



本文主要对社交网络进行分析溯源,并考究其发展过程。并分享一些近些年高质量会议和期刊上的部分文章。
前置定义
社交网络:
根据维基百科的解释,“社会网络(Social Networking:SN)”是指个人之间的关系网络。
据一些不系统的分析,社会网络(或称为社会性网络)的理论基础源于六度分隔理论(Six Degrees of Separation)和150法则(Rule Of 150)。六度分隔理论:任何两个陌生人之间所间隔的人不会超过六个。150法则:150是公认的“我们可以与之保持社交关系的人数的最大值。
推荐系统:
英伟达术语表中给出了推荐系统的解释:推荐系统是使用大数据向消费者建议或推荐其他产品。这些推荐可以基于各种标准,包括过去的购买、搜索历史记录、人口统计信息和其他因素。推荐系统非常有用,因为它们可以帮助用户了解自己无法自行找到的产品和服务。
但是笔者认为推荐系统是给user即用户推荐item的一个系统,使这些item尽量满足user的喜好,其中item包含商品,感兴趣的人或地点等。
引言(社交推荐的诞生)
社交推荐的诞生离不开社交网络和推荐系统的发展。
社交网络随着1991年万维网(world wide web)的诞生而迅速发展。
而推荐系统起源于1992年Xerox PARC中心的研究人员对邮件做个性化过滤的需求。也与计算机网络有着密不可分的关系。同年,Goldberg提出了“推荐系统”这个概念。
社交网络的前世
当今时代多数人手机中都有微博和微信两个应用,分别代表了两种不同类型的"社交关系":社交媒体和社交网络。
社交网络是连接人与人的服务平台,中心在于构建人与人之间的关系,内容是附属品,内容的消费价值附着在关系链上,拆开单独来看,内容可能并不具备普世意义上的可消费属性。 而社交媒体恰恰相反,它构建的是人与内容的关系,人与人的关系构建是附带的,其目的依旧是为了产生高消费价值的内容并快速传播。
人类是社会性动物,因此社交关系在2100万年前还未从猿猴演化为人类时已经存在。百度百科上人类社会起源中提到:
人类社会是整个自然界的一个特殊部分,是在自然界发展一定阶段上随着人类的产生而出现的。
人类社会的形成主要不是人的生理组织与机制进化的生物学过程,而是以劳动为基础的人类共同活动和相互交往等社会关系形成的过程。人类的直接祖先曾经是一种群居动物,它们在严酷的大自然面前不得不以群体的联合力量和集体活动来弥补个体能力的不足。
恩格斯曾把过着群居生活的古猿称之为“社会化的动物”,把它们的群体关系称为“社会本能”。他指出:“我们的猿类祖先是一种社会化的动物,人,一切动物中最社会化的动物,显然不可能从一种非社会化的最近的祖先发展而来。”(《马克思恩格斯选集》第3卷,第510页)人类祖先的群体关系的社会本能,是从猿进化到人的最重要的杠杆之一。同劳动的发展相适应,这种群体关系越来越广泛和密切,终于随着人类的出现而成为真正意义上的社会关系。
因此,社交关系古猿时期就存在:由于生产力低下,人们的行为以解决最简单的生存问题为主,即争夺水源、获取食物以及寻找休憩之地。而在这个过程中,合作与协调是最简单且有效的行为方式,这其实就是社交关系的起源。
社交网络含义:包括硬件、软件、服务及应用,由于四字构成的词组更符合中国人的构词习惯,因此人们习惯上用社交网络来代指SNS(Social Network Service)。
社交网络发展:早期概念化阶段──SixDegrees代表的六度分隔理论;结交陌生人阶段──Friendster帮你建立弱关系从而带来更高社会资本的理论;娱乐化阶段──MySpace创造的丰富的多媒体个性化空间吸引注意力的理论;社交图阶段──Facebook复制线下真实人际网络来到线上低成本管理的理论;云社交阶段——目前国内外的平台。整个SNS发展的过程是循着人们逐渐将线下生活的更完整的信息流转移到线上进行低成本管理,这让虚拟社交越来越与现实世界的社交出现交叉。
推荐系统前世
啤酒和尿布:20世纪90年代,在美国沃尔玛超市中,管理人员分析数据时,发现了一个奇怪的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品出现在了同一个购物篮中。这种独特的销售现象引起了管理人员的注意,经过后续调查发现,一些年轻的爸爸常到超市去购买婴儿尿布,有30%~40%的新爸爸,会顺便买点啤酒犒劳自己。随后,沃尔玛对啤酒和尿布进行了捆绑销售,不出意料,销售量双双增加。
这里参考《推荐系统开发实战》之推荐系统的前世今生与古往今来中给出的推荐系统发展过程:
- Xerox公司在1992年设计的应用协同过滤算法的邮件系统——Tapestry。同年,Goldberg提出了“推荐系统”这个概念。
- 1994年,明尼苏达大学的GroupLens研究组使用基于主动协同过滤的推荐算法,开发了第一个自动化推荐系统 GroupLens,并将其应用在Usenet新闻组中。
- 1996年,卡内基梅隆大学的Dunja Mladenic在Web Watcher的基础上进行了改进,提出了个性化推荐系统Personal Wgb Watchero
- 1996年,著名的网络公司Yahoo也注意到了个性化服务的巨大优势和潜在商机,推出个性化入口MyYahoo。
- 1997年,Resnick和Varian首次在学术届正式提出推荐系统的定义。他们认为:推荐系统可以帮助电子商务网站向用户提供商品和建议,促成用户的产品购买行为,模拟销售人员协助客户完成购买过程。
- 1998年,亚马逊(Amazon.com)上线了基于物品的协同过滤算法,将推荐系统的规模扩大至服务千万级用户和处理百万级商品,并带来了良好的推荐效果。
- 以后的发展在后续会根据需求提到。
本文结构
本文将从社交网络和推荐系统结合的紧密程度、社交推荐定义的清晰程度与社交推荐使用技术这三个层面将社交推荐分为前期中期近代。
社交推荐前期
本文将社交推荐最初提出到其概念被归纳的这段时间称作社交推荐前期。这段时间社交推荐主要表现与
社交推荐在1997年由Henry Kautz在《Combining Social Networks and Collaborative Filtering》中被开始研究,并随着社交媒体的日益普及而受到越来越多的关注。 但是仍然处于发展的早期阶段,因为尚未有明确的定义,研究者只是将社交网络与推荐系统进行低耦合,此时的大部分研究并未发现社交网络应用在推荐系统上的价值,甚至部分社交平台进行的社交推荐完全不起作用甚至有副作用。
2005年,Adomavicius等人发表综述论文,将推荐系统分为3类——基于内容的推荐、基于协同过滤的推荐和混合推荐,并提出了未来可能的主要研究方向。与之类似的,这个阶段社交推荐也主要包含基于内容的社交推荐、基于协同过滤的社交推荐和混合社交推荐。
ACM推荐系统年会(ACM Conf. on Recommender Systems,简称RecSys)自2009年开始涉及社会化推荐系统的专题讨论会(Workshop on Recommender Systems & the Social Web),在2011年的专题研讨会上指出了社会化推荐系统领域的几个发展和研究主题,讨论了该领域的研究热点和难点:(1) 案例研究及新的社会化推荐应用;(2) 以社区为基础的系统体制(economy of community-based systems):利用推荐系统鼓励用户持久地参与;(3) 社会化网络与大众分类法的进展:朋友、标签、书签、博客、音乐、社区推荐等等;(4) 推荐系统的跨界应用,Web 2.0用户界面及多媒介的推荐系统;(5) 系统知识创作和综合人工智能;(6) 在推荐过程中直接涉及的用户或者社团推荐应用;(7) 利用大众分类法、社会化网络信息、交互信息、用户背景及社团等的推荐方法;(8) 有信任和信誉意识的社会化推荐;(9) 利用本体论或者微格局的语义网络推荐系统;(10) 社会化推荐技术的经验评估:成功和失败方法.在2013年专题讨论会[17]上,又进一步提出以下4个发展方向:(1) 异构网络上的社会化推荐;(2) 社会化推荐中的隐私保护问题;(3) 移动社会化推荐;(4) 社交网络与用户-项目关系网络的融合推荐.
社交推荐中期
随着网络技术的发展,社交推荐也随之发展壮大,首先我们从一个案例开始说起:
2012年,李开复在微博上发布了一条微博宣传了酸奶机:
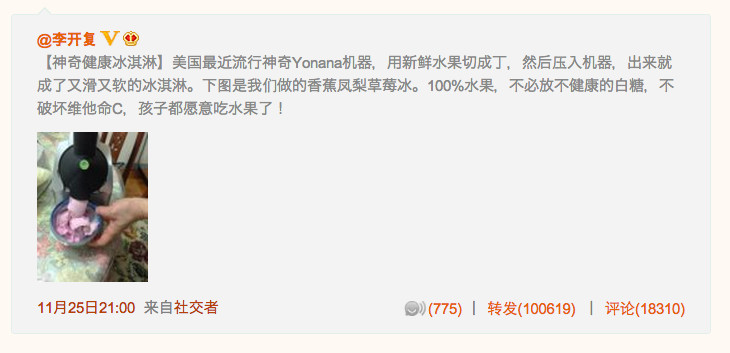
在3个小时之内淘宝就有超过一百个商家从美国进口这种机器并出售,并在一天之内销售超过一千台。随后李开复在领英上发布了The Power of Social Recommendation,虽然有不少研究者质疑这是否是社交推荐,但此时仍然没有明确的定义,社交推荐也因此时逐渐被研究者所重视。
或许与这篇文章有一定的关系,但其实此时社交推荐已经成为顶会的常客,并在明年,也有相关综述给出了一些定义来明确社交推荐到底是什么这个问题:
2013年唐等人在《Social Recommendation: A Review》给出了社交推荐的狭义定义和广义定义:
社交推荐的狭义定义是任何以在线社交关系作为额外输入的推荐,即用额外的社交信号增强现有的推荐引擎。 社会关系可以是信任关系、友谊关系、会员关系或追随关系。 第 19 届 WWW2010 上的一篇题为“Introduction to Social Recommendation”的教程遵循了这个狭隘的定义。 在这个定义中,社交推荐系统假设用户在建立社交关系时是相关的。 例如,用户的偏好可能与他们的好友相似或受其影响。 在此假设下,社交推荐利用社交关系隐含的用户相关性来提高推荐的性能。
第 20 届 WWW2011 上的另一个名为“社交推荐系统”的教程给出了社交推荐的广泛定义,其中社交推荐系统被定义为针对社交媒体领域的任何推荐系统。 该定义涵盖推荐系统推荐社交媒体领域中的任何对象,例如item(狭义定义下推荐系统的焦点)、tags、people和communities。 其使用的来源不仅限于在线社交关系,还包括各种可用的社交媒体数据,例如社交标签、用户交互和用户点击行为。
在这个阶段,社交推荐比较大的应用场景就是朋友推荐,比如qq上的你可能认识的人,或者微博上猜你想认识,给你推荐用户。工业界把这种场景称为朋友推荐,具体可参见这篇16年的文章从好友推荐算法说起。
其中介绍了三元闭包理论,笔者认为是六度分离理论的弱化版:
说到好友推荐,就不得不谈三元闭包理论。
三元闭包定义:在一个社交圈内,若两个人有一个共同好友,则这两个人在未来成为好友的可能性就会提高。
举例说明,若B、C有一个共同好友A,且B、C不认识,则B、C成为好友的几率会增加
这个理论直观自然,可以从机会、信任、动机上来解释:
1、B、C是A的朋友,那么B、C见面的机会会增加,如果A花时间和B、C相处,那么B、C可能会因此有机会认识
2、在友谊形成过程中,基于B、C都是A好友的事实,假定B、C都知道这点,这会为他们提供陌生人之间所缺乏的基本信任
3、A有将B、C撮合为好友的动机:如果B、C不是朋友,可能会为A和B、C的友谊造成潜在的压力
这个时期,处理社交推荐的算法主流为根据三元闭包等理论增强推荐系统的CF结果,从这个角度上说,社交推荐与传统的给user推荐item没有本质的区别。
但是另外一种场景出现了,即使用user之间的信息,即u-u图进一步的增强u-i图之间的交互,相当于是将用户之间的关系视作一种辅助信息,从而增强目标信息,即item推荐。这种场景相当于是狭义的社交推荐,虽然与前者只是场景不同,但其潜力会在有深度学习算法的应用之后才可得到充分挖掘,这种场景会在下一章详细介绍。
社交推荐近期
社交推荐是天生适合深度学习应用的场景,因为推荐本身就是深度学习最常用的场景质之一。而社交推荐这些年的发展主要聚焦在自动编码器、生成对抗网络和图神经网络。
本章节主要参考了2022年的基于图神经网络的社交推荐综述,与笔者整理的去噪相关的论文,关于生成对抗网络、自动编码器也是社交推荐近些年常用的技术,只是在本文不在阐述。本章节大部分内容来源笔者整理的社交推荐下去噪综述,若有需求社交推荐去噪综述请私信。
近些年来,随着深度学习技术的发展,社交推荐由于存在天生的非结构化数据(图数据),因此极其适合图神经网络技术。为了方便理解,以下面这个例子来引入(此例为狭义场景的社交推荐):
快手在社交与算法之间寻找平衡,构建了独特的半熟人社区。微信则注重社交推荐策略,用户在看一看或视频号中更容易被推荐其邻居用户点赞的文章或视频。据公开资料显示,朋友点赞的“社交推荐”在视频号算法中占比高达55%,而优质内容的“热门推荐”仅占15%。
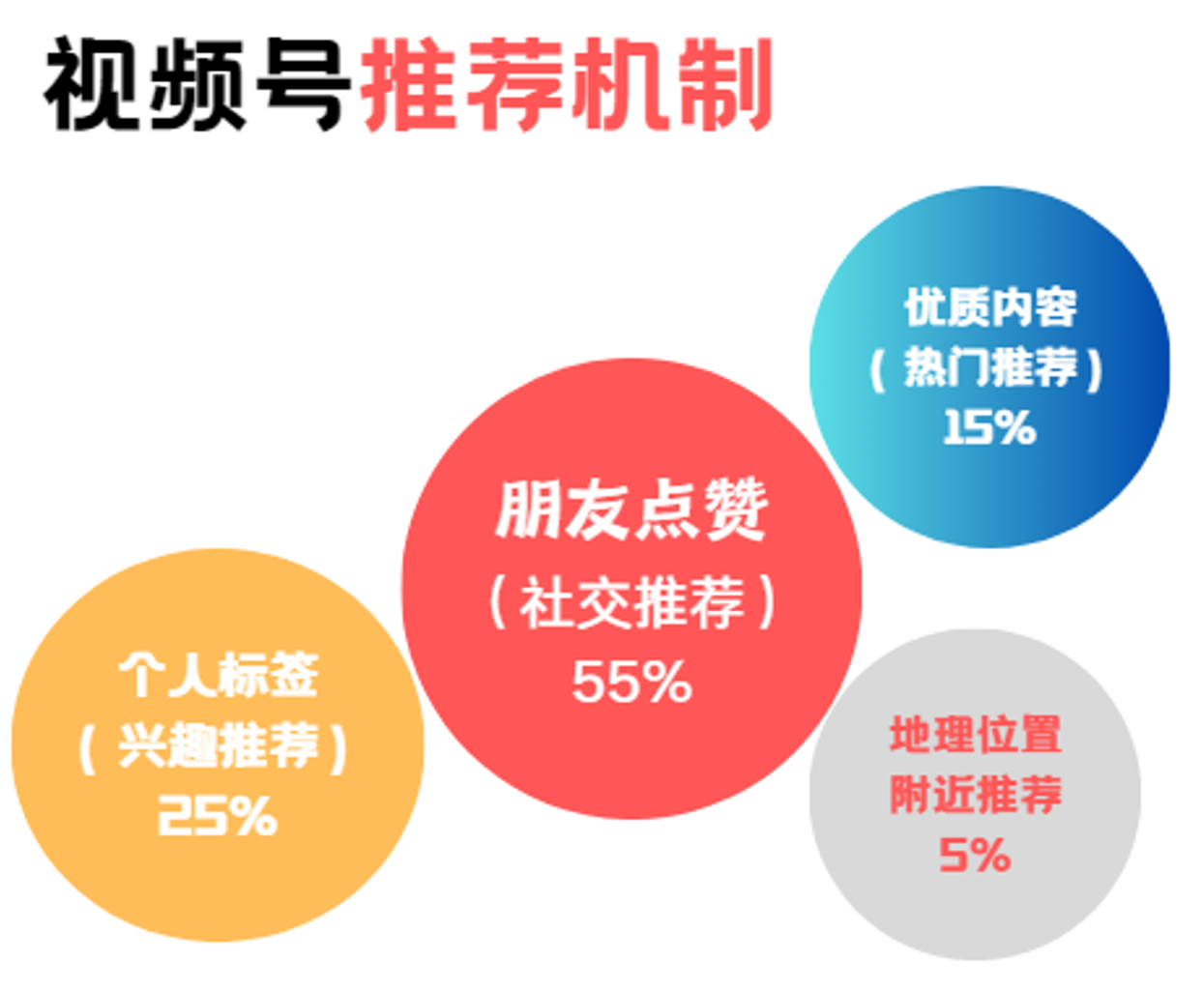
这种机制使得视频号在内容分发上更加侧重于用户的社交关系,而非单纯的内容质量。具体而言,当用户点赞某个视频后,该视频会被推荐给用户的微信好友;如果好友也点赞了,则视频会进一步推荐给好友的好友,形成社交裂变效应。
基于MF的方法无法有效地建模U-U社会关系和U-I交互中固有的复杂(即非线性)关系。受此推动,最近的工作集中在将深度学习技术应用于社交推荐,例如自动编码器、生成对抗网络和图神经网络。
尽管上述方法十分有效,但这些模型方法的性能存在缺陷,因为它们忽略了由于某些原因社交信息对于推荐任务可能是嘈杂的事实。首先,社会联系可能是偶然建立的。社交平台上的用户可能会在不知不觉中关注僵尸账户或虚假账户或被关注。这些社会关系给用户建模带来了偏见。其次,直接将社交图应用于推荐场景的潜在缺点被广泛忽视,因为在将用户社交信息传递给用户交互时存在信息差距。
社交网络存在噪声
由于用户社交行为的复杂性和建立连接的成本较低,社交网络中可能存在嘈杂连接。用户可能出于各种原因与他人建立联系,甚至偶然与他人建立联系,建立社交关系的原因也多种多样,例如学校中某些选择同一门课的同学在某种程度上相当于建立了社交关系,但是大家的兴趣点可能大相径庭。在两个常用的数据集Epinion和Ciao上社交网络中不同U-U关系的偏好相似度非常低,其中大多数低于0.4,如下图所示。
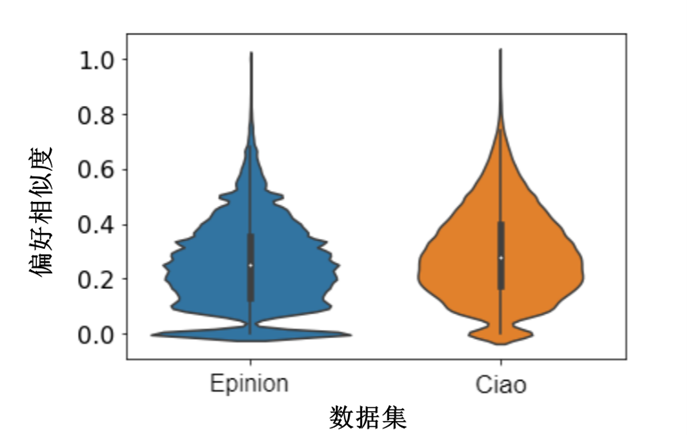
在SSD-ICGA中,作者做了进一步的实验阐述了一件事实,虽然无法直接说明社交推荐下的用户之间存在噪声,但是去掉了相似度较低的用户对最终的推荐结果有积极地影响,因此可以一定程度上认为这部分是噪声。关于SSD-ICGA可以看笔者之前的文章:社交推荐去噪论文简读
同时需要注意的是,噪声不止可能存在于用户关系图中,在UI图中也可能存在噪声。
社交推荐系统的发展
社交推荐系统的发展与社交网络与推荐系统的兴起密切相关。随着社交网络平台的流行,用户生成的内容和社交互动数据呈指数级增长,为推荐系统提供了丰富的信息源。早期的社交推荐系统主要依赖于协同过滤和内容推荐技术,但随着GNN的发展,社交推荐系统开始利用社交网络的结构信息来捕捉用户间的复杂关系和社交影响。
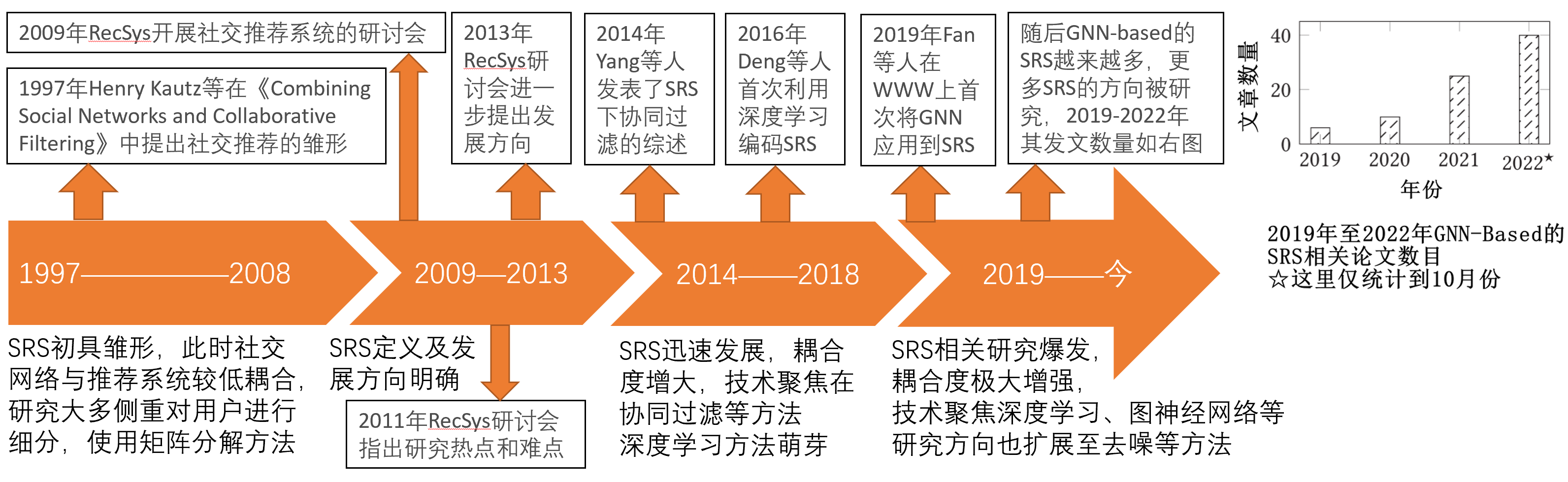
社交推荐系统的发展经历了几个阶段:(1)协同过滤阶段:早期的社交推荐系统主要依赖于用户的历史交互数据,采用协同过滤技术来预测用户可能感兴趣的项目。(2)社交增强阶段:随着社交网络的兴起,研究者开始探索社交网络中的信息,如用户间的社交联系,以增强推荐系统的性能。(3)图神经网络阶段:近年来,图神经网络技术被广泛应用于社交推荐系统,通过捕捉社交网络中的高阶社交影响来提高推荐质量。具体可见下图:
社交推荐中的挑战
尽管社交推荐系统在理论上具有很大的潜力,但在实际应用中仍面临许多挑战:(1)数据稀疏性:用户通常只与少数项目产生交互,导致用户-项目交互数据稀疏,难以捕捉用户的全部偏好。(2)社交网络噪声:社交网络中存在大量的噪声,如不相关的社交联系、僵尸账户和恶意账户,这些噪声会干扰推荐系统的性能。(3)隐私和安全性问题:社交推荐系统需要处理用户的社交数据,这涉及到用户隐私和数据安全的问题。(4)动态性:社交网络是动态变化的,用户的兴趣和社交关系随时间变化,推荐系统需要能够适应这种动态性。
社交推荐中噪声的影响
社交推荐系统中噪声对推荐系统的影响是多方面的:(1)用户建模不准确:噪声社交联系可能导致用户建模不准确,从而影响推荐结果的相关性和准确性。(2)推荐系统性能下降:噪声数据会降低推荐系统的性能,包括准确率、召回率和排序质量。(3)系统鲁棒性降低:社交网络噪声可能会使推荐系统对恶意攻击更加敏感,降低系统的鲁棒性。(4)用户信任度下降:如果推荐系统频繁推送不相关的项目,可能会降低用户对推荐系统的信任度。为了解决这些问题,研究者们提出了多种去噪技术,旨在从社交网络中识别和去除噪声,以提高推荐系统的性能和鲁棒性。这些技术包括基于图的方法、自监督学习方法和基于对抗训练的方法等。通过这些方法,社交推荐系统能够更好地利用社交网络中的有用信息,同时减少噪声的负面影响。
部分社交推荐技术整理
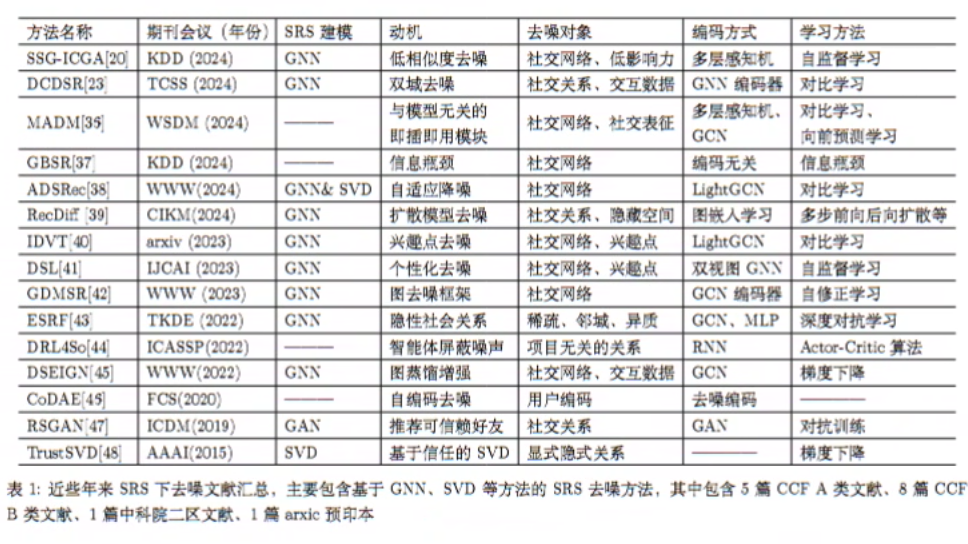
总结
本文从技术出发,简单总结了社交推荐近些年来发展方向,并给出一些例子,最终近代社交推荐落脚于去噪,介绍了当前不同场景下社交推荐的去噪方法。


















 3240
3240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









