







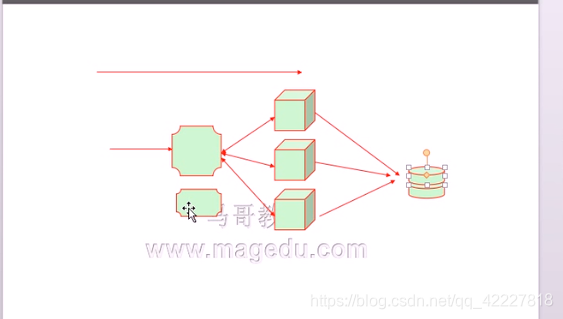
负载集群的调度器试整个集群的单点,整个节点出来故障会导致整个集群不可用,应该给调度器做冗余
,节点也要对后端服务器做检测,任何一台主机出了故障,也能把请求调度到其他服务器上去,如果不考虑调度器故障,的确提高了整个集群的承载能力的
但是调度器宕机了,整个服务将不可用,单点
(还有之前的session server会话存储服务器,也存在单点

所以为了提高单点设备的可用性,一般都是缩短平均修复时间的,MTTR,提供冗余,
出现故障,告诉管理员,但是人工过来解决问题,耗时较久,未必是最好的解决方式,
调度器服务器,主服务器和备用服务器通过 某种关联在一起,主服务器不停地把自己服务状态的信息发送给备用服务器,一旦出现问题,把活动主机提供正常服务器的资源转移到备用节点(这个过程叫失效转移,或者故障转移,tailover)
nginx要想正常 提供服务,介入客户端请求的位置,主要靠的就是ip地址,进来如何提高服务主要靠的是nginx进程(合理配置文件),活动主机出现故障时,ip地址需要被拿走,nginx进程需要被拿走
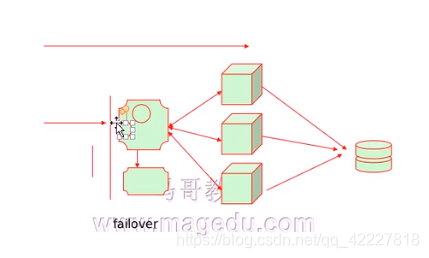
备用的替换活动主机后,管理员需要准备一个备用服务器,避免下一次出现故障

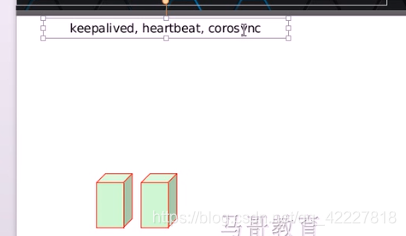
主要解决这种方案的,在开源领域中有很多种,keepalived,heartbeat(接近于瘫痪状态才启用,有比这个更好的corosync,都是专业的,可能细节方面的解决不了,一般用keepalived
冗余如何实现,在两个节点上都要安装程序,基于这个软件程序,彼此之间可以互相通讯
(1.传递心跳信息,主节点可以把自己当前状态通过这个软件程序可以交互信息传递给从节点,来完成通知信息状态
2.这个软件还能从备用节点上判断,主节点是否故障,如果故障,接下来就要做出决策来进行资源转移,触发操作来完成资源转移)
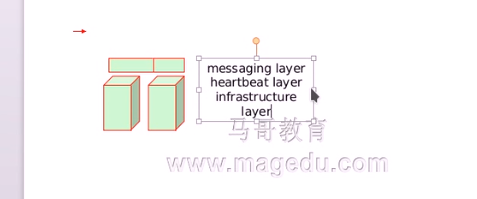
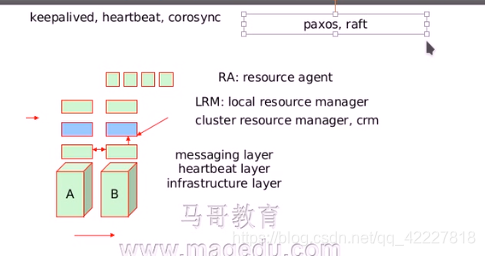
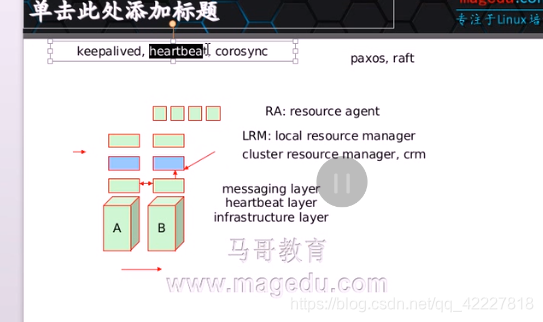
消息层,心跳层或叫基础架构层
能传递心跳,但是该传递或者转移还未定义
服务应该由一个多或多个资源来提高服务,比如ip地址和一些资源
定义一个服务需要由哪些资源组成,这个资源称为高可用资源,这个服务就称为高可用服务,上面的层次只要时管理资源的,所以一般称为资源管理层,集群资源管理器cluster resource manager, crm
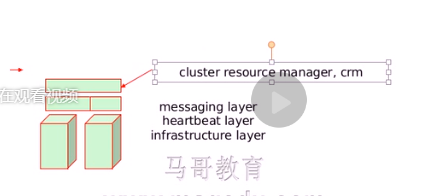
资源管理器这个层负责组织资源称为高可用,(每个资源管理器,都只能与自己本地底层接上,(底层:心跳层,消息层兼通信,),用这些信号来判定节点是否故障
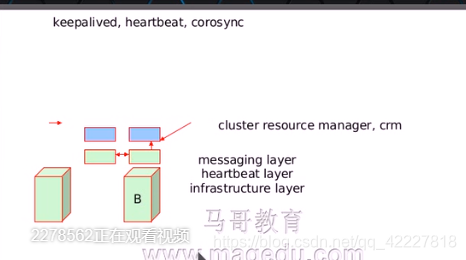
假如A机器宕机了,B机器(nginx的进程两个机器的配置是一样的)
就只能把ip地址直接配上去
资源管理器只是做决策的并不真正执行把资源抢过来或允许起来的这些功能,要真正执行的是它的上面一层(LRM,本地资源管理器 local resource manager,主要接收底下这个层次资源管理器发过来的指令,比如启动,ip地址劫取或是拿掉,把nginx进程启动或是拿掉)
LRM都接收指令,一步步地执行下去(把一个个资源管理,委托给了外部的功能,自己无法实现,因为要实现的功能太多了,所以LRM把每个具体操作委托给了接口输出出来,用户可自行定义一个脚本,把脚本委托给LRM,LRM就知道下一次想要启动只要激活脚本就可以了,start,stop,status,)
所以就有一个个接口管理的脚本或者一个个支撑的unit file,一个个具体的实现,叫RA:resource agent,资源代理,能够帮你去管理资源,是脚本也可以是unit file
总共就有4个层次,
1.资源代理RA
2.本地资源管理器LRM 做执行的 (通过RA的一个个脚本或unit file 去执行
3.集群资源管理器CRM 做决策的
4.消息层,心跳层,基础设施层

A主机(主)会定期发送给B主机信息,自己工作正常,还告诉B自己有着更高的优先级,所以优先运行资源,
所以B只有等到A挂机了,才有继承权
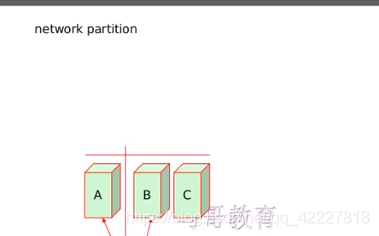
但是两个点组成的集群才是风险最高的集群,因为出现故障,谁去侦测谁故障,一般来讲是一个集群三个节点、而且应该是基数,
B能链接CA
C能链接BA
现在BC都认为A故障 了,这是有判断依据的,这时候就称为网络发生了分区
一旦集群之间的节点无法联络的话(网络发生了分区,network partition)
A找不到BC,BC找不到A,谁还能代表集群继续功能?
这里面就有一个计算法则,少数服从多数
(加入ABC各有一票投票权,一旦发生分区,A只有一票,BC有两票,能够当主机的就只有BC了,此时的A要自动放弃集群身份,BC就可以判定是A发生故障,不管A有没有故障,为了避免A在后面继续工作导致损害,把A彻底干掉)
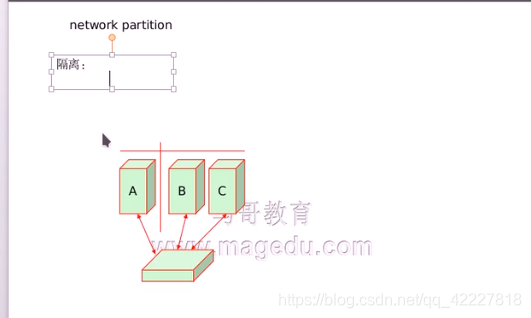
**要干掉A很简单,ABC都链接专门的供电设备,电源交换机上,这个交换机可以通过网线,链接网络接收控制信号,因此每一个节点都有权到其他主机的水晶头,都有权断开其他节点,
如果A宕机 了出故障 了,BC就可以断开他的水晶头
现在BC节点找不到A了,就需要在BC节点中找出一个作为老大的,就有一个leader,由leader来发送断开A的电源的指令,
这种隔离,就是避免双方争用资源,资源只有一个,万一争用会导致这个服务在两个节点之间来回转移,飘忽不定
**
隔离其实有两种隔离方式,
1.STONITH Shoot The Other Node In The Head 一枪打在其他节点头上,需要借助设备
2.FENCE 隔离,一般来讲只是让故障节点不再访问关键资源就可以了
如果BC判断A故障,B把ip地址拿过来,如果A没故障,B再拿回去,这样是没有致命损害的,但是有些操作的时候是为带来致命损害的,
(A,提供服务,能够允许客户端改数据,A故障了,把服务转到B上去,B上面是没有数据的,所以为了避免这种情况,做一个缓存存储,所有缓存节点就该的数据都在这个节点上,谁是主节点,谁就挂载使用,万一A故障了,B判断A故障,为了能够接替服务,就需要链接缓存存储设备,但是有可能A还链接着,上面的进程还在继续修改,如果缓存存储设备是个块设备,每个块设备的内容都是给节点载入内存中访问,A和B就有可能同时进行了修改,会造成文件系统原数据崩溃,原数据崩溃意味,整个服务全崩了,所以资源流转无所谓,但是数据没了就是致命的,
这里的块设备指的是STAT硬盘之类的,基于web存储的SAN设备,存储区域网络,这些是块设备的,传统的很多存储都是这个块级别的,尤其是一些集中的高性能存储
所以在这种情况下就必须爆头STONTH,不爆头STONTH就需要隔离FENCE,这种设备一般是通过分布式交换机接进来的,这个交换机可以控制信号的,是可以屏蔽掉A节点的接口,这就避免了数据损坏)
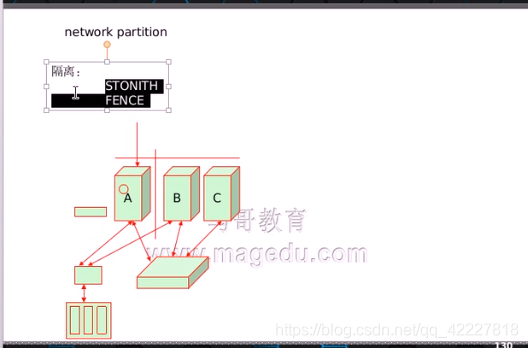
STONTH,节点级别的隔离,
FENCE资源级的隔离,只隔离对某个特别重要的关键资源
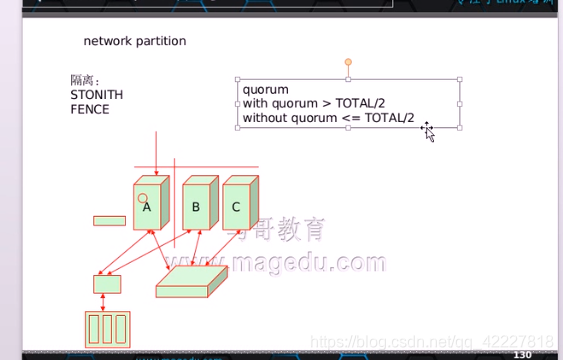
网络分区是必然可能发生的,只能有一个节点代表集群工作,这种判断机制叫做,quorum机制,法定代表数,哪一方能满足法定代表数就能代表集群工作,大于总数的一半
with quorum > totlal/2
不满足法定人数就一定是小于总数一半 without quorum < =total/2
基于这种机制确保只有一个分区只有一个代表
网络分区是不可避免的,网络总会发生故障,一旦发生怎么判定谁去继续工作,就需要用到quorum工作机制来实现,
指定出一个leader,这个领导至关重要,是要管理整个集群的
有两个协议,paxos(作者耗费十年的时间,终于设计出了一个协议,发表了一个论文,但是帕客所思paxos协议使用起来特别麻烦,所以一般都是经过减少的),raft(更加简洁的协议,虽然更简洁,但是并未比paxos高明多少)
分布式系统能走到现在,主要是依靠 paxos协议的存在
回到之前的问题,A节点出了故障,需要把服务转发到BC上,那么究竟是B还是C呢
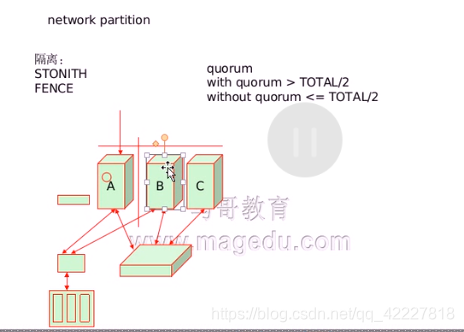
可以定义一个优先级A->B->C(但是这样定义会让这个集群过于死板,因为整个集群上的服务可能不止一个,三个节点只允许一套服务,另外的全部是备用的,比较浪费)
所以集群组织模型如下
A运行服务
B运行服务
谁出现故障都优先转到C上
这个叫N/M模型,N个服务,M个节点
那就需要定义哪个服务对于哪个节点优先级高,比如X资源倾向于A,其次是C,最后是B,Y资源倾向于B
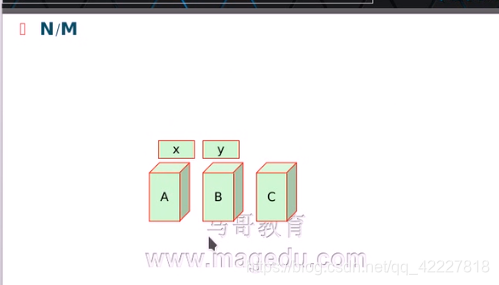
那么能不能有三个服务,每个资源都倾向各自的主机
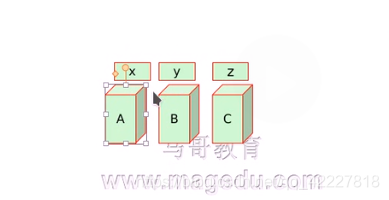
A出现故障x资源转移到C
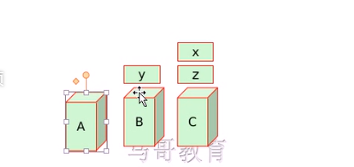
A修复好后,X资源再回到A节点上
这种叫N/N集群

一般都是N/M,m可以等于N-1,再小也可以
这种套路的实现是corosync和heartbeat,是真正意义上的专业集群的管理
**keepalived具体来讲是解决这件事情的,而不是像corosync和heartbeat一样能够高可用任何服务的(比如tomcat高可用corosync就可以,)
keepalived主要是用来设计作为LPVS的高可用的,所以使用范围非常有限,当年设计就是用来LPVS,增加了对lPvs后端RS健康性检查功能
keepalived采用另外一个思路
企业内部网络访问外部,有两个路由器,
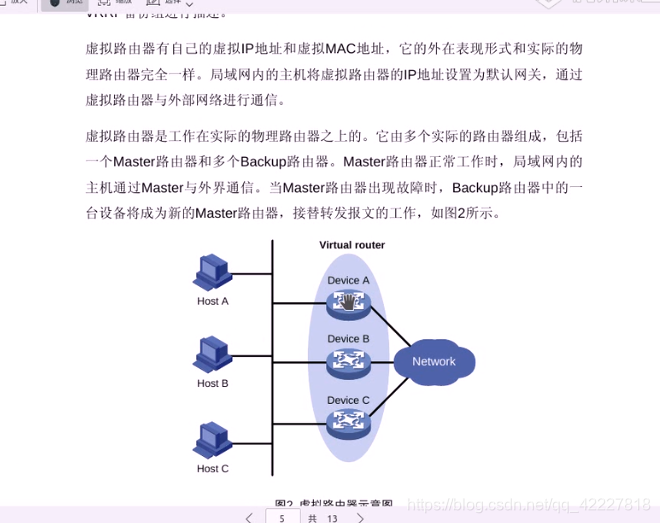
把这两个路由器组织成一个集群比如VIP,每一个客户端访问都指向一个虚拟的ip地址,而这个虚拟ip地址,到底在哪一个路由器网卡进行工作的,可以默认上面一个,万一上面的路由器挂了,VIP就移动到下面的路由器上,底下的也一起跟着资源转移,这个转移过程就是把这两个路由配置成一个集群来实现,就需要用到协议VRRP:虚拟路由冗余协议 virtual routing redundant protocol
**
**VRRP:虚拟路由冗余协议 virtual routing redundant protocol,这个协议可以把两个路由器对应的网卡组织成一个集群。并且这两个网卡上的节点有优先级之分,谁优先级高就 配在谁上面,如果优先级一样,就用谁的ip地址数字大,万一活动的节点出现故障之前,这个节点是需要不停地像其他节点通报心跳,包括自己的优先级,
备用节点如果等待一会发现活动节点没有通过,就认为是活动节点出现故障了,就把vip刦取了配置到自己的网关上了,现在路由器一般都支持这种协议
**
keepalived就是用软件实现 在linux服务器装上以后就能实现VRRP协议
keepalived最终设计是主要用来lpvs实现ldirectord
官方提供的图 vrrp stack vrrp协议实现(所有的地址转义,高可用都是靠这个协议栈来实现的)
另一哥组件叫IPVS wrapper组件,生成ipvs规则,checkers就是健康状态检查工具,能做到tcp,http,ssl,检测,或是自定义MISC的检测
检测失败就调用IPVS,
检测成功就加到IPVS
但是如果checkers或者vrrp stack 任何一个进程挂了都不行
所以有watchdog 哮天犬就是用来监控这两个进程的,可以自动触发来启动这些进程,通常是 个硬件设备
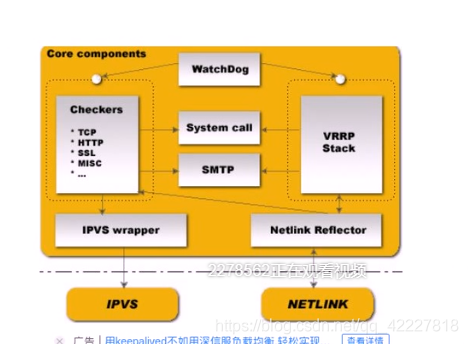
checkers监控某个后端服务器挂了应该通知VRRP来进行修复,所以用到SMTP协议用来通知管理员出现故障,赶紧回来修复节点,system call 可以实现系统调用
checkers 可以监控后端RS

虚拟ip在谁上面,就称为虚拟路由,或是把两个路由器组成的一个集群,称为虚拟路由器,一个虚拟路由器应该有两个或者多个路由器组成
一个路由器网卡接口可能不止一个(如有4块网卡,把其中两块网卡组织成一个虚拟路由器,并且地址转移了,另外两个编号为2的组成一个虚拟路由器,虚拟路由主要绑定的是网卡,跟IP地址关系不大,系统如果宕机了,网卡也就没了)
所以每个人路由器上的编号为3 的网卡就又可以组成一个虚拟路由器
那么这么多虚拟路由器改如何去区别

VRID就是来标识虚拟路由器的,两个虚拟路由器,应该有主有备

master代表现在正在工作的,backup备用的,

ip地址配在谁上面谁就是拥有者,一般虚拟ip还不够,还需要虚拟mac地址,因为光改ip进行转换的时候,请求还会发往原来宕机的路由,还需要虚拟mac地址
顶替的,新的主机拿到VIP以后,自己发一个ARP广播地址解析出去,自己问自己答,下面的主机就看到了,就会更新缓存
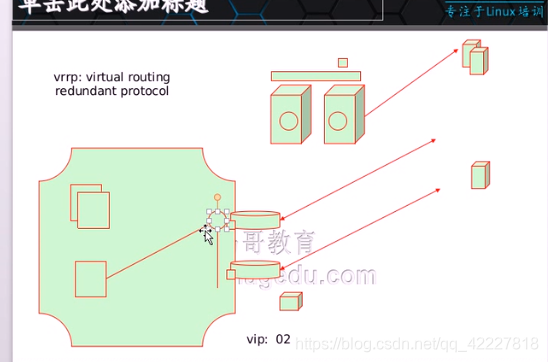

物理节点的优先级,ip地址,谁大谁就是主节点,

抢占模式指的是,主节点会不端地通告自己的优先级,一旦宕机了,没通告优先级,备用节点谁优先高就立即抢
还有一种是,主节点初夏故障,就减少优先级,这样备用节点的优先级高,就会抢去
非抢占模式指的就是只要主节点不出故障,就不抢
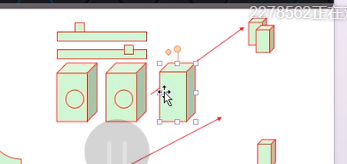
一主一备有点浪费了。可以在两个节点上配置两组虚拟路由,两组虚拟路由配置在同一个网卡是可以的,对虚拟路由1来讲A主B备,对于虚拟路由2来讲B主A备VIP1在A节点,VIP2在B节点上


发送心跳的时候,最好用组播方式,ssl加密,所以在心跳协议的传递还需要做认证

keepalived不支持MD5,只支持,简单字符认证,最长不能超过8个字符
这就是VRRP协议的基础概念



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









