









项目场景:
运行环境:windows10笔记本,wireshark抓包工具。
实现描述:
- 需求:在实现项目过程中,需要将接收的数据进行一个解析,也就是将收到的无序字节流对照协议手册转变成已知的数据结构、提取出具体数据内容。在解决该问题时,协议所提供的结构体中的数据类型所对应的字节数,我忘记了具体大小,所以想要明确一下。
- 问题:明确C++语言中的基本数据类型的字节数以及数据范围。
- 解决思路:网上搜了资料,看一些PDF文档。
实现过程:
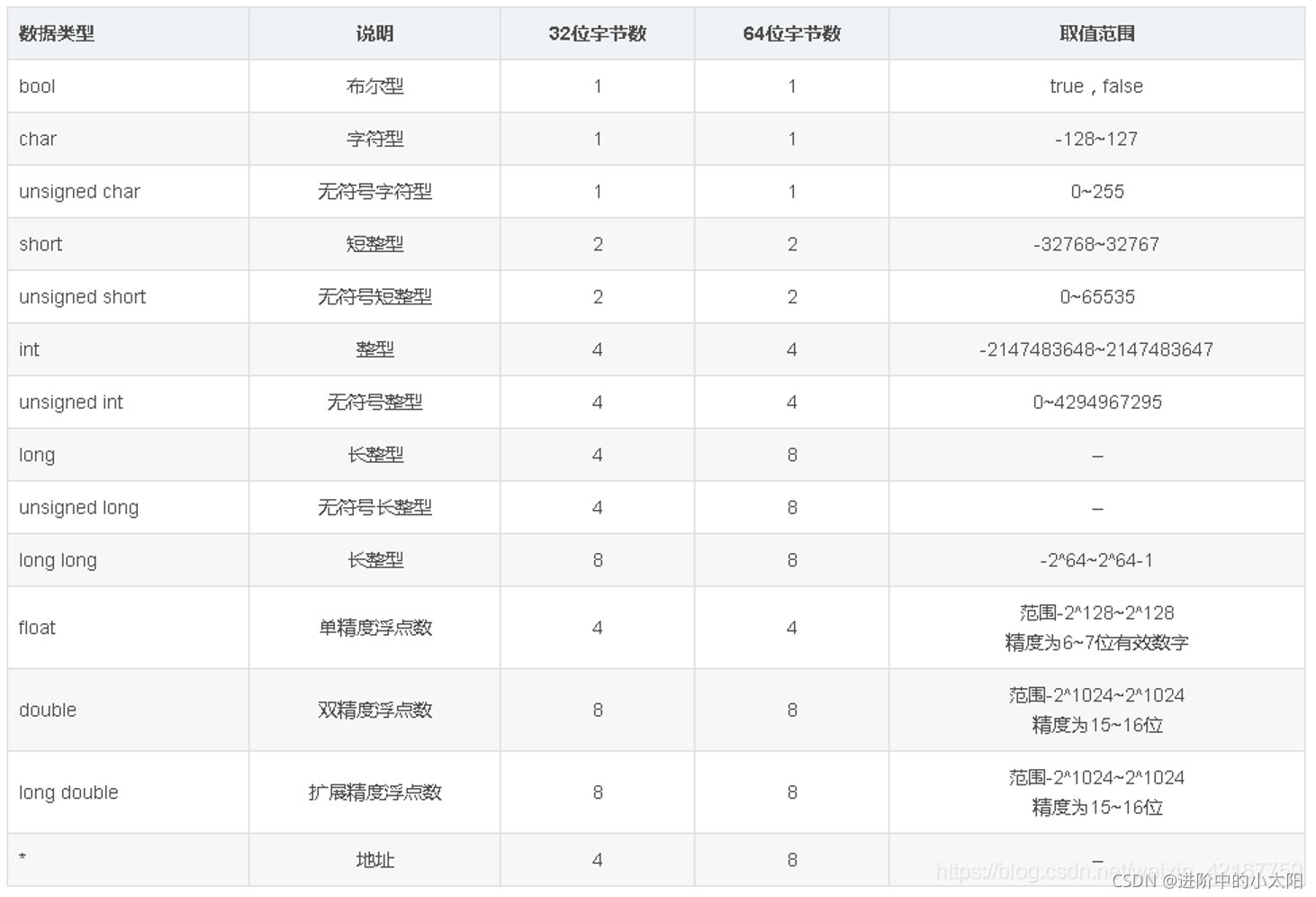
C++ —— 基本数据类型及大小
参考链接:
C++ —— 位与字节
注:下文摘自《C++ Primer Plus》
计算机内存的基本单元是位( bit )。可以将位看作电子开关,可以开,也可以关。关表示值0,开表示值1。8位的内存块可以设置出256种不同的组合,因为每一位都可以有两种设置,所以8位的总组合数为2×2×2×2×2×2×2×2,即256。因此,8位单元可以表示0-255或者-128到127。每增加一位,组合数便加倍。这意味着可以把16位单元设置成65 536个不同的值,把32位单元设置成4294672296个不同的值,把64位单元设置为18446744073709 551616个不同的值。作为比较,unsigned long 存储不了地球上当前的人数和银河系的星星数,而 long long能够。
字节( byte)通常指的是8位的内存单元。从这个意义上说,字节指的就是描述计算机内存量的度量单位,1KB等于1024字节,1MB等于1024KB。然而,C++对字节的定义与此不同。C++字节由至少能够容纳实现的基本字符集的相邻位组成,也就是说,可能取值的数目必须等于或超过字符数目。在美国,基本字符集通常是ASCII和EBCDIC字符集,它们都可以用8位来容纳,所以在使用这两种字符集的系统中,C++字节通常包含8位。然而,国际编程可能需要使用更大的字符集,如Unicode,因此有些实现可能使用16位甚至32位的字节。有些人使用术语八位组( octet)表示8位字节。
总结
unsigned char 在项目中是占用1个字节,比如0x23;short int 占用2个字节,比如0x4E00。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









