







 针对搜索场景中关键字搜索的语义匹配难题,本文介绍了技术选型与实施方案,包括选择SentenceBERT的原因及其优势,利用SimCSE构建弱监督数据的方法,以及模型优化策略如模型压缩、TensorRT加速等。
针对搜索场景中关键字搜索的语义匹配难题,本文介绍了技术选型与实施方案,包括选择SentenceBERT的原因及其优势,利用SimCSE构建弱监督数据的方法,以及模型优化策略如模型压缩、TensorRT加速等。
目录
飞桨AI Studio - 人工智能学习实训社区 (baidu.com)共七节课,本文为第一节课
万方的搜索场景中,关键字搜索需要语义相似,针对这个需求,在技术选型和方案实施中,word2vec和fasttext太简单了、bert计算量太大且LM模型不能满足各向异性,最后选择了表示模型和交互模型的sentencebert,其对bert进行改造使用了双塔结构。
为了将大规模的无监督数据利用起来,可以用SimCSE构造弱监督数据,这也是一种数据增强的方法。(用自己的语料训练一个bert,对其微调构建出SimCSE,SimCSE可以构建出弱监督的数据,放进语义索引训练得到sentencebert,再用标注数据通过sentencebert得到向量,经过排序模型就可以在构建一批弱监督数据,对之前的弱监督数据进行增强,继续训练sentencebert)
SimCSE是一个简单的对比学习,句子通过encoder其实就是bert,得到两个不同的向量,作为正例去学习。原生满足alignment、uniform和anisotropy三个指标。
在模型优化部分,优化策略分别是模型裁剪(减少层数)、动态图转静态图、tensorRT加速等方法,优化效果按序成倍递增,这些都可以在PP中用寥寥几行代码来实现。未来可以尝试在线学习和图神经网络的方法,图神经网络可以学习到深层语义
一、搜索场景中的技术难点
按关键字搜索时,字面相似但语义不相关
“人工智能在数字图书馆中的应用” 检索结果为 “人工智能在图书馆数字阅读推广服务中的应用”
二、技术选型与方案实施
- 搜索系统架构
- 全文搜索引擎
- 向量搜索引擎
2.1 相关性的两个维度
- 字面匹配:利用solr或ess做召回
- 语义匹配:利用向量引擎做召回
2.2 文本相关性
- TF-IDF:TF文档频率,当前检索词在文档中出现次数越多这篇文档越重要。IDF当前的query在所有的文档中出现的次数越多这篇文档越重要
(1)TF是词频(Term Frequency)
词频(TF)表示词条(关键字)在文本中出现的频率。这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。
公式:
即:
其中 ni,j 是该词在文件 dj 中出现的次数,分母则是文件 dj 中所有词汇出现的次数总和;
(2) IDF是逆向文件频率(Inverse Document Frequency)
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
公式:
其中,|D| 是语料库中的文件总数。 |{j:ti∈dj}| 表示包含词语 ti 的文件数目(即 ni,j≠0 的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{j:ti∈dj}|
即:

(3)TF-IDF实际上是:TF * IDF
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。公式:

注: TF-IDF算法非常容易理解,并且很容易实现,但是其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况。

- 词频/权重/覆盖率
- 紧密度/同义词
2.3 词向量模型
word2vec和fasttext太浅,太简单了,不能满足深度语义提取
希望来使用bert和ERNIE,文本相关和语义文本相似度sts任务上表现的很好
2.4 bert不能用
做语义相似度的搜索使用原生bert需要拼接query和document来作为输入,计算量非常大训练时间非常久,基于bert的预训练模型直接获取embedding是不能达到预期目标的。
2.5 选择了表示模型和交互模型
- 表示模型,特征提取器提取文本特征,DSSM是双卡模型的一个典型代表,用两个encoder来分别获取query和document的表示
- 交互模型,模型学习文本之间交互的特征
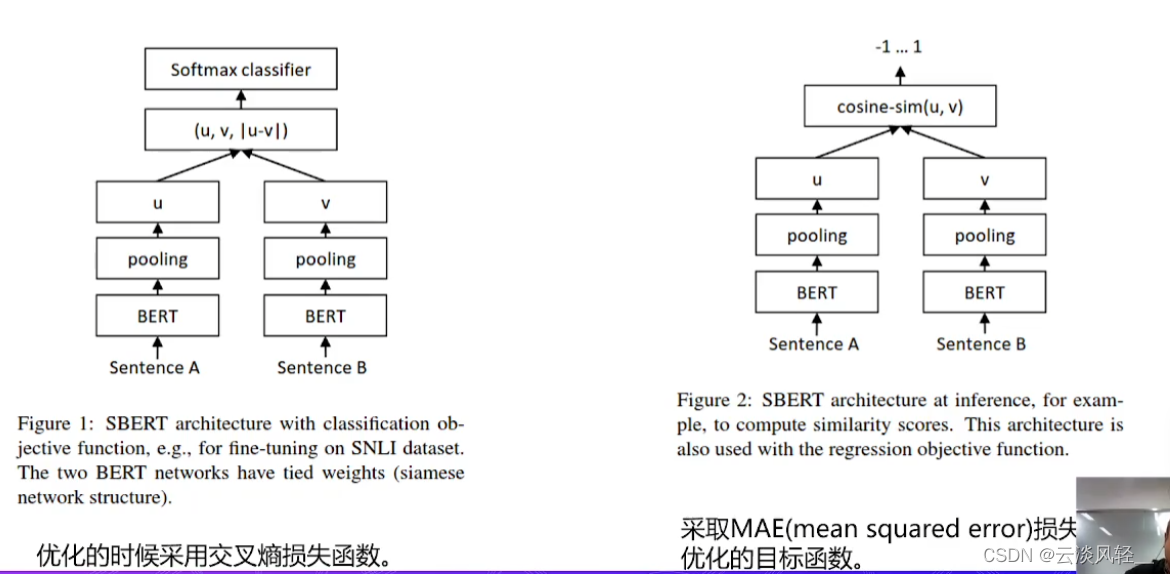
2.6 sentencebert
对预训练bert修改,使用了双塔结构
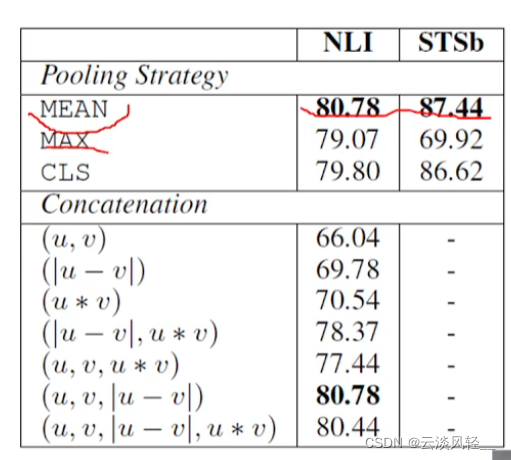
trick:对词向量做平均的效果最好
三、无监督数据使用&模型训练&优化&评估
3.1 只有大规模无监督数据怎么办?
- 用大规模的无监督数据构造弱监督数据
- word deletion
- reordering
- substitution
- word2vec+faiss:也是数据增强的一种方法(早期的数据增强:数据做同义词替换、随机删除无监督)
- 用无监督数据训练一个Word2vec模型称为bow模型
- 然后大规模的无监督语料通过bow模型算出一个向量来(5000个无监督语料获得5000个vector)
- 放到faiss里去(也可以用其他,主要是因为faiss召回比较快所以选用),此时faiss中有5000个向量,接下来如何构建无监督数据?
- 假如要构建10个弱监督数据,在faiss中进行搜索,按照top为2来搜索的话,10个query可以得到20个document
- 每一个query和document都可以构造成一个弱监督数据,作为正样本给sentencebert去学习
- simcse:比较流行的方法
- 用户行为日志:点击语料
- 业务标注监督数据
3.2 PaddleNLP检索场景解决方案

- 有标注、弱监督、无监督数据场景下都可以使用
- 性能很好
- 模型非常丰富,都做好了
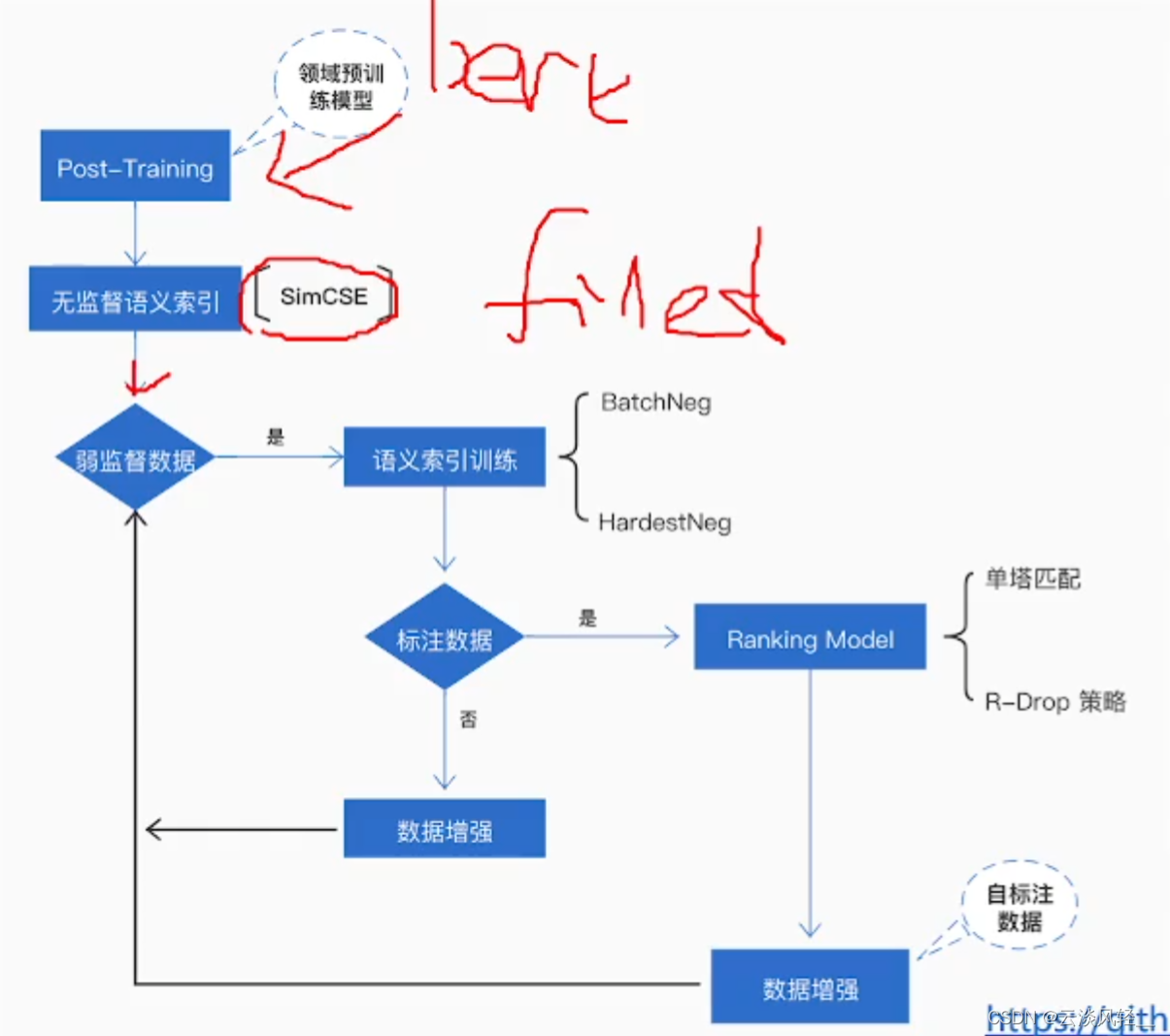
- 可以基于自己的语料训练出一个bert
- 对bert做微调,构建一个simcse模型
- 基于simcse就可以构建弱监督的数据
- 弱监督数据就可以放进语义索引训练,训练出sentencebert模型
- 如果我们的业务场景是有标注数据的,通过sentencebert就可以得到向量,用这个向量来得到ranking model,有了排序模型就可以通过行为日志再构建一批弱监督数据,可以对之前的弱监督数据进行增强。又可以通过增强后的数据来训练sentencebert
- 没有标注数据的话,也可以sentencebert做数据增强,扩充弱监督数据,依然是一个环
3.3 SimCSE
- 简单的一个对比学习,在CV领域比较流行,对图像数据变换来扩充数据
- 做法就是,一个句子通过一个encoder(其实就是bert)得到两个向量(前馈神经网络,随机删除神经元不参加计算,所以能得到两个不同的向量),把这两个向量作为一个正样本去学习。
- 指标:alignment和uniform,分布均匀:两个正样本挨得近,正负样本尽量远,希望词向量尽可能在球面是均匀分布。
- anisotropy各向异性,
- LM和MLM的词向量分布不均,锥形,高频词在尖上,低频词稀疏(空位是没有语义特征的,若词向量相加成为一个句子向量,恰好加到了空位置,计算相似度或者说距离的时候很有问题)且在后面,就不满足各向异性,用它来计算相似度是不行的。
- 提出的一些解决方法
- bert-flow:把各向异性的空间做mapping映射到一个均匀的高斯分布上去
- 加一些正则化
- simcse原生就具有各向异性
四、模型优化
4.1 模型性能优化
- 模型压缩
- 模型裁剪、量化
- 低秩因式分解
- 卷积滤波器
- 知识蒸馏
- tiny版预训练模型
4.2 模型层数12压缩到6层&动态图转静态图(训练阶段)
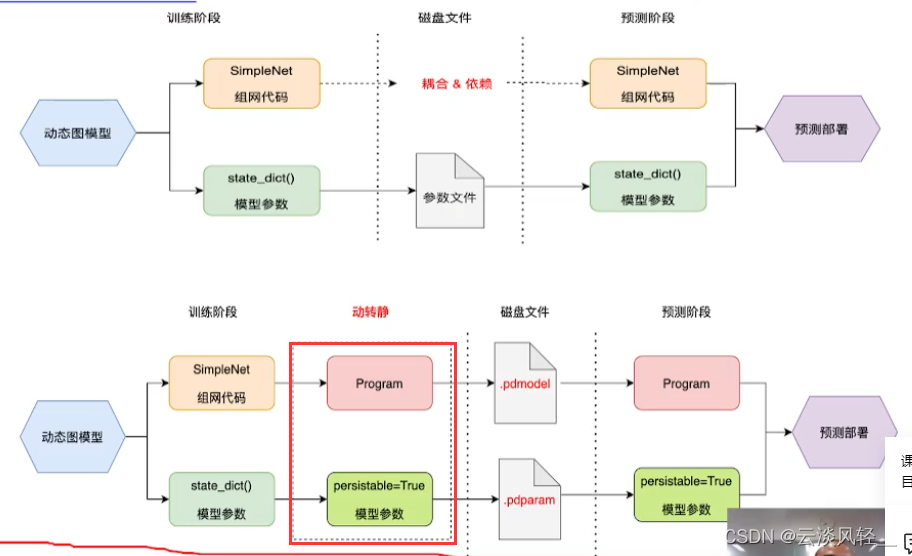
PP一行代码就可以动转静态图
4.3 tensorRT加速(推理阶段)
- 把训练好的模型进行加速,可以直接将训练好的模型丢进去,不需要依赖深度模型框架了(paddlepaddle或tensorflow)
- 可以认为tensorRT是只有前向网络的传播的深度学习框架
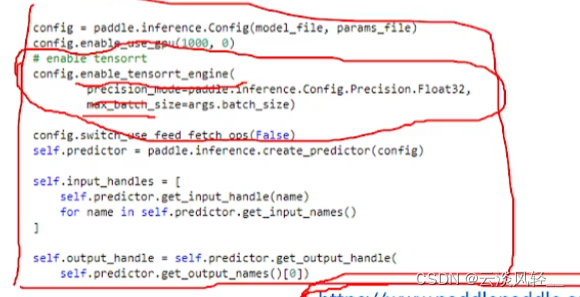
PP提供了,两行代码就可以实现tensorRT的加速
4.4 性能提升效果
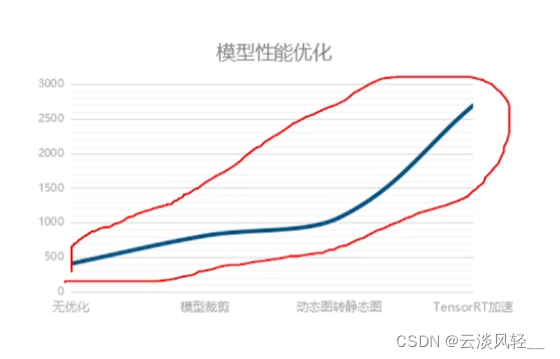

- 模型裁剪
- 动静转换
- tensorRT加速 :优化非常明显!
五、未来方向
- online learning在线学习,因为现在都是离线学习
- graph embedding图神经网络可以学到深层语义


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









