







zookeeper是大数据领域,尤其是hadoop生态圈里举足轻重的一个服务,尤其是hadoop生态圈里,只要是分布式服务,没有这个服务跑不了,是非常核心基础 的服务。
zookeeper可以解决分布一致性的问题

**这东西是来自google的论文,雅虎做的zookeeper,交给apache,进行孵化,称为了顶级项目 **
zookeeper就是动物管理员,管hadoop里的一大堆动物,协调里面的软件,是hadoop生态圈里非常基础的服务
zookeeper是开源的分布式应用协调服务,主要解决分布一致性的问题(就是分布式所有节点的数据应该一致,如果不一致,就会带来很大问题)
关系型数据库用ACID来保证数据一致性,分布式不适用
reids3.0之前的集群codis,就用了zookeeper这样一个软件,自己具备高可用,高性能,原生是java接口
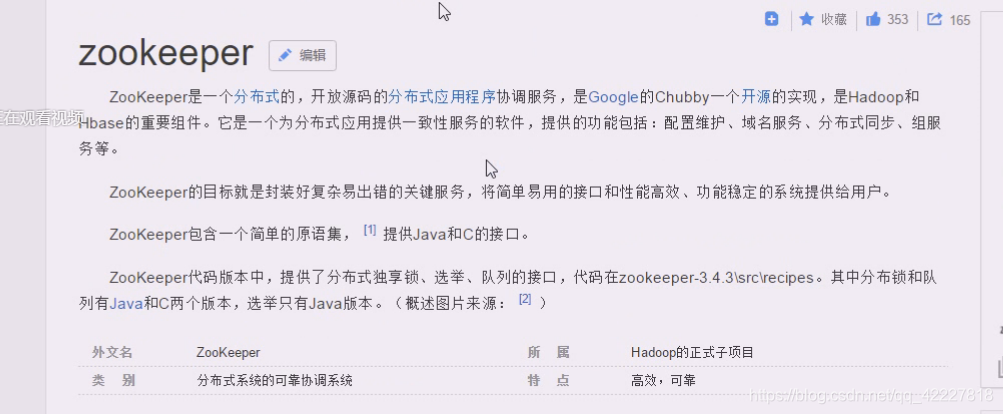
原理是zookeeper实现了paxos算法,只要是做一些选举,它自己是一个集群服务,必须有master,并且只能有一个,必须有领导才能提供服务。
proposer其实就是客户端提供的数据请求,尤其是写的请求,怎么保证所有数据一致,它可以保证,并且计算都是在内存里完成的,速度是很快的
zookeeper是基于内存存数据,所有节点基于内存来存数据,内部保证一个数据结构,类似于一个linux根文件系统的这样一个树状结构,操作命令跟操作linux文件系统命令很相似。
树形结构可以表示层级关系还可以在每个节点捆绑一个数据。每个节点是key,因为路径是唯一的。
zookeeper实现的paxos算法,就能保证提供的分布式一致性的协调能力

基于java写的,必须基于java的jdk
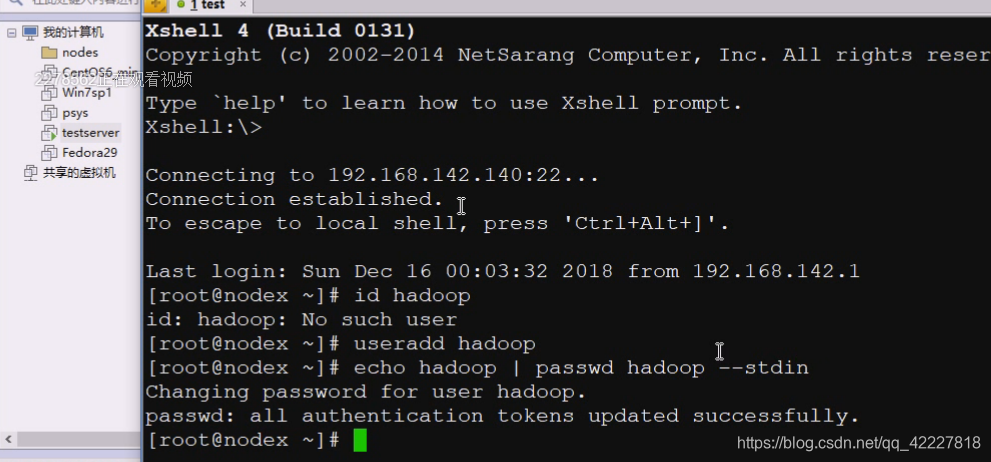
在虚拟机里创建用户
安装一下jdk
现在给全局使用,就用root安装,jdk就是java的开发包
root下把zookeeper相关的放到/tmp下
切换到hadoop用户
拿过来解压缩基本就能用了
最重要的两个目录,bin目录,写的shell脚本都在bin目录下,conf目录下做配置
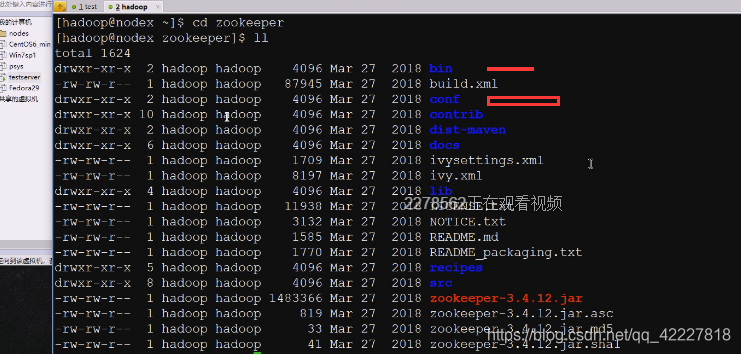
log4j做日志非常有名

zoo.cfg是启动的时候 默认要找的文件。启动的时候有三种模式,
stand alone起一个服务进程,用单机测试
伪分布式,把三个进程放在同一台服务器上
真正的分布式至少三个节点,单独运行一个zookeeper,配置文件完全一样

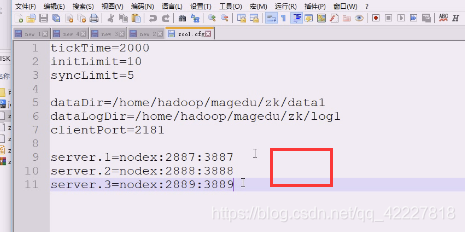
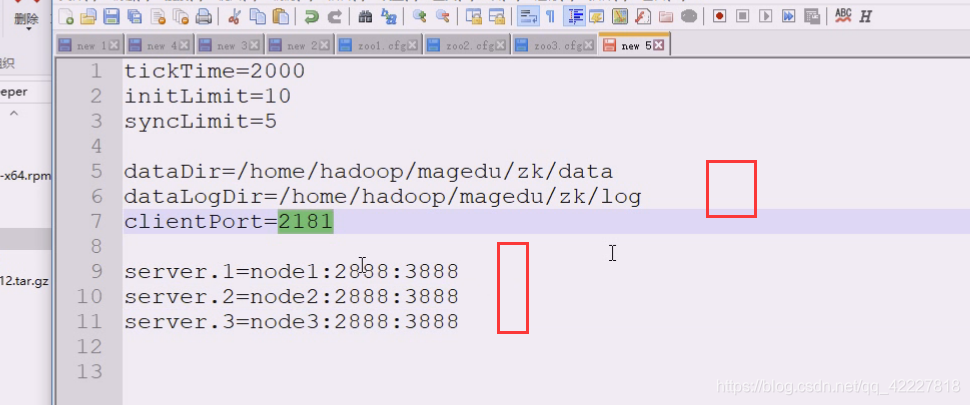
看一下配置文件

看看不以井号开头
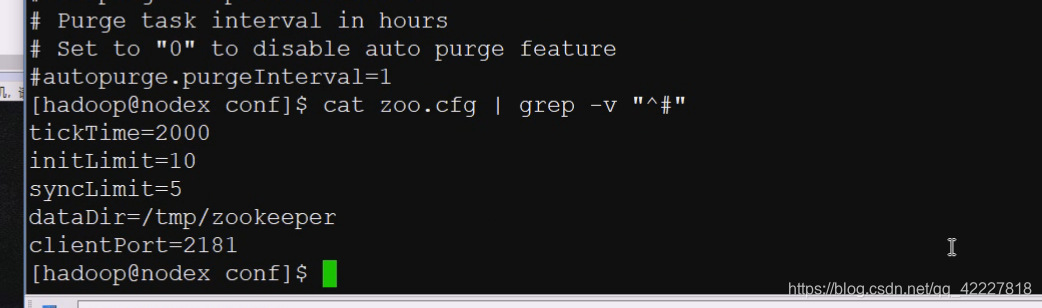
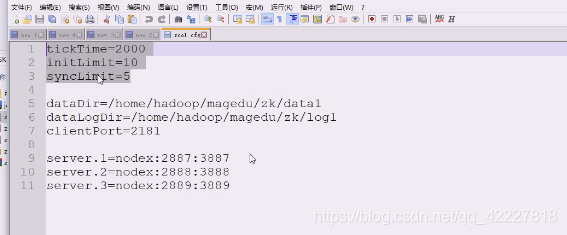
向zk发送心跳的时长,ticktime,2000毫秒=2秒,就是心跳间隔

初始同步阶段,要经过多少个tick时长。10个tick时长,一个是两秒,10个就是20秒
服务器之间在初始化的时候,不能超过10个滴答tick

发个请求最多要经过多少个tick周期。5个,10秒
服务器进行数据同步的时候,要求5个滴答,也就是10秒
数据目录,zk数据都是在内存中的,一挂数据就没有了,也采用了redis的方式,把内存中的数据给快照至指定的存储位置,放在tmp不是很妥当的做法

现在直接跑是单节点,不在生产环境用,是测试的时候用的
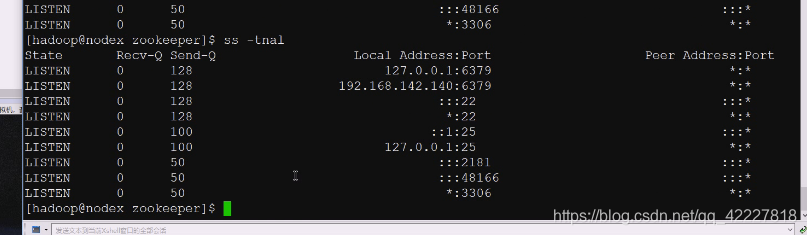
客户端连接哪个端口来提供服务,监听的端口

cmd可以删除,都是windows下的,zkserver本地server,cli就是本地客户端用,最终使用python库来链接

可以指明配置文件

6379 redis。3306mysql
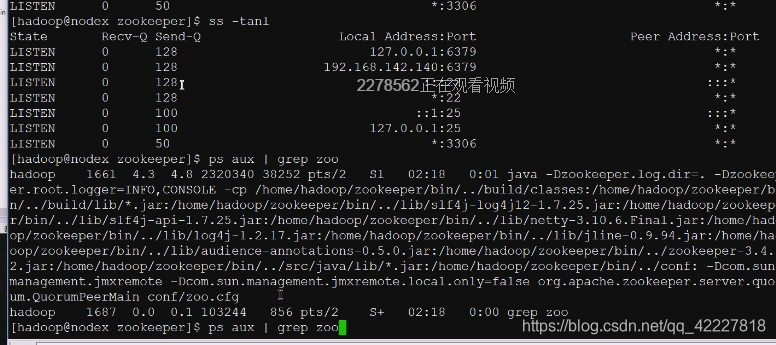
client默认刚才是2181
装完jdk可以确保执行一下java是否成功,不要用完整安装的openjdk,用oracle提供的jdk

什么都不加,默认链接本地2181

根下有个目录,是zookeeper,目录是key,绝对路径可以当key来看,在这个路径上捆一个数据就是kv
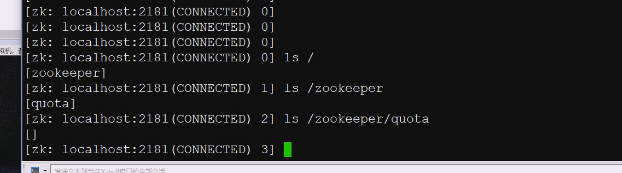
不想用可以先停止
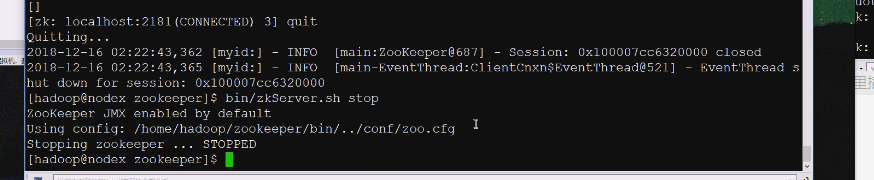
其实安装完服务有非常重要的东西,javahome的配置
伪分布式
为了避免myid不干扰,所以就回到没安装之前
先安装jdk
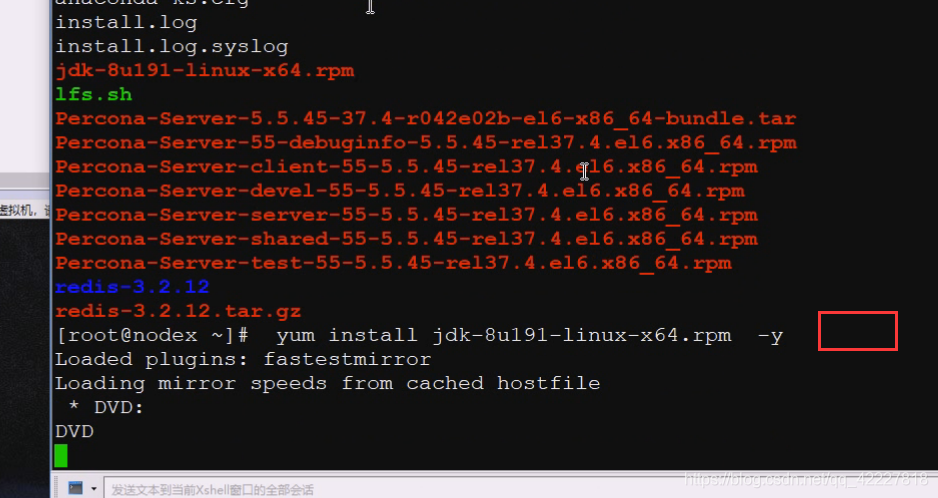
有些人喜欢在profile文件里直接追加,但是不推荐
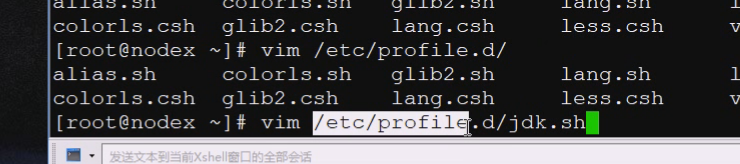
之后就要配置一个java的环境变量,可以配成全局也可以配置成当前用户的,一般都是配置全局的,做一个jdk.sh
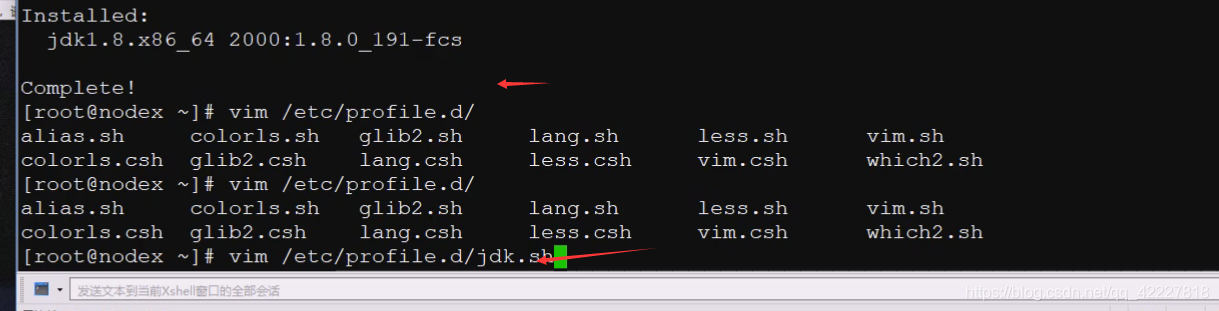
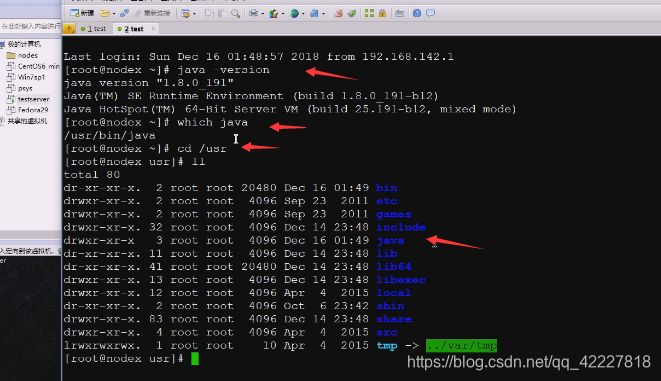
这是真正的安装目录,知道你jdk可能有多版本,所以写了latest,最后安装版本,default缺省版本

以后就可以做个软连接替换掉


export,导出为环境变量
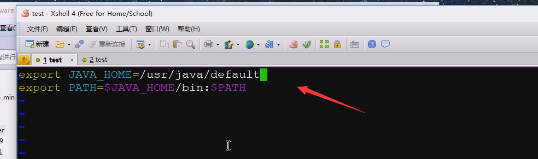
这是一个全局的jdk,创建的hadoop用户,全局也可以用 ,但是也可以单独配一个,在他的家目录下
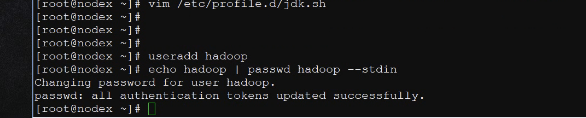
用hadoop用户测一下javahome
java是放在usr/bin下,可以直接在path路径里运行,用java测测不出来,但是有很多命令不在usr/下
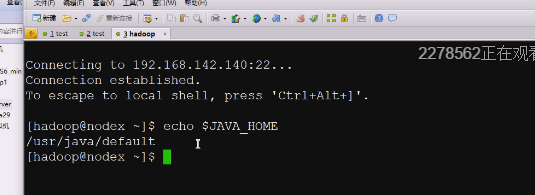
在hadoop用户搭建zookeeper伪分布式
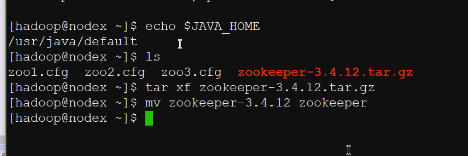

配置hadoop服务也是仿照java,写什么home等于什么,把zookeeper_home配上软件的家目录
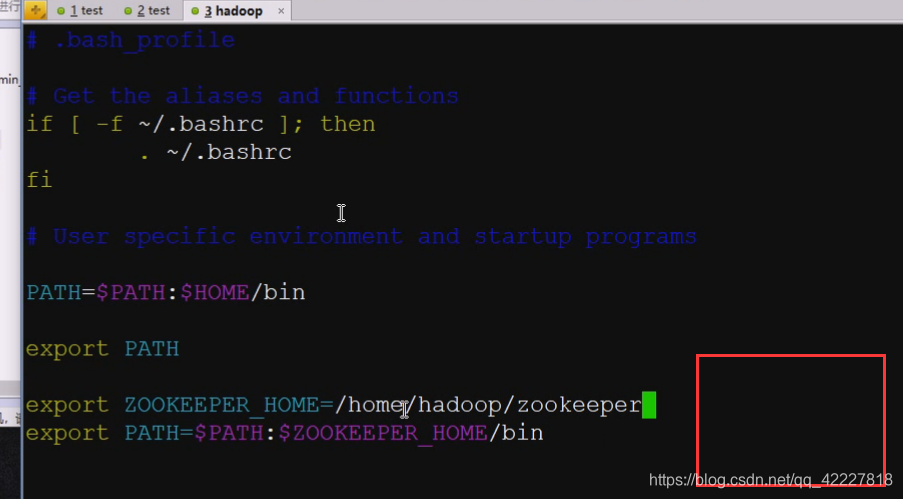
测试成功
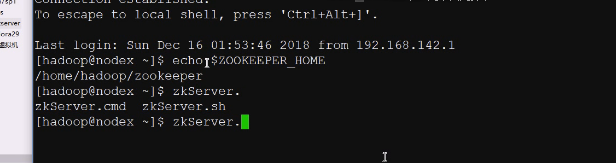
配置了两个环境变量,全局java的环境变量,小用户权限就是zookeeper
看一下配置文件
向zk发送心跳的时长,ticktime,2000毫秒=2秒,就是心跳间隔
初始同步阶段,要经过多少个tick时长。10个tick时长,一个是两秒,10个就是20秒
服务器之间在初始化的时候,不能超过10个滴答tick
发个请求最多要经过多少个tick周期。5个,10秒
服务器进行数据同步的时候,要求5个滴答,也就是10秒
数据目录,zk数据都是在内存中的,一挂数据就没有了,也采用了redis的方式,把内存中的数据给快照至指定的存储位置,放在tmp不是很妥当的做法

客户端连接哪个端口来提供服务,监听的端口
类似mysql的binlog,写操作日志,写分布式一般配置一下

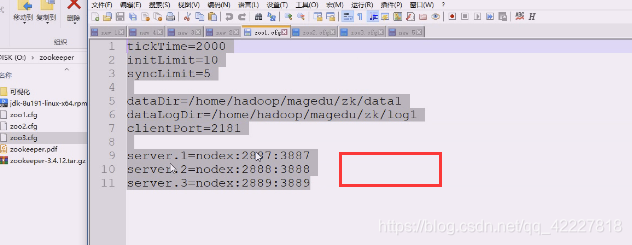
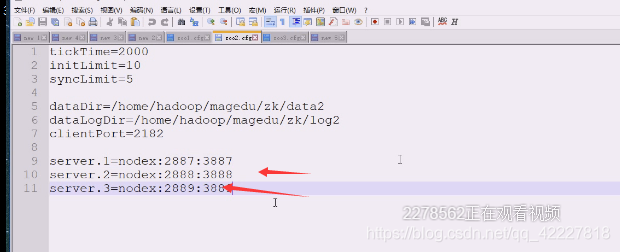
这里就指的是有 几个server,.点后面的数字就是myid,这个id不能重复,会有1,2,3,3个zookeeper进程,每个zookeeper进程给自己打了标记,是在一个myid文件中。
1号服务是在nodex节点(主机名),2887内部通信用:3887选举用

客户端连接用2181,内部通信2887,选举3887
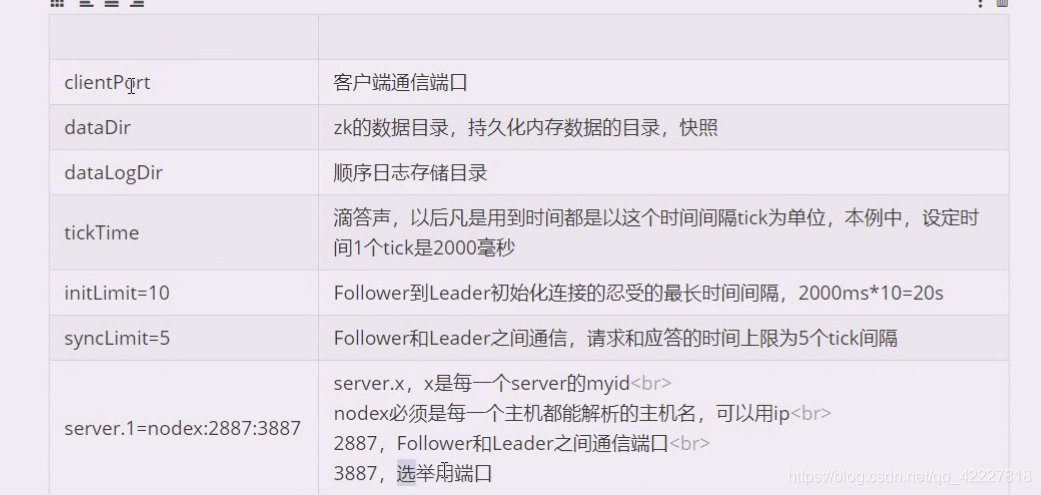 三个全是不同的端口,因为这里不能多个进程占一个端口
三个全是不同的端口,因为这里不能多个进程占一个端口
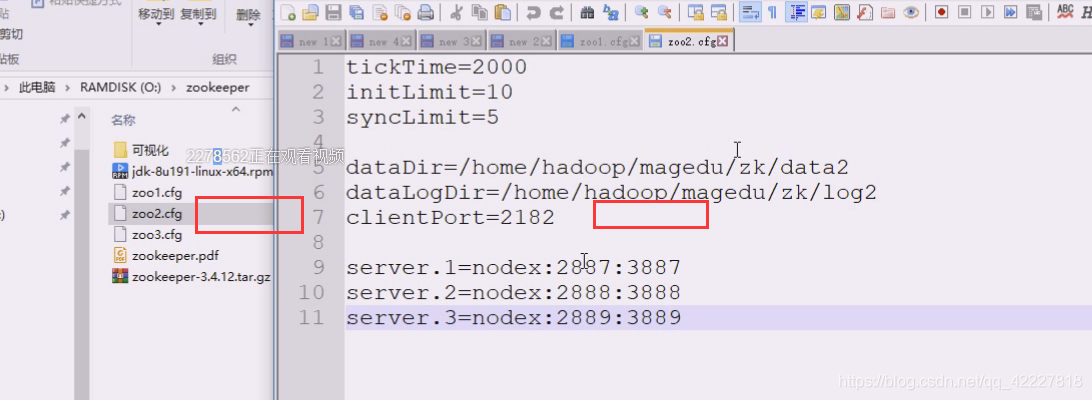
2182被第一台服务器绑走了。所以第二台就不能一样
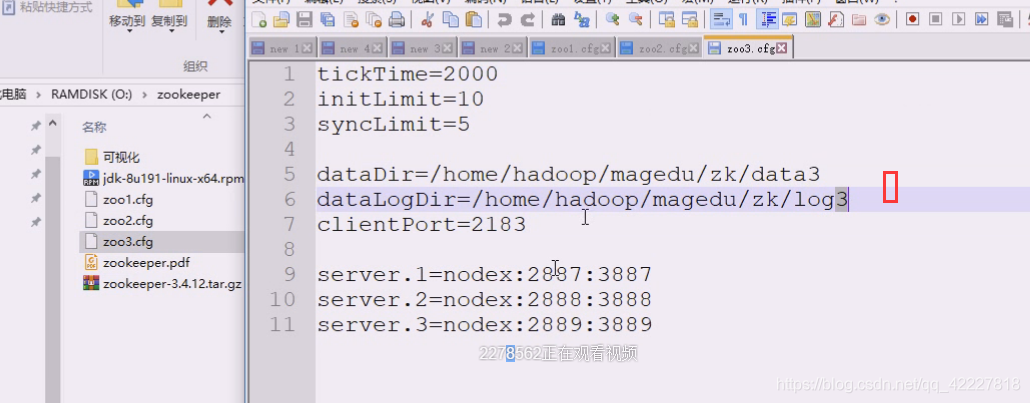
第三台也一样,数据目录和日志目录和端口都不一样
如果真的做分布式,每台主机配置都可以一样,因为没人用一个端口和文件,也就是三台配置文件一模一样
下面三个一模一样,告诉第一个服务,第二第三是;在第二个,告诉第一第三是谁
linux默认并不搜索当前目录,一般加./
现在准备启动三个,先看下主机名是不是这个
先把这目录创建下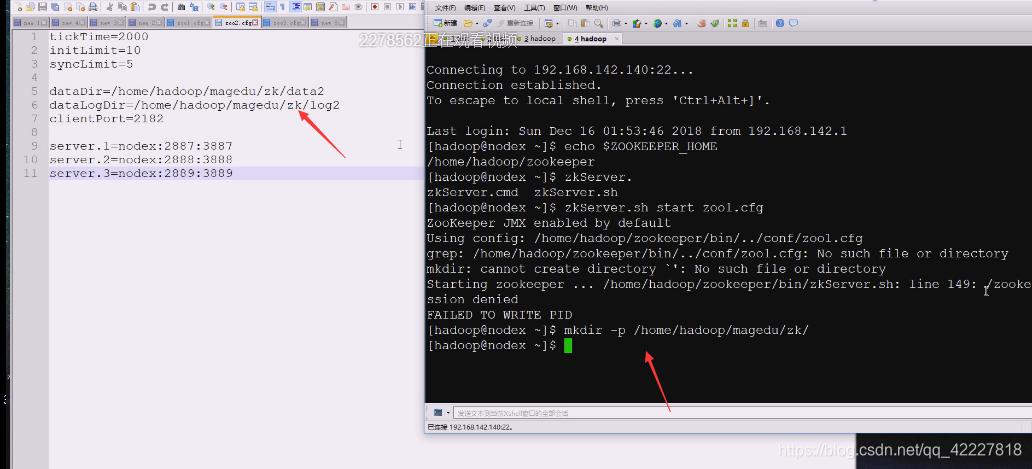
目录创建好

现在创建好了

如果不指定配置文件,就找默认的zoo-example.cfg,现在权限不够
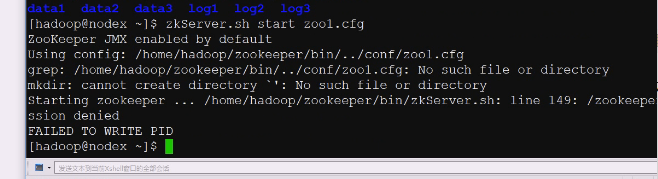
配置文件路径可能要改一下,现在就可以直接用了

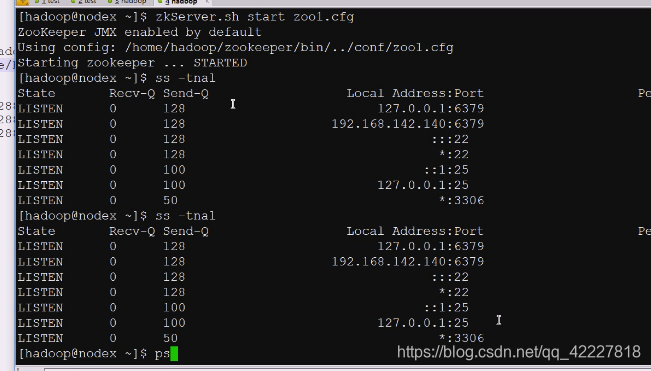
没有端口
需要改成前台启动
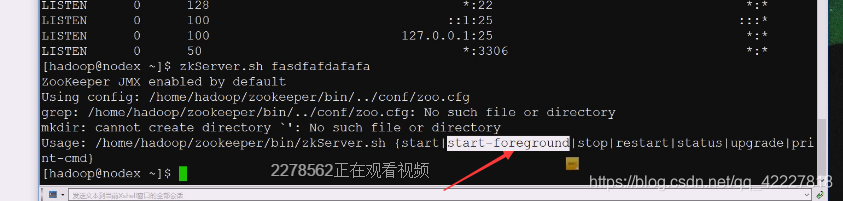 前台启动
前台启动

不能解析这个主机名
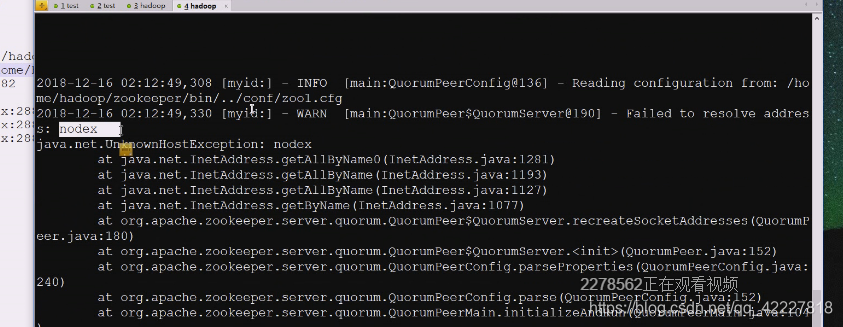
现在确实ping不过来

放在etc/hosts文件里

现在就可以了
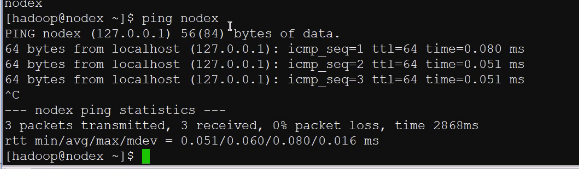
依然抛出问题
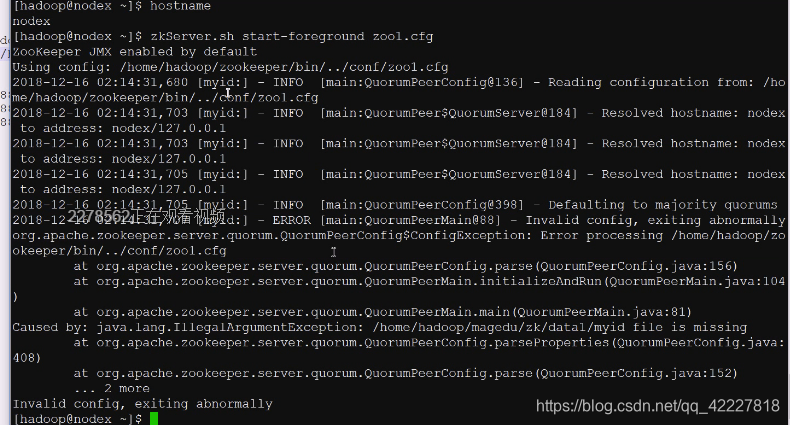
server.1,server.2,server.3,这个数字是id号,但是现在我们没指定过,现在没有myid文件。所以抛出异常 ,进程崩掉 了,在数据文件中,找不到myid文件

这是数据目录
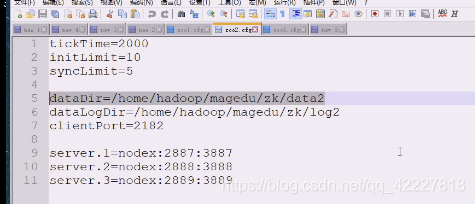
准备创建三个文件
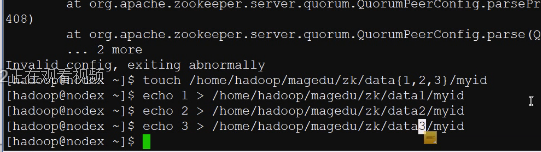

起来了,但是连接3889被人拒绝了
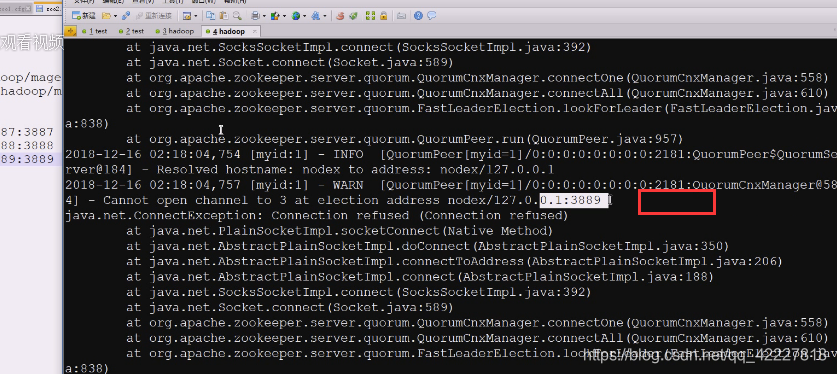
3889,3888还不在
准备快速投票选老大,现在单机只运行了一个进程,其他两个还没起来,现在想选自己当老大,其他两台不在,就不行

现在第一个启动成功了,2181
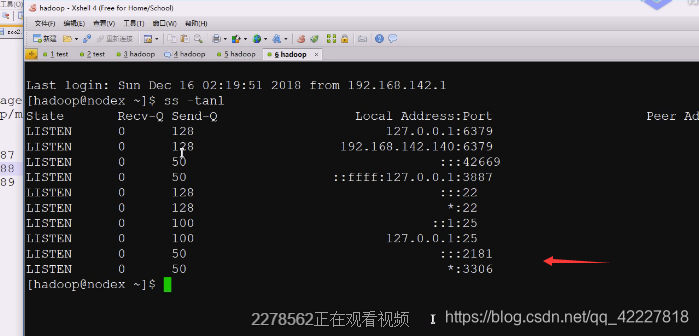
默认连接本机的2181

一会就自己崩溃了,没选举出老大,不可能给你提供服务,2181虽然在,但是不可能给你正常提供 服务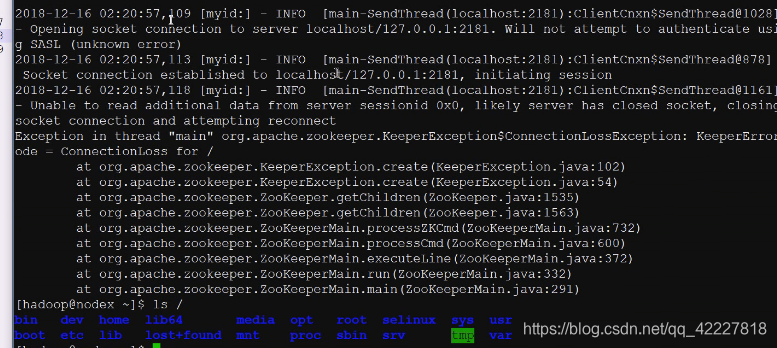
现在就是启动第二个
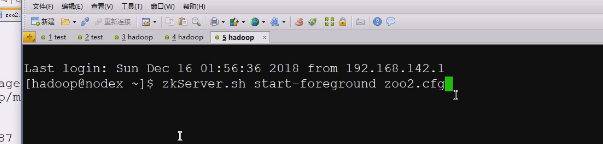
可以看到1,2了
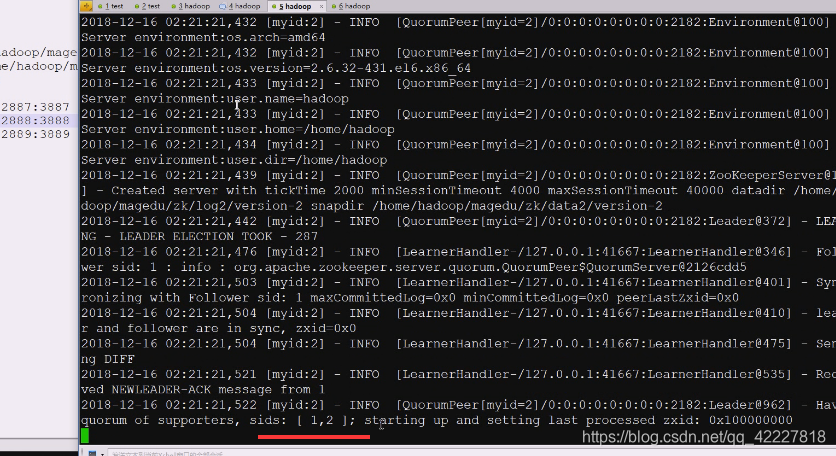
再次链接进来

这次选出老大了
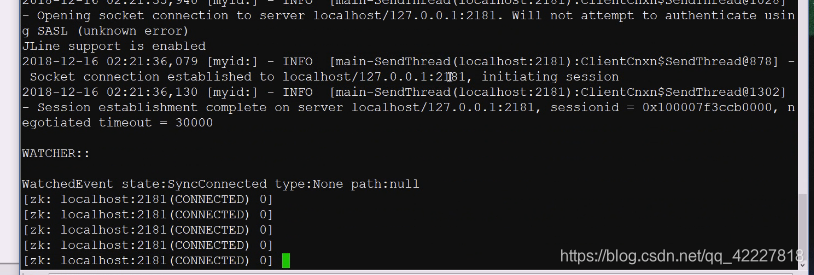
再启动一个
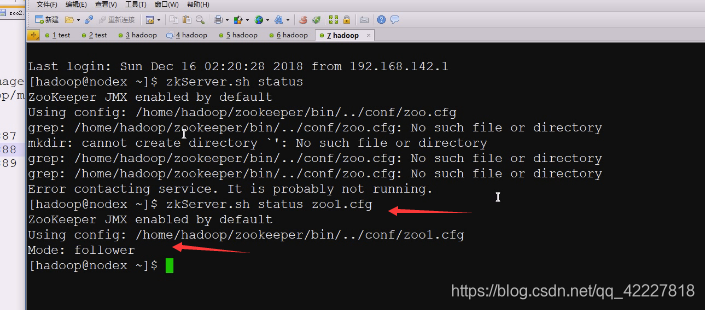
zoo2就是leader
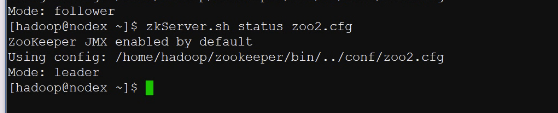
一开始起一台,就一直在那里投票,再启动一台,就决出老大了,第二个启动的应用程序暂时当老大
尝试启动第三个
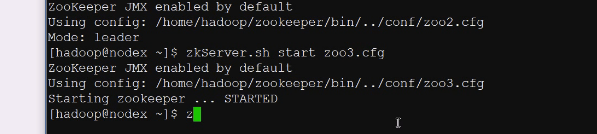
现在的状态是follower,有老大了,就只能跟随

习惯上都配置主机名,不配置ip地址,类似这样
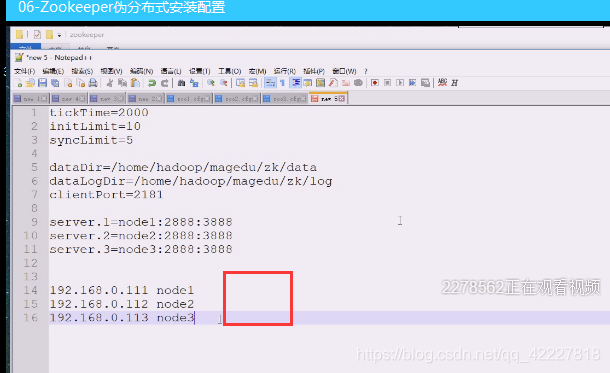
这是用来选举的
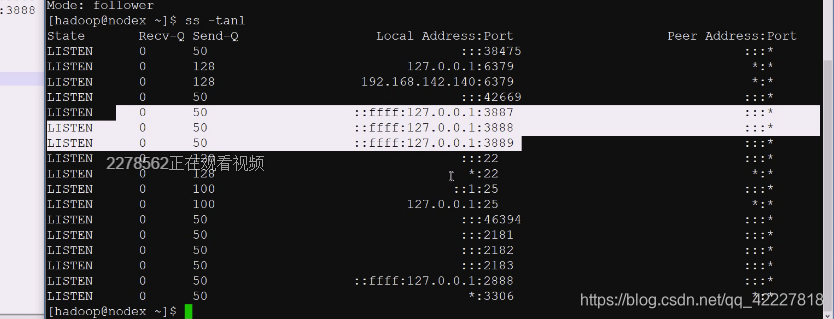
这是客户端的访问端口



















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









