







zookeeper介绍
Zookeeper概念
简化分布式应用,协调其管理的难度,提供高性能的分布式服务(数据管理、统一命名、状态同步、集群管理、分布式应用配置项的管理)
Zookeeper目标
封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户
ZooKeeper工作方式
本身可以以Standalone模式安装运行,不过它的长处在于通过分布式ZooKeeper集群(一个Leader,多个Follower),基于一定的策略来保证ZooKeeper集群的稳定性和可用性,从而实现分布式应用的可靠性
Zookeeper的特点
| 特点 | 说明 |
|---|---|
| 最终一致性 | 为客户端展示同一个视图 |
| 可靠性 | 如果消息被一台服务器接受,那么它将被所有的服务器接受 |
| 实时性 | Zookeeper不能保证两个客户端能同时得到刚更新的数据(可在读数据之前调用sync()接口获取最新数据) |
| 独立性 | 各个Client之间互不干预 |
| 原子性 | 更新只能成功或者失败,没有中间状态 |
| 顺序性 | 所有Server同一消息发布顺序一致 |
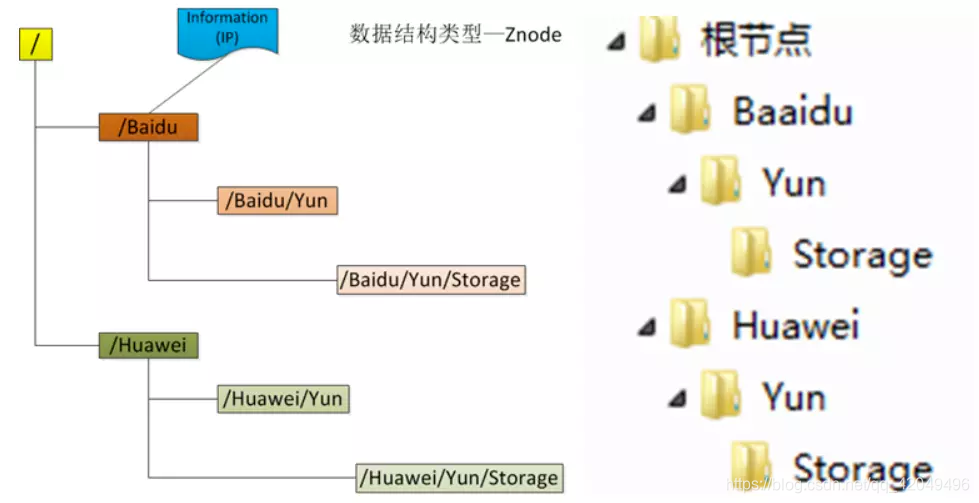
Zookeeper数据类型
分层的文件系统目录树结构,规定同一个目录下只能存在唯一文件名
- PERSISTENT 持久化节点,节点创建后,不会因为会话失效而消失
- EPHEMERAL 临时节点, 客户端session超时此类节点就会被自动删除
- EPHEMERAL_SEQUENTIAL 临时自动编号节点
- PERSISTENT_SEQUENTIAL 顺序自动编号持久化节点,这种节点会根据当前已存在的节点数自动加1
Zookeeper工作原理
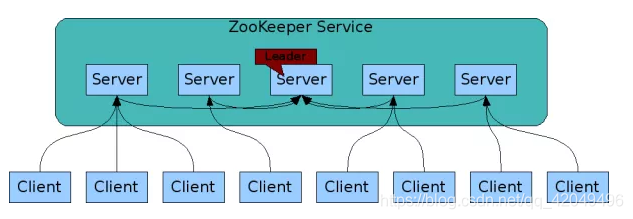
每个Server在内存中存储了一份数据;
Zookeeper启动时,将从实例中选举一个leader (Paxos协议:分布式一致性算法);
Leader负责处理数据更新等操作(ZAB协议) ;
当且仅当大多数Server在内存中成功修改数据,一个更新操作成功。
安装并配置zookeeper集群
环境准备
本实验在elasticsearch集群节点上部署,环境准备同elasticsearch
集群配置
(1)配置JDK
(2)zookeeper下载与安装
[root@zookeeper01 ~]# wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
[root@zookeeper01 ~]# tar xf zookeeper-3.4.14.tar.gz -C /data/program/software
[root@zookeeper01 ~]# cd /data/program/software
[root@zookeeper01 software]# mv zookeeper-3.4.14 zookeeper
[root@zookeeper01 zookeeper]# cd zookeeper
#创建数据和日志目录
[root@zookeeper01 zookeeper]# mkdir {data,logs}
[root@zookeeper01 zookeeper]# cd conf/
[root@zookeeper01 zookeeper]# cp conf/zoo_sample.cfg conf/zoo.cfg
#修改zoo.cfg配置文件
[root@zookeeper01 zookeeper]# vim conf/zoo.cfg
dataDir=/data/program/software/zookeeper/data
dataLogDir=/data/program/software/zookeeper/logs
clientPort=2181
server.1=zookeeper01:2881:3881
server.2=zookeeper02:2881:3881
server.3=zookeeper03:2881:3881
#编辑myid文件,在对应的IP的机器上输入对应的编号
[root@zookeeper01 zookeeper]# echo "1" >data/myid
启动测试
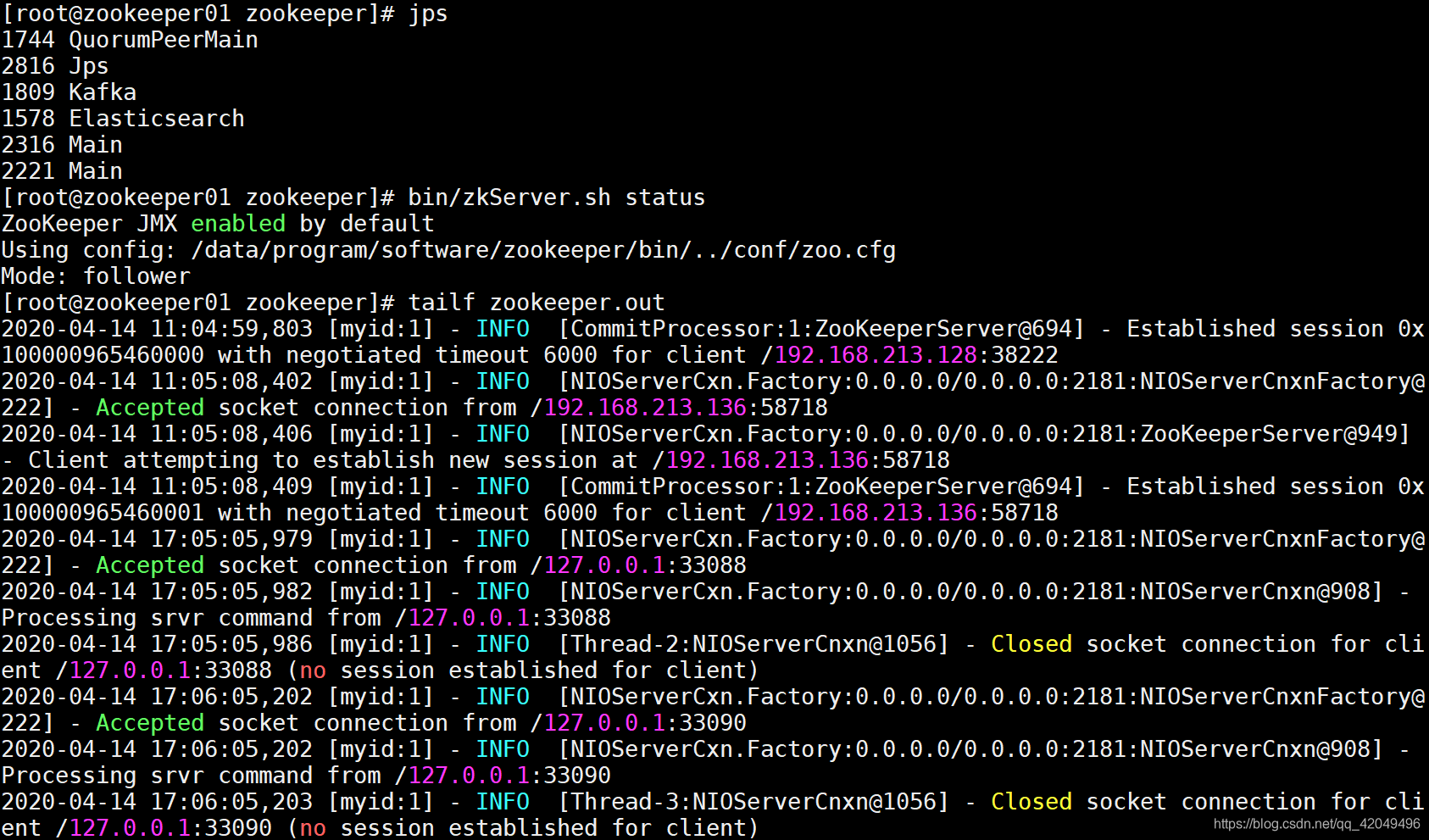
[root@zookeeper01 zookeeper]# bin/zkServer.sh start
查看进程 jps QuorumPeerMain是zookeeper进程,有说明启动正常
查看状态 bin/zkServer.sh status
查看zookeeper服务输出信息 tailf zookeeper.out
知识总结
(1)Zookeeper底层是如何实现的?
使用Paxos协议选举Leader节点,使用原子消息广播协议ZAB保持数据一致
(2)了解CAP原理,Paxos协议,ZAB协议
CAP原理:一个数据分布式系统不可能同时满足C(Consistency一致性),A(Availability可用性),P(Partition tolerance分区容忍性[在时限内达成数据一致性])3个条件
Paxos协议:用于解决分布式系统中一致性问题(将所有节点都写入同一个值,且被写入后不再更改)
Zab协议: 保证分布式事务的最终一致性,借鉴了Paxos算法,是特别为Zookeeper设计的支持崩溃恢复的原子广播协议
(3)为什么zookeeper集群的数目,一般为奇数个?
- 防止由脑裂造成的集群不可用
- 在容错能力相同的情况下,奇数台更节省资源
(4)Filebeat和Logstash实现原理对比?
当开启filebeat程序的时候,它会启动一个或多个探测器(prospectors)去检测指定的日志目录或文件,对于探测器找出的每一个日志文件,filebeat都会启动一个收割进程(harvester)读取日志文件的新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后filebeat会发送集合的数据到指定的地点。
Logstash事件处理管道有三个阶段:输入→过滤器→输出,输入生成事件,过滤器修改它们,然后输出将它们发送到其他地方。输入和输出支持编解码器,使你能够在数据进入或离开管道时对其进行编码或解码,而无需使用单独的过滤器。
(5)Kafka和redis在应用上有什么不同?都有哪些应用场景?
- Kafka与Redis PUB/SUB之间较大的区别在于Kafka是一个完整的系统,而Redis PUB/SUB只是一个套件(utility)
- Redis 消息推送(基于分布式pub/sub)多用于实时性较高的消息推送,并不保证可靠,Kafka保证可靠但有一些延迟
- redis-pub/sub断电就清空,而使用redis-list作为消息推送虽然有持久化,但并非完全可靠不会丢失
- Redis 发布订阅除了表示不同的topic 外,并不支持分组,而Kafka中发布一个东西,多个订阅者可以分组,同一个组里只有一个订阅者会收到该消息,这样可以用作负载均衡
- Kafka消费元数据是保存在consumer端的,所以对于消费而言consumer被赋予极大的自由度。consumer可以顺序地消费消息,也可以重新消费之前处理过的消息,这是Redis PUB/SUB无法做到的
| 软件 | 使用场景 |
|---|---|
| Redis PUB/SUB | 1. 消息持久性需求不高 2. 吞吐量要求不高 3. 可以忍受数据丢失 4. 数据量不大 |
| Kafka | 1. 高可靠性 2. 高吞吐量 3. 持久性 4. 多样化的消费处理模型 |

















 399
399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









