







 本文详细探讨了Python字典的特性和使用场景,特别是defaultdict的应用,包括其如何处理字典中不存在的键,以及在统计和数据处理中的优势。同时,介绍了有序字典OrderedDict的使用,确保数据的插入顺序得以保持。
本文详细探讨了Python字典的特性和使用场景,特别是defaultdict的应用,包括其如何处理字典中不存在的键,以及在统计和数据处理中的优势。同时,介绍了有序字典OrderedDict的使用,确保数据的插入顺序得以保持。


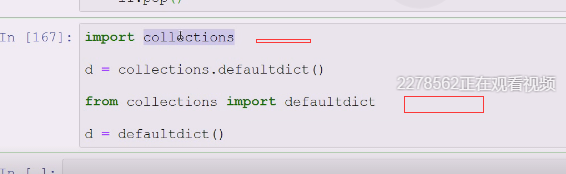
特殊的字典,defaultdict,缺省字典
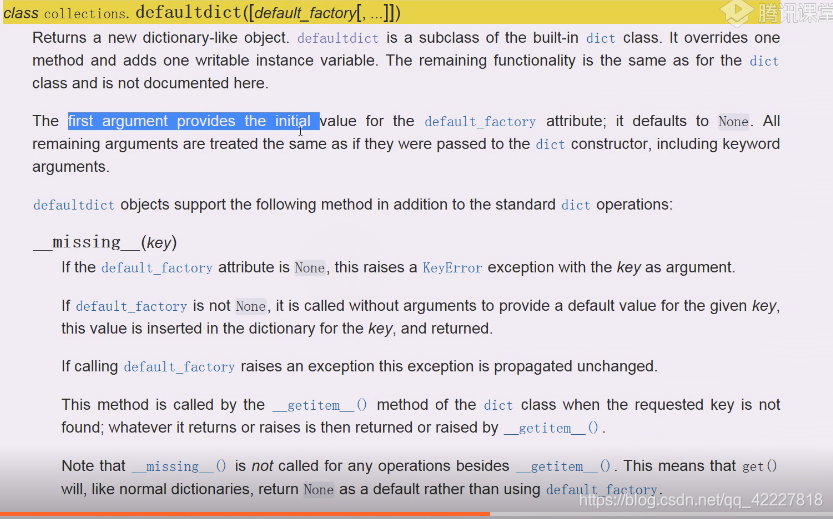
collections这个模块下去调用defaultdict字典(给定缺省工厂方法default_factory),如果缺省就是none,是一个初始化函数,当key不存在的时候,会调用这个工厂函数来生成key对应的value
集合容器模块collections,你要找的字典,集合都在collections里,内建类型你不用找了,dict,set,list,没必要去里面找,
上面只是导入一个模块(模块有一大堆东西),模块.(类似之前的impot math math.random一样)
下面就是从模块把你想要的东西直接导进来,就可以直接用了
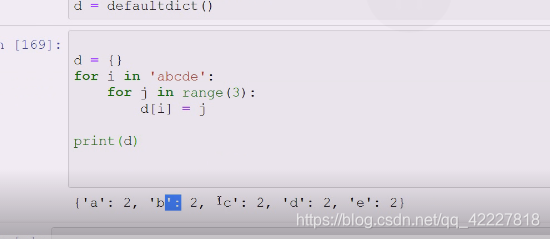
**想要a里面有123三个值,b也有123三个值
这个时候就需要判断一下 i有没有in b中
第一次进来a 当然没有在d的keys中,因为d是空的,不在就造一个a,空列表,出了if就append进去
然后d[i]就在了(不在就创建一个kv对),d[i]列表,append(j),就把0加进去了
然后大循环,b
b不在d里,就append(j),就把012加进去了,依此类推
**
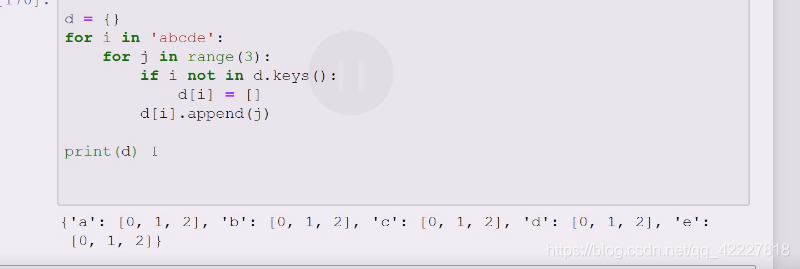
这个代码还可以改造一下
不用普通字典,用缺省字典,没有就用缺省值替代,缺省值就靠list构造
发现使用的d[i]defalutdict的时候,刚开始a进来访问,a不在里面,key如果不在会抛出异常,keyerror
如果使用defaultdict,这个异常不存在就按照你给的工厂方法,
d[i]如果不在就帮你创建=list()
只不过给你看的时候要多打几个字符串而已
这个是缺省字典,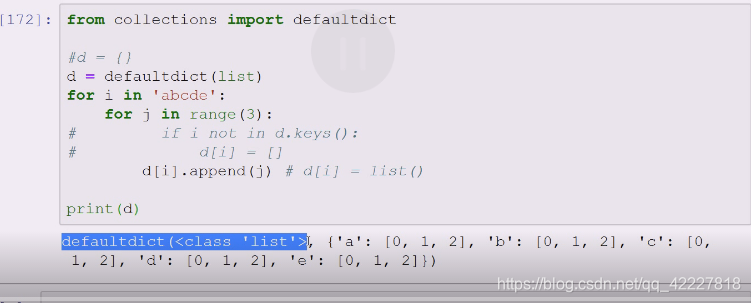
缺省字典也能当字典用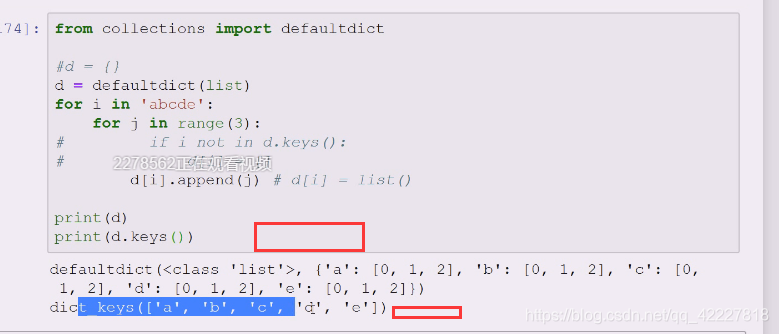
set的set集合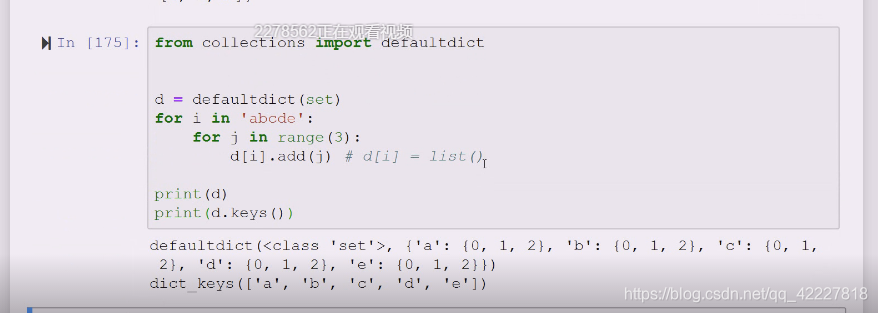
创建dict不能使用add,当你的key不存在的时候就要按照你构建一个你想要的的类型,
类型有了d[I],查的时候要返回对象,如何处理,要跟类型相关,不能都是append
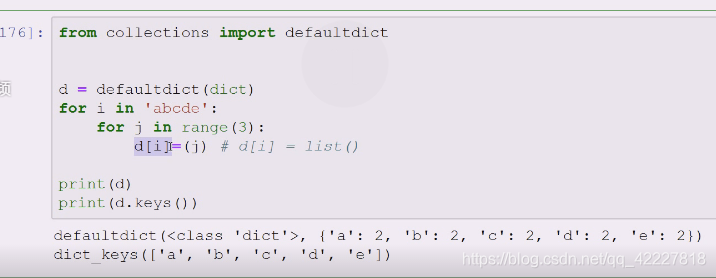
缺省字典在标准库源代码也用的比较多,用起来很简单
开个虚拟机测试一下
切换到3.5.3

ipython效果可能跟cpython效果不一样 两边各自起一个
两边各自起一个
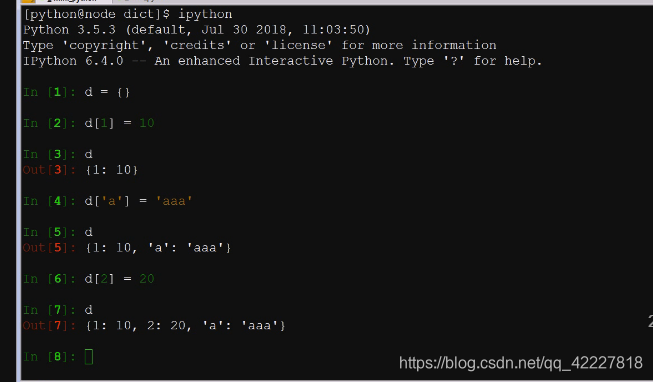
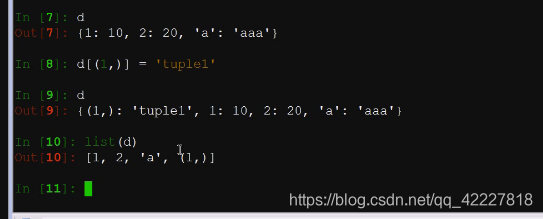
好像3,6的版本你输入的什么顺序就是什么顺序
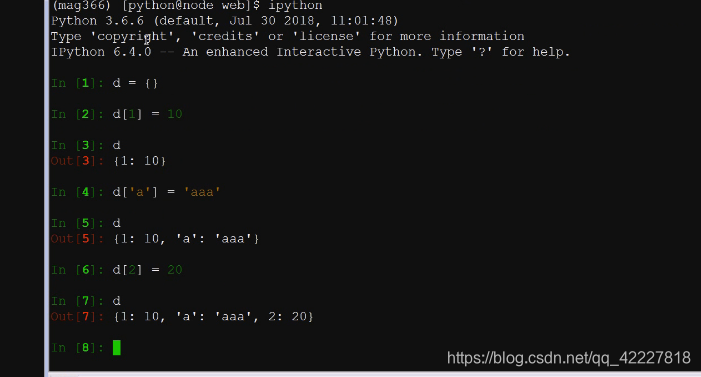
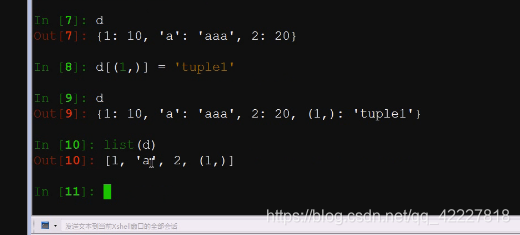
3.6开始就记录了字典录入的时候的顺序,在3.6之前,取出来都是不一定的,但是不建议使用3.6的以上 版本这个特性,万一出问题了就尴尬了
如果记不住,有个东西在collections里,叫做ordereddict

d = ordereddict 字典写成这样
放到3,5里去试试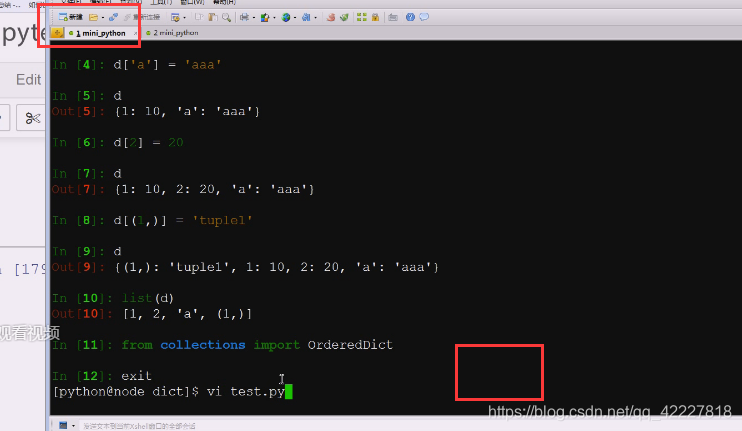
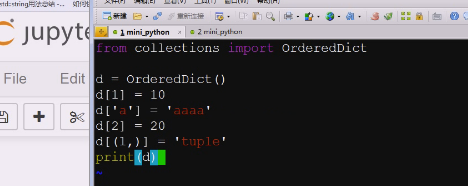

、做个试验

用普通字典来做这个事情了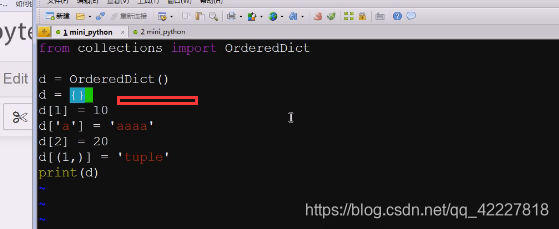
ordereddict不管怎么样就保证有序,造的时候是怎么塞进去数据,就保证出来是什么样的数据
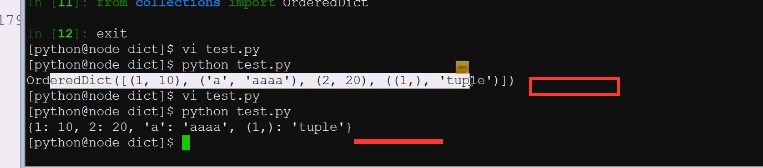
 **keys=list就转换成了一个列表
**keys=list就转换成了一个列表
random。shuffle就地修改列表,顺序打乱
od =ordereddict创建有序字典
for key in key (之前的key是打乱的)
用打乱的顺序来找
**


一般来讲产品的id号是唯一的就跟工号一样,就是key,
除了使用字典检索的遍历,但如果想要取出id,且有顺序的取出,如果输入字典的时候就是按照id号顺序输入进去的,就按照id号顺序取出即可
不用这个,我们就需要用一个列表来记录顺序

降序,列表.sort是个就地修改的,默认升序,降序,就是reverse=true

现在要去key排序,现在搞不定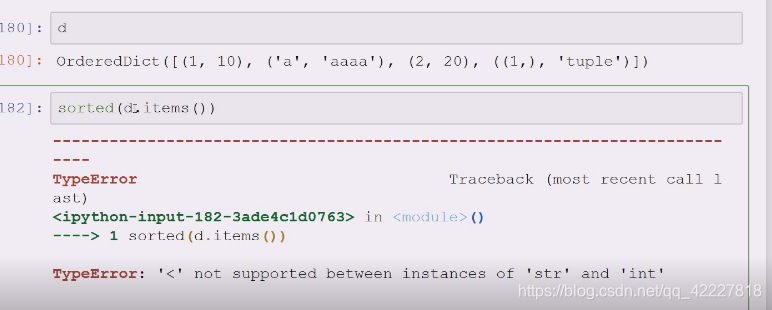



234就相当于.keys


是重新构造了一个列表,然后排序

reverse你要使用是必须要写的
sort排序对于列表来讲,是就地排序,sorted是可以对大多数容器类型来排序的,排完序会生成一个新的列表,返回一个新的,对原有的没有任何影响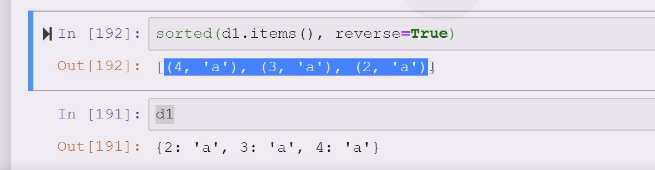
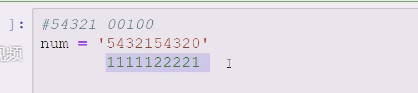
挨个要遍历一遍,字典有个特性 就是去重
{}定义字典,如果在里面设置初始值为0,在里面就+1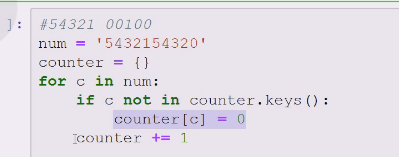
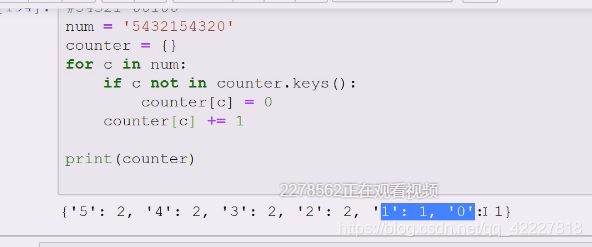
写两个,先算右边有没有,get拿c的话是不出错的,如果没有就是默认值为0
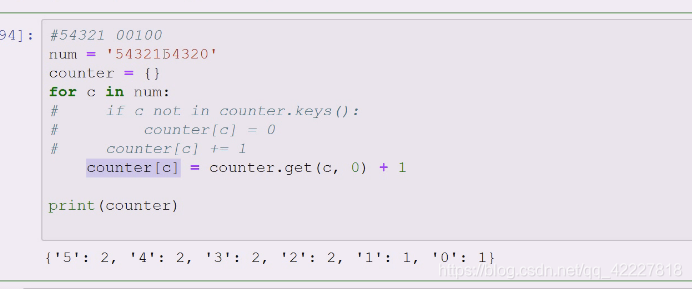
还学了个setdefault,如果没有就给一个缺省值,否则给none,刚开始是没有,5和none做成了kv对,返回当前kv对的值
返回就是0
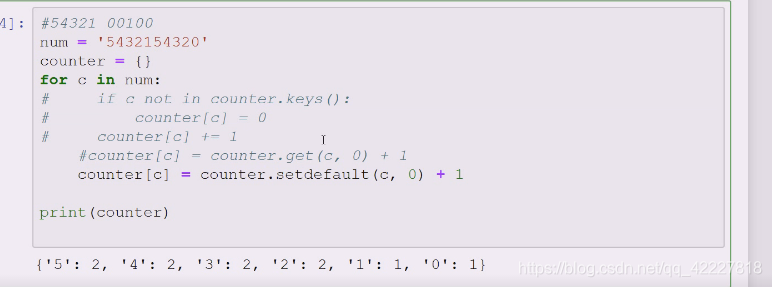
字典最常用的方式就是在做统计的,大数据说实话也是这个,列表也可以高效使用,但是需要你扬长避短,要用列表的索引,没有特殊要求就用字典,把值拿出来当key,用缺省值,+1

第一手资料来自于官方,是最准确的
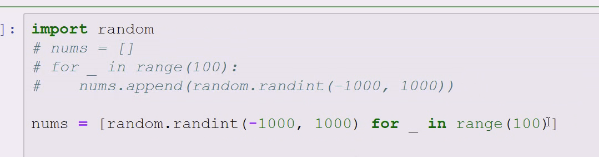
randmon.int,random.shuffle,随机数可能用来测试你的代码是否正确,有时候随机调度性能真的比较好
要么上面这种要么下面这种

使用缺省字典defaultdict
items是按照key来取的
使用第一种方法使用sorted来排序
sorted是排序返回一个新的列表

不用内建函数试试,升序打印数据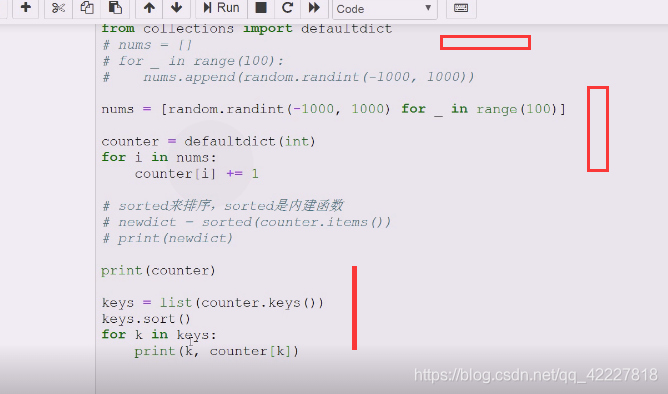
不用nums
i从0开始
相当排序之后拿到key,放到一个有序的列表中
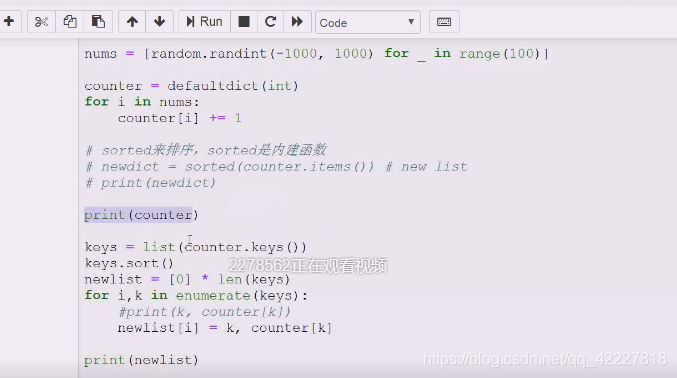
排序了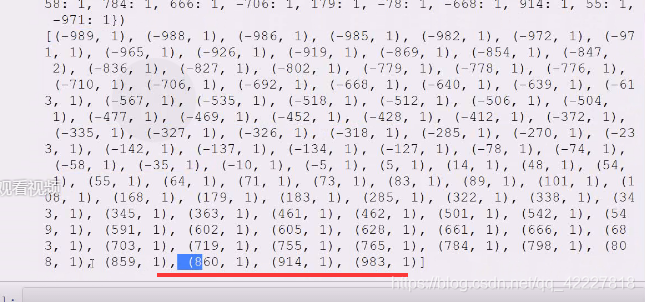
排序了说明这个逻辑没有问题
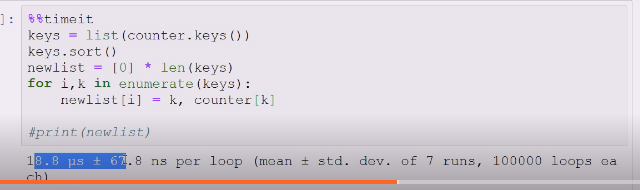
没有排序,在列表里排序,keys。sort
排了序构建一个列表
等于用一个排序好的列表一次用key到无序的字典中塞入到有序的新列表做的事情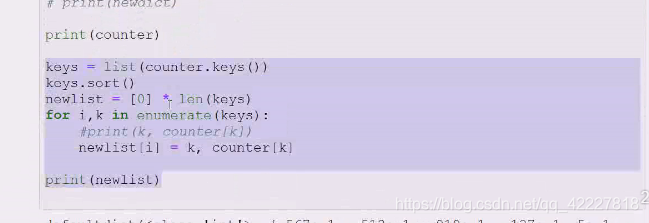
这个写完等于产生的随机数以及统计做完了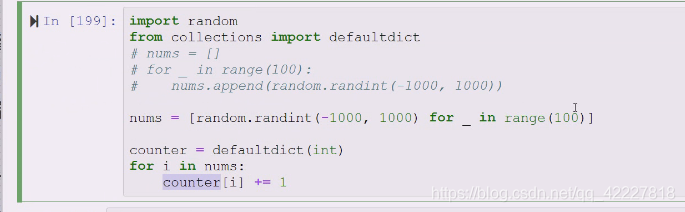
下面就是,内建函数sorted
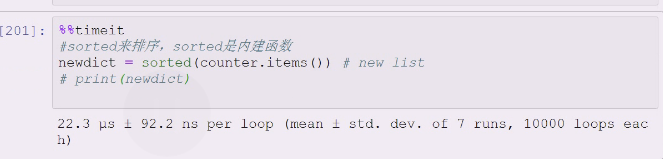
试试是这个效率高,sort函数,然后开辟空间,上面的内建函数未必效率高
迭代,但是在遍历过程中没有用到none的地方

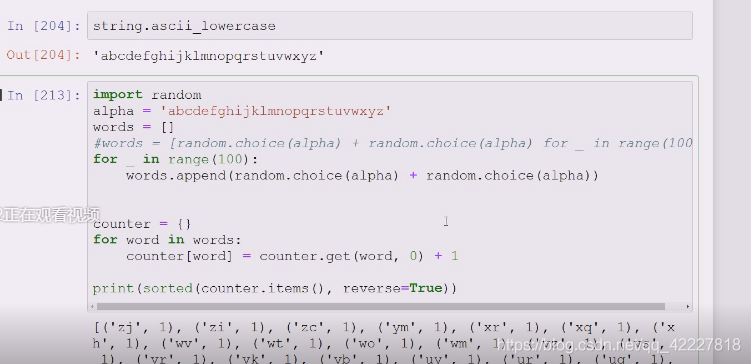
这个有现成的,也可以97-123,是ascii码,97=a

随机可以挑选2个字母
随机100次,构成1个列表
words统计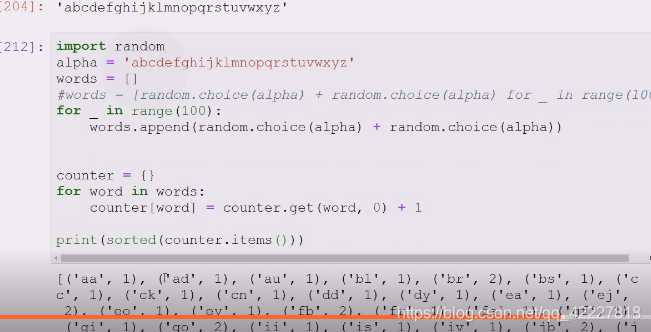
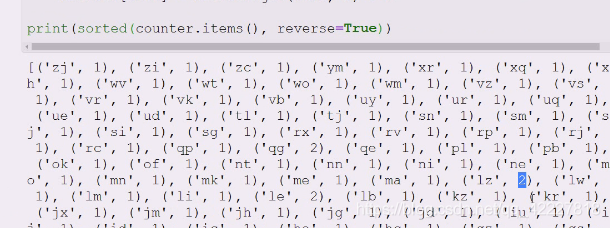
这个是要掌握的
回顾,字典,可变,无序,key不重复,去重的,可迭代的


大部分写成这两个,
解构之后直接是字典

用字典造字典(创建一个字典然后搬进去,因为中间要处理value,用一个字典创建另外的value值)



必须要会


字典的合并是避免不了的

随机的移除

删除的是引用计数,如果指定了del a 变量,相当于把变量,变量没定义过,引用计数需要减一
key,value,item都可以遍历

一定要记住
字典在遍历过程中,不能对它进行增删


工厂方法基本都是换容器塞进来的
有序dict,输入什么顺序,遍历什么顺序,输出什么顺序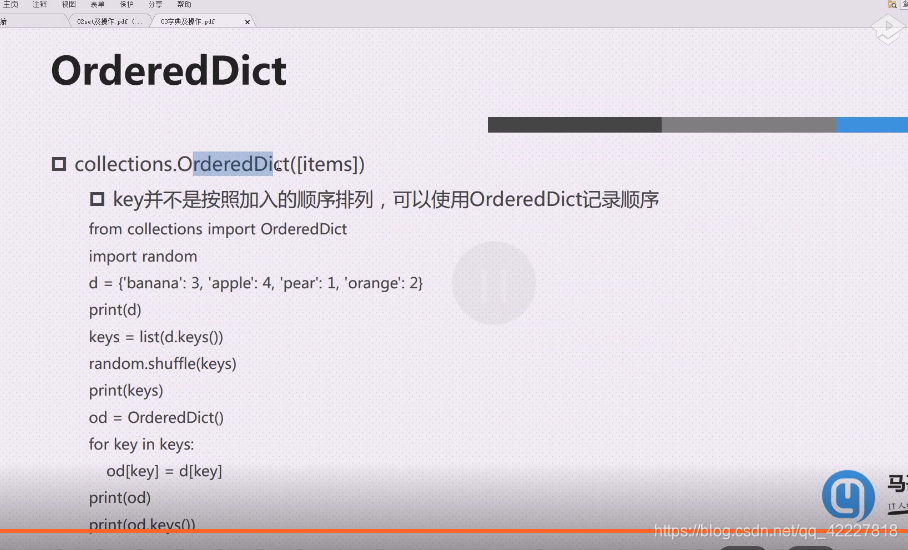




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









