







目录
1. limit_req_zone:限制单位时间内的请求数(控制访问次数)
2. ngx_http_limit_conn_module 限制并发量(控制连接数)
一. Hystrix
hystrix的相关配置
feign:
hystrix:
enabled: true
client:
config:
default:
connectTimeout: 1000 #两个微服务链接时间
readTimeout: 5000 #链接后的处理时间
hystrix:
command:
#"类名#方法名(参数类型1,参数类型2,参数类型n)" 微服务局部处理
"MessageService#sendSMS(String,String)": #HystrixCommandKey
execution:
isolation:
thread:
timeoutInMilliseconds: 1000 #熔断器熔断降级时间 设置要大于 connectTimeout + readTimeout 之和
#假设:连接500毫秒,处理短信4000毫秒,哪个timeOut会触发服务降级
# 链接 500毫秒 < connectTimeout 1000 正常;处理短信4000 < readTimeout 5000 正常; 但是 (4000 + 500) > 1000 超过了熔断时间。因此超时降级
circuitBreaker:
enabled: true #表示开启熔断器,默认就是true
forceOpen: false #true代表强制熔断器强制处于Open状态,即服务不可用
requestVolumeThreshold: 50
errorThresholdPercentage: 60
sleepWindowInMilliseconds: 10000
# 全局默认的熔断设置
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 6000
circuitBreaker:
#在当20秒的时间内,最近50次调用请求,请求错误率超过60%,则触发熔断10秒,期间快速失败。
requestVolumeThreshold: 50
errorThresholdPercentage: 60
sleepWindowInMilliseconds: 10000
metrics:
rollingStats:
timeInMilliseconds: 20000 #此配置项指定了窗口的大小,单位是 ms,默认值是 10001. 服务降级:
当出现异常情况时,给服务调用者提供一个符合预期的有好的fallback提示(给服务调用者提供一个兜底的响应)。而不是直接报错或者调用者一直在等待服务返回而导致线程堆满从而可能出现宕机
hystrix执行fallback时,是hystrix的单独线程去处理的。
什么情况下会使用降级:
- 连接超时
- 服务代码跑出异常
- 线程池占满,无法提供响应
- ...
1.1 降级的使用方法
hystrix的使用需要根据业务逻辑的要求灵活配置
可以应用在服务提供方设置hystrixCommand(服务提供方异常时的降级处理)
也可以在服务调用方设置hystrixCommand(调用方本身出问题的降级处理)
也可以在feign接口处,通过fallback、fallbackFactory来实现feign接口的形式,来返回预设的方法。
疑问一:调用方的每个方法都需要配置一个降级方法吗?
非也,可以通过一个全局的降级方法,如果接口没有标明特殊处理的降级方法,当需要降级时,统一都走该方法:
在controller上面添加@DefaultProperties(defaultFallback = "defaultFallback") 指明该controller的方法如果被@Hystrix标注了,没有指明fallback的话,就会降级到该方法
疑问二:controller中的方法与降级的方法混合在一块,增加了耦合度?
并没有,
①在feign接口的service从层中。指定当前服务如果不可用后的fallback类即可:
@FeignClient(value = "provider", fallback = UserServiceFallbackImpl.class) // 表示如果当前接口不可用,则直接走fallback实现类 public interface UserService {}此时如果提供服务的服务器宕机,feign接口调用就会返回fallback的实现类②使用fallbackFactory同样实现上述功能:
@FeignClient(value = "provider", fallbackFactory = UserServiceFallbackFactory.class)在UserServiceFallbackFactory中实现create方法,并重写该接口类的所有方法。同样能够实现当服务不可用时,直接返回fallback的实现方法
2. 服务熔断
当某个服务达到了设定的最大错误访问率时,当有新的访问请求进来, 直接启动熔断,并且返回fallback预设值。在一定程度上控制了并发数量。
或者当两个服务部署在同一个服务器,在某个访问量几乎可以忽略的服务上启动熔断(直接在调用方熔断feign接口上,然后将服务器宕机),将系统资源释放出来提供给需要大量资源的服务使用。
当某个服务的请求,在XX秒内的xx次请求失败率为xx时,触发熔断xx秒,xx秒后重新恢复尝试,若再次失败再次熔断
例如:用户兑换商品的请求,在20秒内请求50次的失败率为60%时,则触发熔断该服务10秒,10秒后重新尝试。配置方式可以是@HystrixCommand注解,也可以是配置文件(见上面的配置文件circuitBreaker配置)
详细配置说明请参考博客:https://www.imooc.com/article/76515
注解配置:
/**
* 一下熔断的配置是指:
* 在2秒内10次请求如果有50%的错误率,则将该服务熔断1秒(期间无论正确还是错误的请求都会走fallback)
* 熔断时间为1秒,后重新尝试是否成功
* @param userPO
* @return
*/
@HystrixCommand(fallbackMethod = "fallBack", commandProperties = {
@HystrixProperty(name = "circuitBreaker.enabled", value = "true"), //是否开启熔断 默认开启
@HystrixProperty(name = "metrics.rollingStats.timeInMilliseconds", value = "2000"), //统计的时间窗口,即多少秒内的失败率
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10"), //单位时间的请求次数
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50"), // 时间窗口内请求次数的失败率
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds", value = "1000") //当触发熔断后,服务熔断的时间
})
@RequestMapping(value = "/provider/user/add", method = RequestMethod.POST)
public Boolean add(@RequestBody UserPO userPO) {
return userService.add(userPO);
}
3. 服务限流
当一些非常高并发的情况下,讲服务进行限流,在规定时间内只允许指定数量的请求进来。其余的请求排队进来
4. hystrix的适用场景
什么时候适用hystrix,哪些服务需要进行降级,哪些服务需要配置熔断。这些都需要根据自己实际的业务逻辑进行判断后使用的。
** 并不是所有的服务都需要进行降级,像一些核心业务,计费业务,ID生成服务。就尽量不要去进行降级,否则就很有可能导致整个系统不可用。
** 对于一些边缘业务,可能会因为出现异常从而导致调用方线程挂起等待,拖慢系统的服务,可以进行降级或者熔断提醒,例如当某些业务出现排队情况,当线程数达到一定数量后,直接进行降级,返回服务繁忙提示。某个服务出现了BUG,返回系统崩溃友好提示。例如收藏时出现了bug,不让用户感知直接返回fallback的提示,例如进入聊天室时,线程数达到上限,fallback提示人数达到上限等。
** 对于一些必要业务服务,可以通过熔断进行备选调用。例如发送邮件或者短信通知,当某个提供商出现了异常不能正常发送时,可以通过降级采用备份服务商进行发送短信等。
** 对于一些核心业务,在想要保证服务可用并且又不想让用户感知的情况下,例如积分扣减、资料更新等不是要求时效性的服务来说,当出现异常时,可以进行降级处理,将需要处理的业务暂时存放在缓存或者队列中。保证当前业务逻辑正常走通,然后后期再从缓存或者队列中及时将异常的请求重新进行处理。当然只能是一些不要求时效性的服务,像支付、减库存这些就不适合用降级了。当出现支付的异常时,应该直接反馈给用户操作失败。
5. 总结
在实际的应用工作中,如果某些服务失败会导致调用者线程阻塞,或者调用逻辑比较复杂,某个服务调用失败会导致级联异常的情况下,就需要使用hystrix来讲该服务进行降级或者熔断。
通常情况下,可以对某个方法或者所有的方法,都设置一个fallback方法,一般都会在调用方添加fallback。通过hystrixCommand注解设置fallbackMethod或者在feign接口编写实现类,通过fallback参数指明当服务降级时,调用的实现类。来实现服务降级。
如果有些服务需要进行熔断,例如可能会遇到一些恶意错误请求攻击,导致系统资源、线程池被恶意占满,从而影响了其他服务的使用。可以将该服务直接进行熔断。
熔断一般会搭配降级一起使用,熔断的机制就是在设定的时间内的请求多少次有多少次的失败率(失败的请求还是走fallback方法),则将该服务进行熔断。熔断后一定时间内服务不可用,全部返回fallback。
配置的话可以通过注解指定参数值,或者在配置文件中配置,配置hystrixCommand的请求失败率是多少,窗口期是几秒,请求次数是多少,超时时间等,配置的参数可以在源码HystrixCommandProperties里找到。我没有特意记。
二. 网关gateway
1. gateway简介
疑问:为什么要使用gateway?
gateway是spring公司研发的项目,与springcloud整合的稳定性要强于zuul,并且网络通讯的底层是使用的netty的异步非阻塞式IO,并发性能更好。
疑问:zuul与gateway?
zuul是一开始netfilx开发的用于网关的组件。并且被springcloud整合使用。但是由于基于servlet研发的1.0的缺陷和zuul团队的自身问题,研发一直被停滞。后出现了zuul2.0基于netty实现的高性能网关。但迟迟没有稳定版本
所以springcloud自己研发了getaway替代了zuul,实现了网关组件。功能比zuul1.0更加强大。比层采用了netty的通讯。十分适用于高并发场景。
现在网关的选型基本都会使用gateway实现
一般的架构思想为:客户端请求---》nginx负载均衡---》gateway网关路由过滤/鉴权/等---》微服务
疑问:网关能做什么?
- 实现日志统一记录
- 整合微服务网关组成各个不同功能的系统(运营端一套网关、前台页面一套网关、会员一套网关)
- 实现用户的操作跟踪
- 实现限流
- 用户的鉴权认证
- ......
疑问:nginx与网关的关系?
nginx是用户请求的第一道屏障,将请求的入口(项目部署)放在nginx上,能够支持大量的并发性能(如果将系统部署在Tomcat上,并发量会很差)。可以通过nginx来控制访问系统的频率、单位时间内流向、并发连接数、负载均衡、部分恶意请求拦截、甚至是通过openresty将响应直接通过nginx返回
网关是用户通过nginx代码转发后的第二道屏障,此时才会真正的进入到后台服务器,用来做以上功能
最终网关会根据路由将请求分发路由给不同的微服务进行处理
用户------> nginx(负载均衡到各个gateway集群)------>gateway------>微服务
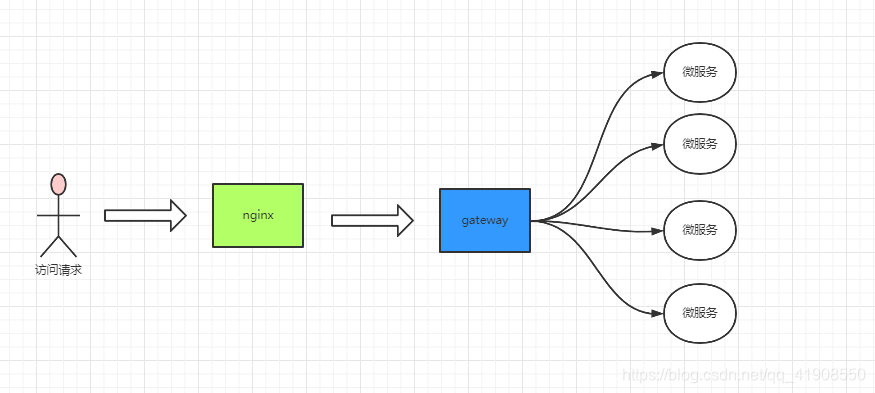
2. gateway核心工作流程
客户端请求进来后,通过路由进行转发,并且实现过滤的功能。最终完成响应
- 路由
客户端请求过来之后,需要通过gateway进行路由判断,从而转发到真实的服务地址
- 断言predicates
客户端请求进来之后,可以通过断言规则判断,当前的请求是否会进行放行,常见的有对时间判断、参数判断、请求头判断等
- 过滤
对于客户端的请求,在经过网关的前、后进行过滤处理。
经过网关前可以进行:参数校验、权限鉴权、流量监控、日志输出、数据类型装换等
经过网关后可以进行:响应内容处理、响应头修改、流量监控等操作。
3. gateway使用demo
3.1 搭建gateway网关工程
①导入依赖:导入gateway依赖和eureka依赖(注册为一个服务)
<!--gateway网关依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
<version>2.2.1.RELEASE</version>
</dependency>
<!--eureka客户端依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
<version>1.4.6.RELEASE</version>②创建yml文件:编写端口,并注册到eureka上去
server:
port: 9500
spring:
application:
name: gateway-9500
eureka:
client:
service-url:
defaultZone: http://eureka.7001.com:7001/eureka/,http://eureka.7002.com:7002/eureka/,http://eureka.7003.com:7003/eureka/③编写启动类
@SpringBootApplication
@EnableEurekaClient
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}3.2 配置路由匹配
作为网关,最核心的功能就是所有的请求通过网关,并有网关进行路由匹配。gateway提供了两种路由匹配的方式:配置文件设置、bean注册设置
gateway路由的核心思想是:通过路由去匹配服务。也就是说,通过访问网关的URL来寻找请求哪个服务
①配置文件路由匹配
以下简单配置了:当通过网关访问/provider/**时,都会被转发到http://localhost:8009中去
server:
port: 9500
spring:
application:
name: gateway-9500
cloud:
gateway:
routes:
- id: provider01 #任意的ID,不要重复
uri: http://localhost:8009 #需要转发的地址
predicates: #设置断言判断
- Path=/provider/** #-Path设置了路由规则,也就是访问网关的所有/provider/**请求都会被转发到上面的uri中
- id: provider02 #可以配置多个路由规则
uri: http://localhost:8002
predicates:
- Path=/provider/**
eureka:
client:
service-url:
defaultZone: http://eureka.7001.com:7001/eureka/,http://eureka.7002.com:7002/eureka/,http://eureka.7003.com:7003/eureka/
但是将URI写死是不优雅的,gateway被注册到了注册中心,所以可以通过服务名的方式,替换显式的URI
其中URI的格式为:lb://服务名:表示如果该服务存在集群的话,会进行负载均衡访问。
此时访问网关的/provider/**时,会被转发到provider服务中,并进行负载均衡。同理,访问网关的/consumer/**时,会被转发到consumer80服务中去。实现了网关的路由转发功能
server:
port: 9500
spring:
application:
name: gateway-9500
cloud:
gateway:
discovery:
locator:
enabled: true #开启通过非服务名的访问
routes:
- id: provider01 #任意的ID,不要重复
uri: lb://provider #需要转发的地址
predicates: #设置断言判断
- Path=/provider/** #-Path设置了路由规则,也就是访问网关的所有/provider/**请求都会被转发到上面的uri中
- id: consumer01 #可以配置多个路由规则
uri: lb://consumer80
predicates:
- Path=/consumer/**
eureka:
client:
service-url:
defaultZone: http://eureka.7001.com:7001/eureka/,http://eureka.7002.com:7002/eureka/,http://eureka.7003.com:7003/eureka/
②通过注册bean的方式进行路由匹配
创建下面这个bean,就能达到与上述配置文件同等效果的配置
/**
* @author hengtao.wu
* @Date 2020/11/4 16:26
**/
@Configuration
public class GatewayConfig {
@Bean
public RouteLocator routeLocatorConsumer(RouteLocatorBuilder routeLocatorBuilder) {
RouteLocatorBuilder.Builder routes = routeLocatorBuilder.routes();
routes.route("consumer01", r -> r.path("/consumer/**").uri("lb://consumer80")).build();
return routes.build();
}
@Bean
public RouteLocator routeLocatorProvider(RouteLocatorBuilder routeLocatorBuilder) {
RouteLocatorBuilder.Builder routes = routeLocatorBuilder.routes();
routes.route("provider01", r -> r.path("/provider/**").uri("lb://provider")).build();
return routes.build();
}
}③通过路由区分服务
gateway路由的核心思想是:通过路由去匹配服务
所以,一般在正式的使用中,会通过不同的前缀URL来区分不同的微服务。例如,所有的请求都打在网关上,但是访问用户服务前缀是:localhost:9500/userapi、访问订单服务前缀就是:localhost:9500/orderapi。但是实际真实的服务中并没有这个前缀
要实现这个配置,就需要在网关层面加一层过滤:
filter(下文会具体讲如何使用)提供了过滤掉第一层路由,filter还可以提供重写路由的功能。
此时:例如:
consumer80这个服务提供的api地址是:localhost:80/consumer/hello
通过网关访问时的地址为:localhost:9500/con/consumer/hello (该请求打到网关后,通过/con匹配到了consumer80这个服务,并且把/con过滤后访问consumer80)
server:
port: 9500
spring:
application:
name: gateway-9500
cloud:
gateway:
discovery:
locator:
enabled: true #开启通过非服务名的访问
routes:
- id: provider01 #任意的ID,不要重复
uri: lb://provider #需要转发的地址
predicates: #设置断言判断
- Path=/pro/** #-Path设置了路由规则,也就是访问网关的所有/provider/**请求都会被转发到上面的uri中
filters:
- StripPrefix=1 #将打在网关上的url的第一个路由过滤掉后,再访问真实的服务器
- id: consumer01 #可以配置多个路由规则
uri: lb://consumer80
predicates:
- Path=/con/**
filters:
- StripPrefix=1
eureka:
client:
service-url:
defaultZone: http://eureka.7001.com:7001/eureka/,http://eureka.7002.com:7002/eureka/,http://eureka.7003.com:7003/eureka/
3.3 断言配置predicates
gateway中的predicates提供了多重断言判断:官网提供的API文档如下:
通过断言配置,可以将某些不符合要求的请求过滤出去

简单实例解释如下:
predicates: #设置断言判断
- Path=/pro/** #-Path设置了路由规则,也就是访问网关的所有/provider/**请求都会被转发到上面的uri中
- After=2020-11-04T16:47:52.542+08:00[Asia/Shanghai] #改路由转发在这个时候之后才生效
- Before=2020-11-04T16:47:52.542+08:00[Asia/Shanghai] #改路由转发在这个时候之前才有效
- Between=2020-11-04T16:47:52.542+08:00[Asia/Shanghai],2020-11-04T18:47:52.542+08:00[Asia/Shanghai] #在这个时间之间才生效
- Cookie=username, zzkk #表示请求中需要有cookie,并且key是username,value是满足zzkk正则的值
- RemoteAddr=192.168.1.1/24 #IP访问,表示只有该网段的IP才能进行访问3.4 filter过滤器
像zuul一样,gateway也通过了过滤请求的功能。能够使用该功能实现日志监测、用户鉴权、流量监控等辅助功能
- gateway提供了jar包提供的过滤器,参考官网:https://docs.spring.io/spring-cloud-gateway/docs/2.2.5.RELEASE/reference/html/#gatewayfilter-factories
- 也提供了可以自定义过滤器的功能,(实现GlobalFilter, Ordered)
自定义filter实现demo,能够实现:
- 用户鉴权
- 请求前后做辅助功能
- 白名单放行
- 黑名单拦截
- 访问量监控
- ....
/**
* @author hengtao.wu
* @Date 2020/11/4 16:54
**/
@Component
public class GatewayFilterConfig implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
System.out.println("拦截器拦截到了请求,url:" + exchange.getRequest().getPath());
RequestPath path = exchange.getRequest().getPath();
//白名单直接放行
if("/pro/provider/user/getById".equals(path.toString())) {
return chain.filter(exchange);
}
//获取request对象并获取header中传递的token值
String token = exchange.getRequest().getHeaders().getFirst("token");
if(StringUtils.isEmpty(token)) {
//当token为空时,设置响应码,并返回response
exchange.getResponse().setStatusCode(HttpStatus.NOT_FOUND);
return exchange.getResponse().setComplete();
}
//当token验证通过,传递给下一个filter链。如果没有下一个,直接放行。
//通过.then的内部类实现了拦截post设置,将会在请求结束后,执行
return chain.filter(exchange).then(
Mono.fromRunnable(() -> {
System.out.println("访问结束");
})
);
}
/**
*可以设置多个filter,数值越小,优先级越高
*/
@Override
public int getOrder() {
return 0;
}
}4. 网关微服务限流
4.1 网关限流简介
目前分布式架构的设计都会进行两层限流配置:
第一层在NGINX,通过 limit_req_zone、limit_conn_zone来控制访问网关的速率和并发量;
第二层会在网关进行限流,对访问某个微服务进行访问限制
最终达到控制并发、保护微服务的作用。
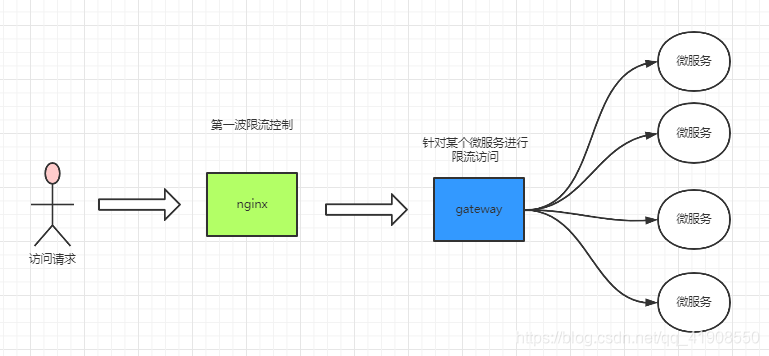
4.2 令牌桶算法限流
①匀速生成令牌存放在“令牌桶”中(存在Redis中),用于控制并发。令牌桶存在最大限额和最小限额
②当用户请求进来后,首先根据IP(或者URI、主机名、用户信息等)去令牌桶中获取一个令牌
③如果能够获取到令牌,则从桶中拿出一个token,放行执行业务逻辑
④如果没有获取到令牌,则返回繁忙响应
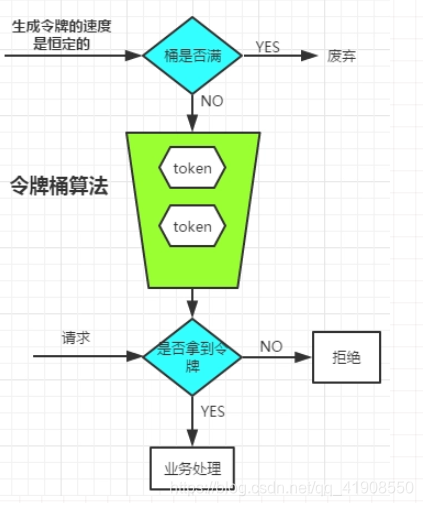
4.3 gateway限流demo:
①在网管服务中导入Redis的依赖包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>②实现限流可以自己写,也可以用spring-cloudAPI中实现的requestRateLimitGatewayFilterFactory直接配置使用
- 如果使用自己写的,可以写一个线程,用来往Redis中生成令牌,然后用gateway的filter拦截,验证令牌的数量以及是否可用来实现限流
- 使用requestRateLimitGatewayFilterFactory,则只需要实现KeyResolver接口设置用于获取令牌的唯一标识,以及配置文件中完成配置即可,如下:
实现KeyResolver:
/**
* @author hengtao.wu
* @Date 2020/11/9 10:43
**/
public class GatewayLimitConfig implements KeyResolver {
@Override
public Mono<String> resolve(ServerWebExchange exchange) {
//通过host地址来限流,
return Mono.just(exchange.getRequest().getRemoteAddress().getAddress().getHostAddress());
}
//注入到spring容器中
@Bean
public GatewayLimitConfig hostAddrKeyResolver() {
return new GatewayLimitConfig();
}
}编写配置文件:
如下配置文件表示:consumer80的这个微服务的限流策略是根据gatewayLimitConfig的唯一标识,最大访问量是3
routes:
- id: provider01 #任意的ID,不要重复
uri: lb://provider #需要转发的地址
filters:
- StripPrefix=1 #将打在网关上的url的第一个路由过滤掉后,再访问真实的服务器
- id: consumer01 #可以配置多个路由规则
uri: lb://consumer80
predicates:
- Path=/con/**
filters:
- name: RequestRateLimiter
args:
key-resolver: '#{@gatewayLimitConfig}'
redis-rate-limiter.replenishRate: 1 #最小令牌数(令牌桶中的数量)
redis-rate-limiter.burstCapacity: 3 #最大令牌书(每次生成的令牌数)
redis:
host: localhost
port: 6379
database: 0③总结
gateway的限流策略主要是对访问某个微服务进行过滤,一般情况下,直接使用springcloud提供的requestRateLimitGatewayFilterFactory,并实现keyResolver都可以满足需求。进行简单的限流
5. JWT使用
JWT是用来验证用户token的一种安全可靠的算法,主要有三部分组成,头部信息、用户信息、秘钥(该秘钥是唯一的)。
依赖包:
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.0</version>
</dependency>
测试类:
package com.lemon.tools;
import io.jsonwebtoken.*;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
/**
* @author hengtao.wu
* @Date 2020/11/9 11:32
**/
public class JwtTest {
public static void main(String[] args) {
getToken();
// System.out.println(checkToken("eyJhbGciOiJIUzI1NiJ9.eyJpc3MiOiJsZW1vbiIsImlhdCI6MTYwNDg5MzA4MSwiZXhwIjoxNjA0ODkzMTE2LCJzdWIiOiJqd3Tku6TniYwifQ.vXFhXuj3wuKEl80lENoGMvVtiJLAKKJG0eWJm7pWvrs"));
System.out.println(checkToken(getToken()));
}
public static String getToken() {
JwtBuilder builder = Jwts.builder();
builder.setIssuer("lemon"); //颁发者
builder.setIssuedAt(new Date()); //颁发时间
builder.setExpiration(new Date(System.currentTimeMillis() + 350000)); //过期时间35秒
builder.setSubject("jwt令牌"); //token主题
builder.signWith(SignatureAlgorithm.HS256, "lemon"); //设置加密算法、唯一秘钥(盐)
Map<String, Object> map = new HashMap<>();
map.put("userId", "asdfhqi23ihreuisadfa");
map.put("userNmae", "lemon");
map.put("phone", "15554356789");
map.put("companyId", "A1001");
builder.addClaims(map);
//或者
//
// builder.claim("userId", "asdfhqi23ihreuisadfa")
// .claim("userNmae", "lemon")
// .claim("phone", "15554356789")
// .claim("companyId", "A1001");
String compact = builder.compact();
System.out.println(compact);
return compact;
}
public static boolean checkToken(String token) {
Claims lemon = null;
try {
lemon = Jwts.parser().setSigningKey("lemon").parseClaimsJws(token).getBody();
} catch (Exception e) {
e.printStackTrace();
return false;
}
System.out.println(lemon.toString());
return true;
}
}
![]()
三. nginx限流
当访问的并发量特别大时、或者可能会遭受某些程序/个人恶意攻击网站导致系统资源被占用而宕机的情况下,我们需要对所有的访问进行限流配置。
常见的限流配置有很多:
- 程序中控制访问的线程数
- 通过服务降级或者熔断
- 通过代理服务nginx实现限流
- 通过nginx的负载均衡upstream配置最大连接数
通过nginx实现限流的思想是基于漏桶算法来实现。漏桶算法的核心思想就是,所有的用户请求都会进入到一个漏桶中,但是流出的时候是匀速控制流出的。
根据配置:
如果单位时间内,流入速度超过指定值,则直接拒绝请求。(针对某个IP/某个服务如果指定时间内超过了请求次数,直接拒绝访问)
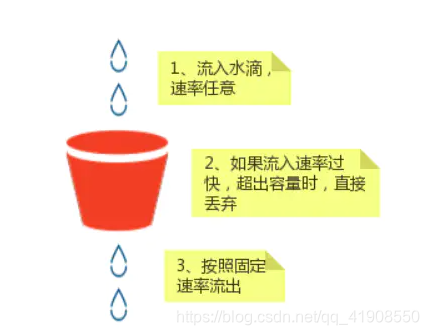
1. limit_req_zone:限制单位时间内的请求数(控制访问次数)
①如果我们需要nginx帮我们设置,单位时间内,一个IP只能访问x次,否则就跳出提示《手速太快了,请休息一下吧》
http {
#limit_req_zone:表示用来限制单位时间内的请求次数,采用的漏桶算法
#$binary_remote_addr :表示用用户的IP来进行标识
#zone=test:10m rate=10r/s:标识这个配置内存空间的别名是test,大小为10M,速率是每秒10次。当超过了每秒10次后就会被拒绝访问
limit_req_zone $binary_remote_addr zone=test:10m rate=10r/s;
...
server{
client_max_body_size 10M;
listen 80;
server_name 124.71.112.168;
location / {
root /opt/pms/static;
index index.html;
}
location /pmsapi{
#表示对于这个接口请求,采用test的限流配置
limit_req zone=test
proxy_pass http://127.0.0.1:8083;
}
}
}②但是,这样设置之后,对于该服务来说,当每秒超过10次后就会直接调到错误提示页面,显得不是特别友好,所以我们可以通过
将超过限制次数的请求缓存起来,存放在队列中。并指定队列中能缓存的次数,当前面请求结束后。继续处理队列中的请求,并且这些请求都是同步并发访问的
下面新增了配置:burst=5 nodelay;
burst=5:表示当超过了设置的10次/秒后,剩余的请求会被缓存在队列中,但是只能缓存5个,超过后还是会调到错误提示页面
nodelay:表示所有的请求都是同步进行的,不会造成异步阻塞。如果没设置,如果当前一秒同一个IP有20个请求进来,10个被接受,5个被缓存,剩余的5个需要在前15个处理结束后(阻塞等待)才会被拒绝。如果设置了,20个请求时同步执行的,会立马被拒绝
http {
#limit_req_zone:表示用来限制单位时间内的请求次数,采用的漏桶算法
#$binary_remote_addr :表示用用户的IP来进行标识
#zone=test:10m rate=10r/s:标识这个配置内存空间的别名是test,大小为10M,速率是每秒10次。当超过了每秒10次后就会被拒绝访问
limit_req_zone $binary_remote_addr zone=test:10m rate=10r/s;
...
server{
client_max_body_size 10M;
listen 80;
server_name 124.71.112.168;
location / {
root /opt/pms/static;
index index.html;
}
location /pmsapi{
#表示对于这个接口请求,采用test的限流配置,并设置缓存5个队列请求,所有请求同步进行
limit_req zone=test burst=5 nodelay;
proxy_pass http://127.0.0.1:8083;
}
}
}
通过以上配置,就可以实现 对同一IP,限制请求次数(限制速率)
2. ngx_http_limit_conn_module 限制并发量(控制连接数)
控制某个IP连接的个数
limit_conn_zone $binary_remote_addr zone=ipAddr:10m;
控制某个服务(server)所有的连接的个数
limit_conn_zone $server_name zone=serviceLimit:10m;
使用limit_conn_zone来控制客户端能够创建的所有连接数,来达到控制并发的目的。所谓并发数,可以理解为在线数/打开的连接数,类似于请求数
具体配置:
http {
#limit_req_zone:表示用来限制单位时间内的请求次数,采用的漏桶算法
#$binary_remote_addr :表示用用户的IP来进行标识
#zone=test:10m rate=10r/s:标识这个配置内存空间的别名是test,大小为10M,速率是每秒10次。当超过了每秒10次后就会被拒绝访问
#limit_req_zone $binary_remote_addr zone=test:10m rate=10r/s;
limit_conn_zone $binary_remote_addr zone=ipAddr:10m;
limit_conn_zone $server_name zone=serviceLimit:10m;
...
server{
client_max_body_size 10M;
listen 80;
server_name 124.71.112.168;
location / {
root /opt/pms/static;
index index.html;
}
location /pmsapi{
#表示对于这个接口请求,采用test的限流配置
#limit_req zone=test burst=5 nodelay;
#表示同一个IP只能同时创建10个连接
limit_conn ipAddr 10;
#表示该server所有的客户端同时只能创建100个连接,也就是该server的最大并发数是100
limit_conn serviceLimit 100;
proxy_pass http://127.0.0.1:8083;
}
}
}通过以上两种方式可以实现:
- 针对某个IP进行请求速率的限制
- 针对某个IP进行最大同时连接数的限制
- 针对某个server进行同时最大连接数的限制(并发量的限制)
当然,限流的配置可以同时搭配:
限流被拒绝后,错误页面、白名单配置、限流日志的记录等

















 1818
1818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









