






摘要: 最近,有一份自然语言处理 (NLP) 进展合辑,一发布就受到了同性交友网站用户的疯狂标星,已经连续3天高居GitHub热门榜首位。 合集里面包括,20多种NLP任务前赴后继的研究成果,以及用到的数据集。
最近,有一份自然语言处理 (NLP) 进展合辑,一发布就受到了同性交友网站用户的疯狂标星,已经连续3天高居GitHub热门榜首位。
合集里面包括,20多种NLP任务前赴后继的研究成果,以及用到的数据集。
这是来自爱尔兰的Sebastian Ruder,倾力汇总而成。

他在爱尔兰国立大学 (戈尔韦) 读博。另一个身份,是AI创业公司Aylien的研究人员。
塞巴斯蒂安说,NLP近来发展太快了,即便作为局内人,也很难顺畅地跟进这个领域里发生的事。
无微不至的仓库
要找到最常用的数据集,要了解自己研究的问题有了哪些新进展,还是很费力的。

所以,他就在GitHub上面建了一个仓库,追踪各种自然语言任务的研究成果,还有对应的数据集。
这是一间整齐的仓库,任务是按字母顺序排列——
· CCG supertagging
· Chunking
· Constituency parsing
· Coreference resolution
· Dependency parsing
· Dialog
· Domain adaptation
· Language modelling
· Machine translation
· Multi-task learning
· Multimodal
· Named entity recognition
· Natural language inference
· Part-of-speech tagging
· Question answering
· Semantic textual similarity
· Sentiment analysis
· Semantic parsing
· Semantic role labeling
· Summarization
· Text classification
作为一个情绪型选手,我点开了情绪分析 (Sentiment Analysis) 的页面。

这里的数据集很亲切,比如IMDb,电影评分网站的数据。
再比如,“ (姑且称为) 美国的大众点评”,Yelp的店铺评论数据集。

每个数据集下面,都有相关研究的列表,以及所用模型的准确度。
当然,情绪的二分类 (Binary Classification) ,以及细粒度分类 (Fine-Grained Classification) ,作为两种问题,列表也是分开的。
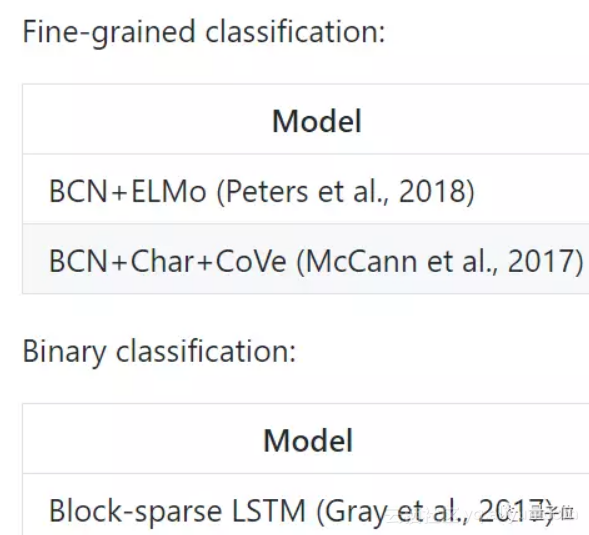
这人文关怀,无微不至。
未解之谜

















 9465
9465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









