




 本文分享了使用XPath爬取人民邮电出版社新书信息的实战经验,包括处理图书价格缺失、多位作者信息及页面信息不全等问题,强调了正确使用XPath的重要性,并介绍了replace与strip()函数的区别以及' '.join函数的用途。
本文分享了使用XPath爬取人民邮电出版社新书信息的实战经验,包括处理图书价格缺失、多位作者信息及页面信息不全等问题,强调了正确使用XPath的重要性,并介绍了replace与strip()函数的区别以及' '.join函数的用途。
爬取人民邮电新书30页的图书信息 具体网址:http://ryjaoyu.com//
遇见的问题:
一: 有些图书信息没有价格,
二: 作者有多个
三: 最后一页的图书信息并不完全 。
本次采用xpath的方式:直接上图
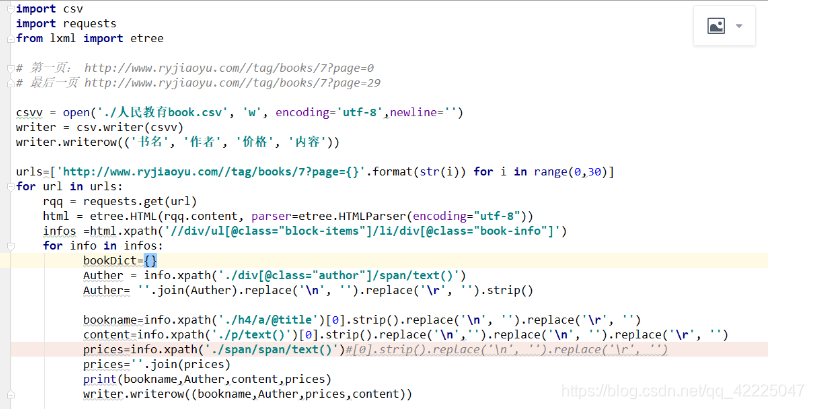
完成后的感悟:
可以通过列表解析的方式 传入url的30页的具体地址
需要记住的是:在遍历当前节点下面的时候 一定不要用 //(注://是匹配所有)
replace 和 strip() 的区别:
replace 可以全部清除, strip() 只能清楚字符串 的前面和后面的\n\t
’ ‘.join函数 :可以将列表转换位字符串 。 分隔符就为’ ’

















 1756
1756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









