







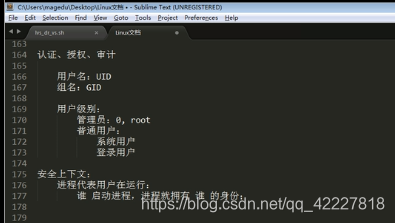
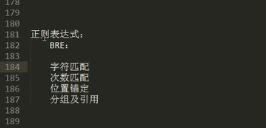
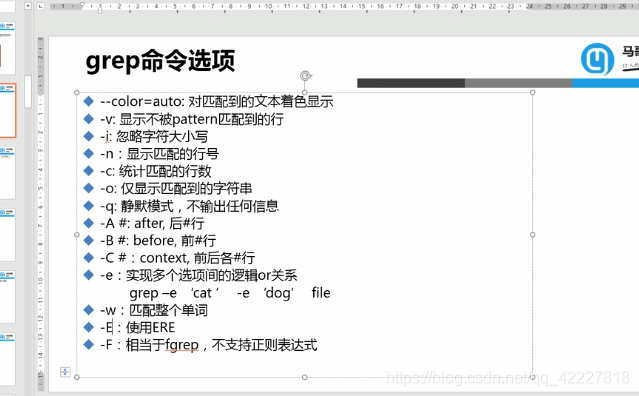
字符匹配“
.任意单个字符
[] 匹配指定范围内的任意字符
[^] 匹配指定范围以外的任意 字符
次数匹配
* 任意次
? 0-1次
+ 一次或多次
{n}至少n个
{n,n}至少n到至多n
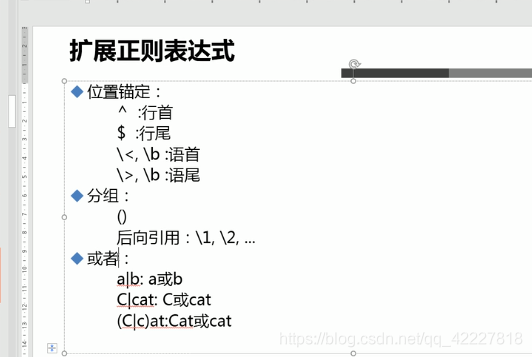
位置锚定
^行首
$行尾
< 或\b 词首
>或\b词尾
分组及引用
()
\1,\2,\3…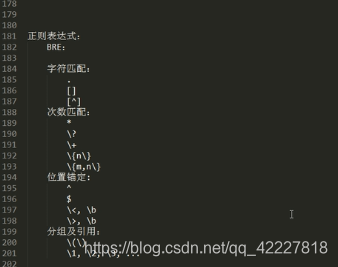

扩展正则表达式字符,不需要转义符了 字符匹配“
字符匹配“
.任意单个字符
[] 匹配指定范围内的任意字符
[^] 匹配指定范围以外的任意 字符
次数匹配
* 任意次
? 0-1次
+ 一次或多次
{n}至少n个
{n,n}至少n到至多n
位置锚定
^行首
$行尾
< 或\b 词首
>或\b词尾
分组及引用
()分组
\1,\2,\3…
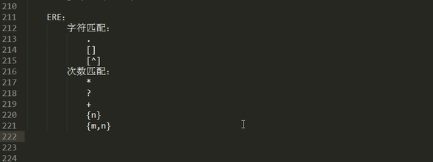
匹配最多6次
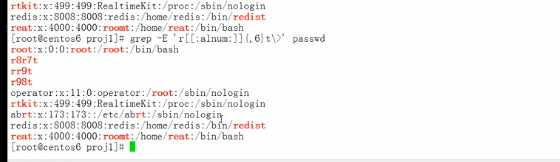
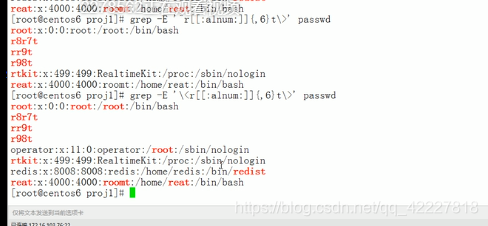
扩展正则表达式还支持或者



这两个一样
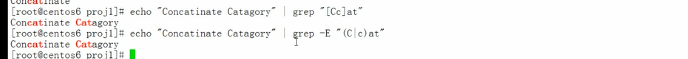
egrep可以表示使用扩展正则表达式的



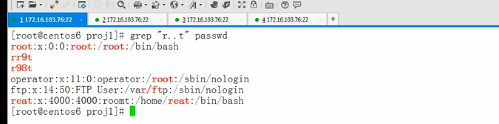
显示匹配到的行在原文中的行号





退出码是0-255的整数,0表示成功

这是失败的


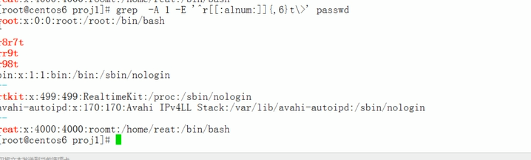
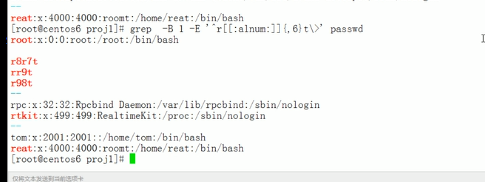

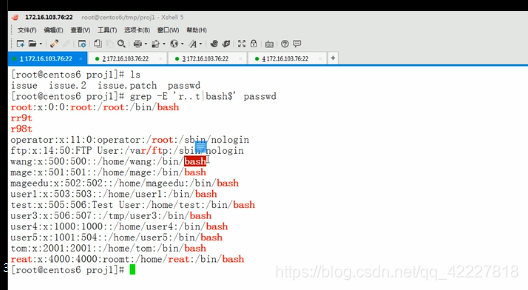
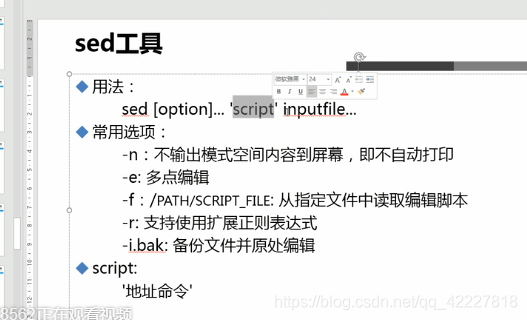
-e指定一个过滤条件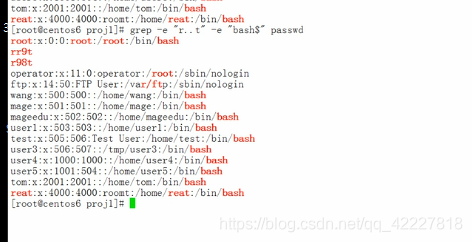

正则表达式做引擎过滤很消耗资源,因为是逐行,需要解析 如果只是简单的字符串检查可以用fgrep,单纯的看你字符串在不在
如果只是简单的字符串检查可以用fgrep,单纯的看你字符串在不在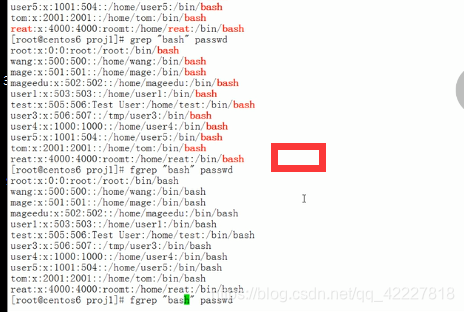

grep是过滤文本
sed 编辑文本
awk 打印文本 ,很耗资源

sed 可以替换内容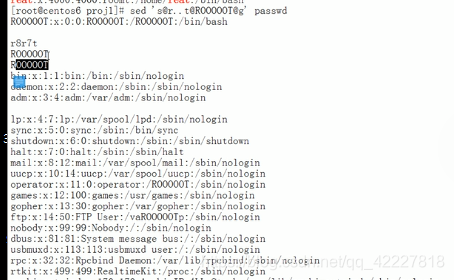
sed也是一次处理一行,在模式空间里修改,把结果打印到终端


可以指明只处理哪些行
‘m,n 从m到n行’
‘m,+x 从m 行+x行’
''所有行
m行本身
/part1,/part2/从第一个模式到第二个模式
1~2从1开始步进2
2~2从2开始步进2
先写地址定界再写命令
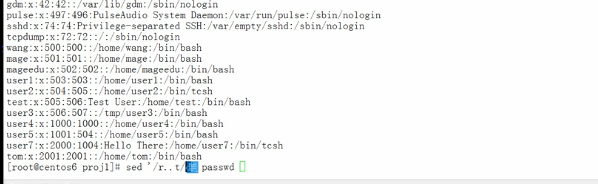

默认打印模式空间的就会打印两份
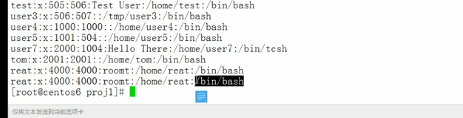

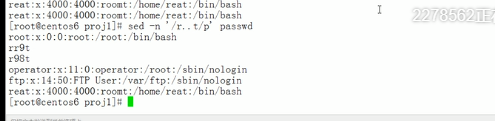

在能够被r…t匹配到的行后面追加信息

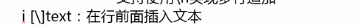
在已有行的前面插入数据
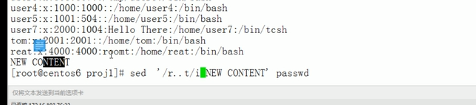



把不匹配到的行删除
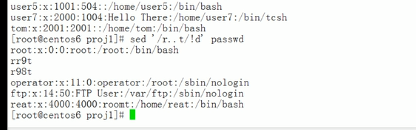


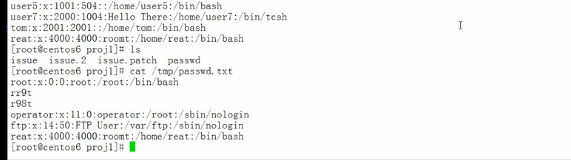
默然还打印模式空间的,-n就不打印了

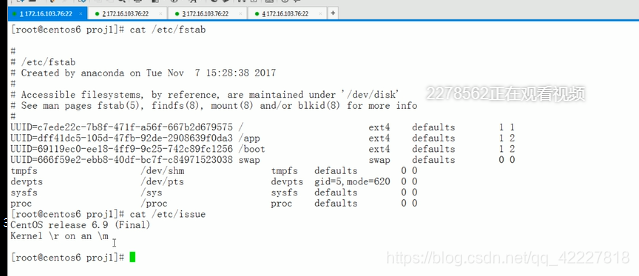

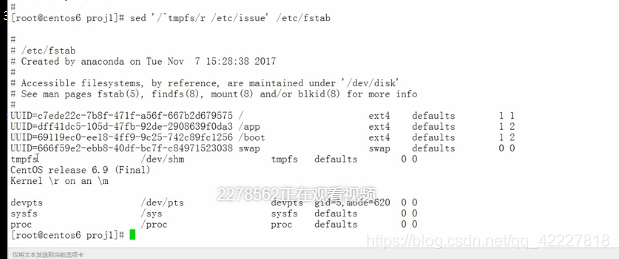
所有UUID都附加了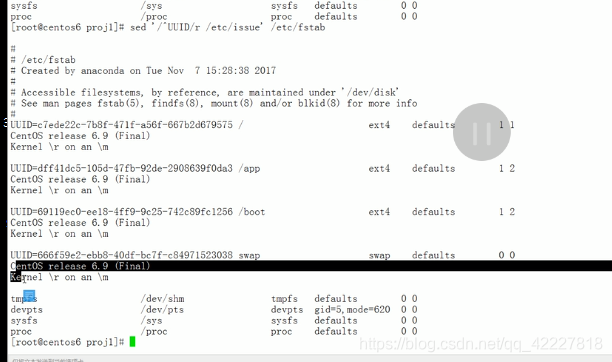


只替换行中第一次匹配到的

全局修改

i表示查找时不区分大小写

也可以换成#号
 !在这里插入图片描述
!在这里插入图片描述
&r引用前面匹配的所有内容

sed也支持扩展正则表达式




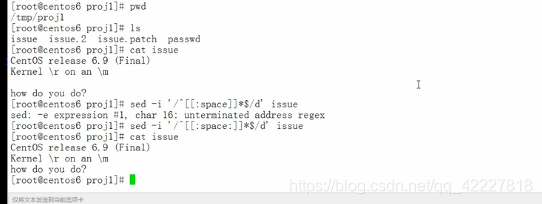
root后面加注释行
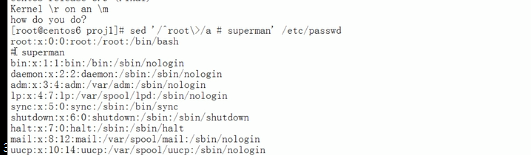
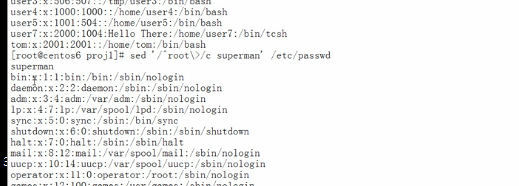
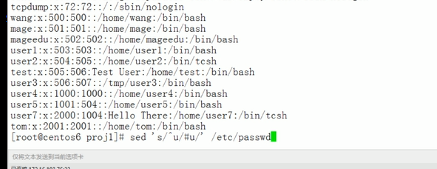
u开头的前面加#





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}