






 本文介绍了并查集的基本概念,详细解析了并查集的API实现过程,并针对原始算法进行了优化,包括路径压缩和加权并查集两种优化手段,提高了算法效率。
本文介绍了并查集的基本概念,详细解析了并查集的API实现过程,并针对原始算法进行了优化,包括路径压缩和加权并查集两种优化手段,提高了算法效率。
并查集
1、并查集概念
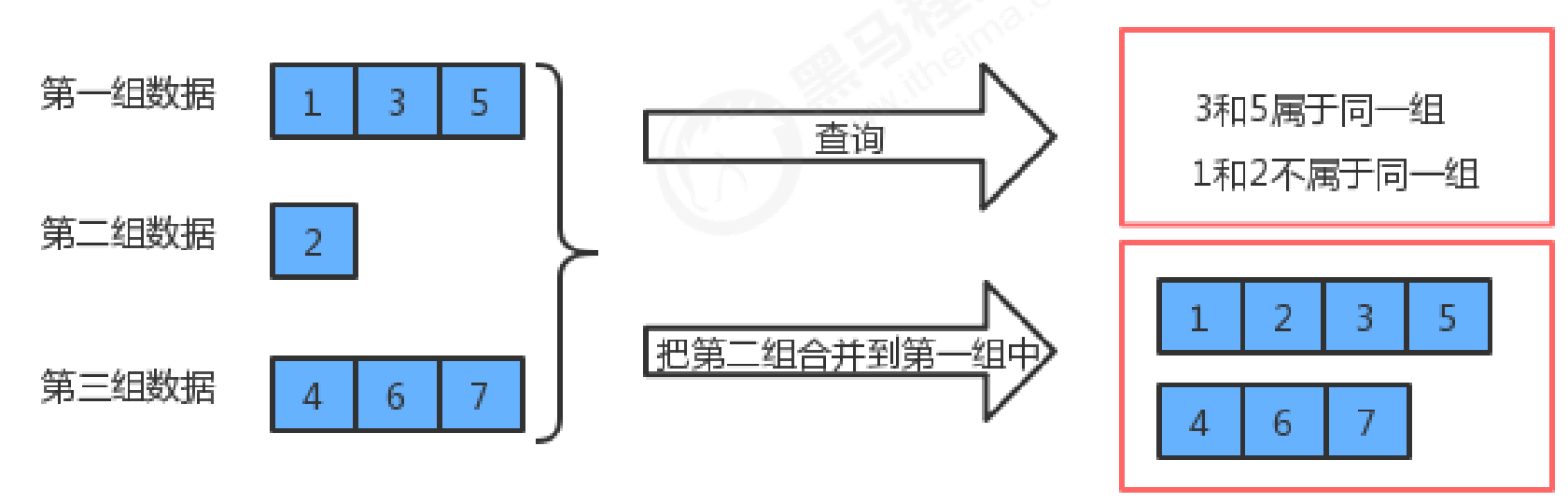
并查集是一种树型的数据结构,并查集可以高效地进行如下操作:
- 查询元素p和元素q是否属于同一组
- 合并元素p和元素q所在的组
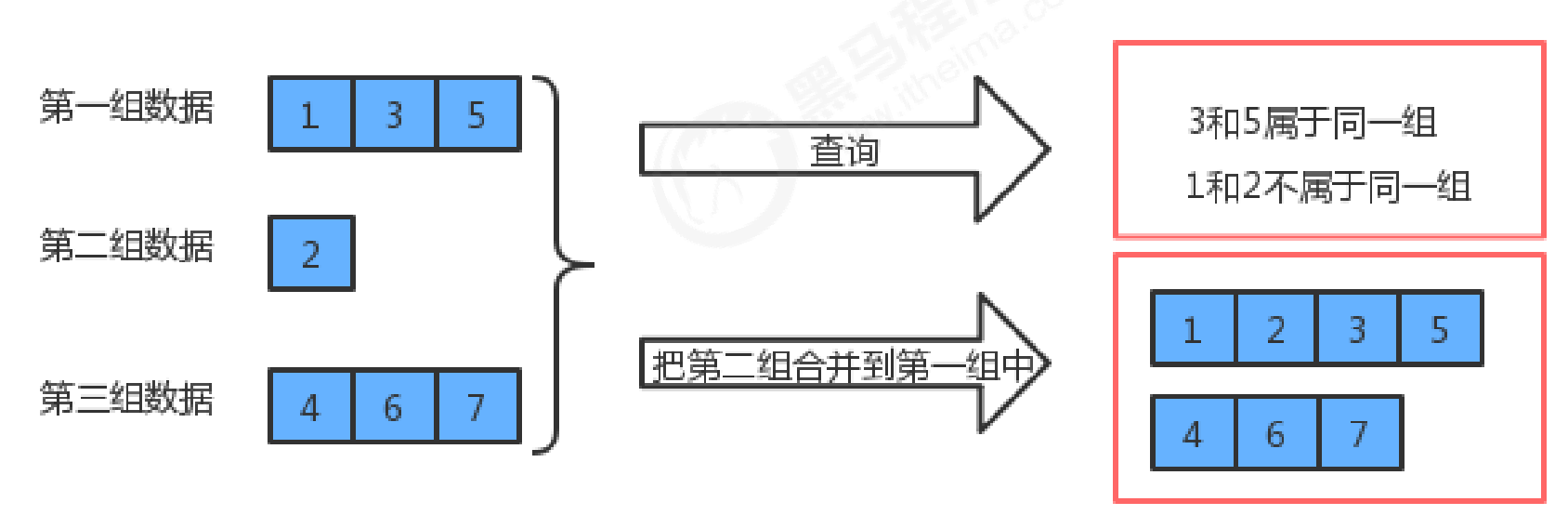
并查集也是一种树型结构,但这棵树跟我们之前讲的二叉树、红黑树、B树等都不一样,这种树的要求比较简单:
- 每个元素都唯一的对应一个结点;
- 每一组数据中的多个元素都在同一颗树中;
- 一个组中的数据对应的树和另外一个组中的数据对应的树之间没有任何联系;
- 元素在树中并没有子父级关系的硬性要求;
2、并查集API实现
package study.algorithm.uf;
public class UF {
//记录节点元素和该元素所在分组的标识
private int[] eleAndGroup;
//记录并查集中数据的分组个数
private int count;
//初始化并查集
public UF(int N) {
//初始化分组的数量
this.count = N;
//初始化eleAndGroup数组
this.eleAndGroup = new int[N];
//初始化eleAndGroup中的元素及其所在的组的标识符,让eleAndGroup数组的索引作为并查集的每个节点的元素,
// 并且让每个索引处的值(该元素所在组的标识)就是该索引
for (int i = 0; i < eleAndGroup.length; i++) {
eleAndGroup[i] = i;
}
}
//获取当前并查集中的数据有多少个分组
public int count() {
return count;
}
//元素p所在分组的标识符
public int find(int p) {
return eleAndGroup[p];
}
//判断并查集中元素p和元素q是否在同一分组中
public boolean connected(int p, int q) {
return find(p) == find(q);
}
//把p元素所在分组和q元素所在分组合并
public void union(int p, int q) {
//判断元素p和q是否已经在同一分组中
if (connected(p, q)) {
return;
}
//找到p所在分组的标识符
int pGroup = find(p);
//找到q所在分组的标识符
int qGroup = find(q);
//合并组:让p所在组的所有元素的组标识符变为q所在分组的标识符
for (int i = 0; i < eleAndGroup.length; i++) {
if (eleAndGroup[i] == pGroup) {
eleAndGroup[i] = qGroup;
}
}
//分组个数-1
this.count--;
}
}
并查集测试:
public static void main(String[] args) {
UF uf = new UF(5);
System.out.println("默认情况下,并查集中有:"+uf.count()+"个分组");
Scanner sc=new Scanner(System.in);
while (true){
System.out.println("请输入第一个要合并的元素:");
int p = sc.nextInt();
System.out.println("请输入第二个要合并的元素:");
int q = sc.nextInt();
if (uf.connected(p,q)){
System.out.println(p+"元素和"+q+"元素已经在同一个组中了");
continue;
}
uf.union(p,q);
System.out.println("当前并查集还有:"+uf.count()+"个分组");
}
}
3、并查集算法改进
如果我们并查集存储的每一个整数表示的是一个大型计算机网络中的计算机,则我们就可以通过connected(int p,int q)来检测,该网络中的某两台计算机之间是否连通?如果连通,则他们之间可以通信,如果不连通,则不能通信,此时我们又可以调用union(int p,int q)使得p和q之间连通,这样两台计算机之间就可以通信了。
一般像计算机这样网络型的数据,我们要求网络中的每两个数据之间都是相连通的,也就是说,我们需要调用很多次union方法,使得网络中所有数据相连,其实我们很容易可以得出,如果要让网络中的数据都相连,则我们至少要调用N-1次union方法才可以,但由于我们的union方法中使用for循环遍历了所有的元素,所以很明显,我们之前实现的合并算法的时间复杂度是O(N^2),如果要解决大规模问题,它是不合适的,所以我们需要对算法进行优化。
UF_Tree算法优化
package study.algorithm.uf;
public class UF_Tree {
//记录节点元素和该元素所在分组的标识
private int[] eleAndGroup;
//记录并查集中数据的分组个数
private int count;
//初始化并查集
public UF_Tree(int N) {
//初始化分组的数量
this.count = N;
//初始化eleAndGroup数组
this.eleAndGroup = new int[N];
//初始化eleAndGroup中的元素及其所在的组的标识符,让eleAndGroup数组的索引作为并查集的每个节点的元素,
// 并且让每个索引处的值(该元素所在组的标识)就是该索引
for (int i = 0; i < eleAndGroup.length; i++) {
eleAndGroup[i] = i;
}
}
//获取当前并查集中的数据有多少个分组
public int count() {
return count;
}
//元素p所在分组的标识符
public int find(int p) {
while (true) {
if (eleAndGroup[p] == p) {
return p;
}
p = eleAndGroup[p];
}
}
//判断并查集中元素p和元素q是否在同一分组中
public boolean connected(int p, int q) {
return find(p) == find(q);
}
//把p元素所在分组和q元素所在分组合并
public void union(int p, int q) {
//找到p元素和q元素所在组对应的树的根节点
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot) {
return;
}
eleAndGroup[pRoot] = eleAndGroup[qRoot];
this.count--;
}
}
优化后性能分析
我们优化后的算法union,如果要把并查集中所有的数据连通,仍然至少要调用N-1次union方法,但是,我们发现union方法中已经没有了for循环,所以union算法的时间复杂度由O(N^2)变为了O(N)。
但是这个算法仍然有问题,因为我们之前不仅修改了union算法,还修改了find算法。我们修改前的find算法的时
间复杂度在任何情况下都为O(1),但修改后的find算法在最坏情况下是O(N)
在union方法中调用了find方法,所以在最坏情况下union算法的时间复杂度仍然为O(N^2)。
路径压缩
package study.algorithm.uf;
public class UF_Tree_Weighted {
//记录节点元素和该元素所在分组的标识
private int[] eleAndGroup;
//记录并查集中数据的分组个数
private int count;
//用来存储每一个根节点对应的树中保存的节点的个数
private int[] sz;
//初始化并查集
public UF_Tree_Weighted(int N) {
//初始化分组的数量
this.count = N;
//初始化eleAndGroup数组
this.eleAndGroup = new int[N];
//初始化eleAndGroup中的元素及其所在的组的标识符,让eleAndGroup数组的索引作为并查集的每个节点的元素,
// 并且让每个索引处的值(该元素所在组的标识)就是该索引
for (int i = 0; i < eleAndGroup.length; i++) {
eleAndGroup[i] = i;
}
//默认情况下,sz中每个索引处的值都是1
sz = new int[N];
for (int i = 0; i < sz.length; i++) {
sz[i] = 1;
}
}
//获取当前并查集中的数据有多少个分组
public int count() {
return count;
}
//元素p所在分组的标识符
public int find(int p) {
while (eleAndGroup[p] != p) {
p = eleAndGroup[p];
}
return eleAndGroup[p];
}
//判断并查集中元素p和元素q是否在同一分组中
public boolean connected(int p, int q) {
return find(p) == find(q);
}
//把p元素所在分组和q元素所在分组合并
public void union(int p, int q) {
//找到p元素和q元素所在组对应的树的根节点
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot) {
return;
}
//判断pRoot对应的树大还是qRoot对应的树大,最终将较小的树合并到较大的树中
if (sz[pRoot] < sz[qRoot]) {
eleAndGroup[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
} else {
eleAndGroup[qRoot] = pRoot;
sz[pRoot] += sz[qRoot];
}
this.count--;
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









