







前序
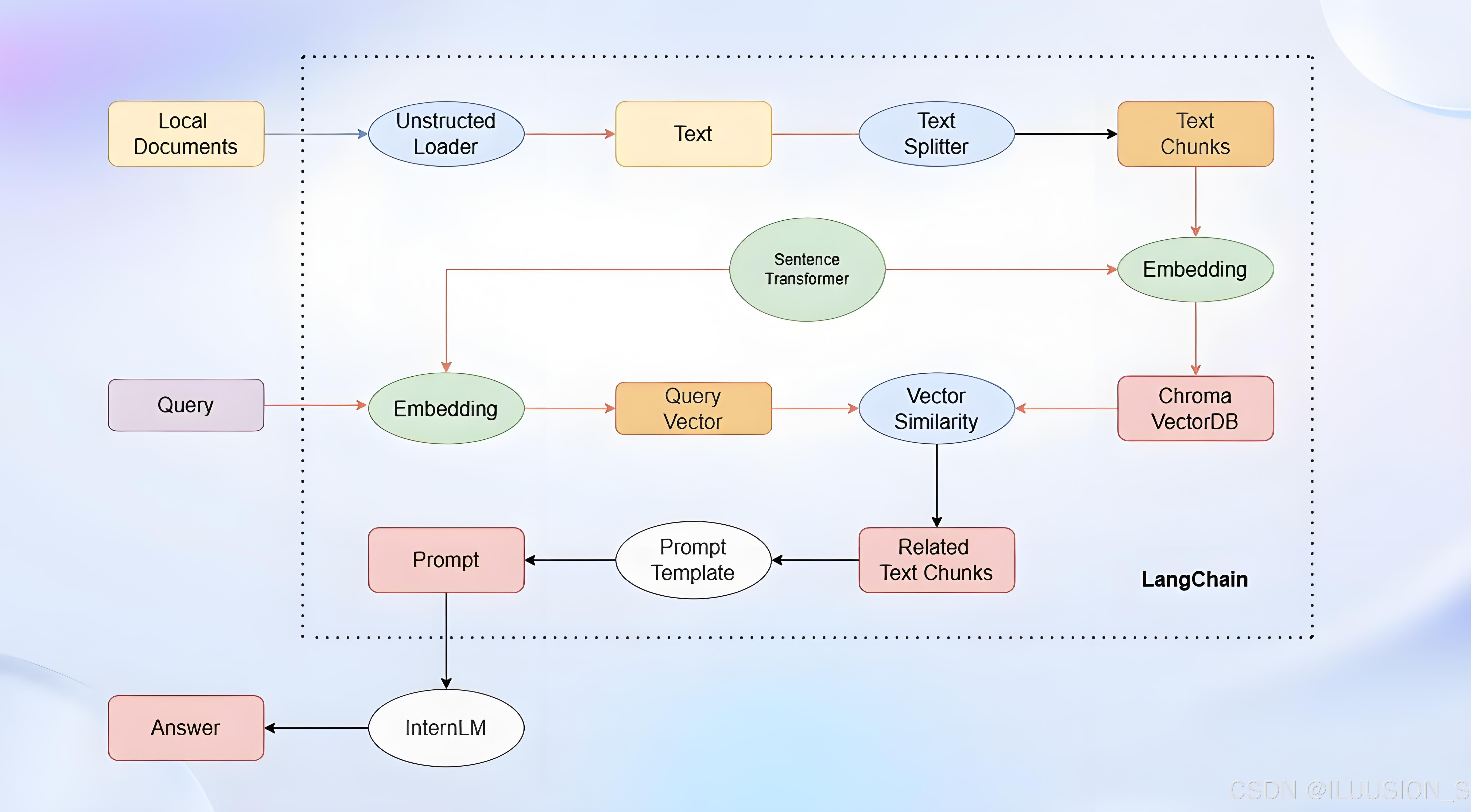 之前简单粗暴将LangChain分了几块,现在就挨着了解学习每块内容。今天主要从文档这条路来看。
之前简单粗暴将LangChain分了几块,现在就挨着了解学习每块内容。今天主要从文档这条路来看。
本地文档这一条链路,通过加载,分割,向量化,再存储数据库
ps:看到这里还想继续实操下去,可以先安装langchain,毕竟还挺费时的,先装着再继续看。
pip install langchain
pip install langchain_community
一、向量及向量化(Embedding)
什么是向量
数学中都学过,向量就是一个点,到另一个点,带有方向的箭头。既有大小,又有方向。
为什么要向量化数据
由于向量可以高度抽象地表示事物的特征和属性,世界上几乎所有类型的数据——视频、图像、声音、文本……统统都可以通过数据处理转换成向量数据。将其他类型的信息转换为向量数据的过程就是向量化。因而,在AI领域流传着一句话,万物皆可Embedding。
举个例子,可以使用词嵌入(word embeddings)来表示文本数据,在词嵌入中,每个单词被转换为一个向量,这个向量捕获了这个单词的语义信息。例如,“Cat” 和 “Dog” 这两个单词在嵌入空间中的位置将会非常接近,因为它们的词性与含义相似;而 “apple” 和 “orange” 也会很接近,因为它们都是水果;而 “Cat” 和 “apple” 这两个单词在嵌入空间中的距离就会比较远,因为它们的含义不同。
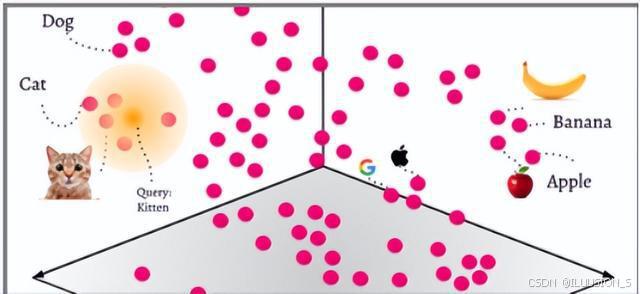
怎么向量化
向量数据,通常指的是将实体(如文本、图像、音频等)转换为数值形式的高维向量。这些向量能够捕捉实体的关键特征,并在向量空间中进行各种计算和比较。向量数据在AI中的应用非常广泛,包括但不限于自然语言处理(NLP)、计算机视觉、语音识别、推荐系统等。通过向量化,AI系统能够更好地理解和处理复杂的数据类型,从而提供更加智能和个性化的服务。
例如我们都是知道代表颜色RGB,如[255,255,255]代表白色。[0,0,0]代表黑色。这就是一种embeding,当然,大模型中,远比这个更复杂,远远不止才3个,而是几百上千,这跟使用的embedding模型
实际上可以通过一些别人训练好的向量化模型,或者说Embedding模型,将输入的内容进行向量化。
二、实操向量化
上面一堆从其他地方CV过来的文字,可以看一下。下面就简单实操。
langchain集成支持的模型列表:https://python.langchain.com/docs/integrations/text_embedding/
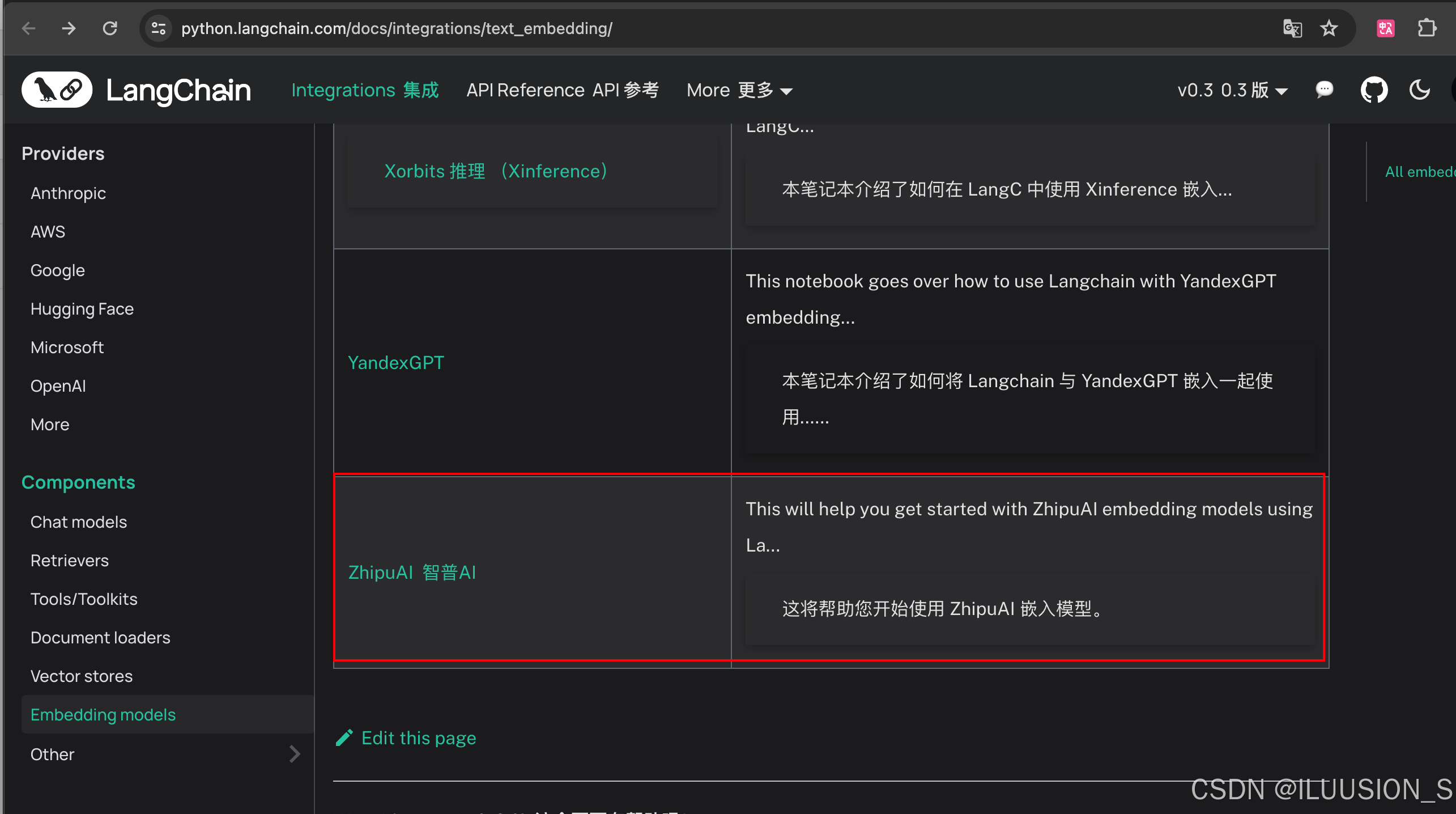
支持的有许多,没看到deepseek,那就算了。再重新随便选一个就行,这里我选这个智普AI,别问我为什么(因为我点到官网看注册后它免费送我次数-_-)
2.1 注册智普,申请key
智普官网:https://bigmodel.cn/
申请key,找不到可以点链接(https://www.bigmodel.cn/usercenter/proj-mgmt/apikeys)
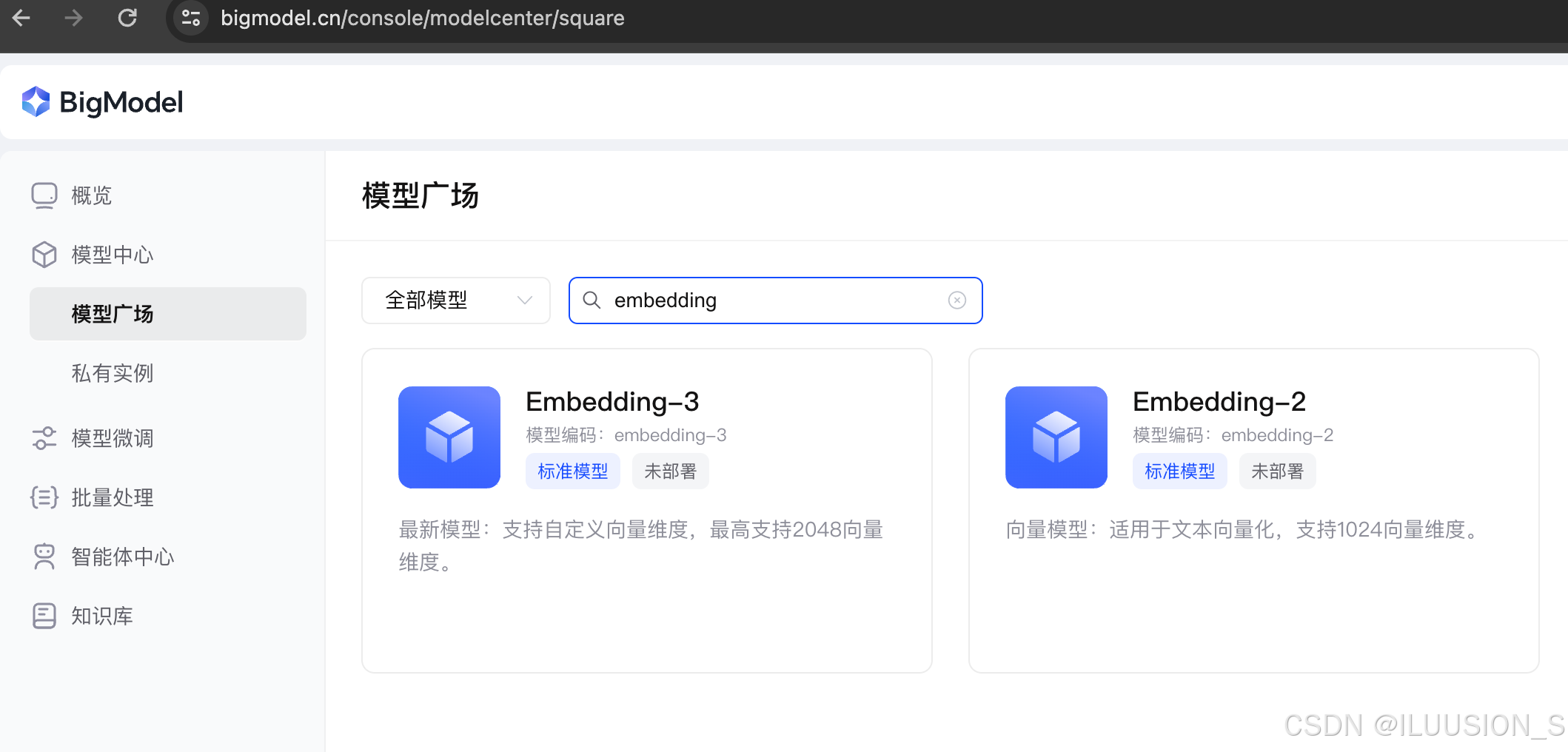
可以去模型广场,搜embedding,可以看到有2个model可供选择
2.2 安装所需要的环境
pip install -U zhipuai
pip install -U langchain_community
import os
os.environ["ZHIPUAI_API_KEY"] = "a22568xxx"
from langchain_community.embeddings import ZhipuAIEmbeddings
embeddings = ZhipuAIEmbeddings(
model="embedding-3",
)
text = "苹果"
single_vector = embeddings.embed_query(text)
print(single_vector, len(single_vector))

可以看到,一个“苹果”就被分成了2048纬度的向量。
官网这里也有单独使用的方法,但是就像最开始说的,每个模型都用他们单独的来使用,那么确实不方便。所以还是尽量选用langcahin提供的跳用方法,到时换模型的话,只需要把参数什么的一换就行

三、文档加载与分割
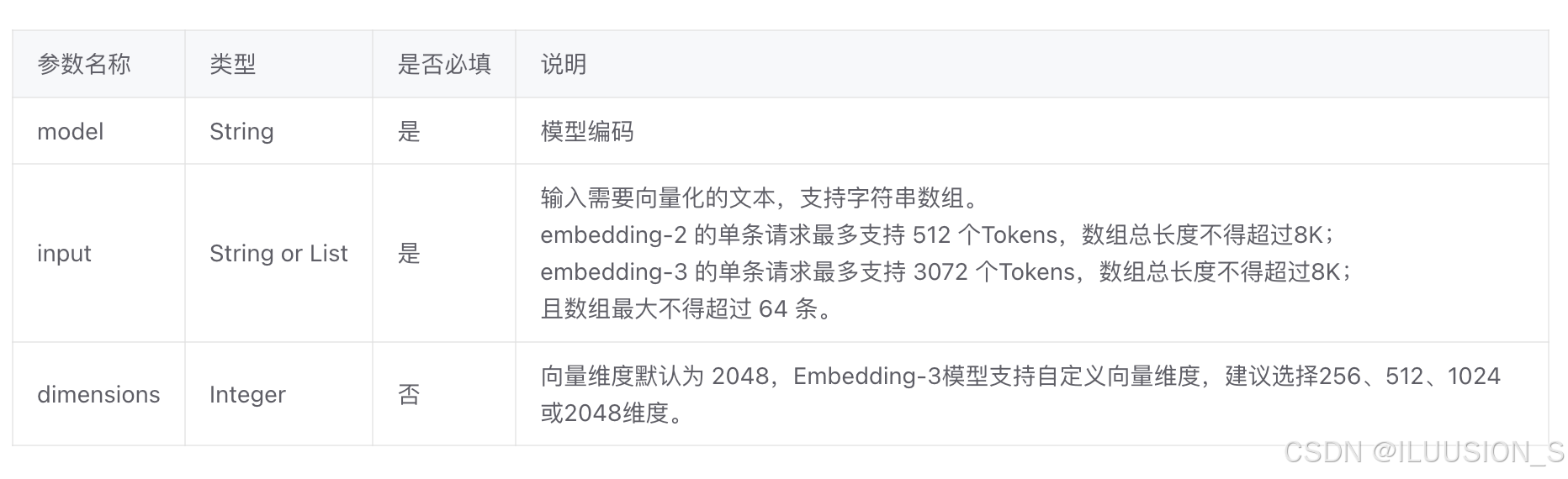
向量化数据是有长度限制的,所以需要先将文件加载,再进行分割。
langchain提供的文档加载器(Document loaders)主要基于Unstructured 包,Unstructured 是一个python包,可以把各种类型的文件转换成文本。LangChain支持的文档加载器包括了csv(CSVLoader),html(UnstructuredHTMLLoader),json(JSONLoader),markdown(UnstructuredMarkdownLoader)以及pdf(因为pdf的格式比较复杂,提供了PyPDFLoader、MathpixPDFLoader、UnstructuredPDFLoader,PyMuPDF等多种形式的PDF加载引擎)几种常用格式的内容解析,但是在实际的项目中,数据来源一般比较多样,格式也比较复杂
最常用的也就是文本文档 TextLoader
3.1 TextLoader文档加载分割
# 文档加载器
from langchain_community.document_loaders import TextLoader
loader = TextLoader('./1.txt', encoding='utf-8')
# 适用于小型的txt文档,加载所有
docs = loader.load()
# 文档分割器
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size=512, # 被分割文档的切块大小,500~2000
chunk_overlap=100, # 被分割切块的重叠部分长度,200以内
)
# 开始文档分割
texts = text_splitter.split_documents(docs)
print(texts)
"""
[Document(metadata={'source': './1.txt'}, page_content='夜已深,漆黑一片,景物不可见。但山中并不宁静,猛兽咆哮,震动山河,万木摇颤,乱叶簌簌坠落。\n\n群山万壑间,洪荒猛兽横行,太古遗种出没,各种可怕的声音在黑暗中此起彼伏,直欲裂开这天地。\n\n山脉中,远远望去有一团柔和的光隐现,在这黑暗无尽的夜幕下与万山间犹如一点烛火在摇曳,随时会熄灭。\n\n渐渐接近,可以看清那里有半截巨大的枯木,树干直径足有十几米,通体焦黑。除却半截主干外,它只剩下了一条柔弱的枝条,但却在散发着生机,枝叶晶莹如绿玉刻成,点点柔和的光扩散,将一个村子笼罩。\n\n确切的说,这是一株雷击木,在很多年前曾经遭遇过通天的闪电,老柳树巨大的树冠与旺盛的生机被摧毁了。如今地表上只剩下八九米高的一段树桩,粗的惊人,而那仅有的一条柳枝如绿霞神链般,光晕弥漫,笼罩与守护住了整个村子,令这片栖居地朦朦胧胧,犹若一片仙乡,在这大荒中显得很神秘。\n\n村中各户都是石屋,夜深人静,这里祥和而安谧,像是与外界的黑暗还有兽吼隔绝了。\n\n“呜……”\n\n一阵狂风吹过,一片巨大的乌云横空,遮住了整片夜空,挡住了那仅有的一点星华,山脉中更加黑暗了。'),
Document(metadata={'source': './1.txt'}, page_content='村中各户都是石屋,夜深人静,这里祥和而安谧,像是与外界的黑暗还有兽吼隔绝了。\n\n“呜……”\n\n一阵狂风吹过,一片巨大的乌云横空,遮住了整片夜空,挡住了那仅有的一点星华,山脉中更加黑暗了。\n\n一声凶戾的禽鸣自高天传来,穿金裂石,竟源自那片乌云,细看它居然是一只庞大到不可思议的巨鸟,遮天蔽月,长也不知多少里。\n\n路过石村,它俯视下方,两只眼睛宛若两轮血月般,凶气滔天,盯着老柳木看了片刻,最终飞向了山脉最深处。\n\n平静了很长一段时间,直到后半夜,大地颤动了起来,一条模糊的身影从远方走来,竟与群山齐高!\n\n莫名气息散发,群山万壑死一般的寂静,凶禽猛兽皆蛰伏,不敢发出一点声音。\n\n近了,这是一个拥有人形的生物,直立行走,庞大的惊人,身高比肩山岳,浑身没有毛发,通体密布着金色的鳞片,熠熠生辉。面部很平,只有一只竖眼,开合间像是一道金色的闪电划过,犀利慑人。整体血气如海,宛如一尊神魔!\n\n它路过此地,看了一眼老柳木,稍作停留后,似乎急于赶路,最终快速远去,许多山峰被其脚步震的轰鸣,山地剧烈颤抖。'),
Document(metadata={'source': './1.txt'}, page_content='它路过此地,看了一眼老柳木,稍作停留后,似乎急于赶路,最终快速远去,许多山峰被其脚步震的轰鸣,山地剧烈颤抖。\n\n黎明,一条十米长、水桶粗、银光灿灿的蜈蚣在山中蜿蜒而行,像是白银浇铸而成,每一节都锃亮而狰狞,划过山石时铿锵作响,火星飞溅。但最终它却避过了石村,没有侵入,所过之处黑雾翻腾,万兽避退。\n\n一根散发着莹莹绿霞的柔弱柳条在风中轻轻摇曳……')]
"""
可以看到,将1.txt这个文件分成了3块。
chunk_size=512, # 被分割文档的切块大小,500~2000
chunk_overlap=100, # 被分割切块的重叠部分长度,200以内
# 重叠是指下一块分割时,包含上一部分的后面100个字符,这样做的目的是避免将重要信息分割时打乱,导致后续处理一些问题。
有点类似断句 “数学王子韩老师”,如果刚好512个字符断到了数学王子, 然后下一个块内容不重叠之前的,韩老师就是人名了。这与最开始的意思不同。所以重叠可以解决一些不必要的歧义问题。
分割完成后,再将每一块分别向量化得到结果
# ...拆分的代码
from langchain_community.embeddings import ZhipuAIEmbeddings
embeddings = ZhipuAIEmbeddings(
model="embedding-3",
)
many_vector = embeddings.embed_documents([text.page_content for text in texts])
for vector in many_vector:
print(vector, len(vector))
这就完成了一次完整的文档分割和向量化的过程
from langchain_text_splitters import CharacterTextSplitter
# 从langchain_text_splitters 点进去,可以看到分割器有很多很多
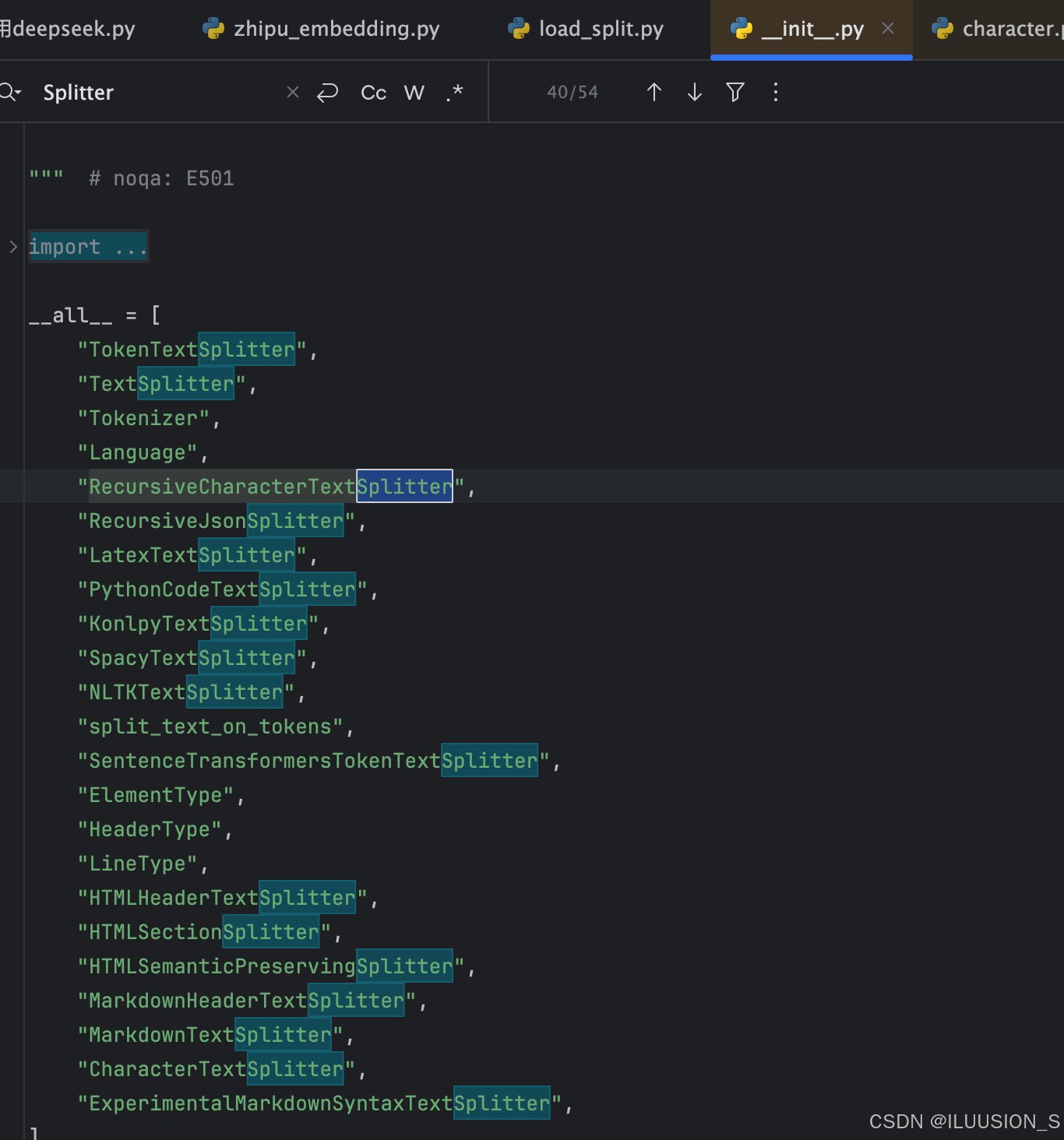
好像说的是 切分文档的话[RecursiveCharacterTextSplitter递归文档切割器比CharacterTextSplitter字符文本切割器更好用]
更多可以查看其他大神的了解更多,既然更好用,那后面就不用CharacterTextSplitter就行了,我也跟着用RecursiveCharacterTextSplitter
RecursiveCharacterTextSplitter分割代码:
# 文档加载器
from langchain_community.document_loaders import TextLoader
loader = TextLoader('./1.txt', encoding='utf-8')
# 适用于小型的txt文档,加载所有
docs = loader.load()
# 文档分割器
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512, # 被分割文档的切块大小,500~2000
chunk_overlap=100, # 被分割切块的重叠部分长度,200以内
)
# 开始文档分割
texts = text_splitter.split_documents(docs)
print(texts)
"""
[Document(metadata={'source': './1.txt'}, page_content='夜已深,漆黑一片,景物不可见。但山中并不宁静,猛兽咆哮,震动山河,万木摇颤,乱叶簌簌坠落。\n\n群山万壑间,洪荒猛兽横行,太古遗种出没,各种可怕的声音在黑暗中此起彼伏,直欲裂开这天地。\n\n山脉中,远远望去有一团柔和的光隐现,在这黑暗无尽的夜幕下与万山间犹如一点烛火在摇曳,随时会熄灭。\n\n渐渐接近,可以看清那里有半截巨大的枯木,树干直径足有十几米,通体焦黑。除却半截主干外,它只剩下了一条柔弱的枝条,但却在散发着生机,枝叶晶莹如绿玉刻成,点点柔和的光扩散,将一个村子笼罩。\n\n确切的说,这是一株雷击木,在很多年前曾经遭遇过通天的闪电,老柳树巨大的树冠与旺盛的生机被摧毁了。如今地表上只剩下八九米高的一段树桩,粗的惊人,而那仅有的一条柳枝如绿霞神链般,光晕弥漫,笼罩与守护住了整个村子,令这片栖居地朦朦胧胧,犹若一片仙乡,在这大荒中显得很神秘。\n\n村中各户都是石屋,夜深人静,这里祥和而安谧,像是与外界的黑暗还有兽吼隔绝了。\n\n“呜……”\n\n一阵狂风吹过,一片巨大的乌云横空,遮住了整片夜空,挡住了那仅有的一点星华,山脉中更加黑暗了。'),
Document(metadata={'source': './1.txt'}, page_content='村中各户都是石屋,夜深人静,这里祥和而安谧,像是与外界的黑暗还有兽吼隔绝了。\n\n“呜……”\n\n一阵狂风吹过,一片巨大的乌云横空,遮住了整片夜空,挡住了那仅有的一点星华,山脉中更加黑暗了。\n\n一声凶戾的禽鸣自高天传来,穿金裂石,竟源自那片乌云,细看它居然是一只庞大到不可思议的巨鸟,遮天蔽月,长也不知多少里。\n\n路过石村,它俯视下方,两只眼睛宛若两轮血月般,凶气滔天,盯着老柳木看了片刻,最终飞向了山脉最深处。\n\n平静了很长一段时间,直到后半夜,大地颤动了起来,一条模糊的身影从远方走来,竟与群山齐高!\n\n莫名气息散发,群山万壑死一般的寂静,凶禽猛兽皆蛰伏,不敢发出一点声音。\n\n近了,这是一个拥有人形的生物,直立行走,庞大的惊人,身高比肩山岳,浑身没有毛发,通体密布着金色的鳞片,熠熠生辉。面部很平,只有一只竖眼,开合间像是一道金色的闪电划过,犀利慑人。整体血气如海,宛如一尊神魔!\n\n它路过此地,看了一眼老柳木,稍作停留后,似乎急于赶路,最终快速远去,许多山峰被其脚步震的轰鸣,山地剧烈颤抖。'),
Document(metadata={'source': './1.txt'}, page_content='它路过此地,看了一眼老柳木,稍作停留后,似乎急于赶路,最终快速远去,许多山峰被其脚步震的轰鸣,山地剧烈颤抖。\n\n黎明,一条十米长、水桶粗、银光灿灿的蜈蚣在山中蜿蜒而行,像是白银浇铸而成,每一节都锃亮而狰狞,划过山石时铿锵作响,火星飞溅。但最终它却避过了石村,没有侵入,所过之处黑雾翻腾,万兽避退。\n\n一根散发着莹莹绿霞的柔弱柳条在风中轻轻摇曳……')]
"""
https://blog.youkuaiyun.com/m0_62965652/article/details/142999598
3.2 markdownLoder
需要安装一些库,一般是报错什么,缺什么就装什么。
pip install unstructured
pip install unstructured
# coding=utf-8
"""
@project: LLM_study
@file: md_loader.py
@Author:John
@date:2025/2/23 18:23
"""
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = UnstructuredMarkdownLoader("langchain.md", mode="elements", autodetect_encoding=True)
docs = loader.load_and_split(text_splitter=RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=100))
print(docs)
运行过程中一直报错,各种找问题,发现好像是这个有问题,让手动下载一下,但是下载又失败。
import nltk
nltk.download('punkt')

就是缺什么去装什么。运行报错时会告诉缺什么,装好就行了。

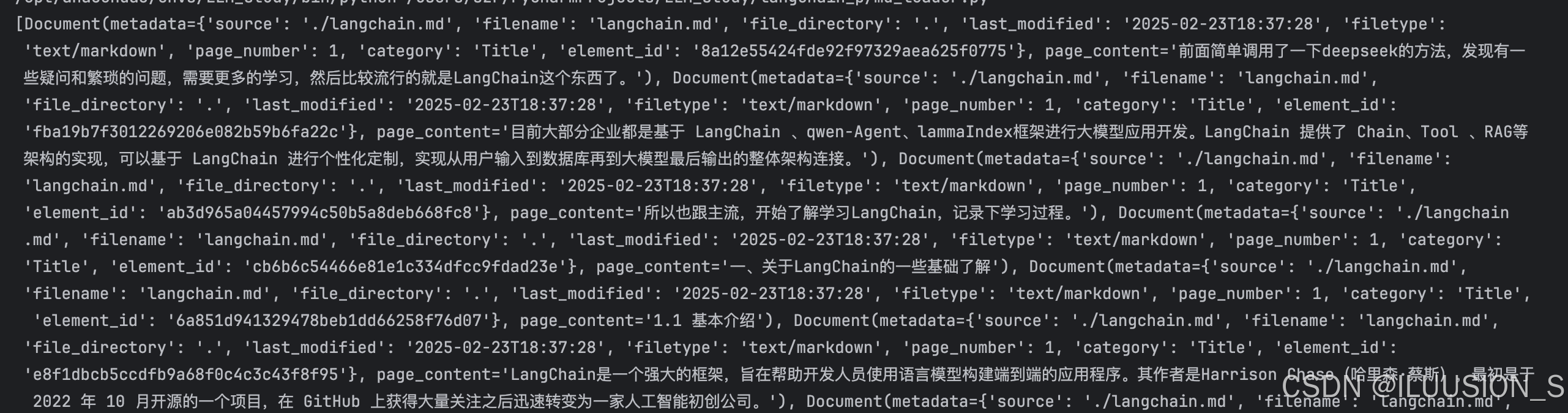
最后成功 运行结果:
其它
其他loader用法都大差不差的。这里也不一一展示了,几乎一样的用法,不同的文档类型,选择不同的loader就行。
也许后面用到了什么再回来补这里。暂时还没用到其他的。附上官网下提供的loader,需要的可以自己选择查看。
https://python.langchain.com/docs/how_to/




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











