



一. JOIN操作
JOIN操作将相关表中的数据组合在一起:INNER JOIN、LEFT JOIN、RIGHT JOIN和FULL OUTER JOIN
二.运算符
逻辑运算符(and、or、not)允许符合过滤条件;
算数运算符(+、-、*、/、%);
比较运算符(=、<>、>、<、between and、in、not in、like)
三. 函数
1.日期和时间函数
获取年月日:YEAR(‘2025-01-01’)----2025、MONTH()、DAY()、DATEPART(hour, ‘2025-01-01 11:20:53’)----11
获取当前日期时间:GETDATE()、CURRENT_TIMESTAMP
计算日期差:DATEDIFF(DAY, ‘2025-07-01’, ‘2025-07-29’)----28天
日期加减:DATEADD(YEAR, 1, ‘2024-01-01’)----2025-01-01
日期格式:FORMAT(GETDATE(), ‘yyyy-MM-dd’),CONVERT(char(10),‘2025-01-01 08:53:26’,120)----2025-01-01
2.聚合函数
SUM(),AVG(),COUNT(),MIN(),MAX(),STDEV()计算标准差
3.字符串函数
截取字符串:LEFT(‘hello’, 3)----hel,RIGHT(),SUBSTRING(‘hello’, 2, 3)----ell
计算字符串长度:LEN(‘hello’)----5
替换字符串:REPLACE(‘a-b-c’, ‘-’, ‘/’)----a/b/c
查找位置:CHARINDEX(‘l’, ‘hello’)----3
4.数学函数
ROUND(123.147,2)----123.18四舍五入
ABS(-12)----12绝对值
POWER(2,3)----8幂运算
RAND()生成0~1的随机数
5.类型转换函数
CAST(123 AS VARCHAR)----‘123’
TRY_CAST(‘ABC’ AS INT)---- NULL 安全转换失败返回null
CONVERT(VARCHAR, GETDATE(), 23)----2025-08-01 'yyyy-MM-dd’格式
6.逻辑条件函数
ISNULL(desc,‘无’)----替换NULL值为’无’
IIF(score >=95, ‘合格接收’, ‘退回’)----条件判断
CASE WHEN score >= 95 THEN ‘接收’ ELSE ‘退回’ END as colname
1.分页查询
方法1. 使用OFFSET-FETCH子句
须在SQL Server 2012 及更高版本中引入;必须要有 order by 排序才可使用;更高效
--获取第 3 页的数据,每页显示 10 条记录
select *
from MTL_ITEM_INFO
order by CREATE_DATE
OFFSET 20 ROWS -- 跳过前20行(即第一二页的各10行)
FETCH NEXT 10 ROWS ONLY -- 获取接下来的10行
方法2.使用ROW_NUMBER()函数
在 SQL Server 2008 及更高版本中使用;OVER (ORDER BY ITEM_NO)子句也不可缺少
--获取第 2 页的数据,每页显示 10 条记录
DECLARE @StartRow INT = 11; -- (页码-1)*每页行数 + 1
DECLARE @EndRow INT = 20; -- 页码*每页行数
WITH OrderedResults AS (
SELECT ROW_NUMBER() OVER (ORDER BY ITEM_NO) AS RowNum,*
FROM MTL_ITEM_INFO
)
SELECT *
FROM OrderedResults
WHERE RowNum BETWEEN @StartRow AND @EndRow
--简便一点 都是用ROW_NUMBER()
select * from (
select ROW_NUMBER() over(order by ITEM_NO desc) id,*
from MTL_ITEM_INFO
) a
where a.id>=1 and a.id<=10
2.EXISTS 和 NOT EXISTS 子查询
exists 指定一个子查询,检测行的存在。相当于两个集合的交集。强调是否返回结果集,不要求知道返回什么
not exists 相当于两个集合的差集(不存在)
--查询日期范围内未打印过的条码,即条码表(MTL_BRCODE_INFO)中不包含已打印的条码(MTL_BRCODE_BIZ)的信息
select *
from MTL_BRCODE_INFO
WHERE CREATE_DATE between '2020-3-26' and '2020-3-27'
and not exists (select BRCODE from MTL_BRCODE_BIZ where BRCODE=MTL_BRCODE_INFO.BRCODE)
3.IN 和 NOT IN子查询
in 关键字选择与列表中的任意一个值匹配的行,即包含
not in 与之不匹配的行
--与上面的结果是一样的
select *
from MTL_BRCODE_INFO
WHERE CREATE_DATE between '2020-3-26' and '2020-3-27'
and BRCODE not in (select BRCODE from MTL_BRCODE_BIZ where BRCODE=MTL_BRCODE_INFO.BRCODE)
4.EXISTS VS IN
exists 效率一般优于 in
exists 后面以是整句的查询语句(只要返回的是真就显示结果),in 的后面只能是对单列(只能返回一个字段值,同一个字段值用逗号【,】隔开)
5.分组查询 GROUP BY ----聚合函数
一般在质量等各种分析时用的最多
--查询打印条码表(MTL_BRCODE_BIZ)中,按物料分组并统计各物料打印的次数
select ITEM_NO, COUNT(1)
from MTL_BRCODE_BIZ a
group by ITEM_NO
7.视图
视图是一种虚拟表,它由一个或多个表的列组成,提供对数据的不同视图,并且可以被当作一个表一样进行查询,简化查询。
--创建视图
CREATE VIEW v_viewname AS
select a.sid,a.name,b.class,b.classname
from student a
left join class b on a.sid=b.sid
8.存储过程
(用户自定义)存储过程是一种预编译的SQL脚本,它可以包含一个或多个SQL语句,可以接受参数,并且可以返回多个结果集。类似于编程中的函数或方法。用于执行复杂的数据库操作,提高代码的模块化和重用性。通过存储过程预先编译 SQL 语句,减少运行时编译的开销。可以使用存储过程定期清理旧数据或归档数据。
不能创建以sp_作为前缀的存储过程
可以用存储过程做增删改查的操作
--创建存储过程
CREATE PROCEDURE insert_iteminfo
@itemno nvarchar(50),
@desc nvarchar(50),
@createdate datetime,
@len int output --输出参数
AS
BEGIN
IF NOT EXISTS (SELECT 1 FROM MTL_ITEM_INFO WHERE ITEM_NO = @itemno)
BEGIN
INSERT INTO MTL_ITEM_INFO (ITEM_NO, DESCRIPTION, CREATE_DATE)
VALUES (@itemno, @desc, @createdate)
END
ELSE
BEGIN
RAISERROR('ITEM_NO already exists.', 16, 1); -- 抛出错误信息
RETURN
END
select @len=COUNT(1)
from MTL_ITEM_INFO
END
GO
--调用存储过程
DECLARE @result INT --DECLARE 语句用于声明变量 声明的变量可以用于存储临时数据,并在 SQL 查询中多次引用
EXEC insert_iteminfo
@itemno='1000001',
@desc='描述',
@createdate='2025-01-01',
@len = @result OUTPUT
SELECT @result AS TotalSum
9.索引
索引是在数据库表上创建的数据结构,提高查询效率
聚集索引:数据表的实际数据按照索引顺序排列一个表只能有一个聚集索引,因为数据行的存储顺序只能有一种通常在主键列上创建
非聚集索引:创建一个单独的索引结构,指向表中的数据行可以有多个非聚集索引
10.触发器(Trigger)
触发器是一种特殊类型的存储过程,它会在特定的数据库事件发生时自动执行。这些事件可以是数据修改操作(如 INSERT、UPDATE、DELETE)或者是数据库事件(如登录、注销)
使用触发器在数据插入前验证数据的完整性,还可以自动日志记录
--AFTER 或 INSTEAD OF 指定触发器是在事件之后执行还是代替事件执行。
--event_type 是触发器响应的事件类型,如 INSERT, UPDATE, DELETE
--在用户插入新记录后自动更新另一个表
CREATE TRIGGER trgAfterInsert
ON MTL_ITEM_INFO
AFTER INSERT
AS
BEGIN
INSERT INTO MTL_ITEM_LOG (ITEM_NO, CUSER, ACTION, CTIME)
VALUES ...
END
11.事务
事务是一组逻辑操作单元,这些操作要么全部成功,要么全部失败
11.1用法
BEGIN TRANSACTION 启动一个事务。之后的所有操作都将包含在事务中,直到执行 COMMIT 或 ROLLBACK。
COMMIT TRANSACTION 提交事务,确保事务中的所有操作永久生效。如果提交成功,事务中的更改将被保存到数据库。
ROLLBACK TRANSACTION 回滚事务,将事务中的所有更改撤销,数据库恢复到事务开始前的状态
BEGIN TRANSACTION;
BEGIN TRY
--sql语句 增删改...
-- 提交事务
COMMIT TRANSACTION;
PRINT 'Transaction committed successfully.';
END TRY
BEGIN CATCH
-- 回滚事务
ROLLBACK TRANSACTION;
PRINT 'Transaction rolled back due to an error.';
END CATCH
11.2 事务的特性 四大特性----ACID
①原子性:保证任务中的所有操作都执行完毕;否则,事务会在出现错误时终止,并回滚之前所有操作到原始状态。
②一致性:事务必须使数据库从一个一致性状态变换到另一个一致性状态。
③持久性:保证任务中的多有操作都执行完毕;否则,事务会在出现错误时终止,并回滚之前所有操作到原始状态。
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
④隔离性:保证不同的事务相互独立、透明地执行
11.3 事务并发数据访问
11.3.1 事务并发(不隔离)导致的一致性问题
(当多个线程都开启事务操作数据库中的数据时,数据库系统要能进行隔离操作,以保证各个线程获取数据的准确性)
①更新丢失:两个事务都同时更新一行数据,但是第二个事务却中途失败退出,导致对数据的两个修改都失效了。这是因为系统没有执行任何的锁操作,因此并发事务并没有被隔离开来。
②脏读(读了未提交的数据):一个事务读取了另一个事务修改了但是未提交的数据,这个数据可能是不正确的,因为另一个事务可能会回滚,所以这个数据也会被回滚
③不可重复读(多次读取数据值不一致):在一个事务中,多次读取同一数据,但是每次读取的结果不一样,这是因为其他事务在前一个事务两次读取过程中修改了数据并提交了
④幻读(多次读取数据条数不一致):在一个事务中,多次读取数据,但是存在两次或多次读取的数据的条数不一致,这是因为另一个事务在前一个事务两次读取过程中插入了数据并提交了
11.3.2事务并发一致性问题解决方法
并发控制
①悲观并发控制:在访问数据之前,会先对数据加锁,使其他用户不能对数据进行会对该事务产生负面影响的访问,直到该事务完成对数据的访问,即使同一时间没有其他事务访问,也会对访问的资源加锁。
优点:实现简单
缺点:并发效率低下,因为并发访问同一资源的事务大部分时间都在等待其他事务释放资源上的锁,而且锁需要系统维护,也是一种资源的开销。
SQL Server事务(通过锁控制)隔离级别中的读取未提交)、读取已提交、可重复读和串行化都是悲观并发控制的实现。直接使用即可,基本不用接触底层的锁机制
②乐观并发控制:不会对数据加锁,而是在事务提交时,才去检查数据是否被其他事务修改过,如果没有被修改,则提交事务,如果被其他用户修改了,将产生一个错误。一般情况下,收到错误信息的用户将回滚事务并重新运行事务
优点:并发效率高
缺点:实现难度大,主要在以下环境中使用:数据争用不大且偶尔回滚事务的成本低于读取数据时锁定数据的成本。
SQL Server事务(使用行版本控制)隔离级别中的读已提交快照和快照是乐观并发控制的实现
--通过判断数据是否变化实现乐观并发控制
-- 乐观并发控制
-- 1. 读取数据
Begin Tran
declare @Name varchar(50);
select @Name = Name from T where Id = 1;
-- 2. 修改数据
UPDATE T SET NAME = '张三' WHERE ID = 1 AND NAME = @Name;--通过条件判断,如果数据已经被修改,则不会更新
-- 3. 提交修改
COMMIT;
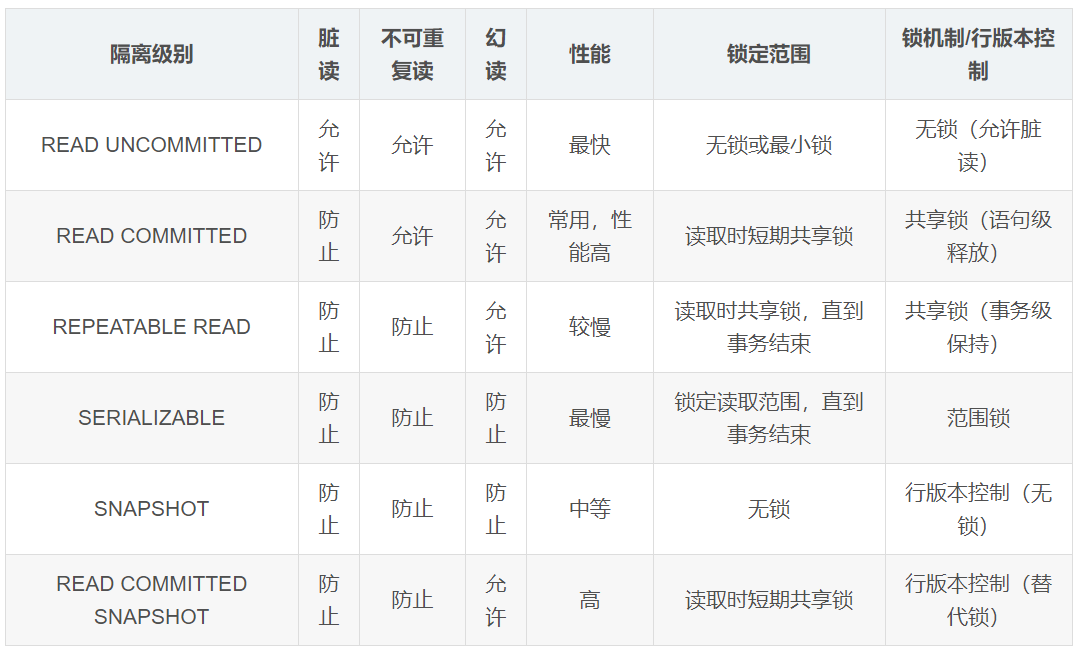
11.4 事务的隔离级别
事务的隔离级别是指在并发环境下,多个事务之间的隔离程度。事务的隔离级别越高,系统并发能力越强,但是并发效率越低
①读未提交(Read Uncommitted)----最低
允许读取未提交的数据,可能会产生脏读(a事务update了但未提交可能过几秒就回滚了,事务b在这期间读取了表数据,读的是update后的脏数据)
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
②读已提交(Read Committed)----SQL Server 默认
只读取已提交的数据,防止脏读,但可能出现不可重复读
(a事务update了但未提交可能过几秒就回滚或者提交了,事务b在这期间读取了表数据,读的是阻塞过后的数据,直到事务1提交事务或者回滚事务,事务2才能查询到数据,)
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
③可重复读(Repeatable Read)
锁定读取的数据,防止脏读和不可重复读,但可能产生幻读
(事务a有两次读取,在执行第一次select查询之后,提交事务之前,事务b要执行update更新同一个数据,就会被阻塞,直到事务a执行完所有操作后提交事务,事务b才能执行update更新数据并提交,所以事务a两次查询结果一致,解决了不可重复读问题。但b更新后的数据跟a的结果不一致,会导致幻读)
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
④串行化(Serializable)----最高
锁定整个范围,防止脏读、不可重复读和幻读,但性能最差
实际上串行化隔离级别就是在可重复读隔离级别的基础上,加了一个键范围锁(where)来实现的。
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
⑤已提交读快照(Read Committed Snapshot)
⑥快照(Snapshot)
11.4.1 注意事项
高隔离级别会加大锁的范围和持锁时间,可能导致死锁。应合理规划事务的逻辑,以减少死锁风险

















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









