







 本文深入解析了Java 1.7和1.8中HashMap的实现原理,包括put和get操作的详细步骤,以及为何HashMap在多线程环境下不安全。同时,介绍了ConcurrentHashMap在1.7和1.8版本的并发控制策略,如分段锁和CAS操作,确保线程安全。文章还探讨了扩容、查询效率优化以及size计算的方法。
本文深入解析了Java 1.7和1.8中HashMap的实现原理,包括put和get操作的详细步骤,以及为何HashMap在多线程环境下不安全。同时,介绍了ConcurrentHashMap在1.7和1.8版本的并发控制策略,如分段锁和CAS操作,确保线程安全。文章还探讨了扩容、查询效率优化以及size计算的方法。
HashMap(java1.7)
简单来说,HashMap是一个Entry对象的数组。数组中的每一个Entry元素,又是一个链表的头节点。底层基于 数组+链表 组成;
put操作
1、判断当前数组是否需要初始化。
2、如果 key 为空,则 put 一个空值进去。
3、根据 key 计算出 hashcode。
4、根据计算出的 hashcode 定位出所在桶。
5、如果桶是一个链表则需要遍历判断里面的 hashcode、key 是否和传入 key 相等,如果相等则进行覆盖,并返回原来的值。
6、如果桶是空的,说明当前位置没有数据存入;新增一个 Entry 对象写入当前位置。
当新增Entry 时需要判断是否需要扩容。
如果需要就进行两倍扩充,并将当前的 key 重新 hash 并定位。
而在新增Entry 中会将当前位置的桶传入到新建的桶中,如果当前桶有值就会在位置形成链表。
get操作
1、首先也是根据 key 计算出 hashcode,然后定位到具体的桶中。
2、判断该位置是否为链表。
3、不是链表就根据 key、key 的 hashcode 是否相等来返回值。
4、为链表则需要遍历直到 key 及 hashcode 相等时候就返回值。
5、啥都没取到就直接返回 null 。
HashMap(java1.8)
当 Hash 冲突严重时,在桶上形成的链表会变的越来越长,这样在查询时的效率就会越来越低;时间复杂度为 O(N),因此 1.8 中重点优化查询效率。
put 操作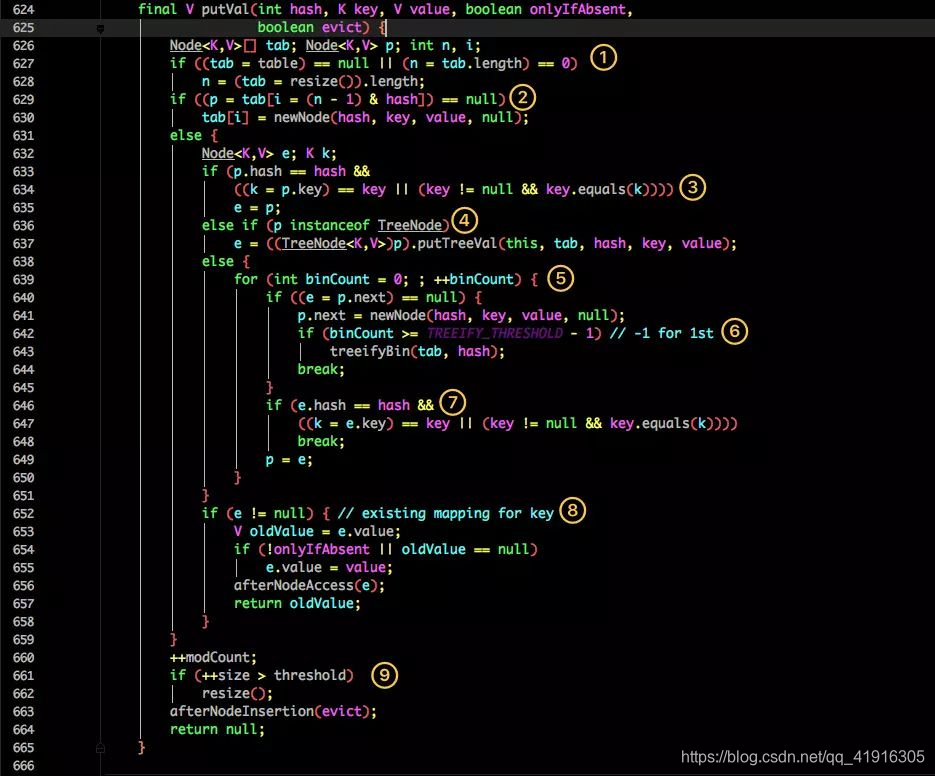
1、判断当前桶是否为空,空的就需要初始化(resize 中会判断是否进行初始化)。
2、根据当前 key 的 hashcode 定位到具体的桶中并判断是否为空,为空表明没有 Hash 冲突就直接在当前位置创建一个新桶即可。
3、如果当前桶有值( Hash 冲突),那么就要比较当前桶中的 key、key 的 hashcode 与写入的 key 是否相等,相等就赋值给 e,在第 8 步的时候会统一进行赋值及返回。
4、如果当前桶为红黑树,那就要按照红黑树的方式写入数据。
5、如果是个链表,就需要将当前的 key、value 封装成一个新节点写入到当前桶的后面(形成链表)。
6、接着判断当前链表的大小是否大于预设的阈值,大于时就要转换为红黑树。
7、如果在遍历过程中找到 key 相同时直接退出遍历。
8、如果 e != null 就相当于存在相同的 key,那就需要将值覆盖。
9、最后判断是否需要进行扩容。
get 操作
1、首先将 key hash 之后取得所定位的桶。
2、如果桶为空则直接返回 null 。
3、否则判断桶的第一个位置(有可能是链表、红黑树)的 key 是否为查询的 key,是就直接返回 value。
4、如果第一个不匹配,则判断它的下一个是红黑树还是链表。
5、红黑树就按照树的查找方式返回值。
6、不然就按照链表的方式遍历匹配返回值。
为什么HashMap线程不安全
1、put的时候导致的多线程数据不一致。
2、扩容的时候会调用 resize() 方法,这里的并发操作容易在一个桶上形成环形链表;这样当获取一个不存在的 key 时,计算出的 index 正好是环形链表的下标就会出现死循环。
在并发使用到HashMap的时候,往往不建议直接用HashMap,因为HashMap在并发写数据的时候容易因为rehash的过程产生环形链表的情况。所以在并发使用Map结构时,一般建议使用ConcurrentHashMap。
ConcurrentHashMap(java1.7)
由 Segment 数组、HashEntry 组成,和 HashMap 一样,仍然是数组加链表。
Segment(分段锁):ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表,同时又是一个ReentrantLock(Segment继承了ReentrantLock)。
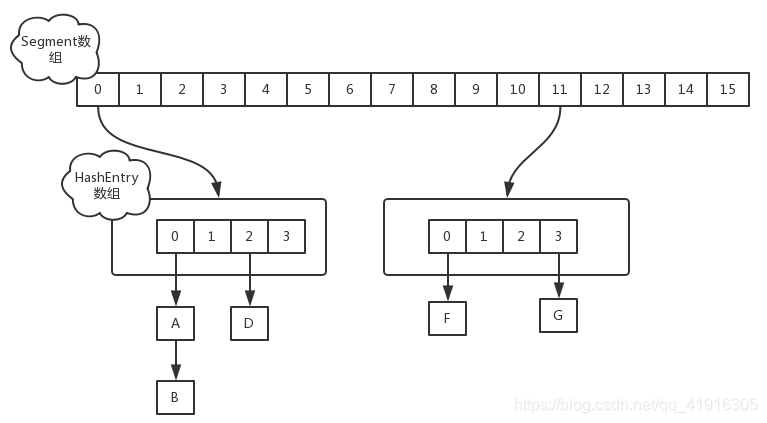
ConcurrentHashMap使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。
put 操作
1、首先是通过 key 定位到 Segment,之后在对应的 Segment 中进行具体的 put。HashEntry 中的 value 是用 volatile 关键词修饰的,但是并不能保证并发的原子性,所以 put 操作时仍然需要加锁处理。
2、尝试获取锁,如果获取失败肯定就有其他线程存在竞争,则利用 scanAndLockForPut() 自旋获取锁。
3、如果重试的次数达到了 MAX_SCAN_RETRIES 则改为阻塞锁获取,保证能获取成功
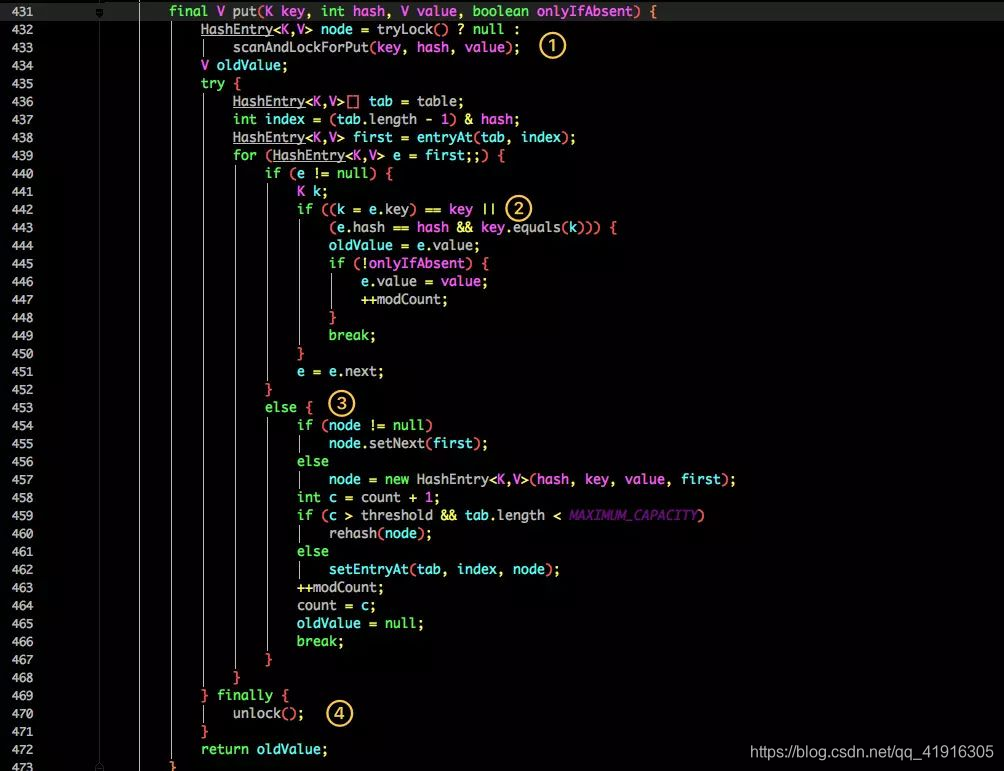
1、将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry。
2、遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。
3、不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容。
4、最后会解除在 1 中所获取当前 Segment 的锁。
get 操作
只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上。
由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。
ConcurrentHashMap 的 get 方法是非常高效,因为整个过程都不需要加锁。
size操作
1、给3次机会,不lock所有的Segment,遍历所有Segment,累加各个Segment的大小得到整个Map的大小,如果某相邻的两次计算获取的所有Segment的更新的次数(每个Segment都有一个modCount变量,这个变量在Segment中的Entry被修改时会加一,通过这个值可以得到每个Segment的更新操作的次数)是一样的,说明计算过程中没有更新操作,则直接返回这个值。
2、如果这三次不加锁的计算过程中Map的更新次数有变化,则之后的计算先对所有的Segment加锁,再遍历所有Segment计算Map大小,最后再解锁所有Segment。
ConcurrentHashMap(java1.8)
ConcurrentHashMap参考了JDK8 HashMap的实现,采用了数组+链表+红黑树的实现方式来设计,内部大量采用CAS操作。并发控制使⽤synchronized 和 CAS 来操作
由于1.7查询遍历链表效率太低,1.8抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性,将 1.7 中存放数据的HashEntry 改为 Node,但作用都相同
put操作
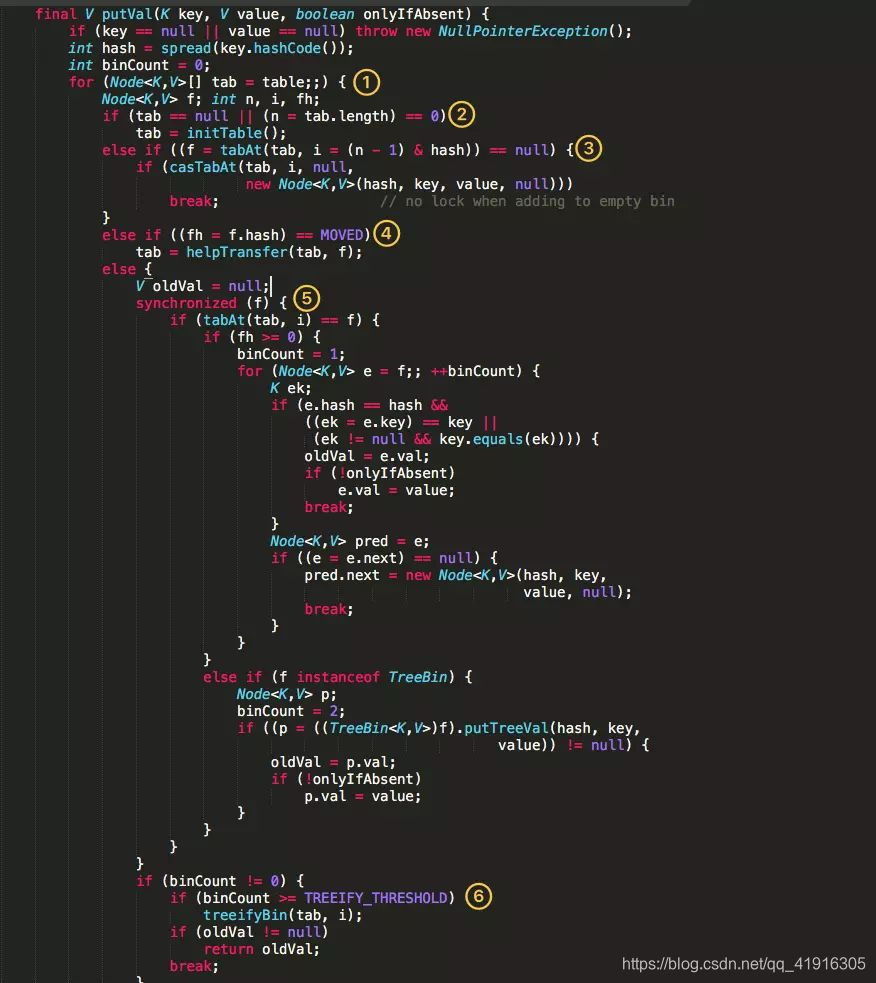
1、根据 key 计算出 hashcode 。
2、判断是否需要进行初始化。
3、f 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
4、如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。
5、如果都不满足,则利用 synchronized 锁写入数据。
6、如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。
get 操作
1、根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
2、如果是红黑树那就按照树的方式获取值。
3、就不满足那就按照链表的方式遍历获取值。
size操作(看的一脸懵逼)
size方法返回的最大值是 Integer 类型的最大值,但是 Map 的 size 可能超过 MAX_VALUE, 所以还有一个方法 mappingCount(),JDK 的建议使用 mappingCount() 而不是 size()
计算 size 的方法调用链:size() -> sumCount()
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n); // 将 n 裁剪到 [0, Integer.MAX_VALUE] 内
}
// 计算 baseCount 字段与所有 counterCells 数组的非空元素的和
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
可以看到,map 中键值对的个数通过求 baseCount 与 counterCells 非空元素的和得到。
ConcurrentHashMap 内部所有改变键值对个数的方法都会调用 addCount 方法更新键值对的计数
addCount 方法记录 size 变化的过程可以分为两类情况,
1、counterCells 数组未初始化
- a. CAS 一次 baseCount
- b. 如果 CAS 失败,则调用 fullAddCount 方法
2、counterCells 数组已初始化
- a. CAS 一次当前线程探针哈希到的数组元素
- b. 如果 CAS 失败,则调用 fullAddCount 方法
// 参数 x 表示键值对个数的变化值,如果为正,表示新增了元素,如果为负,表示删除了元素
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
// 如果 counterCells 为空,则直接尝试通过 CAS 将 x 累加到 baseCount 中
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
// counterCells 非空
// 或 counterCells 为空,但 CAS baseCount 失败都会来到这里
CounterCell a; long v; int m;
boolean uncontended = true; // CAS 数组元素时,有没有发生线程争用的标志
// 如果当前线程探针哈希到的数组元素非空,则尝试将 x 累加到对应数组元素
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
// counterCells 为空,或其长度小于1
// 或当前线程探针哈希到的数组元素为空
// 或当前线程探针哈希到的数组元素非空,但 CAS 数组元素失败
// 都会调用 fullAddCount 方法来完成 x 的写入
fullAddCount(x, uncontended);
return; // 如果调用过 fullAddCount,则当前线程一定不会协助扩容
}
// 走到这说明,CAS 数组元素成功
// 此时如果 check <= 1,也不协助可能会发生的扩容
if (check <= 1)
return;
// 如果 check 大于 1,则计算当前 map 的 size,为判断是否需要扩容做准备
s = sumCount();
}
// size 的变化已经写入完成
// 后面如果 check >= 0,则判断当前的 size 是否会触发扩容
if (check >= 0) {
// 扩容相关的逻辑
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
转载于:https://www.ycblog.top/article?articleId=141&commentPageNum=1

















 705
705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









