







 本文深入探讨了正则表达式的基本概念与应用,详细解释了单行模式和多行模式下元字符的行为变化,以及如何正确处理换行符、行首和行尾等特殊场景。同时,提供了实用的正则表达式编写技巧,帮助读者理解和运用正则表达式解决实际问题。
本文深入探讨了正则表达式的基本概念与应用,详细解释了单行模式和多行模式下元字符的行为变化,以及如何正确处理换行符、行首和行尾等特殊场景。同时,提供了实用的正则表达式编写技巧,帮助读者理解和运用正则表达式解决实际问题。

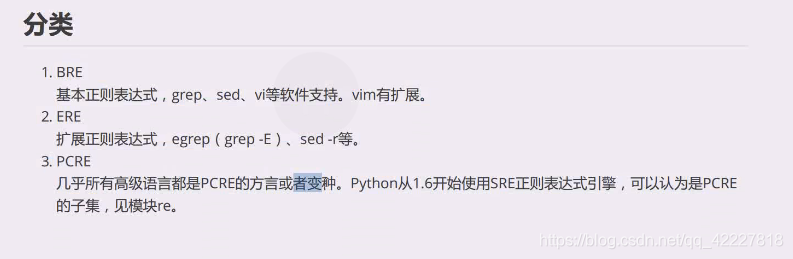
正则表达式是进行检索和替换的
大多数变成语言都是用的PCRE方言


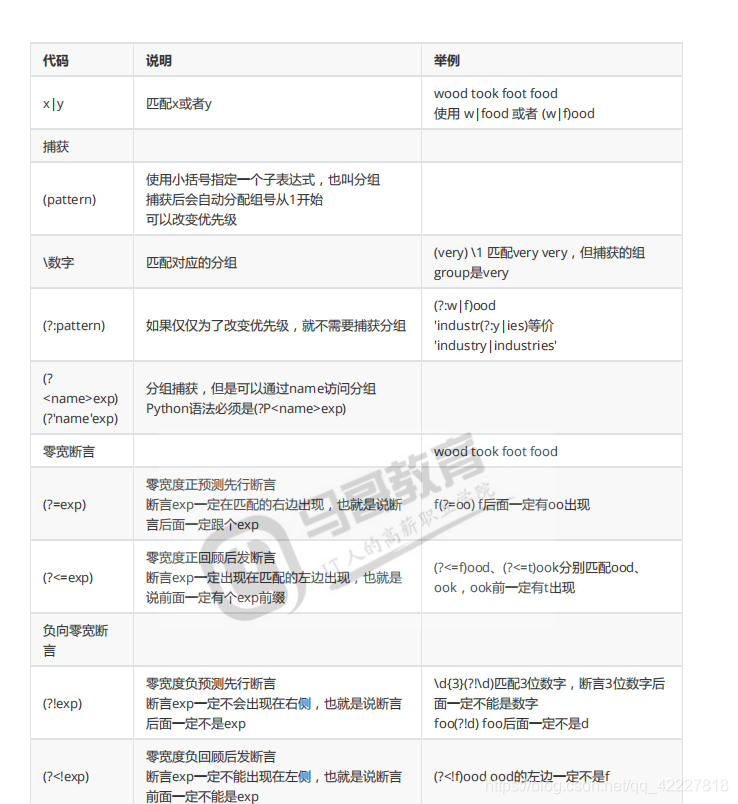



遇到正则表达式先用一下提供的工具,不同的库可能某些地方表现的略有不同
引擎选项

把所有都看做一行,跟换行符无关,、
单行是看不看\n,控制这个\n起不起作用,单行是控制换行符
多行是控制行首行尾的元字符

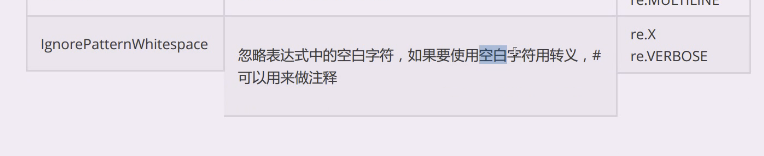
**总结:
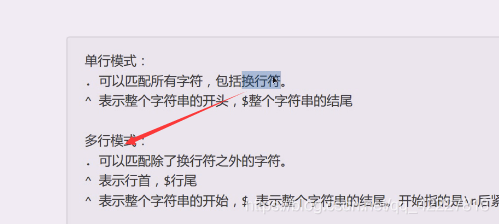
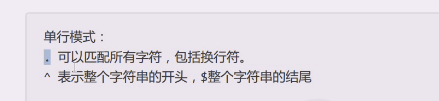
单行模式:
.可以匹配所有字符,包括换行符。
^表示整个字符串的开头,$整个字符串的结尾
多上模式:
.可以匹配除了换行符之外的所有字符。
^表示行首, $行尾
^表示整个字符串的开始,¥ 表示整个字符串的结尾。开始指的是\n后紧接着下一个字符,结束指的是/n前的字符 **
可以认为,单行模式就如同看穿了换行符,所有文本就是一个长长的只有一行的字符串,所以^就是这一行字符串的行首,$就是这一行的行尾。
多行模式,无法穿透换行符,^和¥还是行首行尾的意思,只不过限于每一行
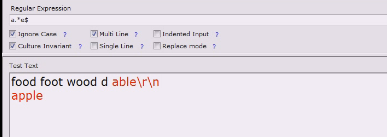
注意:注意字符串中看不见的换行符,\r\n会影响e¥的测试,e¥只能匹配e\n
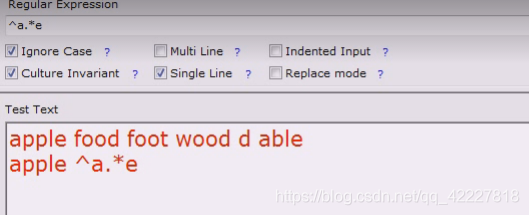
单行模式
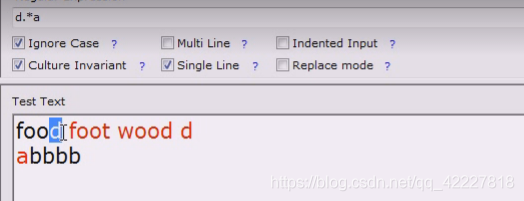
单行模式去掉就匹配不到了,见到换行符就断了,一般是不想要的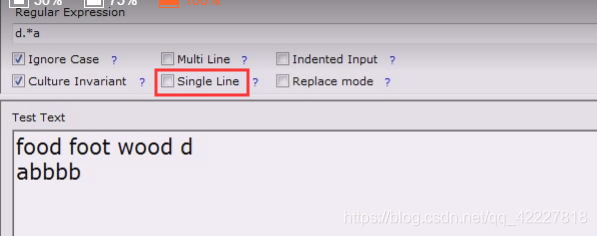
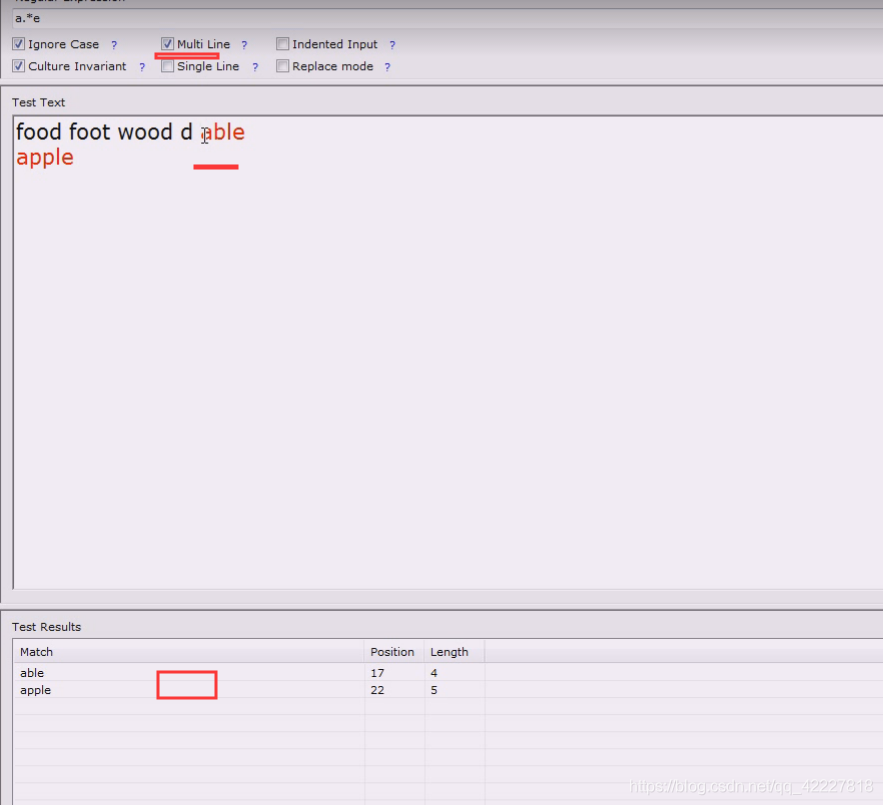
如果选上单行模式,相当于.点的意义包括换行符
去掉单行模式,就是.不包括换行符,就匹配到两个
单行,就是匹配一个,多行并不是控制换行符的
单行模式,换行符就是.点号包括的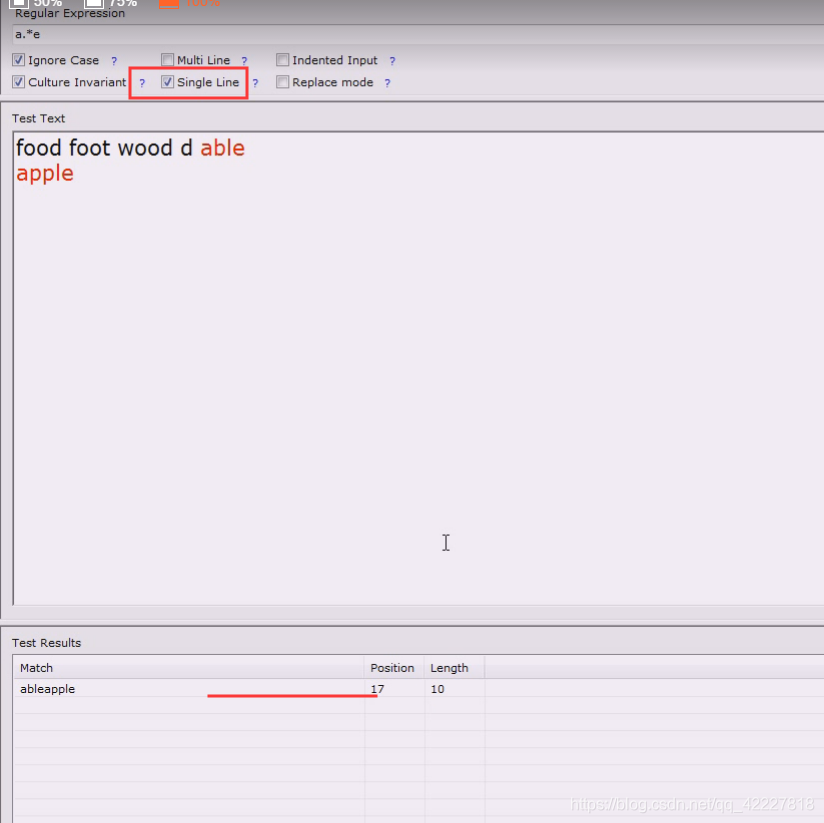
在多行的时候
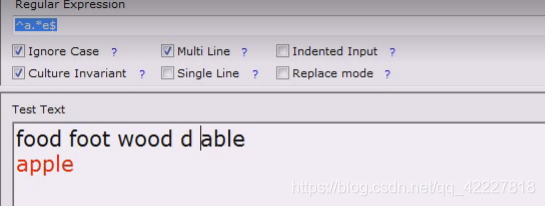
一旦看行首就不要看single line了
要看multiine,第二行就满足了
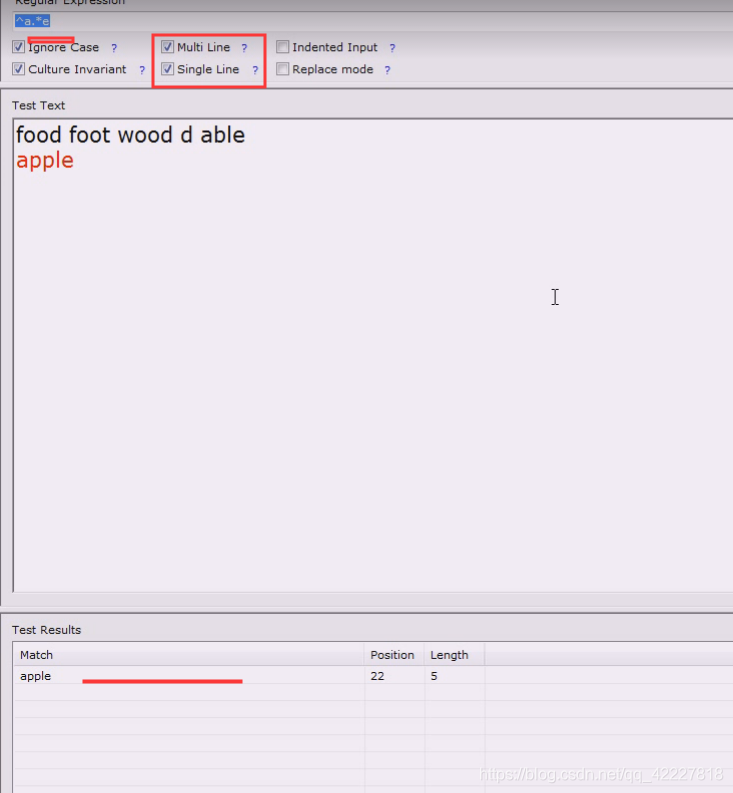
不选多行就匹配不到,不是多行这个就是看起来一个长的字符串,行首就是f
多行模式就切出多个行首行尾来,这时候就可以用^秃子符
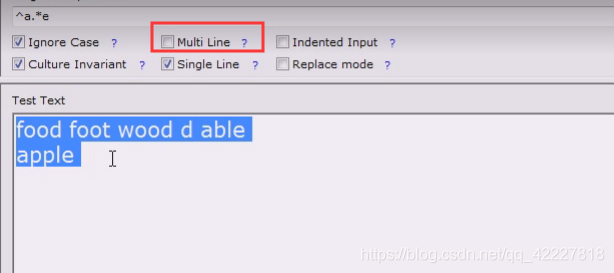
单行模式就可以修改点.缺省的能力,本来是不可以匹配换行符的\n,单行模式是可以匹配的
单行模式的时候^是指整个字符串的开头,¥指整个字符串的结尾
多行模式,没有修改.点本来的意思
每一行行首就是^,行尾¥
$行尾的时候要注意,因为前面可能有个\r回车,尤其在windows下,容易出现
是\r\n ,\n

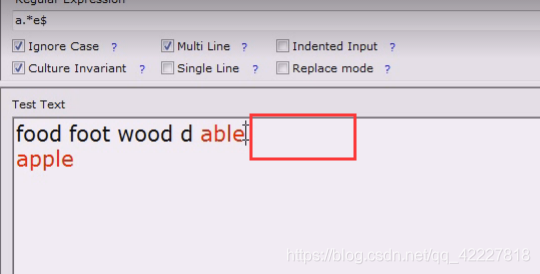
如果这个地方有回车符就匹配不到了,尤其在解决行尾的时候要特别小心
不看成多行就匹配不到了
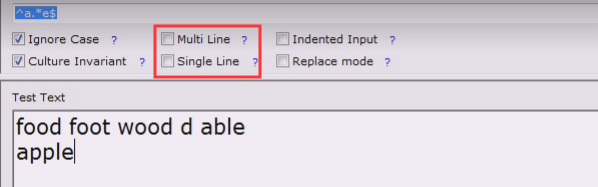
我们一般处理的时候,都是一行行迭代文件,所以多行模式一般用不到

不是多行模式,就不看第二行
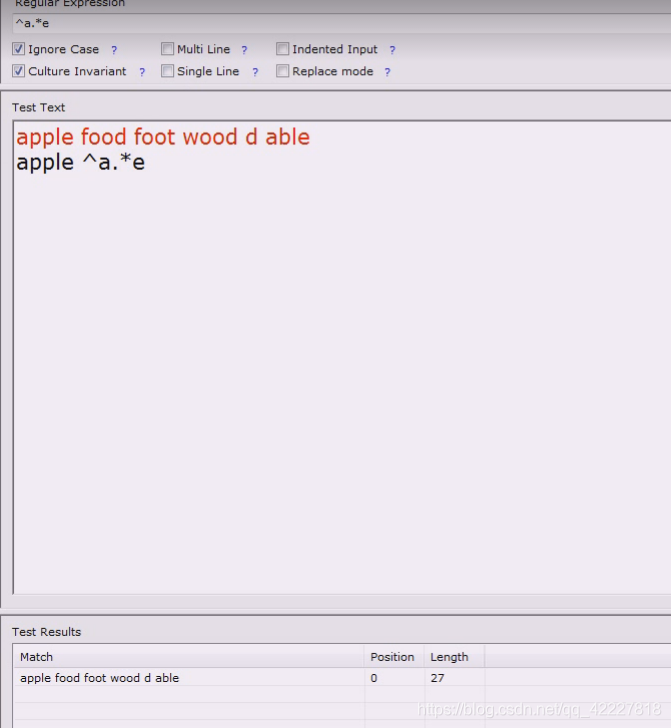
加上单行就是从头到尾
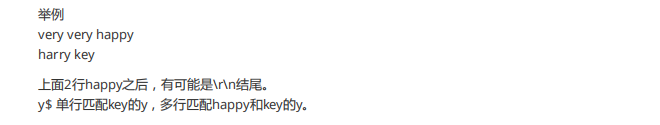
没用多行,当作大字符串来看,key就是结尾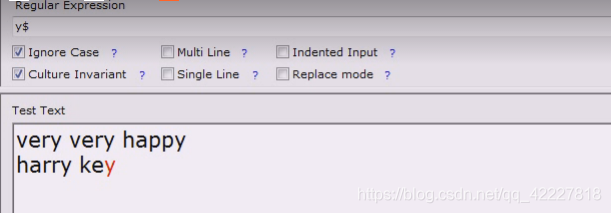
多行模式,$的意思一直是行尾
如果happy后面有\r\n就有问题
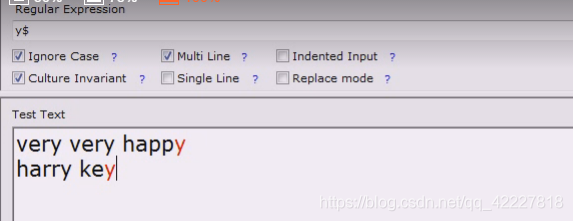
现在有\r\n回车换行
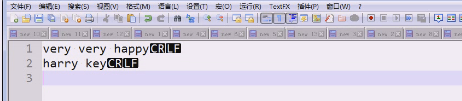
查找的时候使用正则表达式
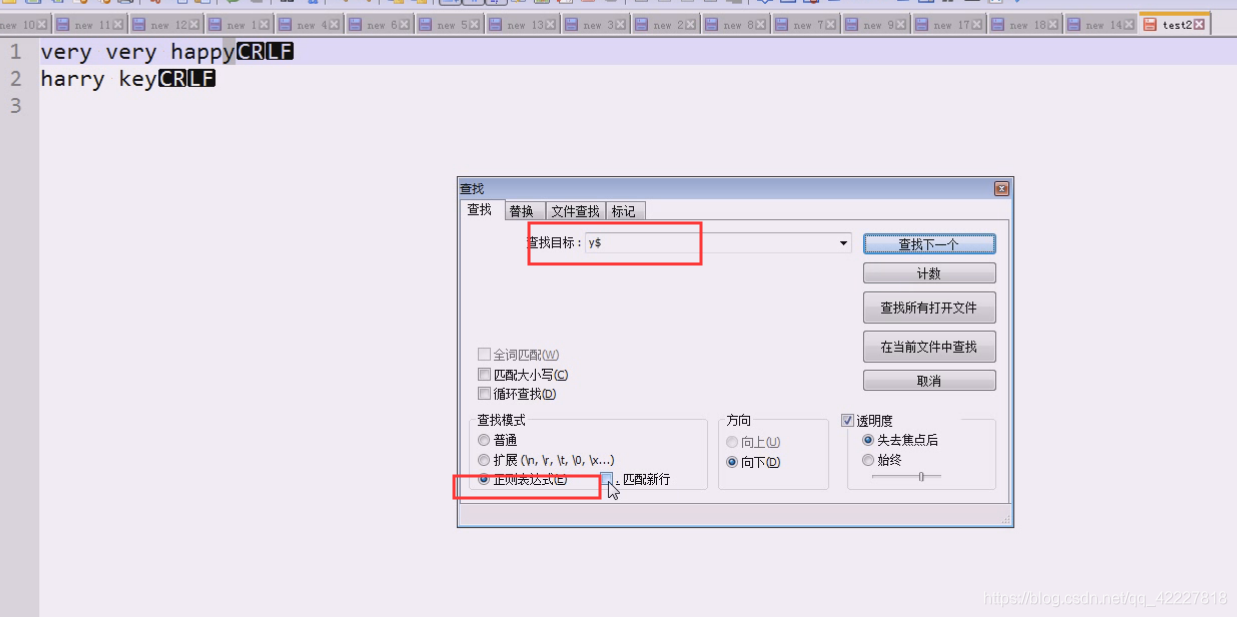
如果担心回车换行符,就可以这么写 \r?

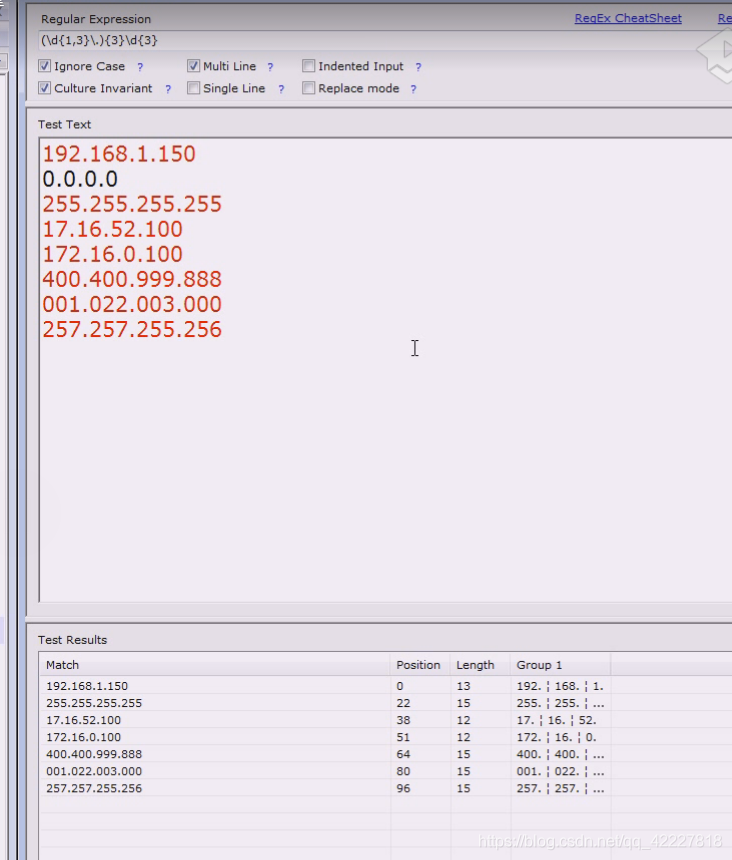
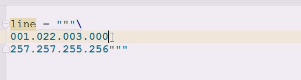
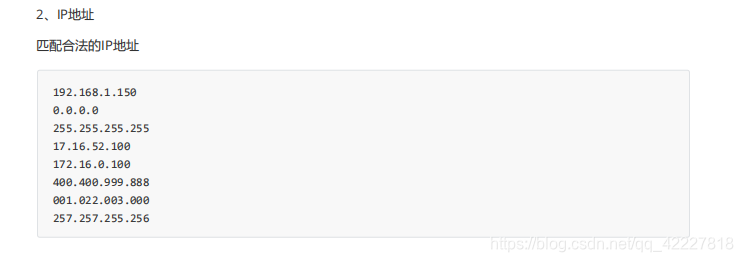
每一段有效的应该是0-255,每个字段是一个字节,4段是个4字节
这个其实就是2位数或者1位数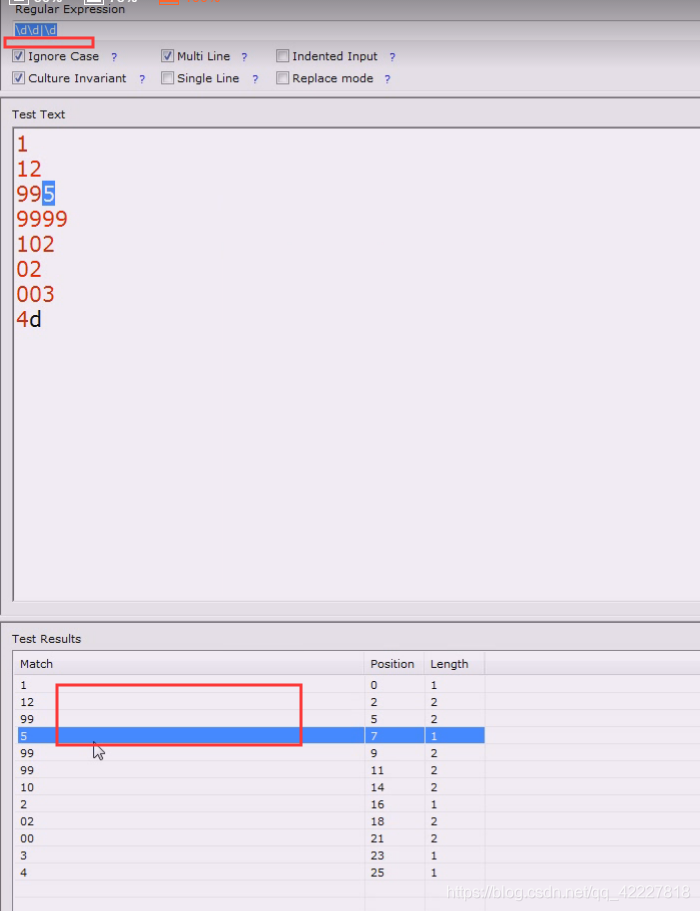
但是着并不是我们想要的,我们应该先想要一开始就是995,三位数,两位数,一位数
这4位没有加断言判断所以就提取了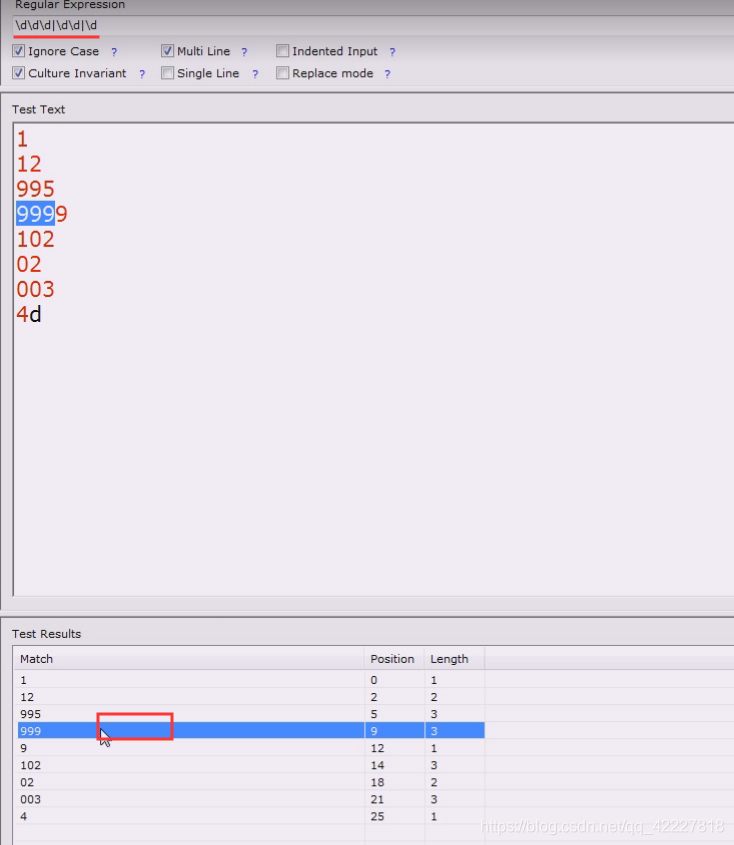
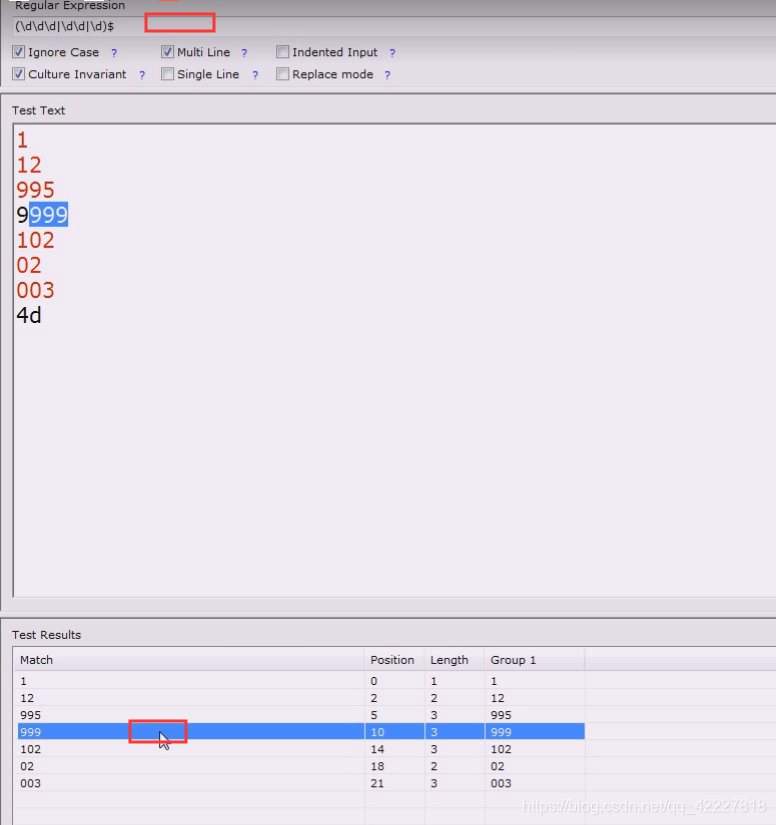
现在就可以控制数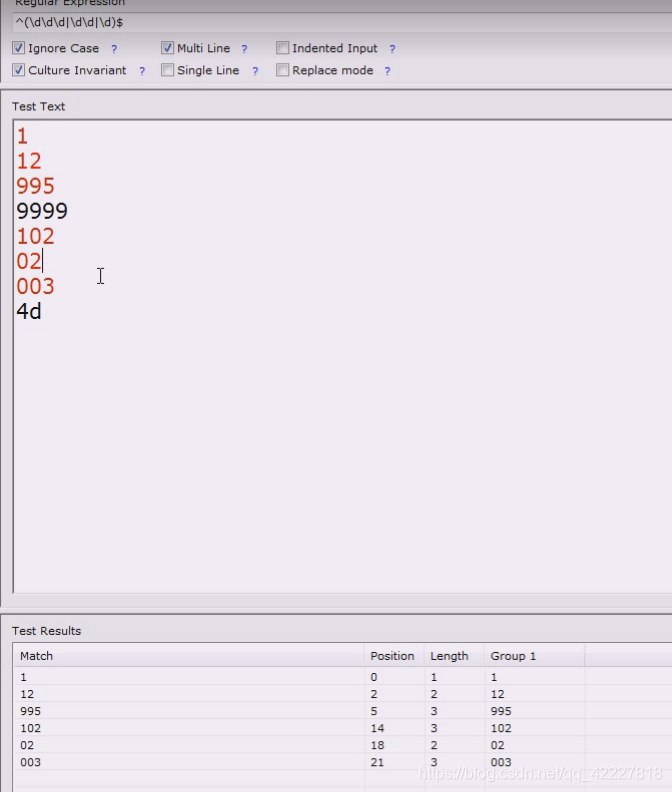
但是遇到0003就不好判断几位数了,我们是看着文本写的表达式,不可能取适应所有的例子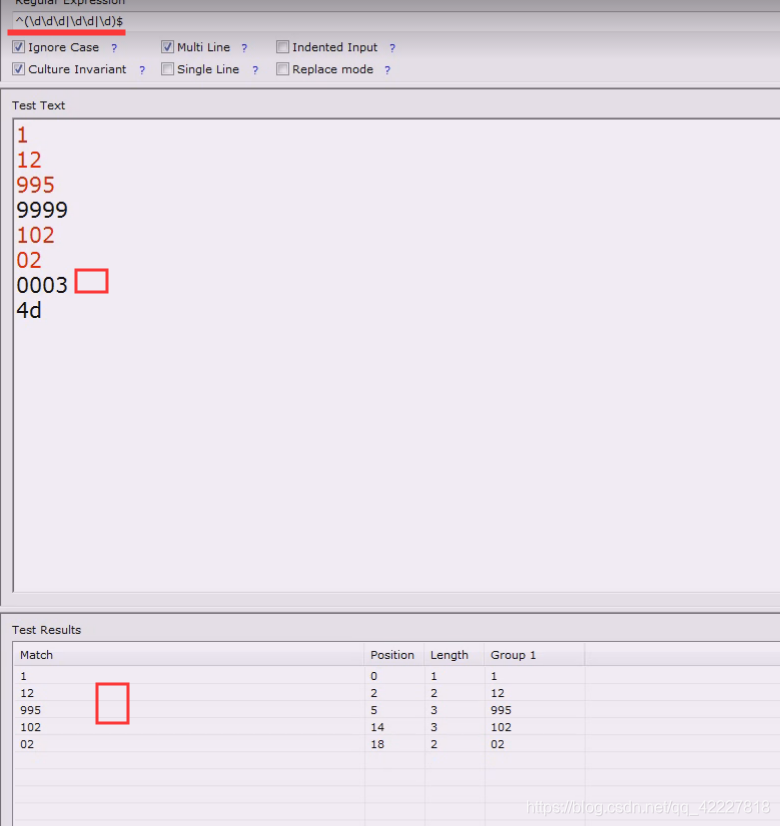
改成(\d{1,3})¥目前来看,003和02都在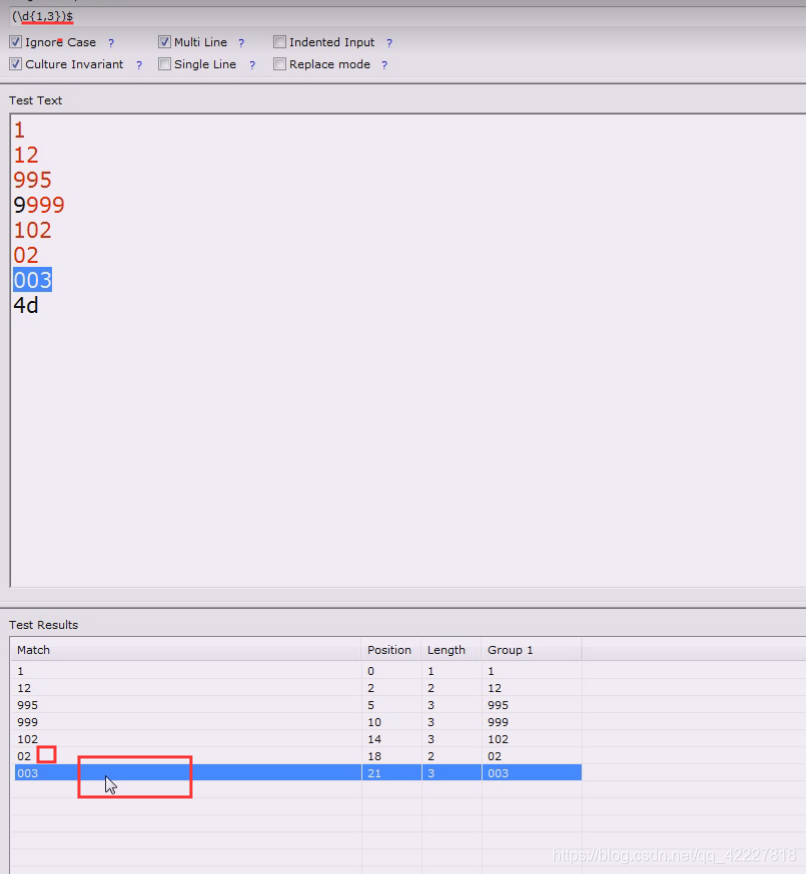
表示两位先占
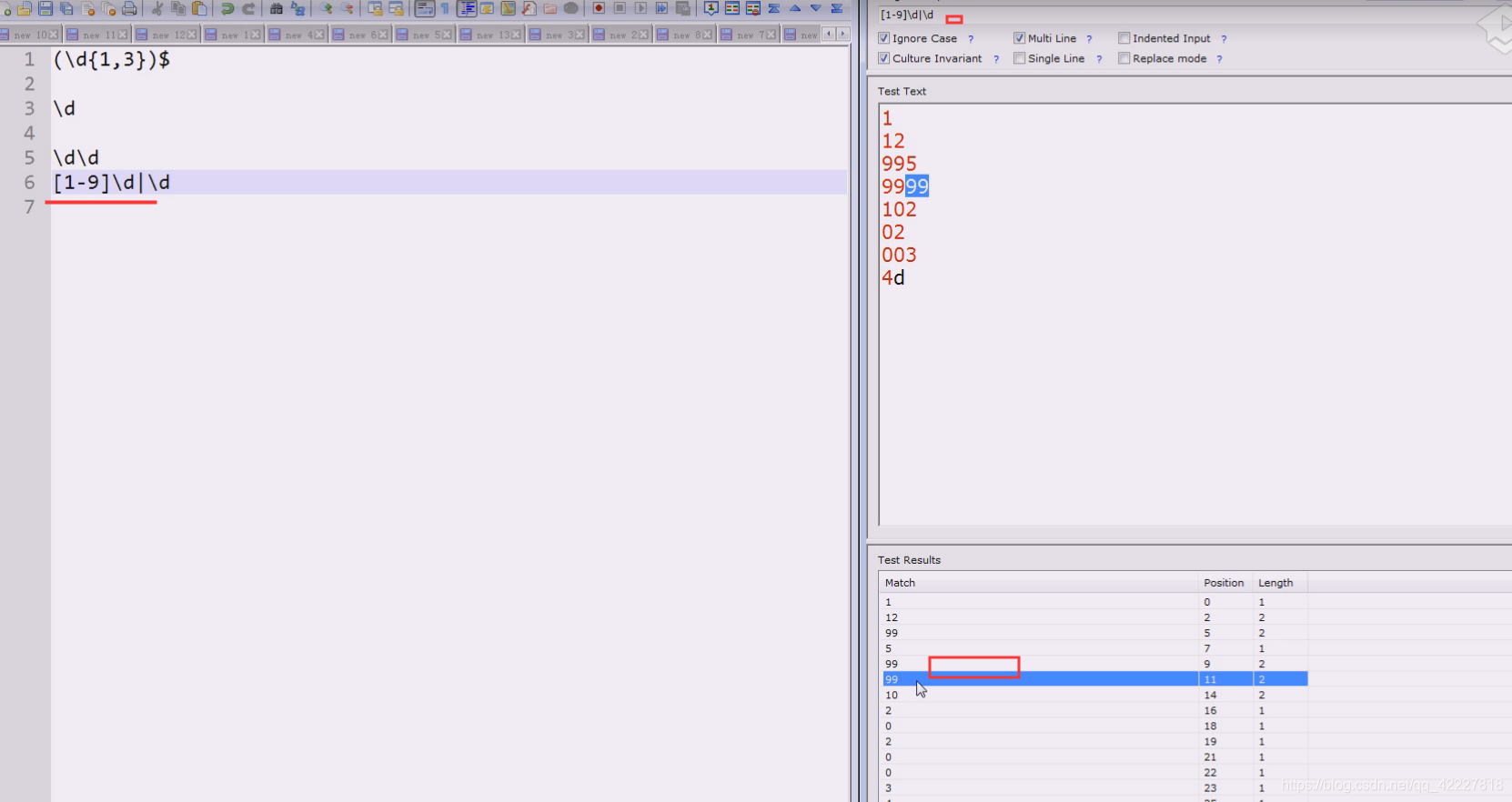
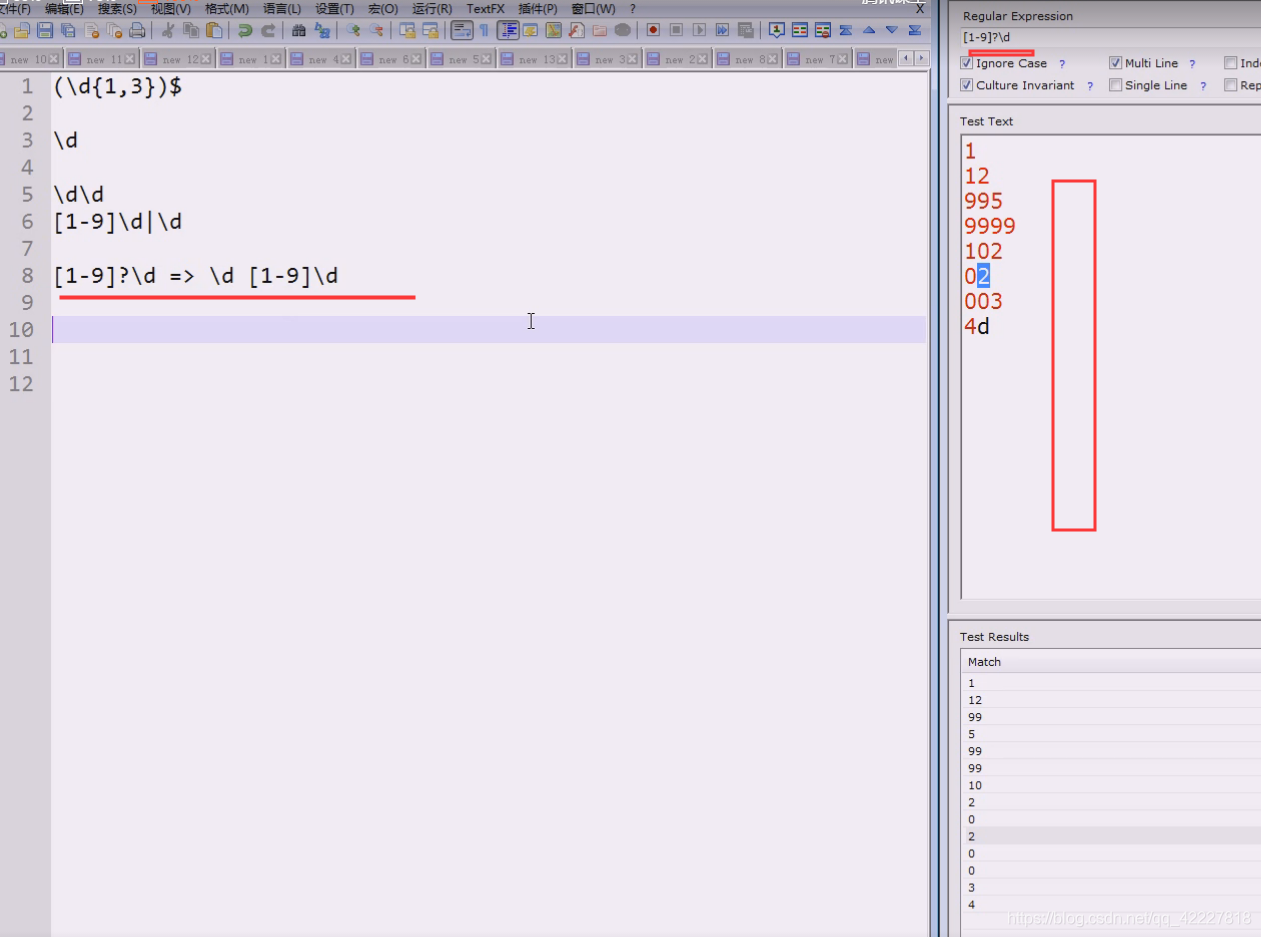
这个能代表这么多种情况
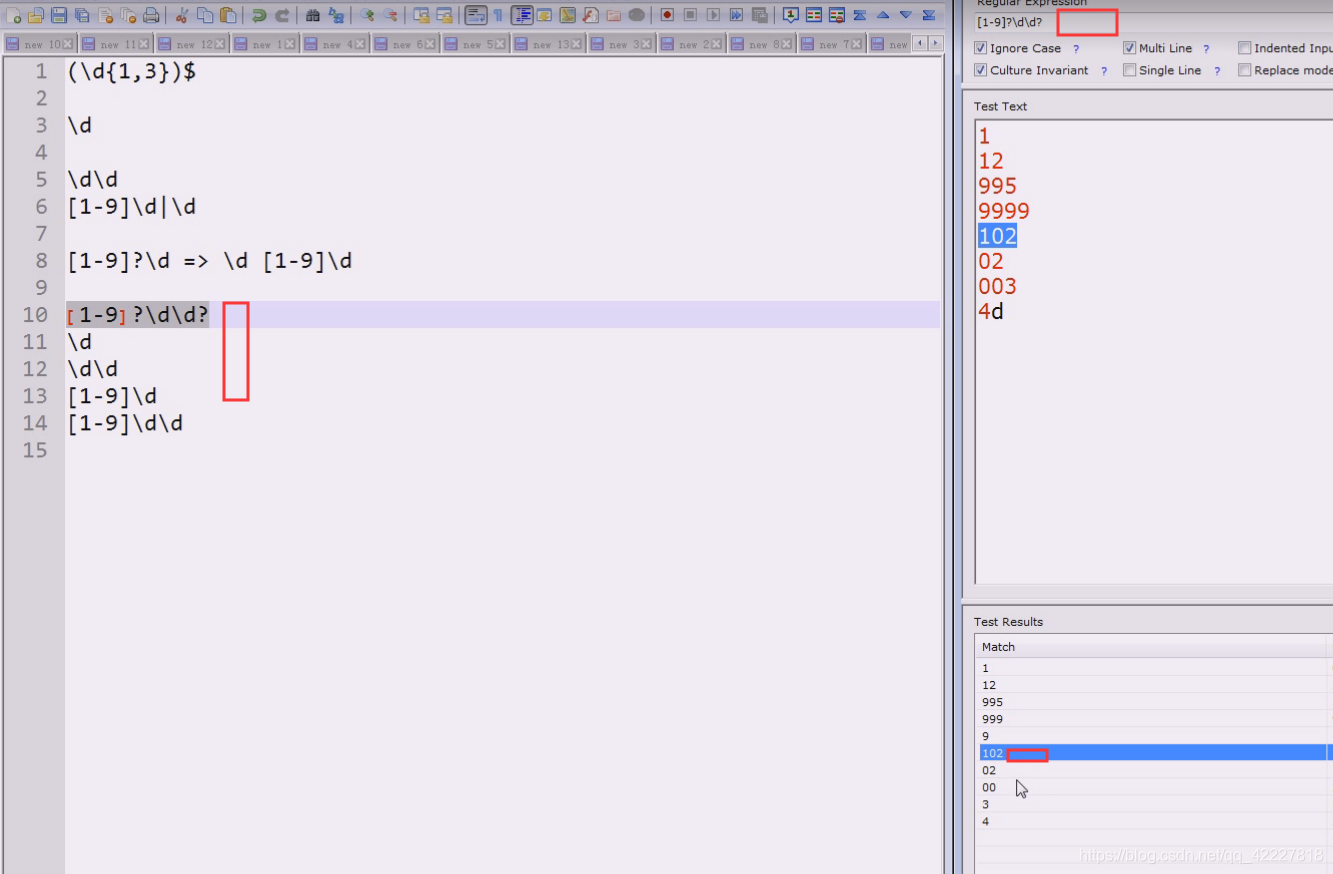
现这样搞定02恐怕需要做一些调整

多种写法,可以试着掌握


最简单的方式i

不能把0丢了
但是第一个字符出现只能是0/1/2,因为有效范围是0-255

先塞进去看看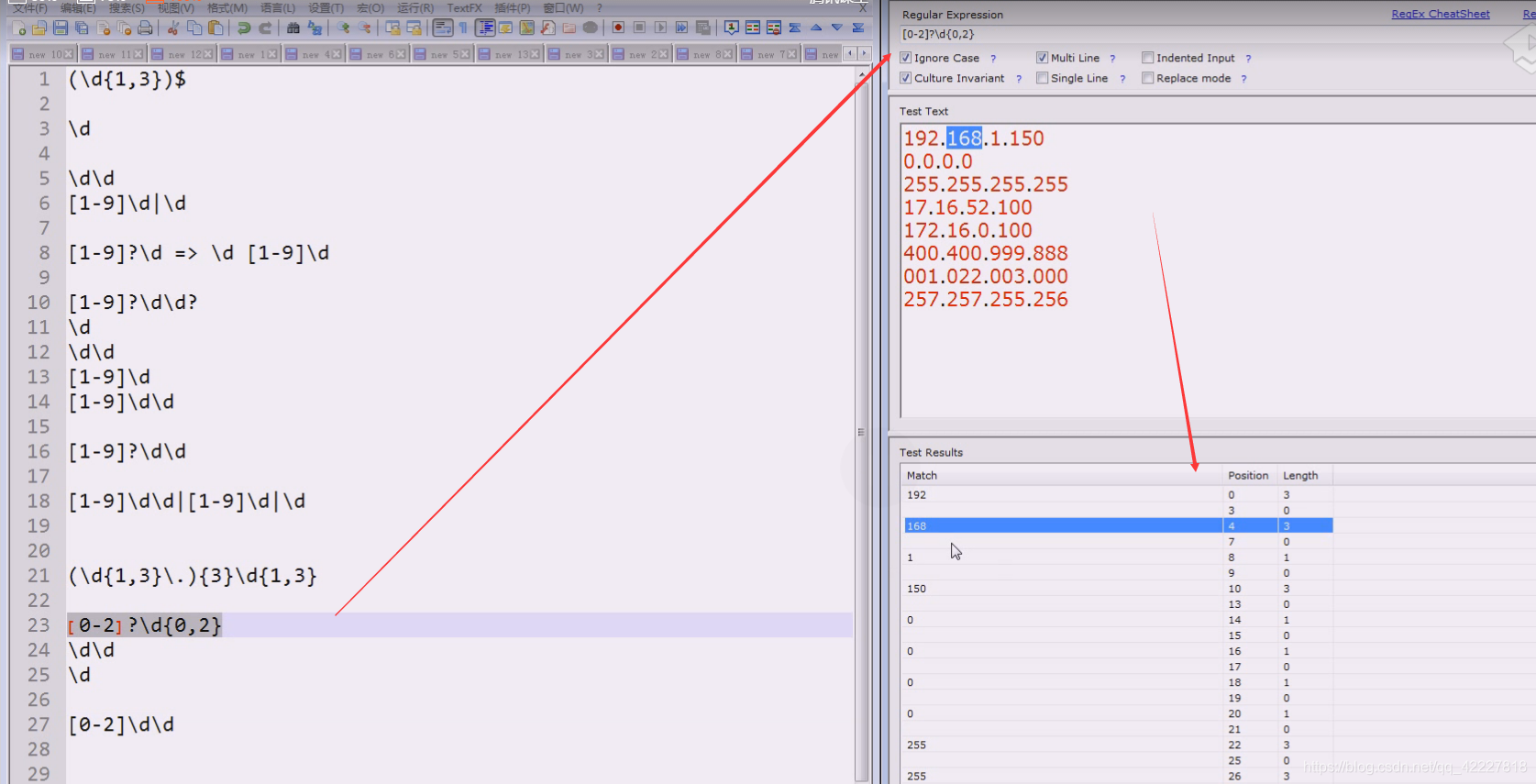
现在要解决ip地址所谓的范围问题,现在只能用或者的关系来判断
100几200几,两位数,1位数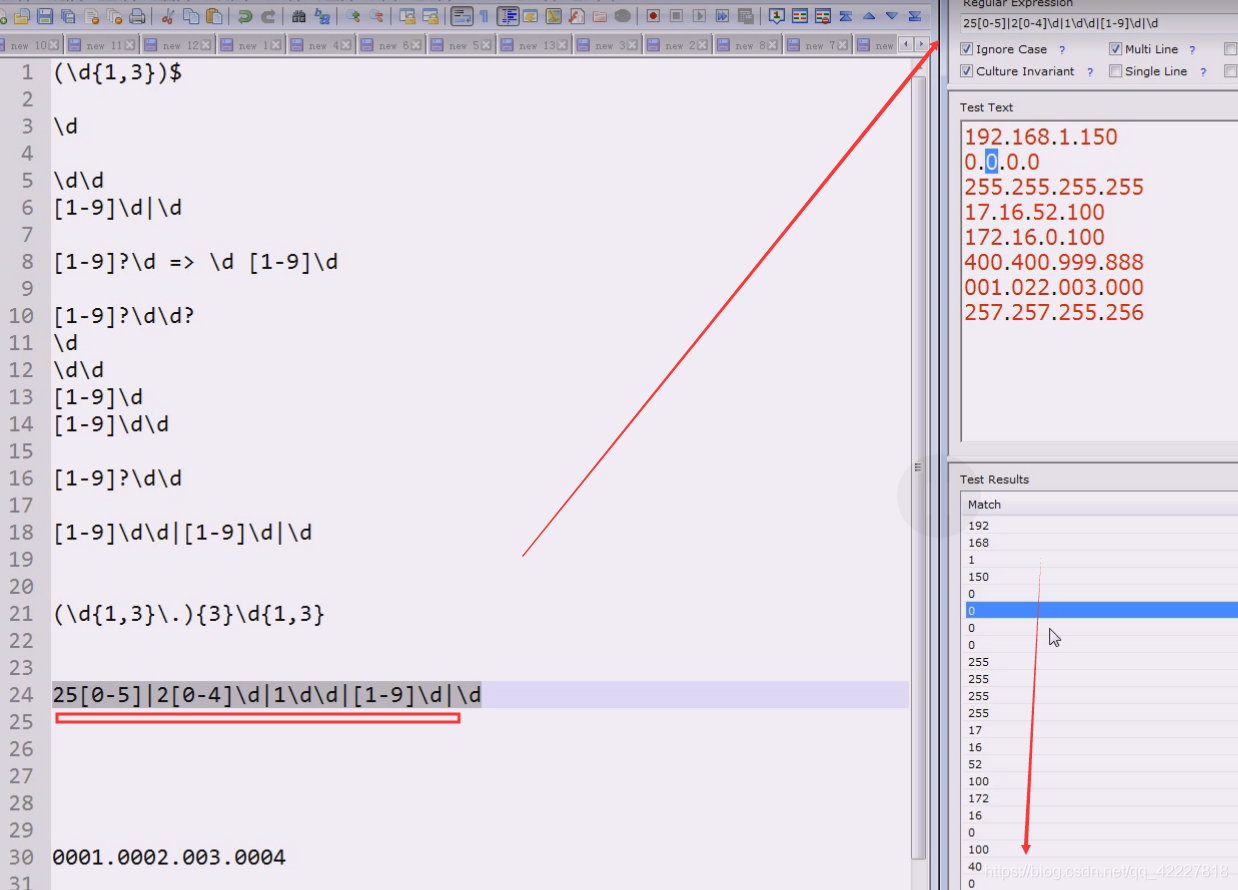
加个转义.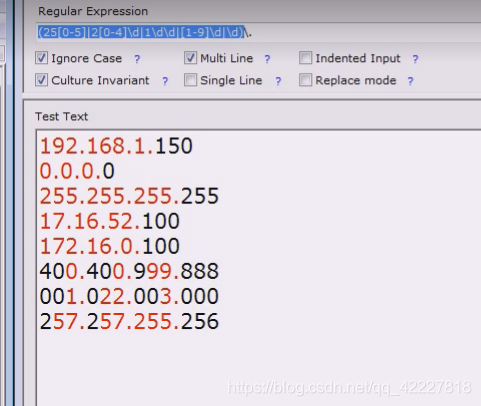
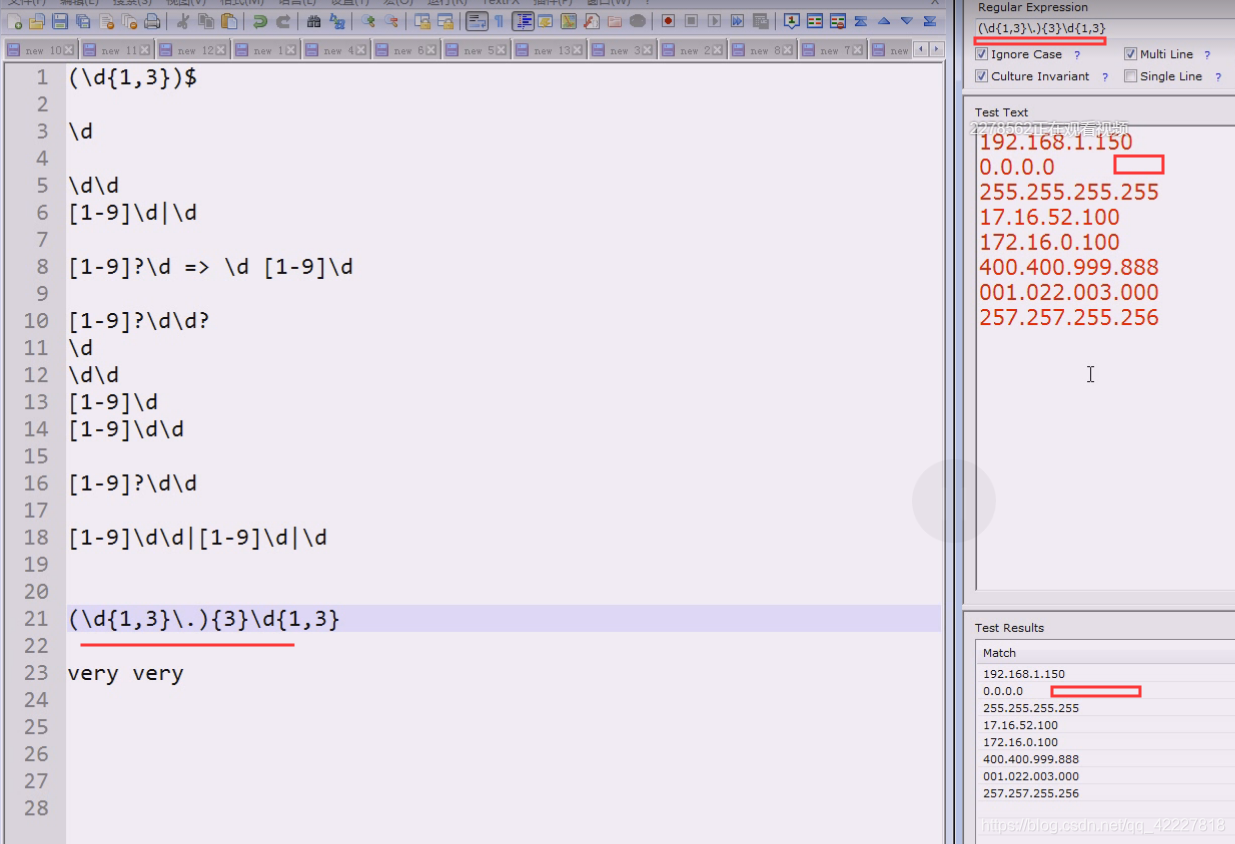
这个模式要重复三回

再补全后面的,就正好是我们想要的东西
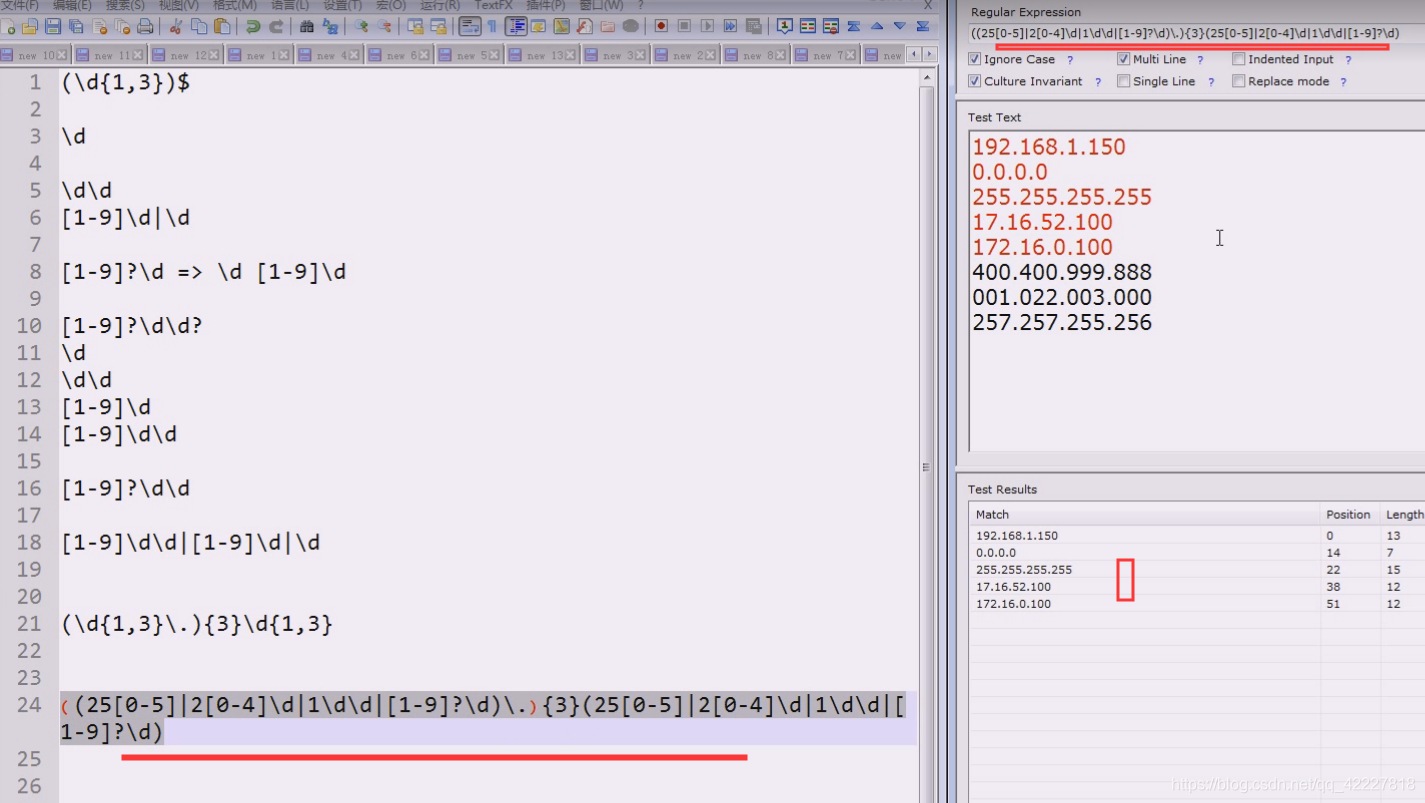
主要看分组

不想要分组就可以再某个括号前面加?: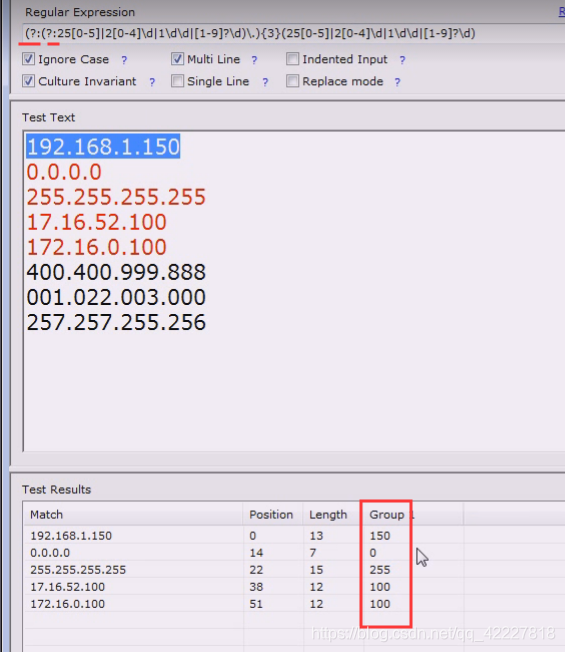
大字符串就需要用splitlines
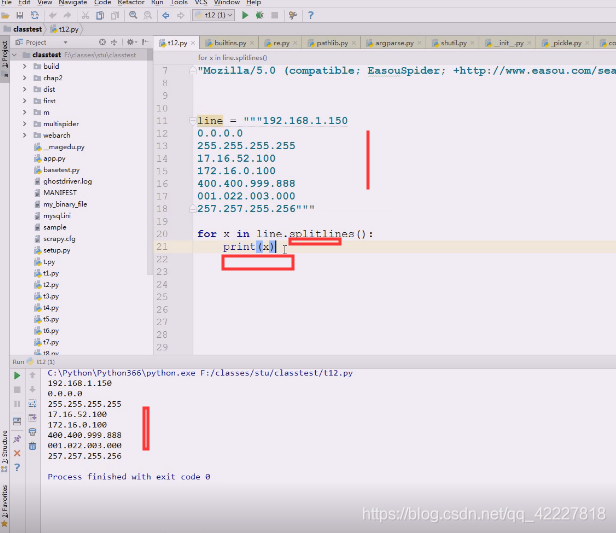
每一个ip都是字符串,
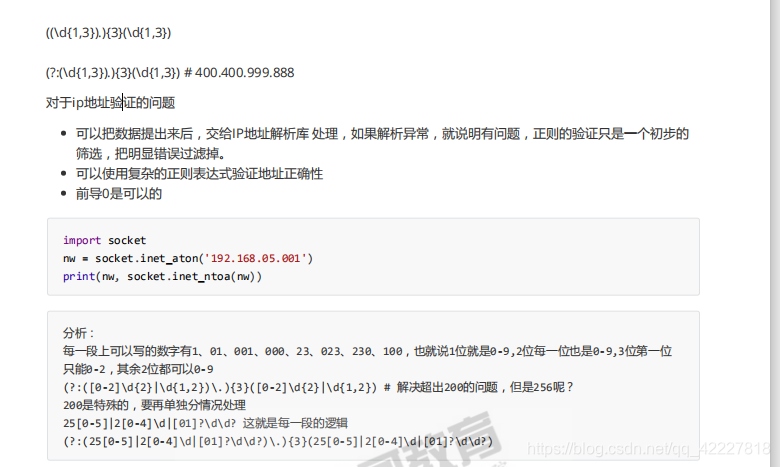
socket有一些方法,
有些东西就出异常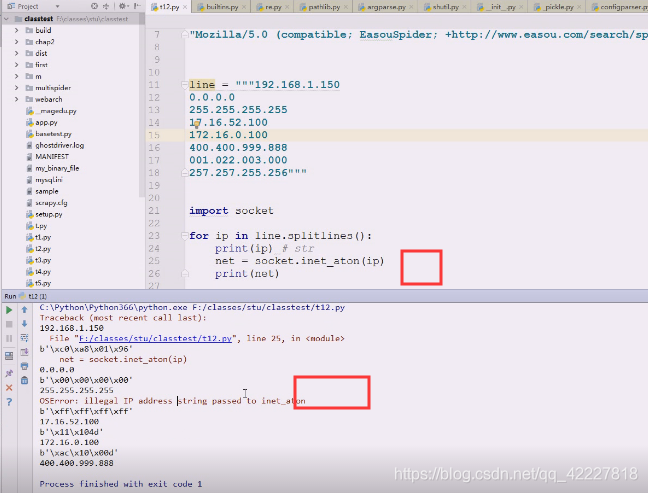
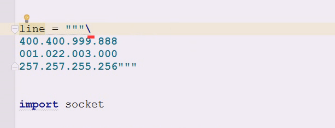
400这种地址就超界了

都告诉你是非法地址

对比一下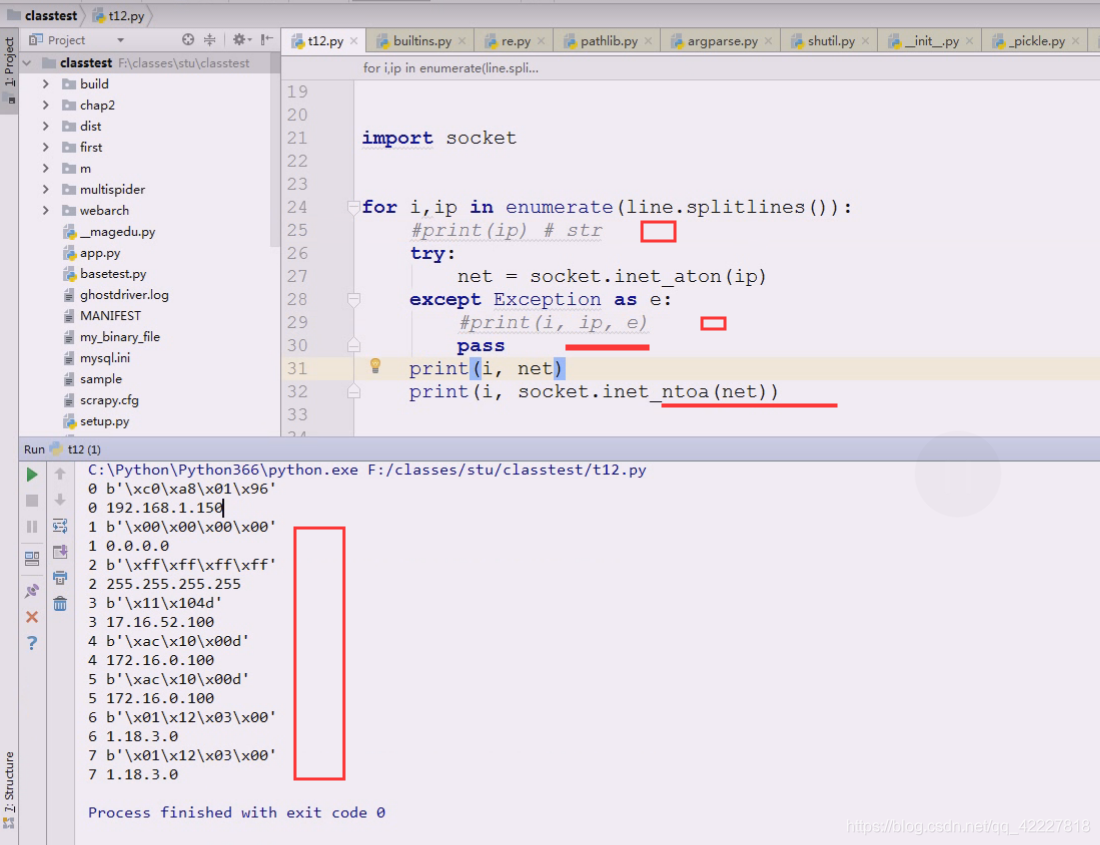
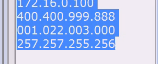
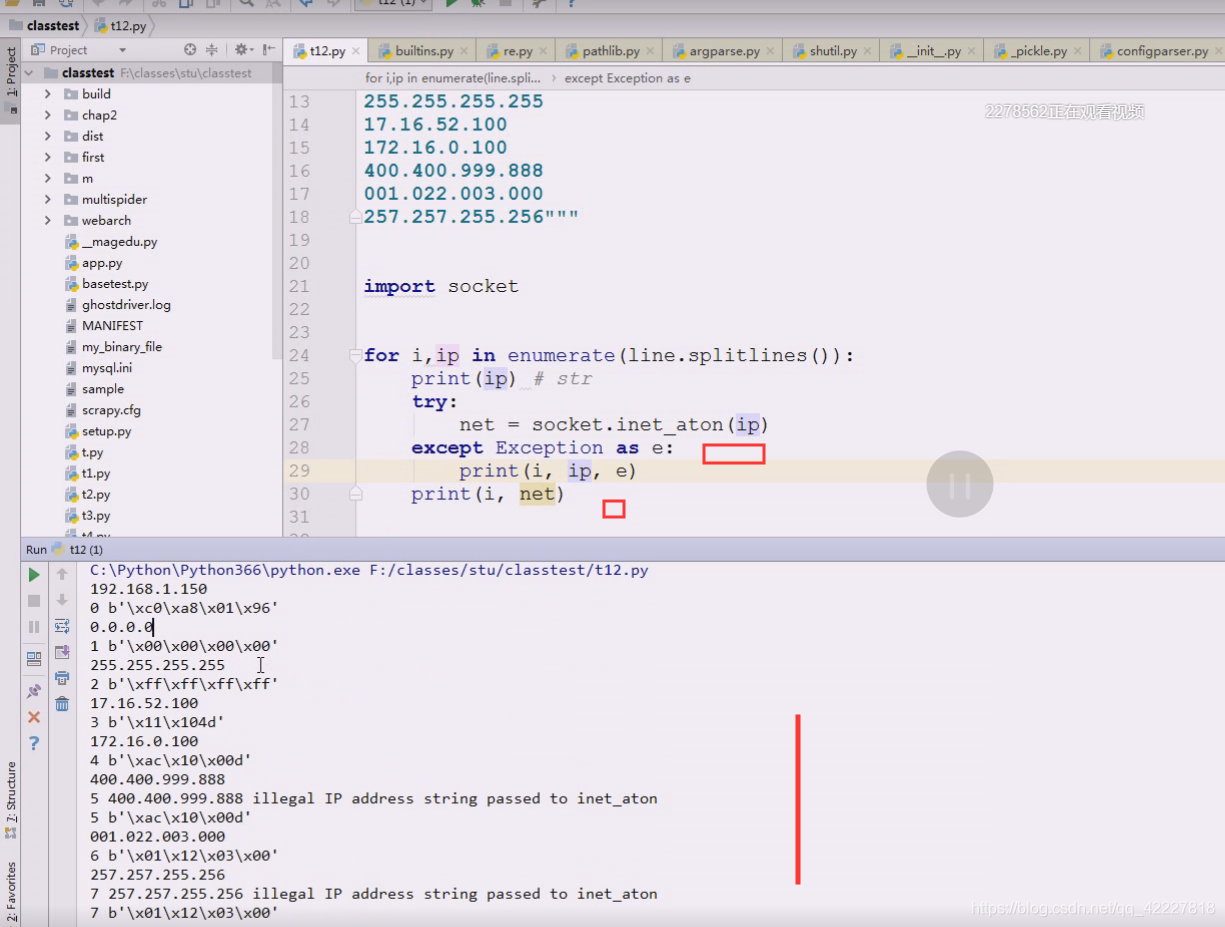
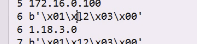
001转成,1转成16进制是1 \x01,22转成\x12,3 =\x03,0=\x00
最后是1.18.3.0
现在就光看几个有问题的
\续航符
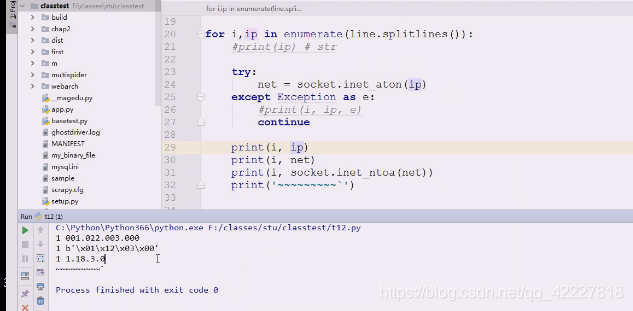
400出问题直接跳过相当于不存在

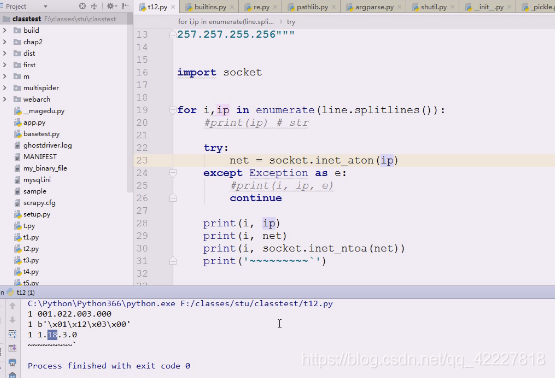
022是8进制,2*8=16+2=18,没当整数转,看到前面有0就当8进制转了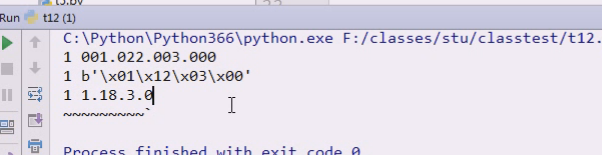
这个超界就根本没有输出
大可以写的简单一点,ip地址对不对交给socket库来解决,没必要想半天把精确的值抠出来,跟电话号码一样,别再费很大劲了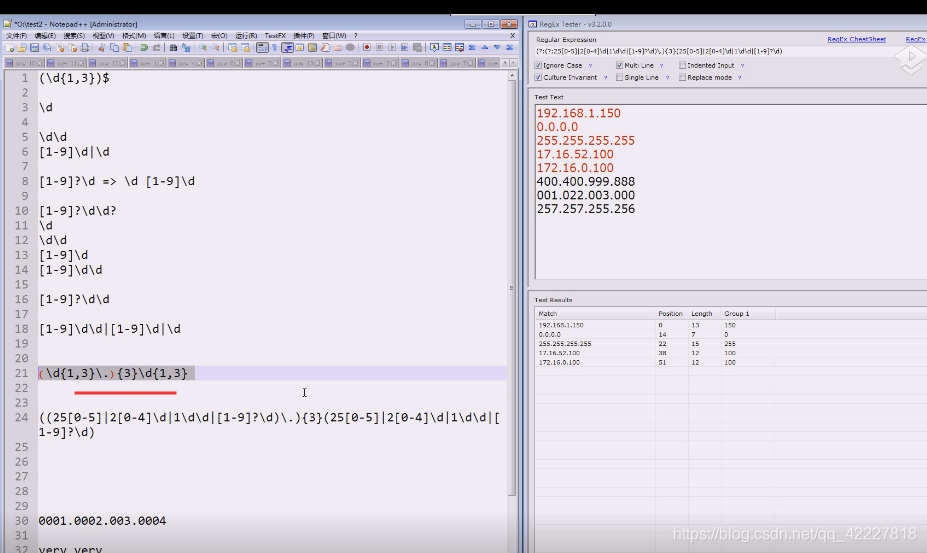


match匹配的是全长,要看看匹配的长度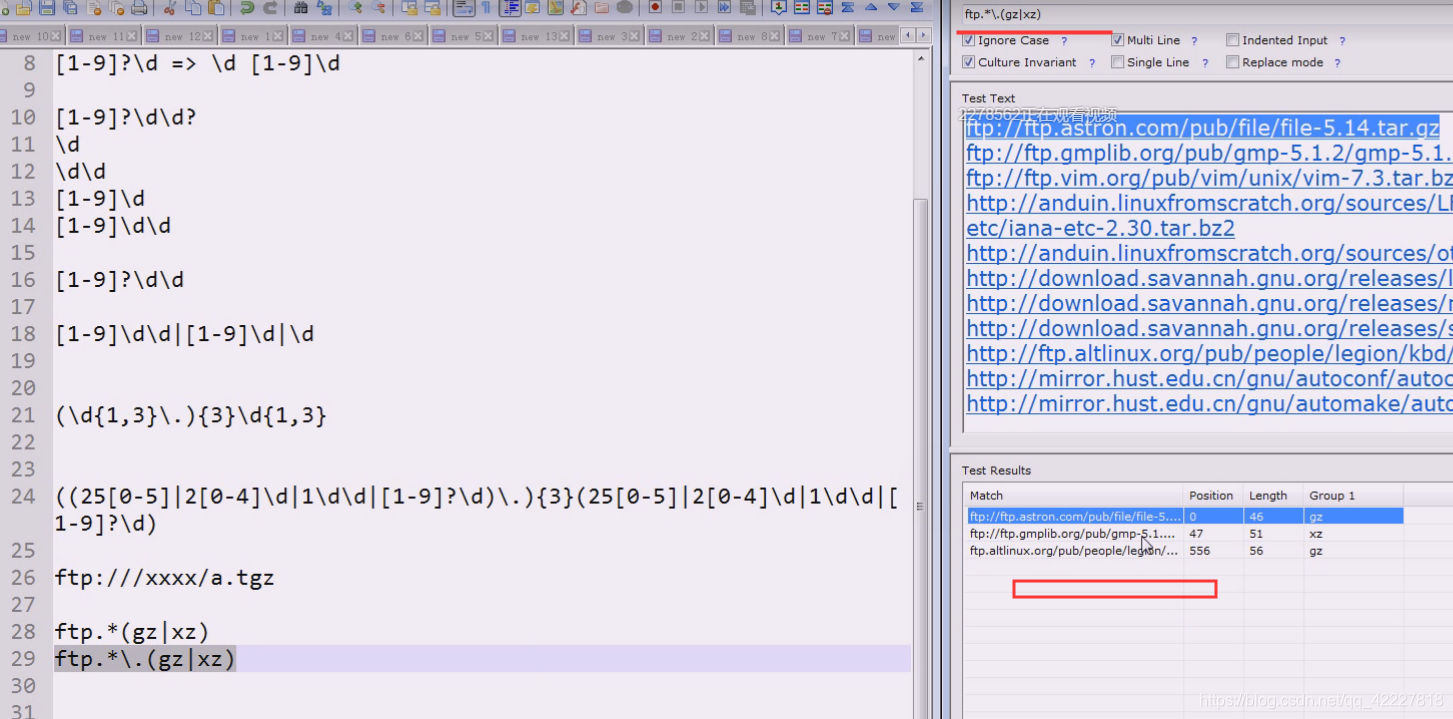
可以不要分组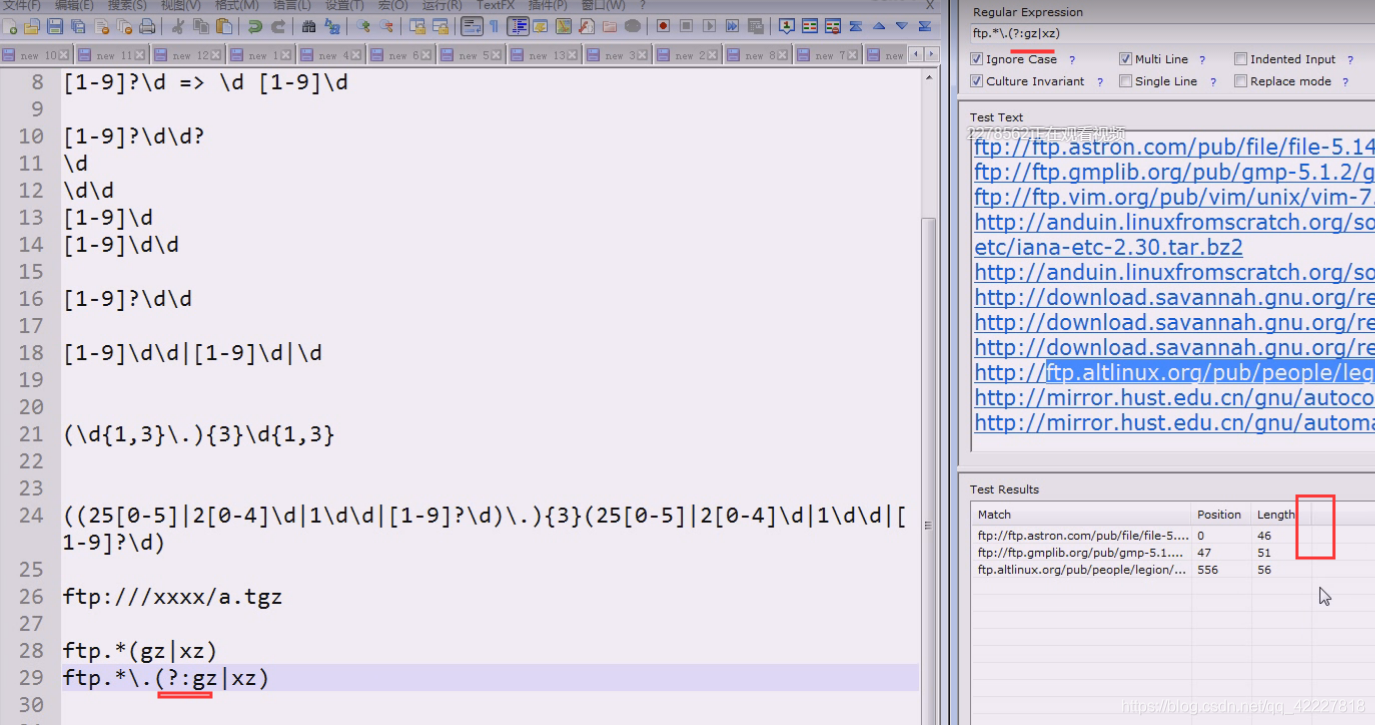
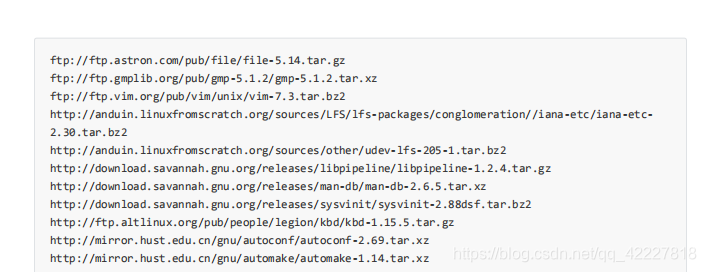
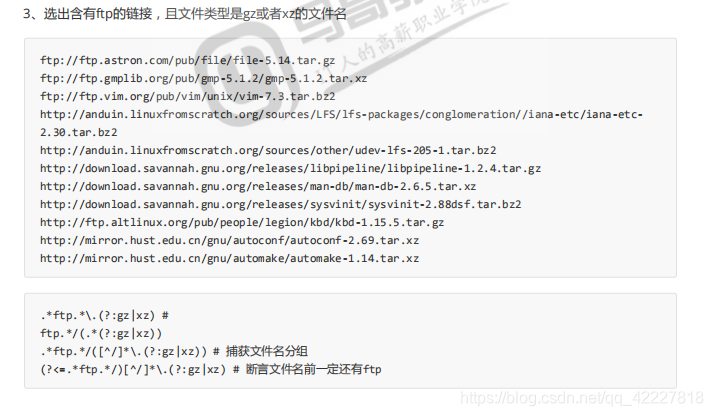
那么如何拿到文件名
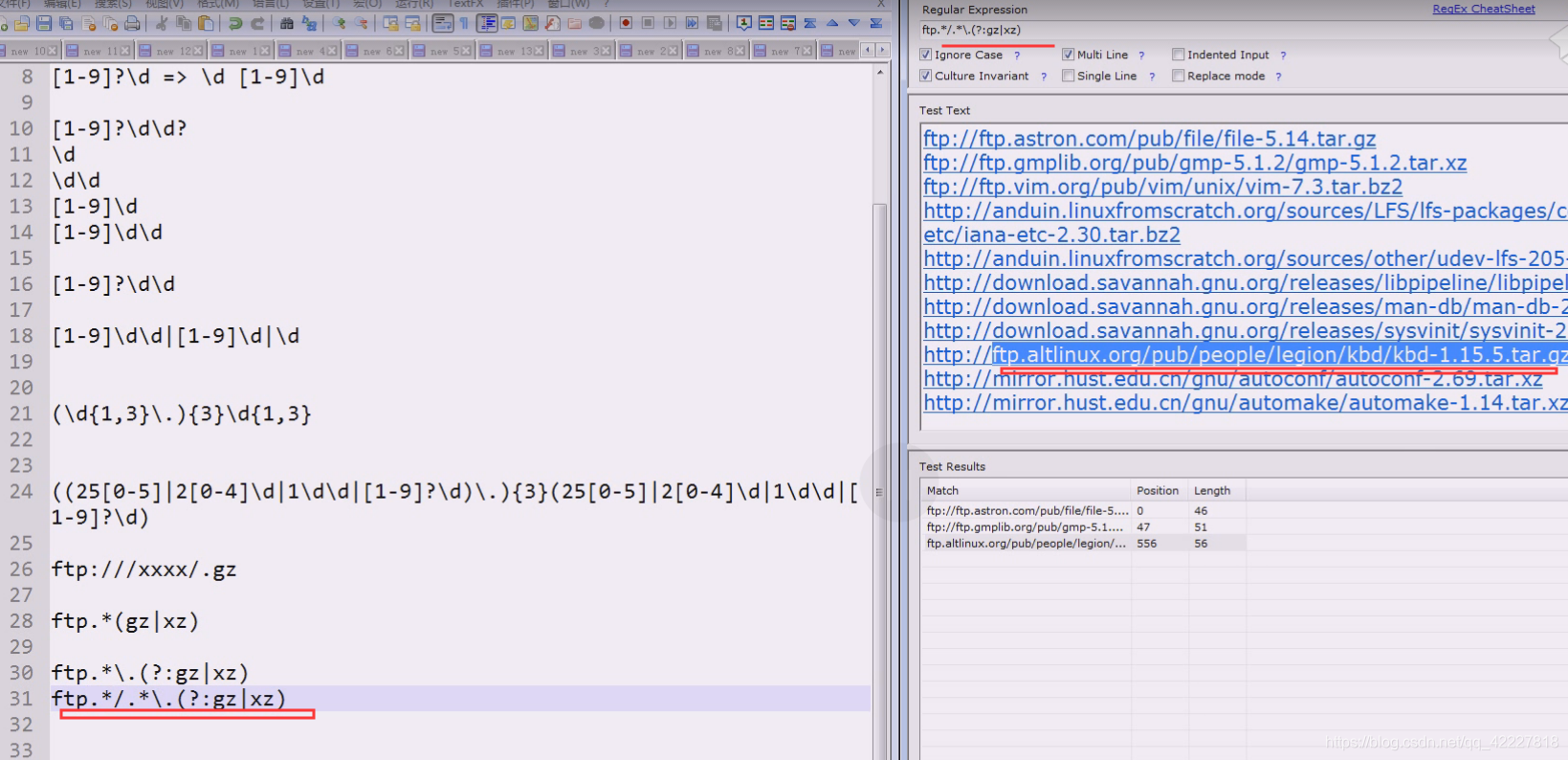 这一部分就是.了,要求后面留一个斜杠,然后再。 到.gz|xz
这一部分就是.了,要求后面留一个斜杠,然后再。 到.gz|xz
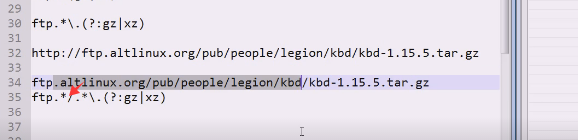
分组就把文件名提取出来了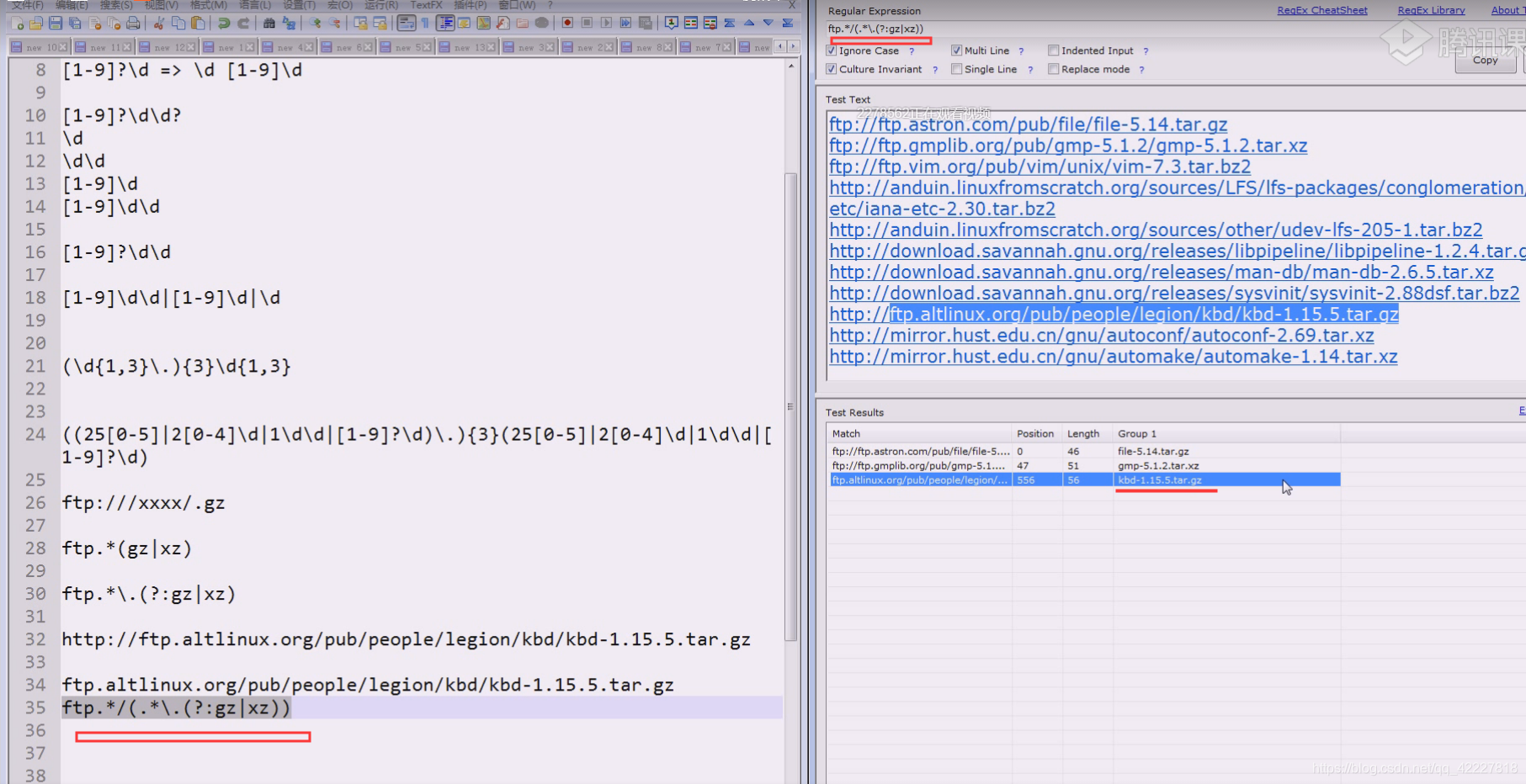
往往都会在分组中提取想要的数据
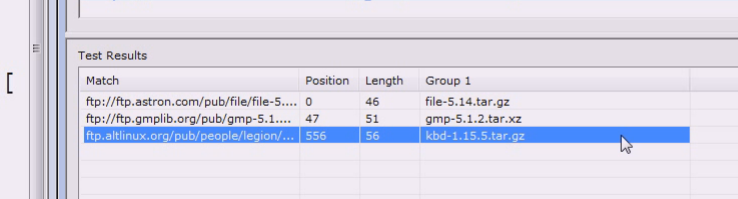
可以试试断言
ftp作为条件,就不参与分组了
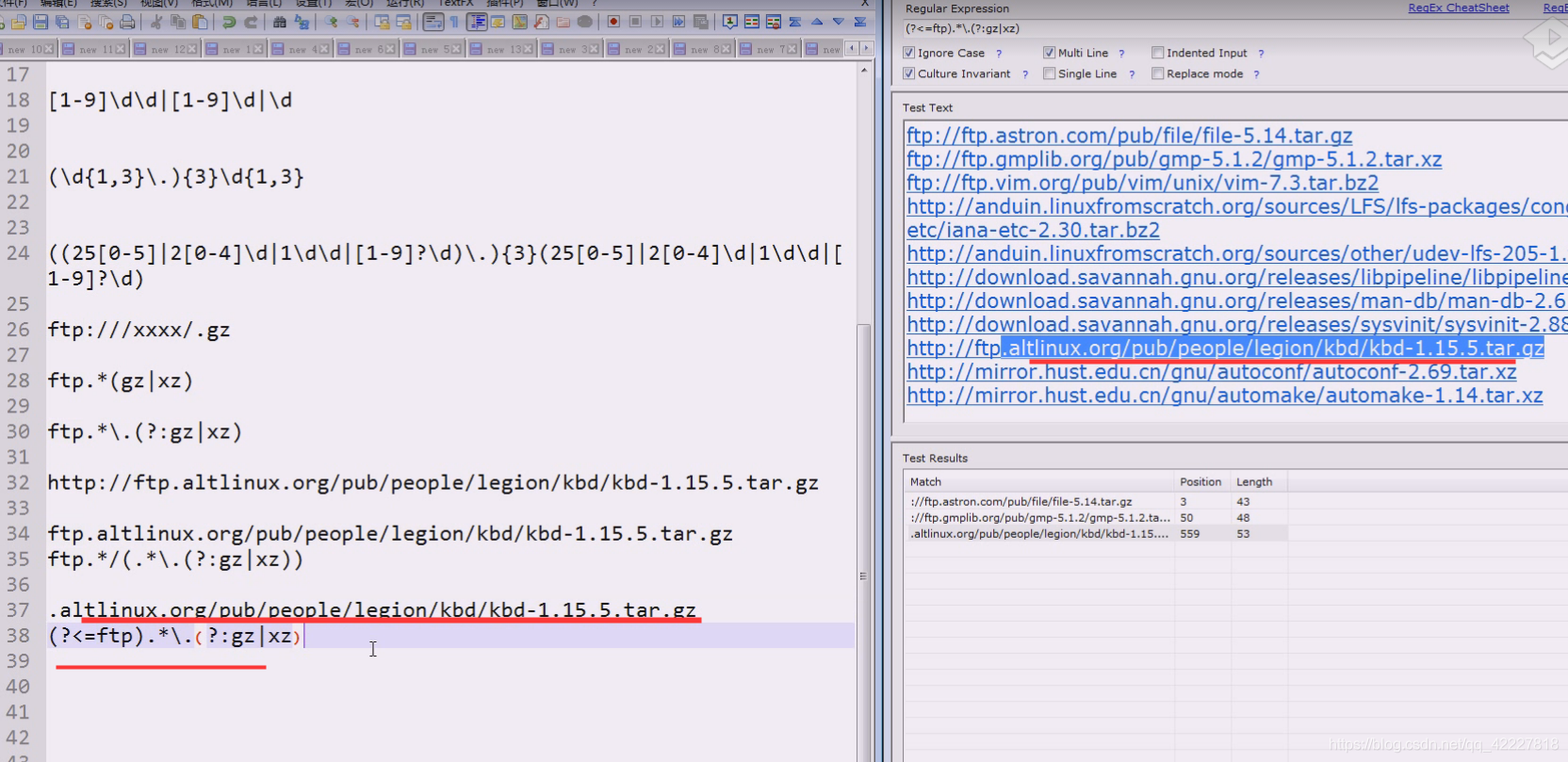
这一块也是可以写正则表达式的

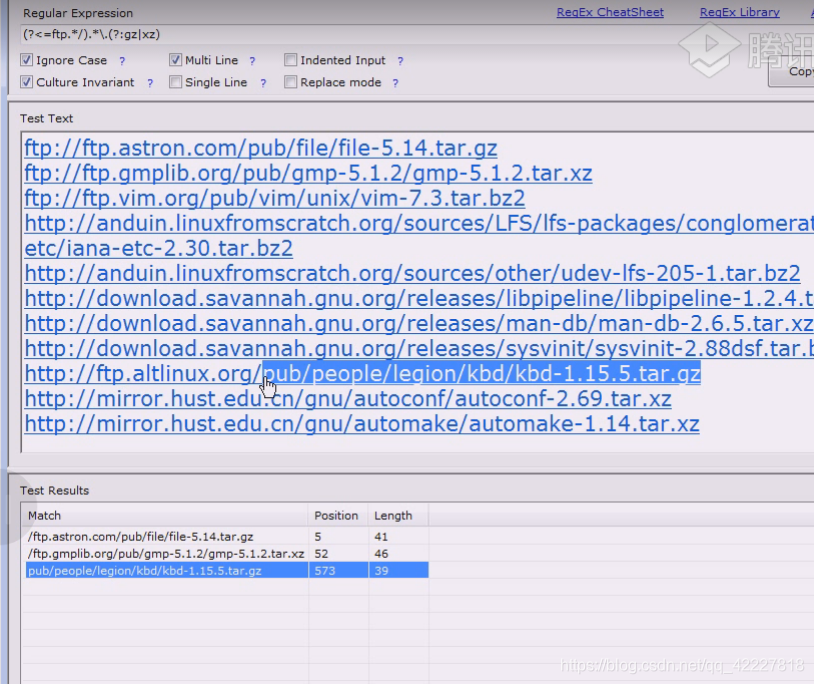
前面ftp尽量长无所谓,然后后面除去\斜杠之外的可以作为你的文件名,后面跟.gz和xz

前面是条件,后面是匹配的分组

断言的好处就是把哪些做条件的不见,只把想要的留下来,不用断言可以,用分组也可以解决
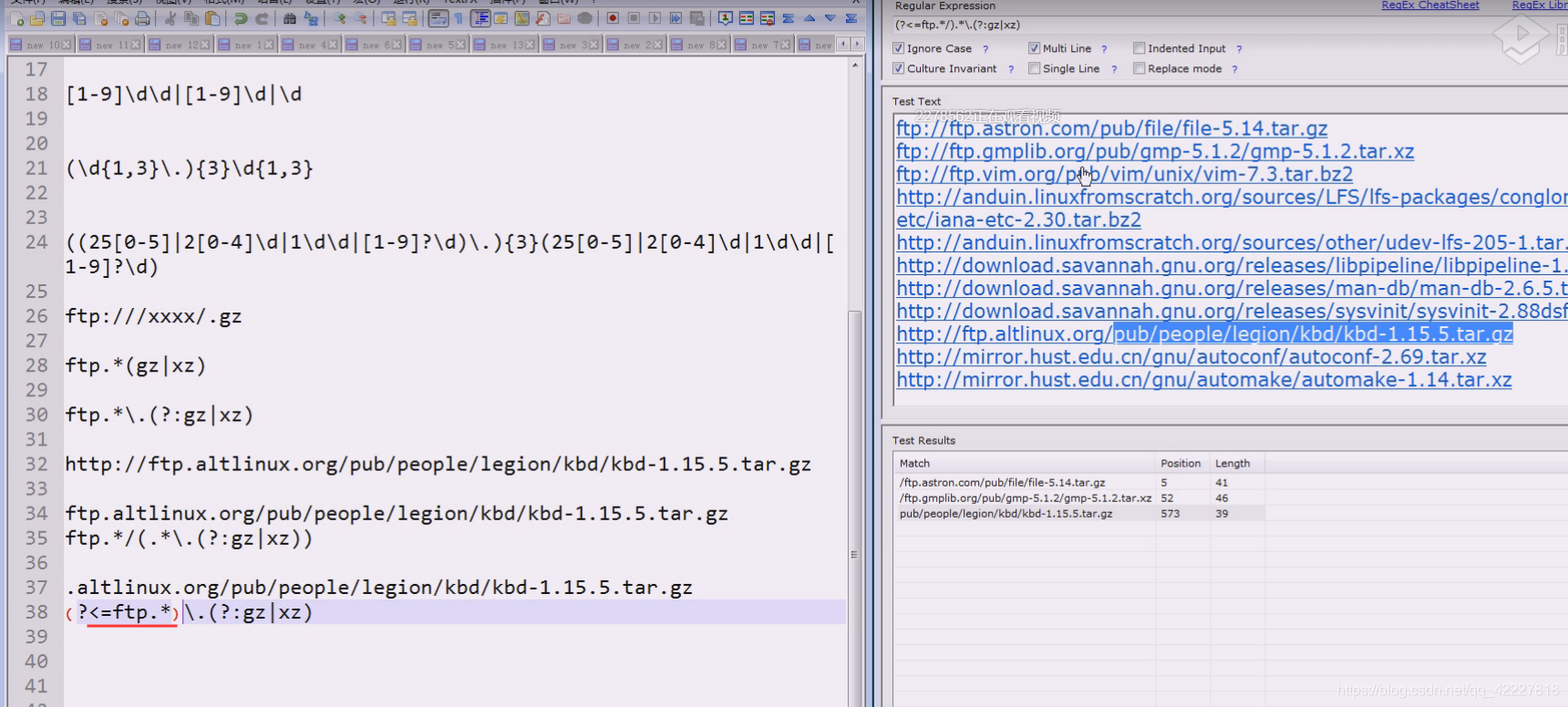
技巧,分隔符是谁就用谁来取反,可能取的名字往往就是这样

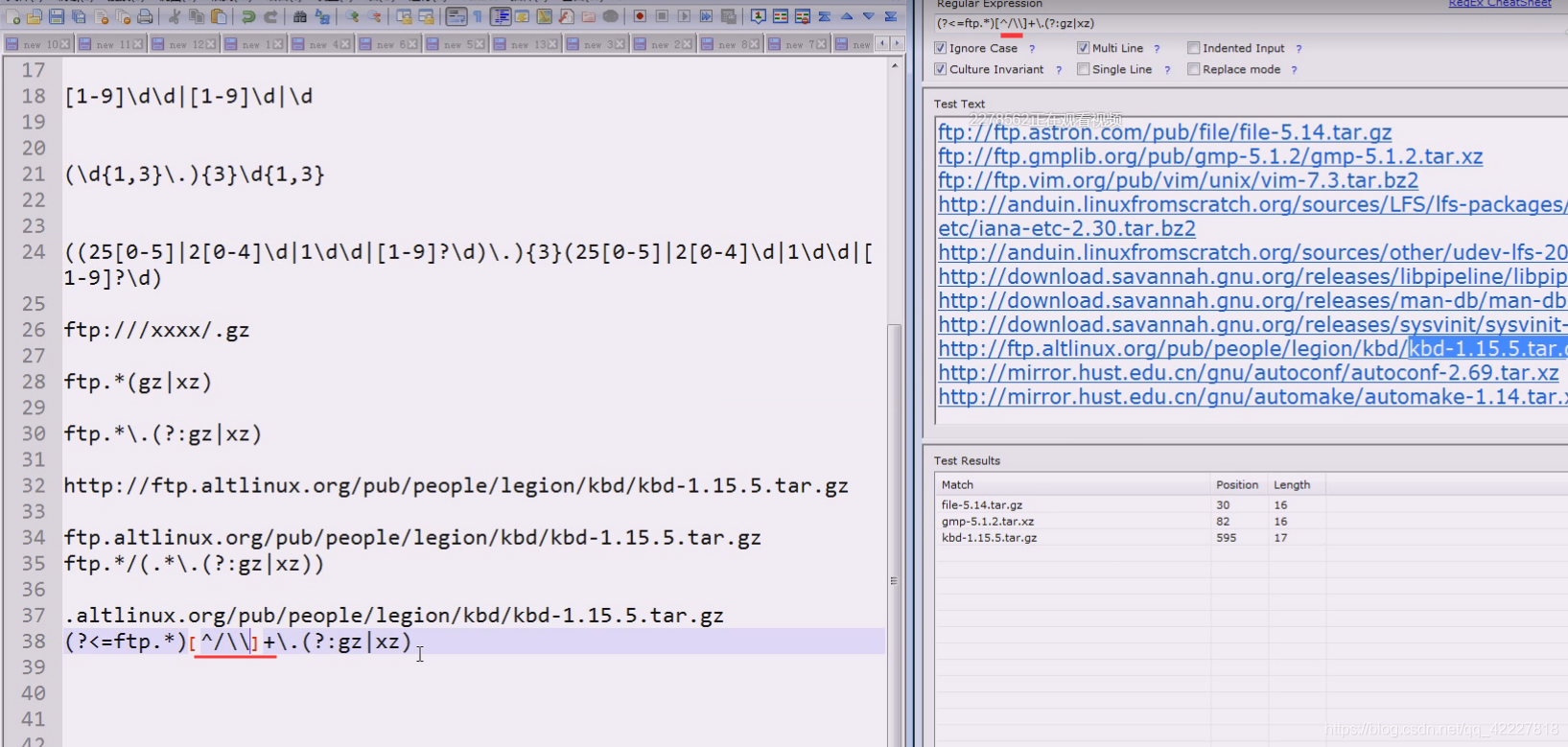
反斜杠需要转义,双反斜杠
中括号的.不当作任意字符看,是当作小数点看,可以不加转义



















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









