







C 基础知识总结
C 函数指针
函数指针是指向函数的指针变量。
通常我们说的指针变量是指向一个整型、字符型或数组等变量,而函数指针是指向函数。
函数指针可以像一般函数一样,用于调用函数、传递参数。
函数指针变量的声明:
typedef int (*fun_ptr)(int,int); // 声明一个指向同样参数、返回值的函数指针类型
//以下实例声明了函数指针变量 p,指向函数 max:
#include <stdio.h>
int max(int x, int y)
{
return x > y ? x : y;
}
int main(void)
{
/* p 是函数指针 */
int (* p)(int, int) = & max; // &可以省略
int a, b, c, d;
printf("请输入三个数字:");
scanf("%d %d %d", & a, & b, & c);
/* 与直接调用函数等价,d = max(max(a, b), c) */
d = p(p(a, b), c);
printf("最大的数字是: %d\n", d);
return 0;
}
C 位域
如果程序的结构中包含多个开关量,只有 TRUE/FALSE 变量,如下:
struct
{
unsigned int widthValidated;
unsigned int heightValidated;
} status;
这种结构需要 8 字节的内存空间,但在实际上,在每个变量中,我们只存储 0 或 1。在这种情况下,C 语言提供了一种更好的利用内存空间的方式。如果您在结构内使用这样的变量,您可以定义变量的宽度来告诉编译器,您将只使用这些字节。例如,上面的结构可以重写成:
struct
{
unsigned int widthValidated : 1;
unsigned int heightValidated : 1;
} status;
现在,上面的结构中,status 变量将占用 4 个字节的内存空间,但是只有 2 位被用来存储值。如果您用了 32 个变量,每一个变量宽度为 1 位,那么 status 结构将使用 4 个字节,但只要您再多用一个变量,如果使用了 33 个变量,那么它将分配内存的下一段来存储第 33 个变量,这个时候就开始使用 8 个字节。让我们看看下面的实例来理解这个概念:
#include <stdio.h>
#include <string.h>
/* 定义简单的结构 */
struct
{
unsigned int widthValidated;
unsigned int heightValidated;
} status1;
/* 定义位域结构 */
struct
{
unsigned int widthValidated : 1;
unsigned int heightValidated : 1;
} status2;
int main( )
{
printf( "Memory size occupied by status1 : %d\n", sizeof(status1));
printf( "Memory size occupied by status2 : %d\n", sizeof(status2));
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Memory size occupied by status1 : 8
Memory size occupied by status2 : 4
位域声明
在结构内声明位域的形式如下:
struct
{
type [member_name] : width ;
};
下面是有关位域中变量元素的描述:
| 元素 | 描述 |
|---|---|
| type | 整数类型,决定了如何解释位域的值。类型可以是整型、有符号整型、无符号整型。 |
| member_name | 位域的名称。 |
| width | 位域中位的数量。宽度必须小于或等于指定类型的位宽度。 |
带有预定义宽度的变量被称为位域。位域可以存储多于 1 位的数,例如,需要一个变量来存储从 0 到 7 的值,您可以定义一个宽度为 3 位的位域,如下:
struct
{
unsigned int age : 3;
} Age;
上面的结构定义指示 C 编译器,age 变量将只使用 3 位来存储这个值,如果您试图使用超过 3 位,则无法完成。让我们来看下面的实例:
#include <stdio.h>
#include <string.h>
struct
{
unsigned int age : 3;
} Age;
int main( )
{
Age.age = 4;
printf( "Sizeof( Age ) : %d\n", sizeof(Age) );
printf( "Age.age : %d\n", Age.age );
Age.age = 7;
printf( "Age.age : %d\n", Age.age );
Age.age = 8; // 二进制表示为 1000 有四位,超出
printf( "Age.age : %d\n", Age.age );
return 0;
}
当上面的代码被编译时,它会带有警告,当上面的代码被执行时,它会产生下列结果:
Sizeof( Age ) : 4
Age.age : 4
Age.age : 7
Age.age : 0//出错
typedef vs #define
#define 是 C 指令,用于为各种数据类型定义别名,与 typedef 类似,但是它们有以下几点不同:
①typedef 仅限于为类型定义符号名称,#define 不仅可以为类型定义别名,也能为数值定义别名,比如您可以定义 1 为 ONE。
②typedef 是由***编译器***执行解释的,#define 语句是由***预编译器***进行处理的。
C 预处理器
C 预处理器不是编译器的组成部分,但是它是编译过程中一个单独的步骤。简言之,C 预处理器只不过是一个文本替换工具而已,它们会指示编译器在实际编译之前完成所需的预处理。我们将把 C 预处理器(C Preprocessor)简写为 CPP。
所有的预处理器命令都是以井号(#)开头。它必须是第一个非空字符,为了增强可读性,预处理器指令应从第一列开始。下面列出了所有重要的预处理器指令:
| 指令 | 描述 |
|---|---|
| #define | 定义宏 |
| #include | 包含一个源代码文件 |
| #undef | 取消已定义的宏 |
| #ifdef | 如果宏已经定义,则返回真 |
| #ifndef | 如果宏没有定义,则返回真 |
| #if | 如果给定条件为真,则编译下面代码 |
| #else | #if 的替代方案 |
| #elif | 如果前面的 #if 给定条件不为真,当前条件为真,则编译下面代码 |
| #endif | 结束一个 #if……#else 条件编译块 |
| #error | 当遇到标准错误时,输出错误消息 |
| #pragma | 使用标准化方法,向编译器发布特殊的命令到编译器中 |
预处理器实例
分析下面的实例来理解不同的指令。
#define MAX_ARRAY_LENGTH 20
这个指令告诉 CPP 把所有的 MAX_ARRAY_LENGTH 替换为 20。使用 #define 定义常量来增强可读性。
#include <stdio.h>
#include "myheader.h"
这些指令告诉 CPP 从系统库中获取 stdio.h,并添加文本到当前的源文件中。下一行告诉 CPP 从本地目录中获取 myheader.h,并添加内容到当前的源文件中。
#undef FILE_SIZE
#define FILE_SIZE 42
这个指令告诉 CPP 取消已定义的 FILE_SIZE,并定义它为 42。
#ifndef MESSAGE
#define MESSAGE "You wish!"
#endif
这个指令告诉 CPP 只有当 MESSAGE 未定义时,才定义 MESSAGE。
#ifdef DEBUG
/* Your debugging statements here */
#endif
这个指令告诉 CPP 如果定义了 DEBUG,则执行处理语句。在编译时,如果您向 gcc 编译器传递了 -DDEBUG 开关量,这个指令就非常有用。它定义了 DEBUG,您可以在编译期间随时开启或关闭调试。
预定义宏
ANSI C 定义了许多宏。在编程中您可以使用这些宏,但是不能直接修改这些预定义的宏。
| 宏 | 描述 |
|---|---|
| DATE | 当前日期,一个以 “MMM DD YYYY” 格式表示的字符常量。 |
| TIME | 当前时间,一个以 “HH:MM:SS” 格式表示的字符常量。 |
| FILE | 这会包含当前文件名,一个字符串常量。 |
| LINE | 这会包含当前行号,一个十进制常量。 |
| STDC | 当编译器以 ANSI 标准编译时,则定义为 1。 |
让我们来尝试下面的实例:
#include <stdio.h>
main()
{
printf("File :%s\n", __FILE__ );
printf("Date :%s\n", __DATE__ );
printf("Time :%s\n", __TIME__ );
printf("Line :%d\n", __LINE__ );
printf("ANSI :%d\n", __STDC__ );
}
当上面的代码(在文件 test.c 中)被编译和执行时,它会产生下列结果:
File :test.c
Date :Jun 2 2012
Time :03:36:24
Line :8
ANSI :1
预处理器运算符(注意一下平时用的少)
C 预处理器提供了下列的运算符来帮助您创建宏:
宏延续运算符(\)
一个宏通常写在一个单行上。但是如果宏太长,一个单行容纳不下,则使用宏延续运算符(\)。例如:
#define message_for(a, b) \
printf(#a " and " #b ": We love you!\n")
字符串常量化运算符(#)
在宏定义中,当需要把一个宏的参数转换为字符串常量时,则使用字符串常量化运算符(#)。在宏中使用的该运算符有一个特定的参数或参数列表。例如:
#include <stdio.h>
#define message_for(a, b) \
printf(#a " and " #b ": We love you!\n")
int main(void)
{
message_for(Carole, Debra);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Carole and Debra: We love you!
标记粘贴运算符(##)
宏定义内的标记粘贴运算符(##)会合并两个参数。它允许在宏定义中两个独立的标记被合并为一个标记。例如:
#include <stdio.h>
#define tokenpaster(n) printf ("token" #n " = %d", token##n)
int main(void)
{
int token34 = 40;
tokenpaster(34);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
token34 = 40
这是怎么发生的,因为这个实例会从编译器产生下列的实际输出:
printf ("token34 = %d", token34);
这个实例演示了 token##n 会连接到 token34 中,在这里,我们使用了**字符串常量化运算符(#)**和 标记粘贴运算符(##)。
defined() 运算符
预处理器 defined 运算符是用在常量表达式中的,用来确定一个标识符是否已经使用 #define 定义过。如果指定的标识符已定义,则值为真(非零)。如果指定的标识符未定义,则值为假(零)。下面的实例演示了 defined() 运算符的用法:
#include <stdio.h>
#if !defined (MESSAGE)
#define MESSAGE "You wish!"
#endif
int main(void)
{
printf("Here is the message: %s\n", MESSAGE);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Here is the message: You wish!
参数化的宏
CPP 一个强大的功能是可以使用参数化的宏来模拟函数。例如,下面的代码是计算一个数的平方:
int square(int x) {
return x * x;
}
我们可以使用宏重写上面的代码,如下:
#define square(x) ((x) * (x))
在使用带有参数的宏之前,必须使用 #define 指令定义。参数列表是括在圆括号内,且必须紧跟在宏名称的后边。宏名称和左圆括号之间不允许有空格。例如:
#include <stdio.h>
#define MAX(x,y) ((x) > (y) ? (x) : (y))
int main(void)
{
printf("Max between 20 and 10 is %d\n", MAX(10, 20));
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Max between 20 and 10 is 20
C 递归
递归指的是在函数的定义中使用函数自身的方法。
语法格式如下:
void recursion()
{
statements;
... ... ...
recursion(); /* 函数调用自身 */
... ... ...
}
int main()
{
recursion();
}
流程图:
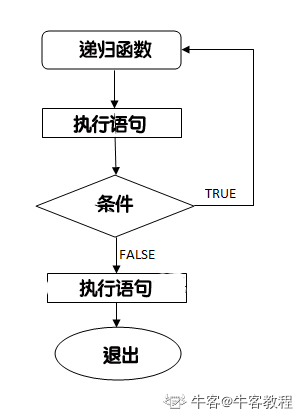
C 语言支持递归,即一个函数可以调用其自身。但在使用递归时,需要注意定义一个从函数退出的条件,否则会进入死循环。
数的阶乘
//下面的实例使用递归函数计算一个给定的数的阶乘:
#include <stdio.h>
double factorial(unsigned int i)
{
if(i <= 1)
{
return 1;
}
return i * factorial(i - 1);
}
int main()
{
int i = 15;
printf("%d 的阶乘为 %f\n", i, factorial(i));
return 0;
}
斐波那契数列
//下面的实例使用递归函数生成一个给定的数的斐波那契数列:
#include <stdio.h>
int fibonaci(int i)
{
if(i == 0)
{
return 0;
}
if(i == 1)
{
return 1;
}
return fibonaci(i-1) + fibonaci(i-2);
}
int main()
{
int i;
for (i = 0; i < 10; i++)
{
printf("%d\t\n", fibonaci(i));
}
return 0;
}
C 内存管理
C 语言为内存的分配和管理提供了几个函数。这些函数可以在 <stdlib.h> 头文件中找到。
| 序号 | 函数和描述 |
|---|---|
| 1 | void *calloc(int num, int size); 在内存中动态地分配 num 个长度为 size 的连续空间,并将每一个字节都初始化为 0。所以它的结果是分配了 num*size 个字节长度的内存空间,并且每个字节的值都是0。 |
| 2 | void free(void *address); 该函数释放 address 所指向的内存块,释放的是动态分配的内存空间。 |
| 3 | void *malloc(int num); 在堆区分配一块指定大小的内存空间,用来存放数据。这块内存空间在函数执行完成后不会被初始化,它们的值是未知的。 |
| 4 | void *realloc(void *address, int newsize); 该函数重新分配内存,把内存扩展到 newsize。 |
**注意:**void * 类型表示未确定类型的指针。C、C++ 规定 void * 类型可以通过类型转换强制转换为任何其它类型的指针。
动态分配内存
编程时,如果您预先知道数组的大小,那么定义数组时就比较容易。例如,一个存储人名的数组,它最多容纳 100 个字符,所以您可以定义数组,如下所示:
char name[100];
但是,如果您预先不知道需要存储的文本长度,例如您向存储有关一个主题的详细描述。在这里,我们需要定义一个指针,该指针指向未定义所需内存大小的字符,后续再根据需求来分配内存,如下所示:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char name[100];
char *description;
strcpy(name, "Zara Ali");
/* 动态分配内存 */
description = (char *)malloc( 200 * sizeof(char) );
if( description == NULL )
{
fprintf(stderr, "Error - unable to allocate required memory\n");
}
else
{
strcpy( description, "Zara ali a DPS student in class 10th");
}
printf("Name = %s\n", name );
printf("Description: %s\n", description );
}
当上面的代码被编译和执行时,它会产生下列结果:
Name = Zara Ali
Description: Zara ali a DPS student in class 10th
上面的程序也可以使用 calloc() 来编写,只需要把 malloc 替换为 calloc 即可,如下所示:
calloc(200, sizeof(char));
当动态分配内存时,您有完全控制权,可以传递任何大小的值。而那些预先定义了大小的数组,一旦定义则无法改变大小。
重新调整内存的大小和释放内存
当程序退出时,操作系统会自动释放所有分配给程序的内存,但是,建议您在不需要内存时,都应该调用函数 free() 来释放内存。
或者,您可以通过调用函数 realloc() 来增加或减少已分配的内存块的大小。让我们使用 realloc() 和 free() 函数,再次查看上面的实例:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char name[100];
char *description;
strcpy(name, "Zara Ali");
/* 动态分配内存 */
description = (char *)malloc( 30 * sizeof(char) );
if( description == NULL )
{
fprintf(stderr, "Error - unable to allocate required memory\n");
}
else
{
strcpy( description, "Zara ali a DPS student.");
}
/* 假设您想要存储更大的描述信息 */
description = (char *) realloc( description, 100 * sizeof(char) );
if( description == NULL )
{
fprintf(stderr, "Error - unable to allocate required memory\n");
}
else
{
strcat( description, "She is in class 10th");
}
printf("Name = %s\n", name );
printf("Description: %s\n", description );
/* 使用 free() 函数释放内存 */
free(description);
}
当上面的代码被编译和执行时,它会产生下列结果:
Name = Zara Ali
Description: Zara ali a DPS student.She is in class 10th
您可以尝试一下不重新分配额外的内存,strcat() 函数会生成一个错误,因为存储 description 时可用的内存不足。
C break 语句
C 语言中 break 语句有以下两种用法:
- 当 break 语句出现在一个循环内时,循环会立即终止,且程序流将继续执行紧接着循环的下一条语句。
- 它可用于终止 switch 语句中的一个 case。
如果您使用的是嵌套循环(即一个循环内嵌套另一个循环),break 语句会停止执行最内层的循环,然后开始执行该块之后的下一行代码。
break;
C continue 语句
C 语言中的 continue 语句有点像 break 语句。但它不是强制终止,continue 会跳过当前循环中的代码,强迫开始下一次循环。
对于 for 循环,continue 语句执行后自增语句仍然会执行。对于 while 和 do…while 循环,continue 语句重新执行条件判断语句。
continue;
例:以下程序中,while循环的次数是( )
main( )
{
int i=0;
while(i<10)
{
if(i<1)continue;
if(i==5)break;i++;
}
}
//死循环,不能确定次数
**解析:**break是结束整个循环体,continue是结束单次循环
此题执行if(i<1)continue; 后,结束单次循环,后面的if(i==5)break;i++; 将不被执行,故 i 仍等于0,进入死循环。
C goto 语句
C 语言中的 goto 语句允许把控制无条件转移到同一函数内的被标记的语句。
**注意:**在任何编程语言中,都不建议使用 goto 语句。因为它使得程序的控制流难以跟踪,使程序难以理解和难以修改。任何使用 goto 语句的程序可以改写成不需要使用 goto 语句的写法。
goto label;
..
.
label: statement;
C 排序算法
冒泡排序
冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序(如从大到小、首字母从A到Z)错误就把他们交换过来。
实例
#include <stdio.h>
#define ARR_LEN 255 /*数组长度上限*/
/* 冒泡排序 */
/* 1. 从当前元素起,向后依次比较每一对相邻元素,若逆序则交换 */
/* 2. 对所有元素均重复以上步骤,直至最后一个元素 */
/* int arr[]: 排序目标数组; int len: 元素个数 */
void bubbleSort (int arr[], int len)
{
int temp;
for (int i=0; i<len-1; i++) /* 外循环为排序趟数,len个数进行len-1趟 */
for (int j=0; j<len-1-i; j++) /* 内循环为每趟比较的次数,第i趟比较len-i次 */
{
if (arr[j] > arr[j+1]) /* 相邻元素比较,若逆序则交换(升序为左大于右,降序反之) */
{
temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
int main (void)
{
int arr[ARR_LEN] = {3,5,1,-7,4,9,-6,8,10,4};
int len=(int) sizeof(arr) / sizeof(*arr);
bubbleSort (arr, len);
for (int i=0; i<len; i++)
printf ("%d\t", arr[i]);
putchar ('\n');
return 0;
}
选择排序
选择排序是一种简单直观的排序算法。它的工作原理如下。首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
实例
void swap(int *a,int *b) //交换两个数
{
int temp = *a;
*a = *b;
*b = temp;
}
void selection_sort(int arr[], int len)
{
for (int i = 0 ; i < len - 1 ; i++) /* 外循环为排序趟数,len个数进行len-1趟 */
{
int min = i;
for (int j = i + 1; j < len; j++) //走访未排序的元素
if (arr[j] < arr[min]) //找到目前最小值
min = j; //记录最小值
swap(&arr[min], &arr[i]); //做交换
}
}
插入排序
插入排序(英语:Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到 {\displaystyle O(1)} {\displaystyle O(1)}的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
实例
void insertion_sort(int arr[], int len){
int i,j,temp;
for (i=1;i<len;i++){
temp = arr[i];
for (j=i;j>0 && arr[j-1]>temp;j--)
arr[j] = arr[j-1];
arr[j] = temp;
}
}
希尔排序
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
实例
void shell_sort(int arr[], int len) {
int gap, i, j;
int temp;
for (gap = len >> 1; gap > 0; gap = gap >> 1)
for (i = gap; i < len; i++) {
temp = arr[i];
for (j = i - gap; j >= 0 && arr[j] > temp; j -= gap)
arr[j + gap] = arr[j];
arr[j + gap] = temp;
}
}
归并排序
把数据分为两段,从两段中逐个选最小的元素移入新数据段的末尾。
可从上到下或从下到上进行。
迭代法
int min(int x, int y) {
return x < y ? x : y;
}
void merge_sort(int arr[], int len) {
int* a = arr;
int* b = (int*) malloc(len * sizeof(int));
int seg, start;
for (seg = 1; seg < len; seg += seg) {
for (start = 0; start < len; start += seg + seg) {
int low = start, mid = min(start + seg, len), high = min(start + seg + seg, len);
int k = low;
int start1 = low, end1 = mid;
int start2 = mid, end2 = high;
while (start1 < end1 && start2 < end2)
b[k++] = a[start1] < a[start2] ? a[start1++] : a[start2++];
while (start1 < end1)
b[k++] = a[start1++];
while (start2 < end2)
b[k++] = a[start2++];
}
int* temp = a;
a = b;
b = temp;
}
if (a != arr) {
int i;
for (i = 0; i < len; i++)
b[i] = a[i];
b = a;
}
free(b);
}
递归法
void merge_sort_recursive(int arr[], int reg[], int start, int end)
{
if (start >= end)
return;
int len = end - start, mid = (len >> 1) + start;
int start1 = start, end1 = mid;
int start2 = mid + 1, end2 = end;
merge_sort_recursive(arr, reg, start1, end1);
merge_sort_recursive(arr, reg, start2, end2);
int k = start;
while (start1 <= end1 && start2 <= end2)
reg[k++] = arr[start1] < arr[start2] ? arr[start1++] : arr[start2++];
while (start1 <= end1)
reg[k++] = arr[start1++];
while (start2 <= end2)
reg[k++] = arr[start2++];
for (k = start; k <= end; k++)
arr[k] = reg[k];
}
void merge_sort(int arr[], const int len) {
int reg[len];
merge_sort_recursive(arr, reg, 0, len - 1);
}
快速排序
在区间中随机挑选一个元素作基准,将小于基准的元素放在基准之前,大于基准的元素放在基准之后,再分别对小数区与大数区进行排序。
迭代法
typedef struct _Range {
int start, end;
} Range;
Range new_Range(int s, int e) {
Range r;
r.start = s;
r.end = e;
return r;
}
void swap(int *x, int *y) {
int t = *x;
*x = *y;
*y = t;
}
void quick_sort(int arr[], const int len) {
if (len <= 0)
return; // 避免len等於負值時引發段錯誤(Segment Fault)
// r[]模擬列表,p為數量,r[p++]為push,r[--p]為pop且取得元素
Range r[len];
int p = 0;
r[p++] = new_Range(0, len - 1);
while (p) {
Range range = r[--p];
if (range.start >= range.end)
continue;
int mid = arr[(range.start + range.end) / 2]; // 選取中間點為基準點
int left = range.start, right = range.end;
do
{
while (arr[left] < mid) ++left; // 檢測基準點左側是否符合要求
while (arr[right] > mid) --right; //檢測基準點右側是否符合要求
if (left <= right)
{
swap(&arr[left],&arr[right]);
left++;right--; // 移動指針以繼續
}
} while (left <= right);
if (range.start < right) r[p++] = new_Range(range.start, right);
if (range.end > left) r[p++] = new_Range(left, range.end);
}
}
递归法
void swap(int *x, int *y) {
int t = *x;
*x = *y;
*y = t;
}
void quick_sort_recursive(int arr[], int start, int end) {
if (start >= end)
return;
int mid = arr[end];
int left = start, right = end - 1;
while (left < right) {
while (arr[left] < mid && left < right)
left++;
while (arr[right] >= mid && left < right)
right--;
swap(&arr[left], &arr[right]);
}
if (arr[left] >= arr[end])
swap(&arr[left], &arr[end]);
else
left++;
if (left)
quick_sort_recursive(arr, start, left - 1);
quick_sort_recursive(arr, left + 1, end);
}
void quick_sort(int arr[], int len) {
quick_sort_recursive(arr, 0, len - 1);
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











