



Domain adaptation
[1] Cross-Domain Contrastive Learning for Time Series Clustering
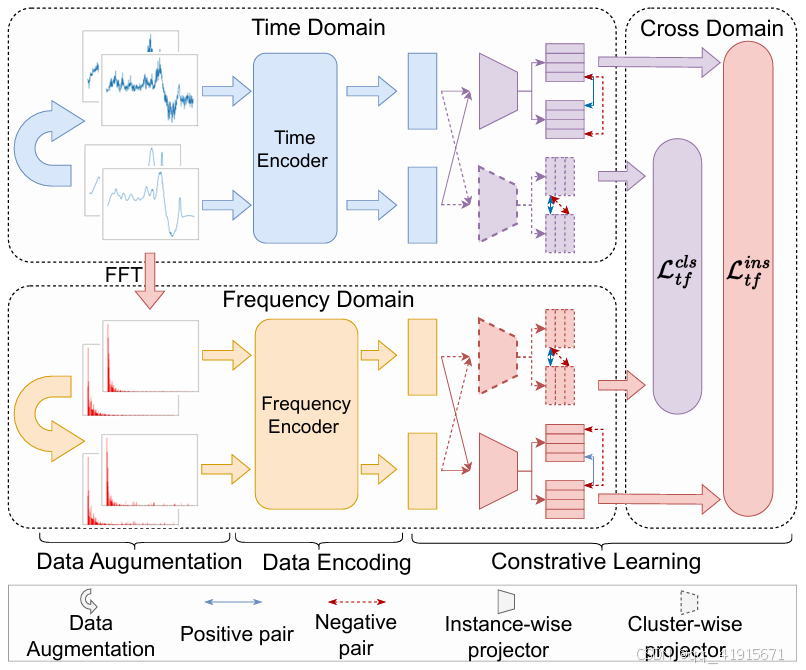
(1) 在簇级和实例级使用对比约束将聚类和特征提取过程融合
(2) 在时域和频域提取特征,并利用对比学习增强域内特征表示
(3) 通过跨域对齐约束来优化特征表示和样本类簇分布
[2] Open-Set Graph Domain Adaptation via Separate Domain Alignment
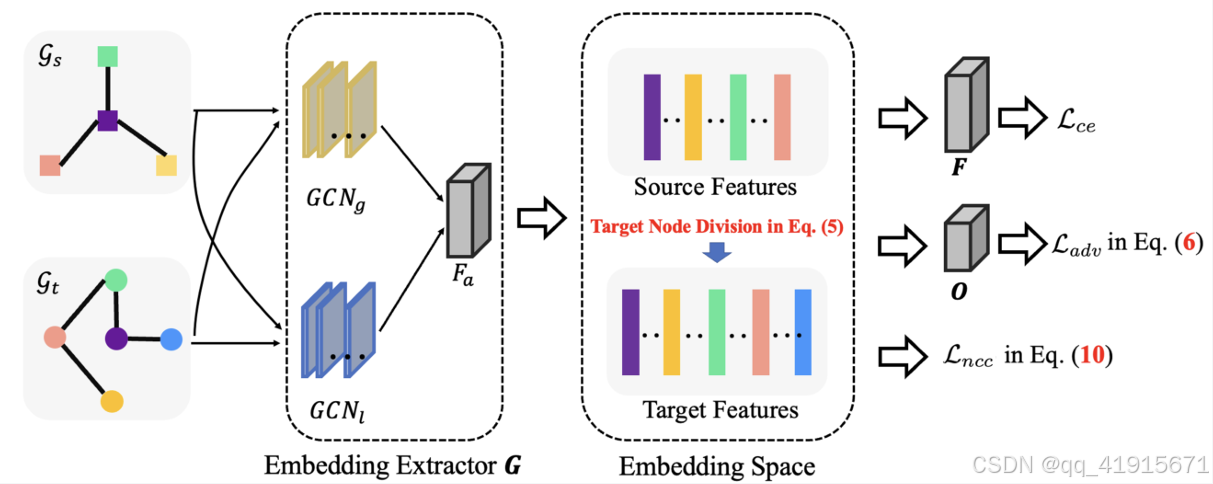
解决问题:open-set graph domain adaptation that allows target graphs to contain unknown class nodes
two novel contributions for graph domain adaptation:
- target domain separation, and
- neighbor center clustering.
The first part helps to dynamically split target nodes into certain and uncertain groups through entropy value, while the second part aims to refine the coarsely divided unknown group by pushing these nodes close to their neighbor centers.
[3] Pushing the Limit of Fine-Tuning for Few-Shot Learning: Where Feature Reusing Meets Cross-Scale Attention
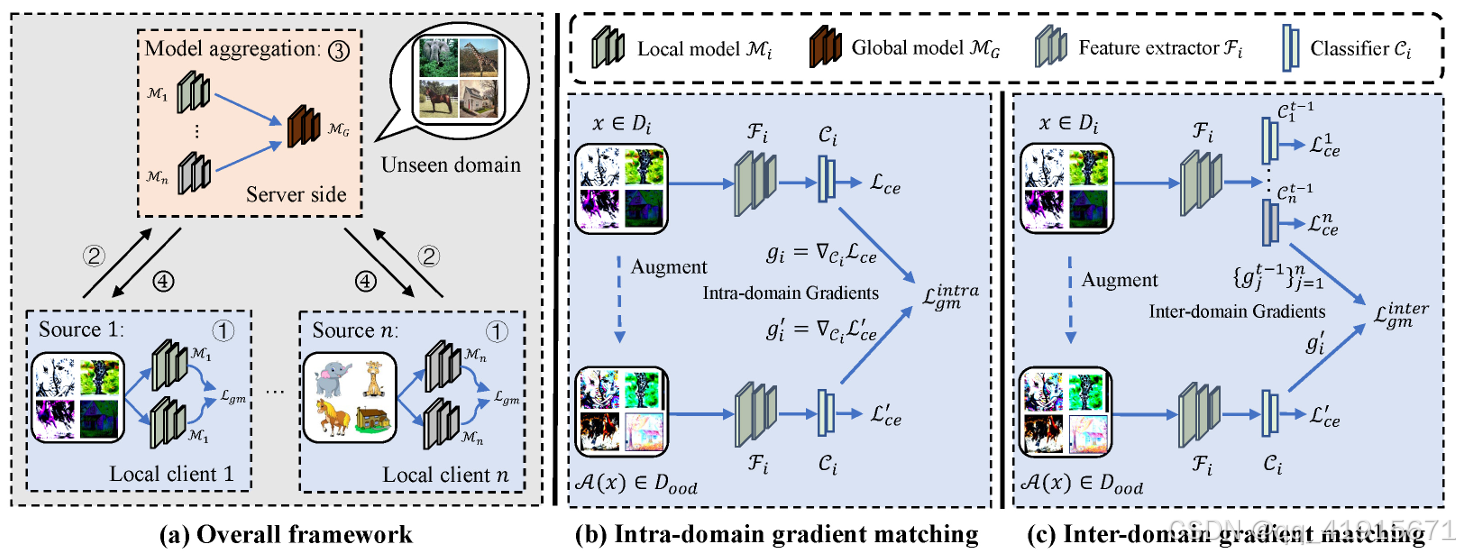
问题背景:federated domain generalization with data privacy protection
(1)To avoid the domain-specific information learned by local models, we propose intra-domain gradient matching, which minimizes the gradient discrepancy between original images and augmented images for learning the intrinsic semantic information.
(2) To reduce the domain shift across decentralized source domains, we propose inter-domain gradient matching, which minimizes the gradient discrepancy between the current model and the models from other domains.
(3) By combining intra-domain gradient matching and inter domain gradient matching, the domain shift can be reduced within isolated source domains and across decentralized source domains to generalize well on unseen target domain.
Feature selection/fusion
[1] Pushing the Limit of Fine-Tuning for Few-Shot Learning: Where Feature Reusing Meets Cross-Scale Attention
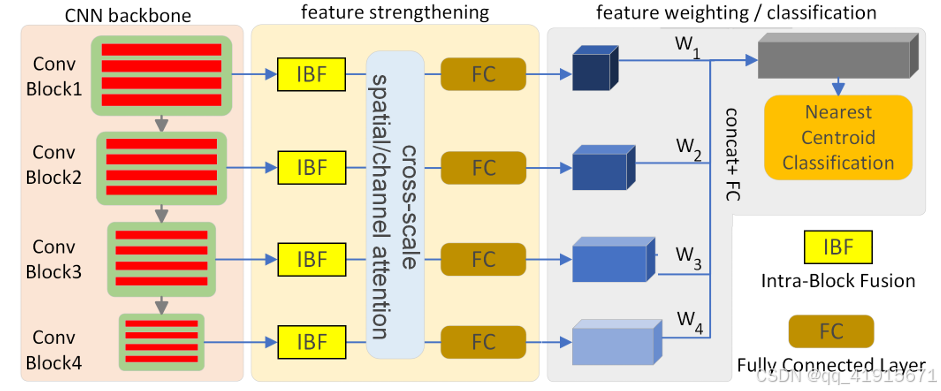
- a hybrid design named Intra-Block Fusion (IBF) to strengthen the extracted features within each convolution block;
- a novel Cross-Scale Attention (CSA) module to mitigate the scaling inconsistencies arising from the limited training samples, especially
for cross-domain tasks.
[2] Pushing the Limit of Fine-Tuning for Few-Shot Learning: Where Feature Reusing Meets Cross-Scale Attention
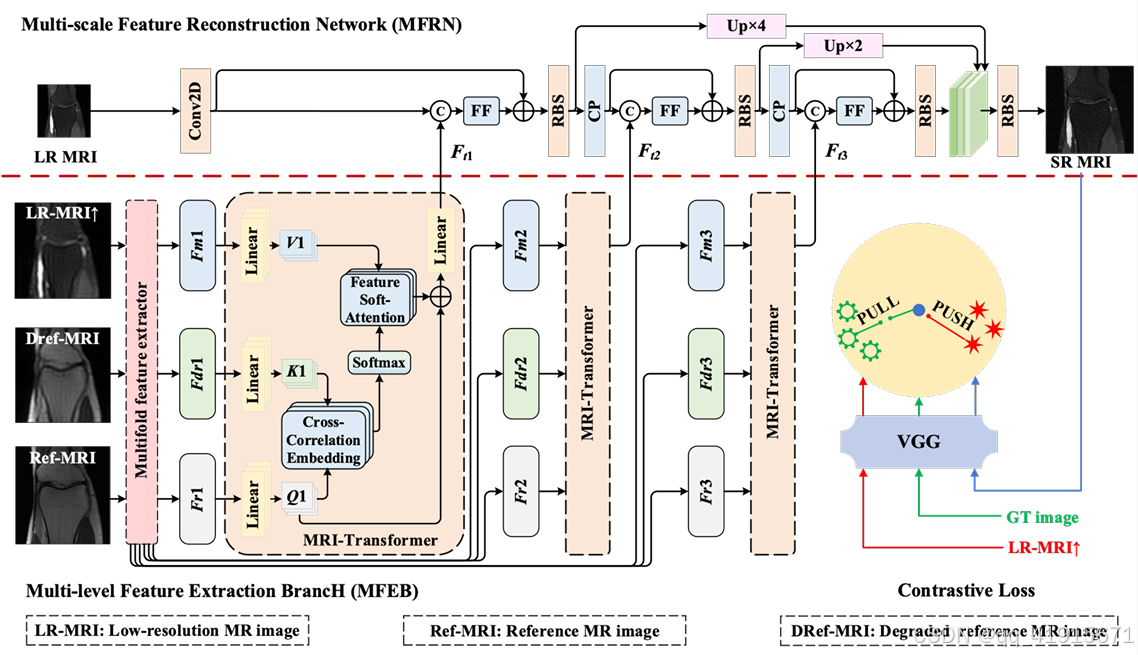
(1) The multifold feature extractors are constructed to extract different levels of shallow features from the input MR image
(2) MRI-transformer modules take features of different levels as inputs to extract transfer features, which are transferred
as supplementary features to MFRN.
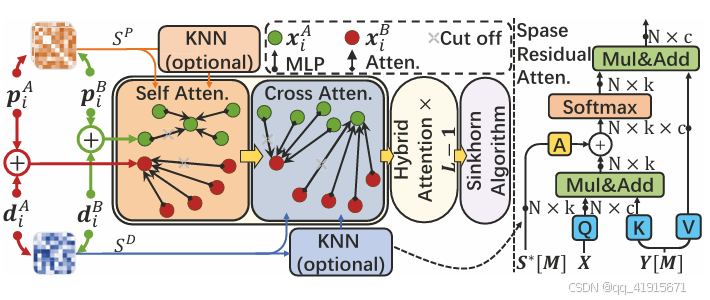
[3] ResMatch: Residual Attention Learning for Feature Matching
(1) We propose residual attention learning for feature matching, termed ResMatch. Simple bypassing injection of relative positions and the similarity of descriptors facilitates feature matching learning.
(2) sResMatch with KNN-based linear attention is proposed
Contrastive Learning
[1] Pushing the Limit of Fine-Tuning for Few-Shot Learning: Where Feature Reusing Meets Cross-Scale Attention
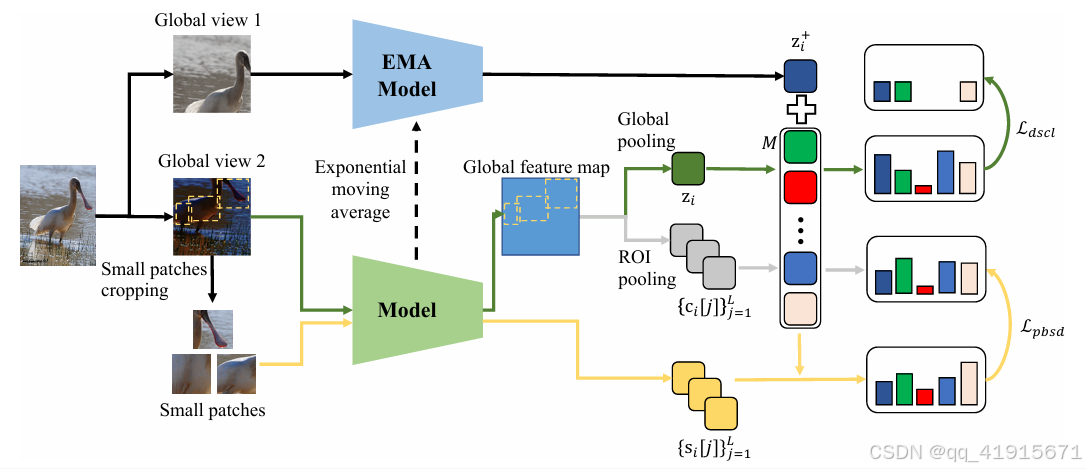
问题背景: To tackle the challenge of long-tailed recognition, this paper analyzed two issues in supervised contrastive learning and address them with DSCL and PBSD
(1) The DSCL decouples two types of positives in SCL, and optimizes their relations toward different objectives to alleviate the influence of the imbalanced dataset.
(2). The PBSD leverages head classes to facilitate the representation learning in tail classes by exploring patch-level similarity relationships.
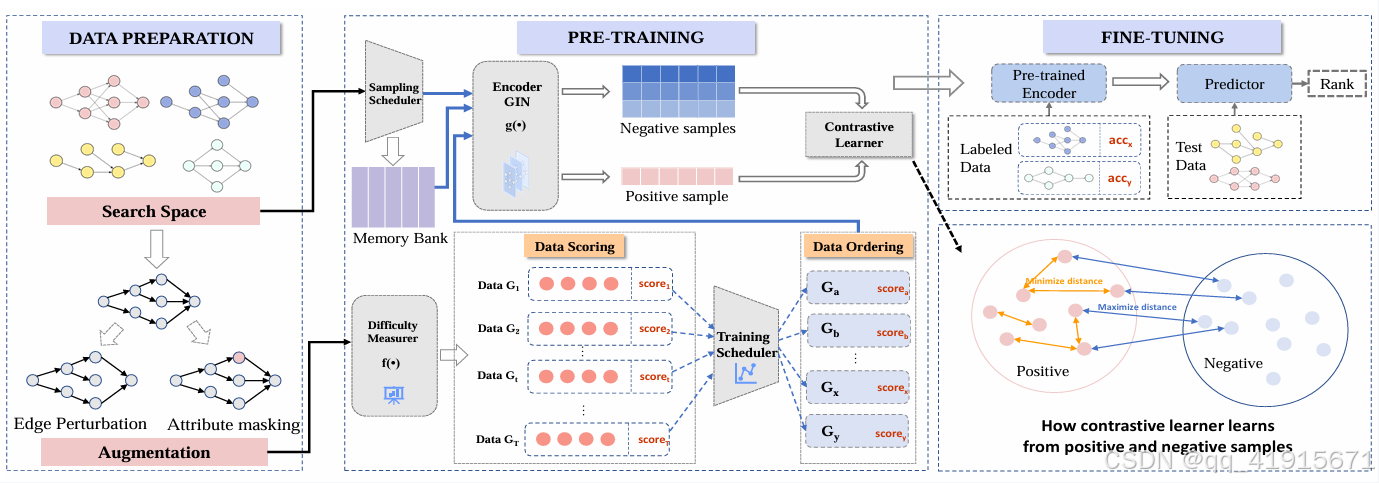
[2]DCLP: Neural Architecture Predictor with Curriculum Contrastive Learning
(1)utilize contrastive learning in neural predictors to leverage unlabeled data. This approach reduces the requirement for labeled training data of the predictor and improves its generalization ability.
(2) propose a novel curriculum method to guide the contrastive task, which makes the predictor converge faster and perform better in NAS.
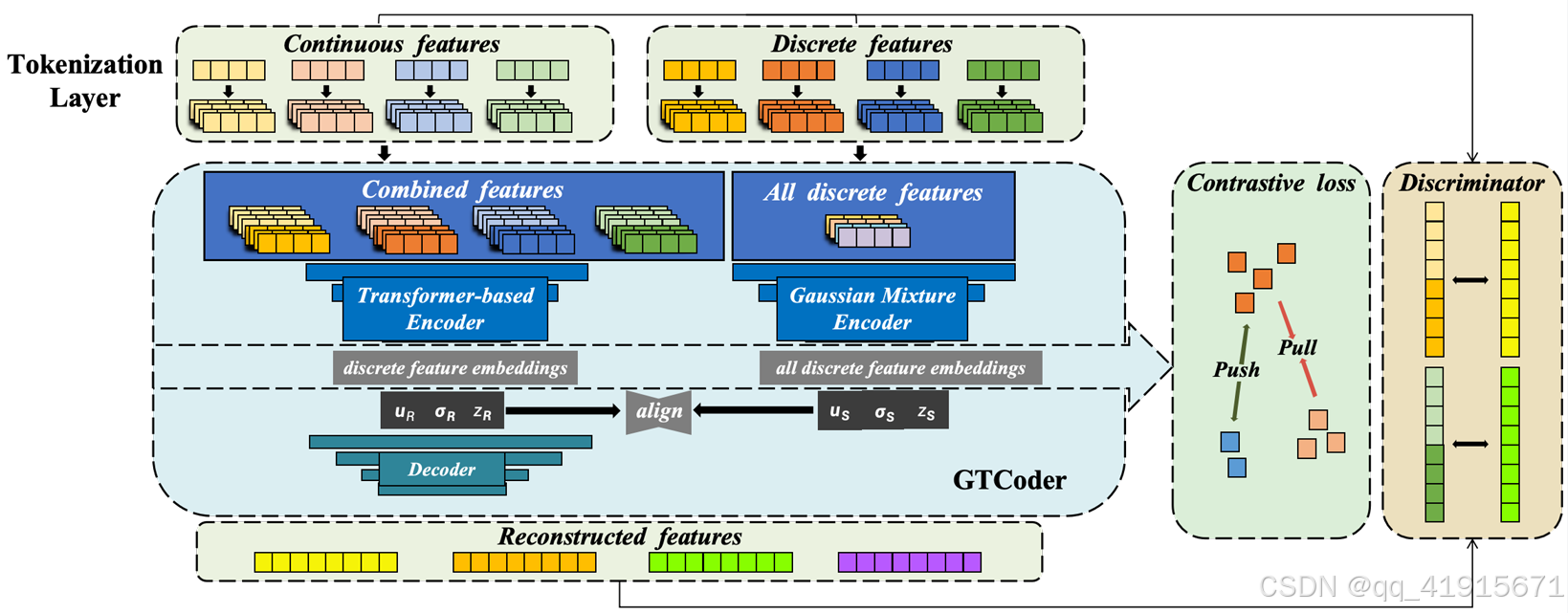
[3] A learnable discrete-prior fusion autoencoder with constrative learning for tabular data analysis
(1)We propose to exploit the transformer attention mechanism for tabular feature semantic fusion. It fuses unimodal and multimodal features to generate latent representations in the encoder.
(2)We introduce a contrastive learning strategy to encourage the similar discrete feature distributions closer while pushing the dissimilar further away, which has a dynamic constraint on representativeness for latent embeddings.
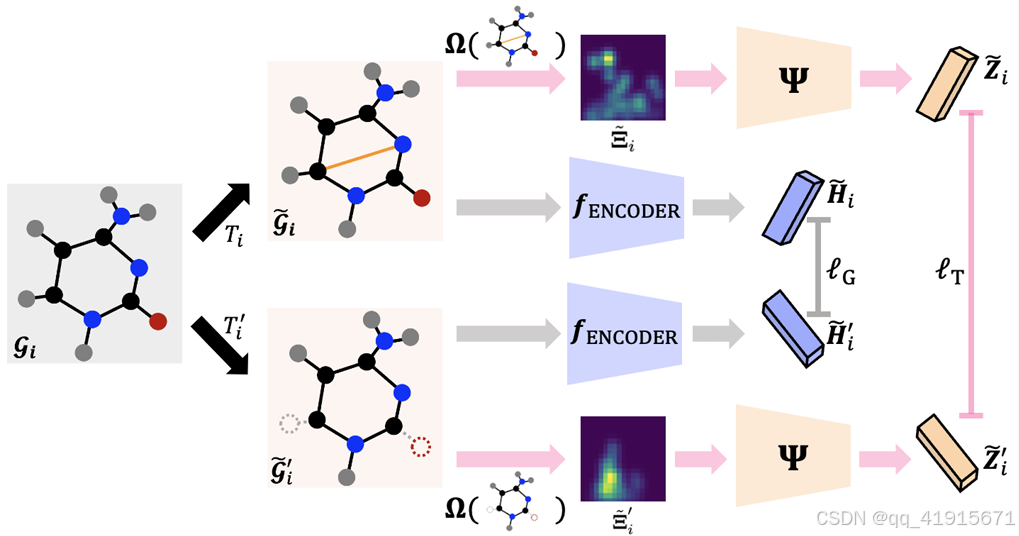
[4] TopoGCL: Topological Graph Contrastive Learning
(1) we propose a new contrastive mode which targets topological representations of the two augmented views from the same graph, yielded by extracting latent shape properties of the graph at multiple resolutions.
(2) we introduce a new extended persistence summary, namely, extended persistence landscapes (EPL) and derive its theoretical stability guarantees.
Incremental/continual learning
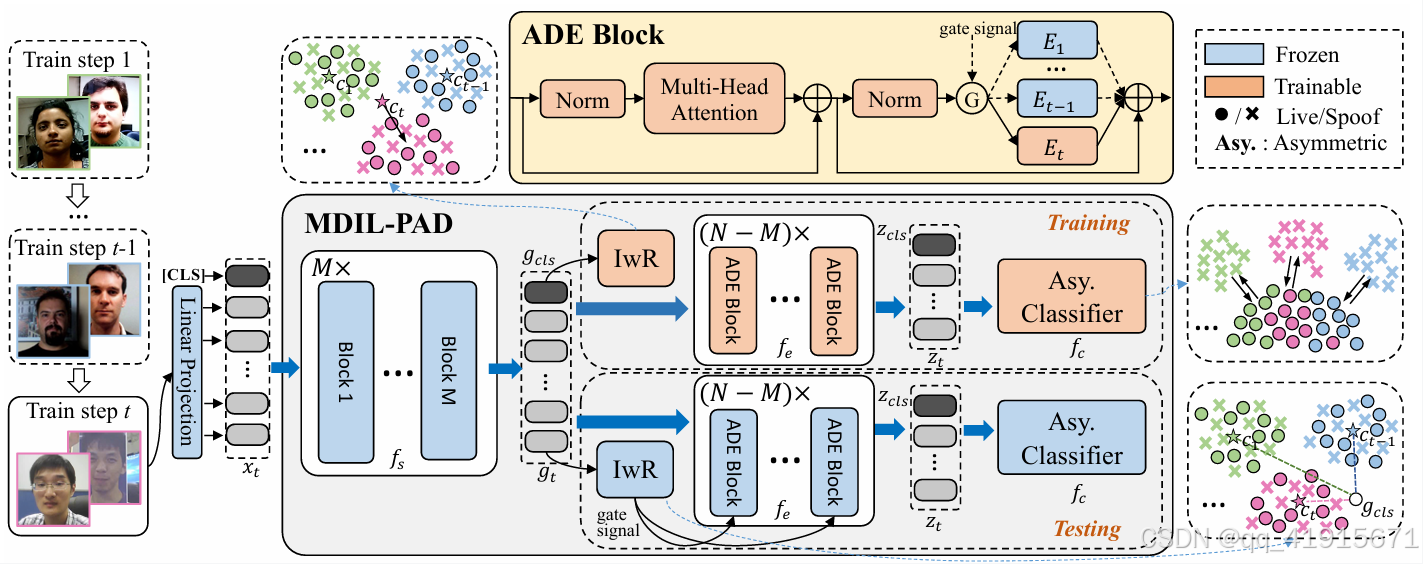
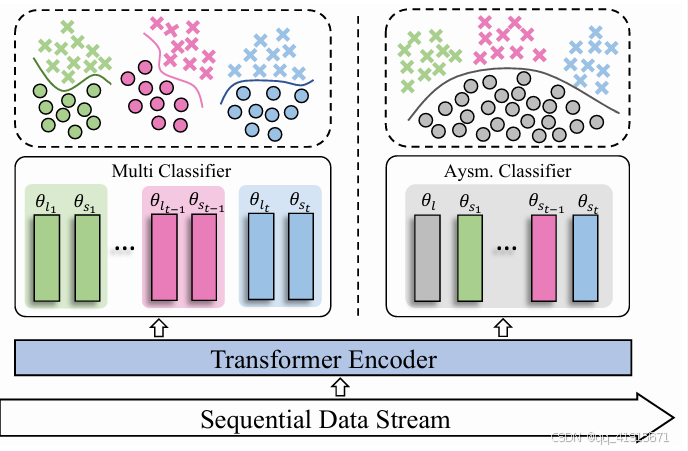
[1] Multi-Domain Incremental Learning for Face Presentation Attack Detection
问题背景:in real-world scenarios, the original training data of the pre-trained model is not available due to data privacy or other reasons.
(1) an instance-wise router module is designed to select the relevant expert via obtaining the associated domain index based on the similarity with the domain centers
(2) the appropriate index guides the instance into the Domain-specific Experts blocks with the corresponding expert branch by gating mechanism.
(3) an asymmetric classifier is designed to solve the problem of PPD of live samples inconsistent in open appending domains.
[2] Multi-Domain Incremental Learning for Face Presentation Attack Detection
(1) formulate a continuous prompt function as a neural bottleneck and encode the collection of prompts on network weights
(2) establish a paired prompt memory system consisting of a stable reference and a flexible working prompt memory.
(3) we progressively fuse the working prompt memory and reference prompt memory during inter-task periods, resulting in continually evolved prompt memory
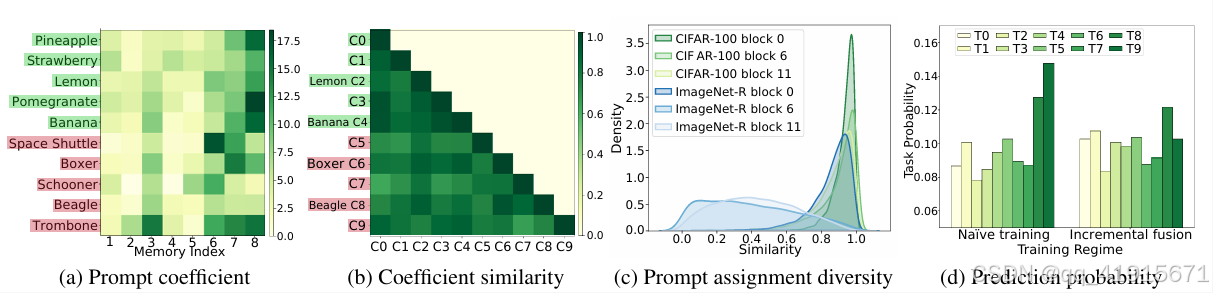
[3] Non-exemplar Online Class-Incremental Continual Learning via Dual-Prototype Self-Augment aand Refinement
- Dual class prototypes: vanilla and high-dimensional prototypes are exploited to utilize the pre-trained information and obtain robust quasi-orthogonal representations rather than example buffers for both privacy preservation and memory reduction.
- Self-augment and refinement: Instead of updating the whole network, we optimize high-dimensional prototypes alternatively with the
extra projection module based on self-augment vanilla prototypes, through a bi-level optimization problem.
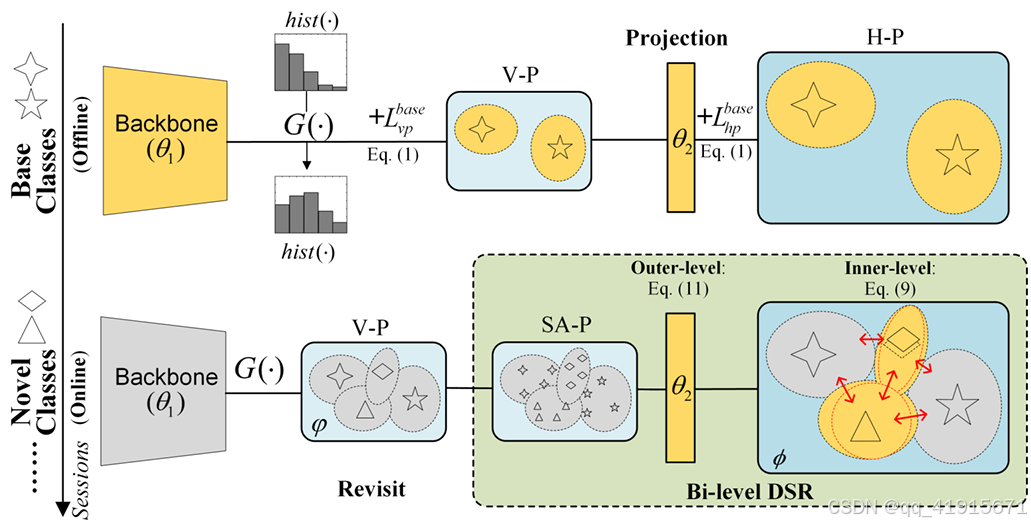
[3] Cross-Class Feature Augmentation for Class Incremental Learning
(1)The proposed approach has an unique perspective to utilize the previous knowledge in class incremental learning since it augments features of arbitrary target classes using examples in other classes via adversarial attacks on a previously learned classifier.
(2)By allowing the Cross-Class Feature Augmentations (CCFA), each class in the old tasks conveniently populates samples in the feature space, which alleviates the collapse of the decision boundaries caused by sample deficiency for the previous tasks
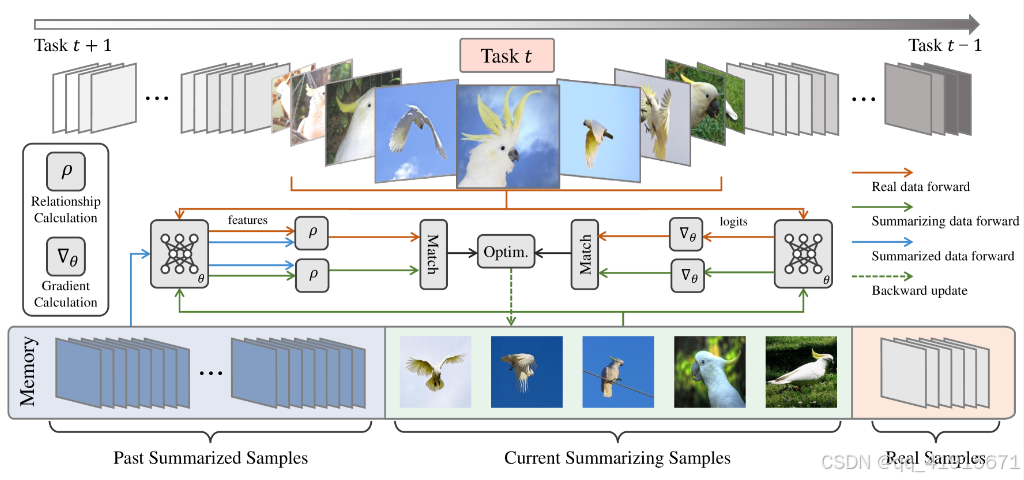
[3] Summarizing Stream Data for Memory-Constrained Online Continual Learning
(1)the training gradients of real and summarized samples on the same network are matched.Thereby training the summarized samples provides similar parameter update results to the original images
(2)we employ the samples of previous tasks in the memory to help fit the overall distribution and provide more proper gradient supervision
(3)the consistency on the relationship to the previous samples between real and summarized samples also serves as a constraint for establishing better distribution in the memory
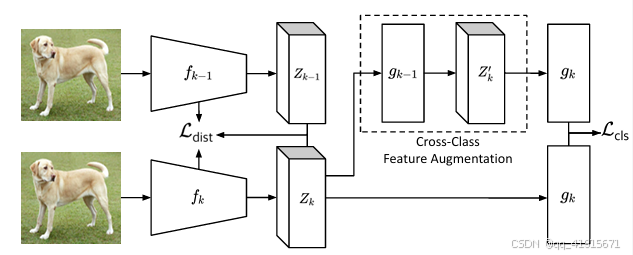
[4] Contrastive Continual Learning with Importance Sampling and Prototype-Instance Relation Distillation
(1) a replay buffer selection module is proposed to save hard negative samples for representation learning with high quality;
(2) Prototype-instance Relation Distillation (PRD) loss is designed to maintain the relationship between prototypes and sample representations using a self-distillation process.

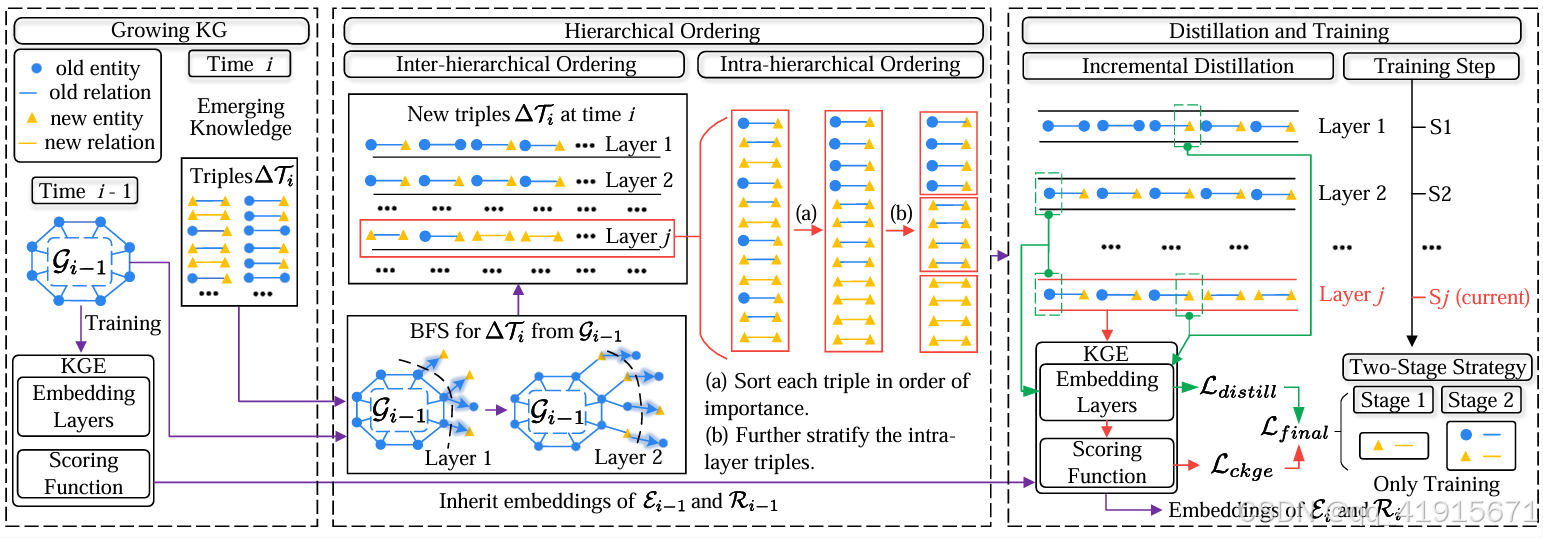
[5] Towards Continual Knowledge Graph Embedding via Incremental Distillation
(1) a hierarchical strategy, ranking new triples for layer-by-layer learning is proposed to optimize the learning order;
(2) a novel incremental distillation mechanism is designed to facilitate the seamless transfer of entity representations from
the previous layer to the next one, promoting old knowledge preservation.
(3) a two-stage training paradigm is developed to avoid the over-corruption of old knowledge influenced by under-trained new knowledge
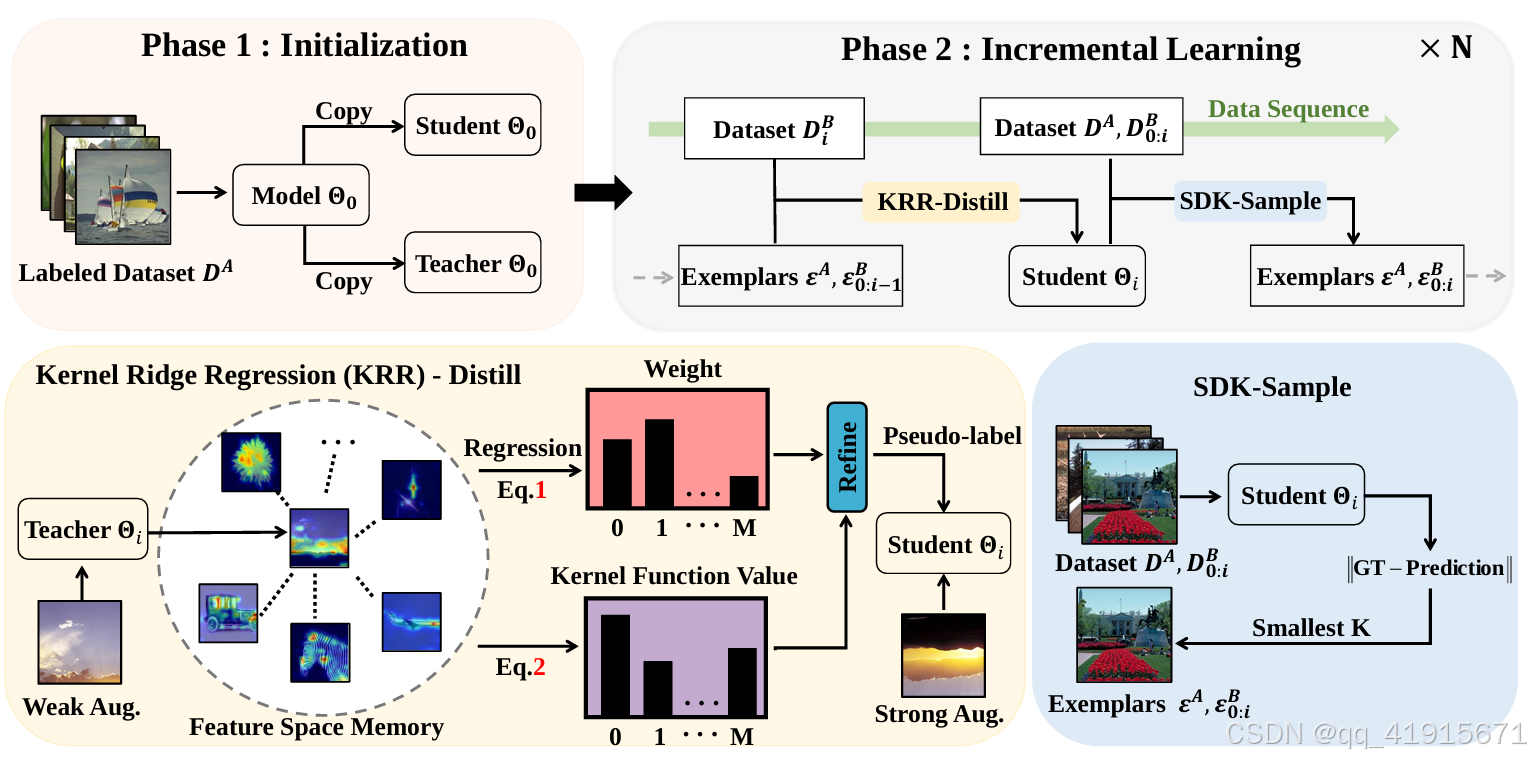
[6] Semi-Supervised Blind Image Quality Assessment through Knowledge Distillation and Incremental Learning
解决问题:模型对有标签数据需求大
(1)Knowledge distillation is utilized to assign pseudo-labels to unlabeled data to preserve analytical capability
(2) Experience replay is employed to alleviate the forgetting issue.
Time series data
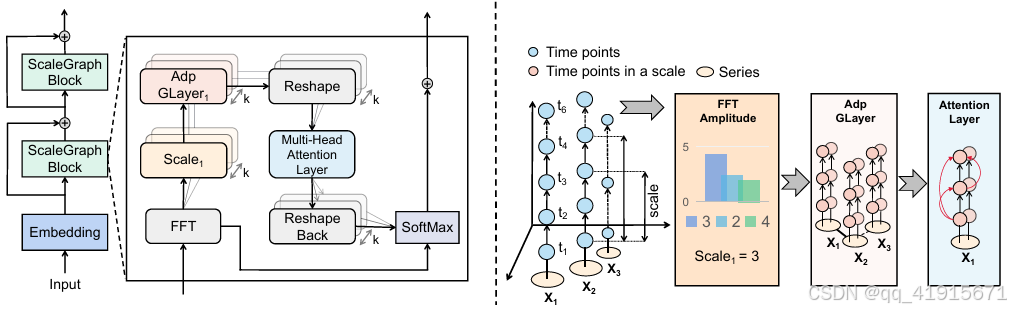
[1] MSGNet: Learning Multi-Scale Inter-Series Correlations for Multivariate Time Series Forecasting
(1) frequency domain analysis and adaptive graph convolution are utilized to learn the varying inter-series correlations across multiple time scales
(2) The model incorporates a self-attention mechanism to capture intra-series dependencies while introducing an adaptive mixhop graph convolution layer to autonomously learn diverse inter-series correlations within each time scale.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









