







 本文深入探讨Python中os和shutil模块的功能,包括文件和目录的递归操作、文件拷贝、权限设置及元数据处理。通过源码分析,揭示了如何在不同操作系统间高效地管理文件和目录。
本文深入探讨Python中os和shutil模块的功能,包括文件和目录的递归操作、文件拷贝、权限设置及元数据处理。通过源码分析,揭示了如何在不同操作系统间高效地管理文件和目录。
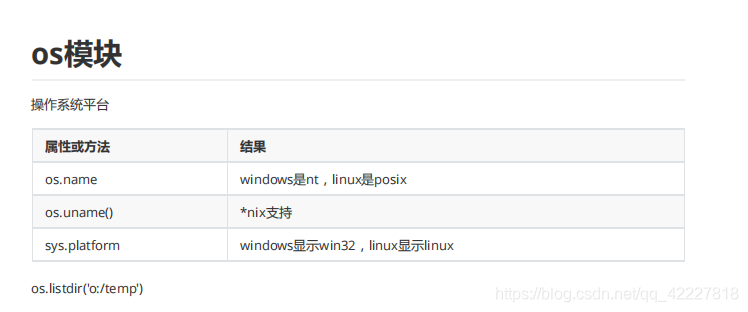
os模块下的path模块,path模块就是.py文件,里面定义了一大堆函数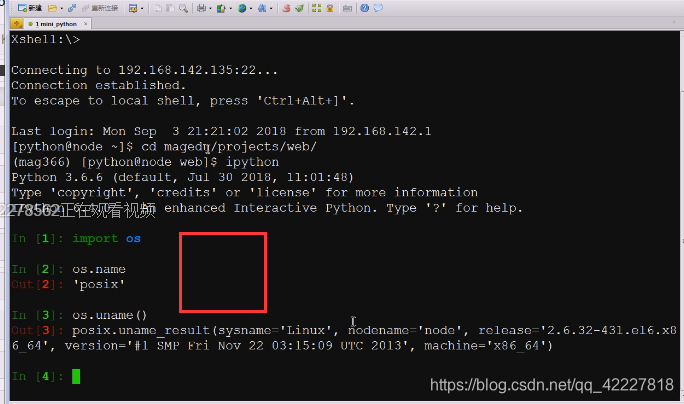
windows不支持uname,这个是纯粹 用在linx上的
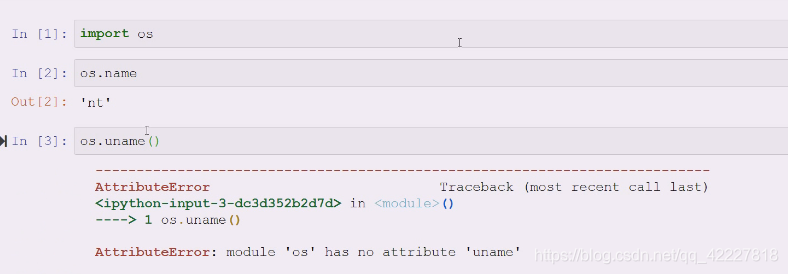
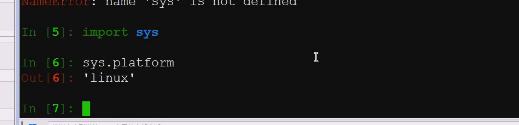
有时候虽然python尽量抹平了不同系统的差别,但是有时候还是需要做一些判断
用path对象去迭代的时候也没有递归,默认情况都不会递归,因为深度太深就恐怖了
递归就需要你判断是不是目录,如果是就继续进去,如果不是就进去,由你自己完成
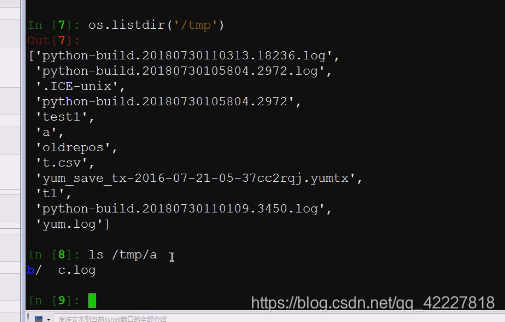
这个经常用,如果写了字符串,就需要用这个来列出路径下的文件内容
现在去迭代目录的话,实际上是用os.listdir这个方法去立即返回下面内容也是可以的,或者用pathlib下的pathlist构建一个目录对象,在这个对象里去迭代这个dir,只不过是惰性求值
生成器是必须掌握的一个技能
在python3种是鼓励使用装饰器,生成器的
python建议,如果直接使用os模块,如果没有用到,os模块想要导入文件,都推荐使用内建函数,内建函数一半都是要经常使用的函数

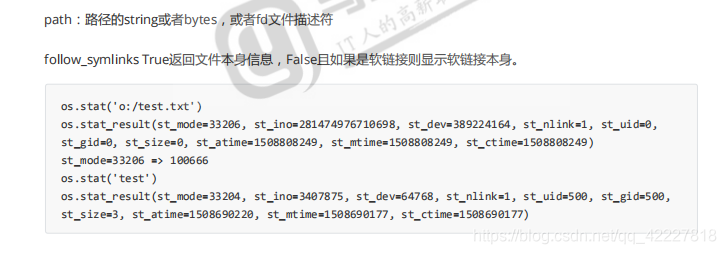
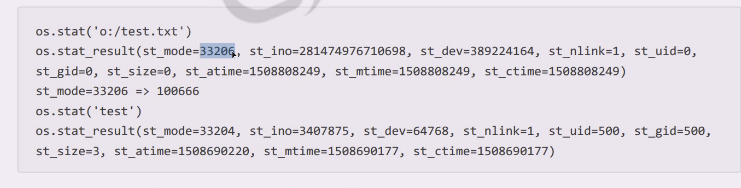
path这块可以给stat命令,看看对于stat信息,path对象.stat这昂的方法获取信息
stat信息软连接可以看两种,看软连接本身加l,不看软链接自动指向原来的文件
path的类,底层就是用的os里面的东西
os内部就是调用的操作系统功能,os是跟不同操作系统打交道的,不同系统差异由os模块和子模块抹平

本质上是调用的linux的系统调用,lstat的参数和stat的类似
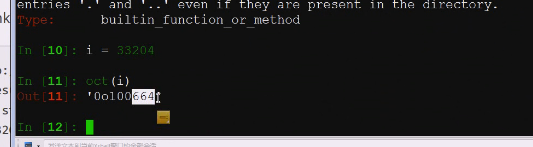
这是一个十进制,前面说错了。写的0o,十进制直接用8进制展开就行
最后是664
可以把文件的权限,属主属组切换一下,这些命令都是和操作系统的权限系统相关,权限不够想改是改不了的,在Linux下,大多数文件都是跟属主属组相关,一般都操作不了
权限尽量最小化
操作系统的命令只不过是别人写的程序,命令自己写,就由提供的编程接口,这个接口叫系统调用,系统调用是c语言写的,python把这些c语言写的封装起来,就变成现在看到的IO模块,sys模块,所以用起来是比较方便的
window和linux基本相通,因为都脱胎于unix,(mac,windows,linux)
用这种os模块,os.path这种始终变扭,不方便,就有shutil这种东西

shutil前面,sh代表shell(跟操作系统打交道),util工具,提供了非常好的方法
python的标准库已经非常全了,经常要用的10几个库,每个库掌管一个方向,到了企业,标准库封装太原始 了,就可以用到第三方框架,打开这个框架看源码,里面打开都是标准库,是做的标准库封装,只不过给你封装更好用,标准库依然是学习的重点
一个源,write往里面写就可以了,源,源源不断地去读数据流,目的地不停地write进去就可以了,最后用完把两个都关掉所谓的拷贝是从一个数据流来了,往另外一个数据流写就可以了,但是这样的操作可能丢东西了
拷贝最基本的要求是两个数据应该一致,两个字节流最后需要保证一致,但是放在磁盘,磁盘一个扇区有512字节,所以是散着放的,所以磁盘叫随机读取设备,下一个扇区在哪靠磁头跳转
磁盘光盘都是随机访问的(磁头反复绕,效率低,但是有肯可能同时访问A文件和B文件,这样就比较方便,有好处有坏处)
现在的问题是读取了这个文件的字节流,写到另外一个文件,两个字节序列应该是一样的,但是文件信息没有,原来文件的权限,元数据没有拷贝
(元数据源码实现也是先拷贝内容,再按照原来的修改元数据
shutil主要学习就是copy方法
src和dest文件名即可
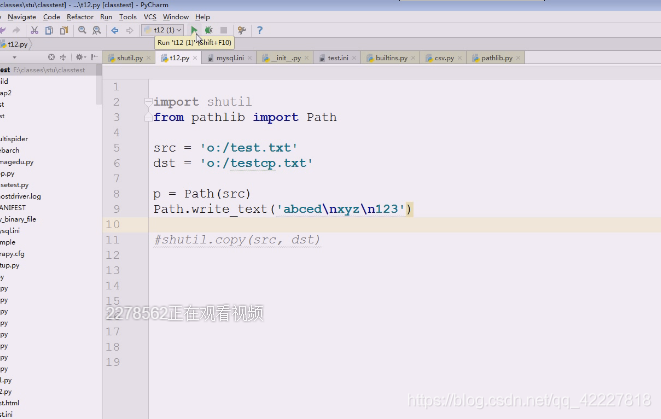
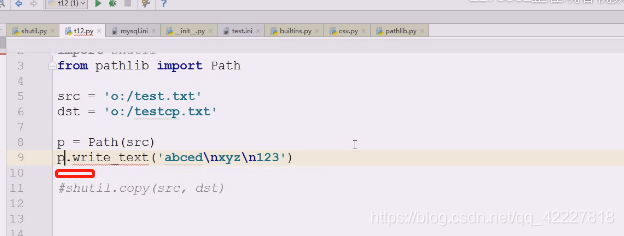
创建了一个文件
拷贝一下
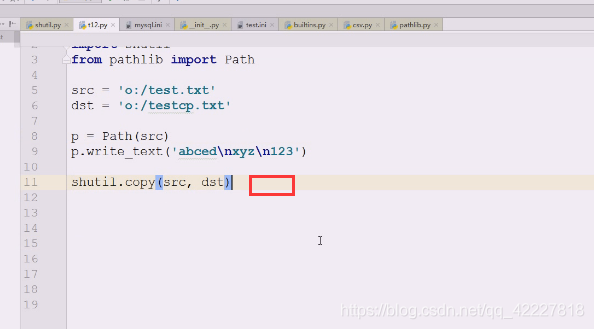

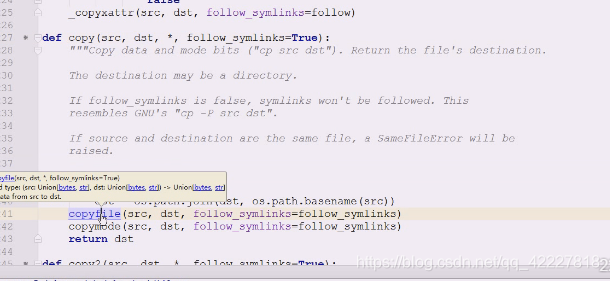
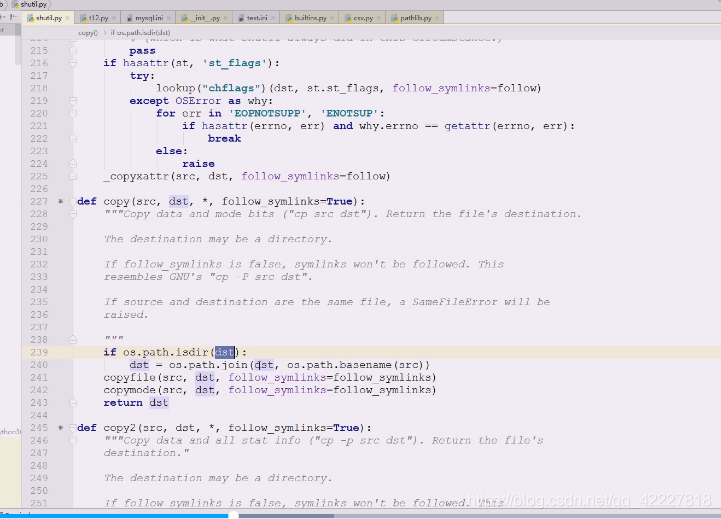
拷贝会拿一些基名basename,src的基名,假如拷贝源文件和目标文件
首先会copyfile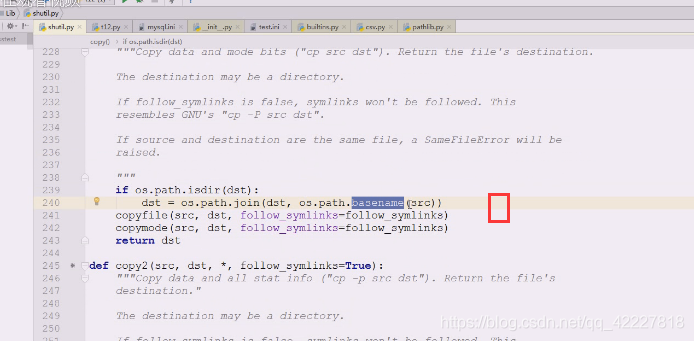
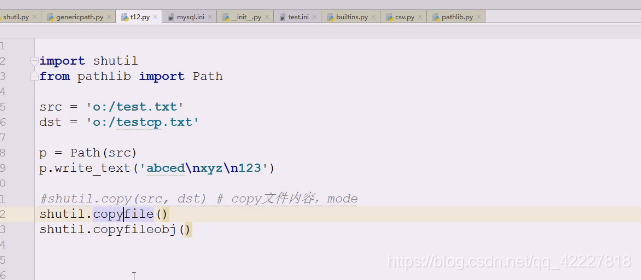
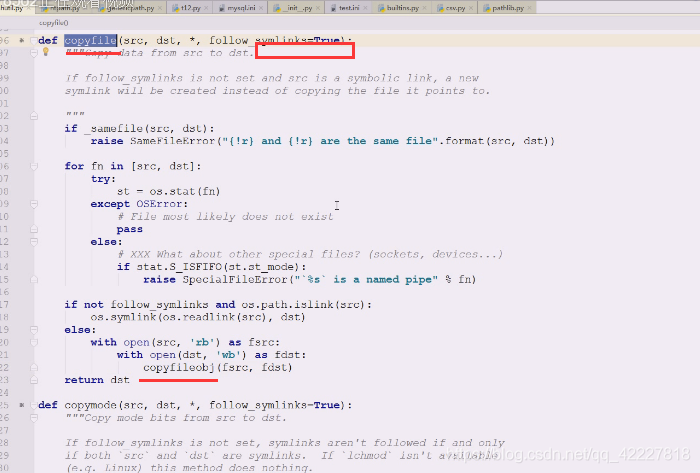
查看copyfile做什么事情,从数据从源到目的拷贝过去
看到这个src,去取一下,,然后查看是否出错,OSError。ISFIFO
如果不是软链接,要不要跟的问题
两个文件打开,源文件和目录文件
字节读和字节写
转成文件对象,最终调用copyfileobj
copyfile做文件是否相同的比较,然后做一些类型文件的判断以及软连接的判断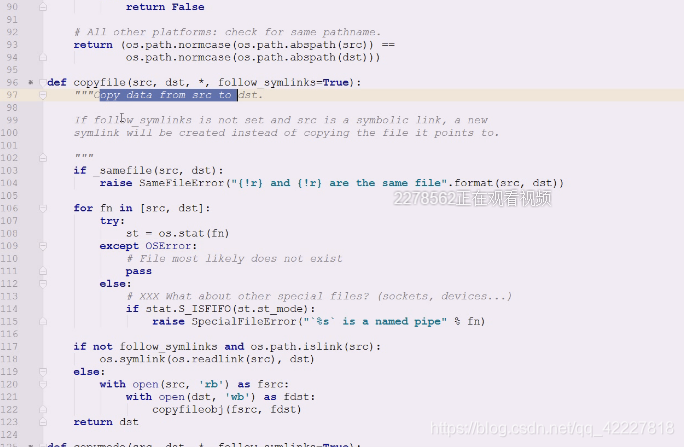
转到copyfileobj,文件对象,刚才用两个位置with语法,出两个文件对象
死循环,怕一下子打开没这么大空间,从源里面一次读16K,缓存起来叫buf,读到内存中
如果能读出来就进不去,,读取一般都是512的倍数,就写
超大文件就是一批批读

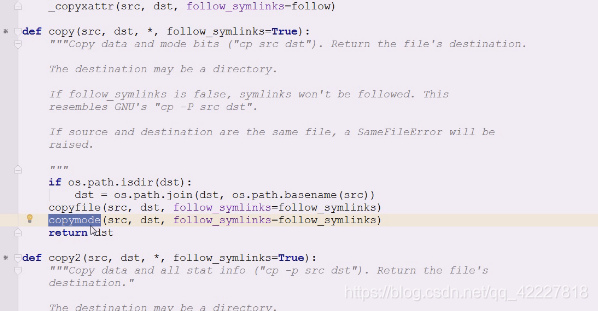
现在copy其实做了两件事,
拷贝文件内容,
copyfile会做文件相同的比较,做一些软连接的判断
如果说os.path下。有samfile,就直接调用os.path。samfile判断(src,dst)是不是同一个东西,是用在mac和unix上,
然后如果目标的src。和源的src目录一样,就是同一个文件
这个函数就是判断是不是同一个文件,如果os.path下有samefile就调用samefile,
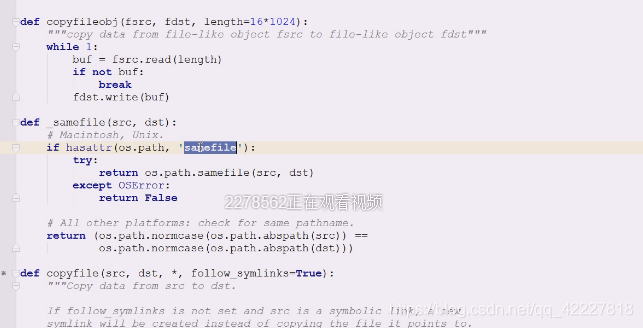
判断这两个是不是一样的,就读取了这两个文件的stat信息,如果这两个信息indoe和dev设备信息相同(windows么有inode,所以之前的函数写了mac和unix,也就是遵从posix协议)
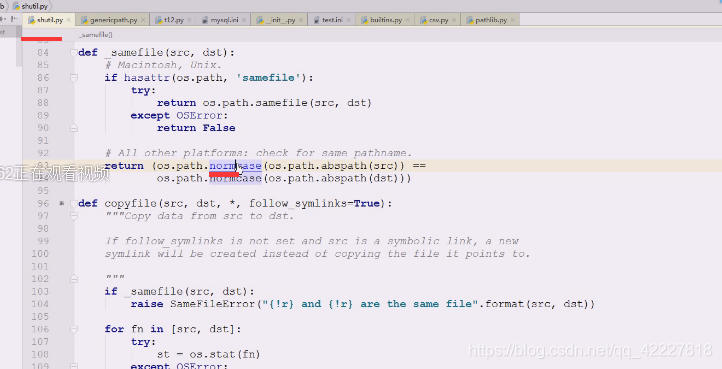
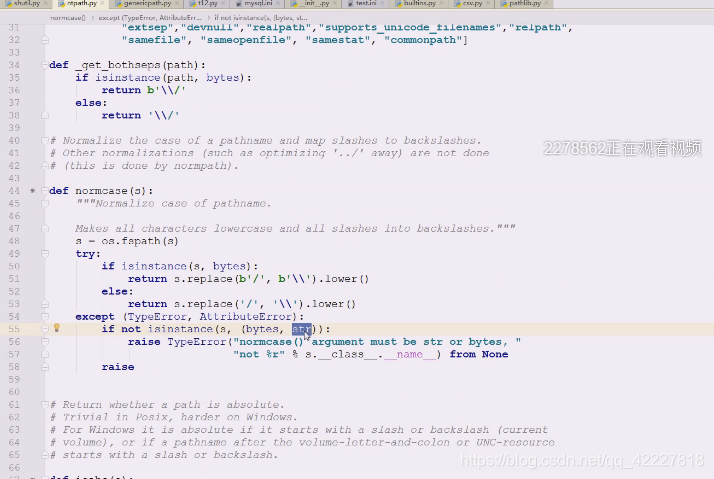
看下normacase怎么做
其实就是做一些大小写的问题
要么文件名相同,要么比较元数据信息是否相同
windows是不缺分大小写,linux下字母是区分大小写的
copyfile会进行判断,以及后面确定是否是软连接,copyfileobj会直接进行拷贝
copy里面还有东西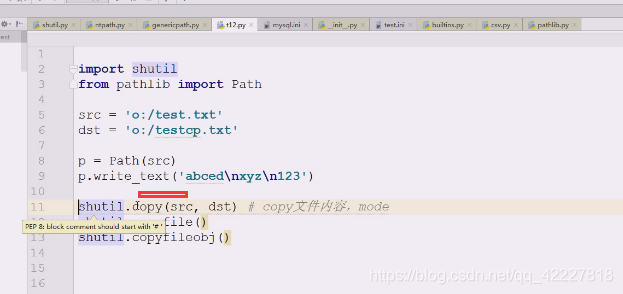
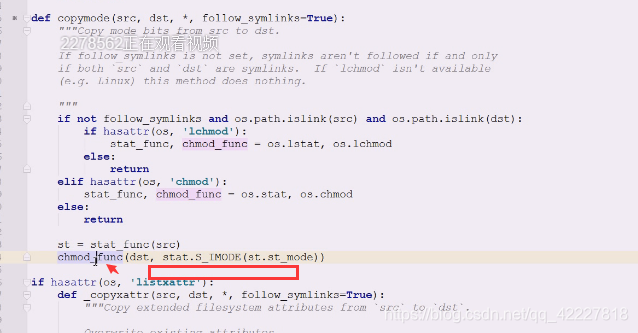
copymode如果有软连接,,
然后判断操作系统,如果平台是有‘lchmod’这个东西,如果有,不同的os操作系统对应的是有差异的,如果操作系统支持chmod,在os里就找到OS.chmod,和os.stat这两个函数扔出来,只是扔出来,还没有调用
l这个东西是专门给链接服务的,如果没有就直接return出去
然后判断有没有chmod,,没有return出去
下面的st=stat_func(等于调用os.stat/lstat)拿到stat信息,之后,扔到st_mode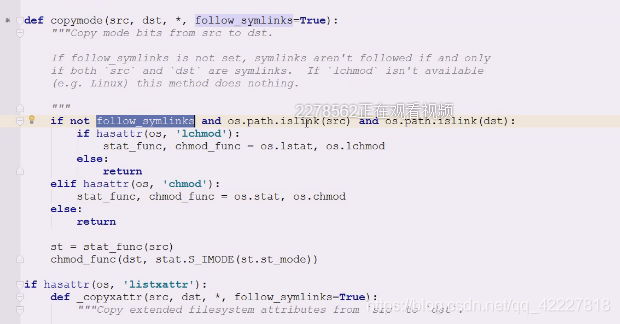 拿到stat信息,之后,扔到st_mode
拿到stat信息,之后,扔到st_mode
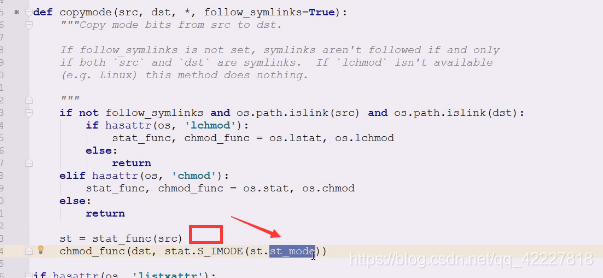
相当于拿到的整体stat信息取 ,st_mode,拿到这个信息交给s_imode,chmod_func函数去(改变目标dst的mode即可) 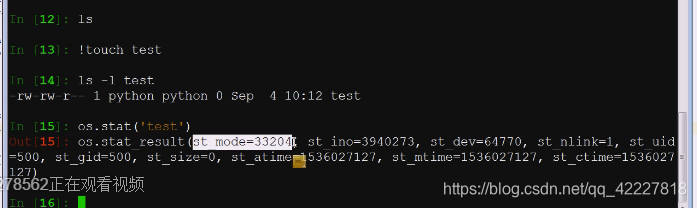
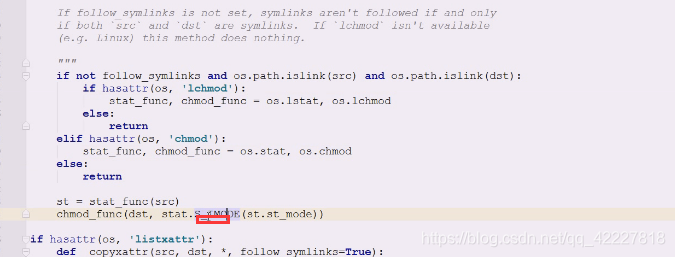
查看s_imode,移位运算经常做位于,4 给7,代表前面什么不关心,后面给什么就是什么
mode整数值 &位与 0o7777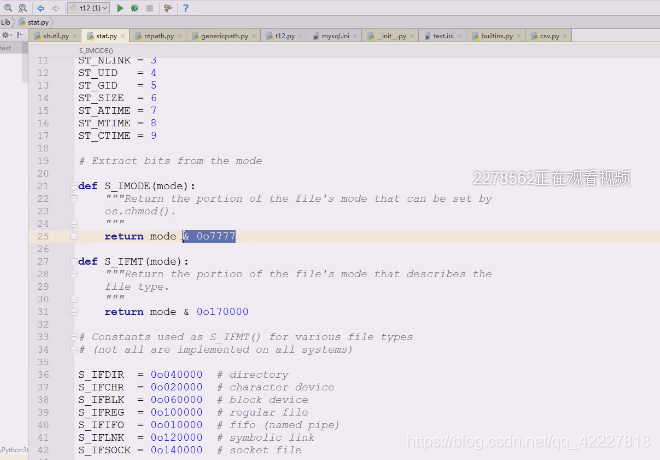
pass,具体应该是需要看c源码
copy是拷贝两样东西,文件内容,和mode元数据
copyfile只解决文件拷贝问题
文件权限没变,就是访问时间变了
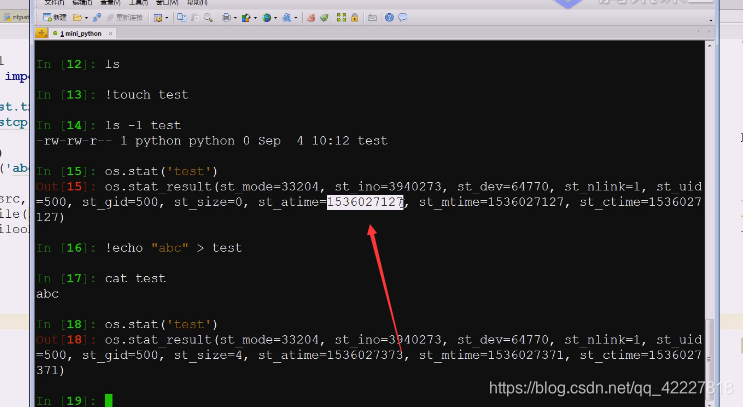 准备开始拷贝,创建文件,现在权限是775
准备开始拷贝,创建文件,现在权限是775
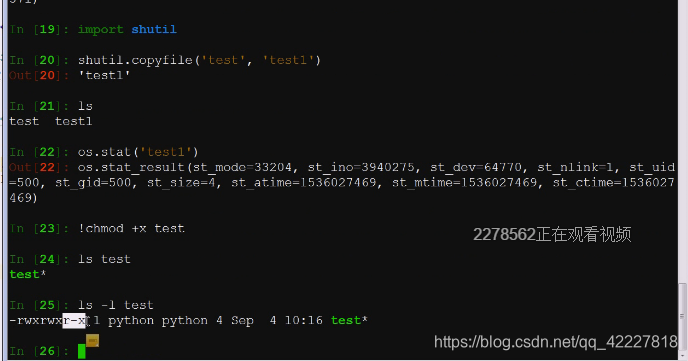
拷贝的时候确实是观察源码一样不带mode,使用默认的mode创建
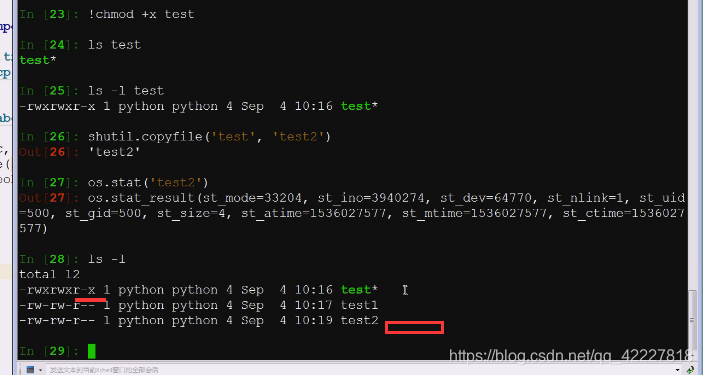

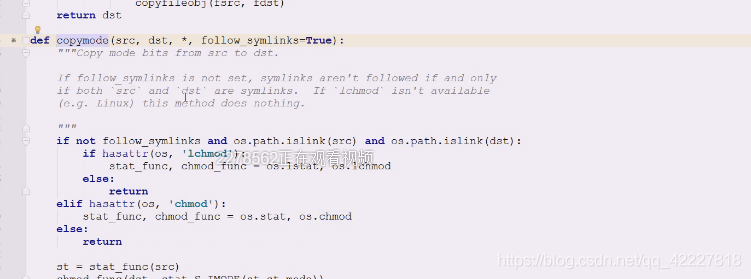
查看在哪里调用copymode,跟copy命令里的文件名就可以,直接使用
使用copymode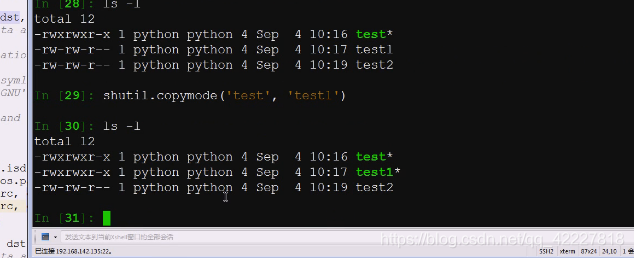
这就是copymode和copyfile,copyfileobj是起两个位置,把两个file对象传进去,下面就是拷贝了
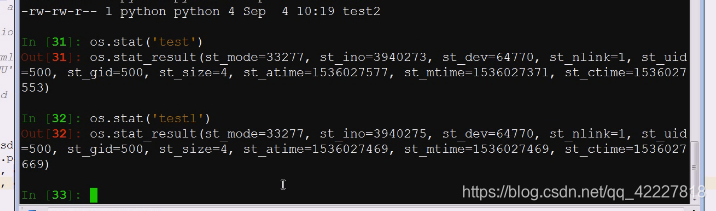
拷贝一定是两个文件,所以inode肯定不一样,所以对于我们来说,文件是有副本的
copy的过程相当于copymode然后是copy文件
能不能把时间戳弄成一样,这就需要copy里面的其他功能
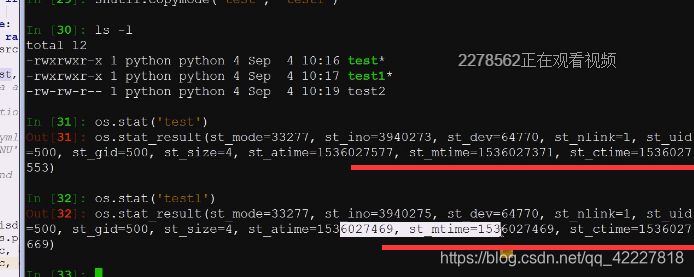
copy的第二个版本
第一部分拷贝文件内的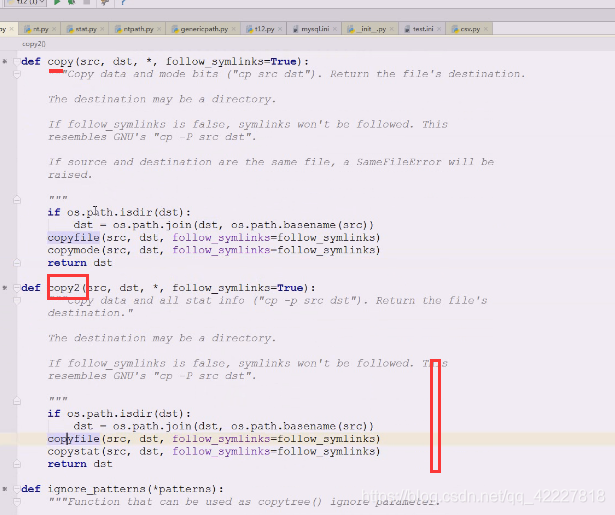 第一部分拷贝文件内容
第一部分拷贝文件内容
第二部分拷贝整个stat部分
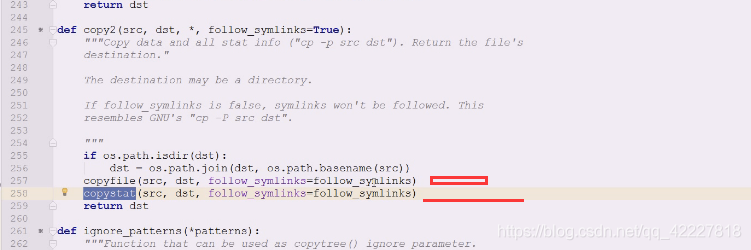
不单copyfile,还有mode,还有stat
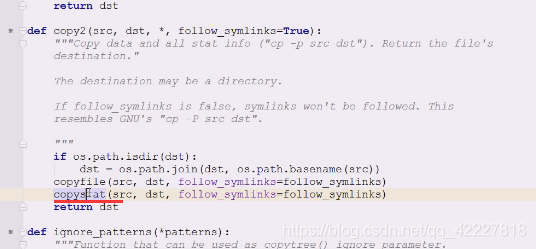
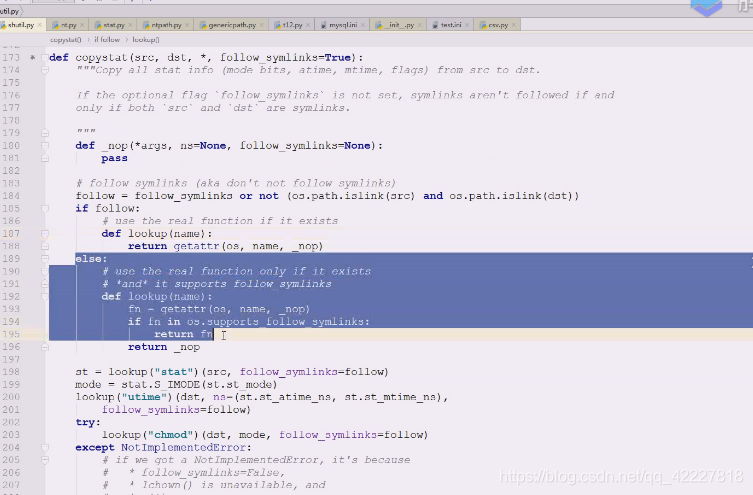
核心代码,找一下stat有没有,然后把stat信息拿出来,然后mode信息单独从st提取
然后chmod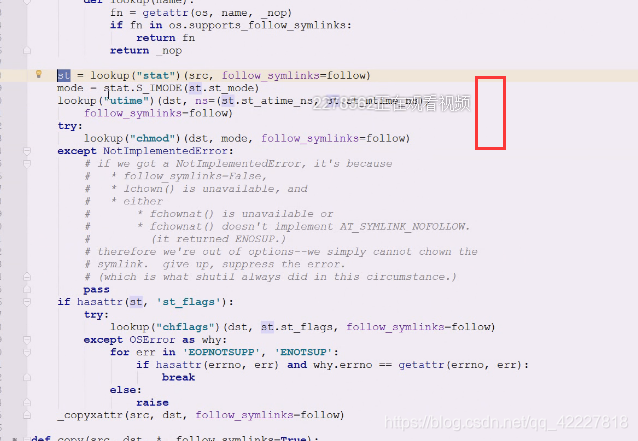 从源地址到目标地址拷贝些属性,最后还要chmod,因为chmod是个单独命令
从源地址到目标地址拷贝些属性,最后还要chmod,因为chmod是个单独命令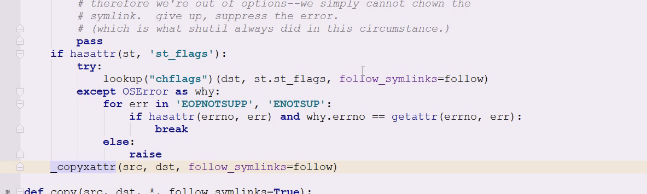
所以这个函数我们也可以单独使用
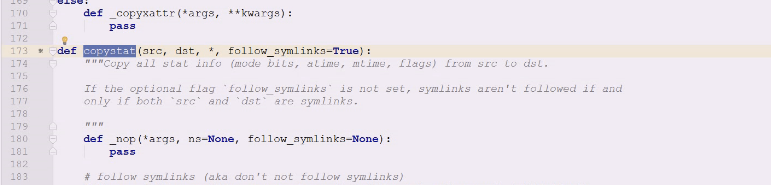
accesstime访问时间和mtime是一样的,ctime是你只要修改元数据,这个数据就一定会动,一般atime和cmtime时间一样就代表拷贝成功了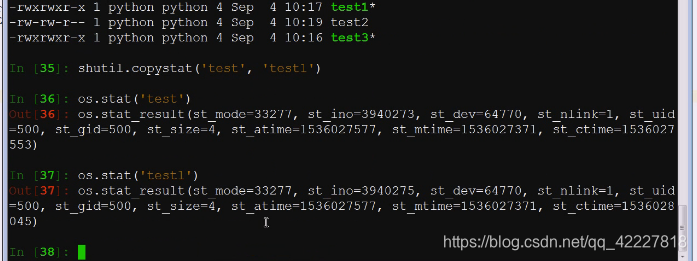
在深入学习这些命令都是在c源码里了
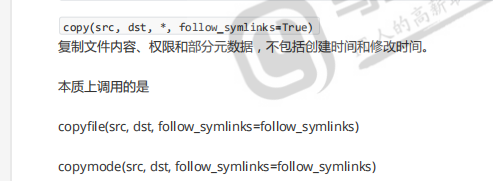
一般都是围绕copy和copy2的
如果想要copy2就带stat
如果满足copy,不带stat,带mode,有时候更加关心的是权限
拷贝的时候把权限带过去方便一点
有时候tar打包的时候,不仅把文件权限带走,实际上还把stat信息带走,解包的时候把权限都带过去了
拷贝的时候过去一定要看你对解包的文件有没有权限,一定要看下
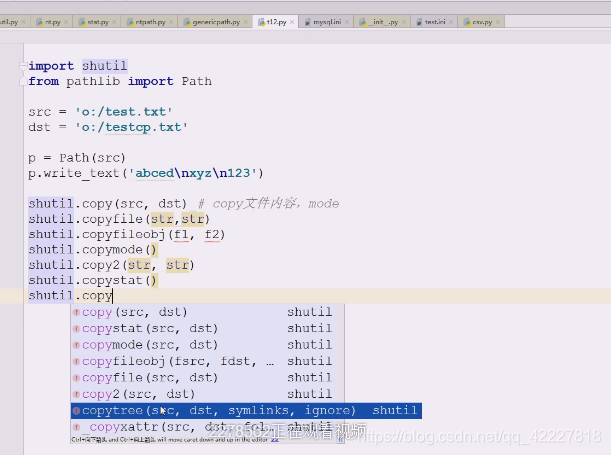
查看copytree(源,目的,符号链接,忽略什么东西,copy拷贝什么函数=copy2(调用copy的时候,调用copy还是调用copy2,元数据想要拷贝多少,是想拷贝权限,还是一起拷贝,默认使用copy2,是吧stat信息全部拷贝过去了))
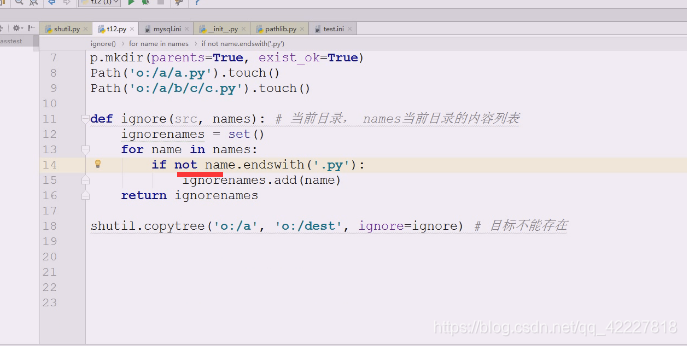
copytree往往拷贝的时候目录对目录的,可能需要只拷贝.py结尾的这样的需求,连拷贝带过滤
global函数,可以把自己想要拷贝的某个目录下的.py文件路径拿到,下来就需要迭代这些文件路径,拷贝这些文件即可,但是拷贝的时候未必能按照它文件结构进行拷贝,global适合把一大批文件找到,迭代这些文件拷贝到一个目的上去
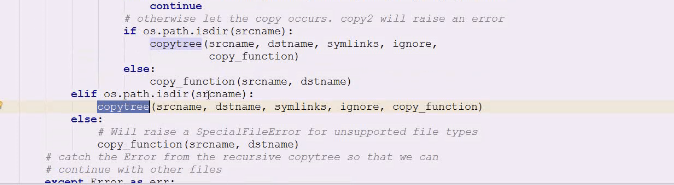
copytree是连树形结构,让树形结构保存下来,有目录结构,代表递归拷贝一个目录树
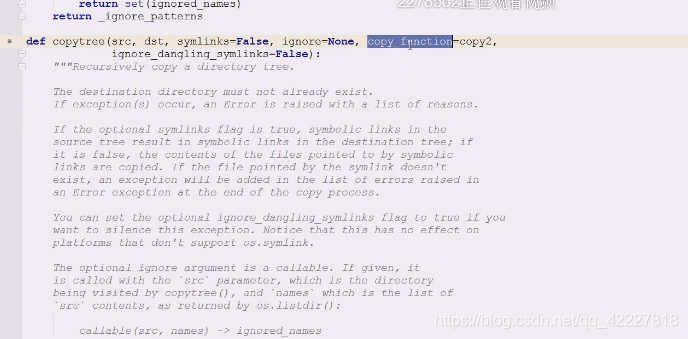
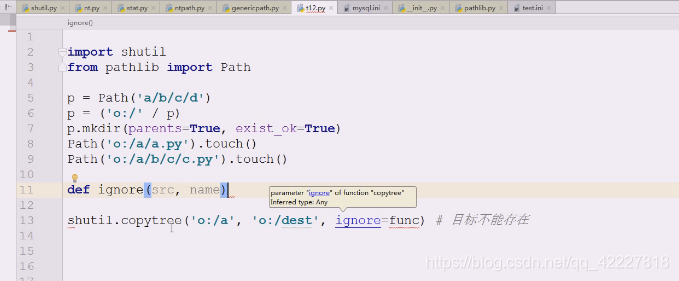
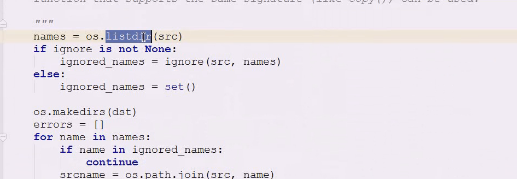
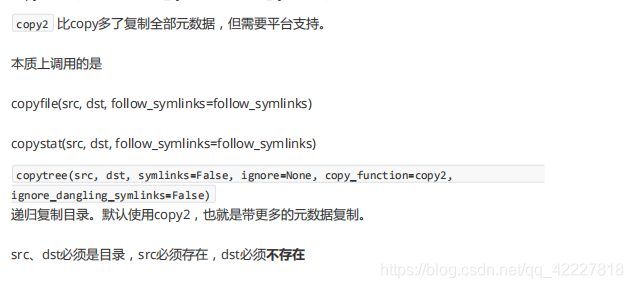
查看ignore是如何做忽略的
如果none,就是空集合,代表忽略的名字们
set,可以通过key来访问
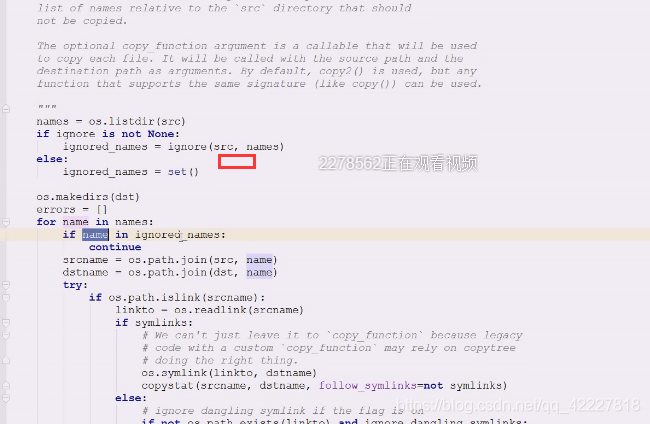
在忽略的名字里直接continue,不拷贝了,代表使用函数的时候只要个忽略的就行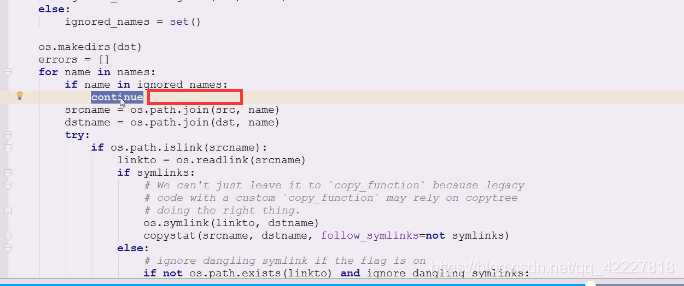
执行一下
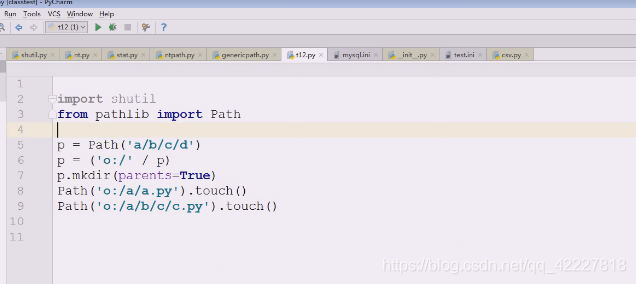
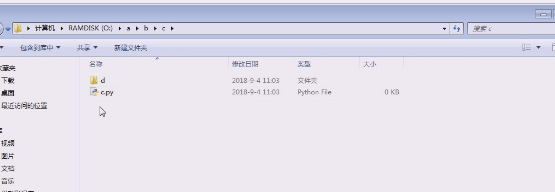
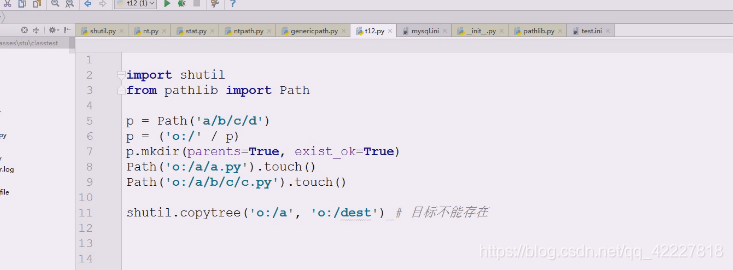
创建一个dest文件夹
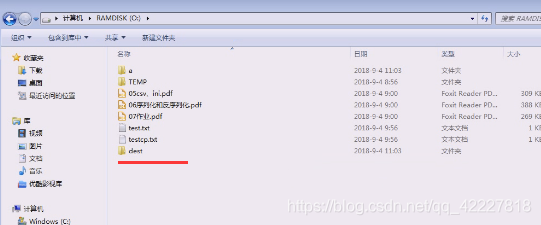
源o:/a想要拷贝到o:/dest下去,提示文件存在,就标识目标不能存在
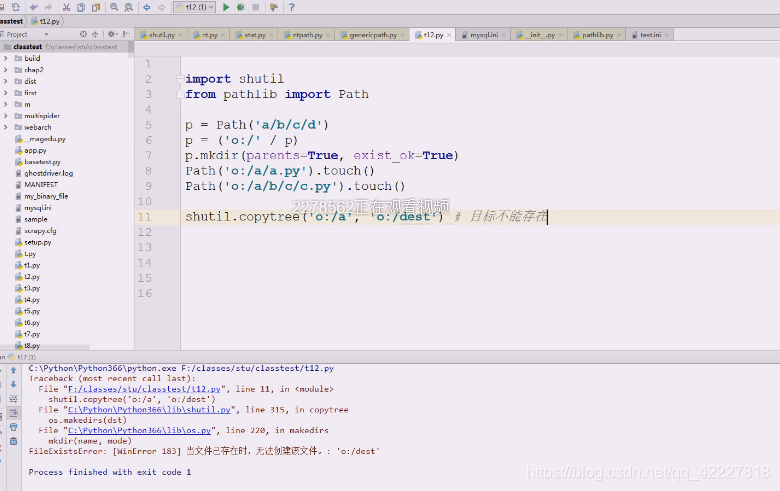
把dest删除
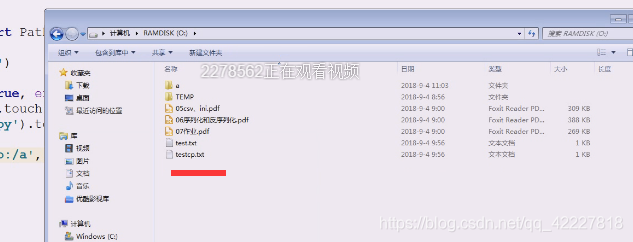
再次执行
拿到name就需要拼一下路径
然后子目录就要递归进去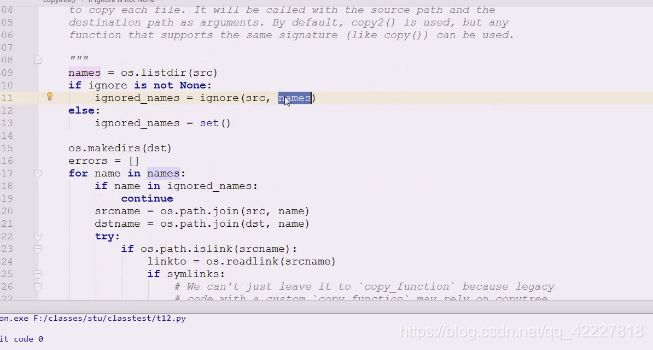
ignore是return回一个可迭代对象,比如set,该如何去忽略、
在src这个目录下传两个参数,顺便就把s目录的,当前src下的内容就直接给你了
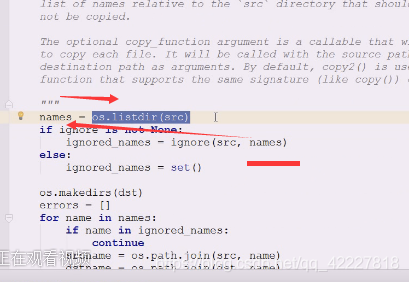
里面在做递归,如果是目录会把目录传进来
目录就变成了新的目录
如果是.py的就可以加进去,最后把ignorenames返回即可
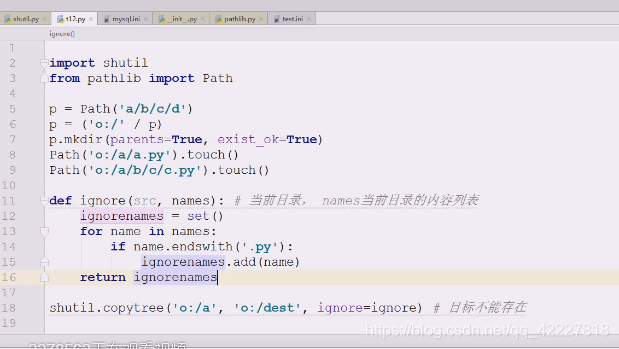
.py发现在names,就跳过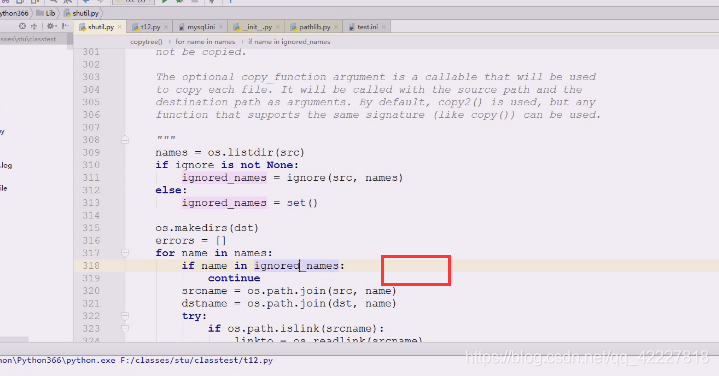
这样就相当于除了.py的都忽略,这种逻辑抽到外面去就变成通用的逻辑了,需要的时候可以自己编写
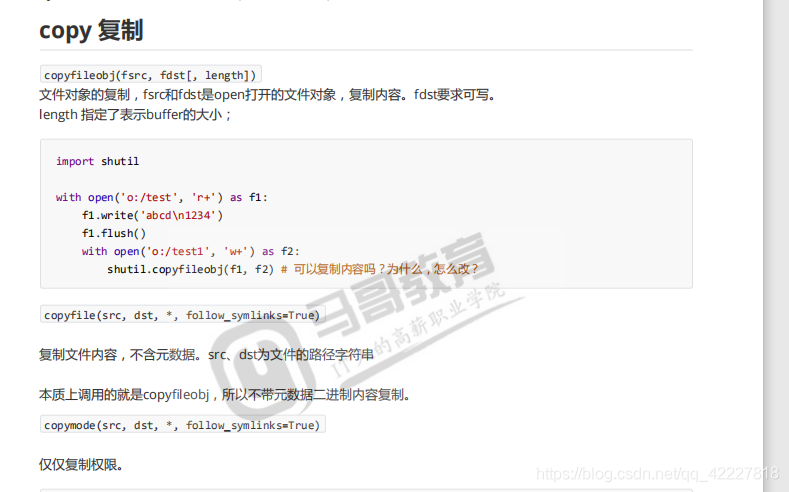
copyfile是仅仅复制文件内容,不包含元数据,copymode是仅仅复制权限
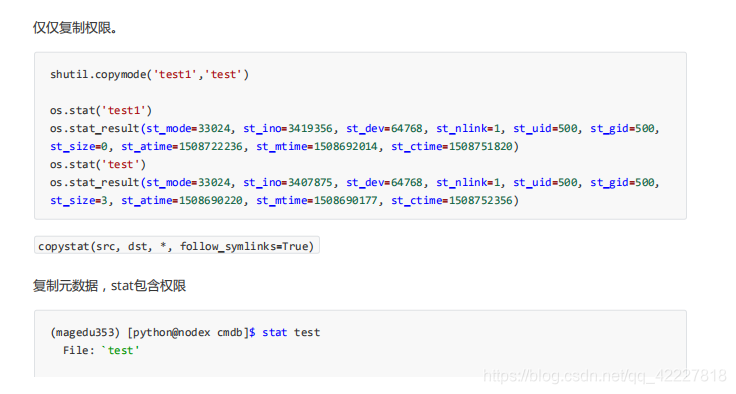
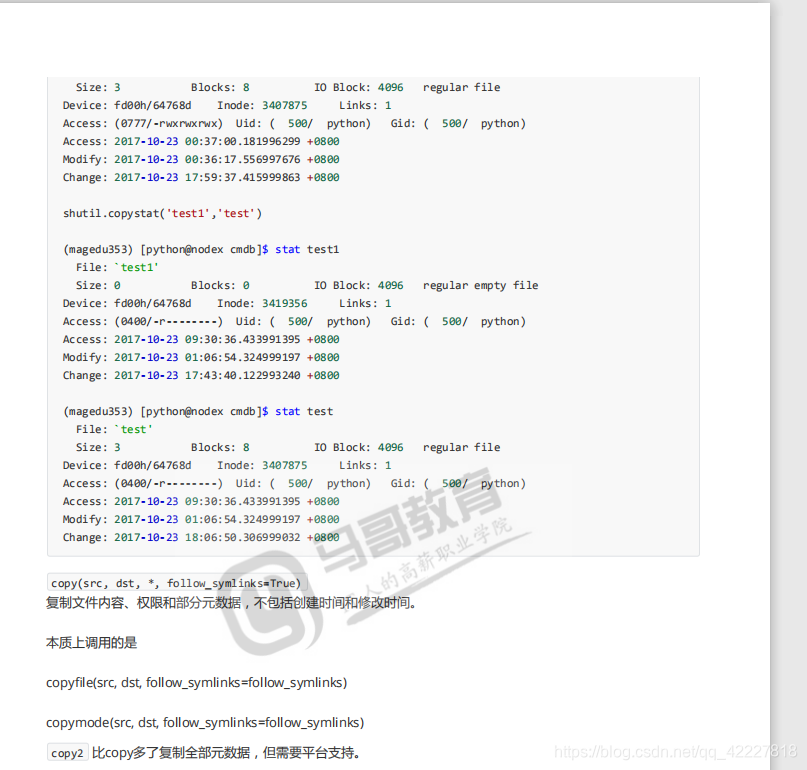
copy两个版本
一个是复制文件内容,权限和部分元数据,不包括时间戳
copytree如果目标存在就报异常
filter可以过滤出你想要的可迭代对象,拿set包一下,传进去就可以了
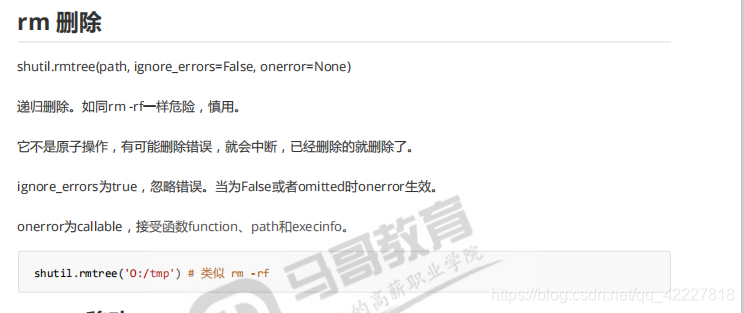
rmtree相当于rm -rf极度危险,因为递归删除
是非原子操作,是可以分开删除的,中间有几个文件删除错误,其他也是可以 删除的
原子操作代表,要删除1000个文件,要么完全删除,要么都不删除,删一个其他都不删除,这就不叫原子操作
*一般在同盘只是做了下标记,所以比较块,不同的盘就真的在拷贝,一般跨分区都要牵扯到挪动,一般都是先拷贝后删除的,一般需要确认目标上的文件真正生成好之后才会去回头删除文件
所谓的剪切就是先拷贝后删除,拷贝不管在不在同盘,都需要生成一份新的,一定有数据流的读取和写入过程
rename就是如果是同盘符直接修改元数据,如果不同盘符先拷贝后删除
**
默认在移动里面用copy2,按道理是要把原来的数据带过来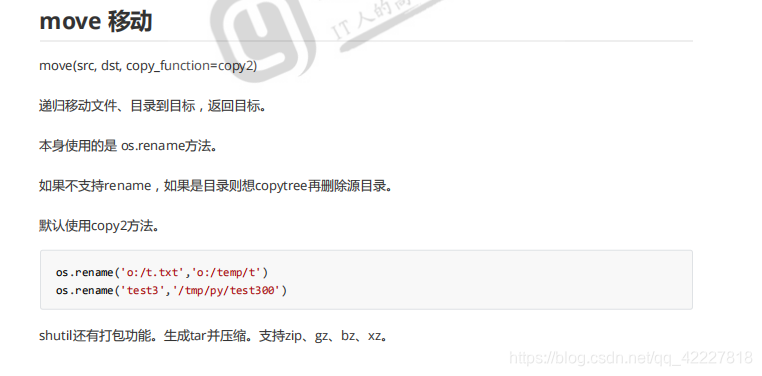
还可以打包生成zip,开源的,rar是闭源的



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









