







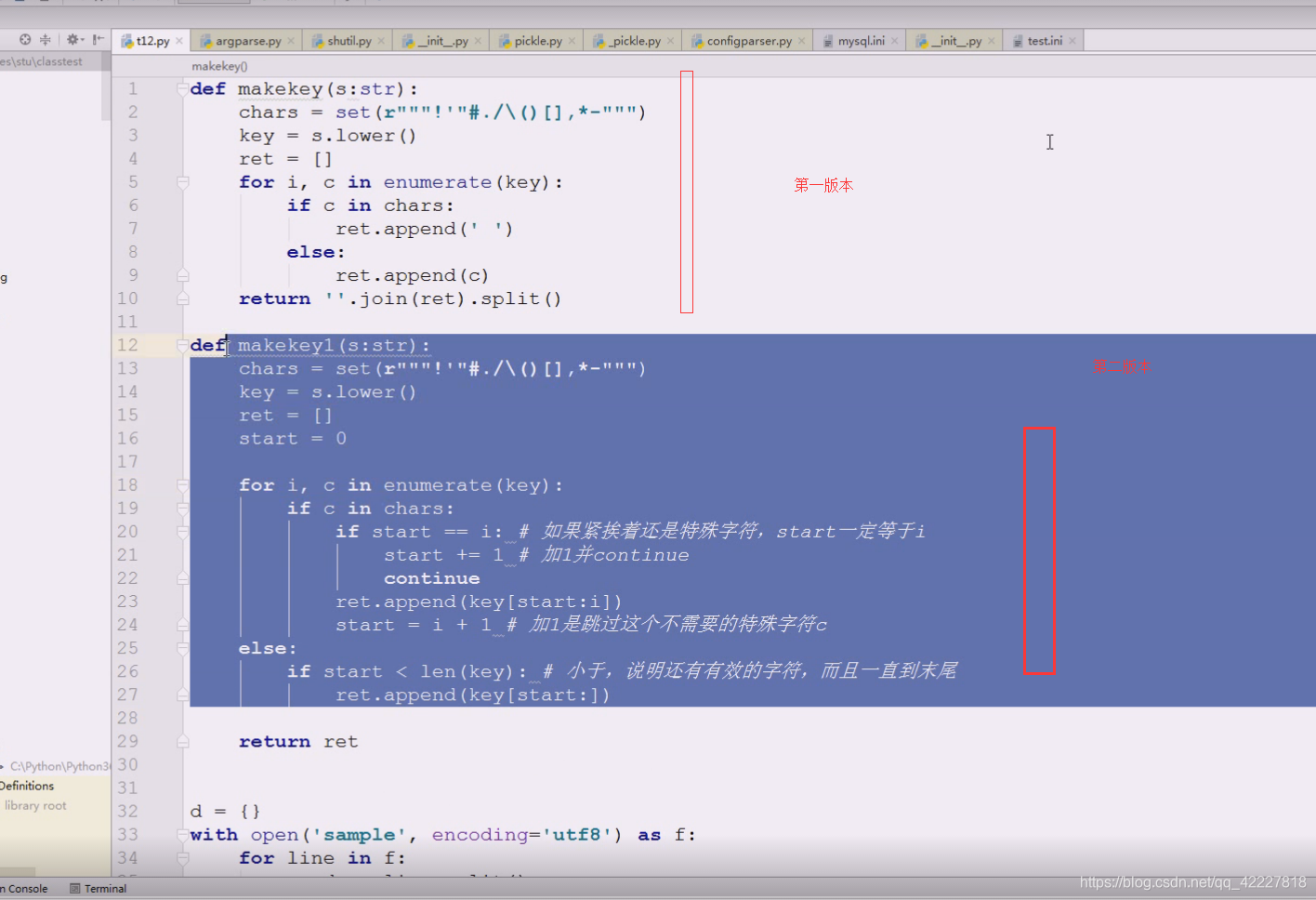
统计的时候能否排除一些词汇,有些词统计了没什么用,介词,冠词,有些形容词和副词或许没用,或许有用,比如判断一部电影的,别人的评价,这时候就不能把形容词副词丢掉了
等于mapreduce
做各种map,然后做reduce,统计,叫消减
从文件里加载
 查看这里是否可以压缩优化
查看这里是否可以压缩优化
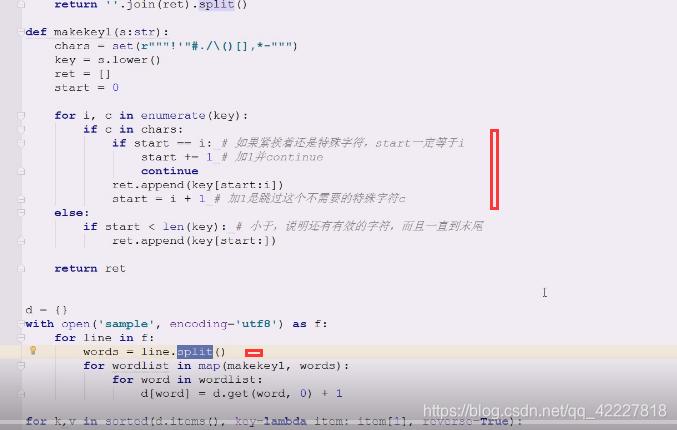
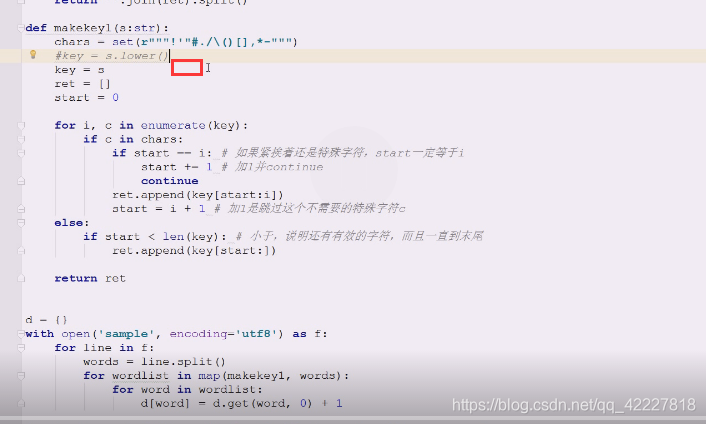
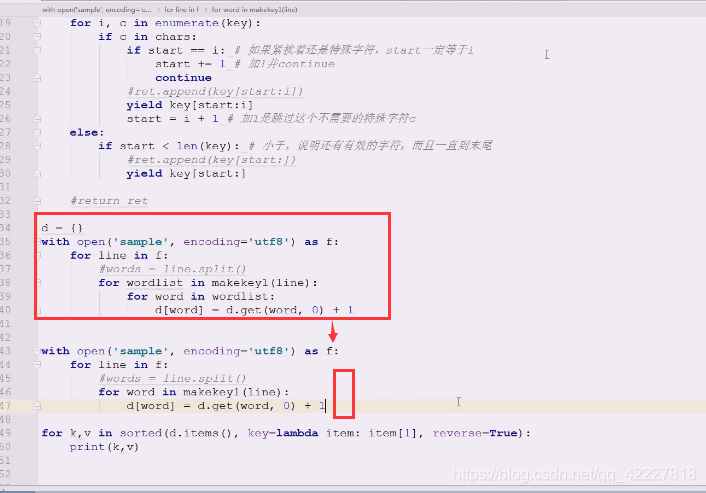
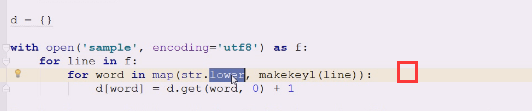
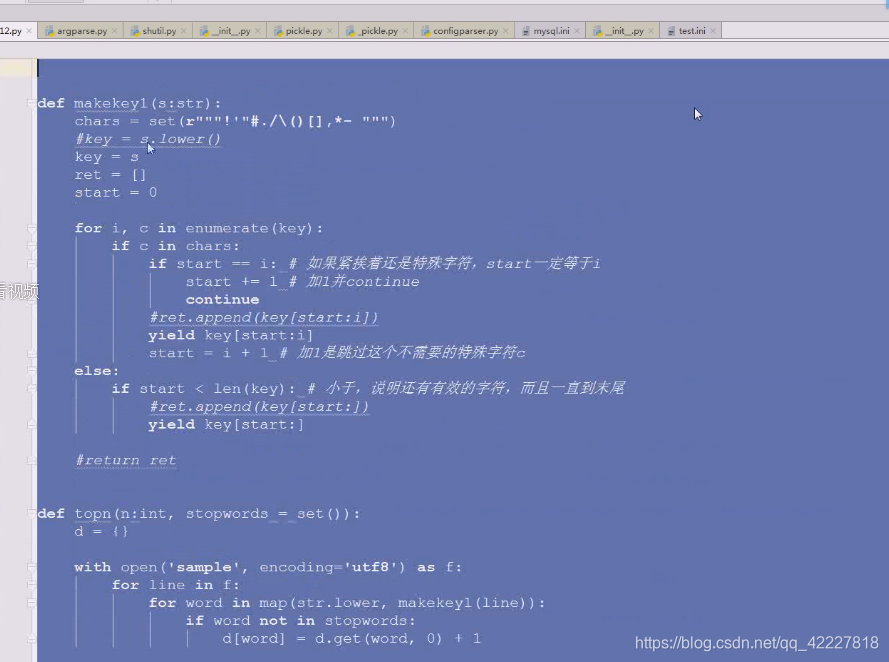
这边,如果一开始就转换成小写也不是不行,只不过,可以在下面进行判断的时候,需要小写的再转换,这样效率更高点
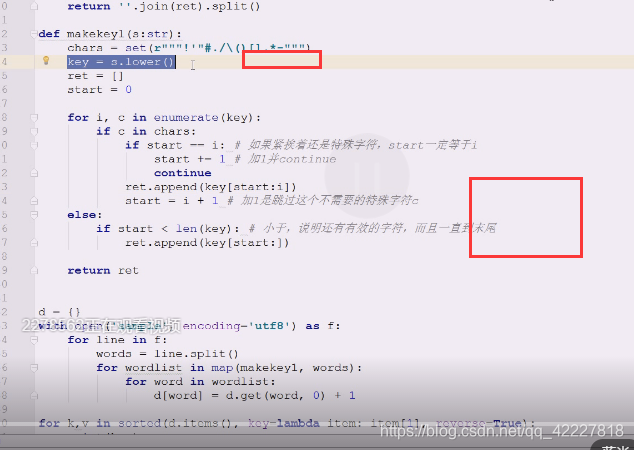
列表作为key肯定出问题,所以再做了次列表,所以下面整了三个for循环,就比较啰嗦
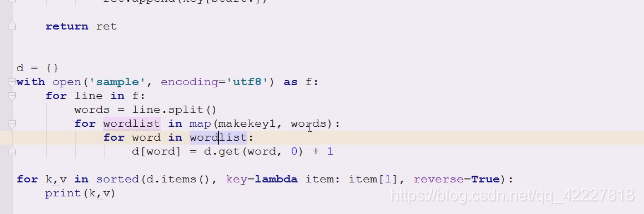
一行行处理是比较好的,一批批写,是比较好的操作,
一行行的线切割相当于先遍历了一遍 words=line.split()
切割后把单词再放到for循环里,(能否把切割的事情 也做了)

能不能整体扫描一遍,就切割出来,没有必要先按空格出来切割之后,再到里面切有没有想要的
文本回车换行,一般都建议一行行来读,现在想要把一行行拿来直接切
如果是这样,下面的代码就要进行一些修改了,给一行切出你想要的单词
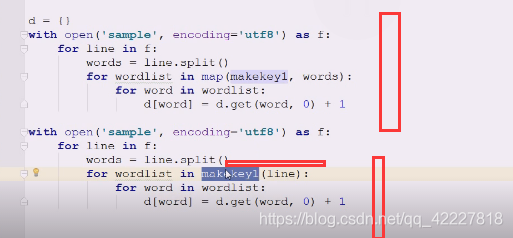
想要切出你喜欢的单词列表,这个列表就不要了,相当于以前给一整行,现在给一个单词让你切,现在得到一行的列表来处理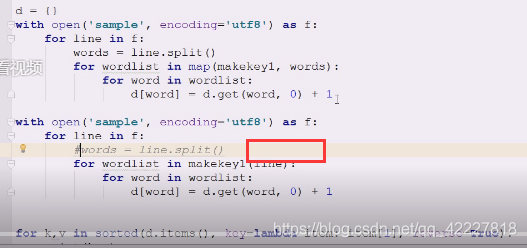
加个空格,原来是按照空格切完了,现在连空格带着一块切,空格也暂停下,到了空格该切一个单词出来,原来是按照单词先split,切完以后交给makekey1来处理
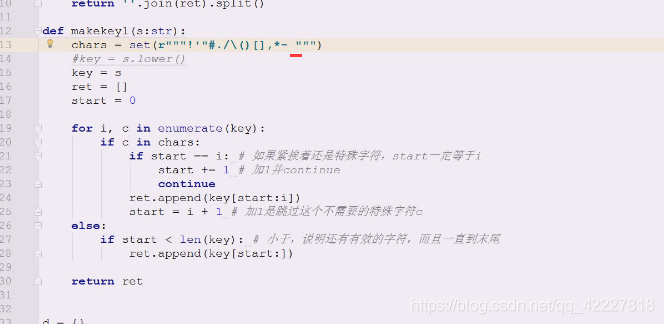
变成这样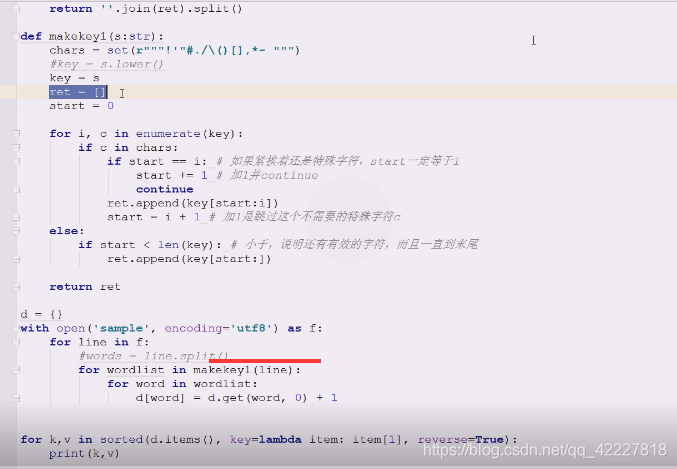
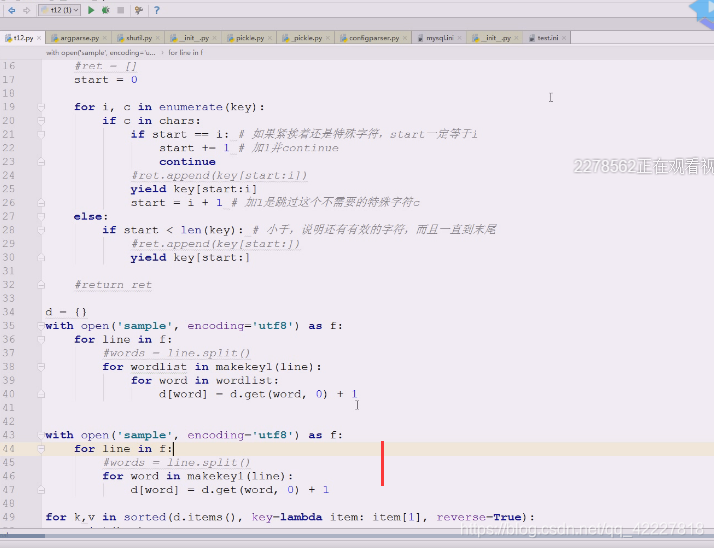
在找个基础上还需要做变化,现在是创建一个列表,追加,再返回一个列表。可以想到典型的列表解析式
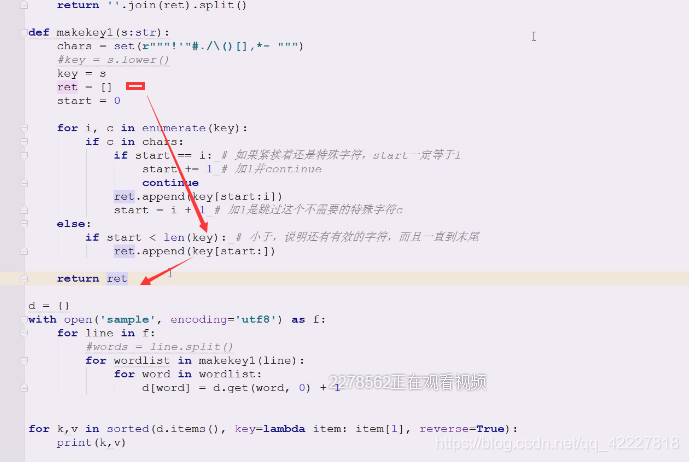
做一些改动,典型生成器应用,一个个来,把一行切一个单词出来,这就是典型的生成器
生成器可以弄成一个个单词弄出来
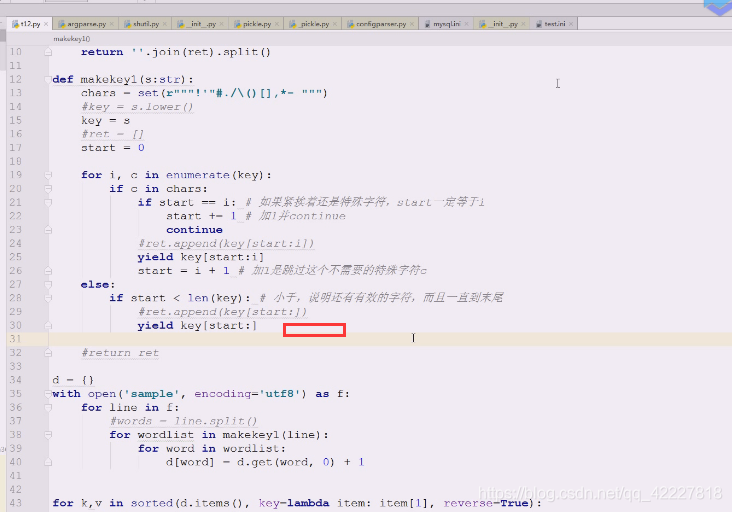
生成器调用会返回生成器对象,用for循环,返回一个单独的word,这就是生成器好处
文本处理万一是dump,就一行行处理,装饰器,生成器才是python,不然用java,现在死一个个,确实是惰性求值,循环转的快,就一次取一个,现在使用生成器就简化代码了,遇到特殊符号,截取一个单词出来传过来
就得到下面的版本,python一行顶替别人几行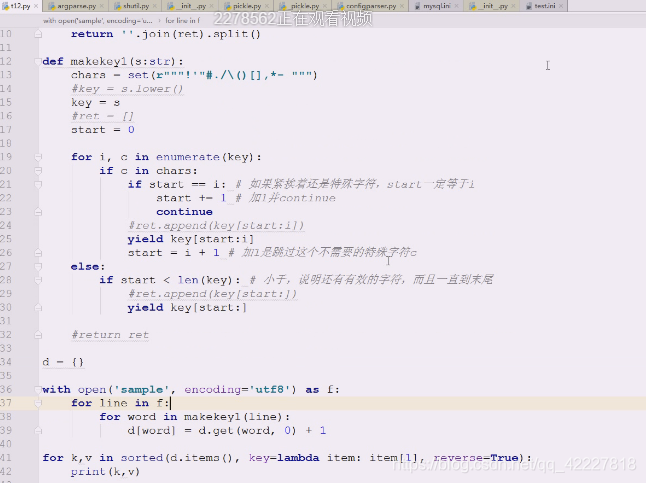
合法字符存在大小写问题就需要转了,map函数生成一个迭代器,yield出来一个,就立即对这个进行处理
word in map()word要从map对象里拿一个,就是把后面的可迭代对象,一个个进行处理,make(line)
然后map是惰性求值的,map对后面的可迭代对象,扔一个元素出来,然后str.lower这里做一些小写处理,
makekey1就yield出来一个值,交给小写处理函数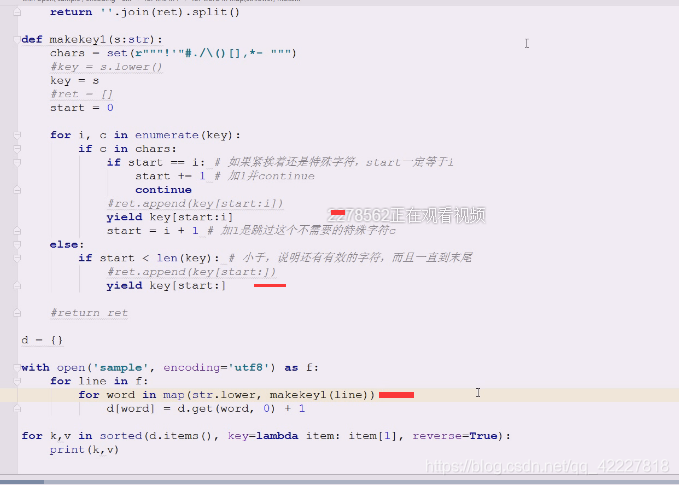 合法字符存在大小写问题就需要转了,map函数生成一个迭代器,yield出来一个,就立即对这个进行处理
合法字符存在大小写问题就需要转了,map函数生成一个迭代器,yield出来一个,就立即对这个进行处理
word in map()word要从map对象里拿一个,就是把后面的可迭代对象,一个个进行处理,make(line)
然后map是惰性求值的,map对后面的可迭代对象,扔一个元素出来,然后str.lower这里做一些小写处理,
makekey1就yield出来一个值,交给小写处理函数,处理完把值交给word,这一次结束了,这两都是惰性求值,没有必要再遍历一遍
如果map是个soretd,就要立即先算一遍,生成出来列表,才能对找个列表进行求值,但是map和makekey1现在都是惰性求值的
执行过程:for循环告诉map给一个值扔出来,map就问后面的makekey1要一个就可以,makekey1就yield出来一个单词,然后lower转换,for循环再迭代就再次要一个
惰性求值,reversed,map,filter都是惰性求值,在这里配合就是不需要立即迭代一遍,只需要来一个元素计算一次,在这里就没有什么性能问题

现在看如何封装函数,把上面的def版删除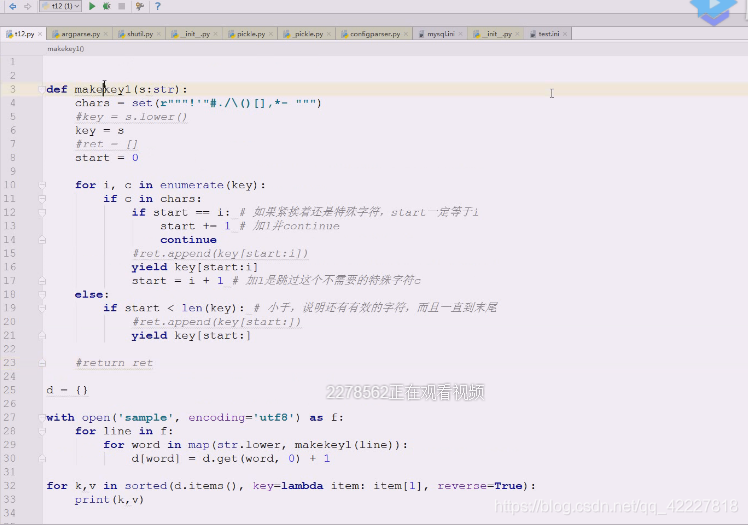
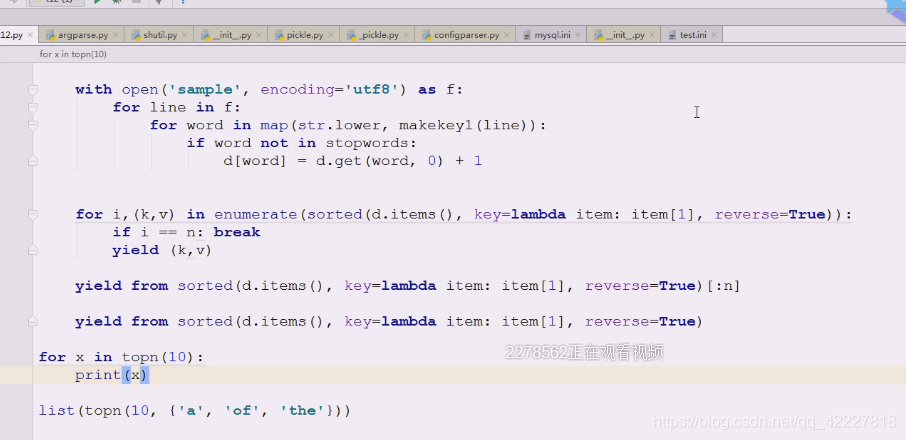
定义top,找出出现单词出现次数最多的,频率跟次数是两码事,出现的次数和频率是两回事,在单词统计里,次数是次数,频率是频率,词频有更加意义的作用
topn,就是要你,计算次数最多的,排个顺序就可以
可以使用切片,排完序就直接切片
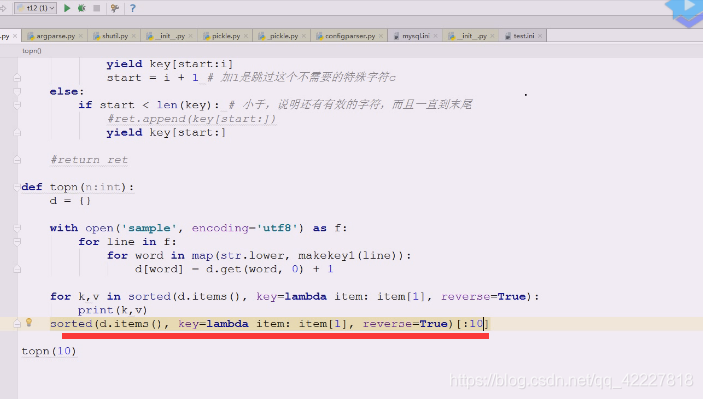
计数器,就需要进入循环,用count,用生成器的方式迭代出来即可
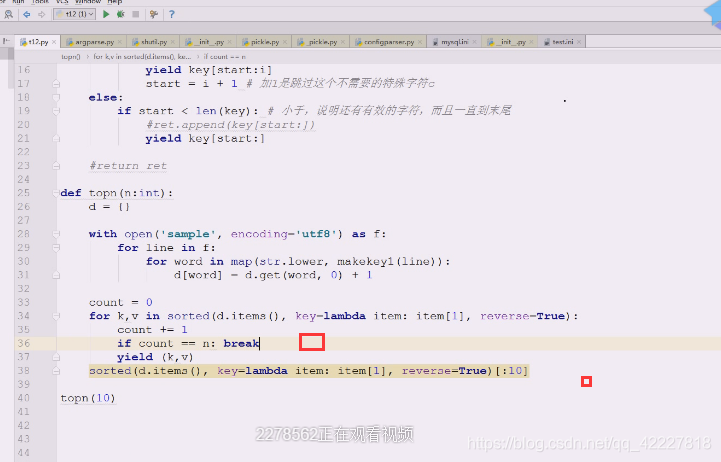
另外一种写法,上面的语法其实就是yield from,只不过控制了下个数,从一个可迭代对象,挨个把对象拿出来,典型的yield from
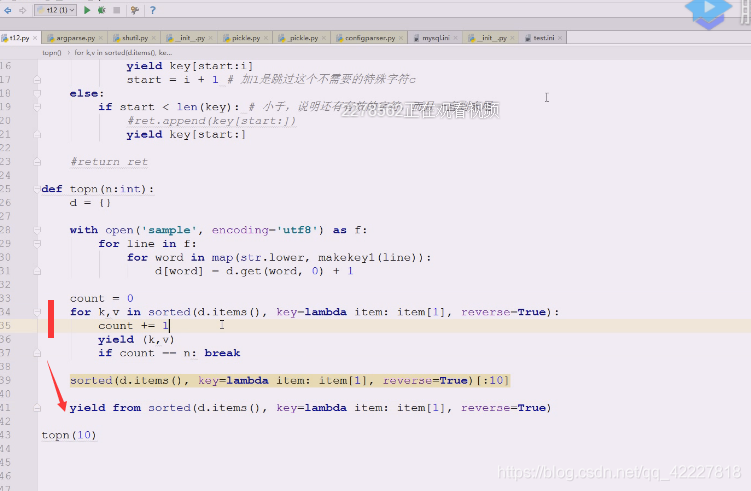
这样也行,这三种都是yield
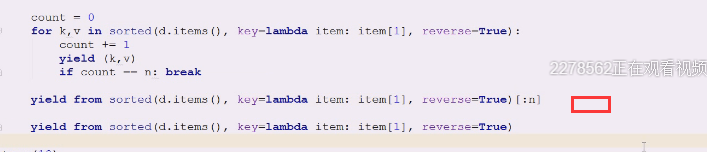
topn返回的也是生成器对象,下面需要写成for 循环,简单测试用list(topn(10))
能写成生成器的方式最好写成生成器的方式,处理数据就是一小批小批,一个个都是生成器的概念一小批就生成一小批,一个个就生成一个个,
那么把return 改成yield是否可以,用这种方式就一批批的概念出来了,给你一批批的数据
但是在这里适合一个个
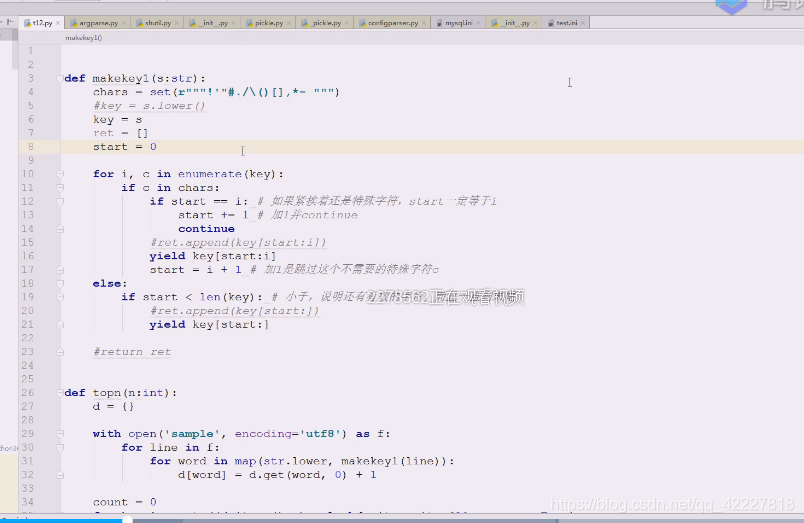

第一道题做了一半,还有一些排除的问题
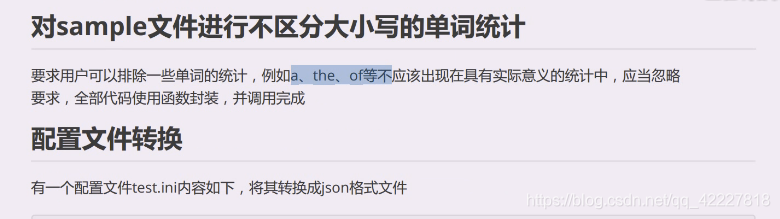
在什么什么里面就要用到in了。写个ignore即可,也就是单词出来要算一下单词在不在这里面,就不要,不在里面,就进行操作
有个专业术语stopwords(习惯翻译是停止词),遇到这个词就不要了忽略了,
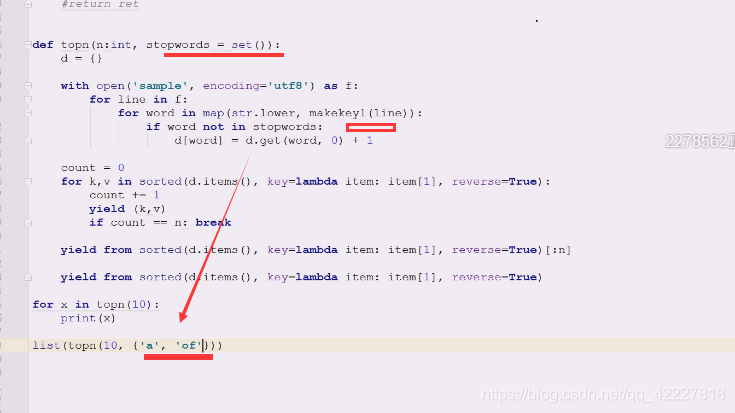
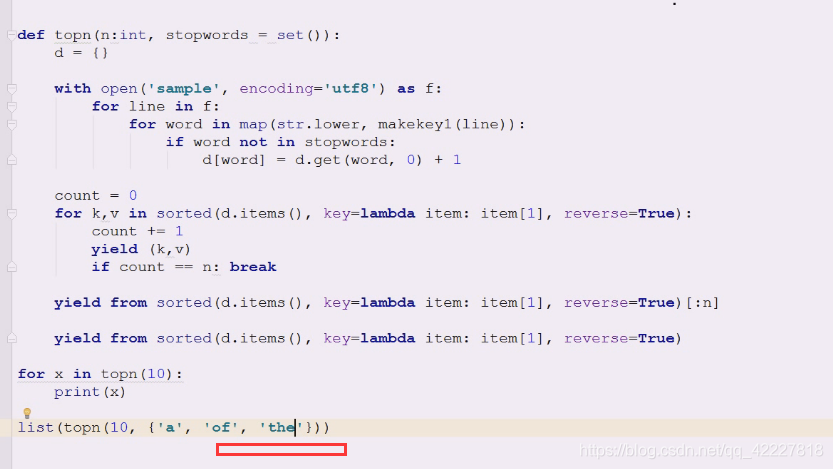
这种写法其实还可以进行修改
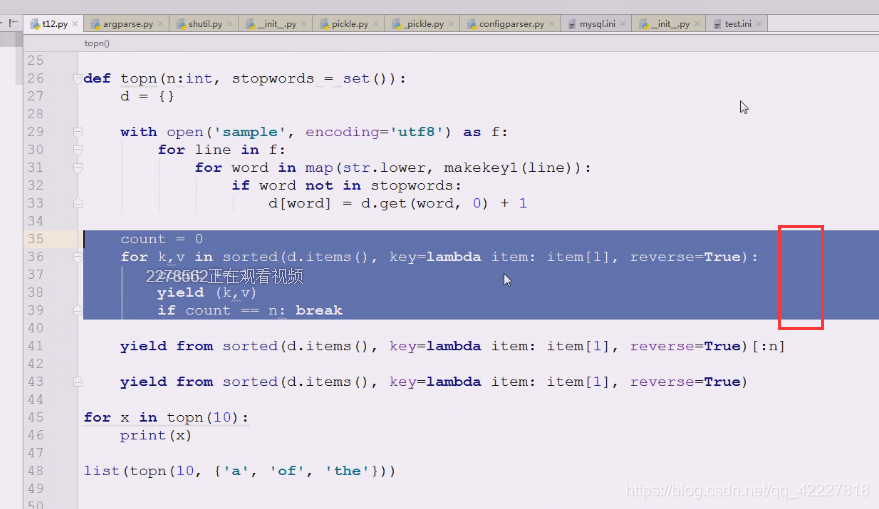
enumerate就可以自己计数了,不用上面的计数了
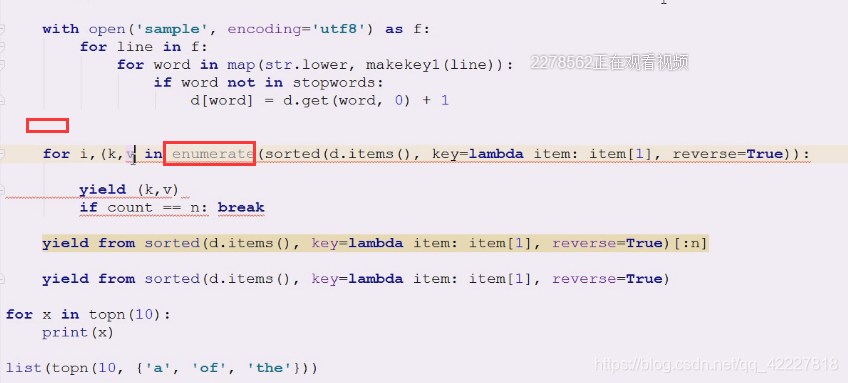
但是解构会有问题。吧你想要的数据yield出去,i=n,先打印,刚开始是0,,往上放一下即可,就不需要用count了,enumerate是惰性求值的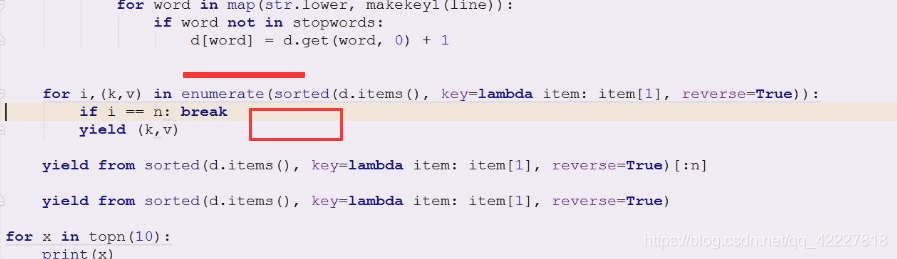
里面也可以不写,表示不控制n了,可以在外面控制n
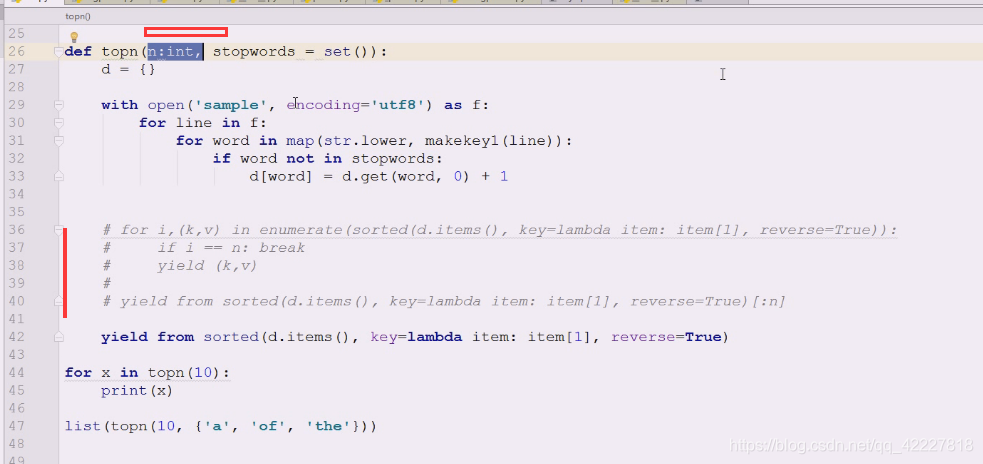
这三个都是惰性的

写代码写成这样就没什么问题了。因为面试进去了,老大会盯着你看的代码,pdf是参考答案,经过调试的
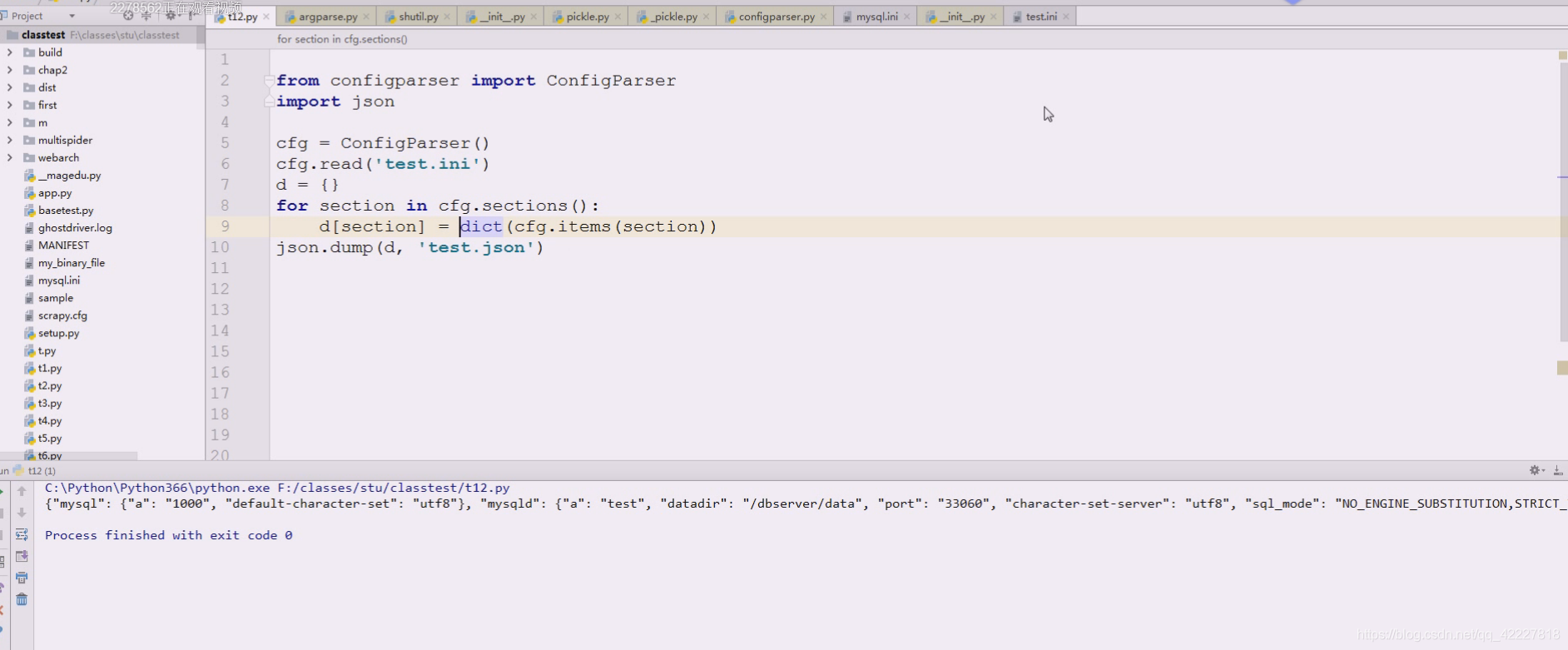
配置文件转换
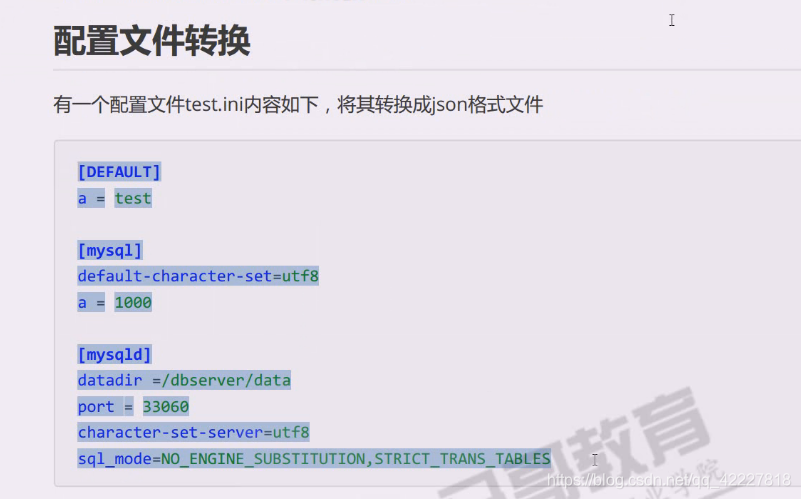
ini可以看成两个大字典
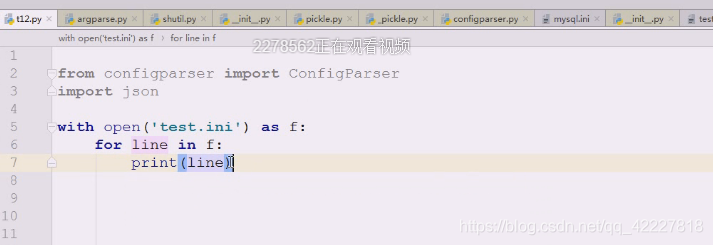
先把文件用with读进来,先查看能否正常读
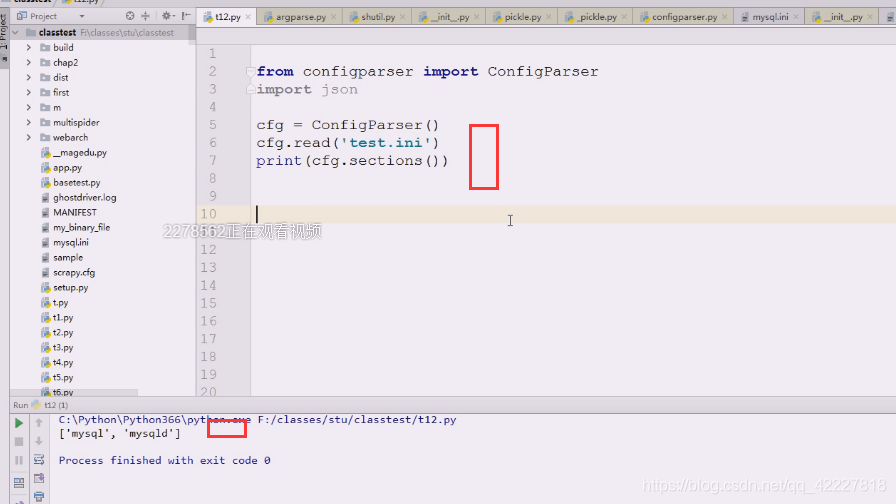
就可以直接sections in
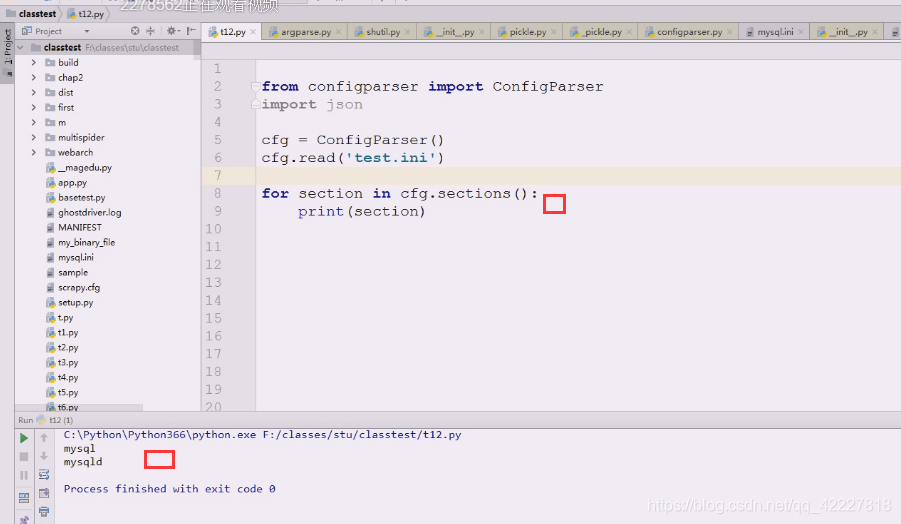
可以先把外层字典定义成d={}
先打印看看
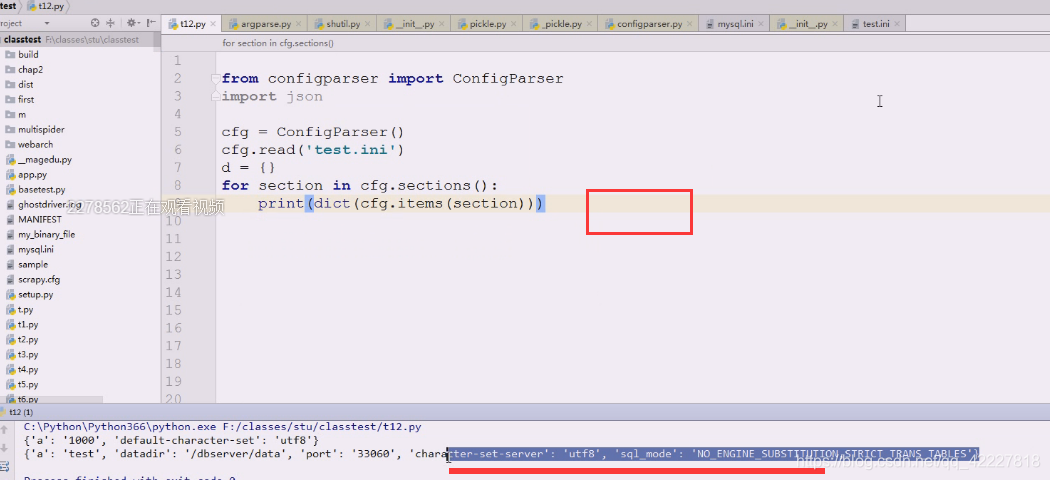
items。从外层字典拿到内层字典,就可以替换成如下
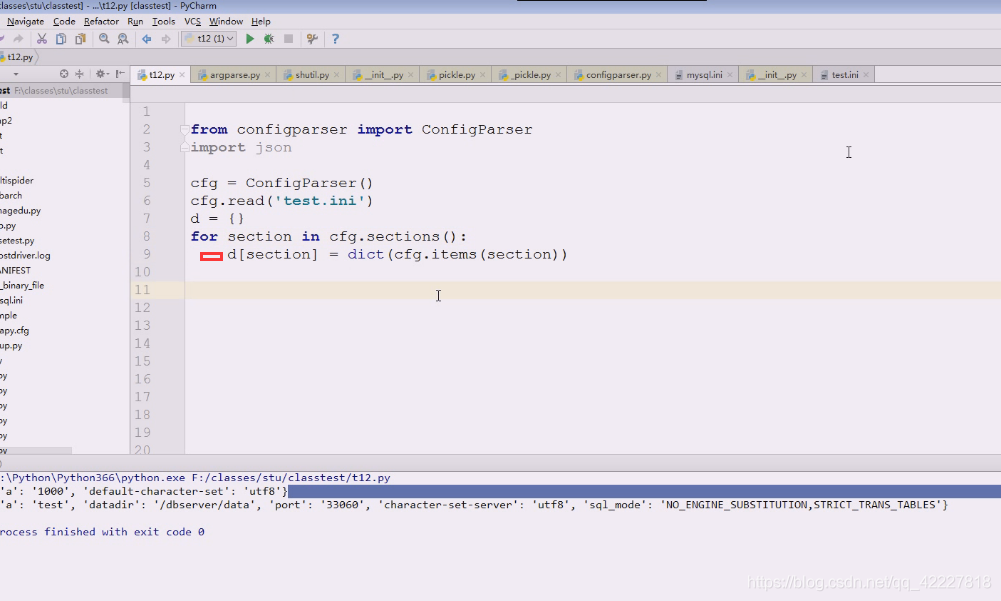

先到文件里打印看看
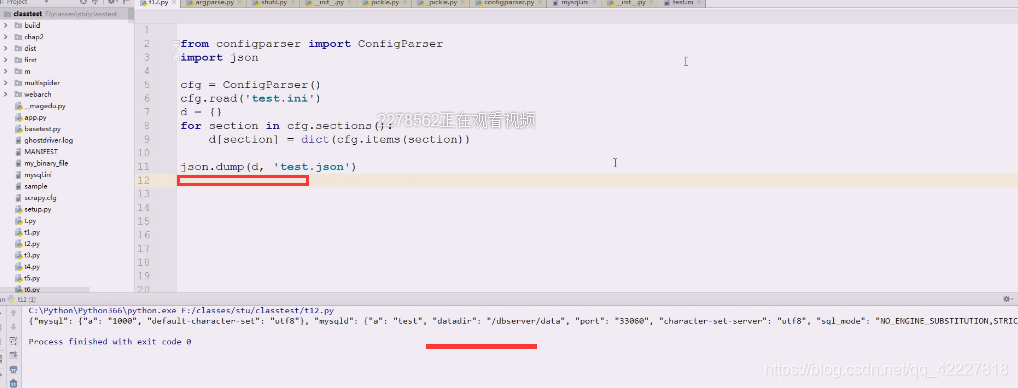
数组本质上就是列表。,只不过列表是对数组的一种封装而已,ini其实就是字典的两层嵌套,字典就可以变成json对象,把两层字典剥离出来就搞定了
这道题是比较简单的
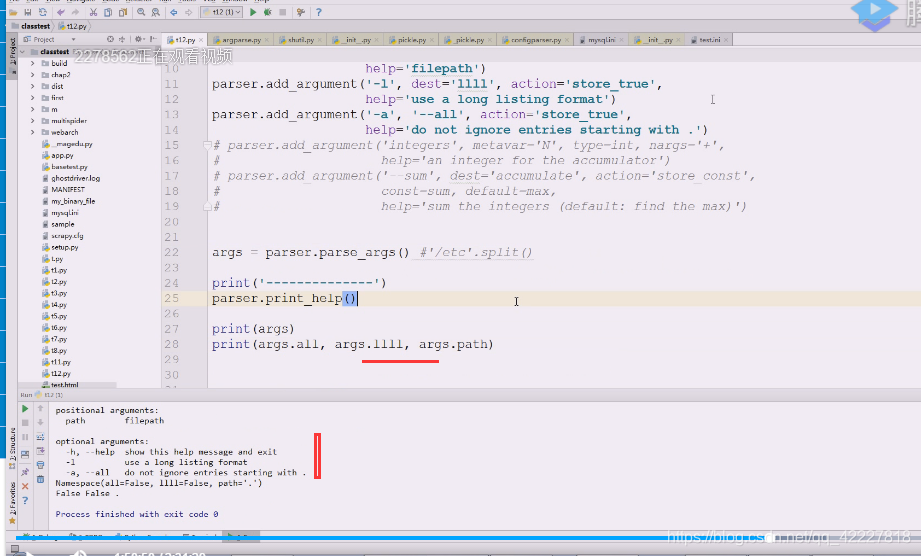
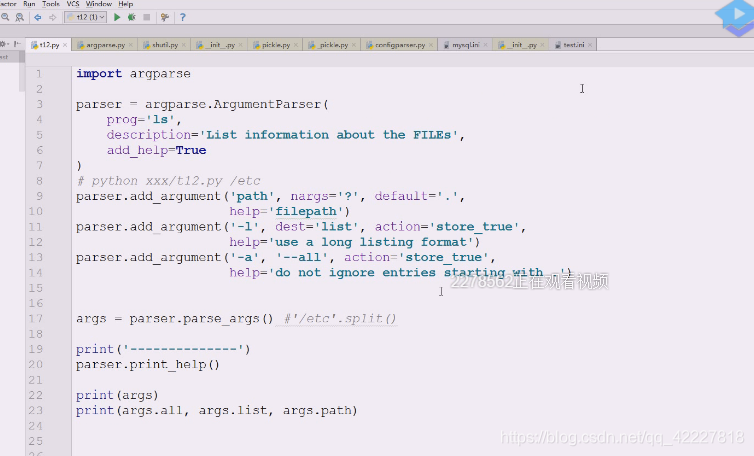
实现ls命令功能

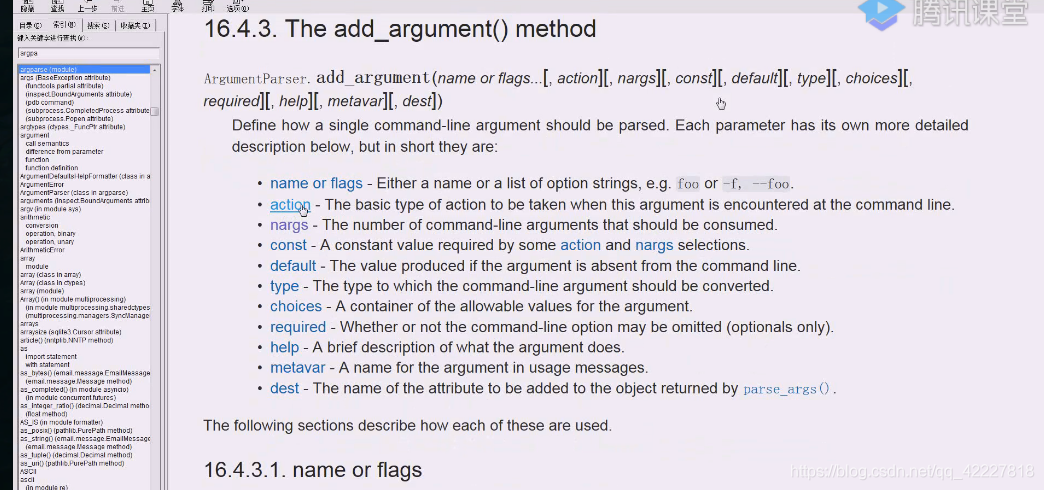
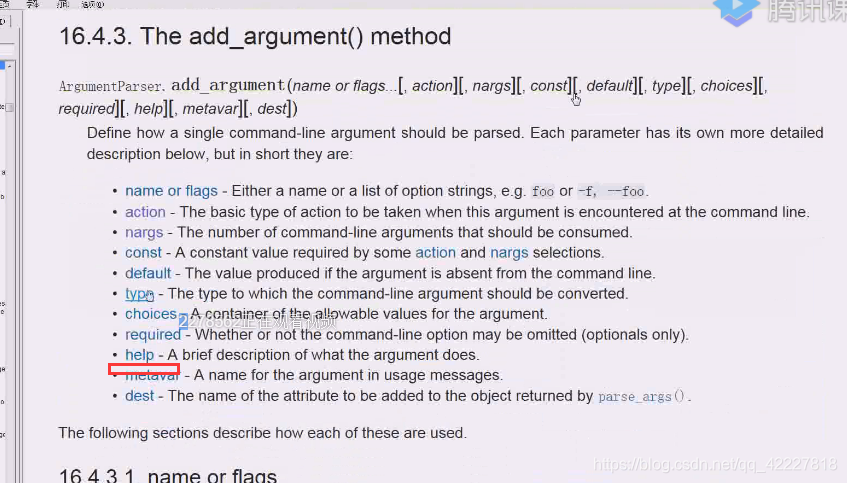
需要自学模块,argparse
这是解析命令行选项参数的,以及子命令的,只要是你在命令行里要处理的东西都能替你搞定,3.2就可以了,这个库把我们所有的命令选项方式都写进去了
常用的就那几个,从最简单先下手
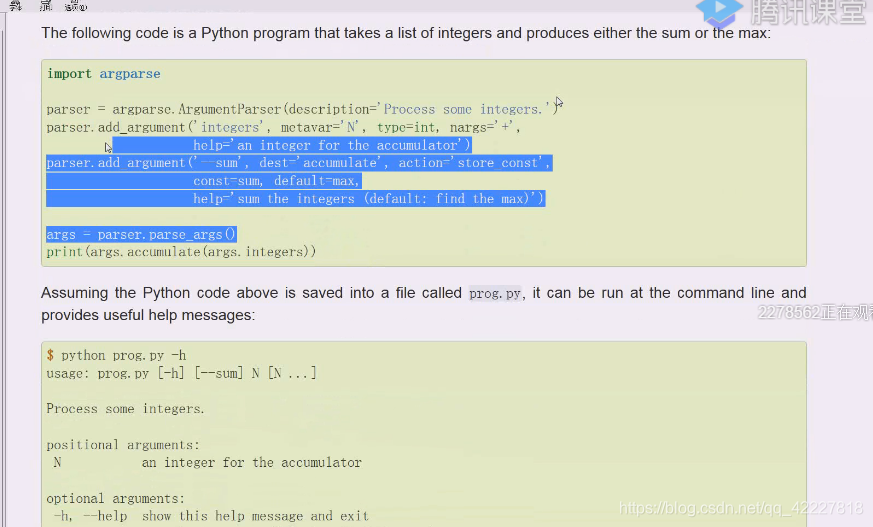
先来认识这个库,中间先注释掉
打印帮助,print_help,执行一下
process some integers处理一些整数,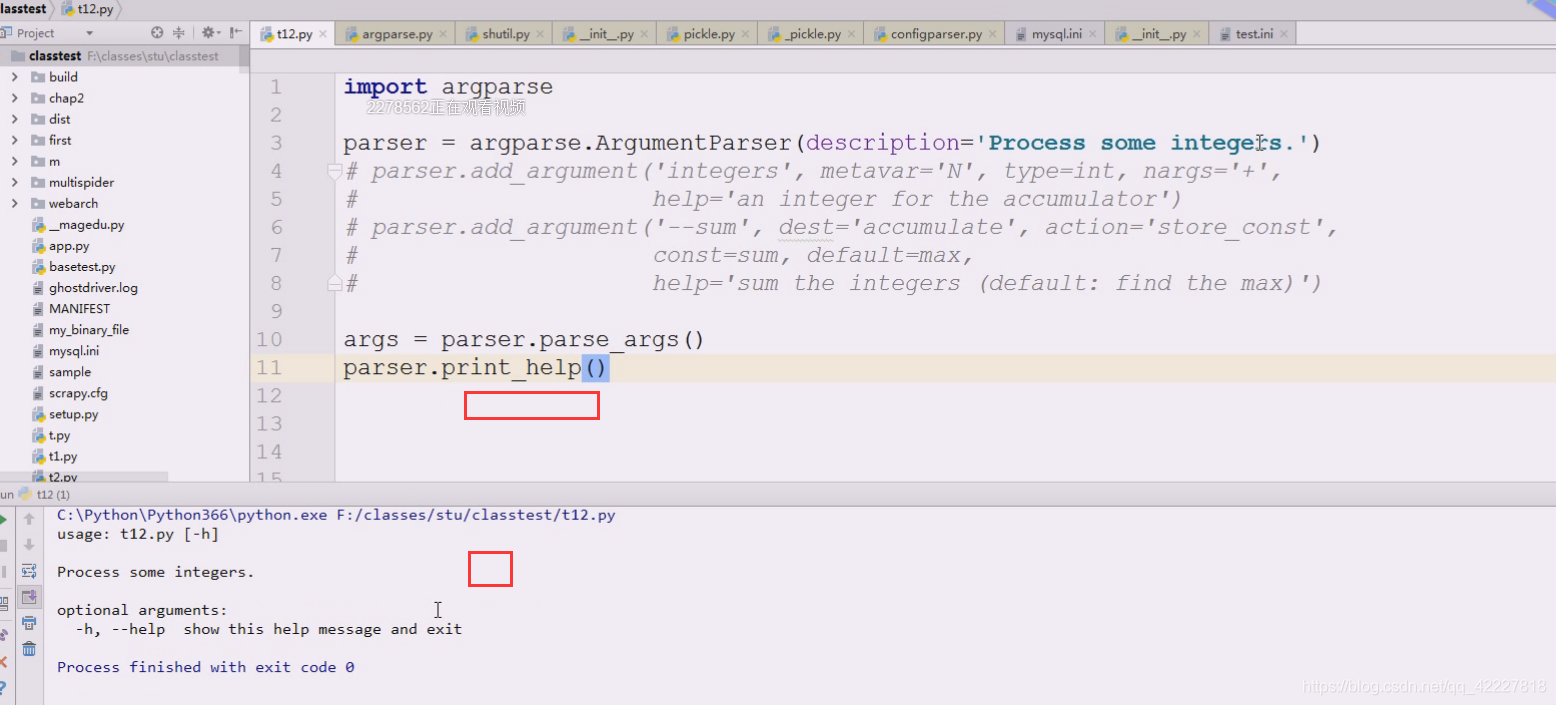
这个帮助是自动生成的
这里应该告诉我们这个program程序是什么东西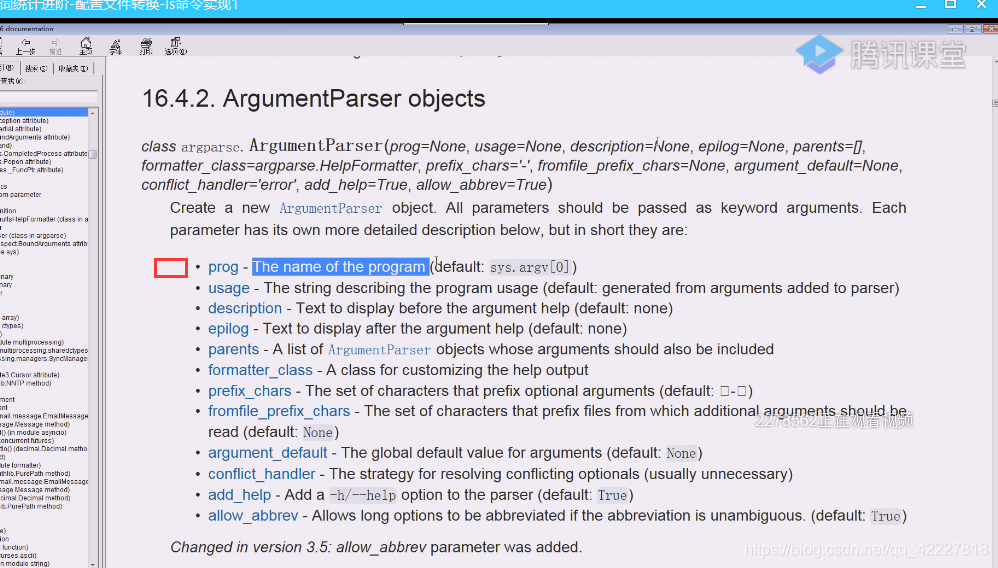
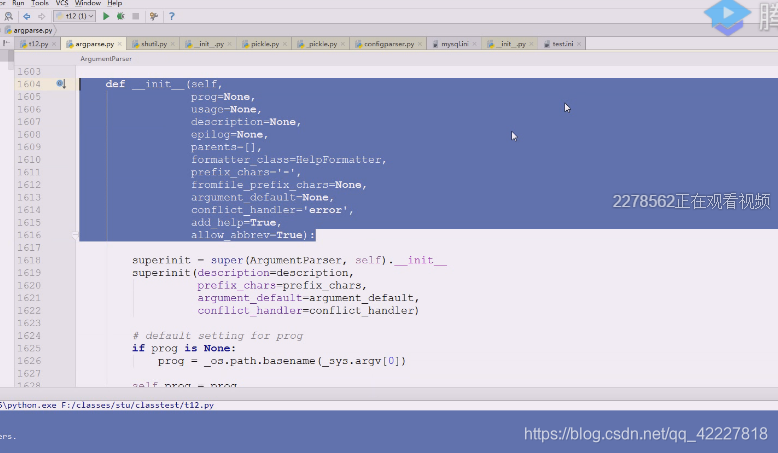
prog=程序名称,否则使用。sys,argv[0]
告诉你程序的使用方式 
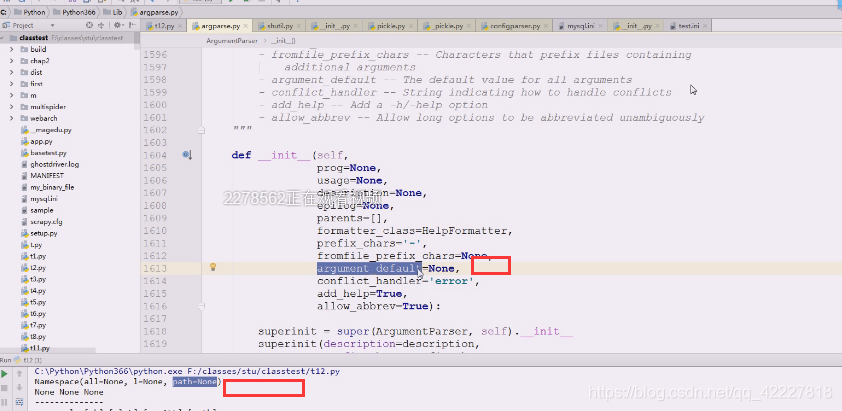
参数的缺省值,默认是none,代表这是一个全局缺省值设定
如果有这个在就会增加一个-h/–help选项,缺省值是True,也就是默认就添加了这两个选项,短选项和长选项就都增加给你了

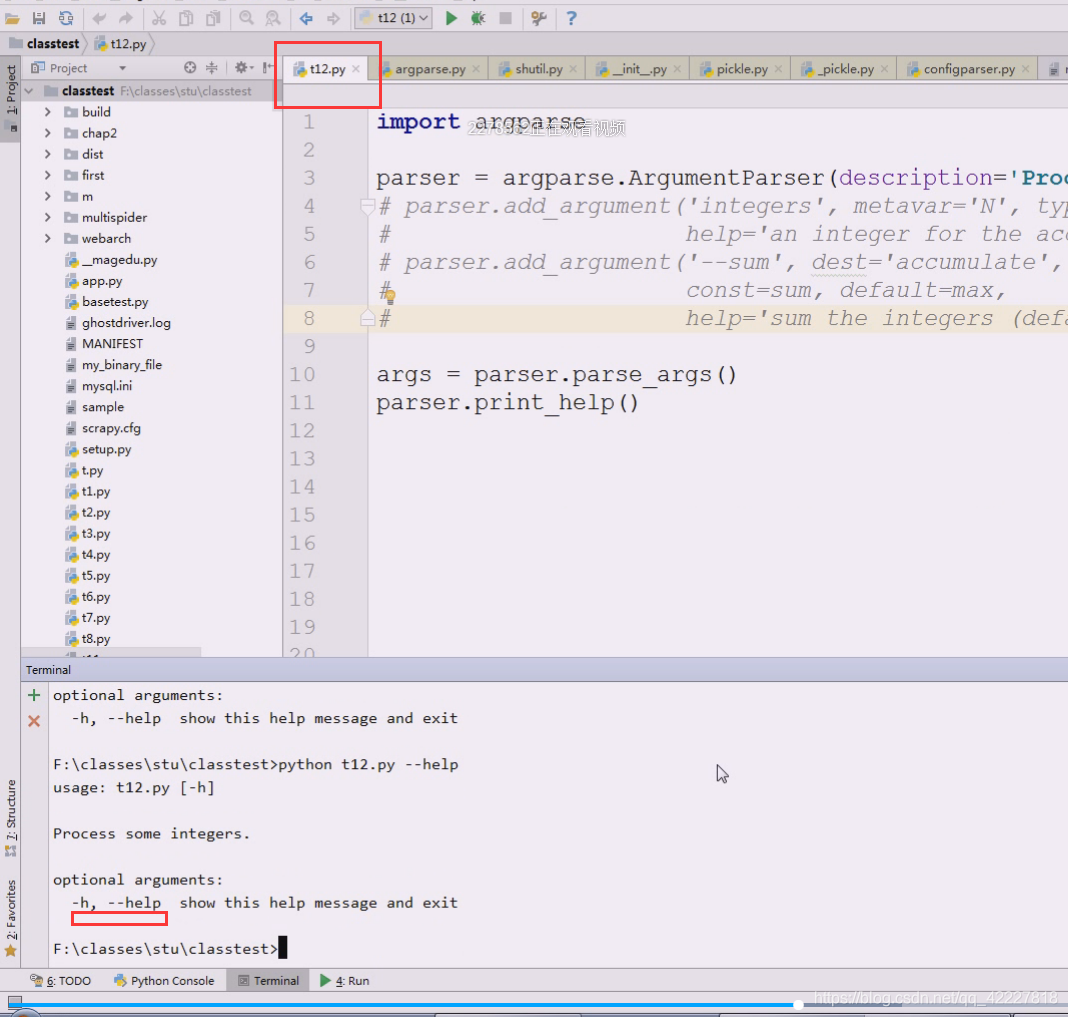
这个-h代表human代表人类可读的
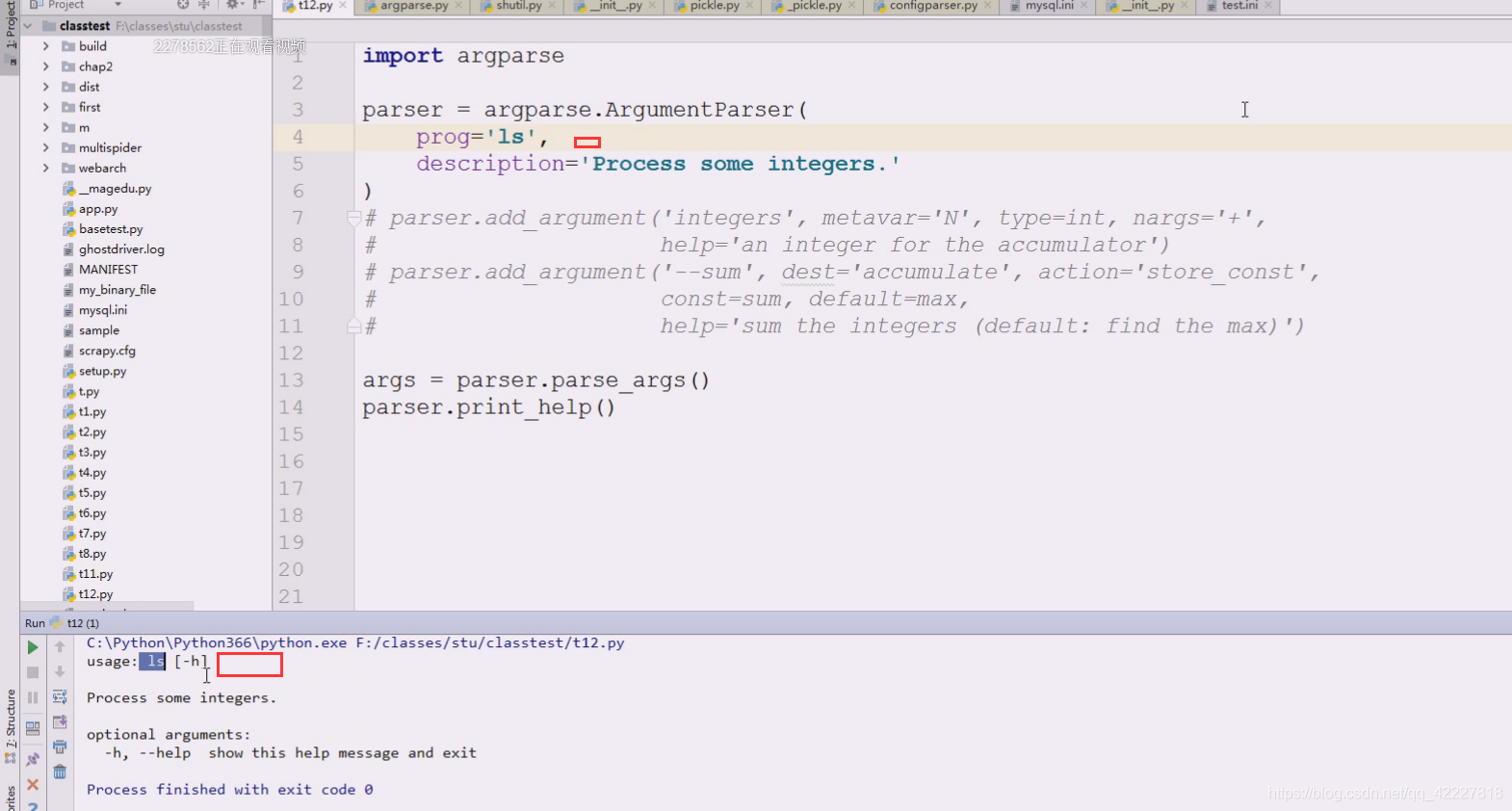
add_help也需要做一些调整,False ,帮助就没了
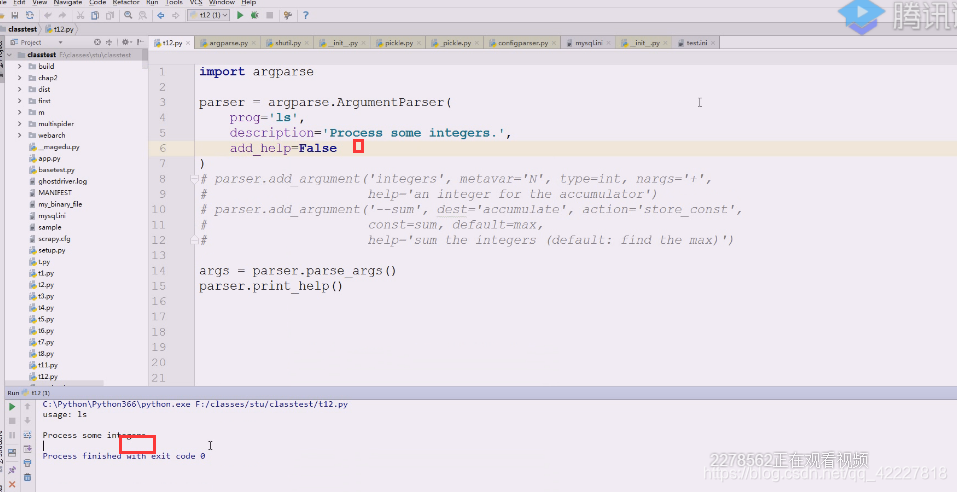
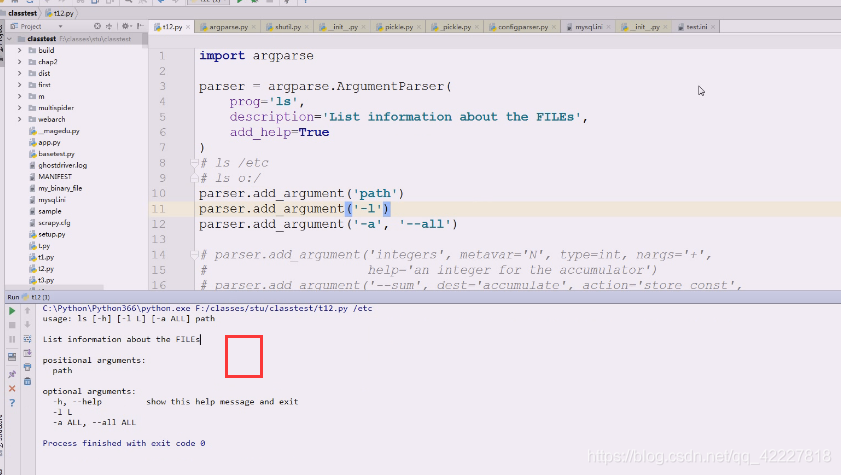
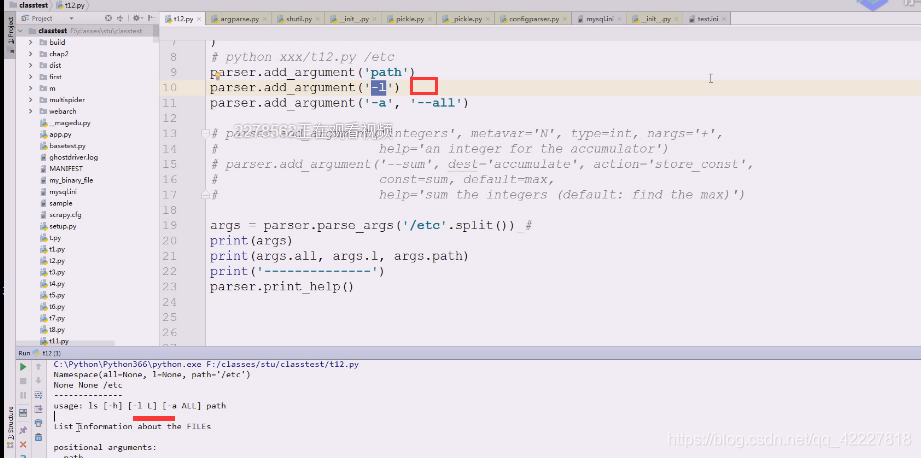
查看linux下的ls帮助,复制一下帮助描述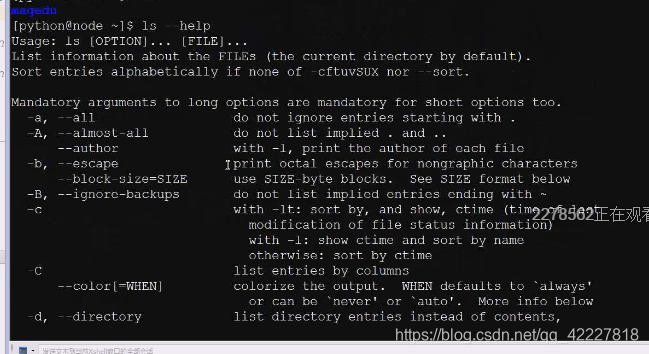
修改成这样,现在默认给你添加个选项,-h。【】中括号表示可有可无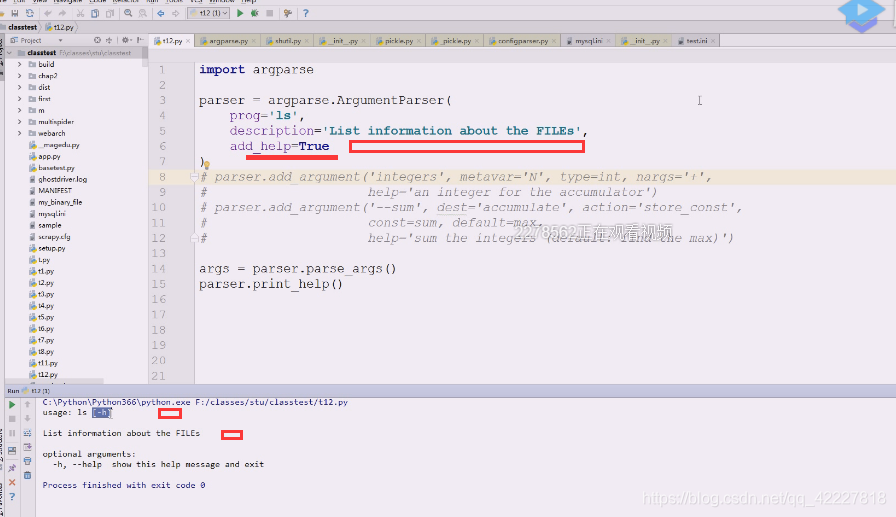
这个argparse模块是必学模块,因为你写的程序在服务器上运行都是要加选项参数的,配置文件加载ini,解析完json就是内建数据结构了
ini和内建数据结构是两种方式,现在一般不用xml,消灭了解析起来比较麻烦
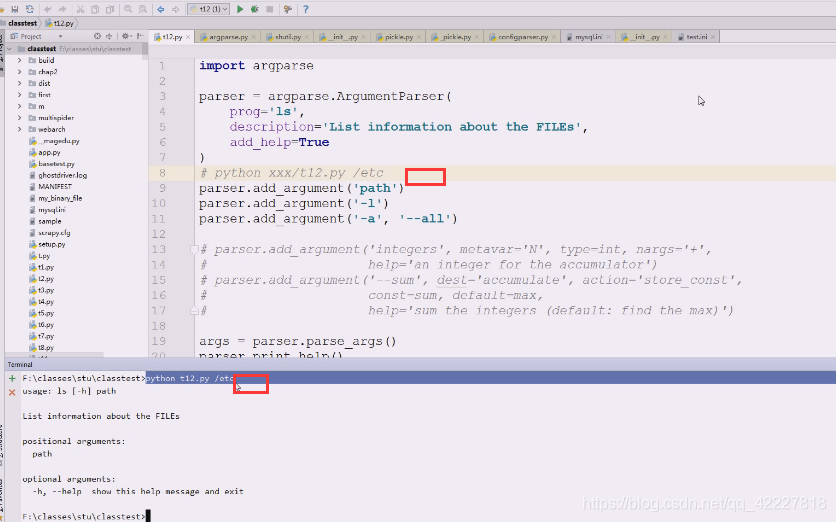
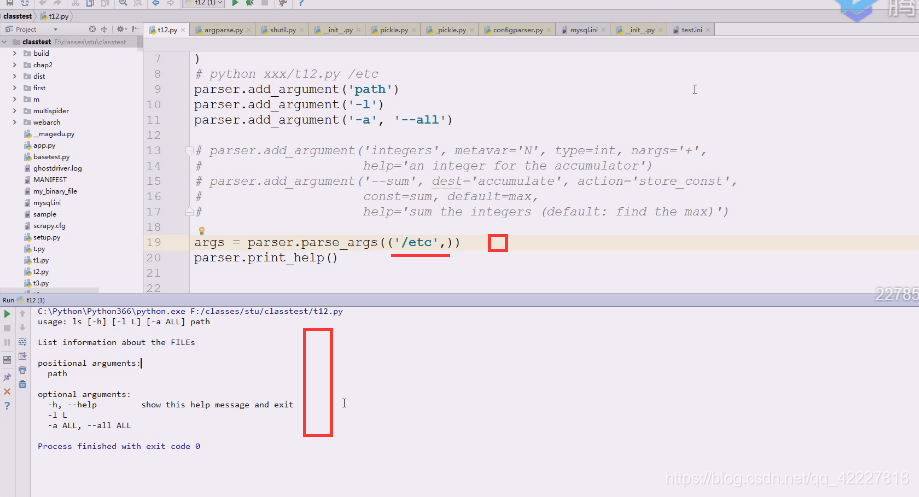
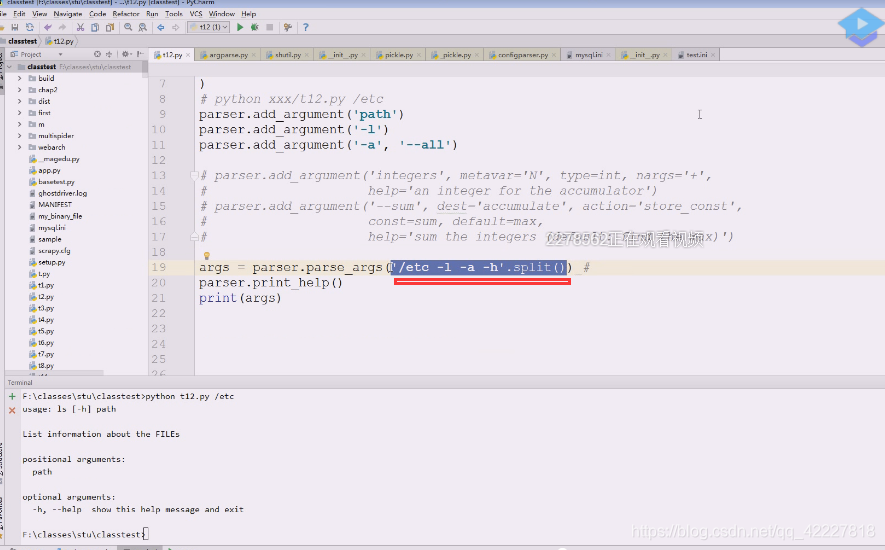
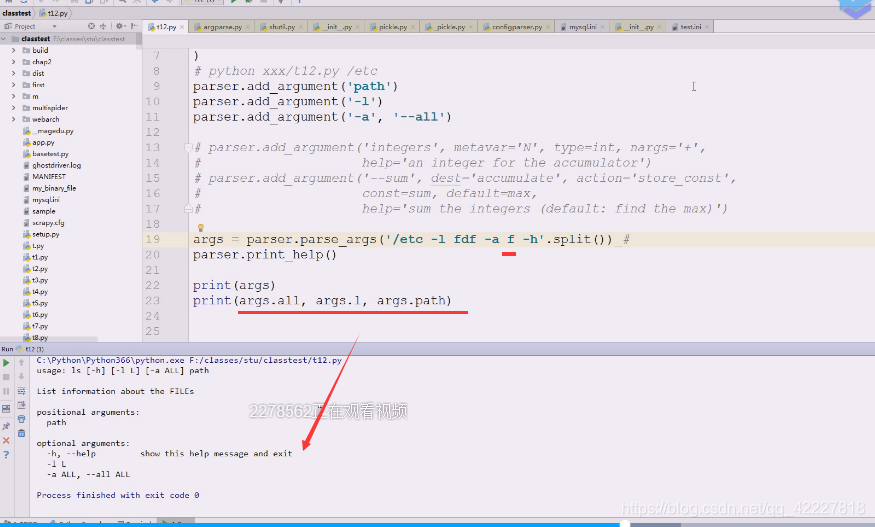
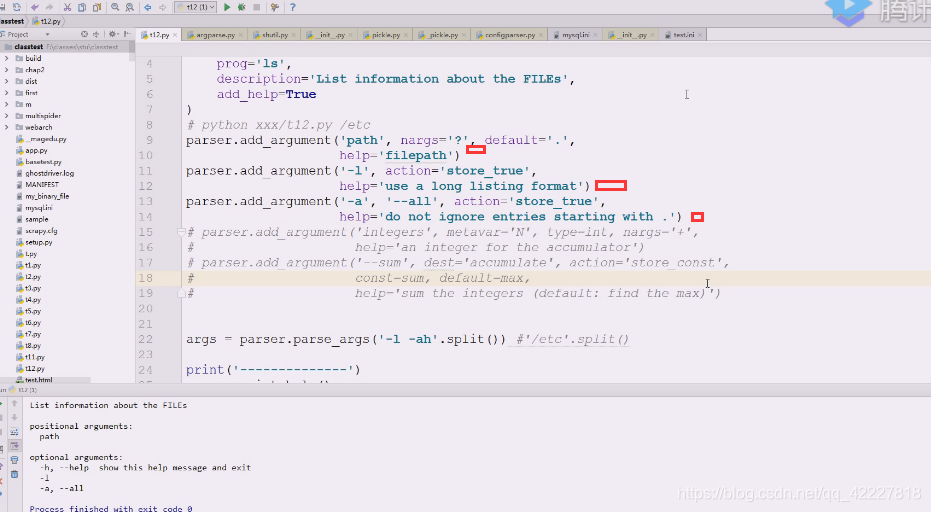
但是我们一般要在后面加上路径,一般是以空白字符切分的,先试试加个path参数,红色为标准错误输出,出错的原因是(刚才运行等于是把t12.py这个文件(相当于ls,命令)运行了一次,这个命令这么写,就需要把路径加上
下面红色的path是不带中括号的,应该提供一个path路径过来,不提供的话,就认为你这个命令参数都没完成,path是必须提供的参数(怎么提供,有两种方式)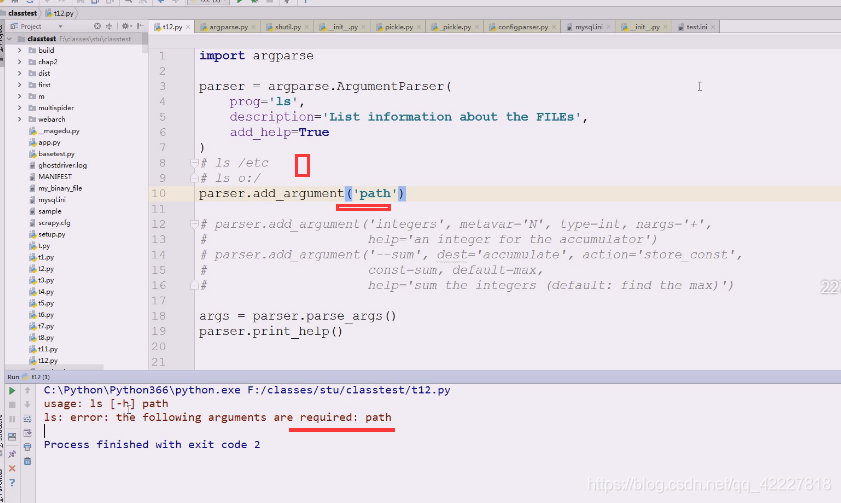
加个路径就好了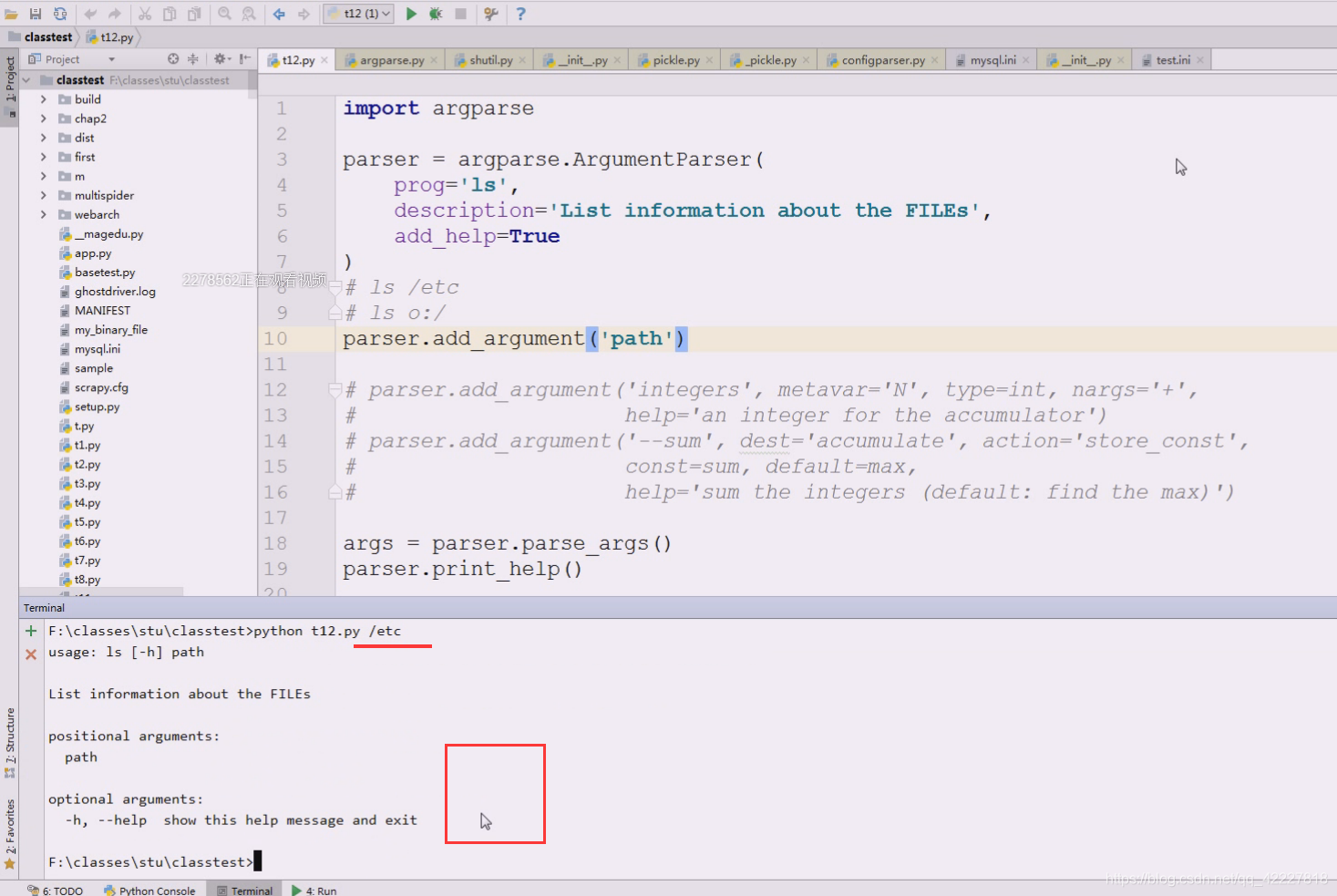
在linux下的ls。path应该是一种可给可不给的参数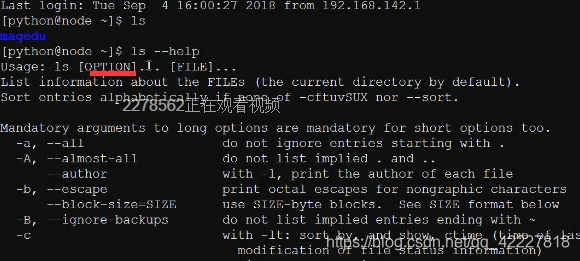
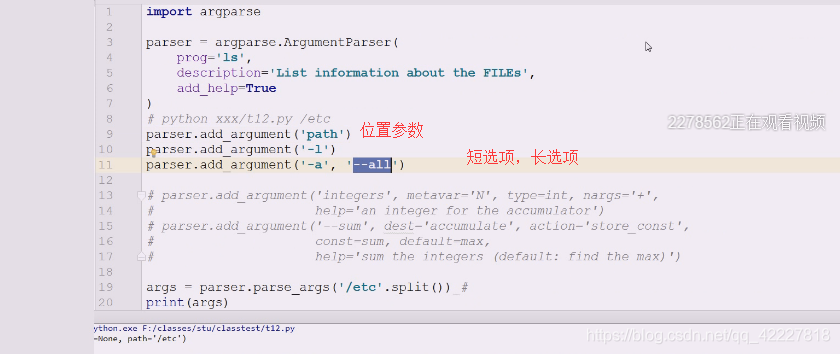
我们还想要列表显示-l
-a
这是典型的长选项
这是添加了多个选项

离目标很接近了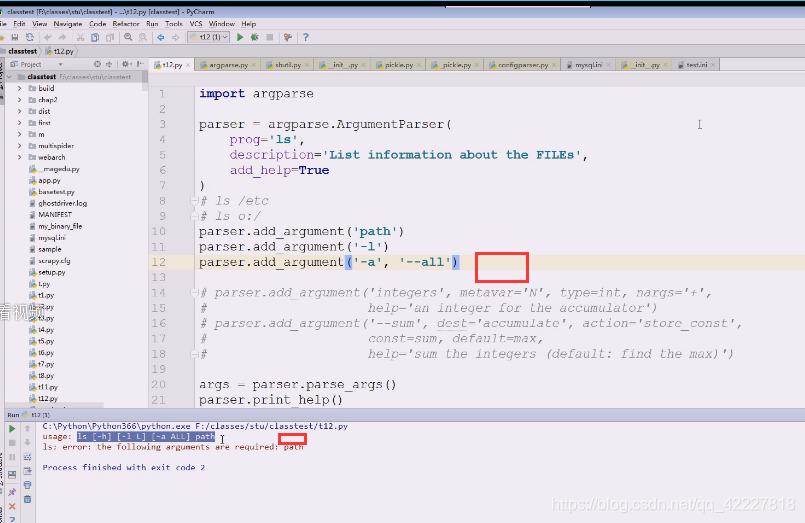
还1缺一个path
出来的是当前正在跑的东西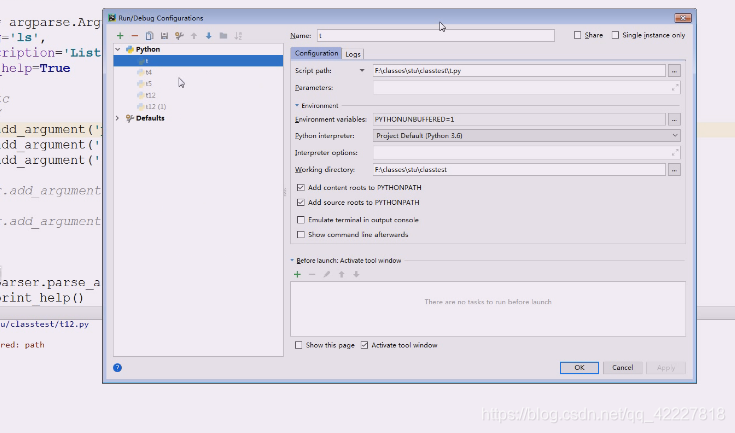
可以减掉

也可以创建,参数就可以加上去
现在就不报错了
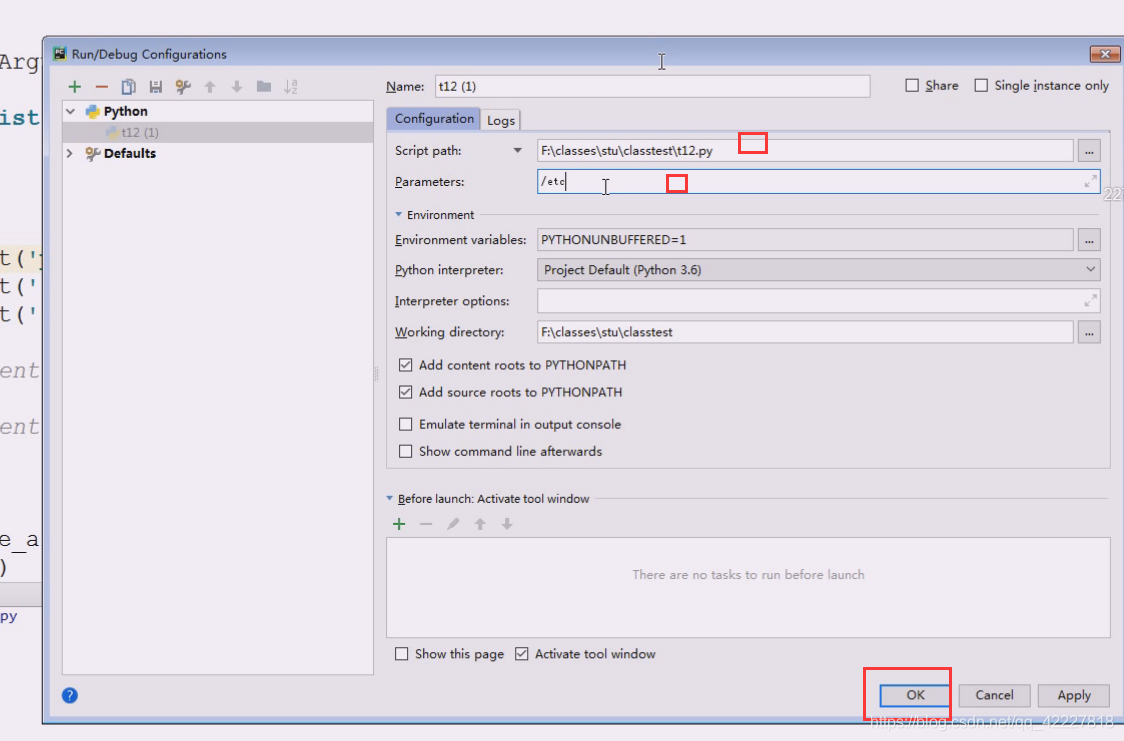
每一次调试或者debug的时候,用python执行这个.py文件,然后后面就隔空格接收参数了,这里相当于补了参数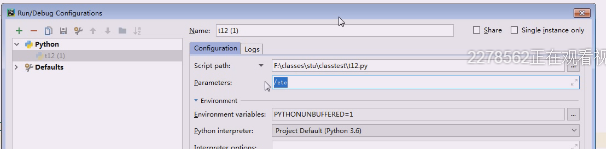
相当于下面敲
还可以跟选项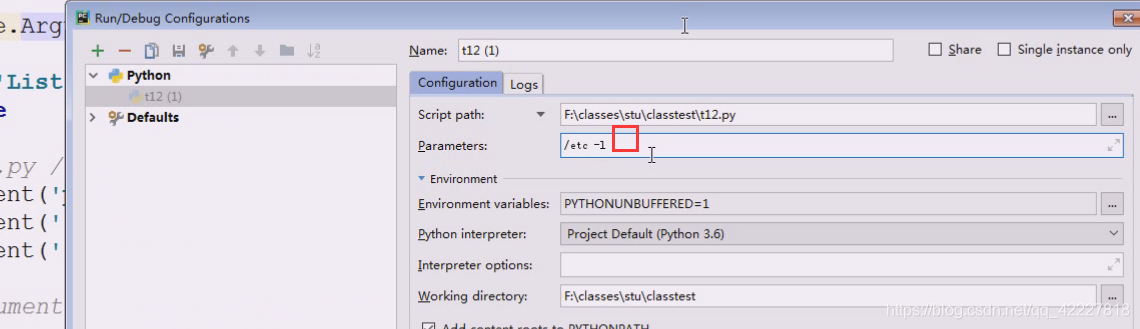
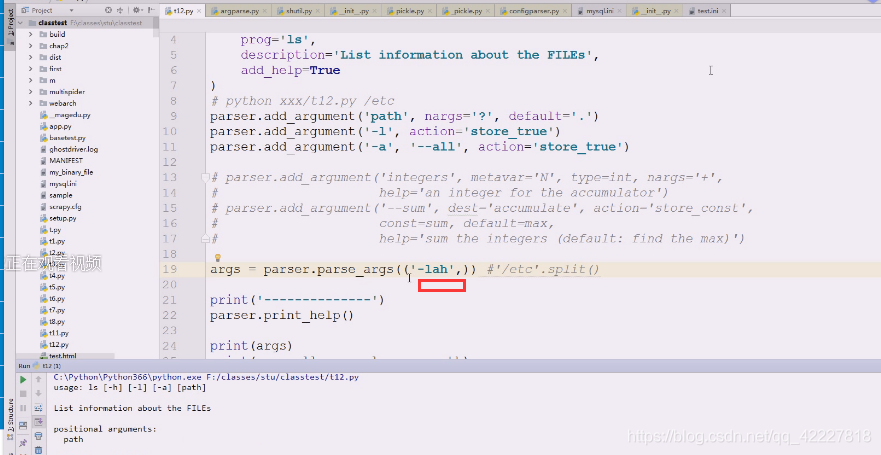
运行一下,[-l L]这里代表要么-l +参数一起写,要么都不写

这是一种解决方案,把参数去掉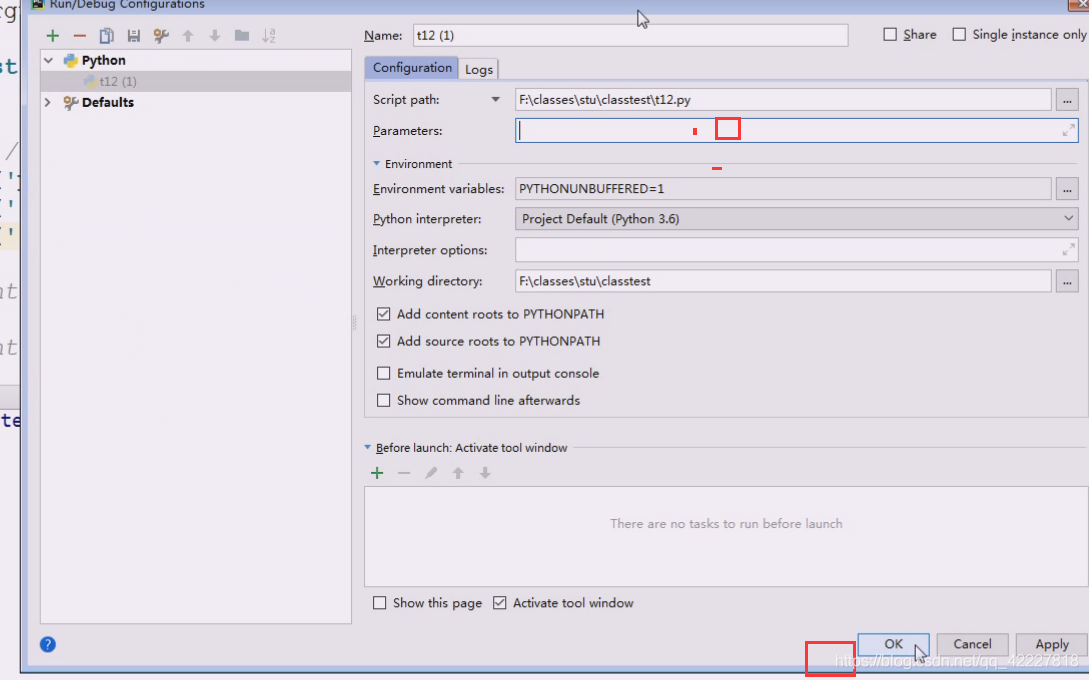
还有一种方案
直接敲会把etc断开,把这个当成分开的来理解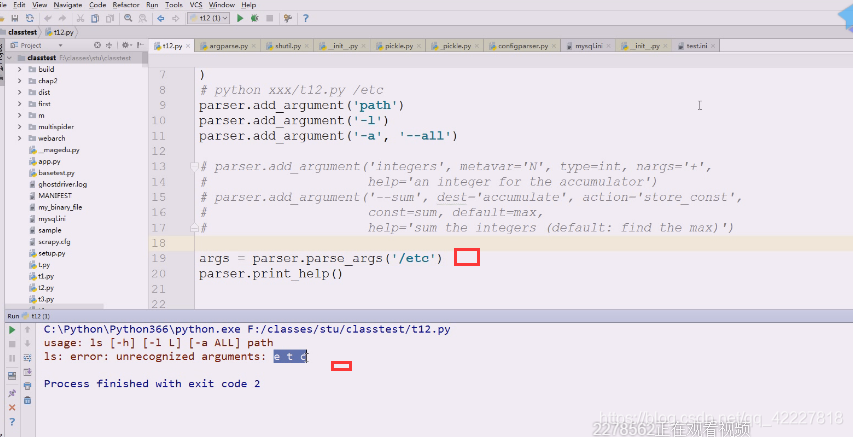
既然迭代就可以改成这样
这个是定义一个命令,名称,描述,参数们
定义好就需要解析你传入的选项和参数
定义的参数都包含在返回的args里
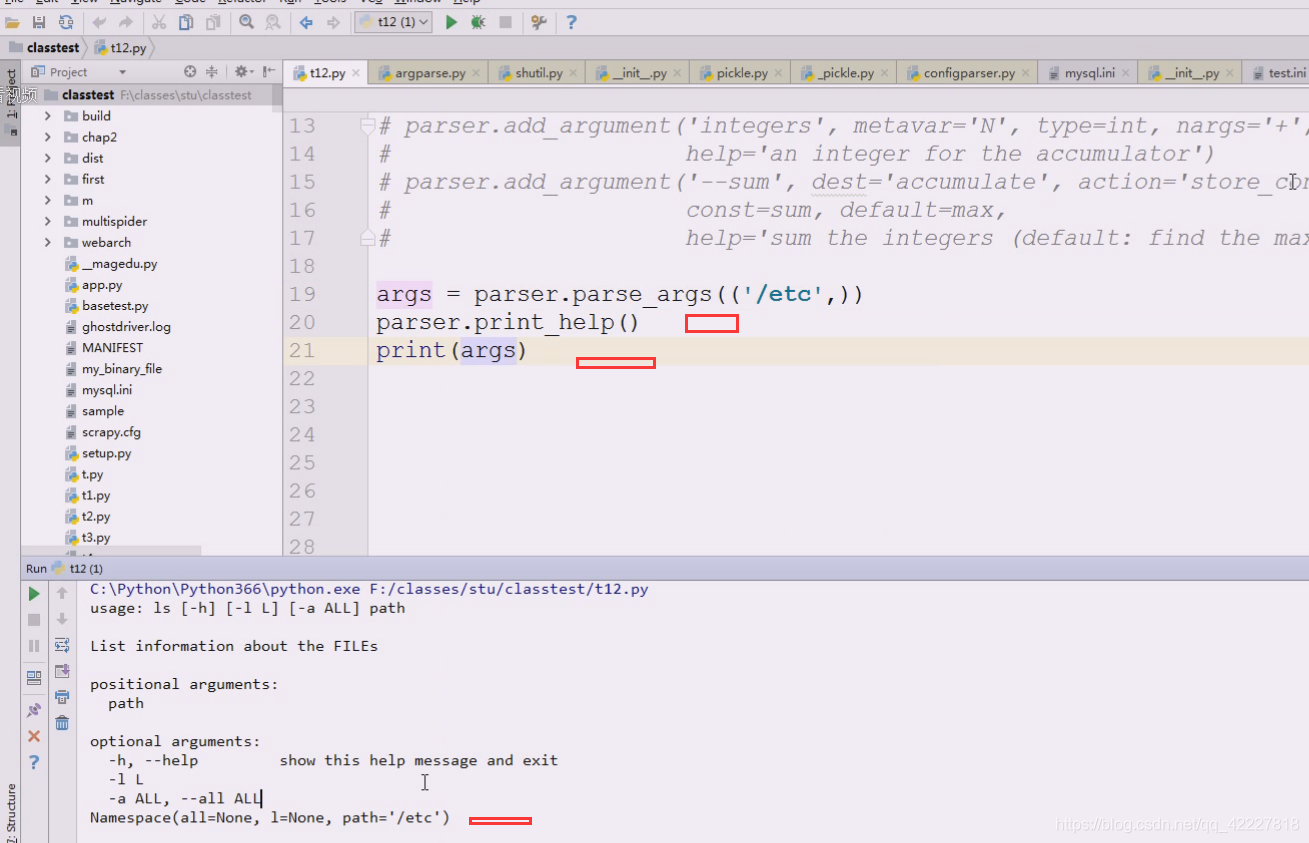
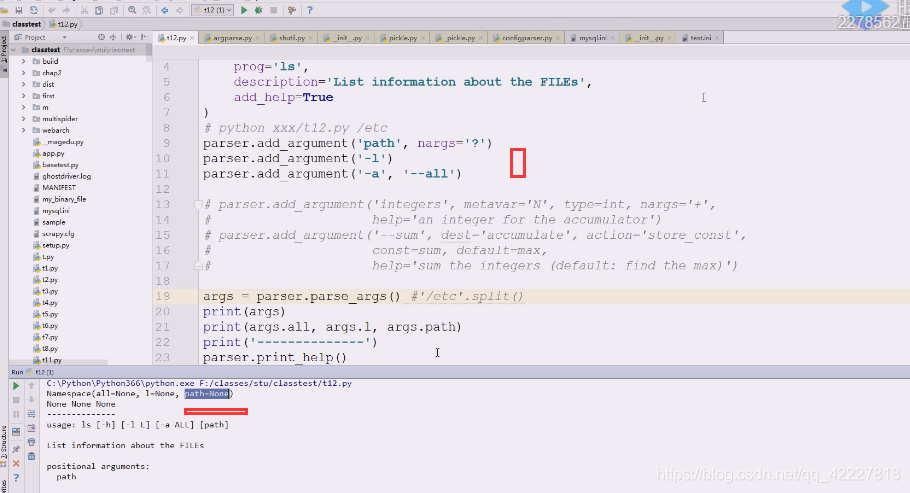
还可以这么写。但是这么写不行,是个字符串,还需要split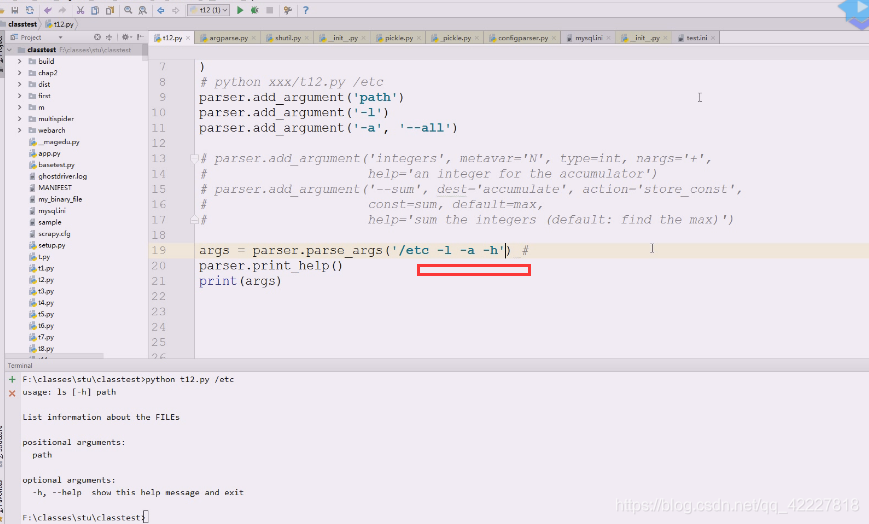
这是帮助文档看到的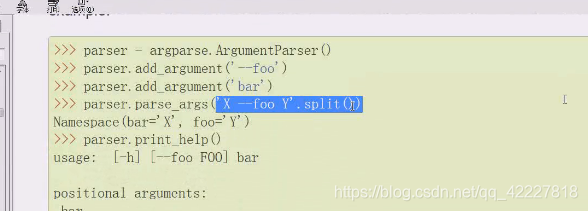
split、返回一个列表,是一个可迭代对象
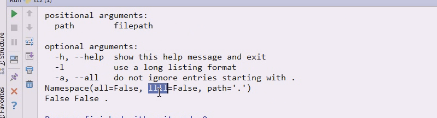
查看一下namespace,如果是none就创建一个
如果参数没给 args is None
就到_sys。argv[1:]里跳过0,0是给了命令行第一个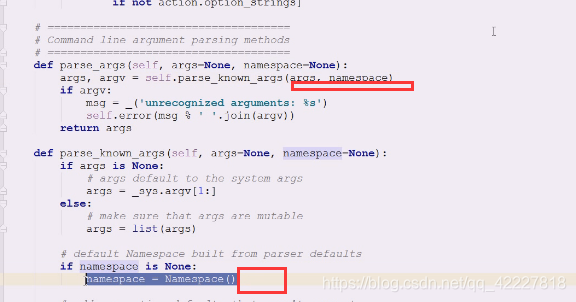
0是 t12.py 1是/etc,所以从1开始拿,真正启动的时候,实际从_sys拿到了所有的命令行参数,排除第一个名字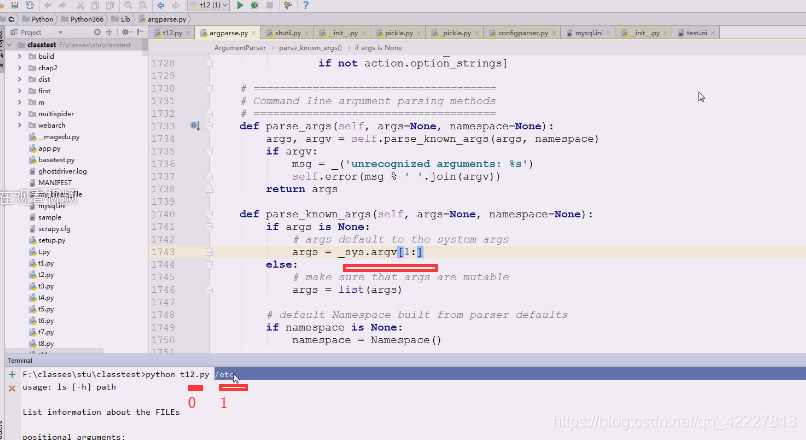
如果给了,是一个迭代对象,就可以把参数list包装进去,也是个可迭代对象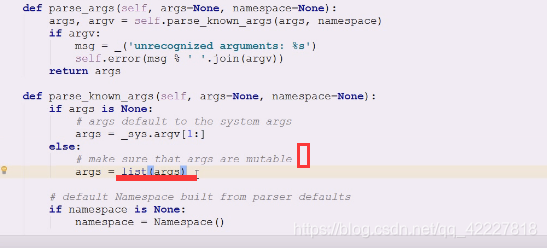
意味着它要处理你所有参数,把参数按照空格切开,然后在里面判断谁是参数谁是选项,下面一大堆的判断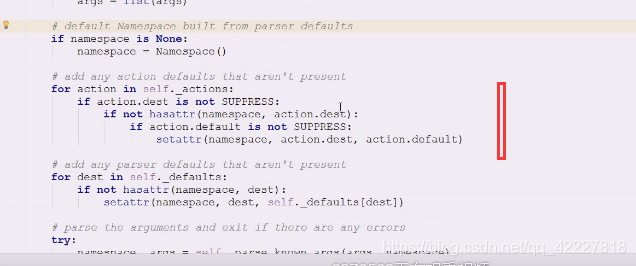
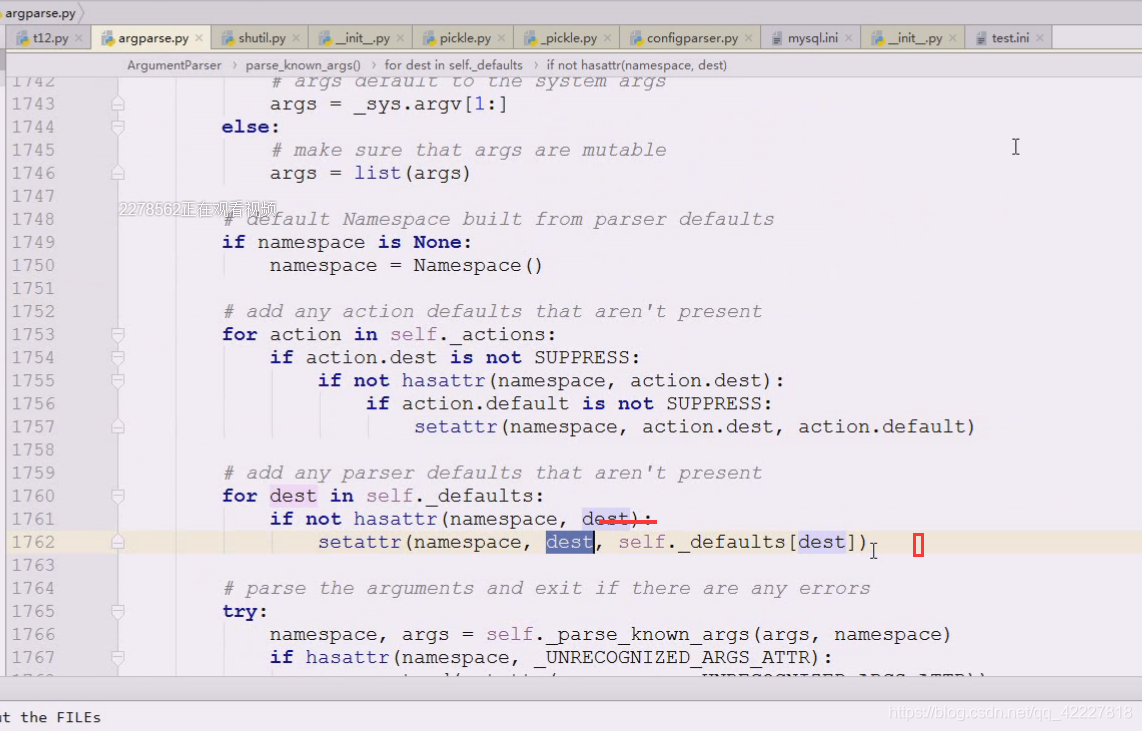
判断namespace有没有传,没有就创建一个对象,有了这个对象之后做了什么事情
缺省值没有被压制的话用什么属性
setattr 添加属性,为namspace对象添加属性,dest,缺省值default,如果有东西没填,就用个缺省值做名字,action.default,缺了才用缺省值补;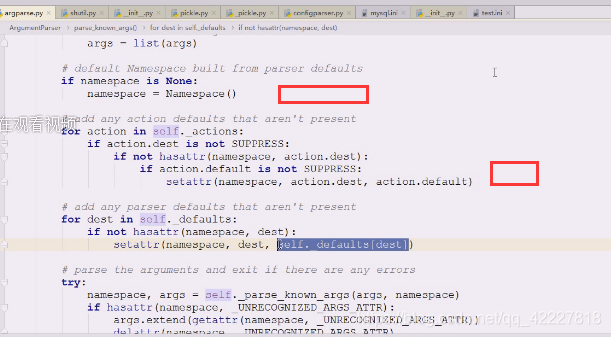
用缺省值往里面填,往这个对象去填东西,添加属性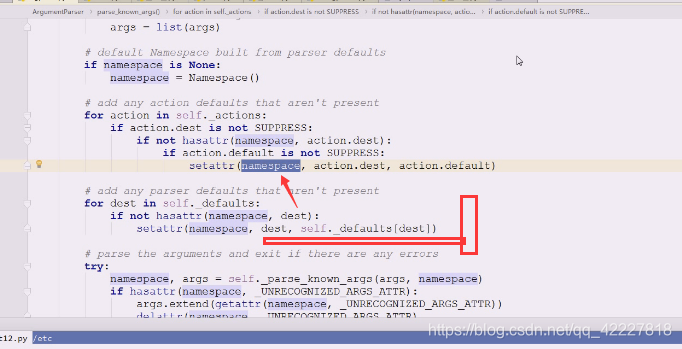
这就是对象 的属性

现在是在里面创建了namespace对象,它在namespace添加了很多东西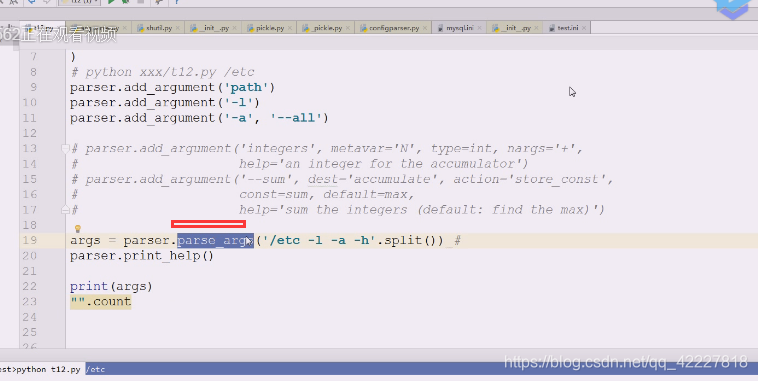
这些属性添加进来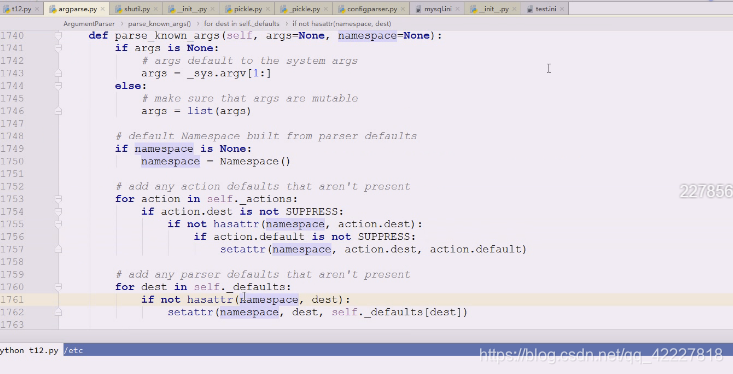
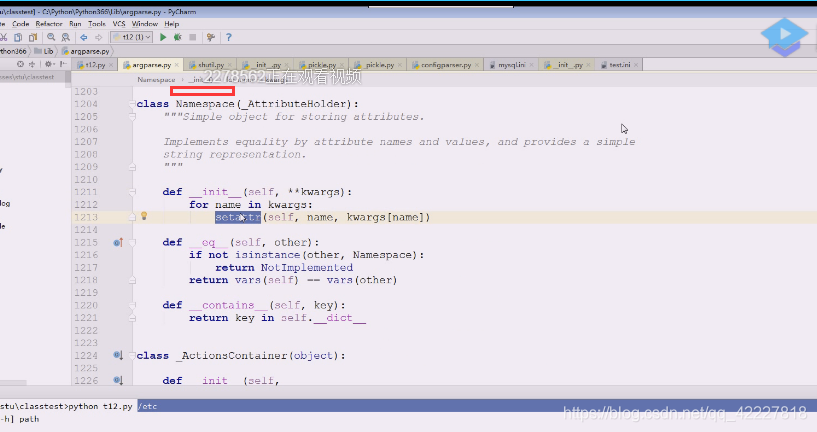
namespace是普通的东西
在创建的时候,判断有没有参,有参数的时候依然添加到属性里去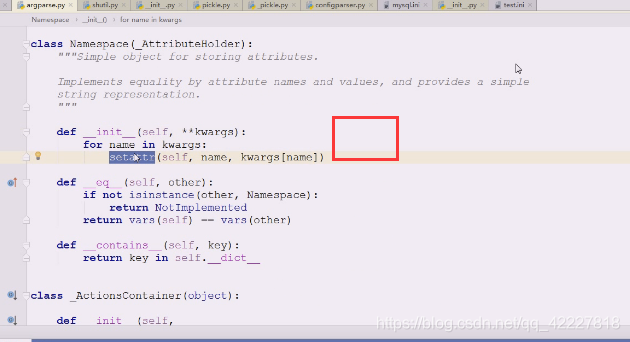
提供了一个方法,可以判断key有没有在什么里面,key有没有 在字典中,__dict__就是管setattr里的属性的
现在明白把所有得到的参数都塞到namespace里去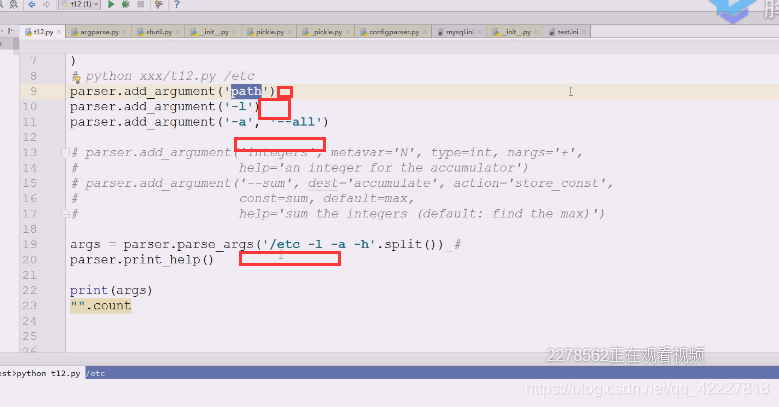
namsespace最终到这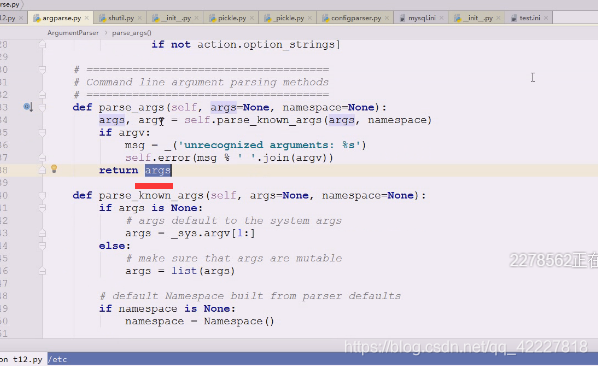
这个函数最终返回一个args和namespace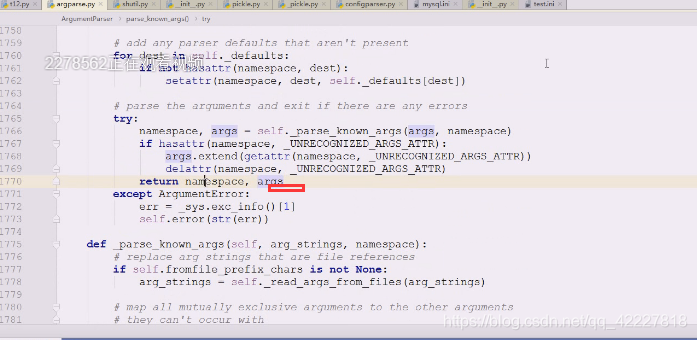
代表前面其实是namespace对象,后面其实就是args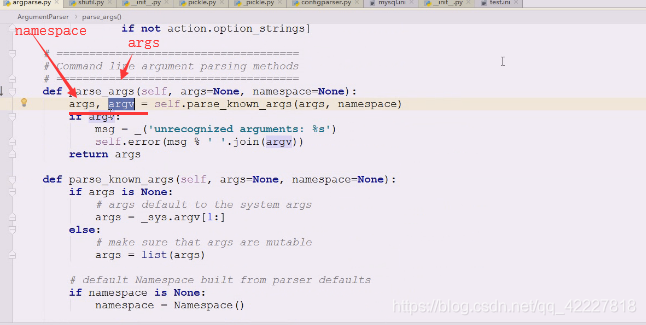
如果后面的args不为空,则抛出异常
假设没有抛出异常
下面的return args其实返回的是一个namespace对象

这个namespace对象就被我们打印出来了,这种是一种字符串表达,是给我们人看的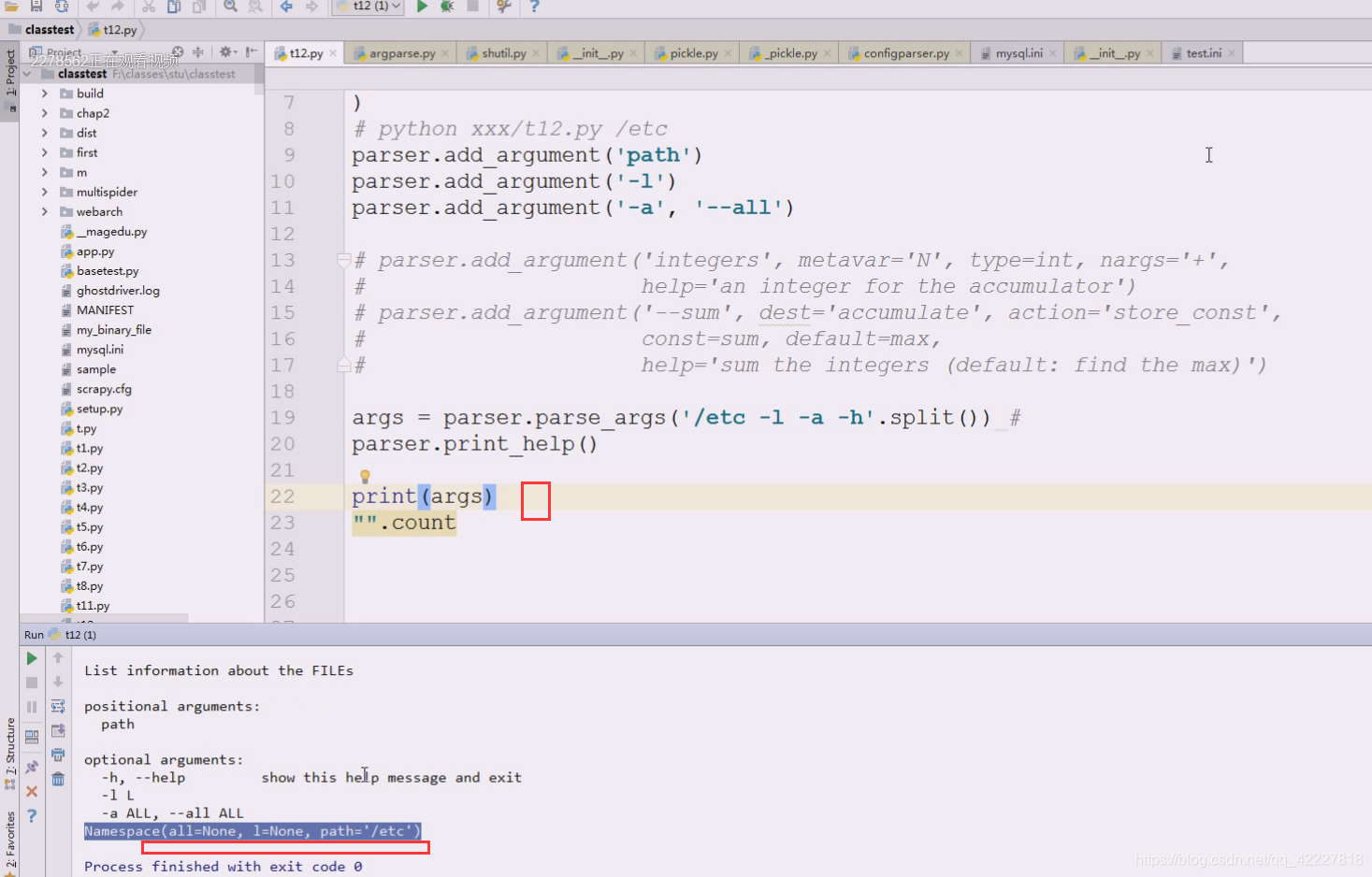
这个说到底就是namespace定义,就这么一点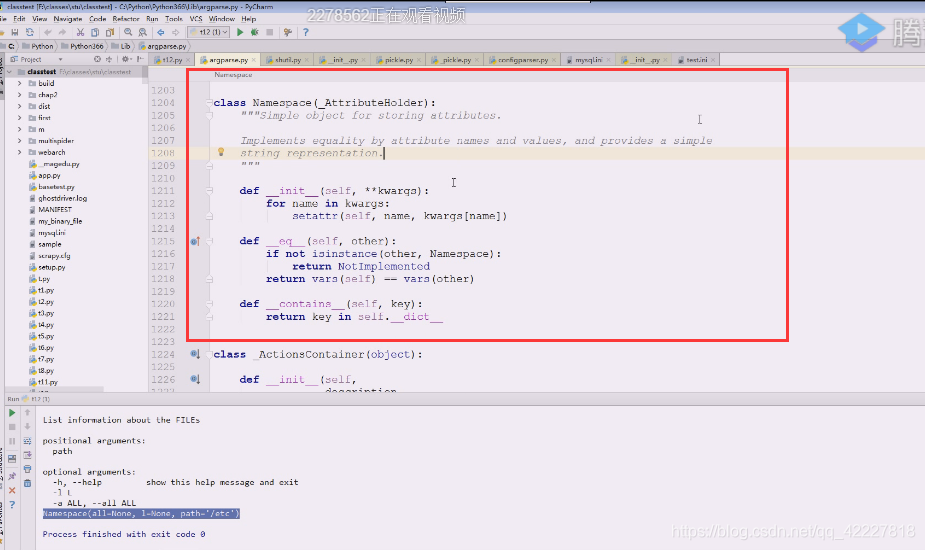
这个是父类
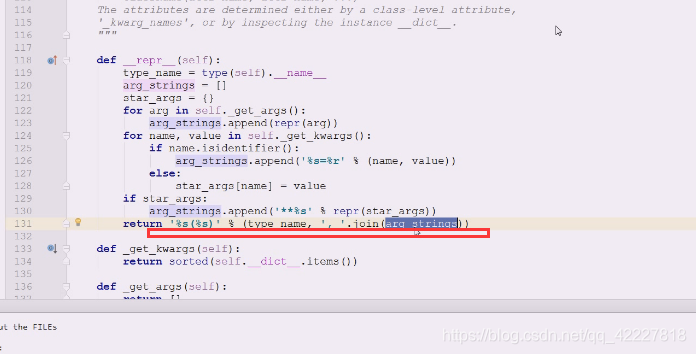
点进去看一下,这就是他们的表达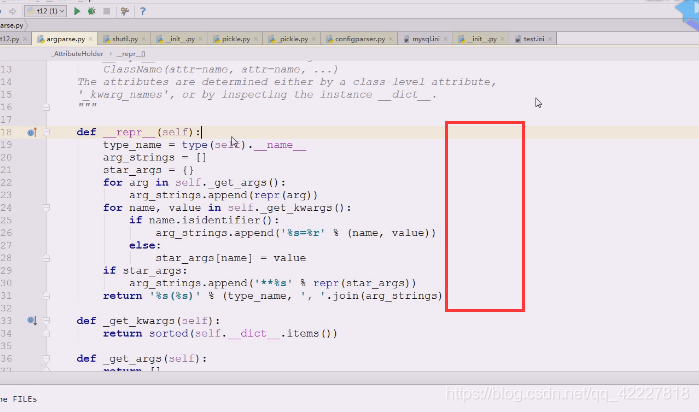
** %s (%s) typename是namespace ,然后加小括号,这个小括号里面填字符串,用逗号间隔的所有arg_string
**
这个就是它拼出来的东西

一点点拼出来,arg的表达
总之在这里拼出来的字符串放到括号里即可
这就是设计的一套表达方式,把namespace里面需要的属性,把属性提取出来,后面把值也算上,然后写成了谁等于谁的模式,放到小括号里,就表达出来了,方便阅读改造出来的东西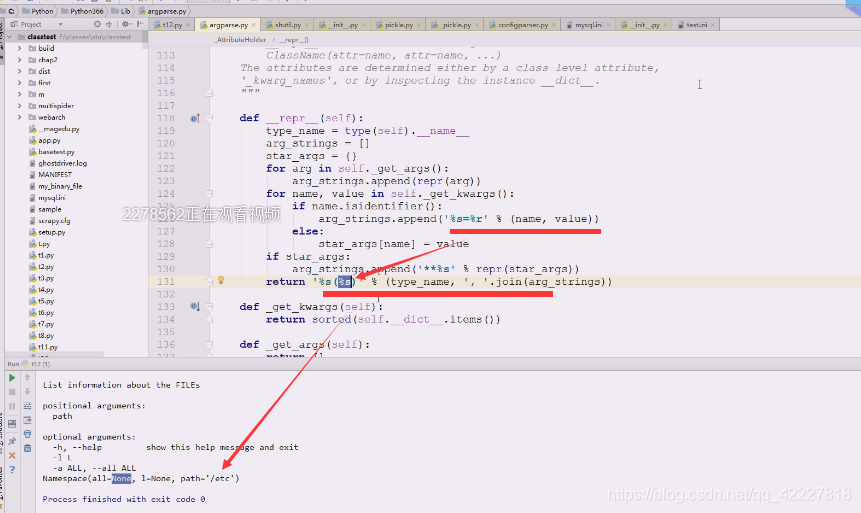
既然是属性就可以这么做,可以直接访问
有点问题需要,改成这样,打印试试
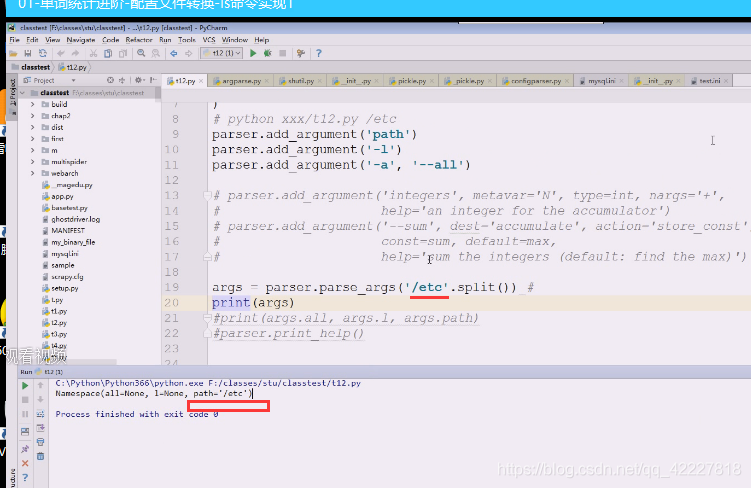
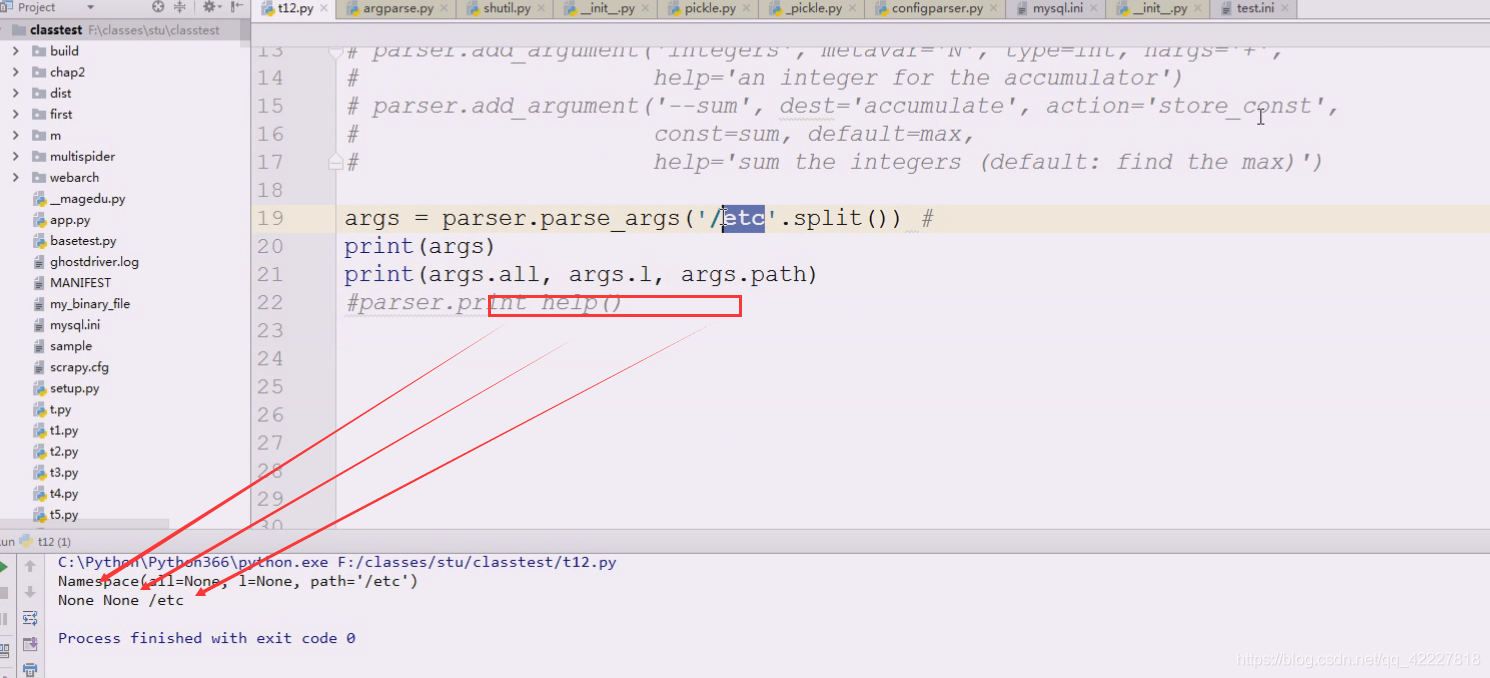
把这两个先打印一下,前面两个属性值没给
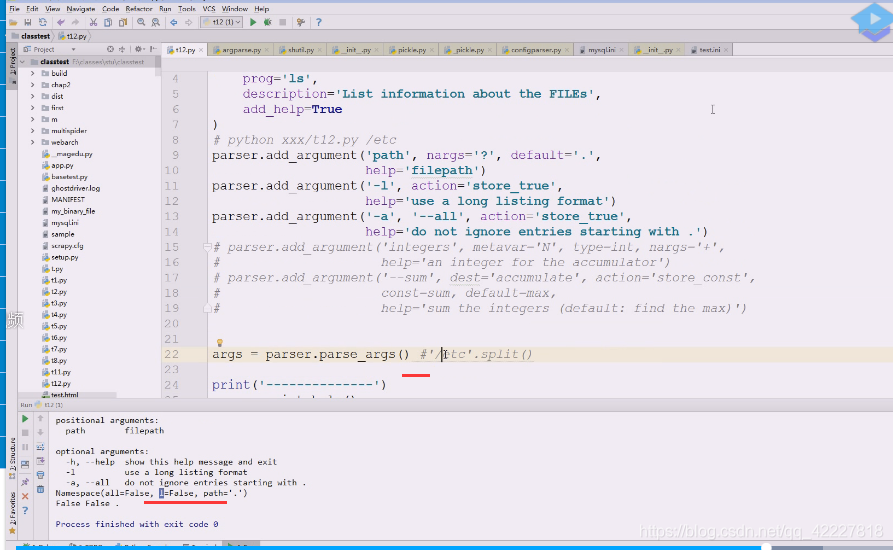
all和l没值,但是path有
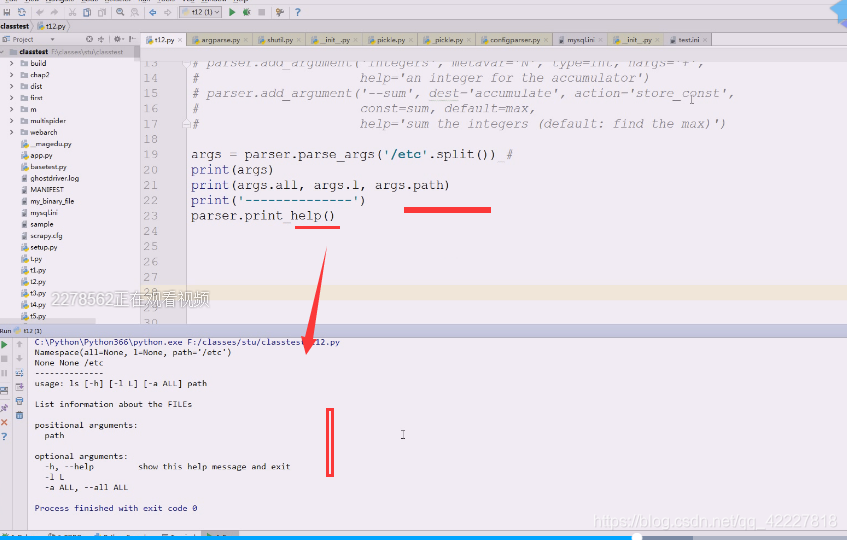
下面打印一些帮助,这样这些值就拿到 了
传完参数选项后,就可以访问
这对象里参数和选项,定义了几个就会有几个属性,可以把这些属性值拿出来打印一下
现在不想要带参l,跟-h一样,还有path带[]可写可不写,不写相当于当前路径
查看帮助如何不写


这个参数叫位置参数,-f --foo这个是选项参数


在命令行,传递的参数能够使用的数量

常量

缺省值

要一个参数还是两个参数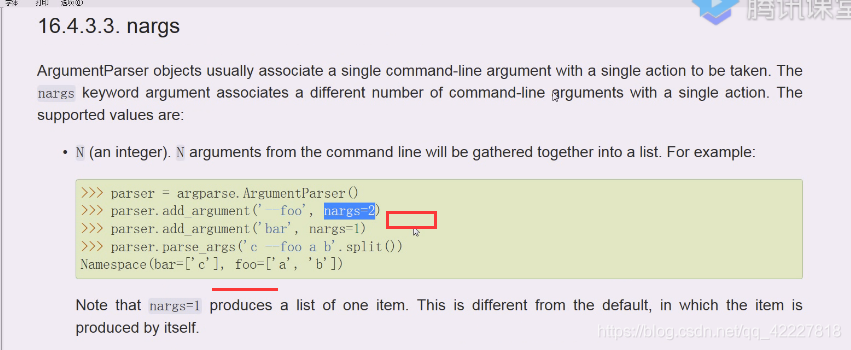
问号?代表有或者没有,0个还是1个
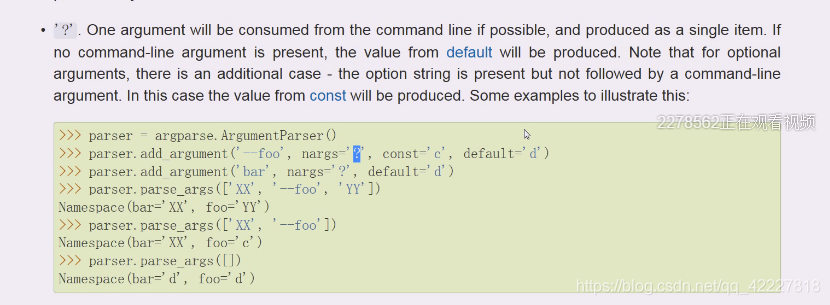
这个就是我们想要的东西
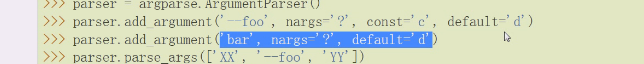
表示path可给可不给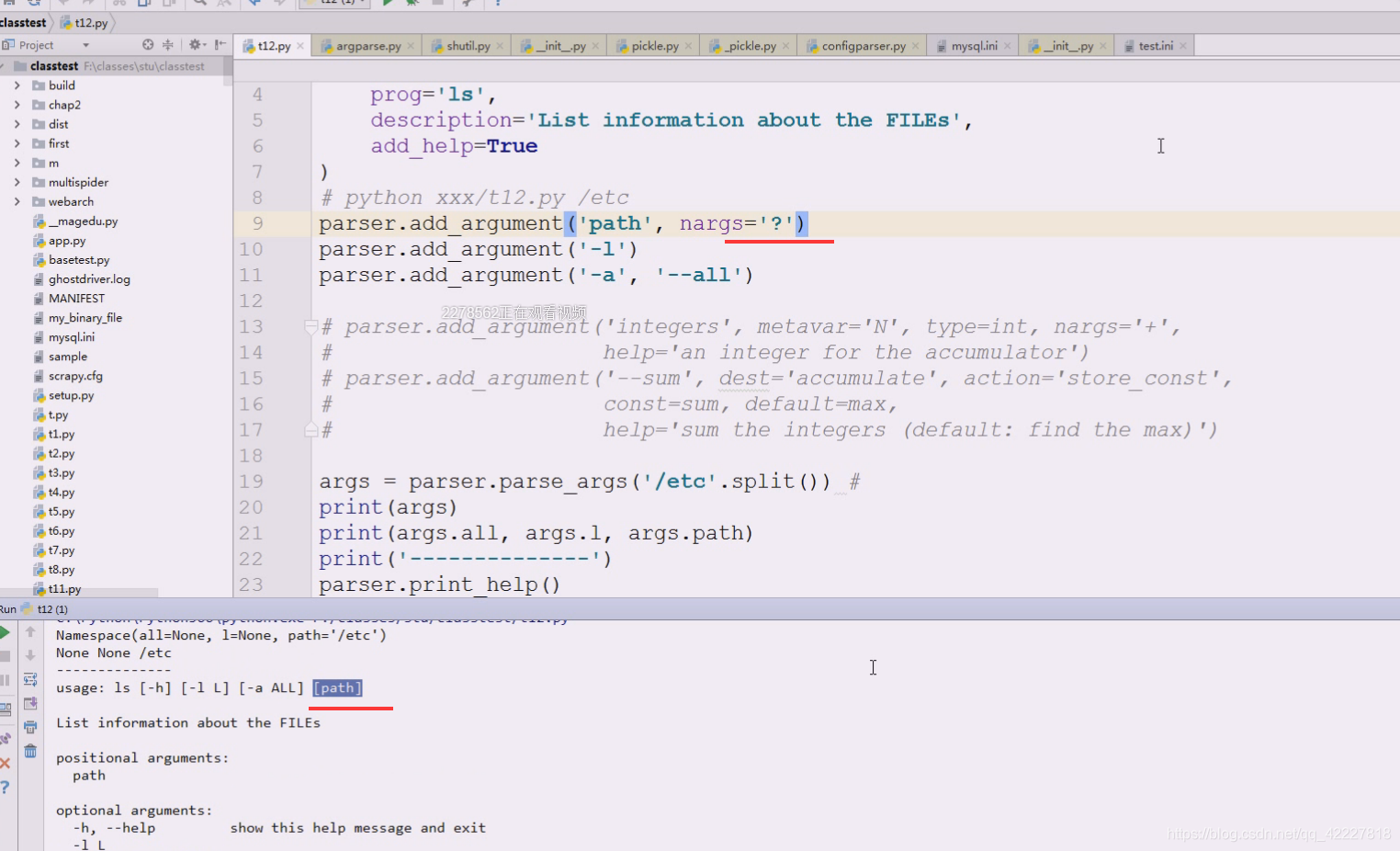
现在所有参数都可以不给
这是个全局设定,缺省值就是None,这个参数就是控制所有命令行里的参数的缺省值的,default就从这 来
缺省值改成点号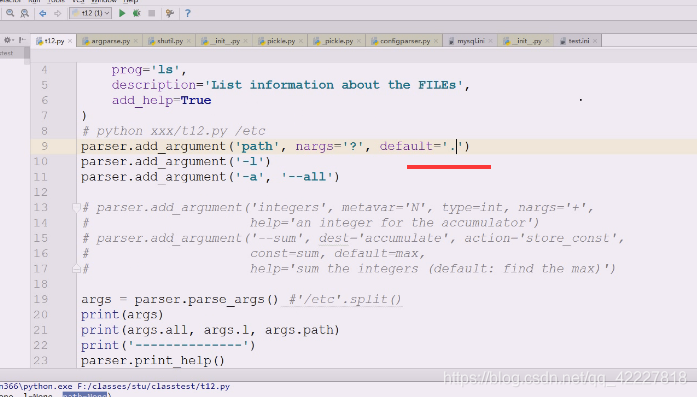
下面替换成这样
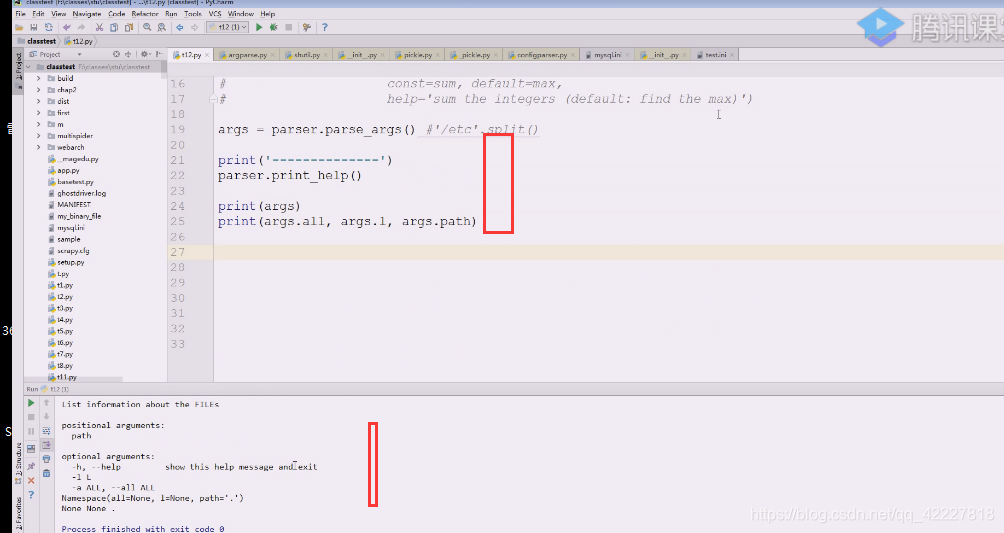
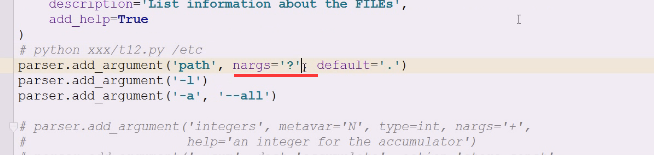
拿到点了,通过这种方式就可以将位置参数转换成一个可选的位置参数,用nargs来描述,它可有可没有,然后后面给default缺省值,这样位置参数就解决了
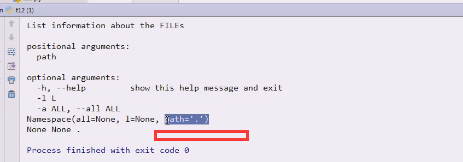
现在就变成这样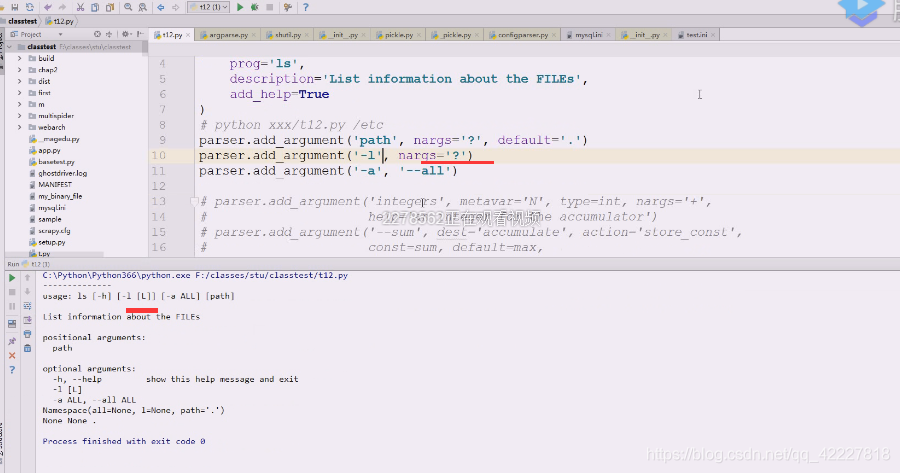
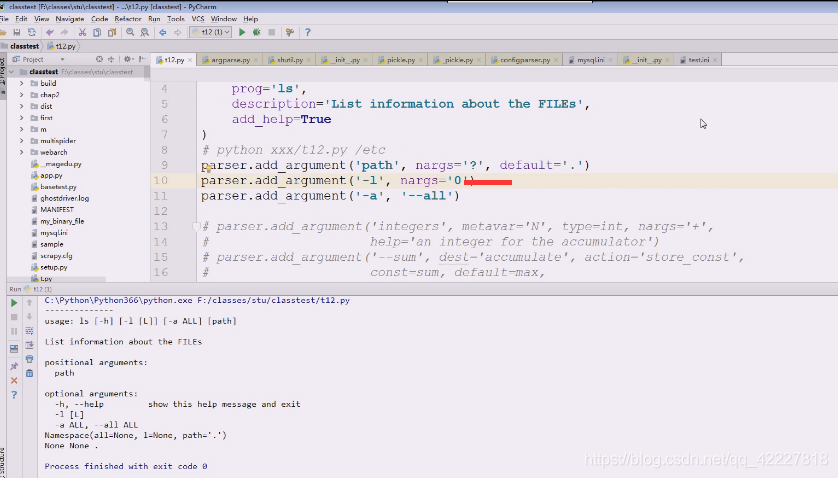
好像没有0
**改成2好像是2 个参, **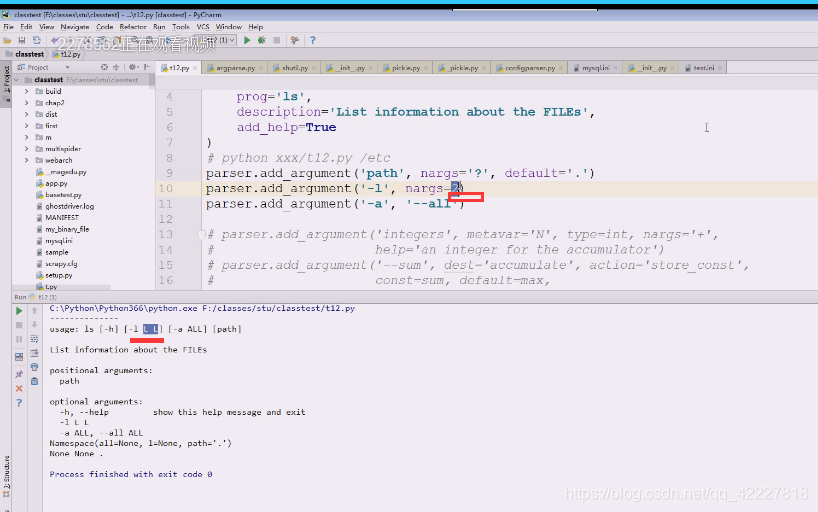
给1就是一个参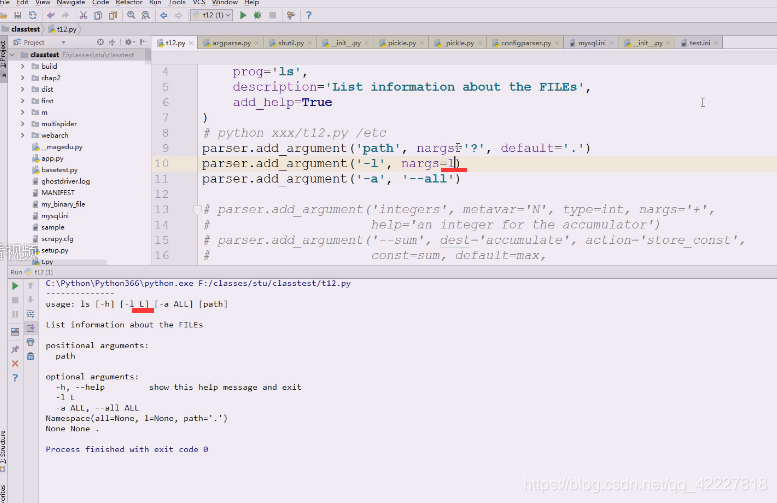
nargs存储的actions,这些必须是大于0的,,如果没有action就用store true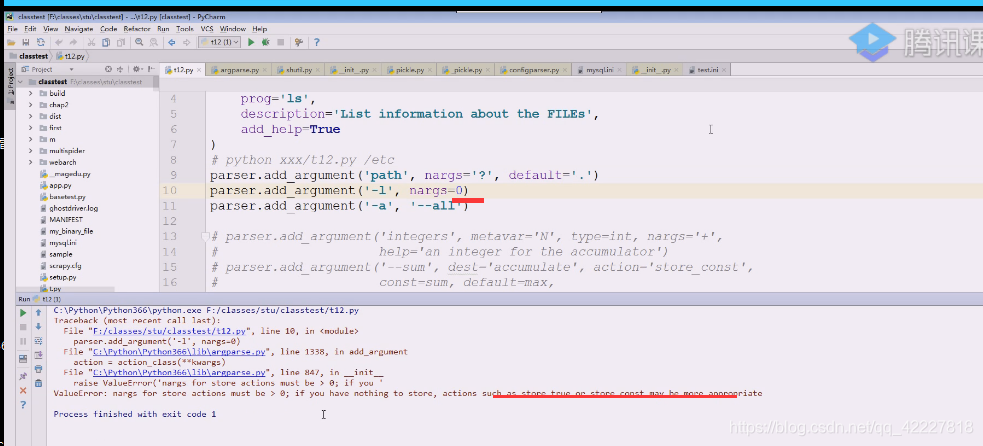
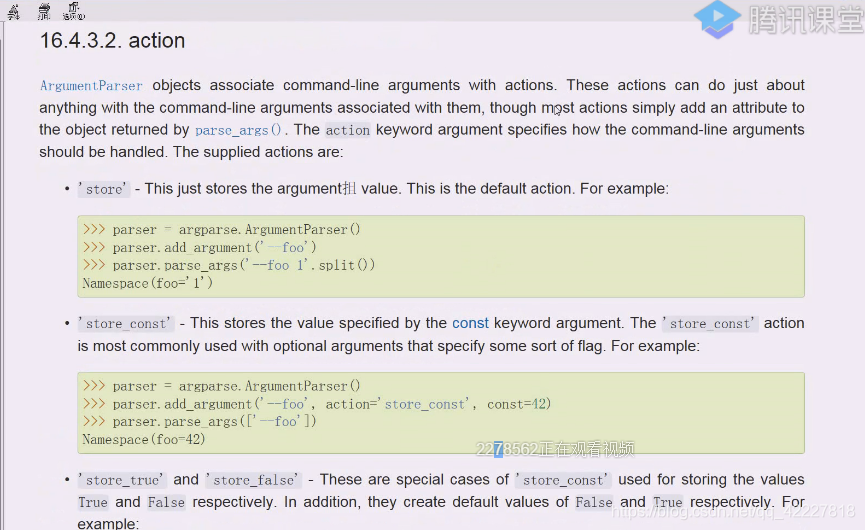

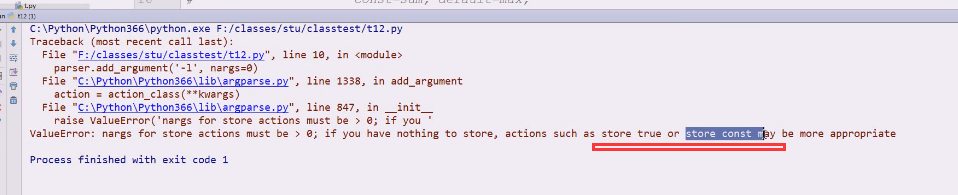
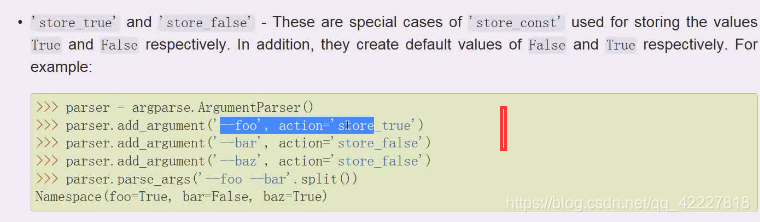
action等于store true或者false,这就是我们想要的结果 了,-l就不加参数了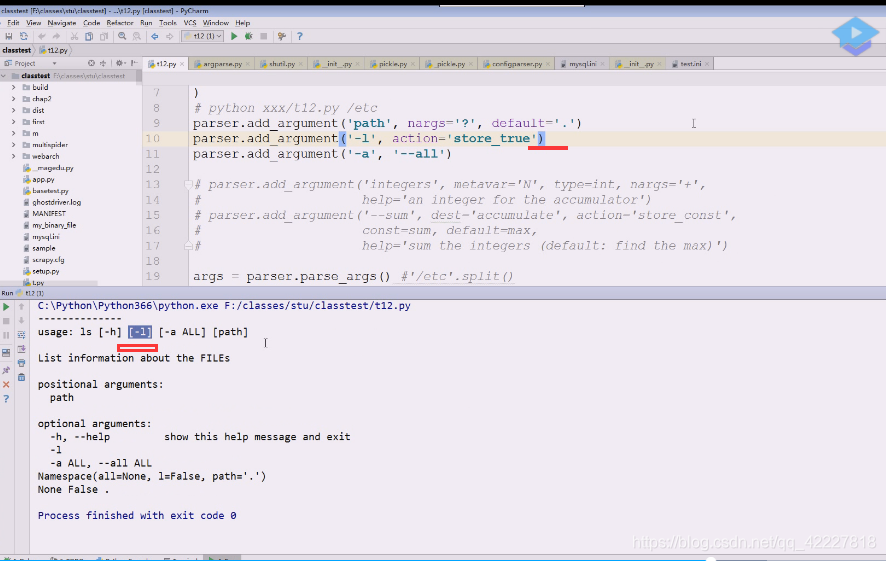
l对应false了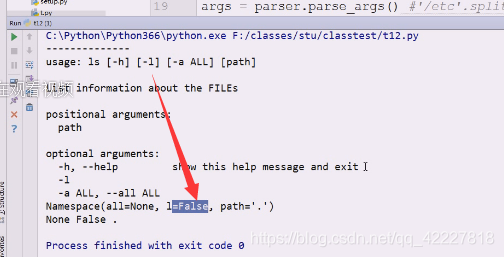
传了一个选项就变成true了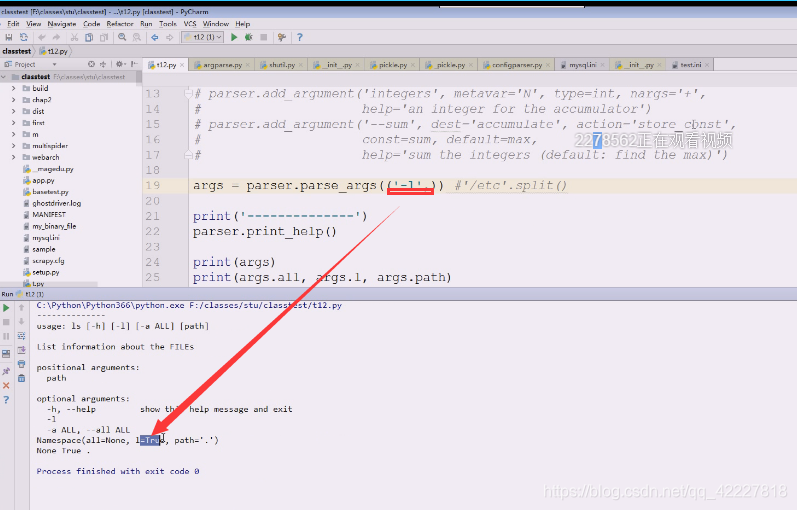
改成store_false试试,代表你给了就是false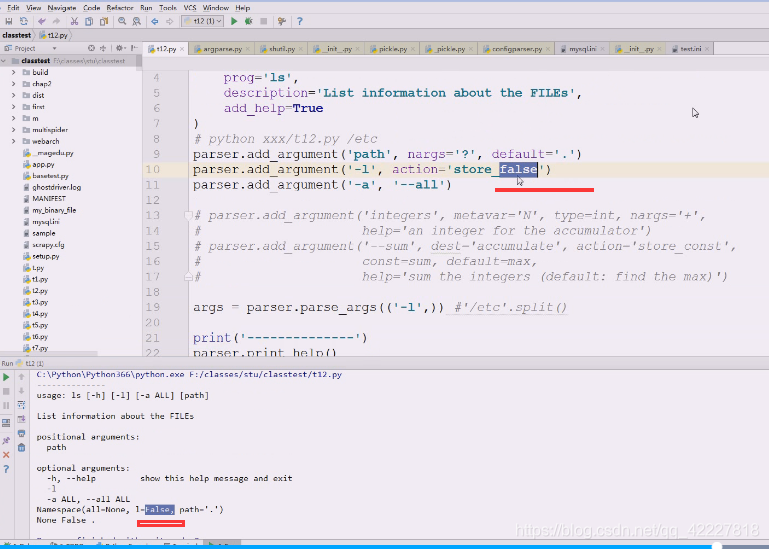
如果是store_true,如果给了这个选项就认为是true即可,用true反之就是false,所以后面不用提供什么值
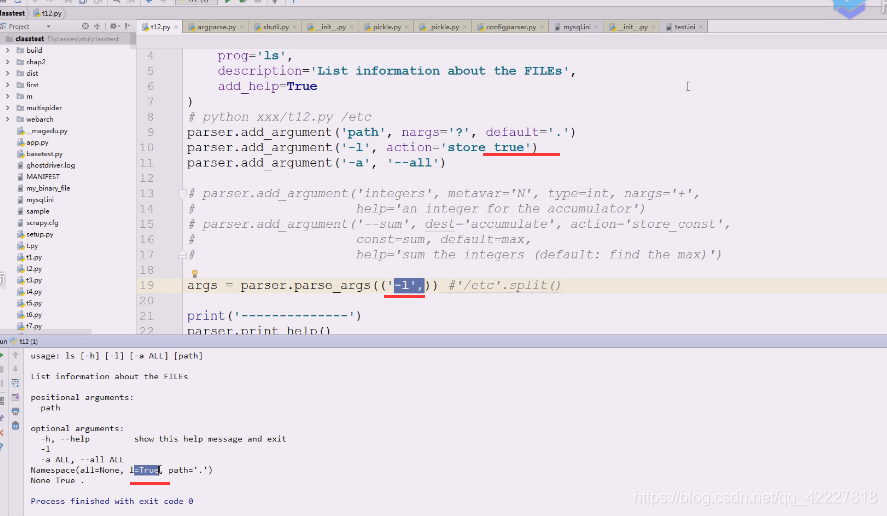
下面-a同样如此
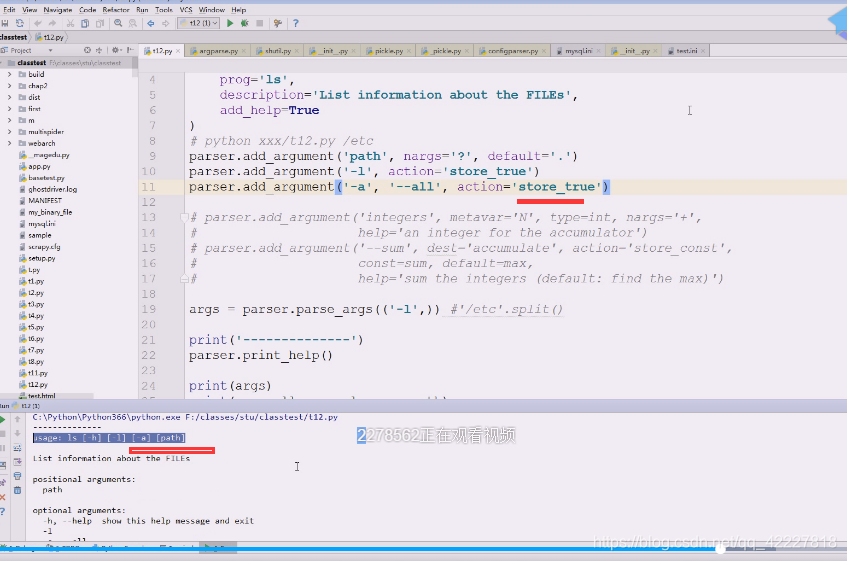
这样输入也没报错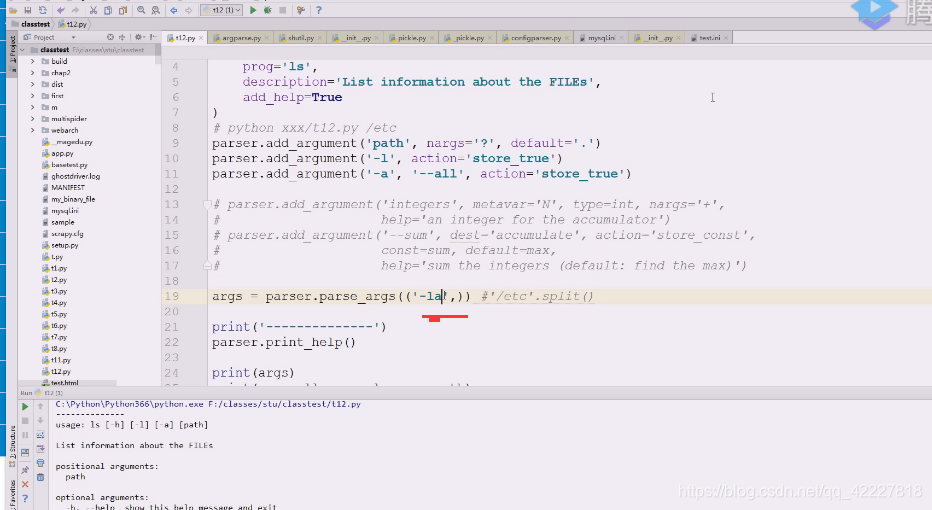
这样就需要用split断开传进去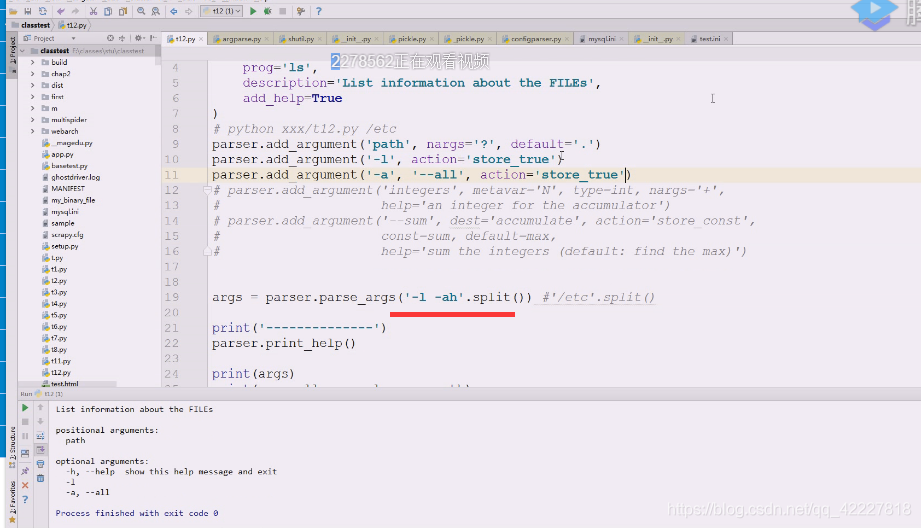
再加几样东西
查看一下帮助里面
help就等于这个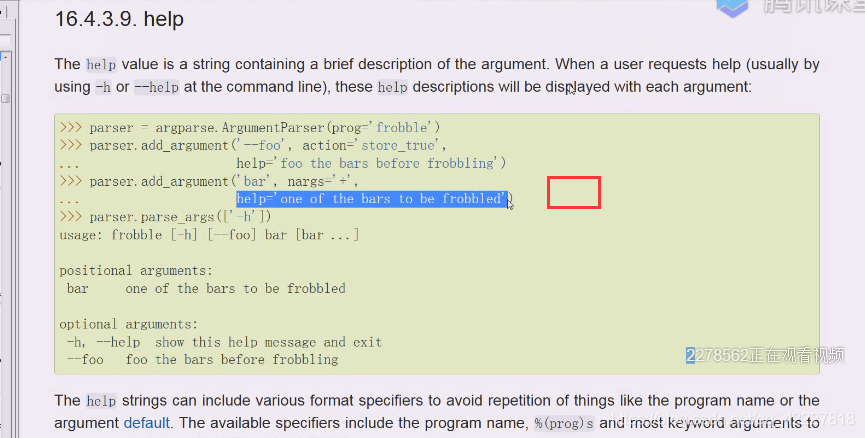
拷贝一下
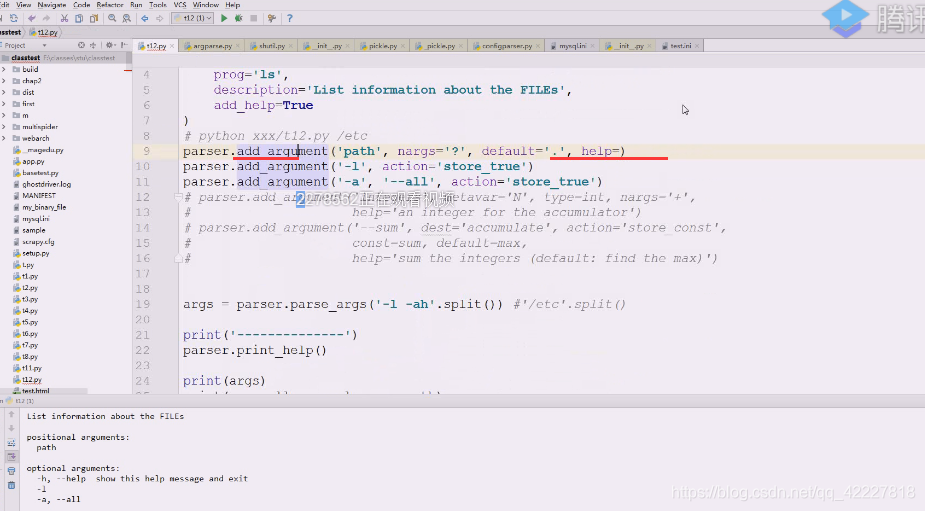
要写help就需要补充内容
在之前的模块里看到过dest,代表对namespace对象设置了属性和kv对,k就是dest
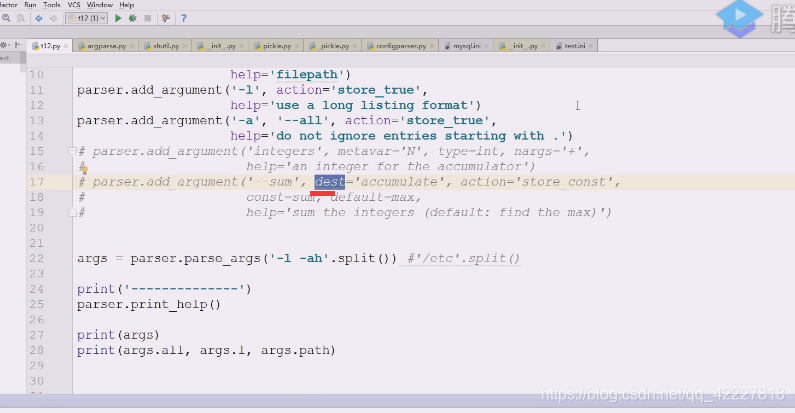
代表对namespace对象设置了属性和kv对,k就是dest
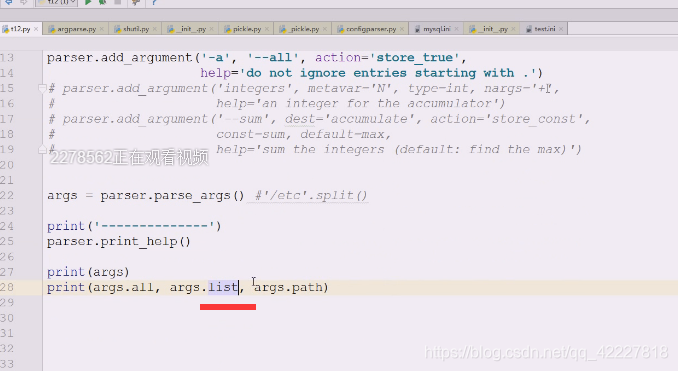
执行一下,l用起来特别不方便
在namespace对象没有找到l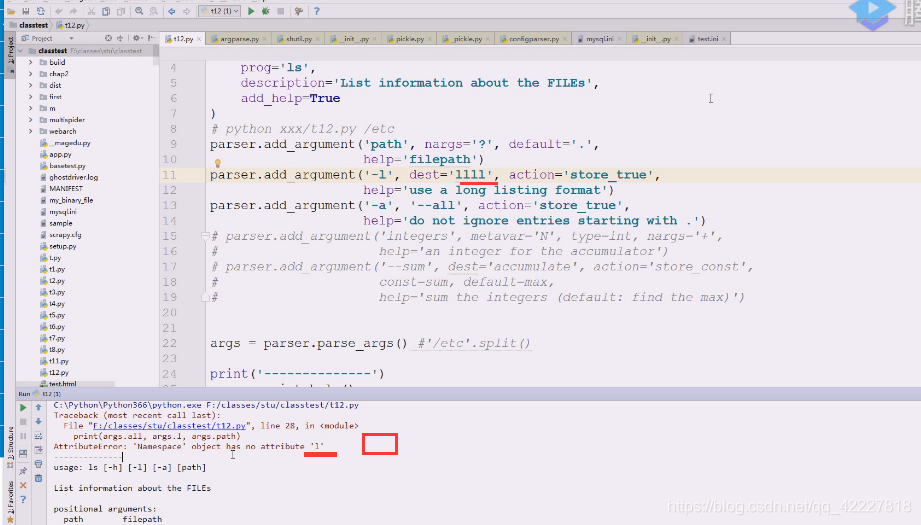
修改一下就没有问题了
这个dest就是控制你的参数未来在namespace叫什么名字
修改一下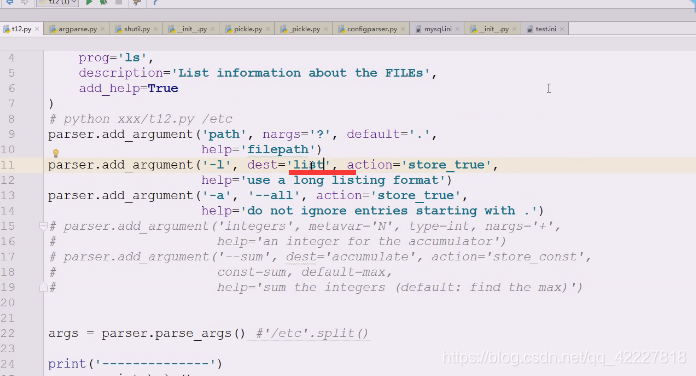
这一行是给用户看该怎么用
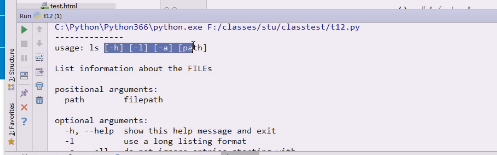
这一块拿到值是编程用的

传进来的值就起一个这样的名字,通过这个名字拿到你想要的值,传给你自己的函数里去
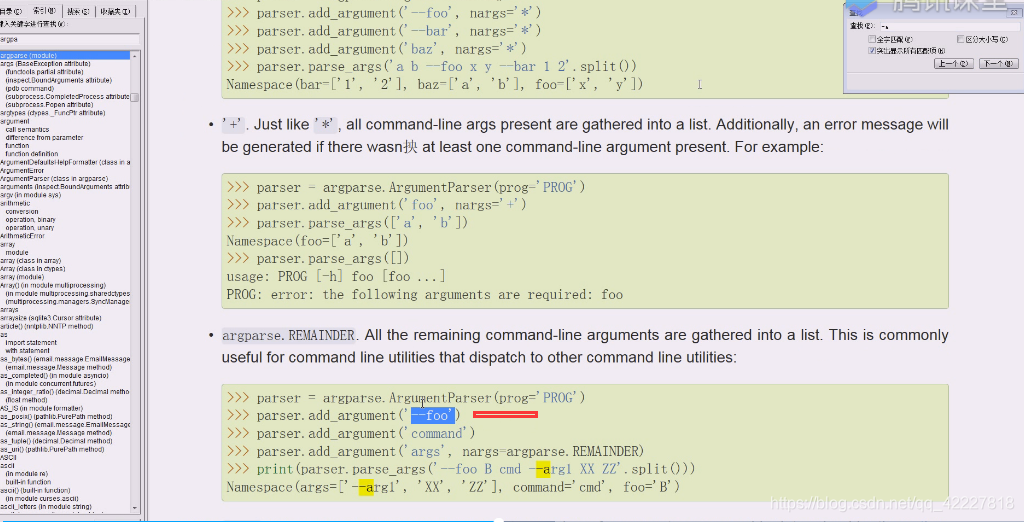
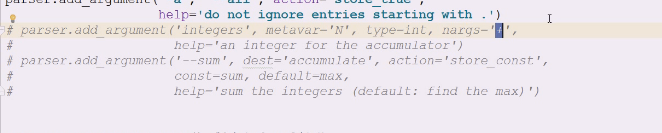
*nargs有0,1,2,可以写数字还可以写问号,
问号?告诉你是可有可无,0/1
+加号至少创建一个
星号代表任意个
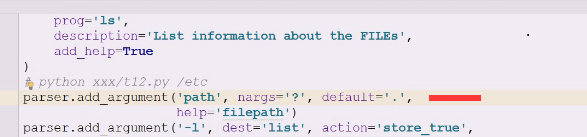
?问号,0或1个,没有默认用点号.代表当前目录
这种方式就可以拿到想要的,可以拿到路径,想用列表方式显示还是不是列表方式显示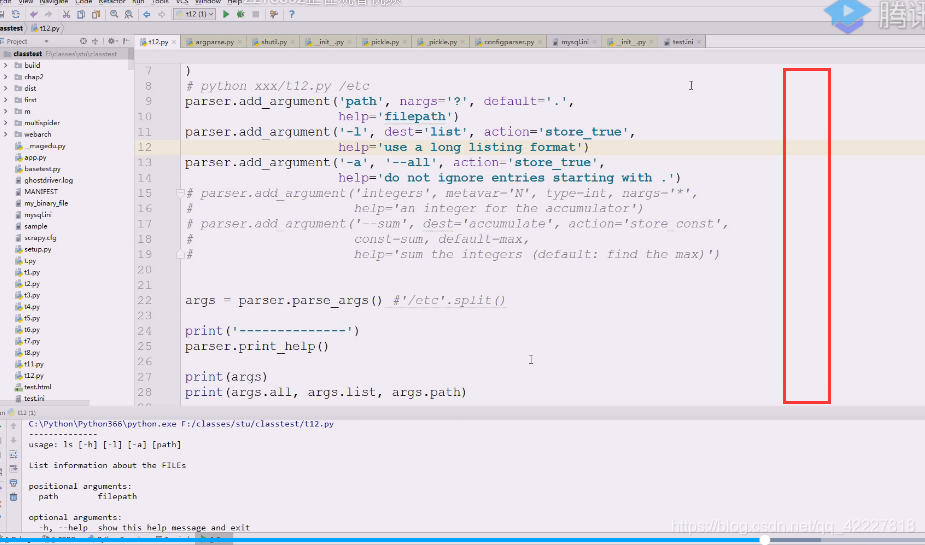
现在该拿的参数都拿到了,除了-h

下一步就需要写代码了,写函数,让哪个目录显示了
namespace就是个对象,只不过做了容器,所以叫名词空间(每个对象在python中都是有个字典,就在字典里 放属性,属性也是kv对,说到底还是用字典,只不过字典特殊,前后两个下划线,中间一个dict,dict)
可以理解为对象内部存了 字典,字典有kv对,k可以做属性名
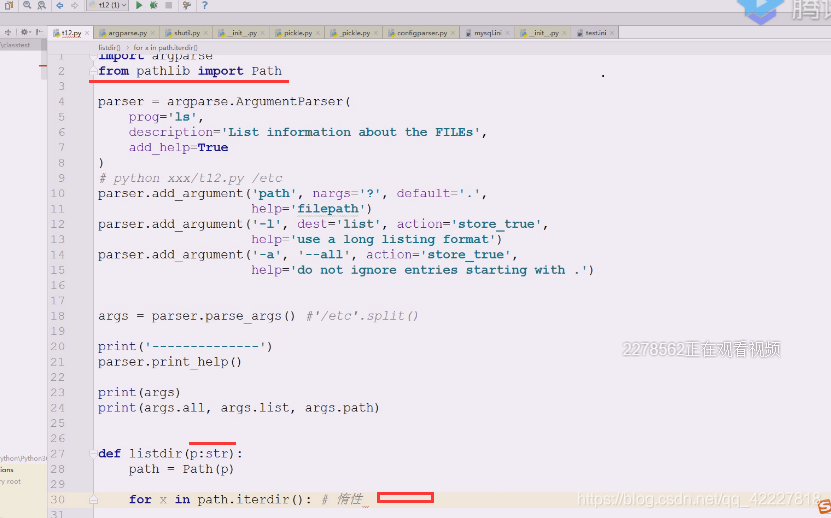
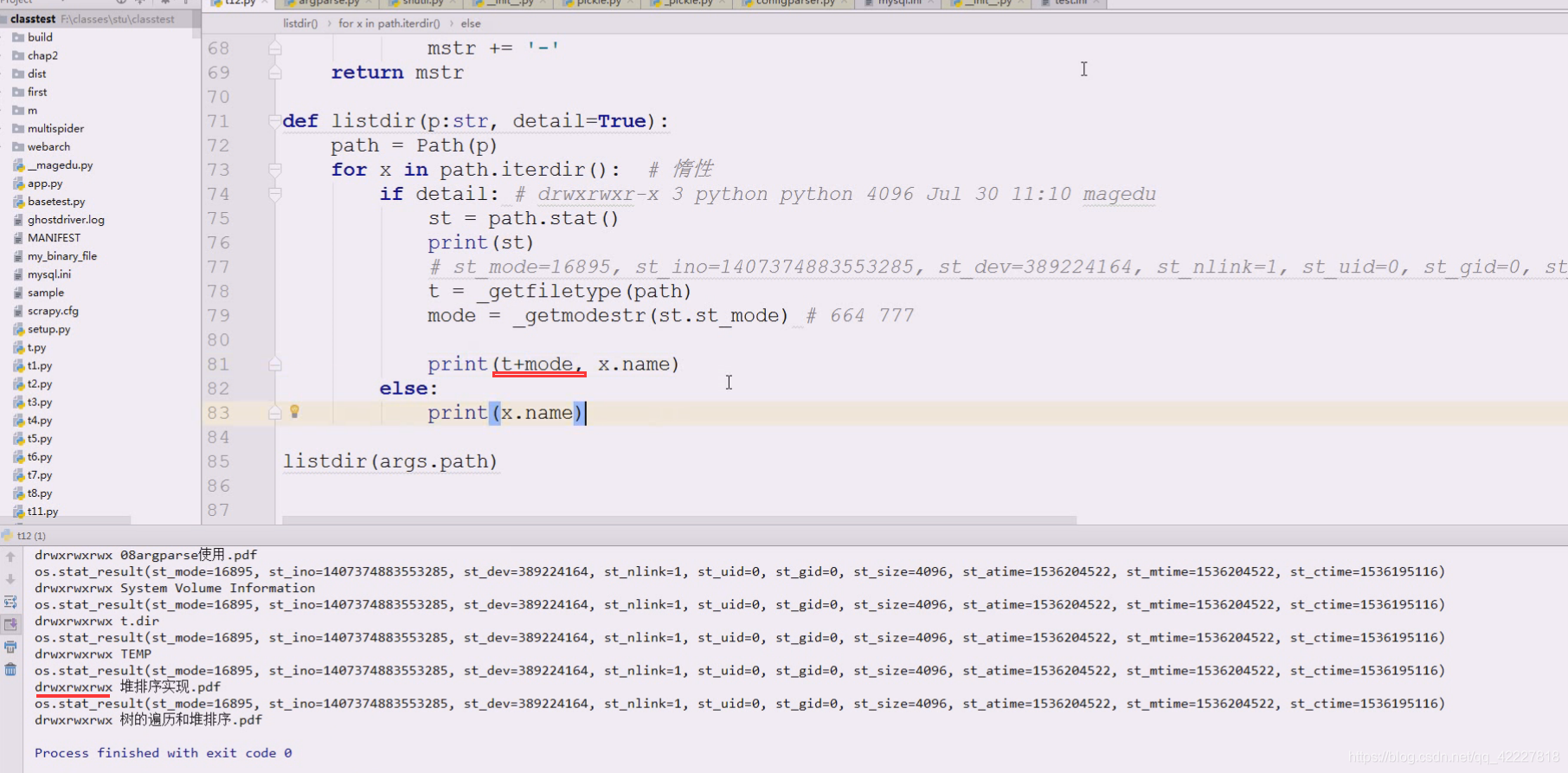
先解决如何把路径内容显示出来即可
os下的迭代方式,是立即返回一个列表
还有是用pathlib下面的,path对象提供 的item方法
定义listdir函数。提供一个路径p
iterdir是惰性的
传入一个值,调试看看
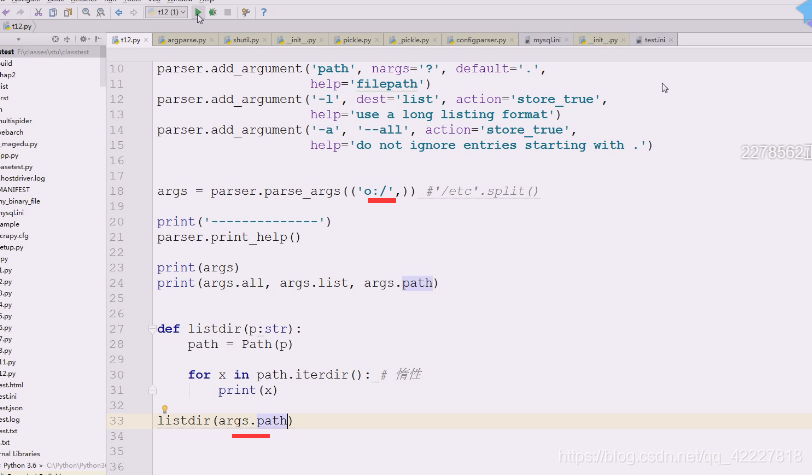
执行一遍,都拿到了
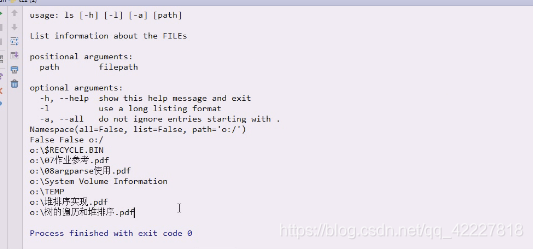
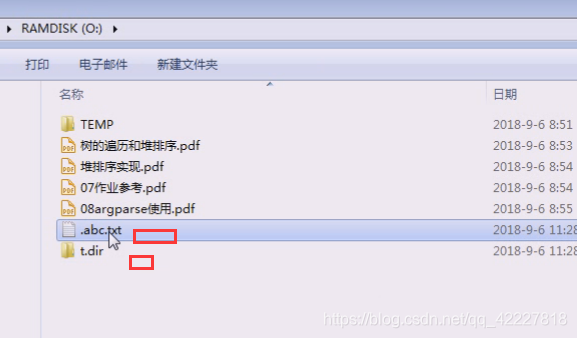
创建一些目录和文件
点开头文件.abc
t.dir
再执行一下都是有的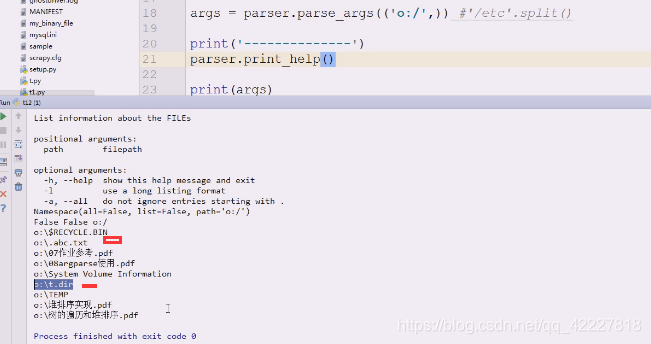
如果只想要最后一部分,一般不显示绝对路径,显示后面部分即可
如何取到最后一段,basename,
或者pathlib下的name,stem主干,suffix后缀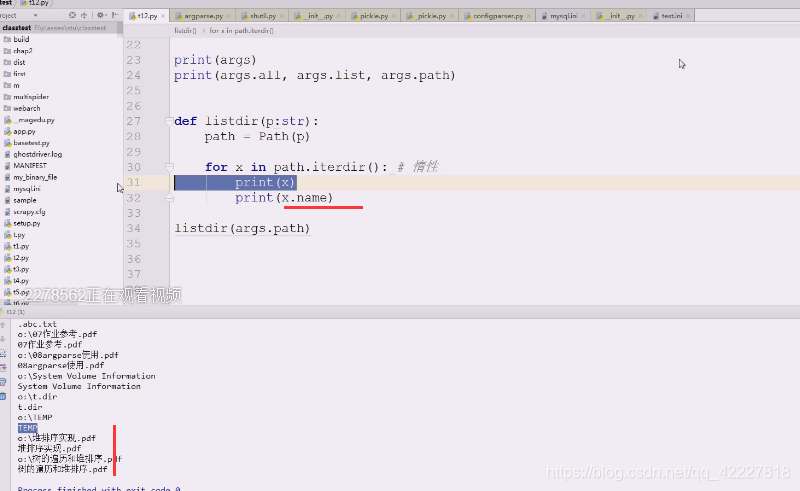
这就是拿到了自己想要的名字了,看看要不要加详细信息detail
这样就控制了打印的详细程度
在打印迭代的时候判断
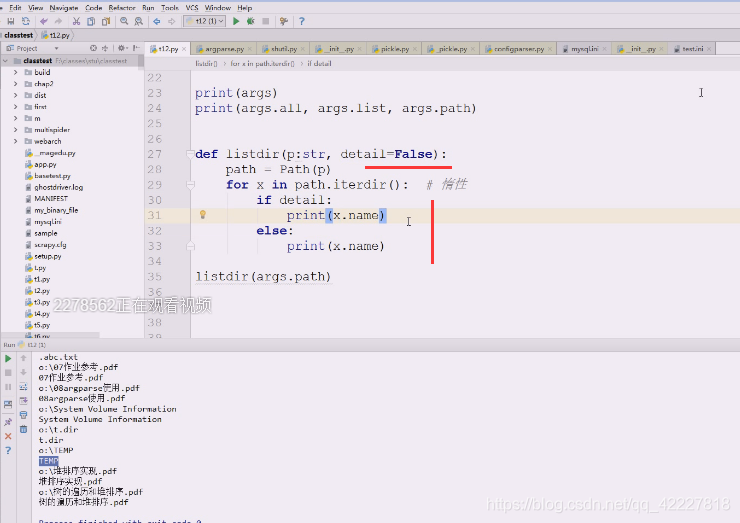
详细打就打印成这样

查看这个如何打印
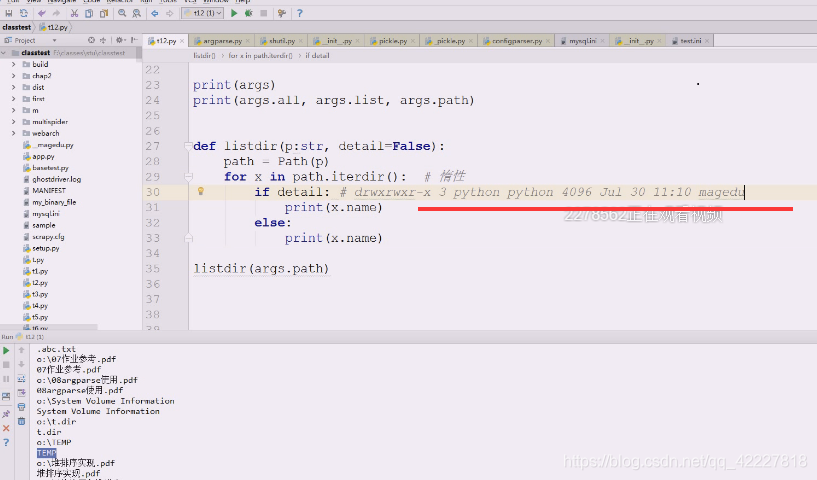
这些就是我们要解决的问题
这个是十进制的直接,转8进制就可以了
oct转8进制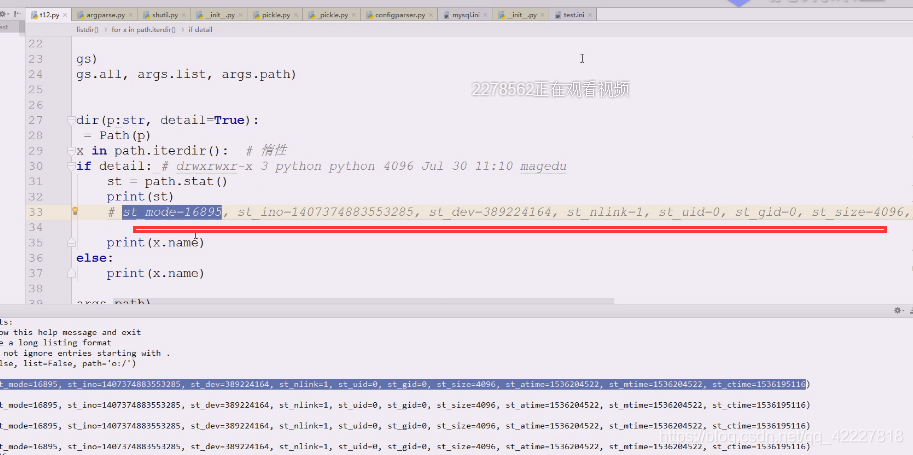
oct是转8进制,777这些就是我们想要的
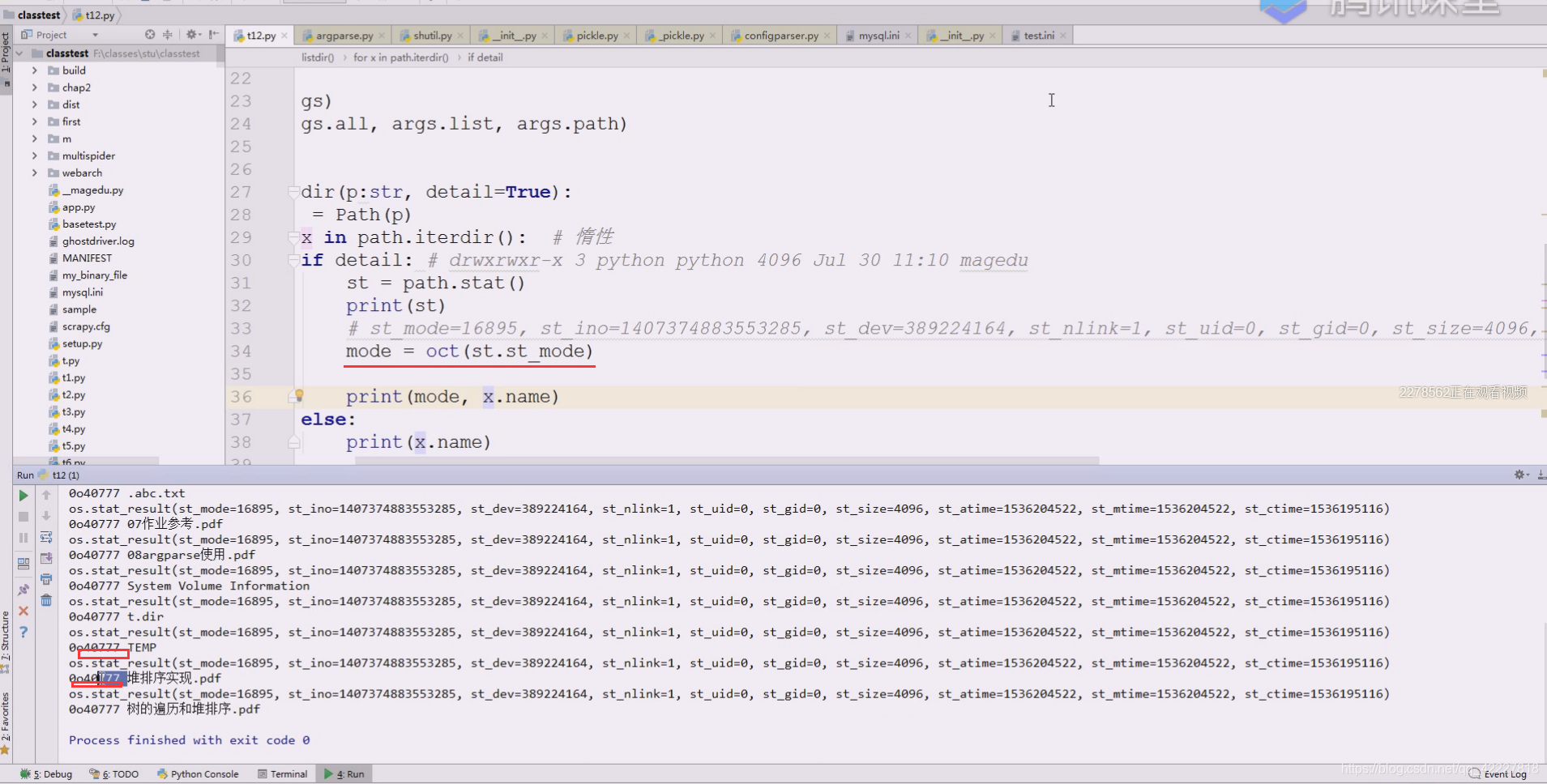
777怎么拿到就需要切出来[-3:]
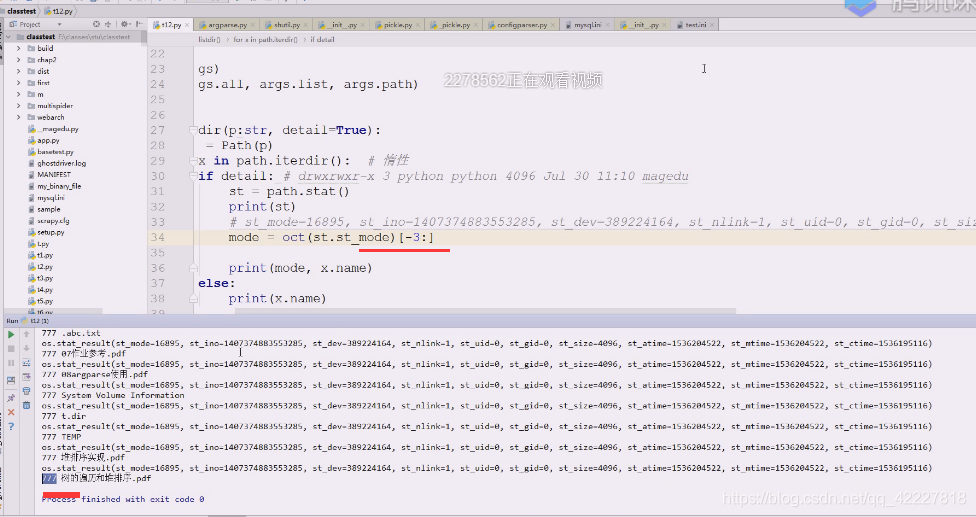
777如何转换成这种,d怎么来

可以自己先定义一个函数,_getfiletype(路径p)
最后做的都需要映射到字符串上去
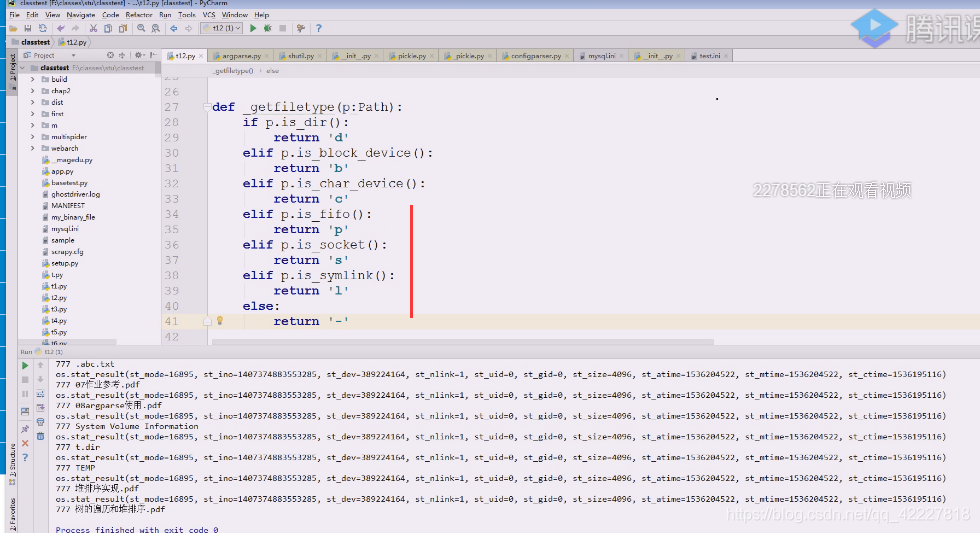
到下面的函数就把return的值拿进来
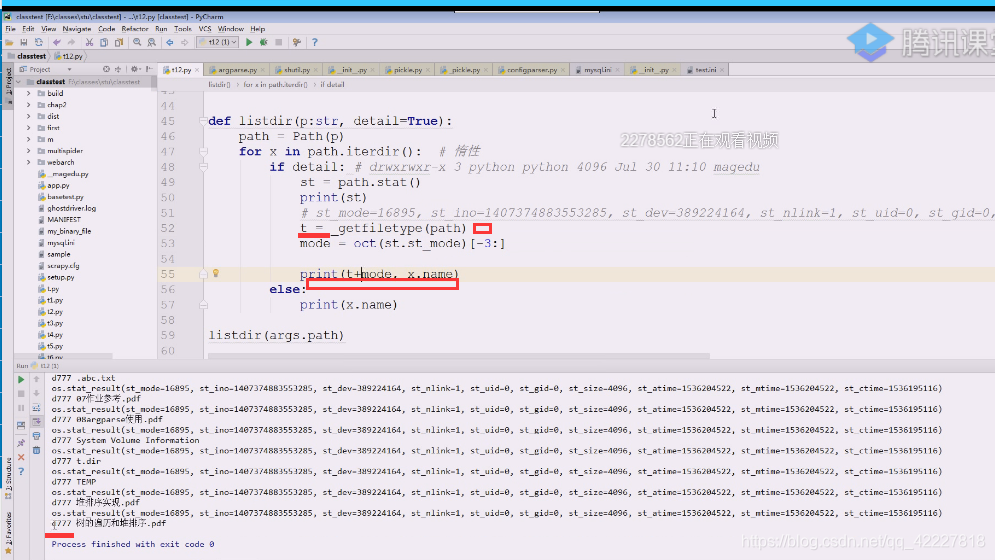
关键是777,664如何变换到rwx上去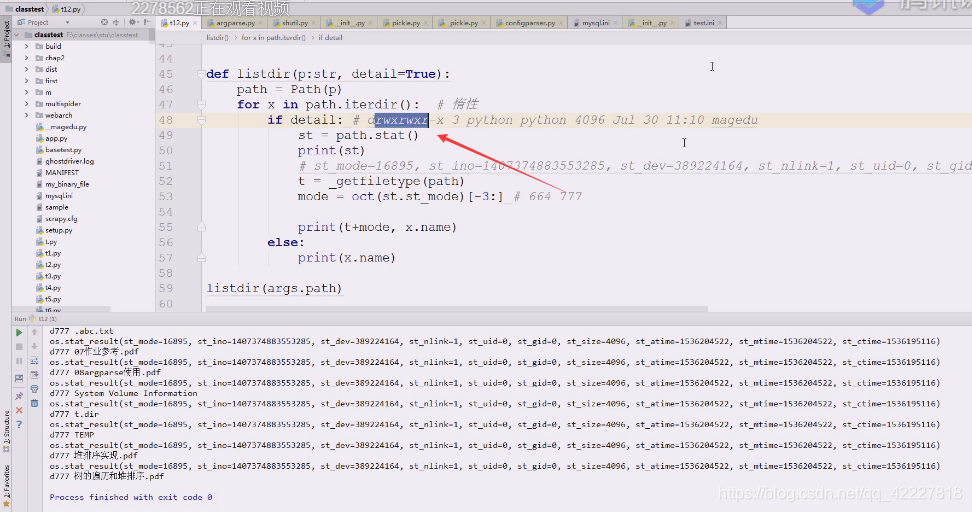
自己写一个getmode方法,(传入int)
mode 位于 0o777 对于8进制来讲只要后面的3个,其他都不要
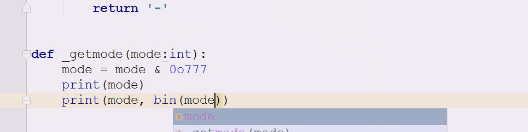
mode是一个整数,先这么写,因为现在getmode返回的是none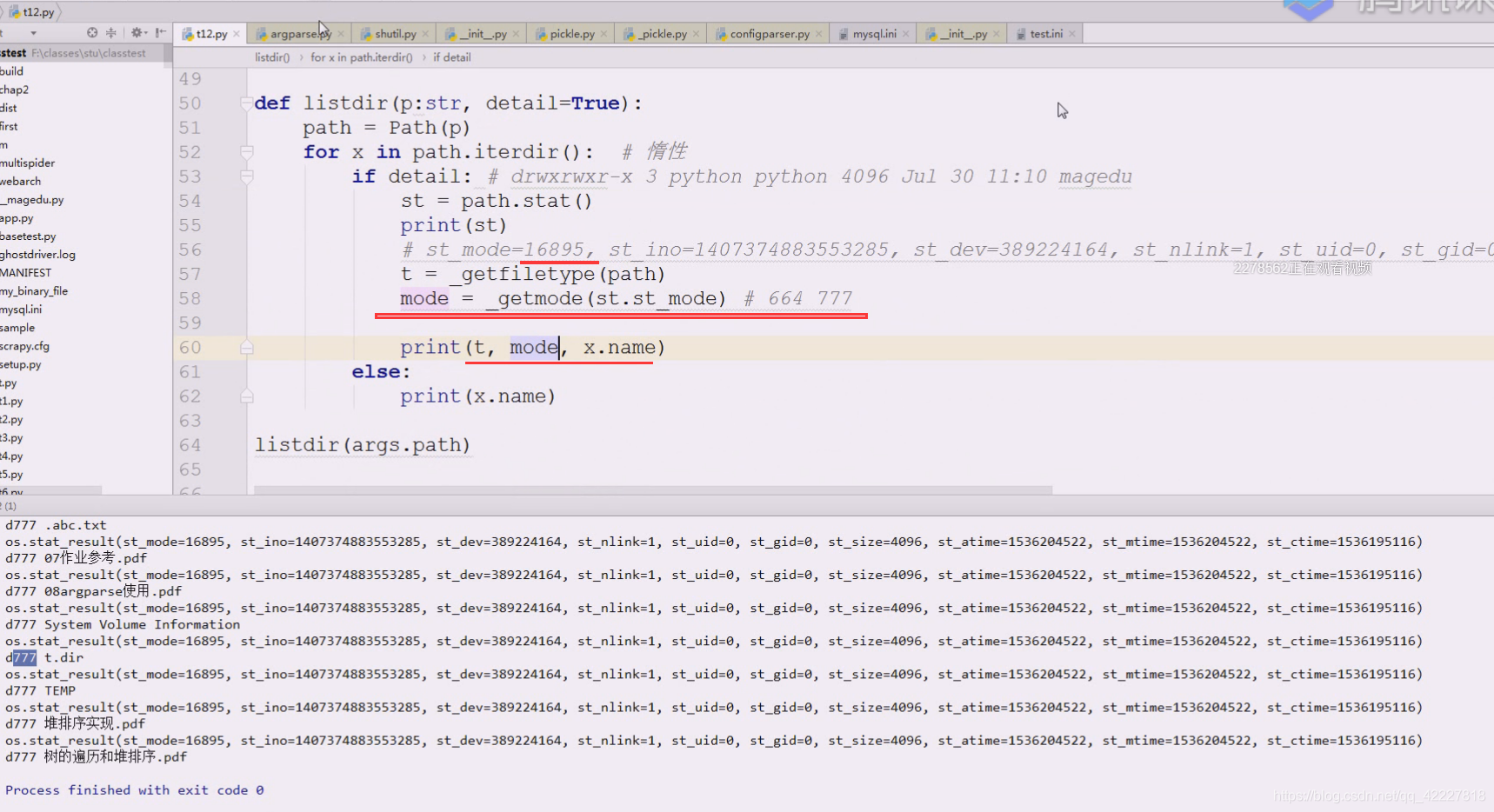
511 0o111111111,9个1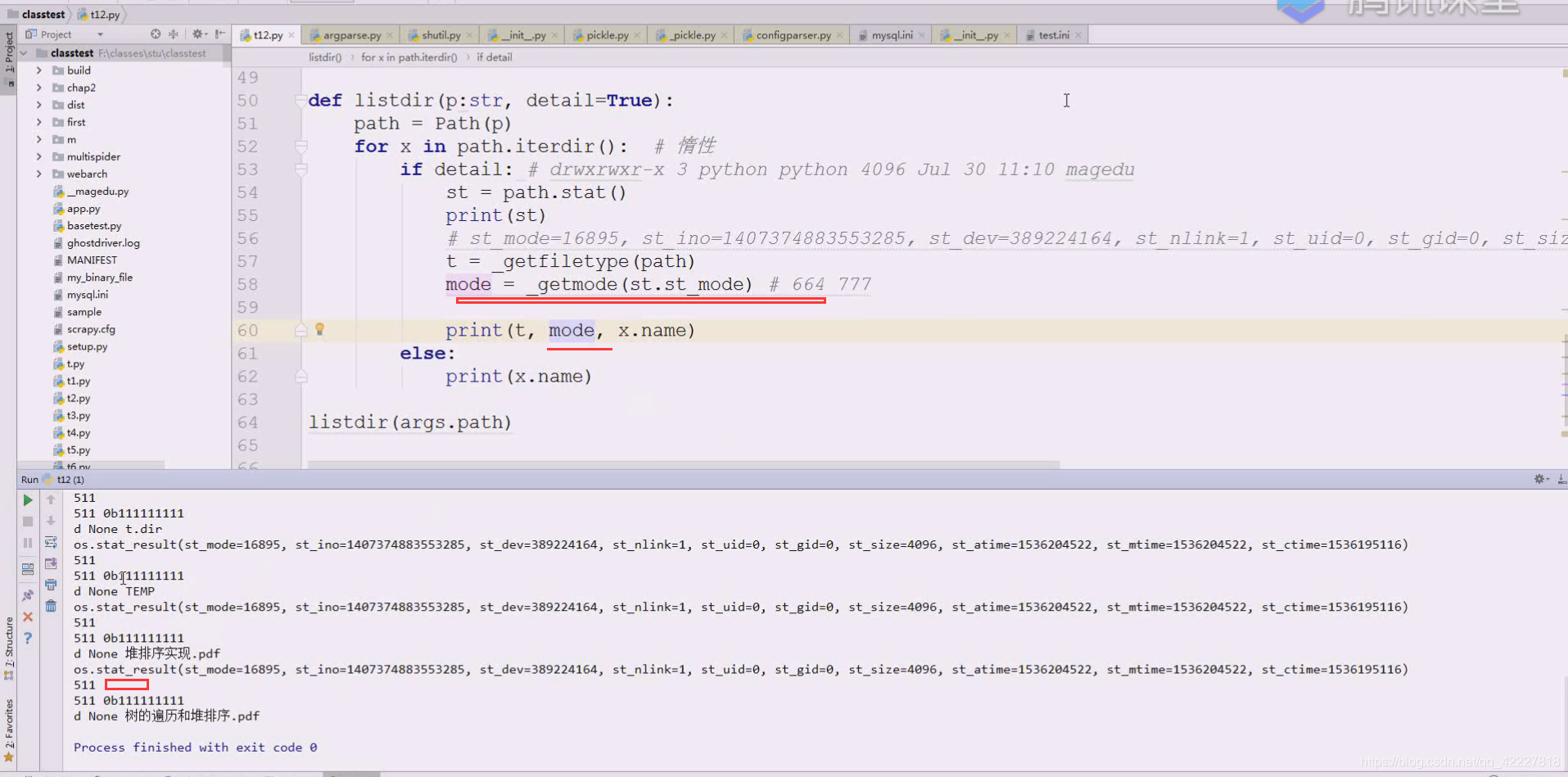
0o111111111是字符串。管你前面是什么,只要后面的9个,这样就需要加一个权限子串
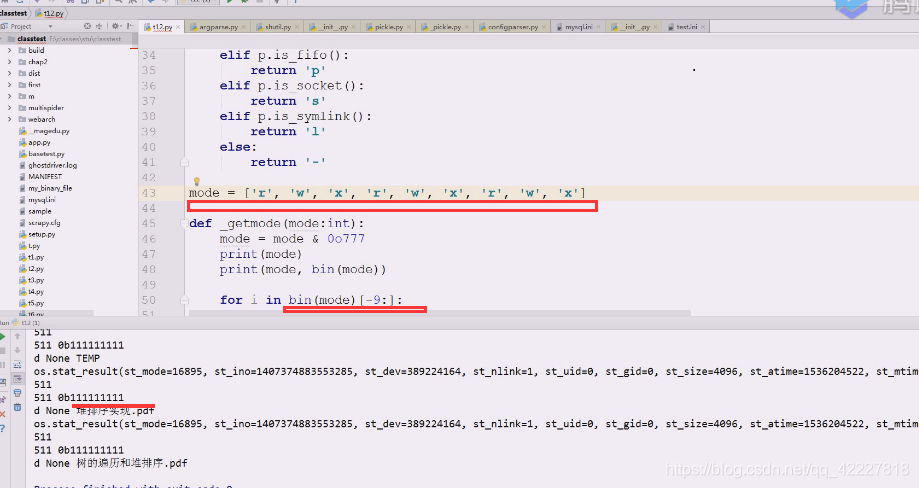
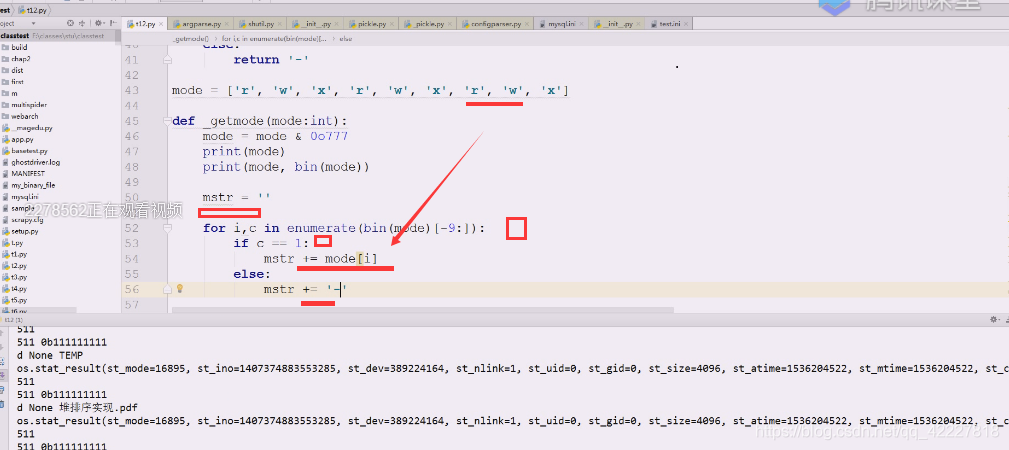
enumerate需要取索引 [-9:]这是一种思路
如果取出来的位置是1就需要给权限,c==i
就要到mode里找权限,加进去
否则mstr就加个’-'即可
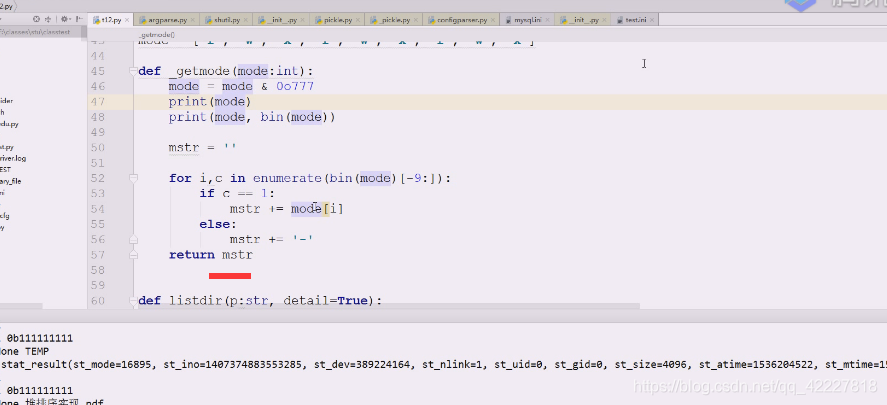
**最后return即可,但是0b有可能忽略,前面补0即可,凑够位
**
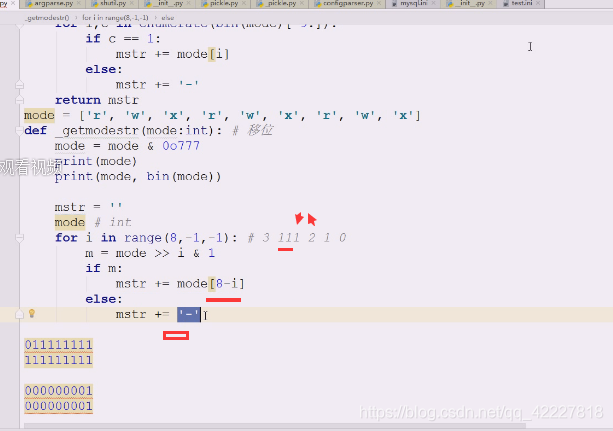
这是一种思路,还有另外的思路,
数字依然是int
试试移位
8-0是9次,所以8,-1,最高移几位需要控制一下,
如果有三位111,如果最高从3开始,就都移完了,要从2开始,移完第一个就是1或0
把mode右移指定的个数 与& 1(除了最低位,其他全是0,因为不管怎么移都要最低位)
位于之后就得到一个值
就需要用这个值来判断 if m:要么1要么0
**
**
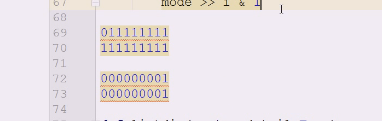
1111111111
移1位是
011111111
移8位
000000001
最后一位是几就是几
把上面注释掉,不用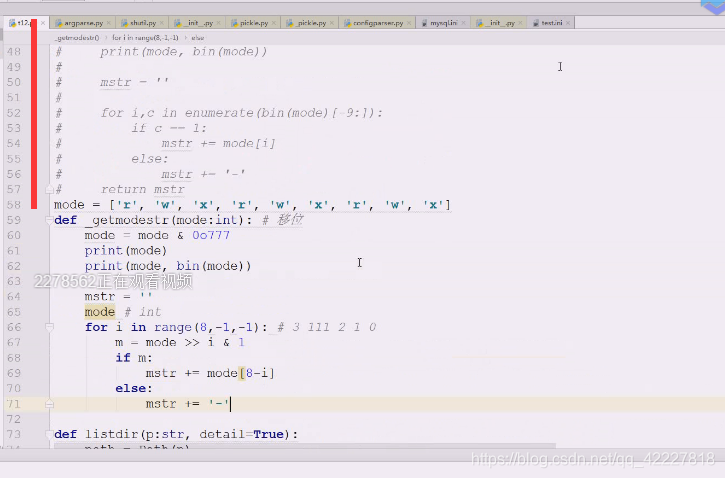
mode就可以通过索引方式得到了
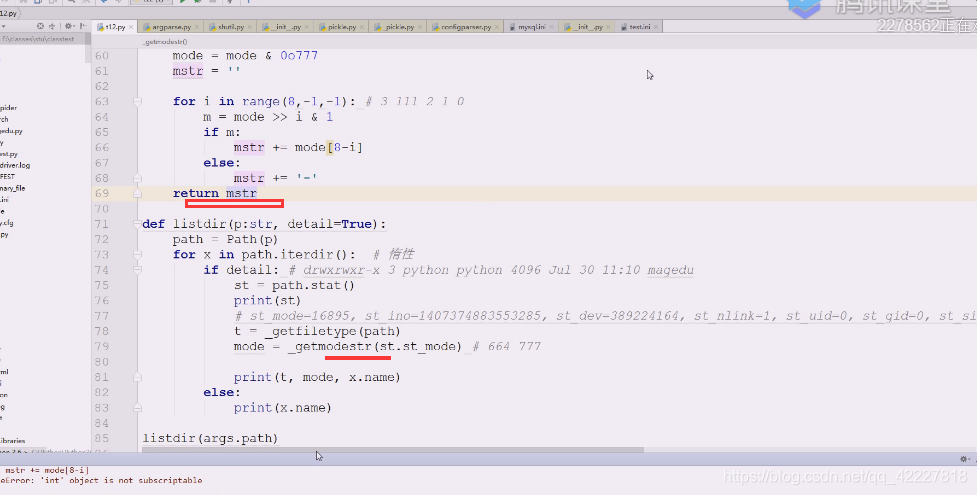
重名了
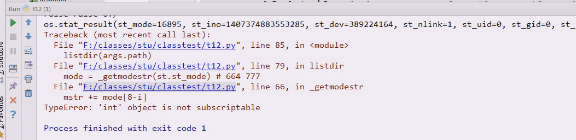
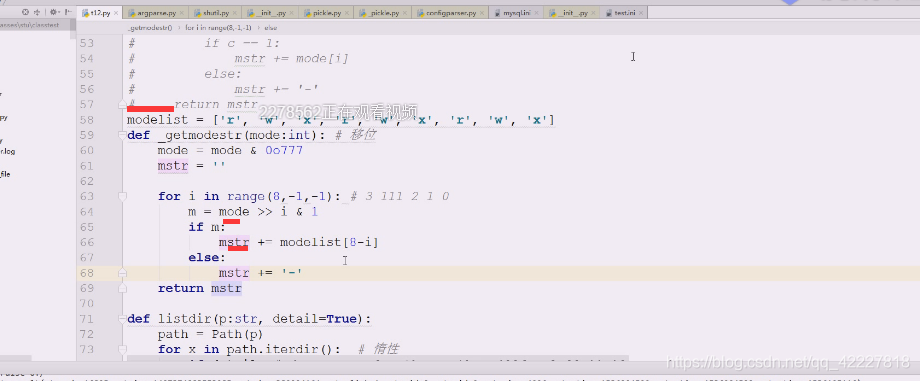
这样就成功了
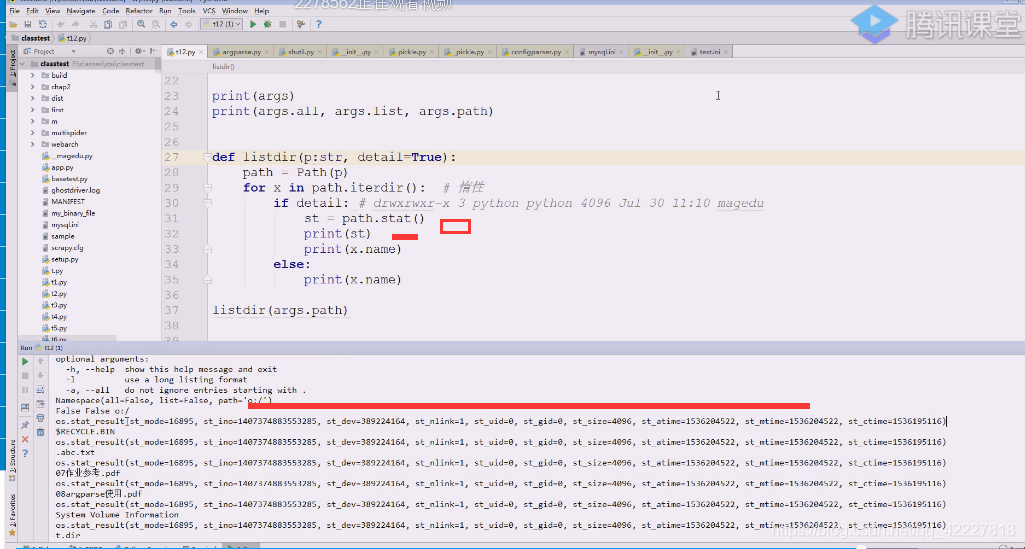
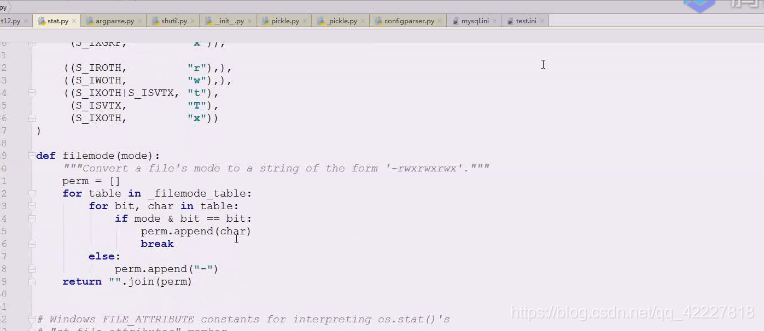
有个方法比这个更好,stat
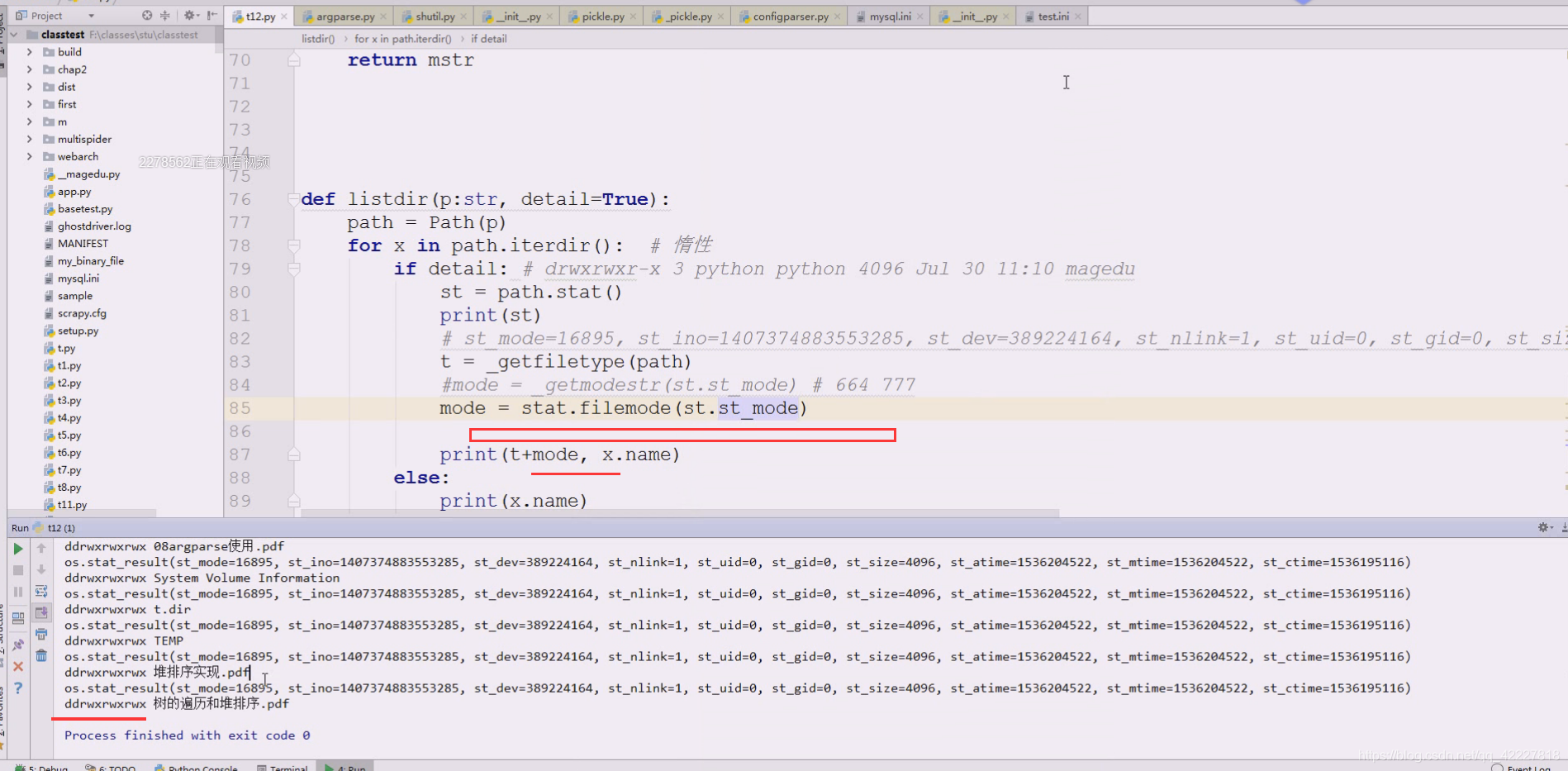
stat的代码跟我们差不多


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









