







起别名,浅拷贝,深拷贝
浅拷贝
复制元素的地址,改变不可变元素则前后不同,改变可变元素则一起改变
可变,不可变的意思是改变时地址是否也需要改变
list_2 = list_1.copy()
list_2 = list_1[:]
list_2 = list(list_1)
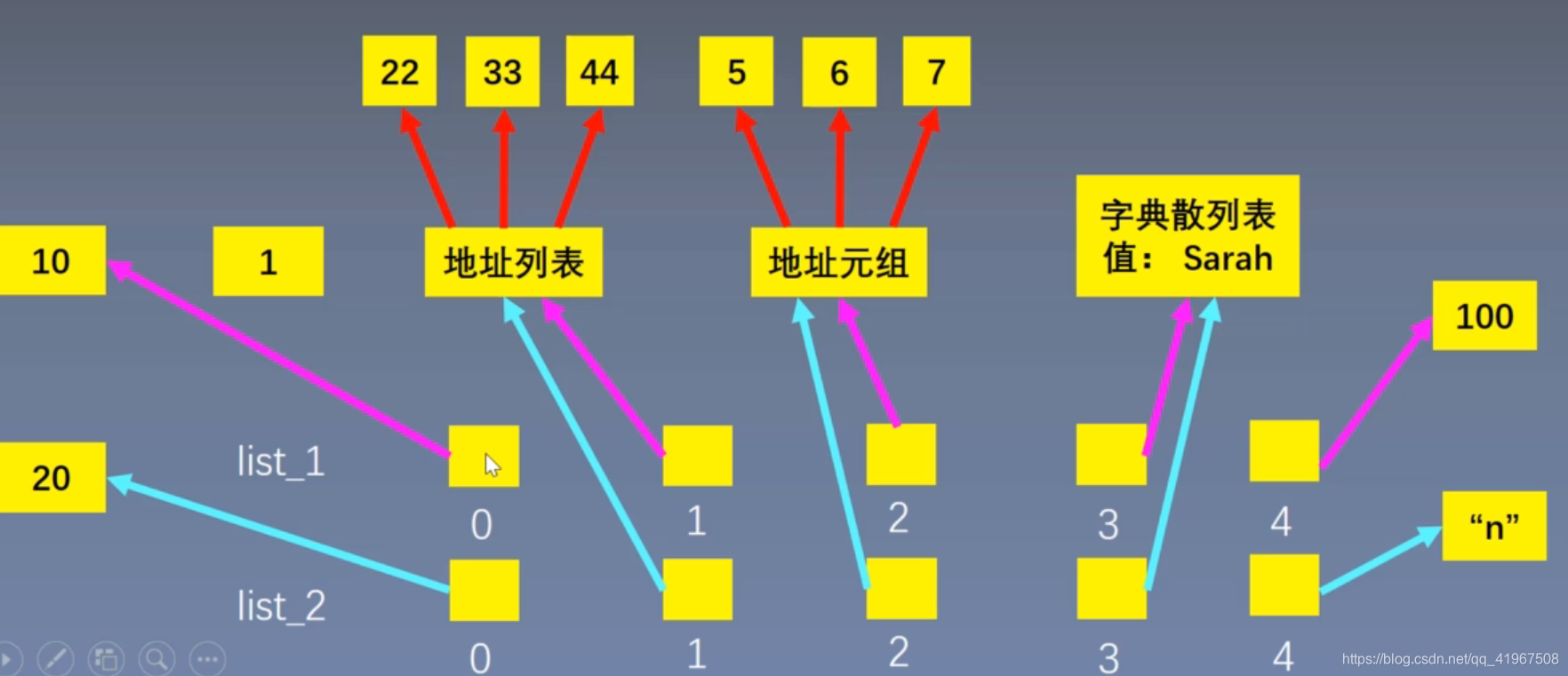
list相当于数组,连续存储的是每个元素的地址
列表内的元素可以分散的存储在内存中
列表存储的,实际上是这些元素的地址!!!——地址的存储在内存中是连续的
为什么列表采用引用数组,而字符串采用紧凑数组
list元素大小未知,而且可以改变
深拷贝
完全不会干扰
字典搜索比list快很多
因为字典是通过hash
第一步:计算要访问的键的散列值
第二步:根据计算的散列值,通过一定的规则,确定其在散列表中的位置
第三步:读取该位置上存储的值
如果存在,则返回该值
如果不存在,则报错KeyError
元组并不是总是不可变的
当元组中的元素为list(可变)时
t = (1,[2])
print(id(t))
t[1].append(3)
print(id(t))
print(t)
删除列表内的特定元素
每次都查找,慢
alist = ["d", "d", "d", "2", "2", "d" ,"d", "4"]
s = "d"
while True:
if s in alist:
alist.remove(s)
else:
break
print(alist)
利用for in删除,出错
因为删完后list改变,而序号一直往下递增,结果某些元素不会被遍历
访问[“d”, “d”, “d”, “2”, “2”, “d” ,“d”, “4”]中的0
访问[“d”, “d”, “2”, “2”, “d” ,“d”, “4”]中的1(此时第二个d被跳过)

解决方法:使用负向索引
range(-len(),0),就算前面减少了,相对于后面的位置也不会变
注意是range(-len(),0)而非range(-len():0)
多维列表的创建
ls = [[0]*10]*5
第一个*;是[0]中的010,不可变元素10,得到10个不一样的,所以可以用[0]10创建list
第二个;是[list]中的list*5,可变元素,直接拷贝地址

解析语法
解析语法的基本结构——以列表解析为例(也称为列表推导)
[expression for value in iterable if conditihon]
三要素:表达式、可迭代对象、if条件(可选)
ls = [[0]*10 for i in range(5)]
# 等价于如下代码
result = []
for value in iterale:
if condition:
result.append(expression)
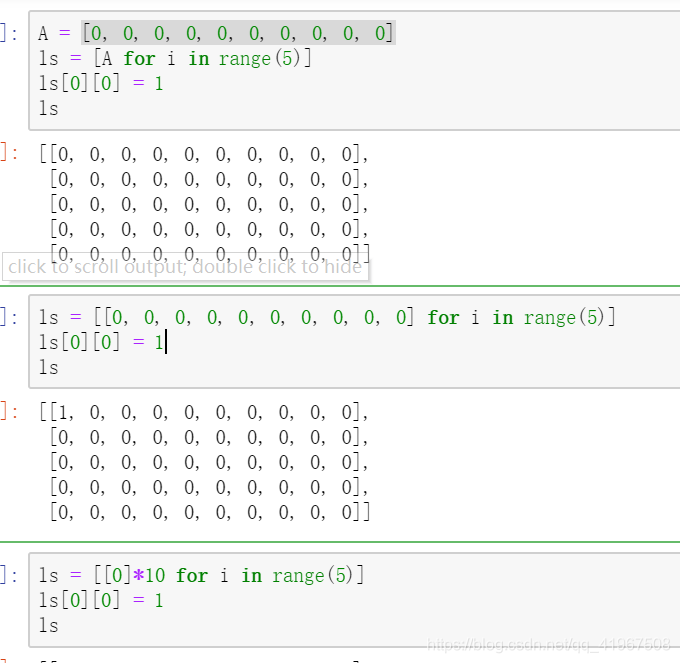
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]是迭代每次创建新的
A = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]是固定的



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









