







官网教程:https://tensorflow.google.cn/text/guide/word_embeddings
独热编码
作为第一个想法,您可以对词汇表中的每个单词进行“one-hot”编码。比如下面的句子 “The cat sat on the mat”.这个句子中的词库是(cat, mat, on,sat, the ).为了表示每个单词,需要创建跟词库长度一样的零向量,然后在对应单词的下标处置1.如下所示
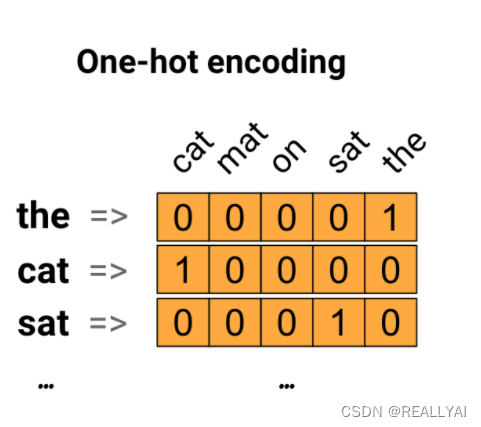
创建长度为5的零向量[0, 0, 0, 0, 0].[1, 0, 0, 0, 0]表示cat;[0,1,0,0,0]表示mat;[0,0,1,0,0]表示on以此类推 sat[0,0,0,1,0]跟the[0,0,0,0,1]。因此"The cat sat on the mat"句子用以下矩阵表示
[0,0,0,0,1] the
[1,0,0,0,0] cat
[0,0,0,1,0] sat
[0,0,1,0,0] on
[0,0,0,0,1] the
[0,1,0,0,0] mat
提示:这种方法是低效的。一个独热编码向量是稀疏的(意味着,大部分下标是0).假如一个词库有1万个单词。对每个单词进行独热编码,会得到一个99.99%的元素为0的向量。
用独特数字编码每个单词
你可以尝试的第二种方法是用一个独特的数字来编码每个单词。在上述示例中,可以给’cat’赋值1,'mat’赋值2等等。将句子 "The cat sat on the mat"编码为如[5, 1, 4, 3, 5, 2]的密集向量。这种方法是有效的。替代稀疏向量,现在有一个元素全满了的密集向量。
然而这个方法有两个缺点:
- 整数编码是任意的(并没有捕捉词与词之间的任何关系)
- 整数编码对于模型解析可能是有挑战的。比如,一个线性分类器对每个特征学习一个单个的权重。由于在任何两个单词间的相似度与编码的相似度之间没有联系,特征-权重结合是没有意义的。
词嵌入(word embeddings)
词嵌入给我们提供了一个相似单词有相似的编码的有效的密集的表示。重要地是,不需要手动地指定这种编码。一个embedding是一个浮点值向量(向量的长度是你指定的参数).替代手动指定embedding的值,它们是可以训练的参数(在训练期间由模型学到的权重,同样地方式模型为了一个密集层学习权重)。通常能看到8维(对于小数据集)到当处理大数据集的1024维的词嵌入。一个更高维的embedding能捕捉词之间的细粒度关系,但需要更多的数据来学习。
一个4维的embedding
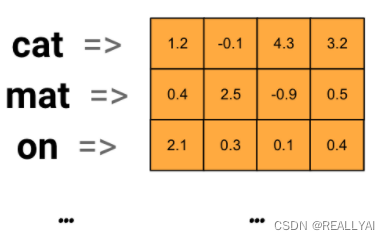
上图是一个词嵌入图。每个单词被表示为一个四维的浮点数值向量。思考一个embedding的方式是作为查找表。学习好这些权重之后,你可以通过在表中查找每个单词对应的密集向量来编码。
实验搭建参考官网教程


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









