




如何爬一个网站的数据?大家熟知的就是python爬取网页数据,对于没有编程技术的普通人来说,怎么才能快速的爬取网站数据呢?今天给大家分享的这款免费爬取网页数据软件让您可以轻松地爬取网页指定数据,不需要你懂任何技术,只要你点点鼠标,就会采集网站任意数据!从此告别复制和粘贴的工作,爬取的数据可导出为Txt文档 、Excel表格、MySQL、SQLServer、 SQlite、Access、HTML网站等(PS:如果你爬取的是英文数据还可以使用自动翻译)
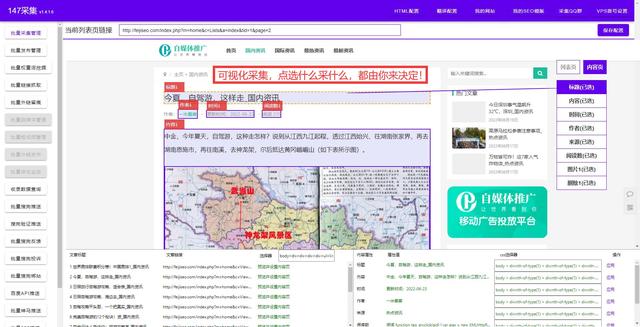
1. 网站数据爬取技巧
网站数据爬取技巧:
\1. 分析网站结构:查看网页的HTML源代码,找到数据所在的标签。
\2. 使用爬虫工具:如Scrapy、BeautifulSoup等。
\3. 设置请求头:防止被网站防爬虫机制识别。
\4. 实现分页爬取:爬取多页数据时要注意分页的参数。
\5. 遵守网站的使用条款:不要过于频繁爬取网站数据,避免影响网站正常运行。
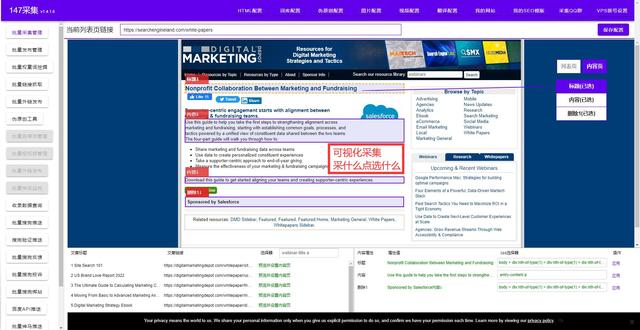
2. 利用Python爬取网站数据
Python爬虫是指利用Python语言编写的程序,通过请求网站数据并解析数据,从而抓取网站上的信息。主要使用的库有BeautifulSoup、 Requests、Scrapy等。爬虫可以用于抓取大量数据,供数据分析、搜索引擎优化等用途。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









