






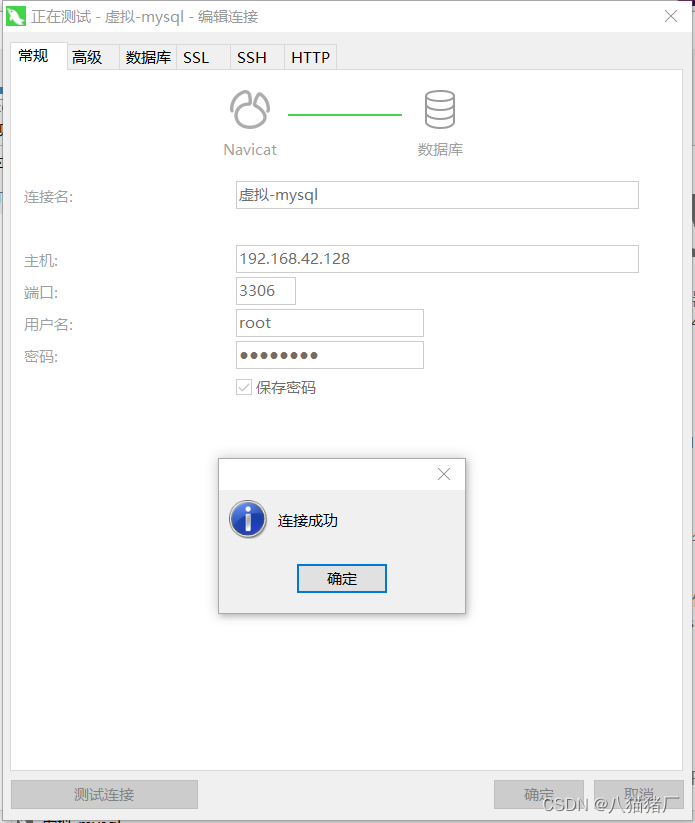
1、连接数据库
1.navicat连接数据库
2.命令行连接mysql -uroot -p
MYSQL(MYSQL5.7)是一个关系型数据库管理系统,navicat客户端连接mysql,默认端口3306,数据库管理系统mysql安装在linux服务器上,可以建很多个db(数据库),每个数据库下有很多表来保存数据;
/etc/my.cnf是MySQL配置文件
db数据库是存储数据的仓库,本质就是一个文件系统
SQL语言(结构化查询语言) 每一个SQL语句是分号结尾
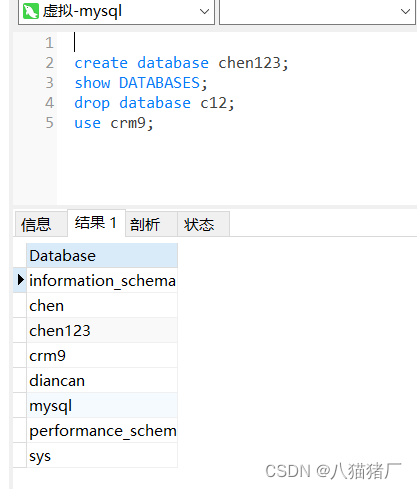
2、创建、查看、删除、使用数据库
创建
create database 数据库名称; create database chen123;
查看
show databases;
删除
drop database 数据库名称; drop database c12; (删库跑路可以用
使用
use 数据库名称;
3、创建、查看、删除、修改表
表中列的数据类型
数值型
整数
int
默认长度为11,数值范围: -2147483648 到 2147483647, int后面不需要加括号加长度
浮点数
float(10,2)
总长度为10,小数点后两位为2,超出范围会四舍五入,带有浮动小数点的小数字
double(size,d)
带有浮动小数点的大数字,在括号中规定最大位数size,在 d 参数中规定小数点右侧的最大位数
decimal(size,d)
使用最多,作为字符串存储的 DOUBLE 类型,允许固定的小数点
字符型
定长
char(11) 例:手机号
变长
varchar(6) 例:地址、昵称
不分中文英文,长度都为1
日期型
日期
date yyyy-mm-dd
时分秒
time HH:MM:SS
年
year YYYY
混合
datetime YYYY-MM-DD HH:MM:SS
时间戳
timestamp
混合,时间转成数字,通过秒数往前推
约束条件
无符号
unsigned
值从0开始,无负数
有符号值可以表示负数,0以及正数,无符号值只能为0或正数
零填充
zerofill
零填充,当数据显示长度不够时可以使用0填充至指定长度,字段会自动添加unsigned
非空
not null
默认值
default
如果插入数据时没有给该字段赋值,就使用默认值
引号括起来
主键
primary key
主键约束,表示唯一标识,这一列不能为空且全局唯一,一个表只能有一个主键,但是可以是多列,两个列数据加一起不重复
比如id
自增
auto_increment
自增,只能用于数值列,默认起始值为1,每次增长1
唯一
unique key
该字段下的值不能重复,但可以为空,可以有多个
unsigned、zerofill必须在not null前面;primary key(列名,列名)放在最后一行
创建表
创建表之前,需要选中数据库 use
CREATE TABLE 表名
(
[列名1] [数据类型1] [约束条件1],
[列名2] [数据类型2] [约束条件2],
[列名3] [数据类型3] [约束条件3]
primary key(列名)
);
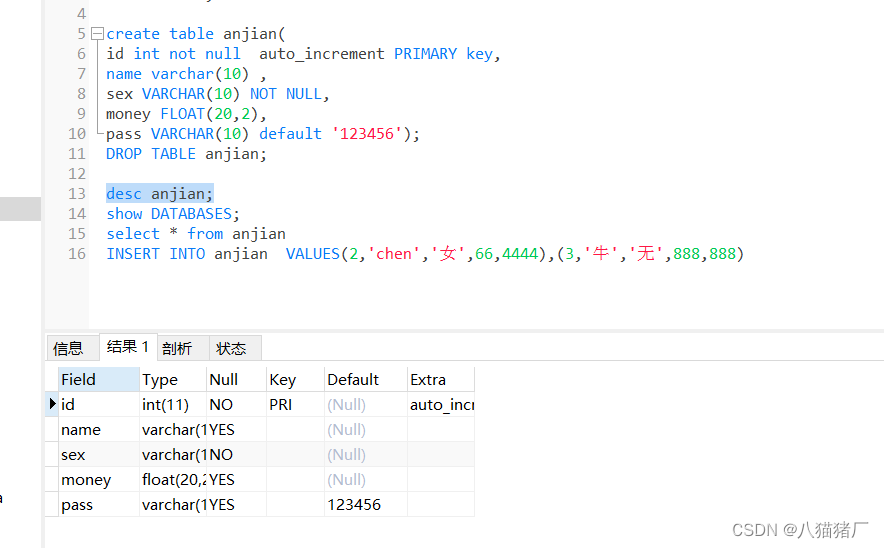
create table anjian(
id int not null auto_increment PRIMARY key,
name varchar(10) ,
sex VARCHAR(10) NOT NULL,
money FLOAT(20,2),
pass VARCHAR(10) default '123456');
DROP TABLE anjian;
查看数据库所有表的名称
show tables;
查看表结构(某张表的每一列的属性:列名、数据类型、约束)
desc 表名
数据表删除命令
drop table 表名;
修改表
向数据表中添加一列命令
alter table 表名 add 列名 列的数据格式 约束;
默认自动添加到数据表字段的末尾
如果要加在第一列在最后面加first
如果要加在某一列后面,在最后面加after某一列列名
删除数据表中的某一列
alter table 表名 drop 列名
修改列的类型和名称
alter table 表名 modify 列名 数据格式
不该列名,改列的类型和约束
alter table 表名 change 旧列名 新列名 数据格式
可以改列名
修改的同时可以设置默认值
alter table 表名 modify 列名 数据格式 default 100
修改的时候要把之前的约束都加上,不会记住列名之前的约束
4、对表里的数据进行增、删、改、查
增加数据
insert into 表名(字段1,字段2) values(值1,值2)
INSERT INTO anjian VALUES(2,'chen','女',66,4444),(3,'牛','无',888,888)
插入的数据应与字段的数据类型相同
数据的长度大小应在列的规定范围内
在values中列出的数据位置必须与加入的列的排列位置相对应
字符串和日期类型应包含在引号内,数字类型不需要
列名不加单双引号
更新、修改数据
update 表名 set 列名=新值 where 列名=某值
删除数据
delete from 表名 where 条件
delete 语句不能删除某一列的值,可使用update
delete 和drop的区别
drop 删数据库、删表、删列
delete 删行
删整行
查找数据
select * from 表名 where 条件;
select 后面跟查询哪些列的数据
select 字段 as 别名 from 表名
比较运算符
>
大于
<
小于
<=
小于等于
>=
大于等于
=
等于
><
不等于
between and
显示在某一区间的值,闭区间,大于等于小于等于
in()
给的值是列表中的某一个值,例:in(100,200)
约等于or
like '张%'
like '_张%'
_代表一个字符
%代表零个或多个任意字符
第二个字符是张的字符串
模糊查询
is null
判断是否为空
逻辑运算符
and
多条件同时成立
or
多条件任一成立
not
不成立
not like
is not null
select * from 表名 \G
人性化展示表的内容
表名太长iner_tooo_piii,书写时可以直接打itp
数据表的排序、聚合命令、分组
排序子句
order by 指定排序的列
asc对查询结果进行升序排序(可不写)
desc降序
order by 子句位于select 语句的结尾
常用聚合函数
distinct 对某一列数据去重
select distinct 列名 from 表名
count统计总行数
count(*)
返回表中总行数,包括列值为null的行数
count(1)
和count(*)区别是执行效率不同
count(列名)
返回指定列的行数,列值为null的行数不统计在内
count(distinct 列名)
返回指定列的不重复的行数,列值为null的行数不统计在内
max最大值
min最小值
avg平均值
sum求和
limit m,n
m是指从哪行开始,m从0取值,0表示第一行,n是指从第m+1开始,取n条
limit 0,2
从第1行开始,显示2行结果
limit n
等价于limit 0,n
limit 5
查询前5行
count(*)&count(1)&count(列名)执行效率比较
如果列为主键,count(列名)效率优于count(1)
如果列不为主键,count(1)效率优于count(列名)
如果表中存在主键,count(主键列名)效率最优
如果表中只有一列,则count(*)效率最优
如果表有多列,且不存在主键,则count(1)效率优于count(*)
分组
group by子句对列进行分组,group by user_id把相同的人分成一组
不加having过滤
select 列名,聚合函数 from 表名 where 子句 group by 列名
加having过滤
对分组结果进行过滤
select 列名,聚合函数 from 表名 where 子句 group by 列名 having 聚合函数 过滤条件
group by 后只能展示分组的列名+聚合函数结果
group by 列名1,列名2
多维度分组(部门,级别),两个值合一块才能成为一组
where条件中不能包含聚组函数
数据表连接查询和子查询(嵌套查询)
两张表连接查询
inner join
内连接
获取两个表中字段匹配关系的行的所有信息
select * from 表名 a inner join 表名 b on a.列名=b.列名
需要交集的数据
left join
左连接
获取左表所有行的信息,即使右表没有对应匹配的行的信息。右表没有匹配部分用null代替
select * from 表名 a left join 表名 b on a.列名=b.列名
right join
右连接
获取右表所有行的信息,即使右表没有对应匹配的行的信息。左表没有匹配部分用null代替
select * from 表名 a right join 表名 b on a.列名=b.列名
a代表重新给表命名
左右连接相对的,换了表的位置
用于场景
需要你有我没有的数据:A表为订单表,B表为用户表,找出用户表与订单表,用户没下过单的,筛选出is null
两两表连接,可以把查询出来的值当成一个表连接另一个表
子查询(嵌套查询)
嵌套在其他查询中的查询
select 列名1 from 表1 where 列名2 in(select 列名2 from 表2 where 列名3=某某)
程序先执行嵌套在最内层的语句,再运行外层。可以一层层往外加,增加子查询正确率
将两个查询结果连接
列名数量需一致
union all
显示所有合并查询结果,不删除重复项
union
删除重复项
数据库与测试的结合:如点餐系统的订单管理,改数据库的订单状态,就可以验证已维修全部订单的订单

















 2400
2400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









