







刚才的MHA实现了当主服务器出现故障,自动的换一个从上去,但是,本质上主服务器只有一个,而且当从服务器成功切换到主服务器上去了,用户的调度,调度到新的主服务器上操作,可能还需要自己去完成,所以终究不是一个特别好的解决方案 ,因此这里可以实现一个强大的功能,主主模型,
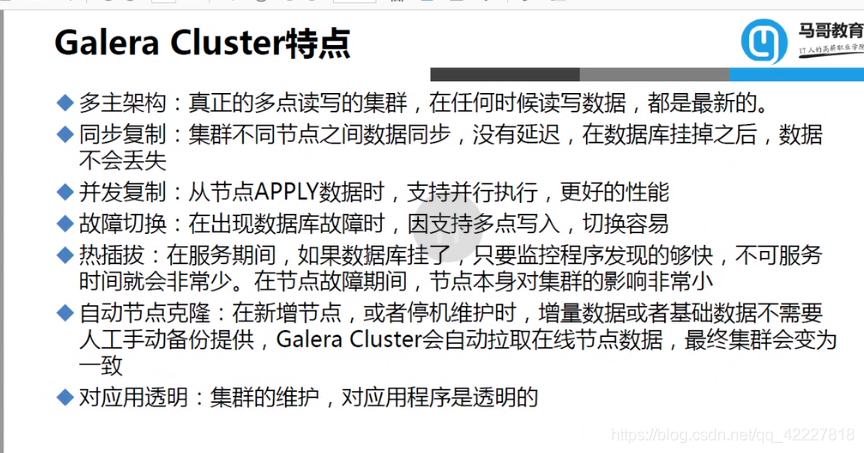
主主模型本质上是既能读又能写

可以实现多主,每个数据库既可以读又可以写,但是和oracle的双主又不一样,(不需要共享存储)
每个数据库都有自己的硬盘,相互之间是平级的关系,每个数据库都可以对外提供读和写的操作
目前galera cluster有两个版本,一个是percona
一个是mariadb
还有一个是mariadb提供的解决方案,由于每个服务器都是主,所以每个服务器都可以均衡负载读写操作


**由于每个服务器都可以对外提供读和写,也就可以充分利用,浮点的飘动的VIP(虚拟ip)
**
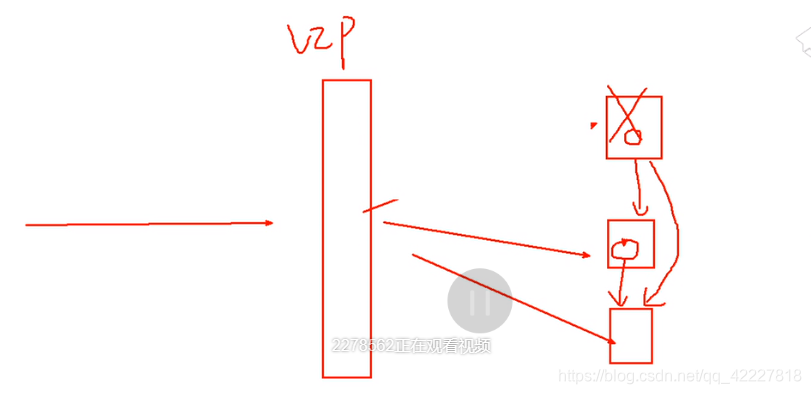
当一个主服务器宕机,VIP可以飘动到下一个,但是vip只有一个的话比较浪费,因为每个主机都可以读和写,如果只有一个VIP,意味着只有一个地址可以被互联网用户访问,就需要前端弄一个调度器,调度器接收到用户请求发送到某一台主机上面,
调度的时候就有3个ip,3个ip地址对应的不是真实的ip,是3个虚拟ip
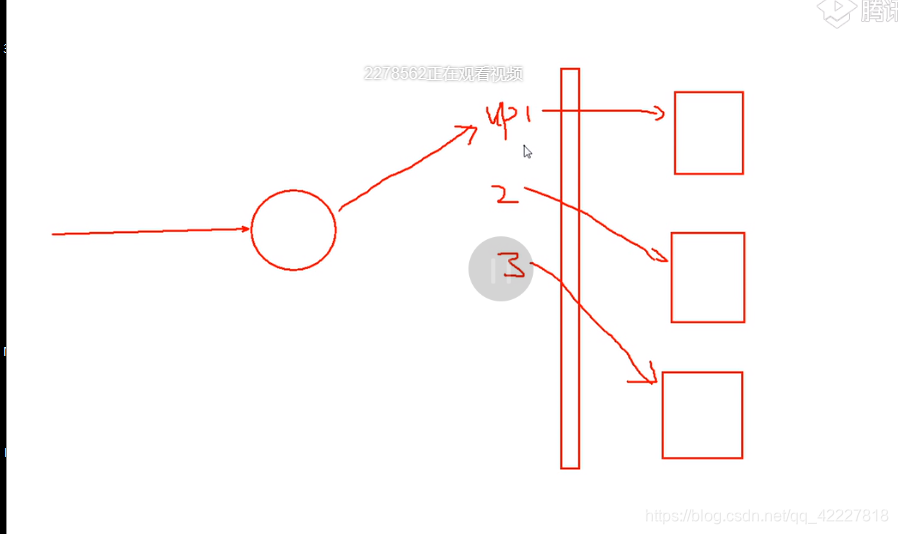
当一台主机坏了,就可以飘动到别的主机上去,这样用户的请求就均匀的分布在每个主机上面
需要配合keepalived
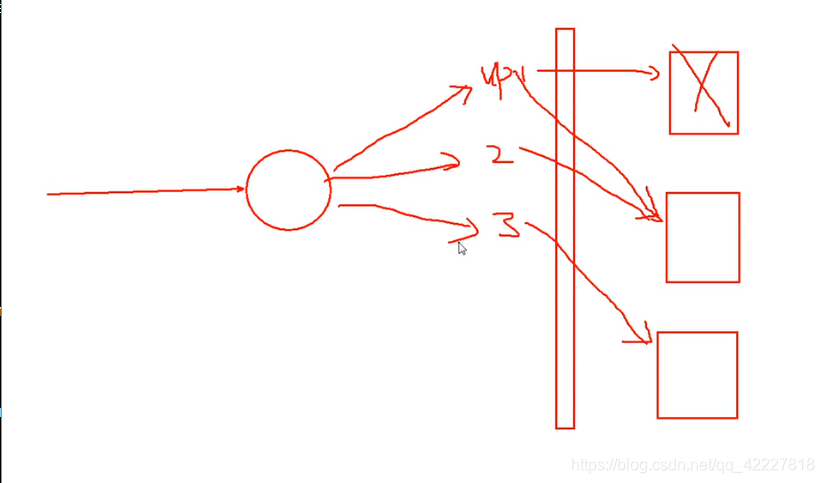
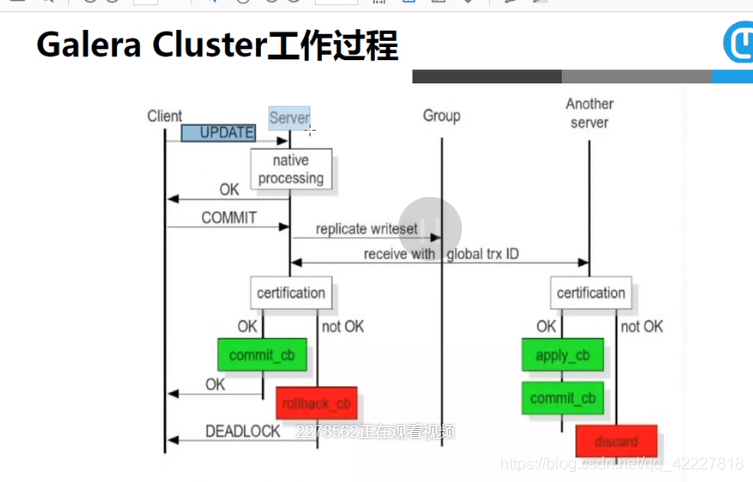
客户端发送update指令,其中某一个galera cluster的集群节点,收到指令以后,要在本地执行这个操作,更改之后会提示用户成功,成功以后,(以事务方式执行)就需要提交,并不会立即让事务生产,而是把刚才操作的过程,同步到其他同一节点的服务器上去,同步过去以后,要在另外的服务器上检查提交过来的内容是否合理,如果是合法的,对本地没有冲突,就认为是提交了,是在本机真实发生的 ,如果发现冲突,就会造成失败,失败以后左边的本机器就会收到通知,也在本地进行验证是否成功,如果成功返回,失败直接撤销,
利用这种机制就可以形成多个节点同时读同时写,底层galera cluster是基于数据块的方式复制的,会把数据库的更新,以数据块的方式一块块读取,传递到其他服务器的节点上去
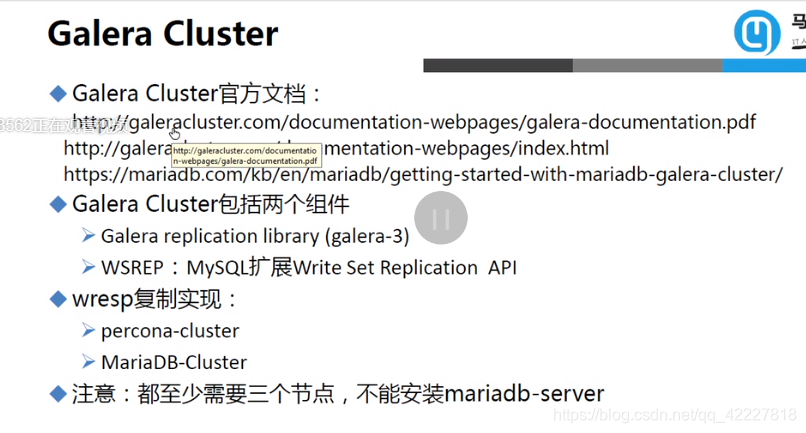
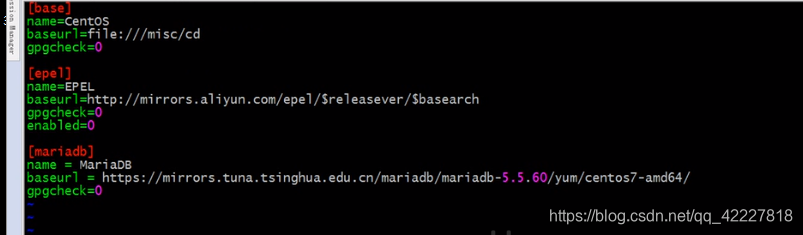
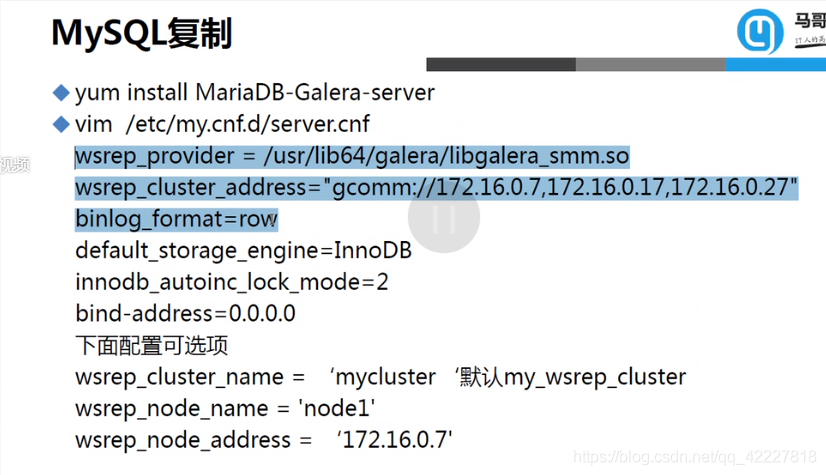
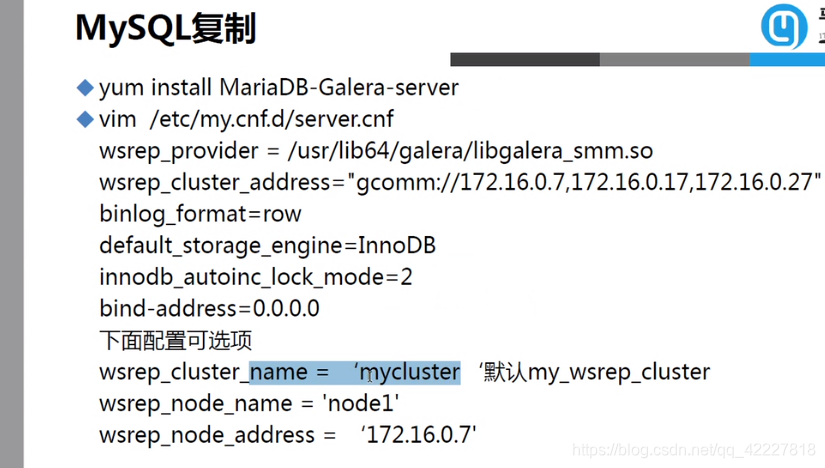
默认mariadb-server是不支持的,需要专门安装支持galera cluster的版本
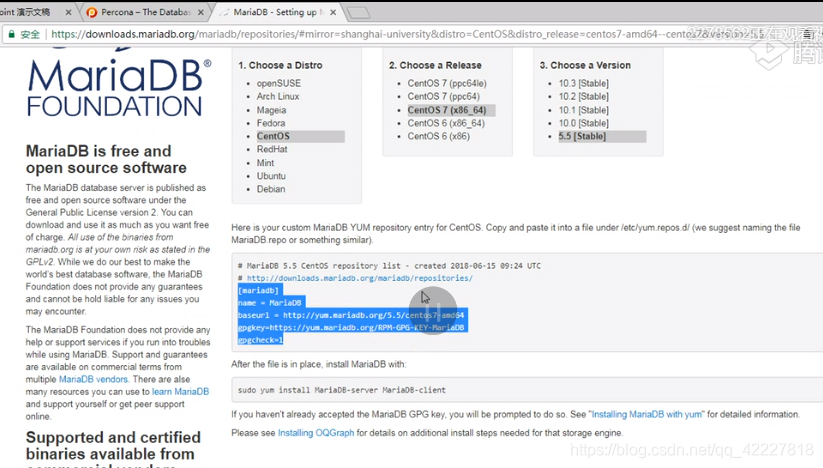
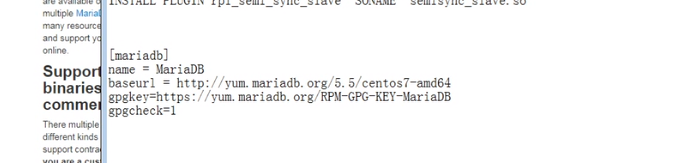
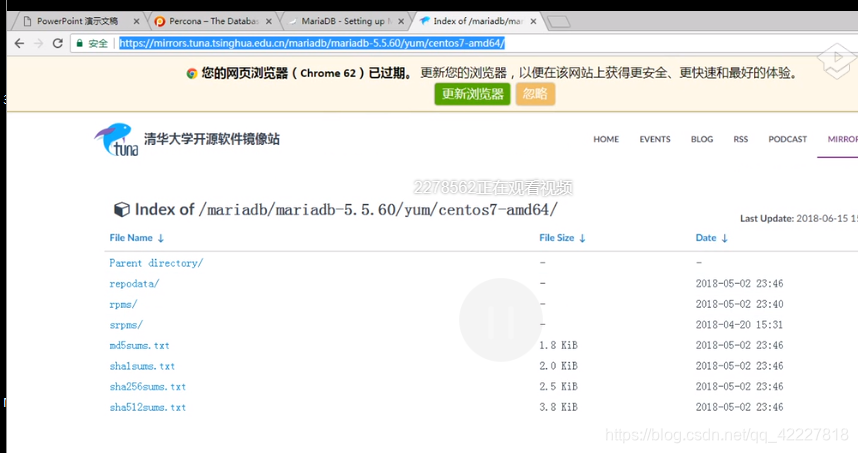
改成国内的yum源快一点

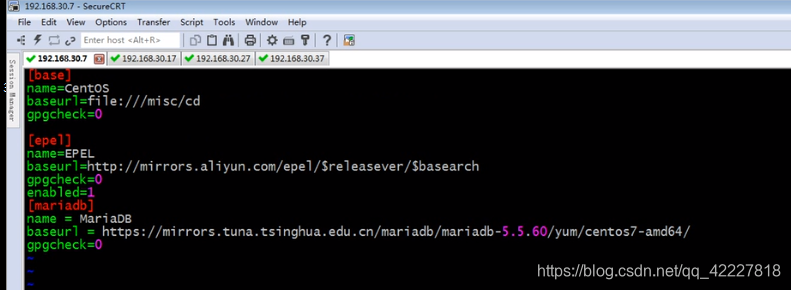
在其他机器上也需要做此配置
装的包不是mariadb-server,是专门带galera cluster的包
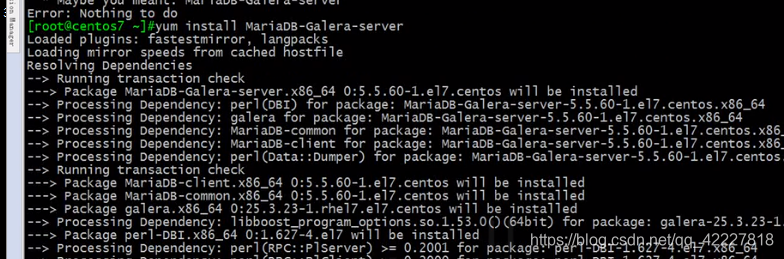
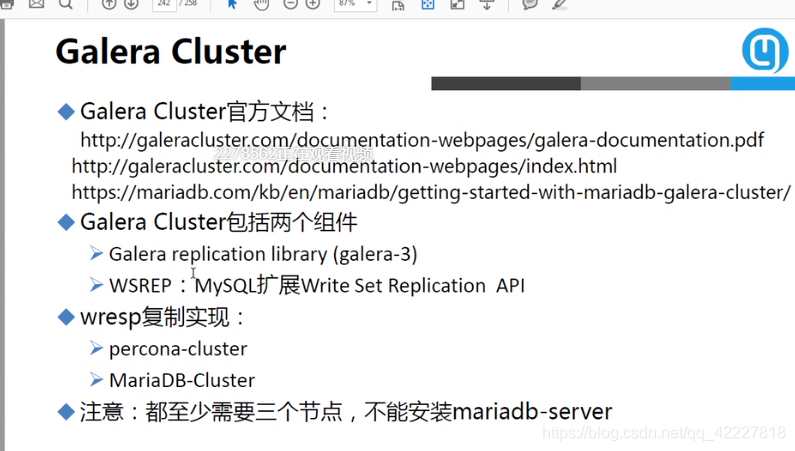
为什么要用专门版本的数据库,是因为它用了专门的开发接口,跟原来的不一样,用到了galera的复制库,都需要至少三个节点来实现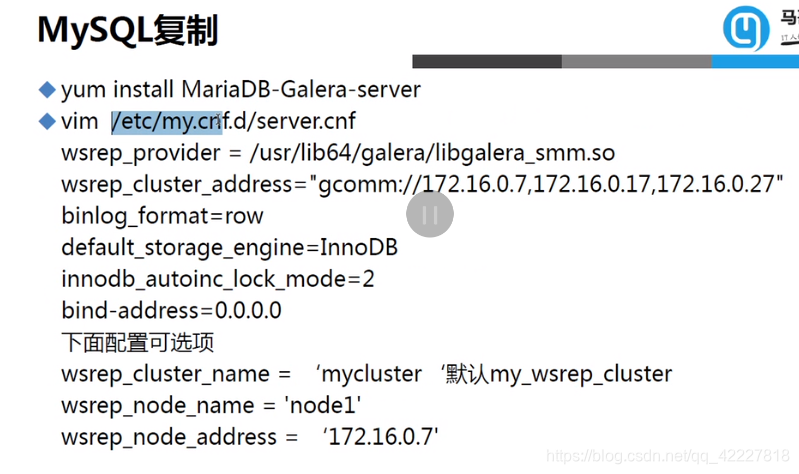

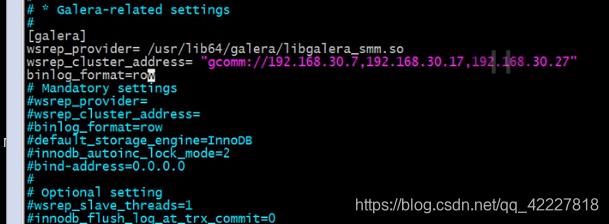
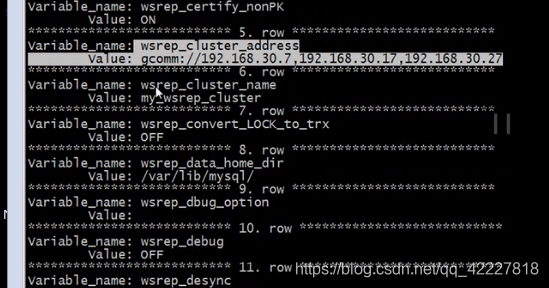
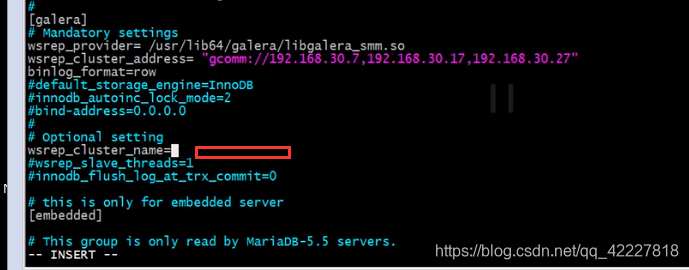
这边写上三台主机的IP地址
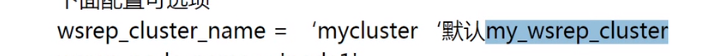
集群名字可以定义,如果不定义就是后面的名字
和一般的mysql数据库有点区别
init.d/mysql启动脚本不是mysqld了
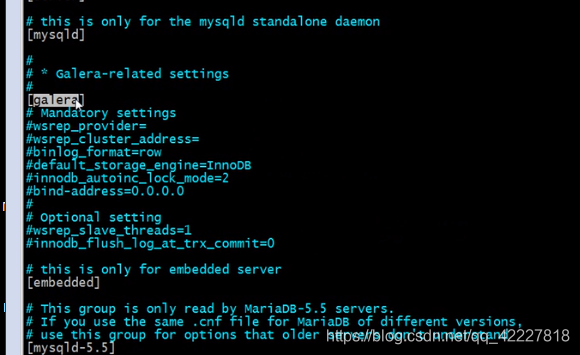
mandatory settings强制设置
optional setting 可选设置
把关键的内容加上就可以有些是可选的,有些是必选的
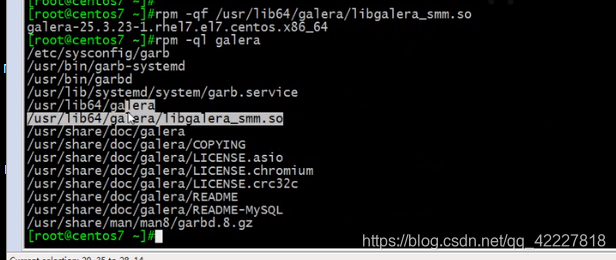
这个模块不在server包里,在刚才的依赖包
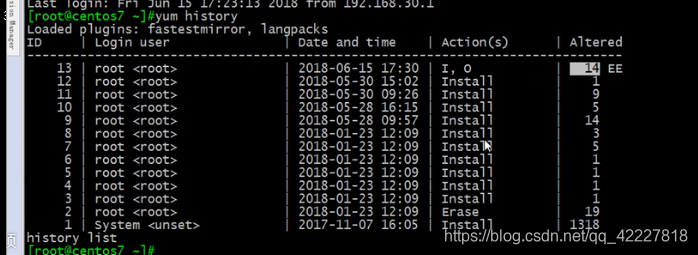
这个模块是装在属于galera的包里的
修改这个三行
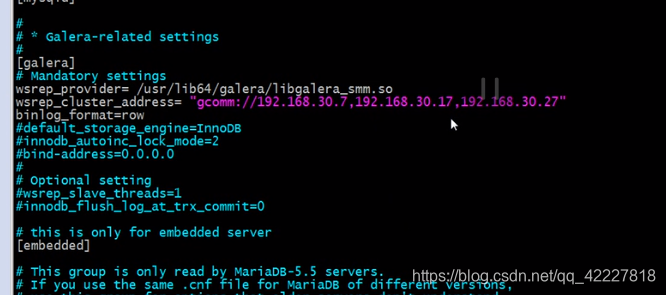
在其他主机上也这么设置
执行第一个节点,后续的就不要了启动,只需要启动服务就可以
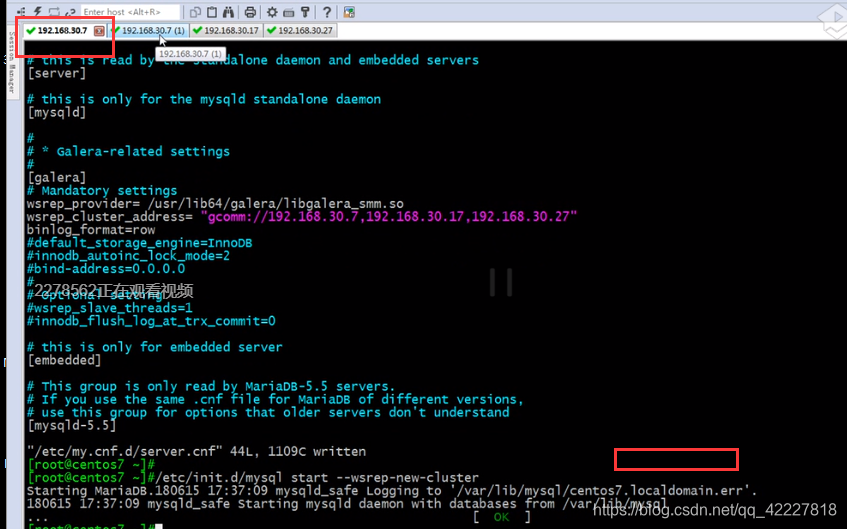
其他主机启动数据库

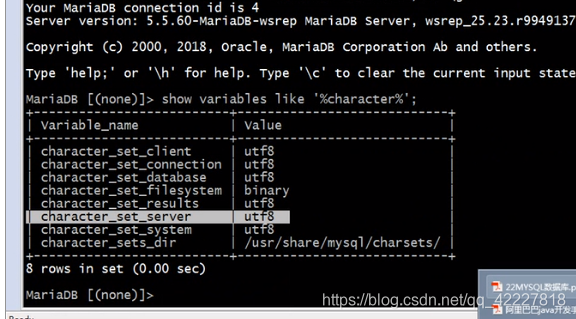
登录数据库查询相关变量

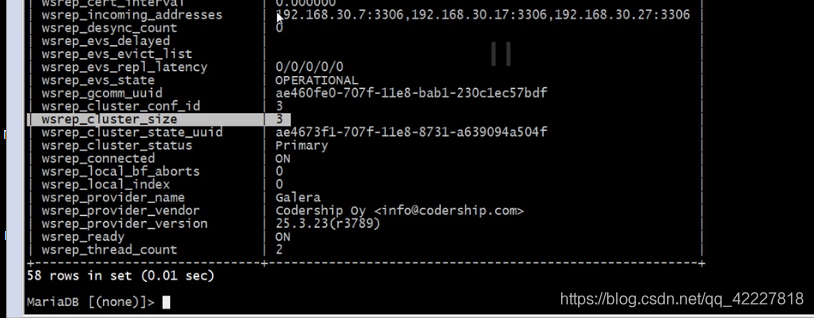
3个成员
现在等于一下,测试是否每个数据库都能写
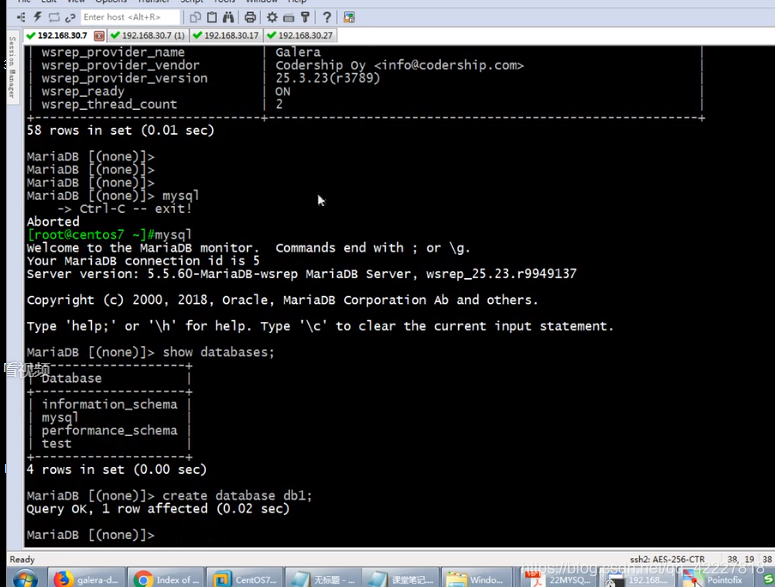
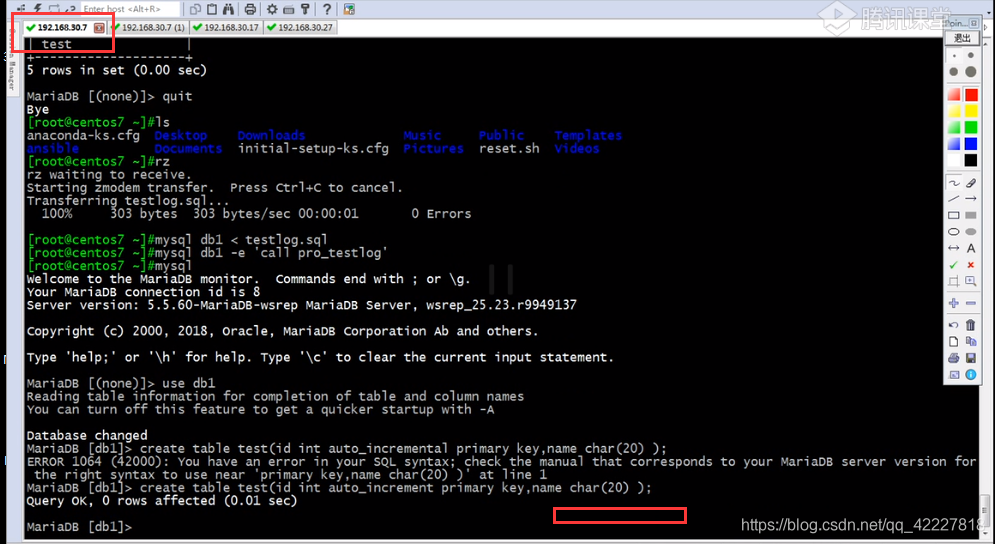
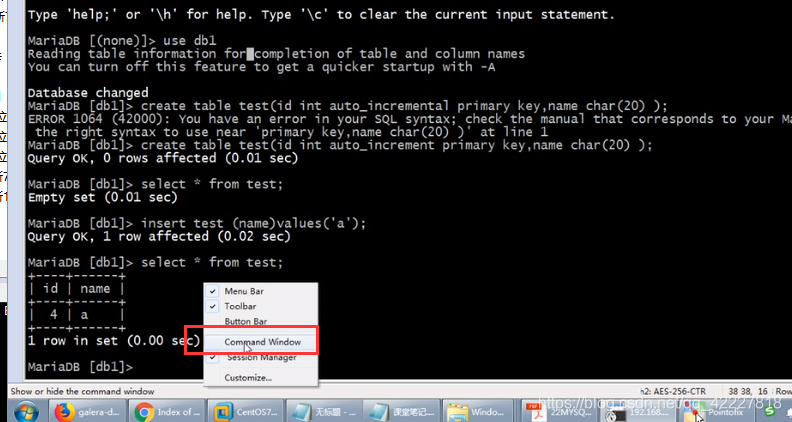
创建数据库
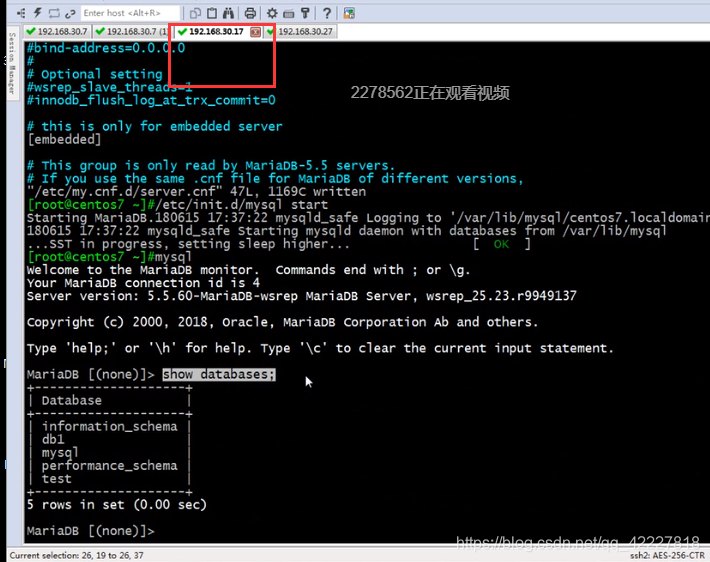
查看是否同步到其他数据库
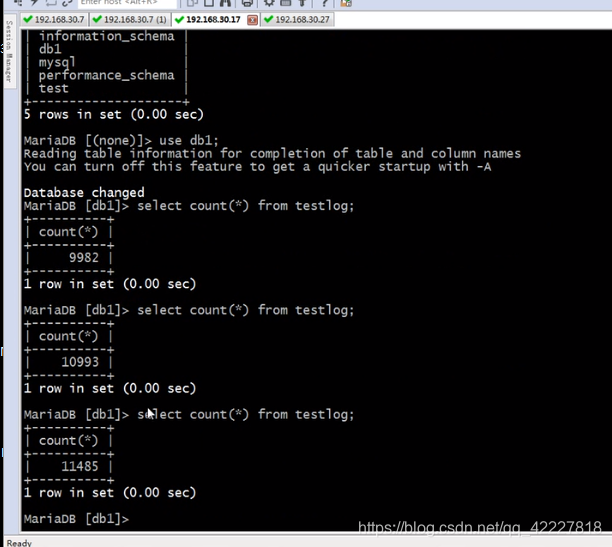
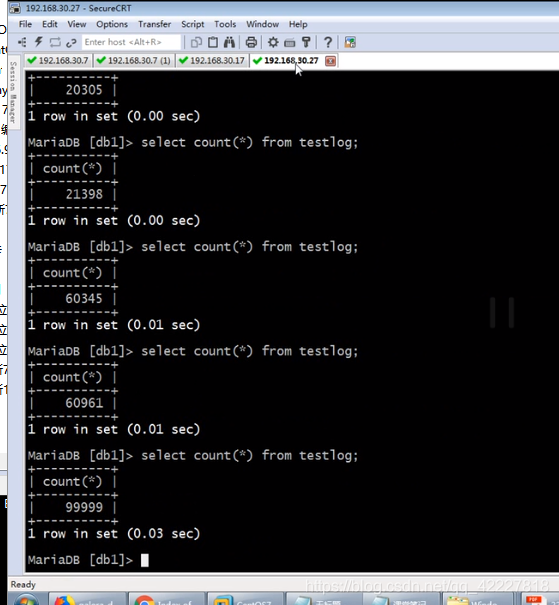
测试效率高不高,用函数批量创建试试

其他数据库在涨
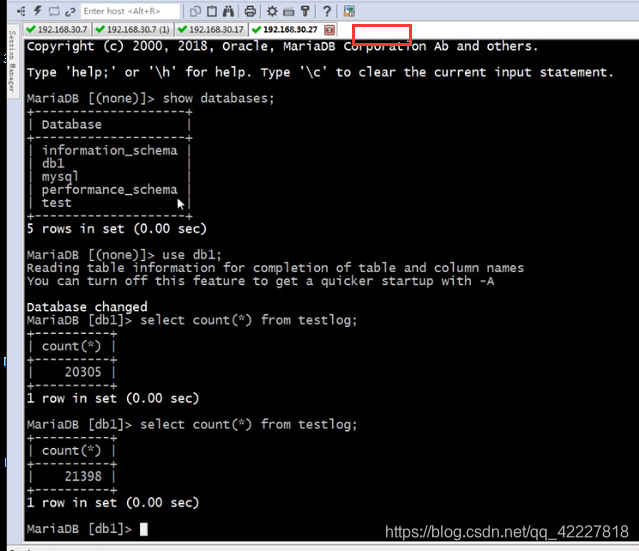
两边能否同时改,是否有自动递增的编号冲突问题
别的地方已经同步了
在7上插入数据
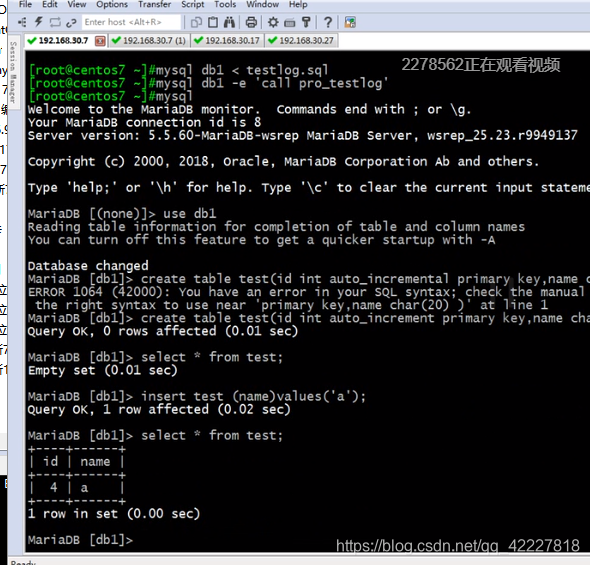
上来就是4,其他主机插入数据就是8
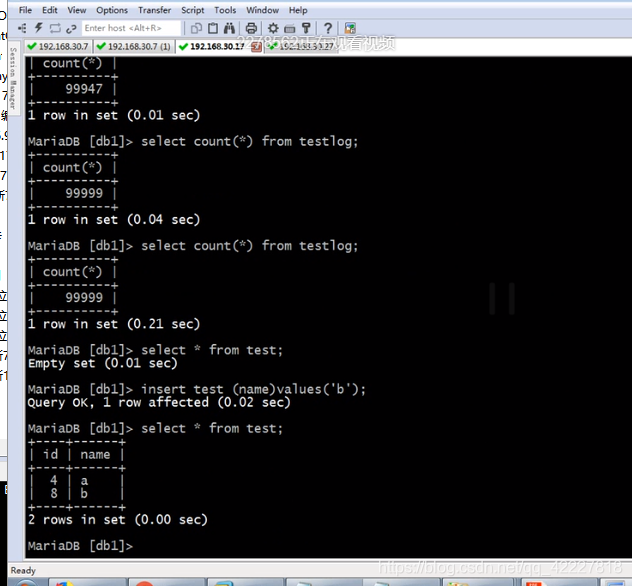
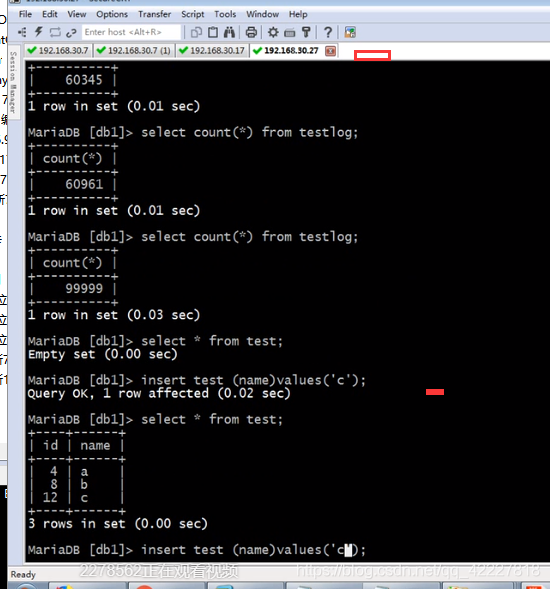
一次性插入几条数据怎么
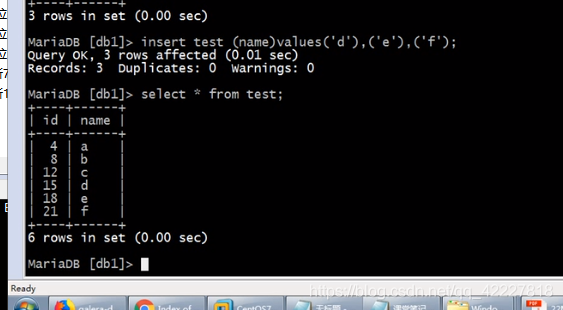
内部也控制这个属性,避免auto-increment的冲突
galera-glaster还没有大规模开始使用
一般来讲还是主从复制,主主避免不了同时写数据的 可能
可以做一个测试
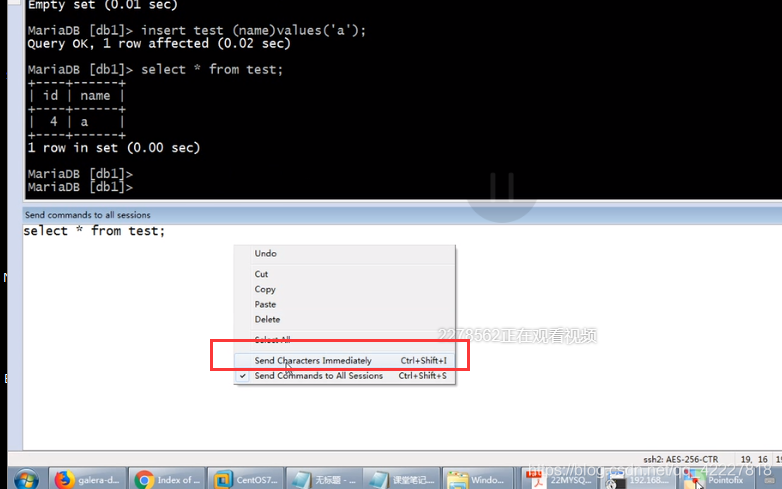
测试往里面插入一条记录,相当于在每个终端同时执行
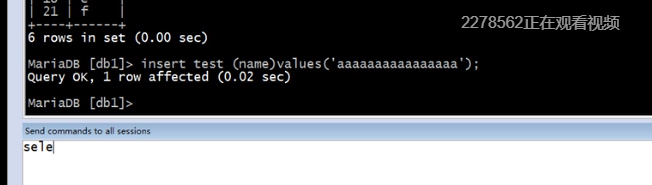
查询插入的结果怎么样的
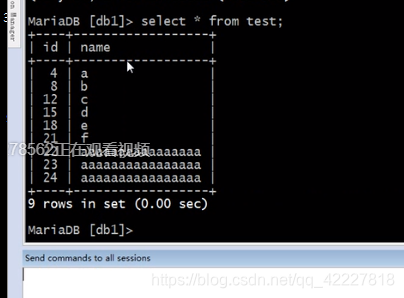
那么要是id设置为主键呢
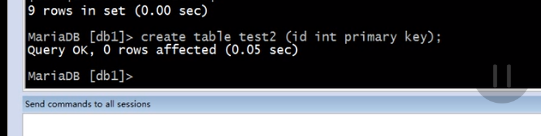
其他的失败了,有一个成功了

按照原理只能一个成功,其他失败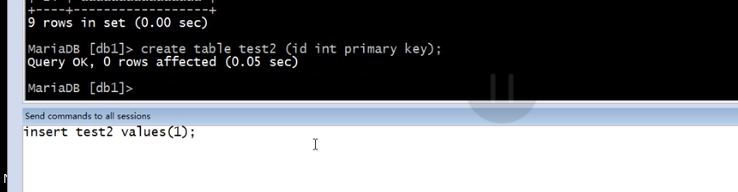

解决了同时插入的问题,配置也比较简单

服务器地址
集群名

想换个名字,可以在配置文件里改


在复制过程中遇到的问题如何解决
主服务器一般配合:MHA(解决主服务器宕机自动切换到从服务器上)和半同步 (保证主服务器始终能把数据传到从服务器)(这样基本可以避免数据丢失)
从服务器

serverid必须唯一,就会复制失败,因为是通过serverid来判断事务日志是谁的

复制延迟需要借助第三方工具,
一从多主,可以从多个主服务器复制多个数据库,实例

qps每秒中的查询次数
tps每秒中执行的事务次数(事务就是对数据库的更改)
对于mysql性能好坏,有一些测试工具

这个是自带的工具

会生成一个测试用的数据库,和数据,然后对表进行测试

可以修改不同类型的测试操作



-a就是生成测试数据库
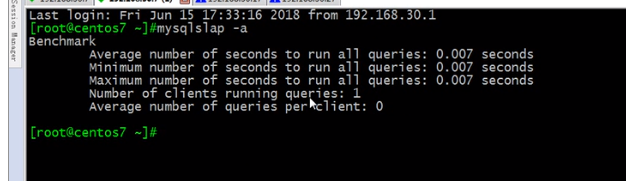
并发一百次访问
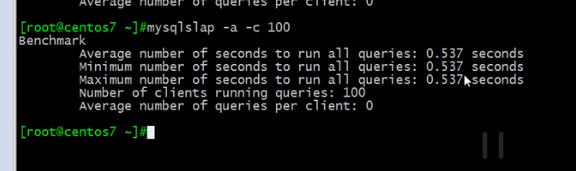

发起1000次请求,并发是50,100分别测,用myisam,innodb分别的去进行测试
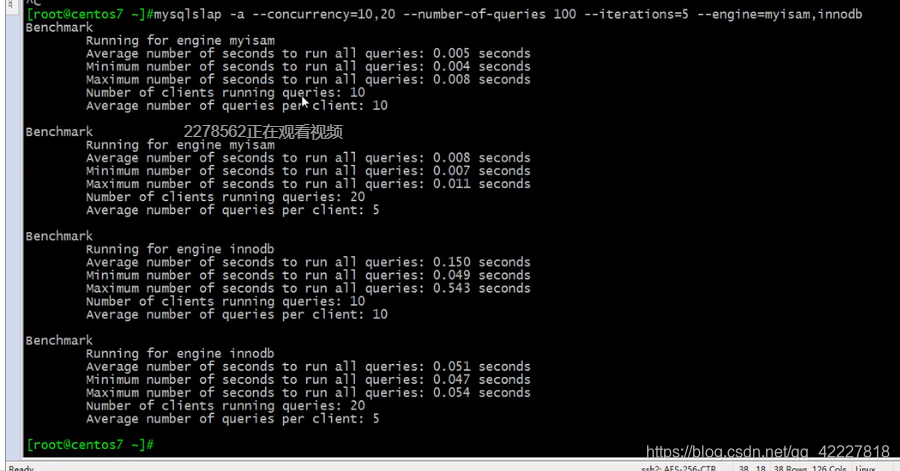
myisam的速度还是更快一些,不支持事务
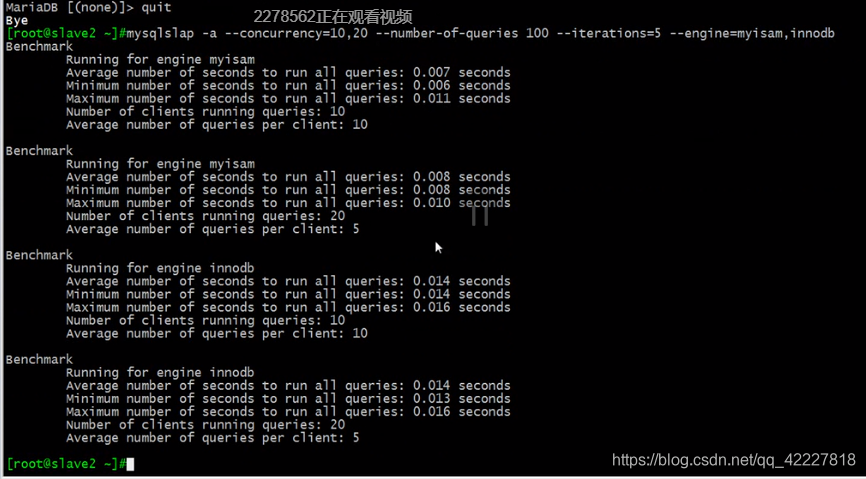
单机的相交做的集群的稍微好点

生产中配置my.cnf的范例
maxconnections并发链接数
一般的设置是不支持这么大的并发

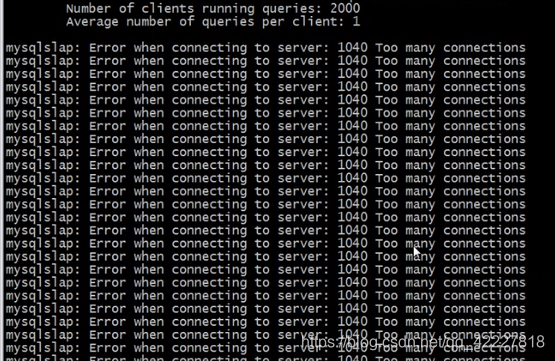
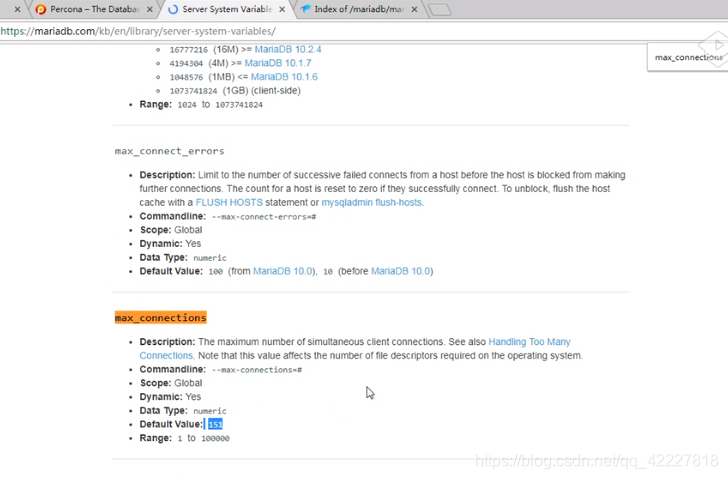
最大连接数是151

链接满了,后续的就需要排队,至少不会拒绝

用户错误链接1000次,就不允许链接了。可以用flush hosts恢复
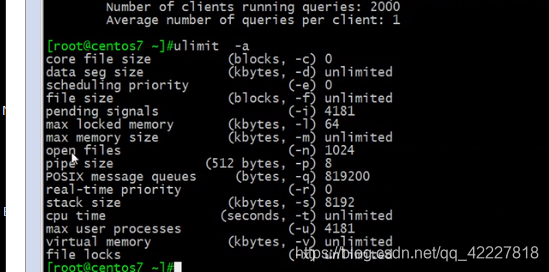
打开文件个数

mysql默认设置都太小了,不符合生产环境设置
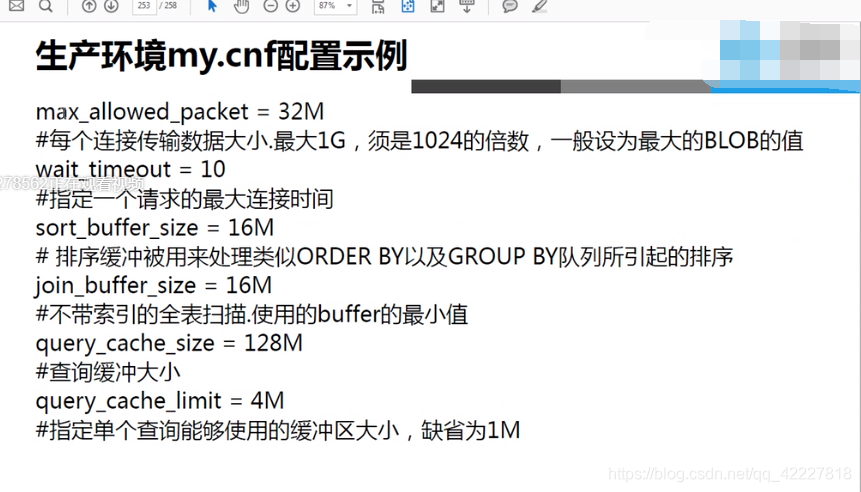
一张表可能有个字段类型是BLOB,可以设置为这个字段的最大值大小

全表扫描,进行多表链接的时候,内存多大

查询缓存默认是0,不启用的、

单个查询缓存最大是多少

事务隔离级别,可重复读

如果栈太小,进行存储过程和复杂语句的时候,有可能失败
 相当重要,数据库在使用存储情况的时候最多使用128M数据,来存储你的数据,如果服务器是32G内存,用128M来缓存你的数据,效率是 很低的,一般都是要物理内存的百分之80
相当重要,数据库在使用存储情况的时候最多使用128M数据,来存储你的数据,如果服务器是32G内存,用128M来缓存你的数据,效率是 很低的,一般都是要物理内存的百分之80
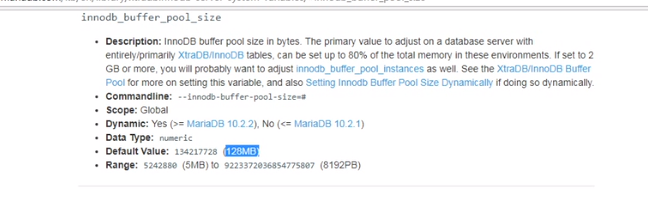 、
、


并发线程数,建议是cpu个数+磁盘数量的两倍

innodb事务日志默认是5M,默认只有两个

当对一行修改时候,就会进行加锁,别人也访问就需要等待,120S超时
慢查询时长,两秒已经很慢了,10秒有点太长了

如果没有利用索引查询,可以记录下来进行优化


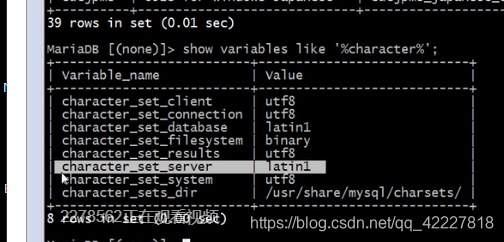
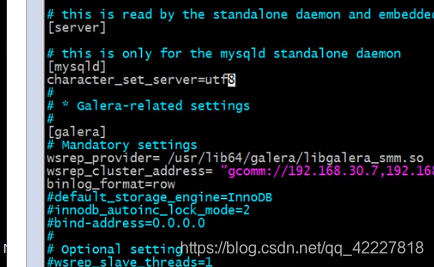
服务器端的字符集设置不是utf-8






















 324
324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









