






第一获取OpenCV 的 对应 特征分类器文件(可以直接下载OpenCV,“opencv4.5.1\opencv\sources\data\haarcascades\haarcascade_frontalface_alt.xml”)
第二部 获取一份 .traineddata文件,这个文件是Tesseract OCR引擎用于识别文本的训练数据文件
训练文件可以用 jTessBoxEditorfx工具进行训练产生 .traineddata文件
训练1 准备一个训练的基础的***.tiff***文件
训练2 使用jTessBoxEditor生成训练样本的的合并tif图片:
(1)打开jTessBoxEditor,选择Tools->Merge TIFF,进入训练样本所在文件夹,选中要参与训练的样本图片(图片格式最好是.tiff)。
(2)点击 “打开” 后弹出保存对话框,选择保存在当前路径下,文件命名为 “xxx.font.exp0.tif” ,格式只有一种 “TIFF” 可选。
tif文面命名格式[lang].[fontname].exp[num].tiff
lang是语言,fontname是字体,num为自定义数字。
比如我们要训练自定义字库 xxx,字体名font,那么我们把图片文件命名为 xxx.font.exp0.tiff
(3)使用tesseract生成.box文件:
在上一步骤生成的“xxx.font.exp0.tif”文件所在目录下打开命令行程序(即在cmd中切换盘符到文件目录下),执行下面命令,执行完之后会生成xxx.font.exp0.box文件。
tesseract number.font.exp0.tiff number.font.exp0 –l eng batch.nochop makebox
(4)使用 jTessBoxEditor矫正.box文件的错误
jTessBoxEditor点击Box Editor ->Open,打开步骤2中生成的“zwp.test.exp0.tif”,会自动关联到“zwp.test.exp0.box”文件,这两文件要求在同一目录下。调整完点击“save”保存修改
(5)生成font_properties文件:(该文件没有后缀名)
手工新建一个名为font_properties的文本文件,输入内容 “font0 0 0 0 0” 表示字体font的粗体、倾斜等共计5个属性。这里的“font”必须与“xxx.font.exp0.box”中的“font”名称一致
(6)执行过程命令 最终获取到***.traineddata*** 文件
脚本:
echo Run Tesseract for Training..
tesseract.exe number.font.exp0.tiff number.font.exp0 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe number.font.exp0.box
mftraining -F font_properties -U unicharset -O number.unicharset number.font.exp0.tr
echo Clustering..
cntraining.exe number.font.exp0.tr
echo Rename Files..
rename normproto number.normproto
rename inttemp number.inttemp
rename pffmtable number.pffmtable
rename shapetable number.shapetable
echo Create Tessdata..
combine_tessdata.exe number.
echo. & pause
将该文件夹下的***.traineddata***文件 放到tesseract-ocr系项目下的\tesseract-ocr\tessdata下
代码使用实例:
maven文件的pom:
<dependencies>
<!-- OpenCV dependency -->
<dependency>
<groupId>org.openpnp</groupId>
<artifactId>opencv</artifactId>
<version>4.5.1-2</version>
</dependency>
<dependency>
<groupId>javax.media</groupId>
<artifactId>jmf</artifactId>
<version>2.1.1e</version>
</dependency>
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.4</version>
</dependency>
</dependencies>
方法函数:
public static void scanWordOCR(String fieldPath,String fieldName) throws TesseractException {
// Load the OpenCV library
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
// Load the image file
Mat image = Imgcodecs.imread(fieldPath+"/"+fieldName);
// Convert the image to grayscale
Mat grayImage = new Mat();
Imgproc.cvtColor(image, grayImage, Imgproc.COLOR_BGR2GRAY);
// Apply adaptive thresholding to the grayscale image
Mat threshImage = new Mat();
Imgproc.adaptiveThreshold(grayImage, threshImage, 255, Imgproc.ADAPTIVE_THRESH_GAUSSIAN_C, Imgproc.THRESH_BINARY, 15, 5);
String filedPashGrayscale = fieldPath+"/thresholded_image.png";
//根据灰度处理后的数据生成,新的灰度文件
Imgcodecs.imwrite(filedPashGrayscale, threshImage);
// 加载 Tesseract OCR 引擎
Tesseract tesseract = new Tesseract();
// Set the path to the Tesseract database
tesseract.setDatapath("D:/tesseract-ocr/tessdata");
//这里就是我们自己训练生成的.traineddata文件名(不带后缀)
tesseract.setLanguage("number");
// 需要识别的图片文件位置
String result = tesseract.doOCR(new File(filedPashGrayscale));
// Print the OCR result
System.out.println(result);
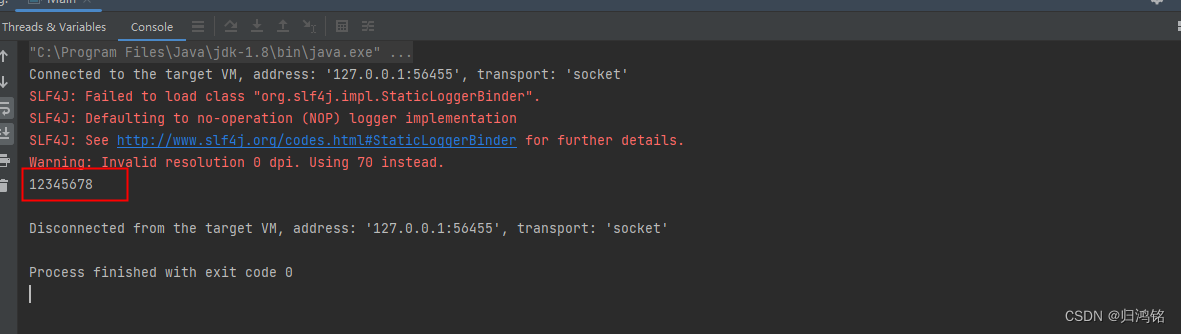
演示结果
需要识别的图片文件
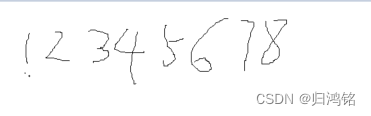
识别结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









