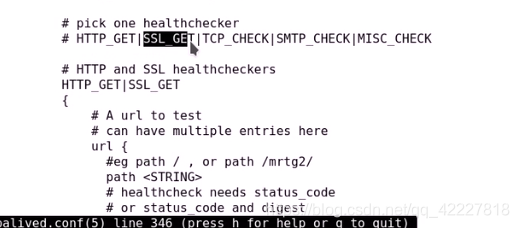
url请求,恢复上面响应码才算正确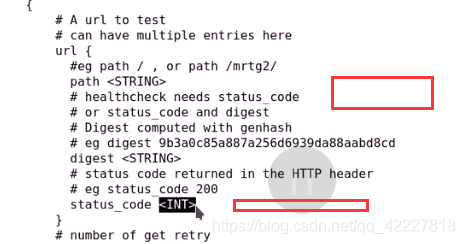
还能对url的请求做校验码,一般用状态码

要重试几次

每次重试的时间

如果不想向后端的RS发送请求,还可以指定链接的主机
多长时间链接超时

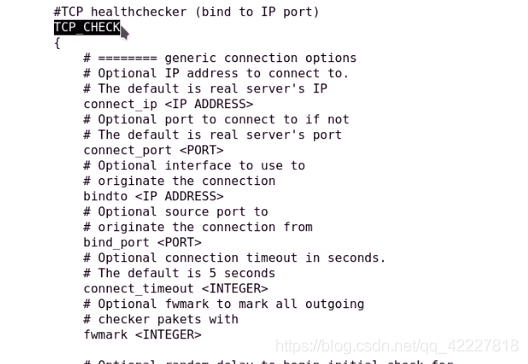
上面是应用层监测,如何做tcp监测呢
tcp监测最终要的监测就是链接超时时间
自定义脚本监测,可以写路径
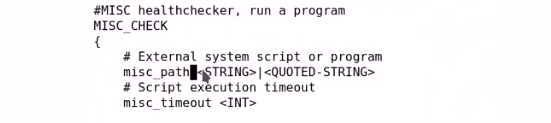
状态码是多少成功,否测失败

后端所有RS的权重加起来至少大于等于这个数字,才认为集群是正常

满足不满足可以发个通过

再node1上配置一个sorryserver服务


另外一个节点也可能称为主节点,就也需要配置sorryserver服务


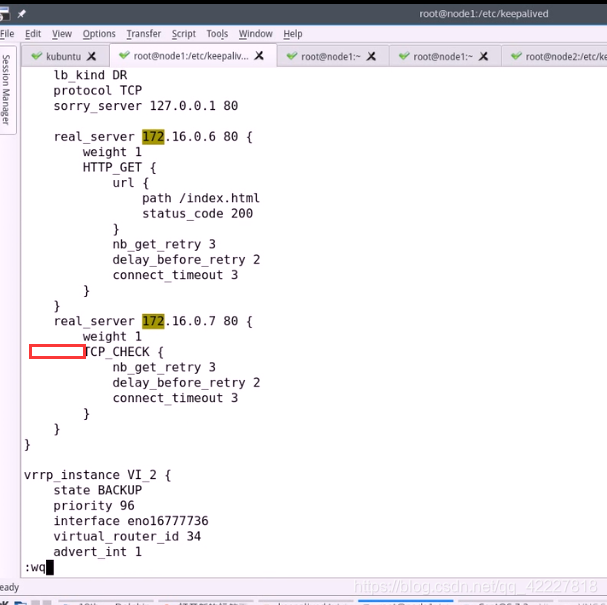
接下来配置real server
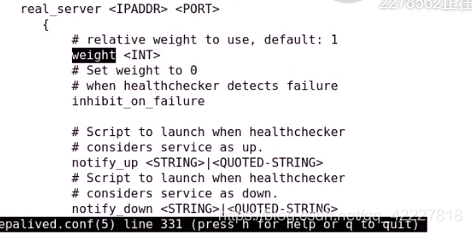
用哪种监测方式
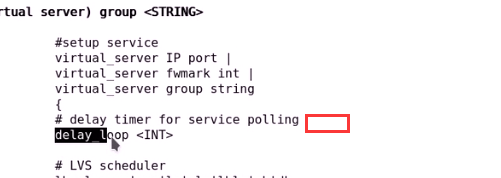
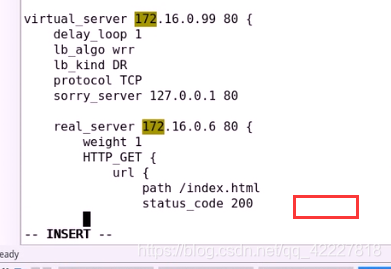
delay_loop 1 每隔1s时间监测一次
lb_algo wrr 调度算法是wrr
lb_kind DR DR模型
protocol 协议只能支持tcp
sorry_server 本机
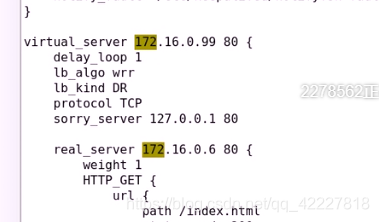
RS 地址
weight 权重
HTTP_GET 用什么方式检测
可以指明对哪个URL发送请求
定义状态码,只有认为200是成功的
通过管道可以传给genash生成校验码
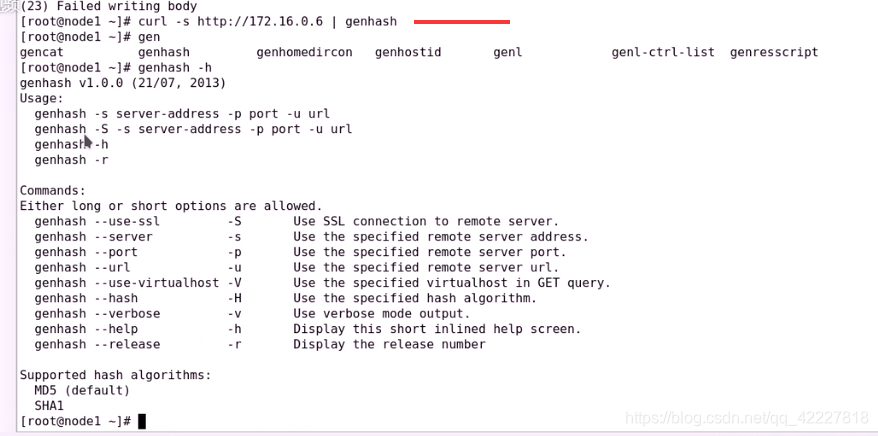
这样就可以生成一个校验码了

也可以使用genhash

需要尝试几次来检测

每次重试之前要延迟多长时间


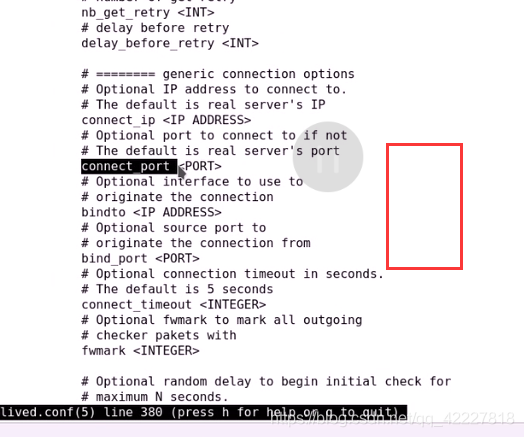
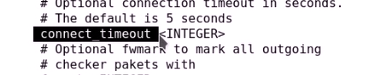
真正发起链接请求的链接超时时长叫connect_timeout,默认为5秒

定义成3秒

这就是对http_get做健康性检测,就定义好了
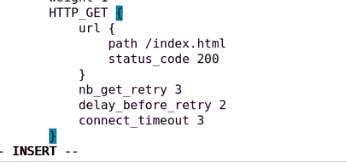
node1的第一个RS就定义好了,
.,$y从当前行到最后一行复制,
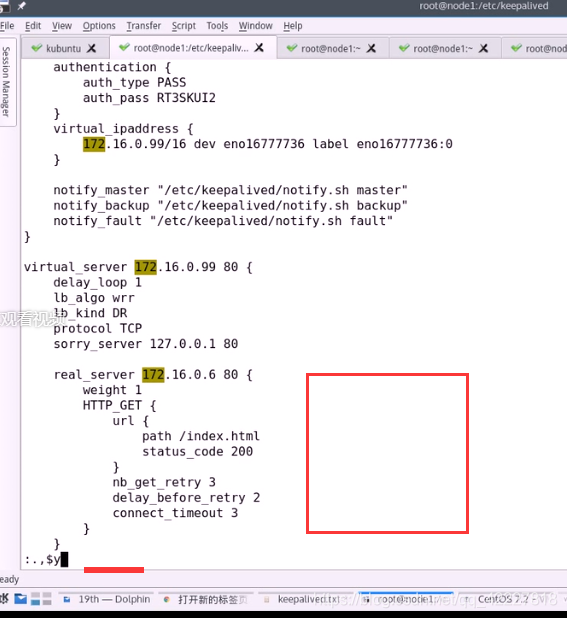
定义RS2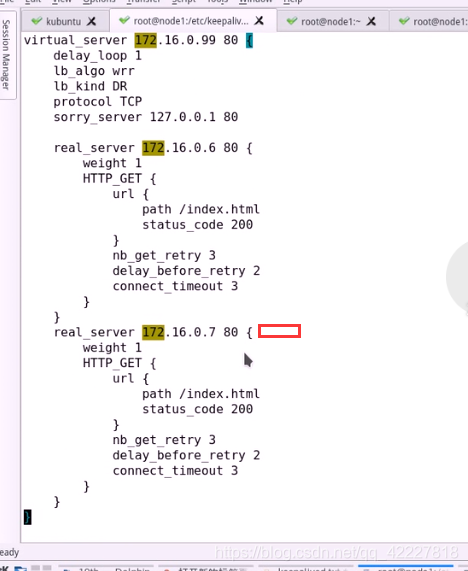
在第二个节点配置

内容于node1的一致
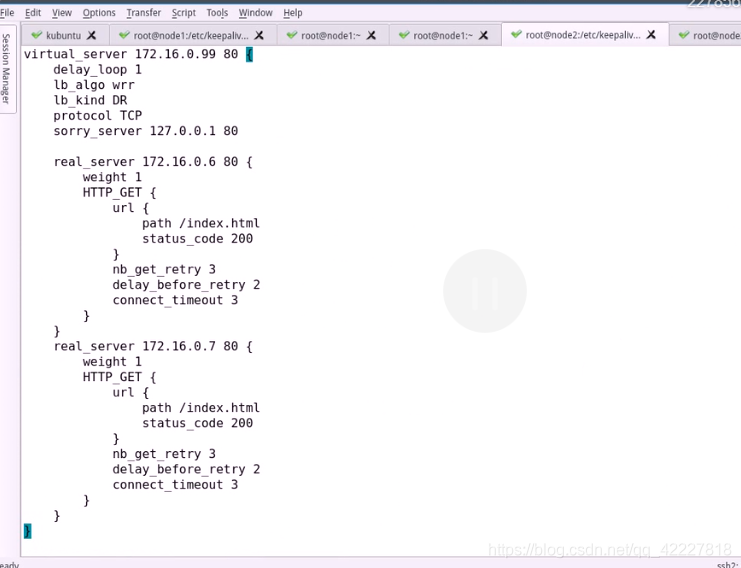
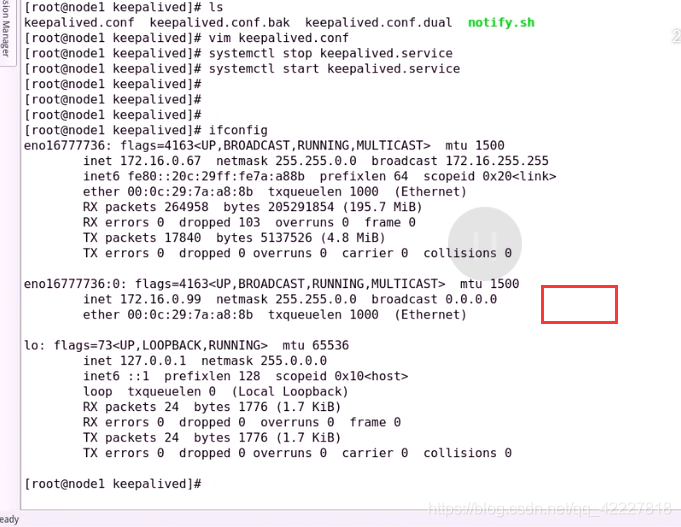
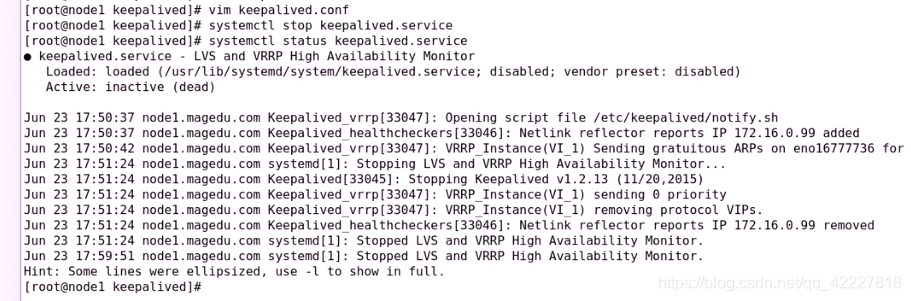
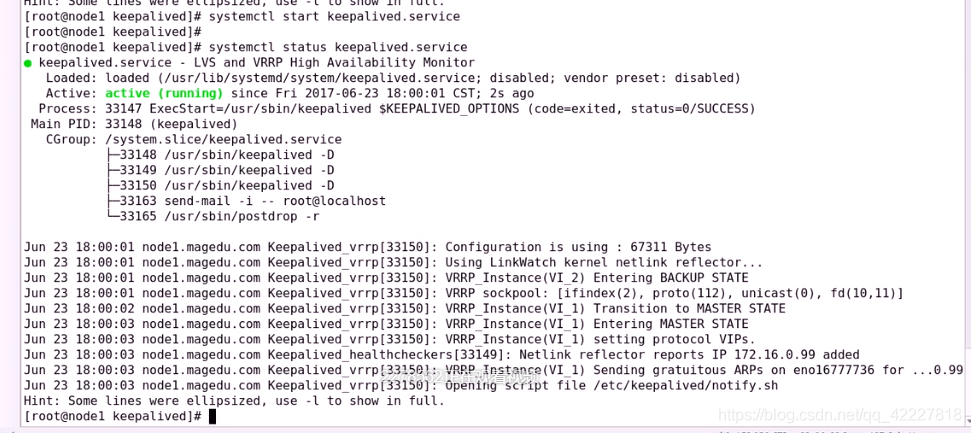
先停止服务,再启动服务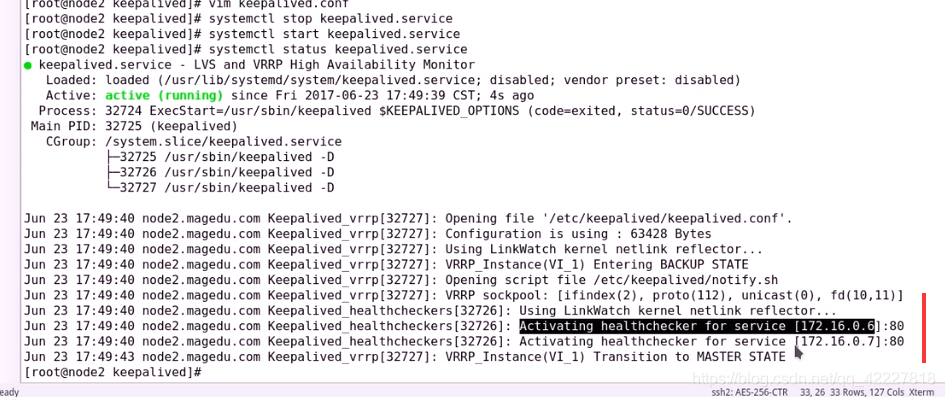
已经激活了RS
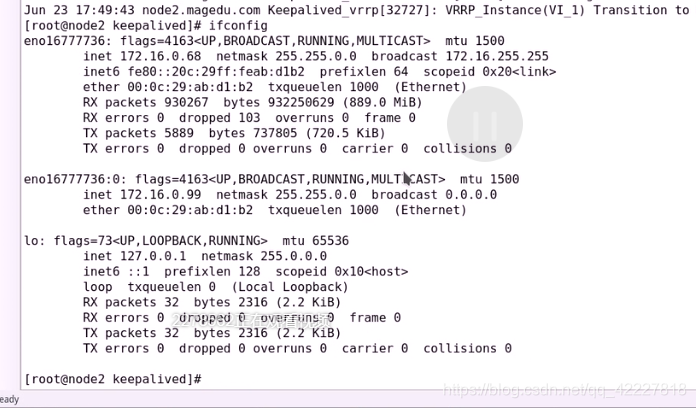
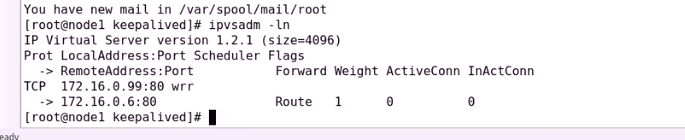
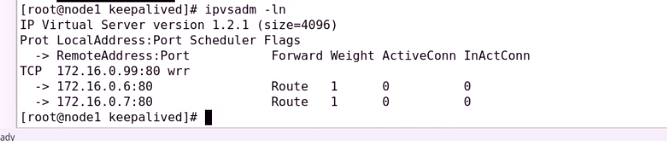
查看一下规则
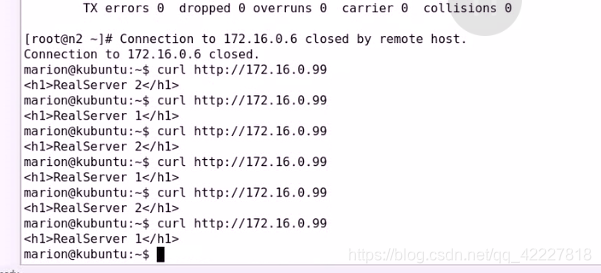
接下来启动node1
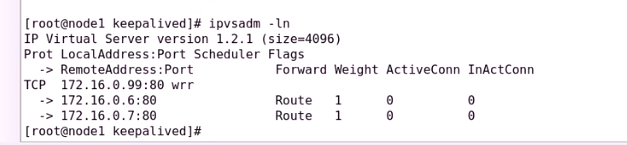
node2的集群服务就被劫取去了
现在做一个双主模型
先停一个服务

停的时候,对于客户端来讲是不受影响的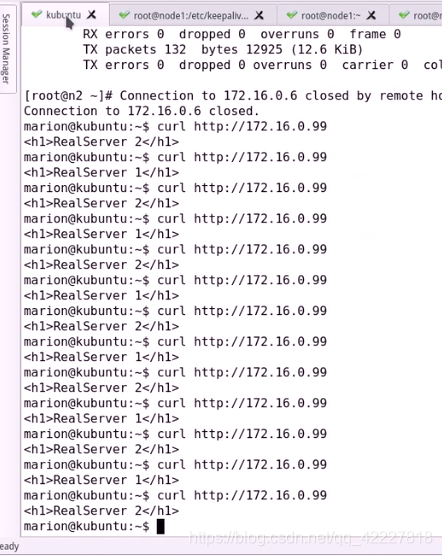
如果把后面的RS主机宕机一个

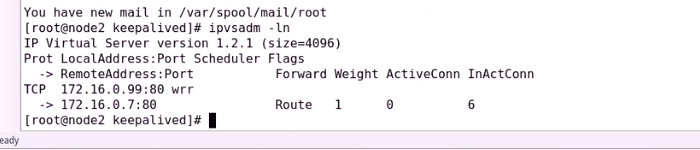
现在把另外的主机也宕机了

sorryserver就上线了
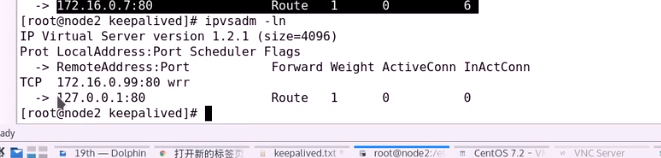
客户端现在访问的就是错误页面了
启动RS1服务

就复活了

启动第二个web服务

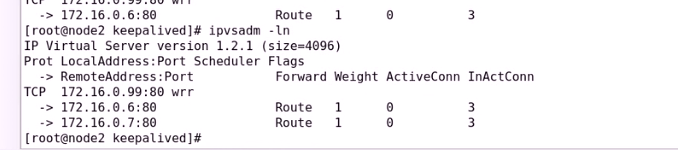
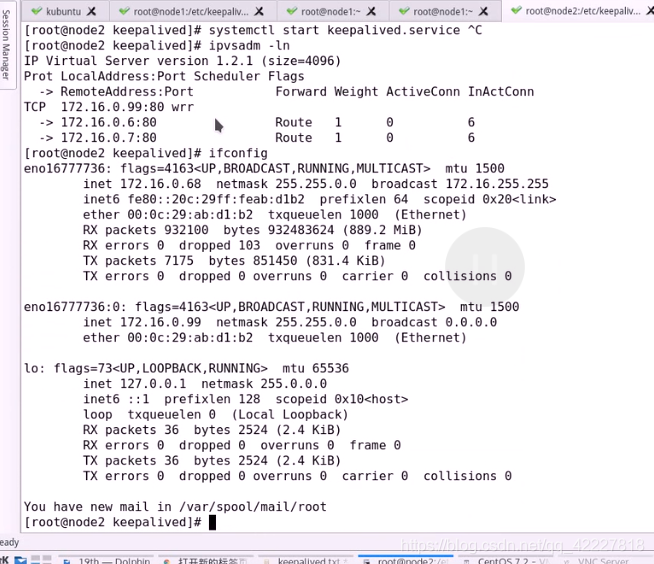
接下来查看双主模型

修改配置文件
把当前到最后一行到重定向到配置文件里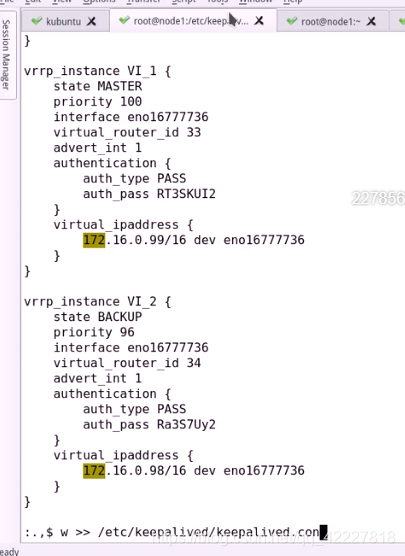

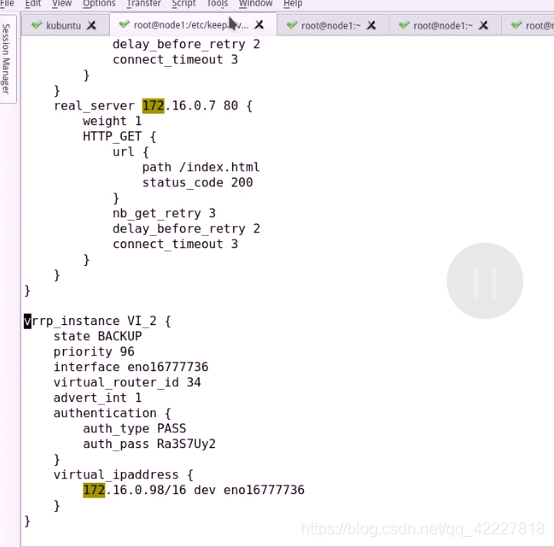
现在修改node2

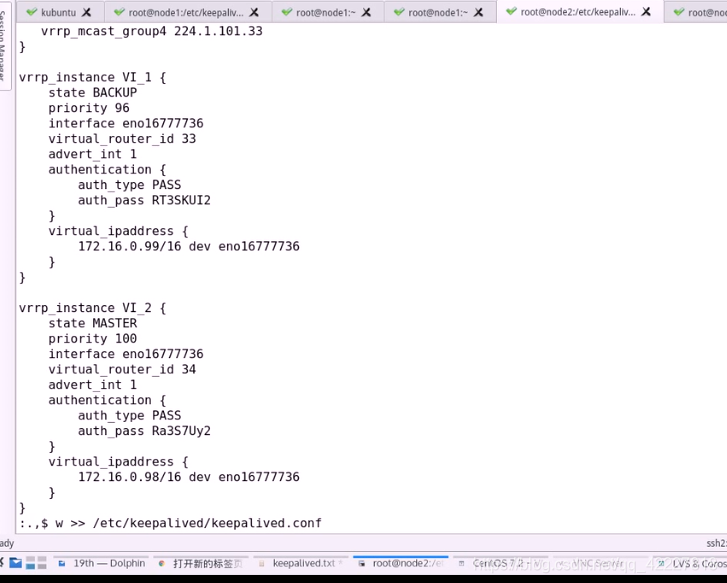

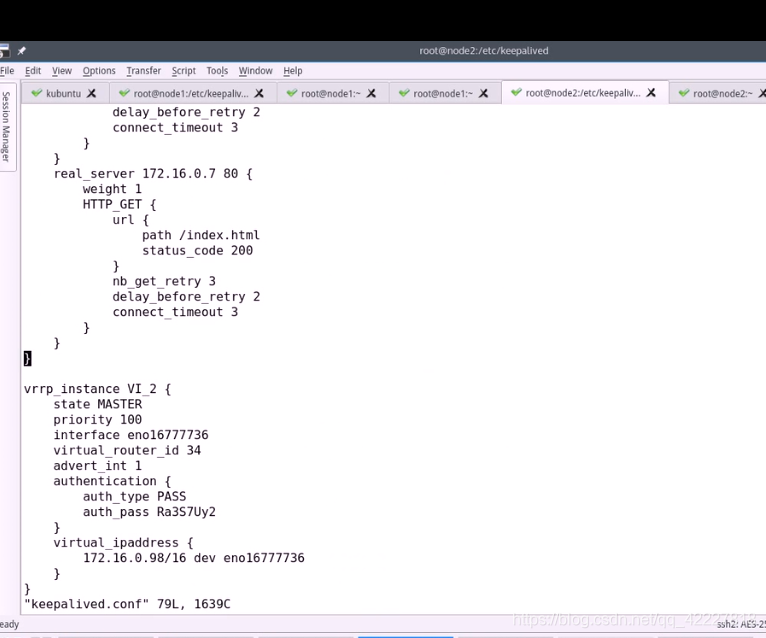
启动服务
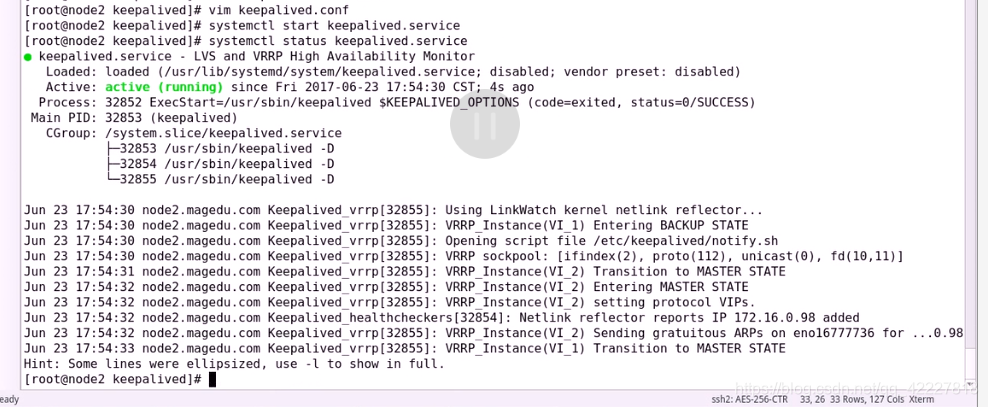
两个主现在都加进来了
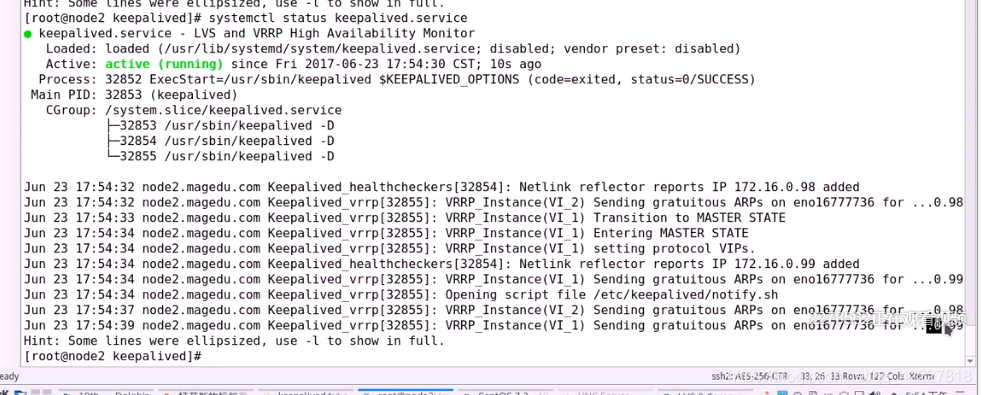
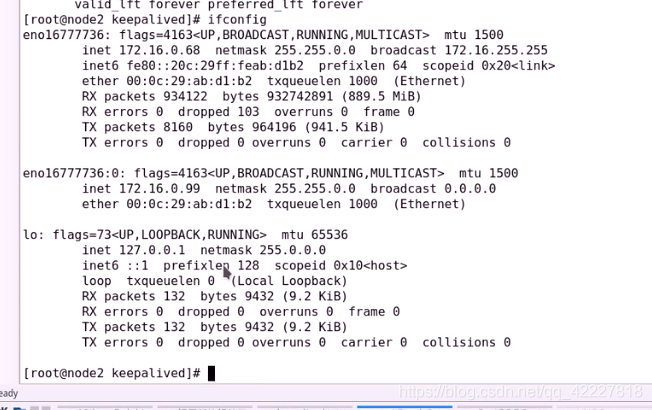
只能看到99,因为99是 别名,ip a l 可以看到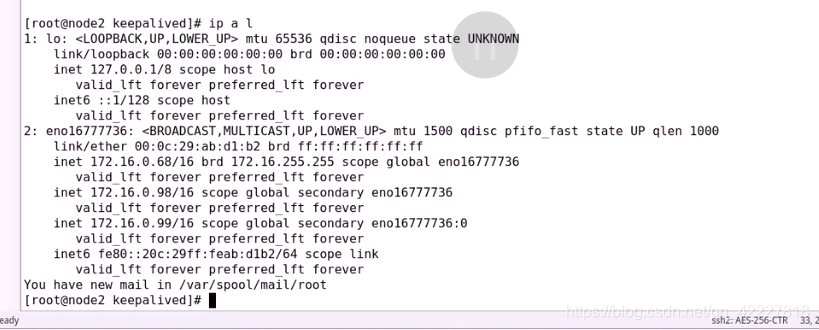
客户端对99发送请求
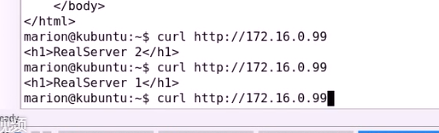
对98发送请求
因为没有写对应98的后端RS的VIP


没有定义98的集群服务,直接照着样子定义就可以了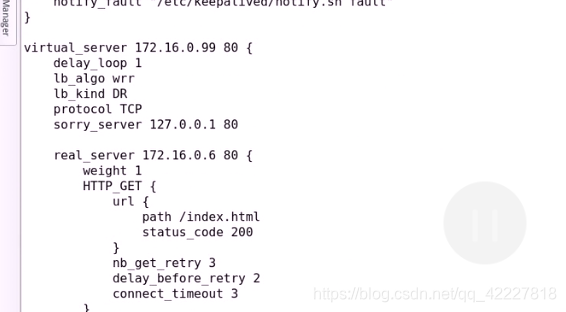

基于tcp协议做监测
只需要一个选项,connect_timeout
先把服务关了
再启动

如果现在把0.7主机宕机

检测成功
再启动服务
 、
、
检测成功
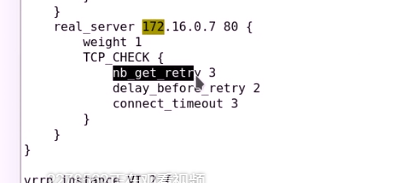
每隔多长时间试一次,每隔多长时间试一次,超时多少时长
这就是tcp常用的方法
也可以定义RS脚本,RS启动就发邮件表明上线了

keepalive高可用nginx需要调用专门的接口



















 1645
1645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









