




 本文深入探讨了Off-by-One漏洞的原理,通过具体代码示例分析了两种常见场景:循环边界错误导致的溢出和NULL字节越界。并以2016年Asis CTF竞赛题目为例,详细讲解了如何利用此类漏洞进行攻击。
本文深入探讨了Off-by-One漏洞的原理,通过具体代码示例分析了两种常见场景:循环边界错误导致的溢出和NULL字节越界。并以2016年Asis CTF竞赛题目为例,详细讲解了如何利用此类漏洞进行攻击。
学习资料:https://ctf-wiki.github.io/ctf-wiki/pwn/linux/heap/off_by_one/#_5
off-by-one 指程序向缓冲区中写入时,写入的字节数超过了这个缓冲区本身所申请的字节数并且只越界了一个字节,emmm
看一下CTFWIKI给的第一个例子(循环边界)
int my_gets(char *ptr,int size)
{
int i;
for(i=0;i<=size;i++)
{
ptr[i]=getchar();
}
return i;
}
int main()
{
void *chunk1,*chunk2;
chunk1=malloc(16);
chunk2=malloc(16);
puts("Get Input:");
my_gets(chunk1,16);
return 0;
}可以看到因为循环次数多了一次,存在溢出,这是一种
另一种和字符串有关(字符串操作)----NULL byte off-by-one
int main(void)
{
char buffer[40]="";
void *chunk1;
chunk1=malloc(24);
puts("Get Input");
gets(buffer);
if(strlen(buffer)==24)
{
strcpy(chunk1,buffer);
}
return 0;
}乍一见没毛病啊,程序也跑得起来,但是溢出了
因为strlen函数计算字符串长度的时候是不包括结尾的\x00的,但是strcpy会,那就正好溢出了一个字节
例题:
1.2016 Asis b00ks----NULL byte off-by-one
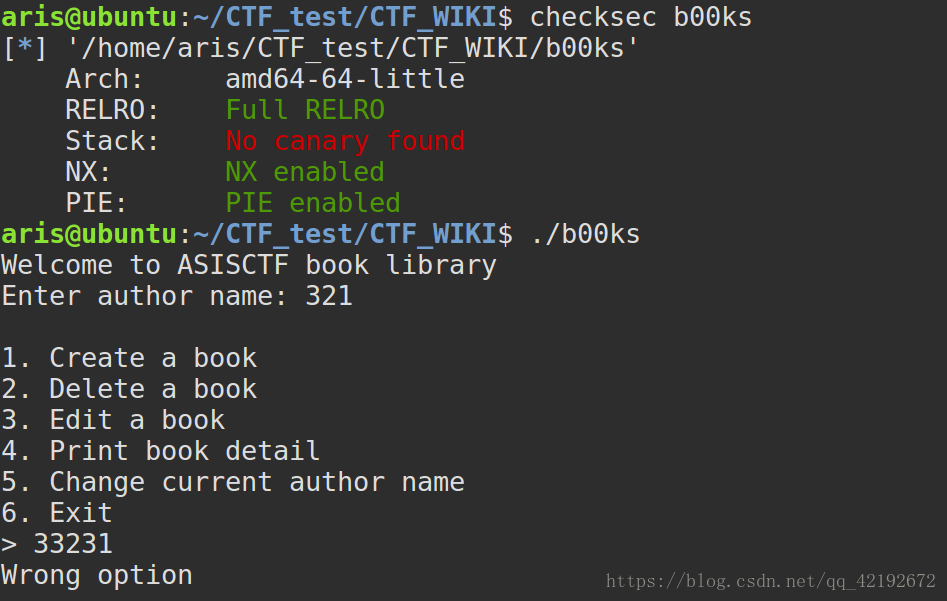
熟悉的PIE\NX\Stack
看一下堆山有什么信息
我们可以看到每次创建一个book,需要开辟0x20个字节(IDA里可以看到创建book的函数里上来就是一个sub rsp,20h,对应的变量个数也能猜出来,之后还有malloc 0x20h)
struct book
{
int id;
char *name;
char *description;
int size;
}其中name与description使用 malloc在堆山分配,大小都是自订的,创建完后
book = malloc(0x20uLL);
if ( book )
{
*((_DWORD *)book + 6) = size;
*((_QWORD *)off_202010 + v2) = book;
*((_QWORD *)book + 2) = description;
*((_QWORD *)book + 1) = name;
*(_DWORD *)book = ++unk_202024;
return 0LL;
} //推一下就好了接下来就是找漏洞的过程了,第一次找这类的还是花了我一些时间的
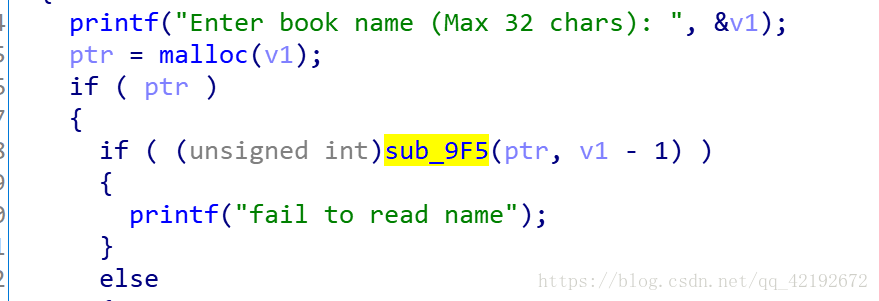
终于在被突出的函数中找到了可能存在漏洞的地方,分析如下

我们可以看到循环执行了a2+1次,其中a2是我们选择创建的(size-1),但最后将第33个字节赋值\x00,所以其实我们read出的数据比我们需要的size超出了一个字节,存在null byte off-by-one
这个函数在read author name的时候也调用了,所以我们只要输入32个字符的话,最后的\x00会写入第一个创建的book中,同时创建book时会把残留的\x00覆盖掉,从而输出author name 就可以泄露book的信息了
打算gdb看一波堆栈的变化,但是开启了PIE保护,先用断点打炸然后vmmap

可以看到数据段在0x555555755000~0x555555757000上,代码段在0x555555554000~0x555555556000上,调试后函数9F5在0x555555554ff8处
……………………

















 706
706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









