







1.产生背景
(1)MapReduce编程十分复杂。
(2)传统的RDBMS能满足一般的需求,但是不能处理大数据,需要一个SQL就能处理大数据的。
(3)这时结合前俩个缺点改进,就有了Hive
(4)提高Hive要想到:SQL on Hadoop(在Hadoop上用SQL来操作)
2.Hive基本概念
(1)Hive的作用:Apache蜂巢™数据仓库软件便于读,写,和管理大型数据集居住在分布式存储系统上使用SQL。结构(meta/schema)可以映射到存储中的数据。提供了一个命令行工具和JDBC(它的操作一般只拿结果,不去做计算)驱动程序来连接用户到Hive。
(2)Hive是构建在Hadoop之上的数据仓库。(HDFS存储,MapReduce/Spark/Tez执行引擎),可以用命令指定(
- set hive.execution.engine=spark/其他;
)
(3)Hive QL:他是类SQL,然后将SQL转成MapReduce/Spark/Tez的作业,提交到集群上去执行。
3.Hive发展历程
(1)08/2007:FaceBook推出的
(2)05/2013: 0.11.0版本 Stinger phase1优化:推出了ORC存储格式和HiveServer2
补充ORC:它是Hadoop生态圈中的列式存储格式,用于降低Hadoop数据存储空间和加速Hive查询速度,有以下优点
1)ORC是列式存储,有多种文件压缩方式,并且有着很高的压缩比。
2)文件是可切分(Split)的。因此,在Hive中使用ORC作为表的文件存储格式,不仅节省HDFS存储资源,查询任务的输入数据量减少,使用的MapTask也就减少了。
3)提供了多种索引,row group index、bloom filter index。
4)ORC可以支持复杂的数据结构(比如Map等)
(3)10/2013:0.12.0 Stinger phase2优化:ORC improve
(4)04/2014:0.13.0 Stinger phase3优化:Vectorized query engine(向量化查询引擎) / Tez(执行引擎推出)
(5)11/2014:0.14.0 Stinger.next phase1 Cost-based optimizer(CBO:判断出最优的执行计划来使用)
(6)1.0.0 ....... 有关Stringer的描述:Making Apache Hive 100 Times Faster(能快一百个数量级,夸张的说法)
4.Hive的优点
(1)简单易用
(2)扩展性强:内存不够加机器,资源不够加Core(Hive不是集群啊,是个客户端)
(3)统一的元数据管理(元数据字段database tablename colum location)元数据一般存在MySQL里面,好处是和其他框架共享元数据之后,就能直接使用,例如SparkSQL处理。解决了一定的权限问题
5.体系架构
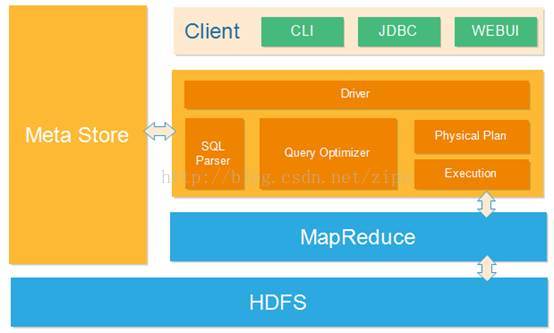
(1)首先访问Hive的方式有三种,CLI、JDBC和WEBUI和Driver交互,然后SQL解析,逻辑执行计划,抽象语法树那些,再对SQL进行优化,最后生成物理执行计划,通过Exection生成MapReduce作业来出咯HDFS上的数据。
(2)上面是右边的,现在我们看Meta Store是有数据的位置信息的,和抽象语法树实现交互。
6.Hive部署安装
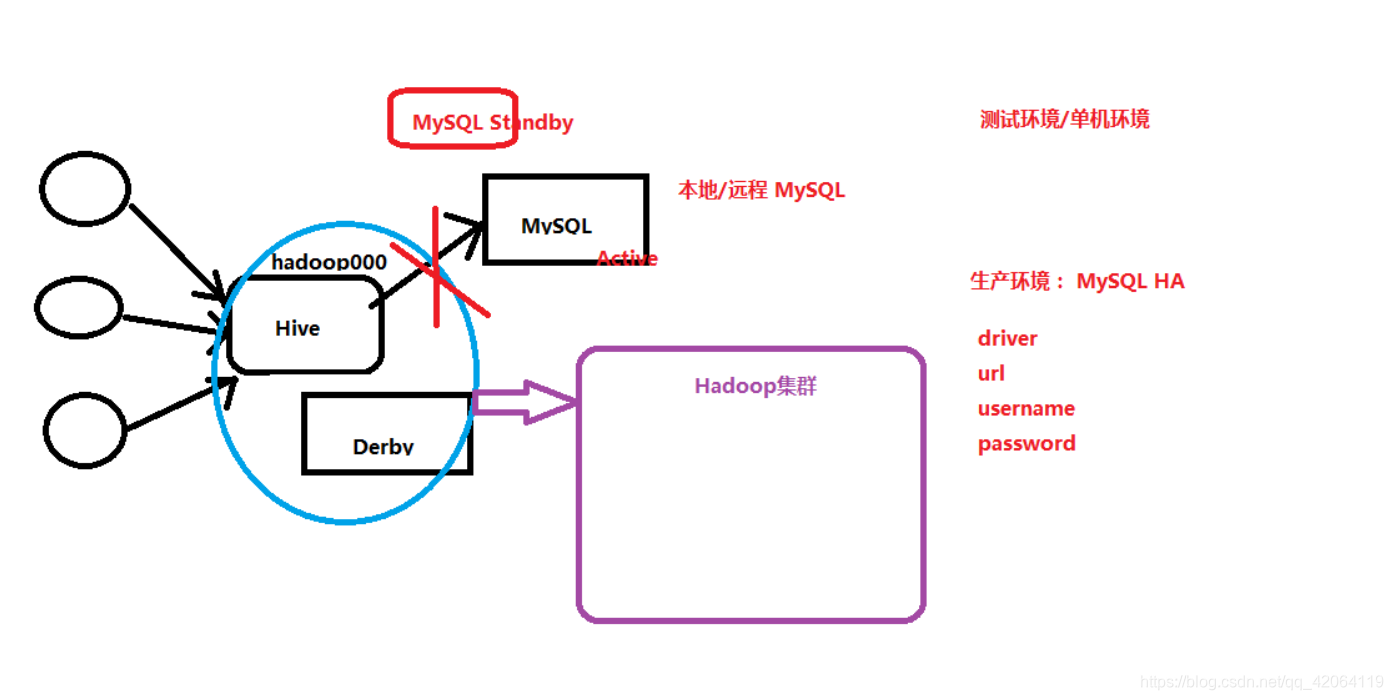
(1)概述:随便找一台机器部署Hive然后关联HDFS,和元数据存储在MySQL中就好了,这只是测试环境,在生产中你的MySQL必须要保证,MySQL是HA的,不然它过了整个HIve架构就废了。访问SQL需要哪些东西?驱动(Driver)、url、权限。(2)下载hive:wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.7.0.tar.gz
(3)解压: tar -zxvf ....... -C ~/app/
(4)配置环境变量: ~/.bash_profile
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0
export PATH=$HIVE_HOME/bin:$PATH
(5)拷贝驱动:cp mysqldriver $HIVE_HOME/lib //这个是要连MySQL来存储元数据的
(6)配置文件修改
cp hive-env.sh.template hive-env.sh
HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0
hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/ruozedata_basic02?createDatabaseIfNotExist=true</v
alue>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
[hadoop@hadoop000 conf]$ clear
[hadoop@hadoop000 conf]$ cat hive-
cat: hive-: No such file or directory
[hadoop@hadoop000 conf]$ cat hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
//自己选取有用的
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/ruozedata_basic03?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration> (7)记一个坑
上面配置了元数据库在MySQL中的,但是如果MySQL GG了,或者Hadoop home目录变了Hive就会怎么都连不起来了,创建表也不行。。。。。
Hive表创建报错,具体日志信息如下:
com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Specified key was too long; max key length is 767 bytes
字符集错误,修改元数据库的编码就可以啦
alter database ruozedata_basic03 character set latin1;
7.Hive和RDBMS的异同点?
(1)俩个都是写SQL
(2)RDBMS的实时性是较为看重的,但Hive是看重的是大数据的分析和统计,延迟性较高一个作业跑几小时很正常。
(3)RDBMS存储的数据量不能多,即使分布式布置也不能太多,且成本高,Hive就可以,因为底层存储的是HDFS。
(4)事务/insert/update,在Hive(0.14版本之后)中一般不用,因为是批次执行的,挂了就重来。
8.为什么生产环境中要CDH/HDP这种商业版的,而不用Apache的?
答:因为CDH/HDB版本的兼容性要比Apache的强许多。多框架整合jar包冲突很麻烦的!
注意选择统一的cdh尾号!!!你别搞5.7.0的Hadoop和5.2.0的Hive,容易出问题。
统一CDH系列下载路径:统一软件安装包下载路径:http://archive.cloudera.com/cdh5/cdh/5/
9.Hive的日志查看
(1)系统日志存储
在${HIVE_HOME}/conf/hive-log4j.properties 文件中记录了Hive日志的存储情况
(2)重命名hive-log4j.properties.template hive-log4j.properties
默认的存储情况:$
hive.root.logger=WARN,DRFA
hive.log.dir=/tmp/${user.name} # 默认的存储位置是/tmp这个临时目录(这个目录就好像Windows的回收站)
hive.log.file=hive.log # 默认的文件名
可以自己修改
10.什么叫结构化数据和非结构化数据和半结构化数据?
(1)相对于结构化数据(即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据)而言,
(2)不方便用数据库二维逻辑表来表现的数据即称为非结构化数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。
(3)字段可根据需要扩充,即字段数目不定,可称为半结构化数据


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









