







 本文介绍了用于视频理解的分层深度递归架构,解决帧级特征建模和视频级分类问题。通过帧级的BiLSTM模型(包括MaxPooling、Random和Hierarchical BiLSTM)和视频级的专家分层混合(HMoE)及分类器链(CC),提高模型性能。最终,通过模型合奏进一步提升分类准确率。
本文介绍了用于视频理解的分层深度递归架构,解决帧级特征建模和视频级分类问题。通过帧级的BiLSTM模型(包括MaxPooling、Random和Hierarchical BiLSTM)和视频级的专家分层混合(HMoE)及分类器链(CC),提高模型性能。最终,通过模型合奏进一步提升分类准确率。
Hierarchical Deep Recurrent Architecture for Video Understanding
arxiv: https://arxiv.org/abs/1707.03296
单注意模型可以去掉无用帧,但是他忽略了预测不同标签时要注意视频不同的帧,不同的标签应该具有不同的注意查询向量,而不是相同的单个向量。因此作者根据4000多标签总结了25个垂直分类,也有了25个注意向量。
单注意BiLSTM模型的基础上三种模型:MaxPooling、Random和Hierarchical。这些方法都是为了解决视频中帧数过多导致梯度消失和递归神经网络训练困难的问题。
max-pooling:作者通过合并相邻帧的特征来减少帧数过多的问题,在两个BiLSTM层之间插入max-pooling层。
随机BiLSTM:每五个相邻帧中随机抽取一帧,来减少帧数量,并且还可以通过增加LSTM层提高性能。
Hierarchical BiLSTM:思想与最大池模型相似,唯一区别为没有使用maxpooling操作,而是使用较小的BiLSTM来合并邻域特征。
摘要
本文1介绍了我们为Youtube-8M视频理解挑战赛开发的系统,其中将大规模基准数据集[1]用于多标签视频分类。 所提出的框架包含分层的深层架构,包括帧级序列建模部分和视频级分类部分。 在帧级序列建模部分,我们探讨了一组方法,包括Pooling-LSTM(PLSTM),Hierarchical-LSTM(HLSTM),Random-LSTM(RLSTM),以解决视频中大量帧的问题。 。 我们还介绍了两种注意力集中方法,即单注意力集中(ATT)和多重注意力集中(Multi-ATT),以便我们可以更加关注视频中的信息帧,而忽略无用的帧。 在视频级分类部分中,提出了两种提高分类性能的方法,即专家分层结构(HMoE)和分类器链(CC)。 我们的最终提交是一个由18个子模型组成的合奏。 就官方评估指标全球平均精度(GAP)为20而言,我们的最佳提交在测试数据集的50%上达到0.84346,在测试数据50%的私有上达到0.84333。
1.介绍
视频理解是计算机视觉领域的核心任务之一。 YouTube-8M数据集[1]是一个大规模的视频理解数据集,包含超过700万个YouTube视频,并用来自25个垂直类别的4,716个标签进行了注释。 每个视频的标签平均数量为3.4。对于每个视频,参与者提交一份预测标签及其对应的置信度得分的列表,评估服务器将为每个视频选择具有最高20置信度得分的预测标签 视频,然后将每个预测和置信度得分视为一长串的全局预测中的单个数据点,以计算所有预测和所有视频的平均精度。 详细来说,评估指标(GAP)的计算公式为:
在本报告的其余部分,我们总结了我们在比赛中的详细解决方法。 首先介绍和评估我们的基准模型。 然后介绍了我们在帧级特征建模和视频级特征分类中的方法。 我们提出的方法主要解决以下三个问题。
一个视频中有太多无用的帧无法分类。 我们如何才能更多地关注真实的信息框架?
视频中的大量帧会导致训练效率低下。 我们如何利用邻域框架非常相似这一事实呢?
我们如何利用不同标签之间的语义关系来提高分类性能?
最后,我们给出了最终提交中采用的整体方法和模型。 最后,我们总结了我们的意见书,并提出了今后的工作建议。
2.方法
在本节中,我们主要详细演示用于获得最终提交信息的所有方法。 整个流程可以分为三部分:帧级特征建模,视频级特征分类和模型集成。
2.1基准模型

在这一部分中,我们通过使用YouTube-8M Tensorflow入门代码展示了基准文件[1]中提出的模型的性能。 由于Kaggle竞赛中使用的数据集比基准论文中报告的数据集要小一些,因此当使用完全相同的模型时,我们也会得到不同的结果。 在这里,我们在表1中列出了三个模型的结果作为基准,包括专家混合(MoE),框架深包(DBOF),长期记忆(LSTM)。 一种模型是基于视频级别的功能,其他两种是基于帧级别的功能。 我们为MoE分类器选择8的混合物,为所有这些模型选择0.001的基本学习率。 对于LSTM模型,我们选择的层数为1,每层的像元数为1024。
2.2帧级特征建模
在这一部分中,我们描述了我们基于帧级特征建议的所有模型。 一方面,模型可以分为单注意方法和多注意方法,并且多注意模型在合并特征时试图更多地关注信息框架。 另一方面,为了解决视频中大量帧导致的耗时且难以训练的问题,提出了三种模型类型,例如MaxPooling-BiLSTM模型(MPLSTM),分层 -BiLSTM模型(HLSTM)和Random-BiLSTM模型(RLSTM)。 为了方便不同模型之间的比较,本节中所有模型的MoE分类器均使用4的混合。
2.2.1基于单注意的BiLSTM
提出该模型以解决视频帧序列中白色/黑色内部帧中存在许多无用帧的问题。 我们有必要对重要框架给予更多的关注(更大的权重),而对不重要的框架则给予更少的关注(更小的权重)。
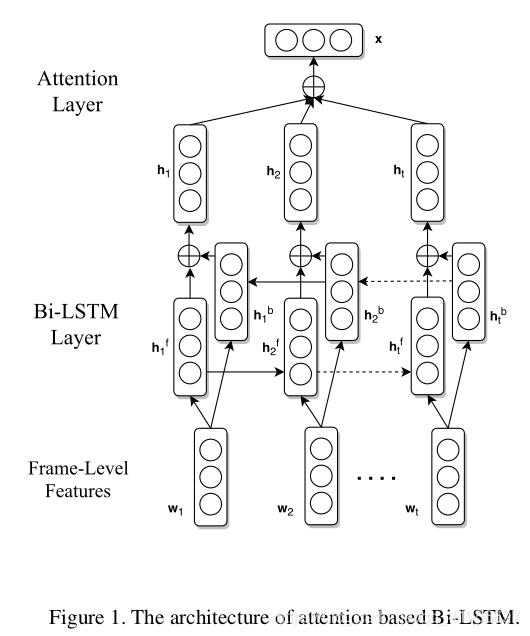
如图1所示,我们通过基于单个注意的Bi-LSTM神经网络将单个视频x编码为其分布式表示x。 首先,将每个帧转换为其分布的嵌入向量,这些向量是从提供的tfrecord数据中获得的。 其次,Bi-LSTM层用于提取每个帧的其他特征。 第三,采用注意层将特征合并到视频级特征向量中,作为视频的分布式表示,即x。
[5]首先提出了长短期记忆(LSTM)单元,通过提出一种自适应门控机制来决定LSTM单元保持先前状态并记忆多少的自适应门控机制,从而解决了递归神经网络中的梯度消失问题。 当前输入数据。LSTM有很多变体,我们采用[3]提出的称为门控循环单元(GRU)的变体。 它主要将忘记门和输入门组合成一个更新门,还合并了单元状态和隐藏状态,从而提高了训练速度。详细地,zt表示具有相应权重矩阵W z和U z的更新门,rt表示具有相应权重矩阵W r和U r的重置门,ĥt表示步骤t的单元具有权重矩阵W h和U U的单元状态 h和ht表示步骤t的输出值。 图1中的整个过程可以表述为: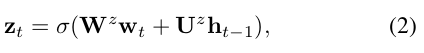
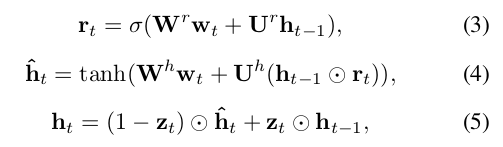
其中σ表示S型函数,表示按元素相乘。 初始隐藏状态h 0固定为0。
由于将来的上下文信息与过去的信息同样重要,因此我们使用双向LSTM网络,该网络包含向前和向后的时间隐藏状态连接顺序,并使模型能够利用过去和未来的信息 。 因此,该网络由用于左和右序列上下文的两个子网组成,然后第i帧w i的输出为h fi和h bi,分别表示前向和后向。 在这里,我们使用逐元素和将它们合并在一起,以获得每一帧的特征向量h i: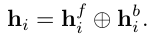
由于一个视频中的不同帧包含用于视频类别分类的有用信息的数量不同,因此在合并特征时,我们应该为每个帧给予不同程度的关注,而不是简单地求平均。 文献[2]首先引入了注意力机制,以逐步在机器翻译中强调目标词,在这里我们使用这种方法来帮助为单个视频提取更好的特征向量。我们在这里使用的单点注意方法与[10]提出的方法非常相似,在该方法中,注意用于关系提取,这是一种自然语言处理(NLP)任务。 假设H = [h 1,h 2,…,h T]是由Bi-LSTM层产生的所有输出矢量组成的矩阵,则整个视频的特征矢量x由每一步输出的加权和形成 :
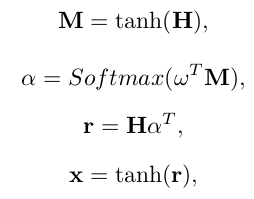
其中H∈R d * T,d h是GRU网络中隐藏状态的维数,T是一个视频中的帧数,ω是可训练的查询向量,ωT表示其转置。
在输入MoE分类器之前,我们还对视频级特征向量x采用了dropout [8],以减轻过度拟合的情况。 dropout层的定义如下:
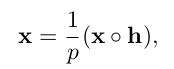
其中◦表示逐元素乘法,h表示概率为p的伯努利随机变量的向量。 p 1表示训练时的特征缩放。 在推断阶段,p = 1。
在以下模型中,我们还采用相同的单关注方法,BiLSTM网络和dropout方法。
此外,我们还尝试了分割方法,其中将视觉特征(1024维度)和音频特征(128维度)分别馈入ATT + BiLSTM网络,以获取每个视频级特征向量,x视觉,x音频,并进行级联以获得 最后的最终特征向量,即x = x视觉⊕x音频,⊕在这里代表串联操作。
2.2.2基于多重注意力的BiLSTM
在前一部分中,我们介绍了单注意方法,它大大提高了分类性能。然而,它忽略了一个事实,即在预测不同的标签时,我们应该注意视频的不同帧。例如,在预测“足球”标签时,我们应该在含有绿草和足球运动员的框架上增加砝码;在面对“烹饪”标签时,我们应该更多地注意含有红肉和绿色蔬菜的框架。因此,不同的标签应该具有不同的注意查询向量,而不是相同的单个向量。
然而考虑到标签的数量是4716,这是如此之大,以至于如果我们真正使用4716注意查询向量,很容易过度拟合以及耗时。由于共享相似语义的标签也可以共享注意向量,因此我们根据25个垂直标签使用25个注意向量。因此,视频应该具有25个视频级表示特征向量,即{x1,x2,···,x25}。例如,标签是{a1,a2,····,a4716},垂直标签是{b1,b2,····,b25}当预测标签ai的得分,并且标签ai属于垂直标签bj时,我们应该使用特征向量xj来表示整个视频并进行以下分类。
具体而言,对于每个视频级特征向量xi被计算为每个帧的后Bi LSTM特征hi的加权和: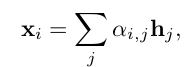
其中αi,j是每个帧向量的权重,这里我们使用[6]提出的选择性注意来计算权重。因此αi,j定义为:
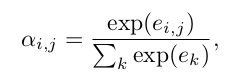
其中ei,j是基于查询的函数,它对当前帧hj和目标垂直标签bi的匹配程度进行评分:
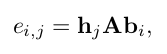
其中A是加权对角矩阵,查询向量bi是垂直标签bi的表示向量。
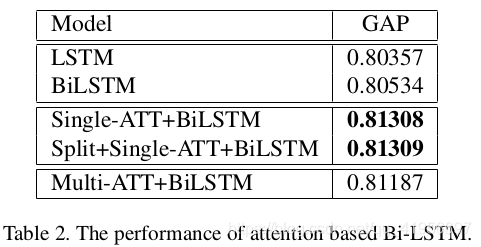
表2中列出了每种基于注意的模型的性能。很明显,双向网络和注意方法对模型的GAP增益都有很大的贡献,尤其是单注意方法。相比之下,分裂方法非常耗时,但并不能获得明显更好的性能,因此,我们不会在以下模型中应用分裂操作。然而,在实践中,分裂模型可以在集成过程中很好地工作,因此我们在最后的提交中使用了相当多的分裂模型。对于多重注意方法,虽然它也提高了双LSMT的性能,但其性能仍然比单一注意模型差,这是相当令人困惑的。我们猜测更多的中间监管可能会使其更好,例如垂直标签分类上的损失函数。
综上所述,单一注意方法效果最好,效率最高,因此我们在下一节介绍的模型中采用这种注意方法。
2.2.3其他基于单注意力的BiLSTM模型
在这一部分中,我们将在前面的单注意BiLSTM模型的基础上介绍三种模型:MaxPooling、Random和Hierarchical。这些方法都是为了解决视频中帧数过多导致梯度消失和递归神经网络训练困难的问题。在我们的数据集中,大多数视频每秒超过150帧,这对于LSTM来说确实太长了,无法达到最佳性能。此外,由于视频序列的一致性,邻域特征通常是非常相似的,因此简单地遍历递归网络中的每一帧特征也是浪费时间的。
第一个模型是基于单个注意的MaxPooling BiLSTM,如图2所示。它只需在两个BiLSTM层之间插入max-pooling操作,就可以合并相邻帧的特征,并减少第二个BiLSTM的帧数。
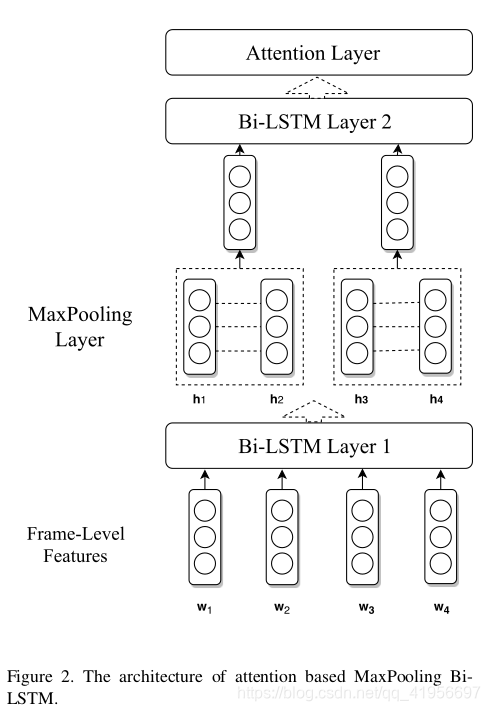
最大池的窗口大小是一个超参数,经过多次实验,我们选择了3和5。
第二种模型是基于单个注意的随机BiLSTM,可以看作是一种数据增强方法。它在每五个相邻帧中随机抽取一帧,这样整个神经网络的输入最大为f帧/5=300/5=60帧。在这样的长度下,学习更深层次的LSTM更容易、更有效,因此我们可以将以前的超参数“LSTM层”从1更改为4甚至更大,以提高性能。另外,由于同一视频的输入总是变化的,因此网络具有较强的鲁棒性。
第三种模型是基于单个注意的层次化BiLSTM,其思想与最大池模型非常相似。唯一的区别是,它没有使用maxpooling操作,而是使用较小的BiLSTM来合并邻域帧特征。整个网络如图3所示。每个BiLSTM层共享相同的LSTM单元参数。
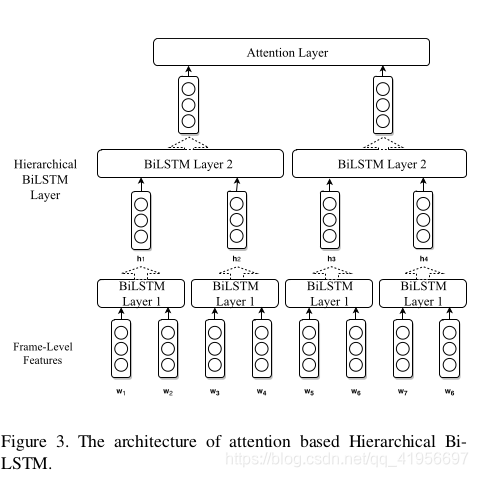
表3列出了这些模型的性能。显然,max-pooling方法的性能最好,窗口大小3是最佳选择。通过随机抽样和更深层次的LSTM网络,随机方法也得到了比基于基线注意的BiLSTM模型更好的性能。然而,层次分析法甚至缩小了这一令人困惑的差距,这可能是因为它的参数更为庞大。但合奏的时候还是算数的。

2.3视频级特征分类
上面阐述的网络结构在从顺序数据中提取关键特征方面显示出非凡的能力。基于这些成果,我们发现我们已经优雅地获得了一组更新的视频级特征,即由我们的帧级模型产生的聚合特征。更具体地说,我们从相关类的角度挖掘数据的更多潜力。最后的结果表明,我们提出的视频级模型HMoE和CC在融合特征的基础上取得了优异的单模型性能。
2.3.1专家分层混合(HMoE)
这项任务的一大障碍是我们要识别大量的类。在视频理解方面,我们还有很多工作要做。常识告诉我们,我们需要区分的阶级越多,我们付出的努力就越多
.当然,这是绝对独立类的情况。然而,当涉及到相关的类,我们可能会发现,更多的类有时可以带给我们更多的信息来理解视频或图像。因此,我们首先研究了4716个目标类的聚类特性,得到了一个层次混合专家模型。
当然,也有一些粗糙的课程和那些实际的精细类一起提供。这些标签是需要利用的宝贵资源。为了利用这些原始的聚类信息,我们将简单的单层MoE模型调整为两层的层次模型。事实上,每一个层次都是对应类的MoE模型。不同的是,高层次的细类分类器是给定粗类概率的条件概率。
在实现上,我们将粗类分类器在softmax层之前的响应与聚集特征连接起来,并将它们输入到细类分类器中。在训练过程中,我们使用给定的粗标签来监督粗分类器。HMoE的两个级别是联合培训的。考虑到粗类数与细类数的不可比性,可以在不影响原MoE模型效率的前提下得到更合理的层次模型。特别是,我们最好的单一模型,它实现了82.416差距,部署了一个HMoE在其顶部。
2.3.2分类器链(CC)
除了聚类特性之外,我们知道不同类之间可能存在相关性。其中有些是冲突,例如猫不能同时成为狗。其中有些是有向边界,例如篮球必须是球。我们相信这些关系在分类任务中,特别是在多标签分类中,可以起到至关重要的作用。以前的文献都试图解决这个问题。
Reed等人[7]提出了一种链方法来建模模型之间的相互依赖关系。最近,Wang等人[9]提出了一种改进的方法,使用递归神经网络以优雅的方式利用标签之间的相关性。与他们的方法不同,我们采用了分类器链的精神来应对这一特定挑战。因此,我们为YouTube-8M开发了一个CC。
这个挑战与以前任务的一个主要区别是,我们要区分4000多个类。也就是说,我们负担不起按顺序对每个类进行二进制分类。在解决这一障碍时,我们发明了一种集团战略,即在效率和效益之间进行权衡。换句话说,我们根据训练集中的频率来安排这些类。然后,我们按顺序每393个类分组。分为12组,每组393个类。显然,12个组适用于分类链。此外,鉴于MoE和HMoE模型的优良性能,我们将MoE模型作为链中的分类器。对于组间的相关性,我们在每次运行中保持一个整体的类概率分布。每一步分类器的输入是聚合特征和4716类概率的组合。再说一次,教育部处理4000多个维度的投入是负担不起的。
因此,我们借用了文献[4]中的瓶颈思想来减少维数。最后的CC是一个整洁的多标签分类模型。在测试集上,CC在其顶部的最佳单模型达到了0.823的差距。我们相信CC和HMoE在我们最后的合奏中扮演着重要的角色。
综上所述,视频分级的所有性能如表4所示。

3.模型合奏
我们最终提交的是以下18个子模型的平均值。事实上,我们也尝试了其他一些集成方法,如加权和、xgboost,甚至在验证集上训练权重,但结果表明平均值仍然是最好的。这也说明了我们的模型具有很强的泛化能力。

4.概况
在此报告中,我们描述了YouTube8M竞赛中的方法。 我们提出了一种关注方法,使模型在合并特征时更加关注信息框架,而不是无用的框架。 我们还介绍了一些功能合并方法,以减少大量帧,同时提高性能。 我们还提出了利用标签之间的语义关系来获得更高的GAP的视频级特征分类方法。 但是,由于时间限制,仍然有许多我们尚未解决的问题。 例如,当前的注意力和标签关联方法非常简单,有时还很幼稚。 与人自身相比,视频帧序列的处理仍然效率低下,因为网络始终在处理每个帧,但是人的方式实际上更像是跳读。

















 5155
5155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









