




 本文讲述了在爬取使用stonefont字体的电影网站票价信息时遇到的问题及解决方案。作者通过分析网页源代码,下载字体库文件,并使用FontCreator软件查看字形定义,建立数字与编号的对应关系,实现字符解码,从而正确获取票价信息。
本文讲述了在爬取使用stonefont字体的电影网站票价信息时遇到的问题及解决方案。作者通过分析网页源代码,下载字体库文件,并使用FontCreator软件查看字形定义,建立数字与编号的对应关系,实现字符解码,从而正确获取票价信息。
一、问题描述
在爬取某电影网站票价信息时,使用selenium定位票价元素信息时,发现票价显示“□□”,如下图所示:
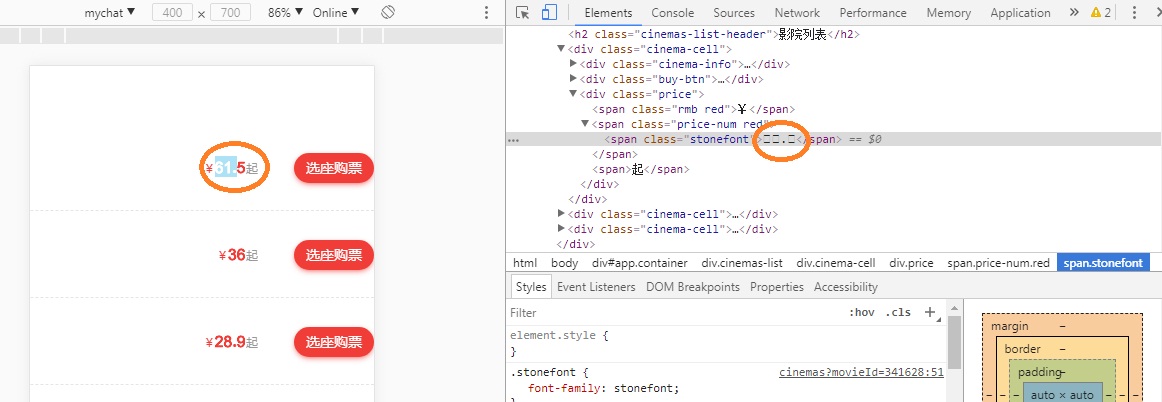
而通过chrome浏览器“查看网页源代码”方式查看该元素数值时,显示的是非正常票价数值,如下图所示:

二、 问题解决思路
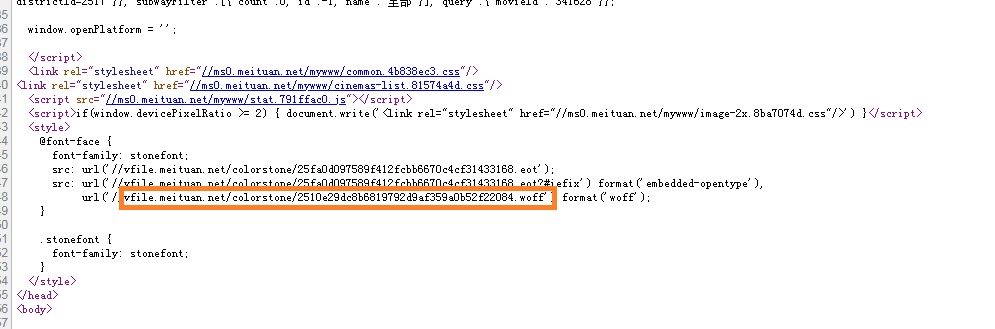
百度查询相关解决方案,发现该网页使用了web-font字体,网页在打开时调用美团字体库对页面中数值进行渲染,需要找出当前网页使用的字体库,因为每次打开网页调用的字体库不一样, 所以需要每次都与基本库字形进行对比,找出实际对应的数字。在该网页源代码中字体库地址如下图所示:
三、解决流程
1、环境
from selenium import webdriver from selenium.webdriver.chrome.options import Options from fontTools import ttLib
FontCreator软件,用于查看下载的字体库文件,可以比较直观的查看字形定义和字形代码。
2、解决流程
1)下载字体文件
下载网页字体库文件woff,保存到电脑中(文件后缀为woff),用于建立用于后期对比的基本字形库(字形名和字形定义),只下载一次即可。需要使用正则表达式搜索网页源代码中字体下载地址。这部分功能用的requests库,其它用的selenium,其实也可以全部用selenium,requests和selenium在解决该类问题时的区别在后面再说一下。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









