



理论基础
机器硬件Cpu
在早期的计算机的Cpu执行原理是是Cpu的寄存器直接访问主内存(RAM),在寄存器中从而进行对数据的更新和读取,再写回主内存。但随着计算机Cpu 的计算技术逐渐成熟,cpu的执行速度与访问主内存的速度被逐渐拉开,最极端情况下可能会达到上万倍。
Cpu Cache模型的提出
基于cpu的计算速度和访问主内存的速度两者之间的差距问题,原有通过FSB直连主内存的方式已不在适用。
于是便衍生出了在Cpu寄存器访问主内存的过程中添加一层缓存层(Cache)。
将缓存层又划分为多个Cache Line:L1、L2、L3,其中L1距离cpu寄存器最近,L3距离主内存最近
将L1又进行细分为:L1 instruction(指令) ,L1 data(数据)
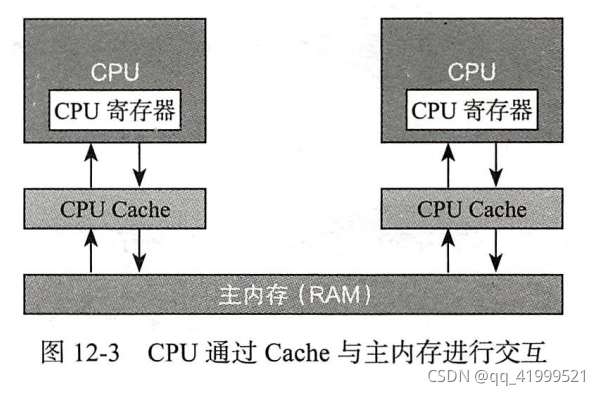
按照这种思想最终形成的结构图为:
执行步骤的改变
原来的:cpu 通过FSB直连主内存 -->读取数据放到寄存器-->计算--->写回主内存。
加入cache层(读操作):cpu--->访问cache层-->读取主内存放到cache层--->cpu 读操作-->返回。
加入cache层(写操作):cpu--->访问cache层-->读取主内存放到cache层--->cpu 读取cache数据-->放进寄存器进行计算-->写回cache层-->写回主内存。
Cpu 缓存不一致问题
Cache层的引入确实解决了cpu寄存器与主内存的速度差距,但也面临了一个新的问题。
如果Cache1与Cache2 同样存储了一份相同的数据,cache1对数据进行了修改,cahce2却无法感知 数据已经发生了变化,还是继续使用Cache2中的数据来进行计算,那么这个时候该怎么办?
比如:多线程进行 i++ 操作?
我们解析一下i++:
- cpu寄存器从主内存加载数据到cache层
- cpu寄存器从cache层获取 i 并进行加1
- 将i+1的结果写回cache层
- 更新主内存中 i 的结果
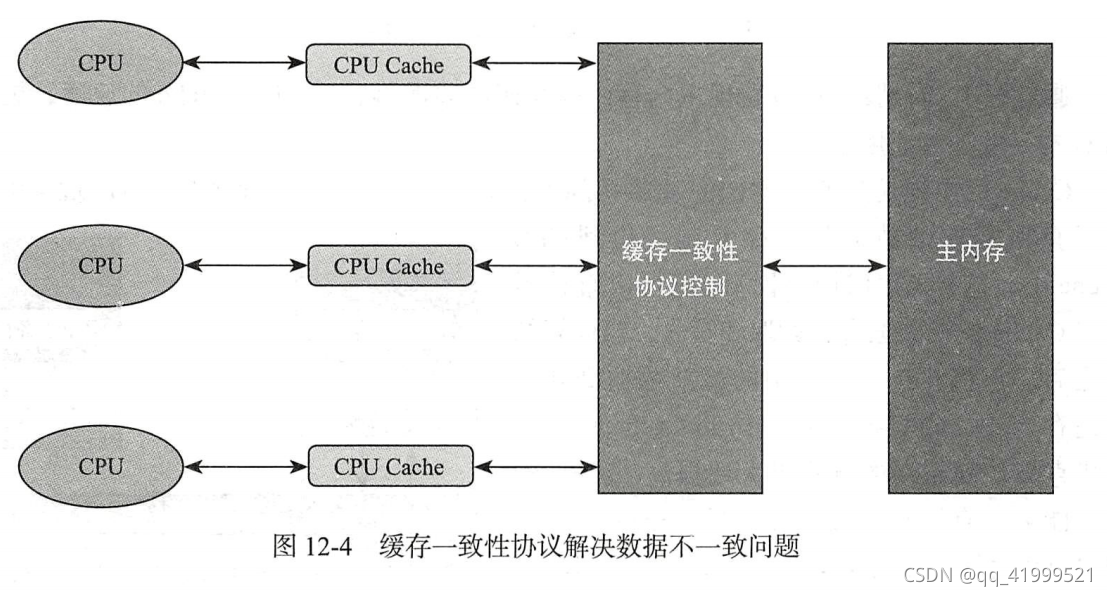
Cpu 缓存不一致问题解决方案
1.采用总线(数据总线、控制总线、地址总线)控制,类似于sync锁,设计理念为只允许单个cpu在拿到总线锁后才能进行对数据的更新。其他cpu进入阻塞状态。缺点也雷同sync。
2.采用缓存一致性协议,设计理念:当共享数据发生修改时其他cpu缓存的共享数据全部失效,直接从主内存中获取。
加入缓存一致性协议后的结构图:
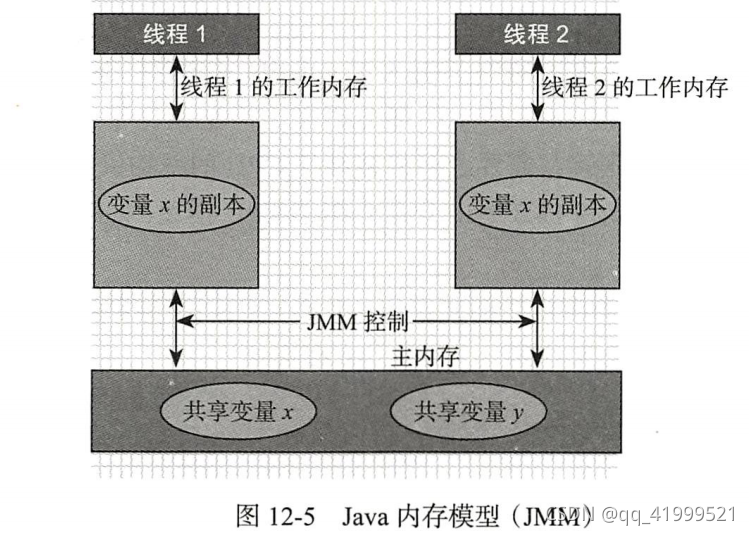
JAVA 内存模型(JMM: java memory mode)
在有了cpu对内存分访问速度以及衍生的缓存问题得到解决后的理论知识,我们来看看Java内存模型是如何与主内存进行交互或者说是怎么样的关系?
在java内存模型中定义了与主内存之间的抽象关系:
- 共享变量值存储于主内存中,每一个线程都可以访问。
- 每一个线程都有自己私有的共享变量副本(工作内存或者本地内存)
- 线程不能直接访问主内存,而是通过操作共享变量副本来更新主内存
- 工作内存只存储该线程对共享变量的副本。
- 工作内存和java内存模型一样只是一个抽象的概念,它其实并不存在。
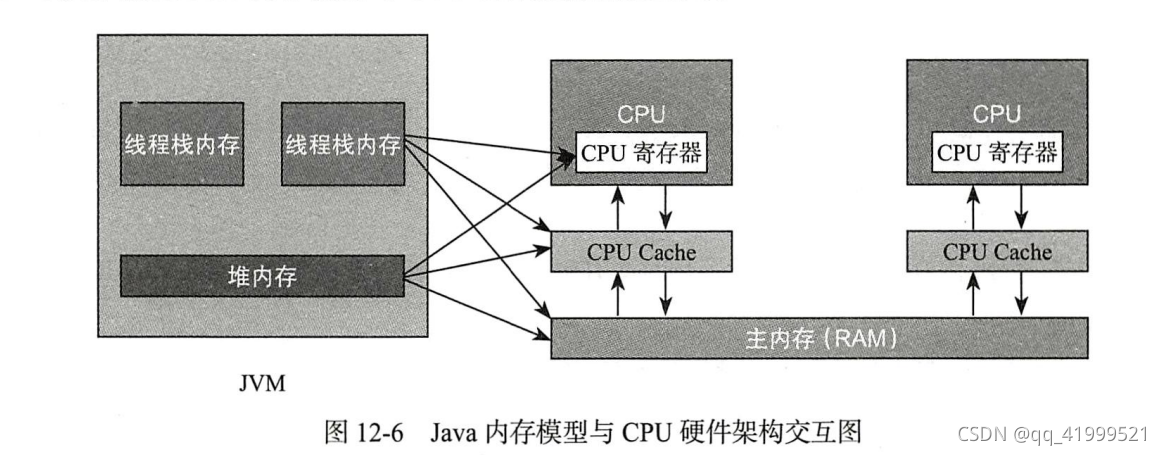
说起java内存模型,那么内存模型中栈内存与堆内存,这种只在java内存模型中的概念是怎么样跟实际物理cpu硬件进行交互的呢?
参考书籍:
《Java高并发编程详解:多线程与架构设计》---汪文君

















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









