







 本文详细介绍了Kubernetes中的配置管理,包括Configmap的创建和使用,Secret对象的类型和安全,以及Volumes的多种配置方式如emptyDir、hostPath、NFS、PV-PVC。此外,还探讨了kubernetes调度的多种策略,如nodeName、nodeSelector、pod亲和与反亲和、污点和容忍。最后提到了Kubernetes的访问控制。
本文详细介绍了Kubernetes中的配置管理,包括Configmap的创建和使用,Secret对象的类型和安全,以及Volumes的多种配置方式如emptyDir、hostPath、NFS、PV-PVC。此外,还探讨了kubernetes调度的多种策略,如nodeName、nodeSelector、pod亲和与反亲和、污点和容忍。最后提到了Kubernetes的访问控制。
一、Configmap配置管理
-
Configmap用于保存配置数据,以键值对形式存储
-
configMap资源提供了向pod注入配置数据的方法
-
旨在让镜像和配置文件解耦,以便实现镜像的可移植性和可复用性
-
典型的使用场景:
填充环境变量的值
设置容器内的命令行参数
填充卷的配置文件 -
创建ConfigMap的方式有4种:
-使用字面值创建
使用文件创建
使用目录创建
编写configmap的yaml文件创建
1创建cm的四种方式
1.1使用字面值创建
[root@node1 configmap]# kubectl create configmap mycm1 --from-literal=key1=111 --from-literal=key2=222
[root@node1 configmap]# kubectl get cm
NAME DATA AGE
mycm1 2 8s
[root@node1 configmap]# kubectl describe cm mycm1

1.2使用文件创建
[root@node1 configmap]# kubectl create configmap mycm2 --from-file=/etc/resolv.conf
configmap/mycm2 created
[root@node1 configmap]# kubectl get cm
NAME DATA AGE
mycm1 2 3m35s
mycm2 1 5s
文件名是key值,内容是vaule

1.3使用目录创建
[root@node1 configmap]# ls
network resolv.conf
[root@node1 configmap]# kubectl create configmap mycm3 --from-file=/root/manifest/configmap/
configmap/mycm3 created
[root@node1 configmap]# kubectl get cm
NAME DATA AGE
mycm1 2 14m
mycm2 1 10m
mycm3 2 5s

1.4使用yml文件创建
[root@node1 cm]# cat cm1.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: mycm4
data:
db_host: "172.25.0.250"
db_port: "3306"
[root@node1 cm]# kubectl apply -f cm1.yml
configmap/mycm4 created
[root@node1 cm]# kubectl get cm
NAME DATA AGE
mycm1 2 11h
mycm2 1 11h
mycm3 2 11h
mycm4 2 4s

2 如何使用configmap
- 通过环境变量的方式直接传递给pod
- 通过在pod的命令行下运行的方式
- 作为volume的方式挂载到pod内
2.1通过环境变量的方式直接给pod
自主命名key值
[root@node1 cm]# cat pod1.yml
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
containers:
- name: pod1
image: busyboxplus
command: ["/bin/sh", "-c", "env"]
env:
- name: key-one ##在这里起个key值的名字
valueFrom: #环境变量值从哪里来
configMapKeyRef: #从configmap来
name: mycm4 #从configmap的mycm4文件里来
key: db_host #将configmap的mycm4文件里key为db_host的值赋给key-one
- name: key-two
valueFrom:
configMapKeyRef:
name: mycm4
key: db_port
restartPolicy: Never
[root@node1 cm]# kubectl apply -f pod1.yml
pod/pod1 created
[root@node1 cm]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod1 0/1 Completed 0 4s
[root@node1 cm]# kubectl logs pod1

使用原来的key值:
[root@node1 cm]# cat pod2.yml
apiVersion: v1
kind: Pod
metadata:
name: pod2
spec:
containers:
- name: pod2
image: busyboxplus
command: ["/bin/sh", "-c", "env"]
envFrom:
- configMapRef:
name: mycm4
restartPolicy: Never
[root@node1 cm]# kubectl apply -f pod2.yml
pod/pod2 created
[root@node1 cm]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod1 0/1 Completed 0 2m24s
pod2 0/1 Completed 0 4s
[root@node1 cm]# kubectl logd pod2

2.2通过在pod的命令行下运行的方式
[root@node1 cm]# cat pod3.yml
apiVersion: v1
kind: Pod
metadata:
name: poddd3
spec:
containers:
- name: p3
image: busyboxplus
command: ["/bin/sh", "-c", "echo $(db_host) $(db_port)"]
envFrom:
- configMapRef:
name: mycm4
restartPolicy: Never
[root@node1 cm]# kubectl apply -f pod3.yml
pod/poddd3 created
[root@node1 cm]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod1 0/1 Completed 0 9m38s
pod2 0/1 Completed 0 7m18s
poddd3 0/1 Completed 0 8s
[root@node1 cm]# kubectl logs poddd3
172.25.0.250 3306
2.3作为volume的方式挂在到pod内
[root@node1 cm]# cat pod1.yml
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
containers: #设定容器
- name: pod1
image: myapp:v1
volumeMounts: #容器的挂载路径
- name: config-volume
mountPath: /config
volumes: #设定容器的卷
- name: config-volume
configMap:
name: mycm4
[root@node1 cm]# kubectl apply -f pod1.yml
pod/pod1 created
[root@node1 cm]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod1 1/1 Running 0 4s
[root@node1 cm]# kubectl exec -it pod1 -- sh #进去看一下
/ # ls
bin dev home media proc run srv tmp var
config etc lib mnt root sbin sys usr
/ # cd config/
/config # ls
db_host db_port
/config # cat *
172.25.0.2503306
2.4 configmap热更新
key–>文件名
vaule–>文件的内容

创建一个文件server.conf–key值–>挂载目录下的文件名
[root@node1 cm]# cat server.conf
server {
listen 8000;
server_name _;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
}
[root@node1 cm]# kubectl create configmap server --from-file=server.conf #将server文件加到cm里
configmap/server created
[root@node1 cm]# kubectl get cm #查看一下已经加到
NAME DATA AGE
mycm1 2 14h
mycm2 1 14h
mycm3 2 14h
mycm4 2 142m
server 1 17s
[root@node1 cm]# cat pod1.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: config-volume
mountPath: /etc/nginx/conf.d/ 挂到此目录下
volumes:
- name: config-volume
configMap:
name: server #源是:cm里的server
[root@node1 cm]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-nginx-6bb8847948-cm5bx 1/1 Running 0 4m41s 10.244.1.110 node2 <none> <none>
可以正常访问:

现在对cm 里的server文件修改:将端口号由8000---->9000
[root@node1 cm]# kubectl edit cm server
configmap/server edited

进入pod中查看:

修改cm 里 的值,隔几秒挂载点才会同步变化,configmap已生效,但是不能pod并没有重新加载,因此就算改了,也没有生效。
如何生效?
1.容器删除,重新生成,就重新读取配置文件
2.patch指令重新加载,手动触发,IP会变

[root@node1 cm]# kubectl patch deployments.apps my-nginx --patch '{"spec": {"template":
> {"metadata": {"annotations": {"version/config": "20200628"}}}}}' #对整个deployment都更新
此时IP已变:端口号也已经更新

二、Secret配置管理
(1)Secret对象类型用来保存敏感信息,例如密码,OAuth令牌和ssh key。
敏感信息放在 secret 中比放在 Pod 的定义或者容器镜像中来说更加安全和灵活。
Pod 可以用两种方式使用 secret:
• 作为 volume 中的文件被挂载到 pod 中的一个或者多个容器里。
•当 kubelet 为 pod 拉取镜像时使用。
(2)Secret的类型:
• Service Account:Kubernetes 自动创建包含访问 API 凭据的 secret,并自动修改
pod 以使用此类型的 secret。
• Opaque:使用base64编码存储信息,可以通过base64 --decode解码获得原始数据,
因此安全性弱。
• kubernetes.io/dockerconfigjson:用于存储docker registry的认证信息。
serviceaccout 创建时 Kubernetes 会默认创建对应的 secret。对应的 secret 会自动挂载到
Pod 的 /run/secrets/kubernetes.io/serviceaccount 目录中。


每个namesapce下都有一个名为default的默认的ServiceAccout对象


• Opaque Secret 其value为base64编码后的值。
[root@node1 cm]# echo -n 'admin' > ./username.txt
[root@node1 cm]# echo -n 'westos' > ./password.txt
[root@node1 cm]# kubectl get secrets
NAME TYPE DATA AGE
default-token-ccttm kubernetes.io/service-account-token 3 5d19h
[root@node1 cm]# kubectl create secret generic db-user-pass --from-file=./username.txt --from-file=./password.txt
secret/db-user-pass created
[root@node1 cm]# kubectl get secrets
NAME TYPE DATA AGE
db-user-pass Opaque 2 3s
default-token-ccttm kubernetes.io/service-account-token 3 5d19h
默认情况下get secret和describe 无法得到密码的内容,可以通过base64 -d得到。


编写yml文件创建secret
[root@node1 cm]# cat mysecret.yml
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: d2VzdG9z
[root@node1 cm]# kubectl apply -f mysecret.yml
secret/mysecret created
[root@node1 cm]# kubectl get secrets
NAME TYPE DATA AGE
default-token-ccttm kubernetes.io/service-account-token 3 5d19h
mysecret Opaque
将secret挂载到卷中
[root@node1 cm]# cat pod1.yml
apiVersion: v1
kind: Pod
metadata:
name: mysecret
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: secrets
mountPath: "/secret"
readOnly: true
volumes:
- name: secrets
secret:
secretName: mysecret
[root@node1 cm]# kubectl exec mysecret -- ls /secret
password
username
向指定路径映射secret密钥
secret文件创建secret
[root@node1 cm]# cat mysecret.yml
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: d2VzdG9z
yml文件创建pod
[root@node1 cm]# cat pod1.yml
apiVersion: v1
kind: Pod
metadata:
name: mysecret
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: secrets
mountPath: "/secret"
readOnly: true
volumes:
- name: secrets
secret:
secretName: mysecret
items:
- key: username
path: my-group/my-username
[root@node1 cm]# kubectl exec mysecret -- cat /secret/my-group/my-username
admin
将secret设置为环境变量
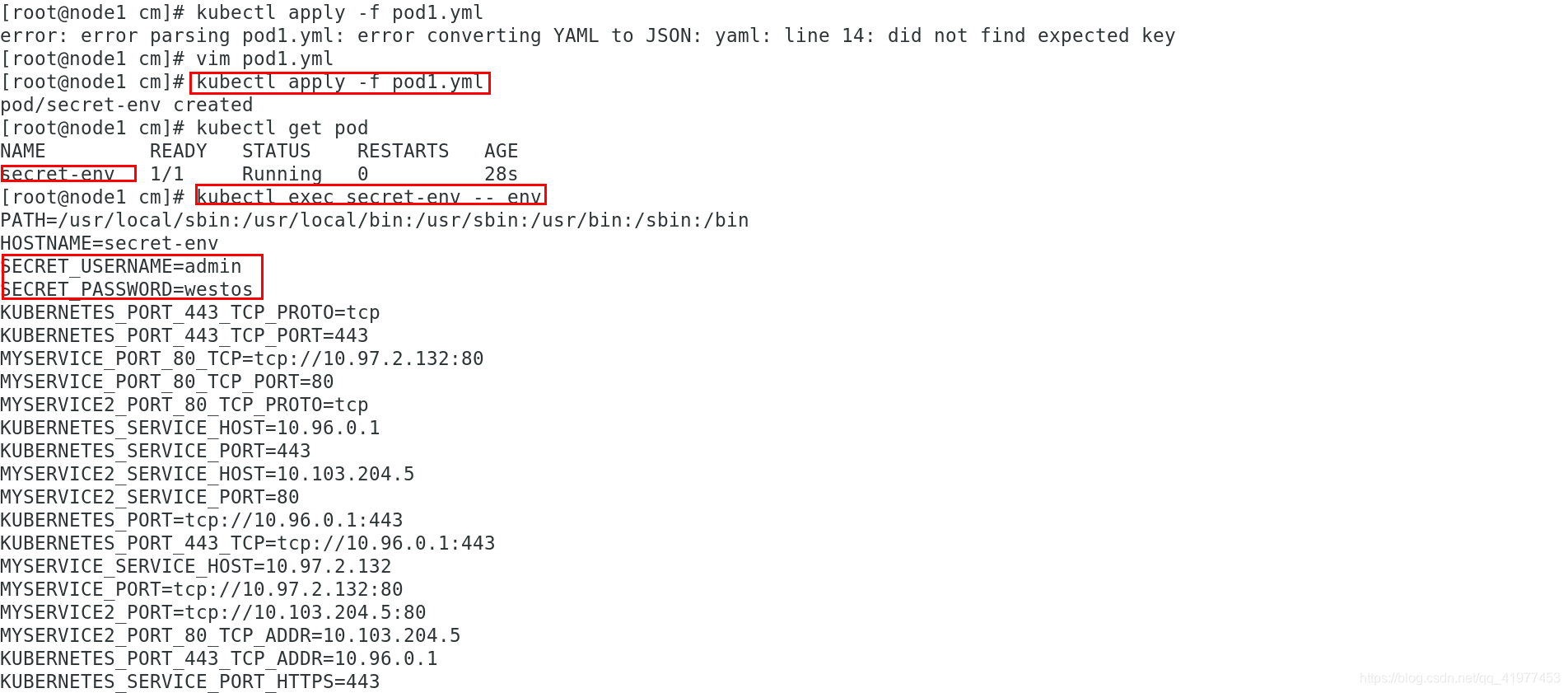
[root@node1 cm]# cat pod1.yml
apiVersion: v1
kind: Pod
metadata:
name: secret-env
spec:
containers:
- name: nginx
image: nginx
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
[root@node1 cm]#
kubernetes.io/dockerconfigjson用于存储docker registry的认证信息.
建立一个私有仓库haha
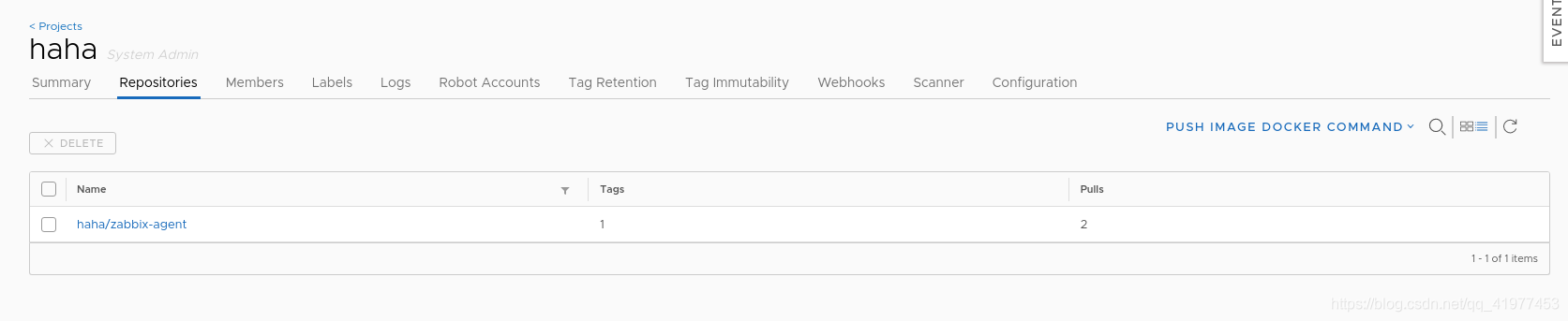

从私有仓库拉取镜像需要:
1.登陆
2.带上仓库全名:reg.westos.org/haha/zabbix-agent
[root@node1 cm]# kubectl create secret docker-registry mykey --docker-server=reg.westos.org --docker-username=admin --docker-password=westos
secret/mykey created
[root@node1 cm]# kubectl get secrets
NAME TYPE DATA AGE
default-token-ccttm kubernetes.io/service-account-token 3 6d
mykey kubernetes.io/dockerconfigjson 1 5s
mysecret Opaque 2 4h9m
[root@node1 cm]# cat mypod.yml
apiVersion: v1
kind: Pod
metadata:
name: mypod-zabbix
spec:
containers:
- name: zabbix
image: reg.westos.org/haha/zabbix-agent
imagePullSecrets:
- name: mykey #指定用哪个secret
[root@node1 cm]# kubectl apply -f mypod.yml
pod/mypod-zabbix created
[root@node1 cm]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mypod-zabbix 1/1 Running 0 6s
三、Volumes配置管理
3.1 emptyDir
[root@node1 cm]# cat cm1.yml
apiVersion: v1
kind: Pod
metadata:
name: vol1
spec:
containers:
- image: busyboxplus
name: vm1
command: ["sleep", "300"]
volumeMounts:
- mountPath: /cache
name: cache-volume
- name: vm2
image: nginx
volumeMounts:
- mountPath: /usr/share/nginx/html
name: cache-volume
volumes:
- name: cache-volume
emptyDir:
medium: Memory
sizeLimit: 100Mi
[root@node1 cm]# kubectl exec -it vol1 -- sh
用dd造一个大的文件,由于内存有限制,dd的文件超过限制大小 ,但是的过1,2分钟才会被kubelet evict掉,之所以不是立即被evict,是因为kubelet是定期检查的,这里会有一个时间差。
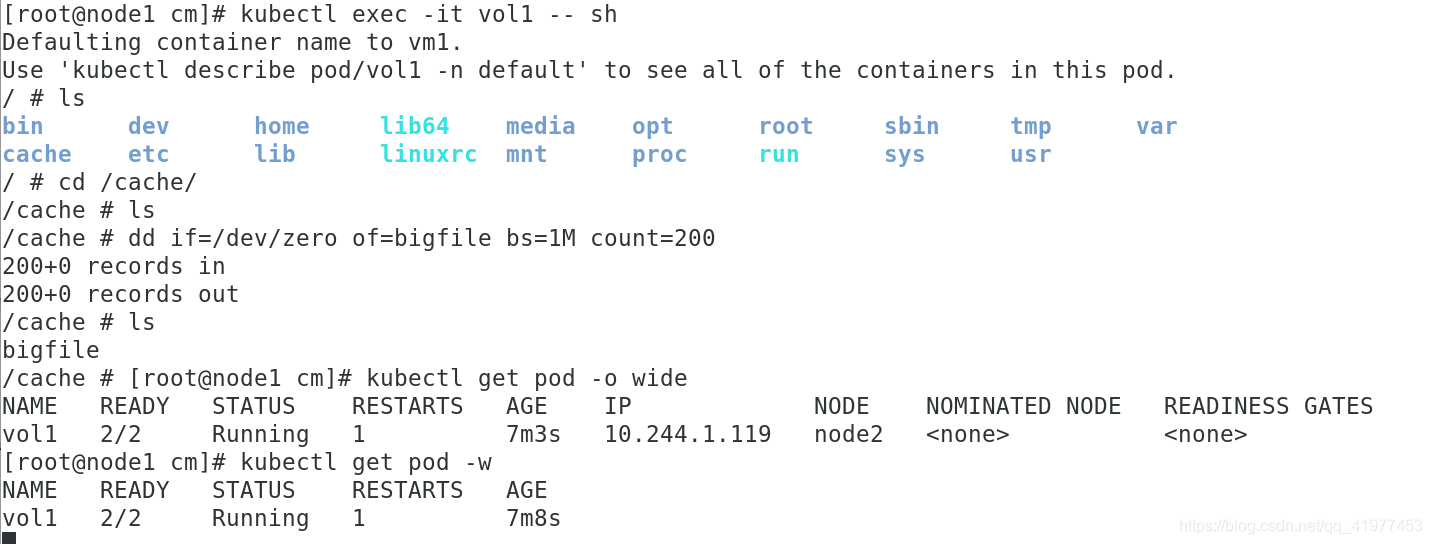

emptydir缺点:
• 不能及时禁止用户使用内存。虽然过1-2分钟kubelet会将Pod挤出,但是这个时间内,其实
对node还是有风险的;
• 影响kubernetes调度,因为empty dir并不涉及node的resources,这样会造成Pod“偷偷”
使用了node的内存,但是调度器并不知晓;
• 用户不能及时感知到内存不可用
3.2 hostPath
hostPath卷能将主机节点文件系统上的文件或目录挂载到pod中,虽然这不是大多数pod需要的,但是它为一些应用程序提供了强大的逃生舱。
hostPath的一些用法:
- 运行一个需要访问 Docker 引擎内部机制的容器,挂载 /var/lib/docker 路径。
• 在容器中运行 cAdvisor 时,以 hostPath 方式挂载 /sys。
• 允许 Pod 指定给定的 hostPath 在运行 Pod 之前是否应该存在,是否应该创建以及应该以
什么方式存在。
[root@node1 cm]# cat cm1.yml
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: nginx
name: test-container
volumeMounts:
- mountPath: /usr/share/nginx/html
name: test-volume
volumes:
- name: test-volume
hostPath:
path: /data
type: DirectoryOrCreate
[root@node1 cm]# kubectl apply -f cm1.yml
pod/test-pd created
[root@node1 cm]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-pd 1/1 Running 0 5s 10.244.1.121 node2 <none> <none>

[root@node1 cm]# curl 10.244.1.121
www
上个节点在node2上,这次指定在node3上,用nodeSelector:
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
nodeSelector:
kubernetes.io/hostname: node3
containers:
- image: nginx
name: test-container
volumeMounts:
- mountPath: /usr/share/nginx/html
name: test-volume
volumes:
- name: test-volume
hostPath:
path: /data
type: DirectoryOrCreate
[root@node1 cm]# kubectl apply -f cm1.yml
pod/test-pd created
[root@node1 cm]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-pd 1/1 Running 0 10s 10.244.2.94 node3 <none> <none>
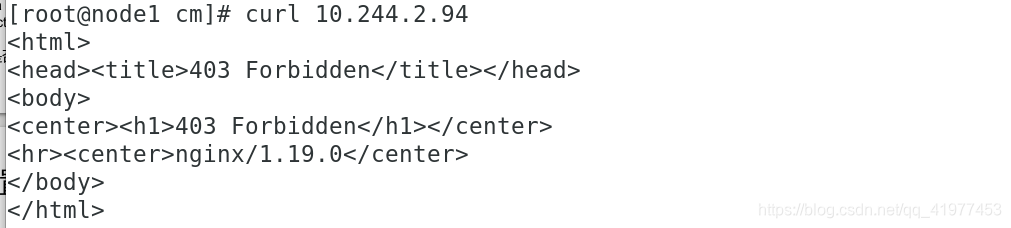
报403,因为node3上,没有写默认发布界面


3.3 NFS存储,要保证看到的东西一样
主节点和从节点都下载nfs:yum install -y nfs-utils
[root@node1 store]# cat /etc/exports
/store *(rw,sync)
[root@node1 store]# showmount -e
Export list for node1:
/store *
在node2.node3上看下是否发现node1
[root@node3 data]# showmount -e 172.25.26.1
Export list for 172.25.26.1:
/store *
[root@node1 store]# cat /root/cm/cm1.yml
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: nginx
name: test-container
volumeMounts:
- mountPath: /usr/share/nginx/html
name: test-volume
volumes:
- name: test-volume
nfs:
server: 172.25.26.1
path: /store
[root@node1 store]# kubectl apply -f /root/cm/cm1.yml
[root@node1 store]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-pd 1/1 Running 0 10m 10.244.1.123 node2 <none> <none>

在node3上运行,用nodeSelector选择node3
[root@node1 cm]# cat cm1.yml
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
nodeSelector:
kubernetes.io/hostname: node3
containers:
- image: nginx
name: test-container
volumeMounts:
- mountPath: /usr/share/nginx/html
name: test-volume
volumes:
- name: test-volume
nfs:
server: 172.25.26.1
path: /store
这样不管在哪个节点,
[root@node1 cm]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-pd 1/1 Running 0 10s 10.244.2.95 node3 <none> <none>
[root@node1 cm]# curl 10.244.2.95
www
3.4 pv–pvc
PersistentVolume(持久卷,简称PV)是集群内,由管理员提供的网络存储的一部分。就像集群中的节点一样,PV也是集群中的一种资源。它也像Volume一样,是一种volume插件,但是它的生命周期却是和使用它的Pod相互独立的。PV这个API对象,捕获了诸如NFS、ISCSI、或其他云存储系统的实现细节。
• PersistentVolumeClaim(持久卷声明,简称PVC)是用户的一种存储请求。它和Pod类似,Pod消耗Node资源,而PVC消耗PV资源。Pod能够请求特定的资源(如CPU和内存)。PVC能够请求指定的大小和访问的模式(可以被映射为一次读写或者多次只读)。
• 有两种PV提供的方式:静态和动态。
• 静态PV:集群管理员创建多个PV,它们携带着真实存储的详细信息,这些存储对于集群用
户是可用的。它们存在于Kubernetes API中,并可用于存储使用。
•动态PV:当管理员创建的静态PV都不匹配用户的PVC时,集群可能会尝试专门地供给volume给PVC。这种供给基StorageClass。
PVC与PV的绑定是一对一的映射。没找到匹配的PV,那么PVC会无限期得处于unbound未绑定
状态。
1.先创建一个pv
[root@node1 cm]# cat pv1.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: nfs
nfs:
path: /store
server: 172.25.26.1
[root@node1 cm]# kubectl apply -f pv1.yml #创建
persistentvolume/pv1 created
[root@node1 cm]# kubectl get pv #查看创建的pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv1 5Gi RWO Recycle Available nfs
2.创建一个pvc
[root@node1 cm]# cat pv1.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: nfs
nfs:
path: /store
server: 172.25.26.1
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc1
spec:
storageClassName: nfs
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
[root@node1 cm]# kubectl apply -f pv1.yml
persistentvolume/pv1 unchanged
persistentvolumeclaim/pvc1 created
[root@node1 cm]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv1 5Gi RWO Recycle Bound default/pvc1 nfs 5m4s
[root@node1 cm]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pvc1 Bound pv1 5Gi RWO nfs 9s
- 建立一个pod,pod中的挂载使用pvc中的卷
[root@node1 cm]# cat pv1.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: nfs
nfs:
path: /store
server: 172.25.26.1
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc1
spec:
storageClassName: nfs
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- mountPath: /usr/share/nginx/html
name: pv1
volumes:
- name: pv1
persistentVolumeClaim:
claimName: pvc1
[root@node1 cm]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-pd 1/1 Running 0 19m 10.244.1.124 node2
[root@node1 cm]# curl 10.244.1.124
www
[root@node1 cm]# cat /store/index.html
www
也可以多个挂载
[root@node1 cm]# cat pv2.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv2
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle
storageClassName: nfs
nfs:
path: /store2
server: 172.25.26.1
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc2
spec:
storageClassName: nfs
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:
name: test-pd-2
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- mountPath: /usr/share/nginx/html
name: pv2
volumes:
- name: pv2
persistentVolumeClaim:
claimName: pvc2
[root@node1 cm]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-pd 1/1 Running 0 39m 10.244.1.124 node2 <none> <none>
test-pd-2 1/1 Running 0 87s 10.244.2.98 node3 <none> <none>
[root@node1 cm]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv1 5Gi RWO Recycle Bound default/pvc1 nfs 48m
pv2 5Gi RWX Recycle Bound default/pvc2 nfs 98s
可以写,进到容器里写:
需要
[root@node1 store2]# chmod 777 /store2
[root@node1 store2]# kubectl exec -it test-pd-2 – bash
root@test-pd-2:/# cd /usr/share/nginx/html
root@test-pd-2:/usr/share/nginx/html# ls
index.html
root@test-pd-2:/usr/share/nginx/html# echo 333 > test.html
root@test-pd-2:/usr/share/nginx/html# exit
测试:
[root@node1 store2]# curl 10.244.2.98
111
[root@node1 store2]# curl 10.244.2.98/test.html
333
3.5动态pv
StorageClass提供了一种描述存储类的方法,不同的class可能会映射到不同的服务质量等级和备份策略或其他策略等。
每个StorageClass都包含provisioner、parameters和reclaimPolicy字段,这些字段会在StorageClass需要动态分配 PersistentVolume 时会使用到。
StorageClass的属性
• Provisioner(存储分配器):用来决定使用哪个卷插件分配 PV,该字段必须指定。可以指定内部分配器,也可以指定外部分配器。外部分配器的代码地址为: kubernetes-incubator/external-storage,其中包括NFS和Ceph等。
• Reclaim Policy(回收策略):通过reclaimPolicy字段指定创建的Persistent Volume的回收策略,回收策略包括:Delete 或者 Retain,没有指定默认为Delete。
NFS Client Provisioner是一个automatic provisioner,使用NFS作为存储,自动创建PV和对应的
PVC,本身不提供NFS存储,需要外部先有一套NFS存储服务。
• PV以
n
a
m
e
s
p
a
c
e
−
{namespace}-
namespace−{pvcName}-
p
v
N
a
m
e
的
命
名
格
式
提
供
(
在
N
F
S
服
务
器
上
)
•
P
V
回
收
的
时
候
以
a
r
c
h
i
e
v
e
d
−
{pvName}的命名格式提供(在NFS服务器上) • PV回收的时候以 archieved-
pvName的命名格式提供(在NFS服务器上)•PV回收的时候以archieved−{namespace}-
p
v
c
N
a
m
e
−
{pvcName}-
pvcName−{pvName} 的命名格式(在NFS
服务器上)
• nfs-client-provisioner源码地址:https://github.com/kubernetes-incubator/external-
storage/tree/master/nfs-client
动态PV需要本来先有一套NFS系统
[root@node1 nfs-client]# pwd
/root/cm/nfs-client
[root@node1 nfs-client]# ls
class.yml deployment.yml pvc.yml rbac.yml test-pod.yml
[root@node1 nfs-client]# cat class.yml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-nfs-storage
provisioner: fuseim.pri/ifs # or choose another name, must match deployment's env PROVISIONER_NAME'
parameters:
archiveOnDelete: "false"
[root@node1 nfs-client]# cat deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: nfs-client-provisioner:latest
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: fuseim.pri/ifs
- name: NFS_SERVER
value: 172.25.26.1
- name: NFS_PATH
value: /store
volumes:
- name: nfs-client-root
nfs:
server: 172.25.26.1
path: /store
[root@node1 nfs-client]# cat pvc.yml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim
annotations:
volume.beta.kubernetes.io/storage-class: "managed-nfs-storage"
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Mi
[root@node1 nfs-client]# cat rbac.yml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
[root@node1 nfs-client]# cat test-pod.yml
kind: Pod
apiVersion: v1
metadata:
name: test-pod
spec:
containers:
- name: test-pod
image: busybox:1.27
command:
- "/bin/sh"
args:
- "-c"
- "touch /mnt/SUCCESS && exit 0 || exit 1"
volumeMounts:
- name: nfs-pvc
mountPath: "/mnt"
restartPolicy: "Never"
volumes:
- name: nfs-pvc
persistentVolumeClaim:
claimName: test-claim
[root@node1 nfs-client]# kubectl apply -f . #因为已经运行过,所以都是unchanged
storageclass.storage.k8s.io/managed-nfs-storage unchanged
deployment.apps/nfs-client-provisioner unchanged
persistentvolumeclaim/test-claim unchanged
serviceaccount/nfs-client-provisioner unchanged
clusterrole.rbac.authorization.k8s.io/nfs-client-provisioner-runner unchanged
clusterrolebinding.rbac.authorization.k8s.io/run-nfs-client-provisioner unchanged
role.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner unchanged
rolebinding.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner unchanged
pod/test-pod configured


四、kubernetes调度
调度器通过kubernetes的watch机制来发现集群中尚未被调度到的node上运行的pod,调度器会将每一个未调度的pod调度到一个合适的node上来运行。kubernetes-scheduler是kubernetes集群的默认调度器,并且是集群控制面的一部分,如果你真的希望或者有这方面的需求,kube-scheduler在设计上是允许你自己写一个调度组件并替换原有kube-scheduler。
- nodeName是节点选择约束的最简单方法,但一般不推荐,如果nodeName在PodSpec中指定了,则它优于其他的节点选择方法。
使用nodeName来选择节点的一些限制: - 如果指定的节点不存在
- 如果指定的节点没有资源来容纳pod,则pod调度失败。
- 云环境中的节点名称并非总是可预测或稳定的
1.nodeName调度
先给node2打个标签:
kubernetes.io/hostname=node3,kubernetes.io/os=linux
[root@node1 cm]# cat test.yml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeName: node3 #部署到这个标签的机器上
[root@node1 cm]# kubectl apply -f test.yml
pod/nginx created
<none>
[root@node1 cm]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 5s 10.244.2.103 node3 <none> <none>
2.nodeSelctor调度
[root@node1 cm]# kubectl label nodes node2 disktype=ssd
node/node2 labeled
[root@node1 cm]# kubectl get nodes --show-labels #查看一下ndoe2的标签
NAME STATUS ROLES AGE VERSION LABELS
node1 Ready master 9d v1.18.4 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node1,kubernetes.io/os=linux,node-role.kubernetes.io/master=
node2 Ready <none> 9d v1.18.4 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=ssd,kubernetes.io/arch=amd64,kubernetes.io/hostname=node2,kubernetes.io/os=linux
node3 Ready <none> 9d v1.18.4 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64
[root@node1 cm]# cat test.yml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
disktype: ssd
[root@node1 cm]# kubectl apply -f test.yml
pod/nginx created
[root@node1 cm]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 5s 10.244.1.131 node2 <none> <none>
3.node亲和与反亲和
• 亲和与反亲和
• nodeSelector 提供了一种非常简单的方法来将 pod 约束到具有特定标签的节点上。亲和/反亲和功能极大地扩展了你可以表达约束的类型。
• 你可以发现规则是“软”/“偏好”,而不是硬性要求,因此,如果调度器无法满足该要求,仍然调度该 pod
• 你可以使用节点上的 pod 的标签来约束,而不是使用节点本身的标签,来允许哪些 pod 可以或者不可以被放置在一起。
• 节点亲和
• requiredDuringSchedulingIgnoredDuringExecution 必须满足
• preferredDuringSchedulingIgnoredDuringExecution 倾向满足
• IgnoreDuringExecution 表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,则继续运行当前的Pod。
• 参考:https://kubernetes.io/zh/docs/concepts/configuration/assign-pod-node/
[root@node1 cm]# cat test.yml
apiVersion: v1
kind: Pod
metadata:
name: node-affinity
spec:
containers:
- name: nginx
image: nginx
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: #必须满足
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn #不在node2这个pod
values:
- node2
preferredDuringSchedulingIgnoredDuringExecution: #倾向满足
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In #最好在有标签disktype=ssd的节点上。node2有此标签
values:
- ssd
[root@node1 cm]# kubectl get pod -o wide #肯定在node3上
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-affinity 1/1 Running 0 9s 10.244.2.104 node3 <none> <none>
nodeaffinity还支持多种规则匹配条件的配置如
• In:label 的值在列表内
• NotIn:label 的值不在列表内
• Gt:label 的值大于设置的值,不支持Pod亲和性
• Lt:label 的值小于设置的值,不支持pod亲和性
• Exists:设置的label 存在
• DoesNotExist:设置的 label 不存在
• pod 亲和性和反亲和性
• podAffinity 主要解决POD可以和哪些POD部署在同一个拓扑域中的问题
(拓扑域用主机标签实现,可以是单个主机,也可以是多个主机组成的
cluster、zone等。)
• podAntiAffinity主要解决POD不能和哪些POD部署在同一个拓扑域中的问题。
它们处理的是Kubernetes集群内部POD和POD之间的关系。
• Pod 间亲和与反亲和在与更高级别的集合(例如 ReplicaSets,StatefulSets,
Deployments 等)一起使用时,它们可能更加有用。可以轻松配置一组应位
于相同定义拓扑(例如,节点)中的工作负载。
4.pod亲和与反亲和
eg1. pod亲和性
[root@node1 cm]# cat test.yml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
---
apiVersion: v1
kind: Pod
metadata:
name: myapp
labels:
app: myapp
spec:
containers:
- name: myapp
image: myapp:v2
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution: #必须满足
- labelSelector: #标签选择器
matchExpressions: #匹配规则
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname #调度区域
[root@node1 cm]# kubectl apply -f test.yml
pod/nginx unchanged
pod/myapp created
[root@node1 cm]# kubectl get pod -o wide #myapp跟着标签app:nginx
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp 1/1 Running 0 7s 10.244.1.137 node2 <none> <none>
nginx 1/1 Running 0 2m22s 10.244.1.136 node2 <none> <none>
eg2.反亲和
[root@node1 cm]# cat test.yml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
---
apiVersion: v1
kind: Pod
metadata:
name: myapp
labels:
app: myapp
spec:
containers:
- name: myapp
image: myapp:v2
affinity:
podAntiAffinity: #节点反亲和
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
[root@node1 cm]# kubectl get pod -o wide #myapp和有标签的app:nginx不在同一个节点上
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp 1/1 Running 0 16s 10.244.2.106 node3 <none> <none>
nginx 1/1 Running 0 16s 10.244.1.138 node2 <none> <none>
5.污点(taint)
• NodeAffinity节点亲和性,是Pod上定义的一种属性,使Pod能够按我们的要求调度到某个Node上,而Taints则恰恰相反,它可以让Node拒绝运行Pod,甚至驱逐Pod。
• Taints(污点)是Node的一个属性,设置了Taints后,所以Kubernetes是不会将Pod调度到这个Node上的,于是Kubernetes就给Pod设置了个属性Tolerations(容忍),只要Pod能够容忍Node上的污点,那么Kubernetes就会忽略Node上的污点,就能够(不是必须)把Pod调度过去。
• NoSchedule:POD 不会被调度到标记为 taints 节点。
• PreferNoSchedule:NoSchedule 的软策略版本。
• NoExecute:该选项意味着一旦 Taint 生效,如该节点内正在运行的 POD 没有对应
Tolerate 设置,会直接被逐出。
默认主节点不会参与调度,是因为有主节点上有污点:

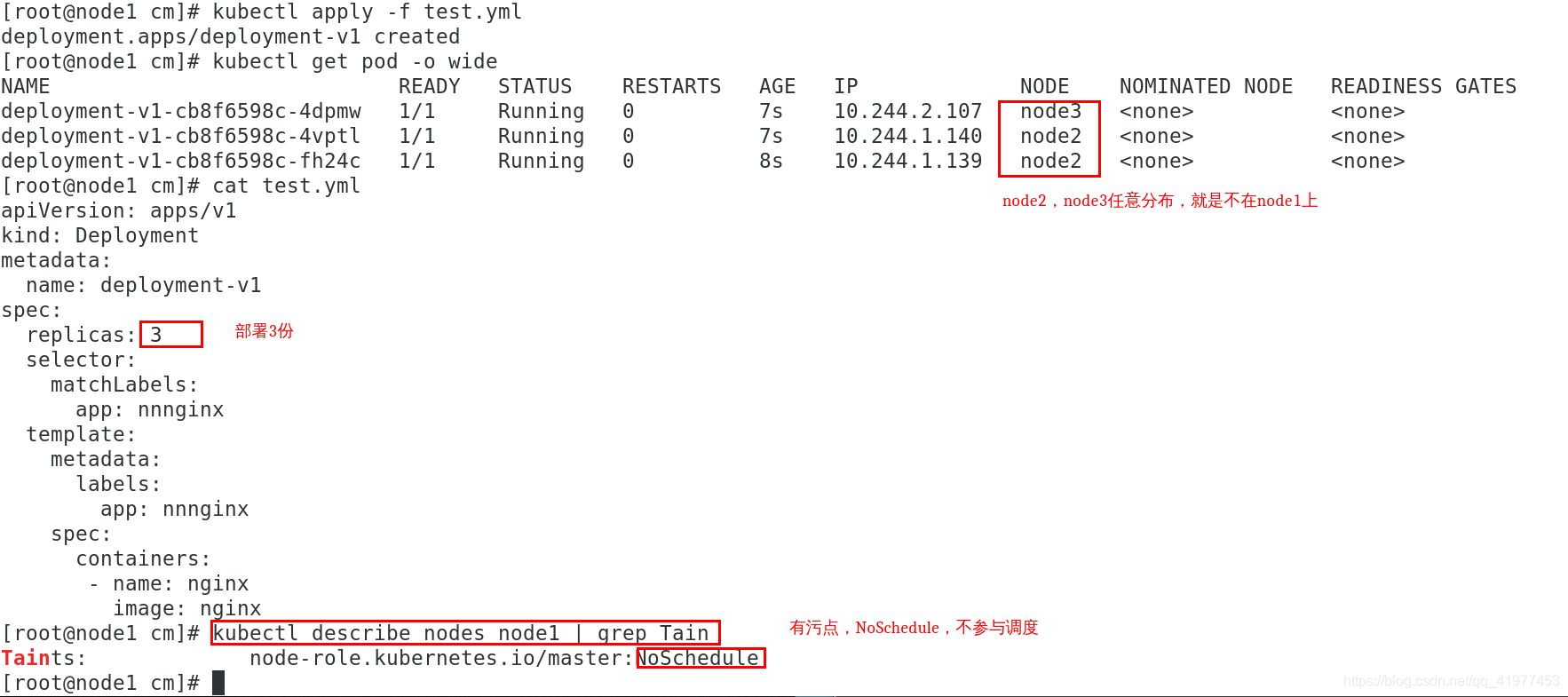
去掉node1的污点,让它也参与进调度来
[root@node1 cm]# kubectl describe nodes node1 | grep Tain
Taints: node-role.kubernetes.io/master:NoSchedule
[root@node1 cm]# kubectl taint node node1 node-role.kubernetes.io/master:NoSchedule- #后面加个减号去除掉
node/node1 untainted
[root@node1 cm]# kubectl describe nodes node1 | grep Tain
Taints: <none>
删除后再次运行,发现各个pod没有均匀额分开来。

在yml文件加入反亲和节点:使得分布均匀
[root@node1 cm]# cat test.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-v1
spec:
replicas: 3
selector:
matchLabels:
app: nnnginx
template:
metadata:
labels:
app: nnnginx
spec:
containers:
- name: nginx
image: nginx
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nnnginx
topologyKey: kubernetes.io/hostname
[root@node1 cm]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-v1-57c44c578c-pnc4s 1/1 Running 0 10s 10.244.1.144 node2 <none> <none>
deployment-v1-57c44c578c-s8pz8 1/1 Running 0 10s 10.244.0.19 node1 <none> <none>
deployment-v1-57c44c578c-wwt2f 1/1 Running 0 10s 10.244.2.112 node3 <none> <none>
在node1上加入污点:
Noschedule #不会在此节点上调度,但若已经调度上,也不会驱逐
Noexecute #会驱逐,不管是否已被调度
[root@node1 cm]# kubectl taint node node1 node-role.kubernetes.io/master:NoSchedule #加上污点,不影响
node/node1 tainted
[root@node1 cm]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-v1-57c44c578c-pnc4s 1/1 Running 0 2m52s 10.244.1.144 node2 <none> <none>
deployment-v1-57c44c578c-s8pz8 1/1 Running 0 2m52s 10.244.0.19 node1 <none> <none>
deployment-v1-57c44c578c-wwt2f 1/1 Running 0 2m52s 10.244.2.112 node3 <none> <none>
[root@node1 cm]# kubectl taint node node1 node-role.kubernetes.io/master:NoExecute #加上此污点,会被驱逐
node/node1 tainted
[root@node1 cm]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-v1-57c44c578c-2s8b7 0/1 Pending 0 13s <none> <none> <none> <none>
deployment-v1-57c44c578c-pnc4s 1/1 Running 0 3m50s 10.244.1.144 node2 <none> <none>
deployment-v1-57c44c578c-wwt2f 1/1 Running 0 3m50s 10.244.2.112 node3 <none> <none>
加上容忍值,让它继续运行
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-v1
spec:
replicas: 3
selector:
matchLabels:
app: nnnginx
template:
metadata:
labels:
app: nnnginx
spec:
tolerations:
- operator: "Exists"
#effect: "NoSchedule" #只要有effect就匹配,不写就默认都接受
containers:
- name: nginx
image: nginx
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nnnginx
topologyKey: kubernetes.io/hostname
[root@node1 cm]# kubectl apply -f test.yml
deployment.apps/deployment-v1 configured

影响pod调度指令的还有:cordon,drain,delete,后期创建的pod都不会被调度到该结点上,但操作的暴力程度不一样。
(1)cordon 停止调度
影响最小,只会将node调为SchedulingDisabled,新建pod,不会被调度到该节点,节点原有pod不会受影响,仍可正常对外提供服务
kuberctl cordon node2
kubectl get node
kubectl uncordon node2
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-v1
spec:
replicas: 3
selector:
matchLabels:
app: nnnginx
template:
metadata:
labels:
app: nnnginx
spec:
containers:
- name: nginx
image: nginx
[root@node1 cm]# kubectl apply -f test.yml
deployment.apps/deployment-v1 created
[root@node1 cm]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-v1-cb8f6598c-9r4db 1/1 Running 0 11s 10.244.2.117 node3 <none> <none>
deployment-v1-cb8f6598c-cjwmr 1/1 Running 0 11s 10.244.1.150 node2 <none> <none>
deployment-v1-cb8f6598c-xz8dq 1/1 Running 0 11s 10.244.1.149 node2 <none> <none>
[root@node1 cm]# kubectl cordon node2
node/node2 cordoned
[root@node1 cm]# kubectl get pod -o wide #不会影响之前的pod
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-v1-cb8f6598c-9r4db 1/1 Running 0 41s 10.244.2.117 node3 <none> <none>
deployment-v1-cb8f6598c-cjwmr 1/1 Running 0 41s 10.244.1.150 node2 <none> <none>
deployment-v1-cb8f6598c-xz8dq 1/1 Running 0 41s 10.244.1.149 node2 <none> <none>
将副本数改为6:
[root@node1 cm]# kubectl apply -f test.yml
deployment.apps/deployment-v1 configured
[root@node1 cm]# kubectl get node
NAME STATUS ROLES AGE VERSION
node1 Ready master 9d v1.18.4
node2 Ready,SchedulingDisabled <none> 9d v1.18.4
node3 Ready <none> 9d v1.18.4
[root@node1 cm]# kubectl get pod -o wide #之后的pod不会再调度到node2上了
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-v1-cb8f6598c-9r4db 1/1 Running 0 64s 10.244.2.117 node3 <none> <none>
deployment-v1-cb8f6598c-cjwmr 1/1 Running 0 64s 10.244.1.150 node2 <none> <none>
deployment-v1-cb8f6598c-npd6x 1/1 Running 0 9s 10.244.2.120 node3 <none> <none>
deployment-v1-cb8f6598c-nqth7 1/1 Running 0 9s 10.244.2.119 node3 <none> <none>
deployment-v1-cb8f6598c-xz8dq 1/1 Running 0 64s 10.244.1.149 node2 <none> <none>
deployment-v1-cb8f6598c-ztf72 1/1 Running 0 9s 10.244.2.118 node3 <none> <none>
将node2上恢复原状:
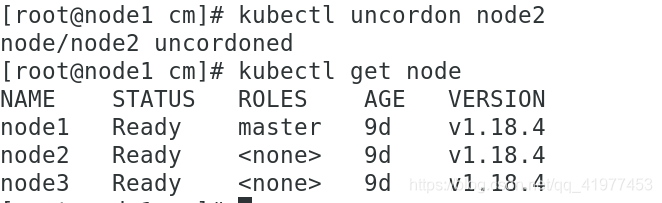
(2)drain驱逐节点
首先驱逐node上的pod,在其他节点重新创建,然后将节点调为SchedulingDisabled
kubectl drain node2
kubectl uncordon node2
[root@node1 cm]# vim test.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-v1
spec:
replicas: 3
selector:
matchLabels:
app: nnnginx
template:
metadata:
labels:
app: nnnginx
spec:
containers:
- name: nginx
image: nginx
随机分配:
[root@node1 cm]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-v1-cb8f6598c-d9h58 1/1 Running 0 19s 10.244.1.151 node2 <none> <none>
deployment-v1-cb8f6598c-wdxlm 1/1 Running 0 19s 10.244.1.152 node2 <none> <none>
deployment-v1-cb8f6598c-zg4bh 1/1 Running 0 19s 10.244.2.121 node3 <none> <none>
[root@node1 cm]# kubectl drain node3 --ignore-daemonsets #驱离一下
node/node3 already cordoned
WARNING: ignoring DaemonSet-managed Pods: ingress-nginx/ingress-nginx-controller-sfprz, kube-system/kube-flannel-ds-amd64-x56sd, kube-system/kube-proxy-l4p44
evicting pod default/deployment-v1-cb8f6598c-zg4bh
evicting pod kube-system/coredns-bd97f9cd9-9zf5c
pod/deployment-v1-cb8f6598c-zg4bh evicted
pod/coredns-bd97f9cd9-9zf5c evicted
node/node3 evicted
[root@node1 cm]# kubectl get pod -o wide #会立马将node3上的pod驱离
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-v1-cb8f6598c-d9h58 1/1 Running 0 83s 10.244.1.151 node2 <none> <none>
deployment-v1-cb8f6598c-vn4vg 1/1 Running 0 32s 10.244.1.153 node2 <none> <none>
deployment-v1-cb8f6598c-wdxlm 1/1 Running 0 83s 10.244.1.152 node2 <none> <none>
(3)delete最暴力
最暴力的一个,首先驱逐node上的pod,在其他节点重新创建,然后,从master节点删除该node,master失去对其控制,如要恢复调度,需进入node节点,重启kubelet服务。
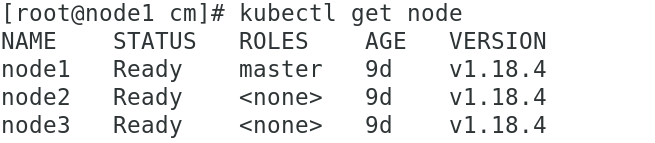
刚开始无影响,node2虽然删除,但还在node2上,过一会就没了,转移到node3上(非ndoe2节点)。

成功转移:
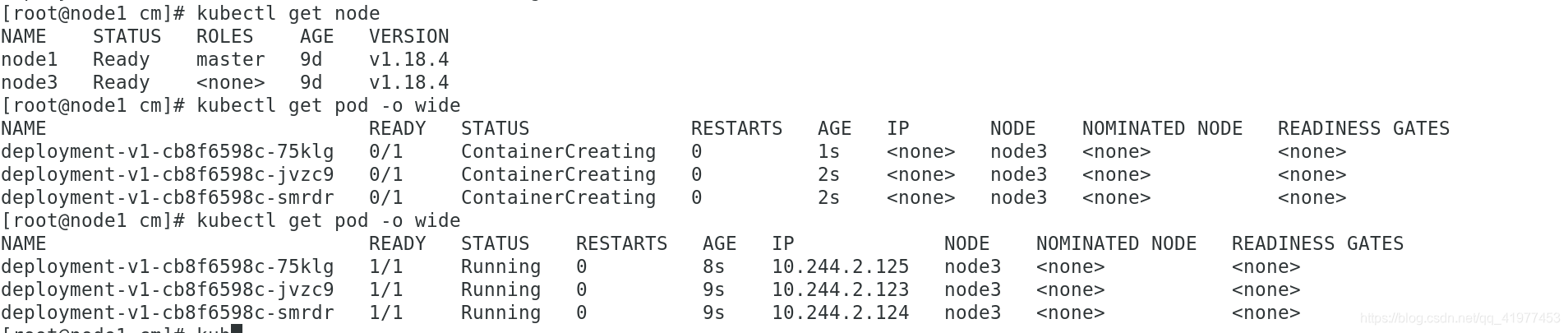
delete掉的node2如何重新加入;

恢复好了。

kubeadm reset #重置节点信息


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









